
Aprendizaje automático y Data Science (Parte 42): Pronóstico de series temporales de Forex con ARIMA en Python, todo lo que necesitas saber

Contenido
- ¿Qué es la pronóstico de series temporales mediante series temporales?
- Introducción a los modelos ARIMA
- Componentes clave de un modelo ARIMA
- Modelo ARIMA en Python
- Creación de un modelo ARIMA para EURUSD
- Predicciones fuera de muestra utilizando ARIMA
- Gráficos de residuos del modelo ARIMA
- Modelo SARIMA
- Conclusión
¿Qué es la pronóstico de series temporales?
La pronóstico de series temporales es el proceso de utilizar datos pasados para predecir valores futuros en una secuencia de puntos de datos. Esta secuencia suele ordenarse cronológicamente, de ahí el nombre de serie temporal.
Variables fundamentales en las series temporales
Aunque nuestros datos pueden contener tantas variables explicativas como queramos, cualquier conjunto de datos destinado al análisis o pronóstico de series temporales debe incluir estas dos variables.
- Tiempo
Se trata de una variable independiente que representa los momentos concretos en los que se observaron los valores de los datos. - Variable objetivo
Es el valor que se intenta predecir a partir de observaciones pasadas y, posiblemente, de otros factores. (por ejemplo, el precio de cierre diario de las acciones, la temperatura por hora, el tráfico del sitio web por minuto).
El objetivo de la pronóstico de series temporales es aprovechar los patrones y tendencias históricos de los datos para realizar predicciones fundamentadas sobre los valores futuros.
Ya hemos hablado anteriormente sobre la pronóstico de series temporales mediante modelos de IA convencionales. En este artículo, vamos a abordar la pronóstico de series temporales utilizando un modelo diseñado específicamente para este tipo de problemas, conocido como ARIMA.
La pronóstico de series temporales se puede dividir en dos tipos.
- Previsión univariante de series temporales
Se trata de un problema de pronóstico de series temporales en el que se utiliza una variable predictora para predecir sus valores futuros. Por ejemplo, utilizar los precios de cierre actuales de una acción para predecir los precios de cierre futuros.
Este es el tipo de pronóstico de series temporales que permiten realizar los modelos ARIMA. - Previsión multivariante de series temporales
Se trata de un problema de pronóstico de series temporales en el que se utilizan múltiples variables predictoras para predecir una variable objetivo en el futuro.
De forma similar a lo que hicimos en este artículo.
Introducción a los modelos ARIMA
ARIMA son las siglas de «Autoregressive Integrated Moving Average» (modelo autorregresivo integrado de media móvil)
Pertenece a una clase de modelos que explican una serie temporal determinada basándose en sus valores pasados, es decir, en sus valores retrasados y en los errores de pronóstico de series temporales retrasados.
La ecuación se puede utilizar para predecir valores futuros. Cualquier serie temporal «no estacional» que presente patrones y no sea un ruido blanco aleatorio puede modelarse con modelos ARIMA.
Así pues, ARIMA, abreviatura de «AutoRegressive Integrated Moving Average» (media móvil autorregresiva integrada), es un algoritmo de pronóstico de series temporales basado en la idea de que la información contenida en los valores pasados de una serie temporal puede utilizarse por sí sola para predecir los valores futuros.
Los modelos ARIMA se definen mediante tres parámetros de orden: (p, d, q).
Donde:
- p es el orden del término AR.
- q es el orden del término de la media móvil.
- d es el número de diferencias necesarias para que la serie temporal sea estacionaria.
El significado de p, d y q en el modelo ARIMA
El significado de p
p es el orden del término autorregresivo (AR). Se refiere al número de retardos de Y que se utilizarán como predictores.
El significado de d
En ARIMA, el término autorregresivo indica que se trata de un modelo de regresión lineal que utiliza sus retardos como predictores. Como sabemos, los modelos de regresión lineal funcionan mejor cuando las variables predictoras no están correlacionadas y son independientes entre sí, por lo que necesitamos que la serie temporal sea estacionaria.
El método más común para hacer que la serie sea estacionaria es diferenciarla. Es decir, se resta el valor anterior al valor actual. En ocasiones, dependiendo de la complejidad de la serie, puede ser necesario realizar más de una diferenciación.
Por lo tanto, el valor de d es el número mínimo de diferencias necesarias para que la serie sea estacionaria. Si la serie temporal ya es estacionaria, entonces d = 0.
El significado de q
q es el orden del término de Media Móvil (MA). Se refiere al número de errores de pronóstico rezagados que deben incluirse en el modelo ARIMA.
Componentes clave de un modelo ARIMA
Para comprender ARIMA, necesitamos descomponer sus componentes básicos. Una vez que hayamos desglosado los componentes, será más fácil comprender cómo funciona este método de pronóstico de series temporales en su conjunto.
El nombre ARIMA se puede dividir en tres partes (AR, I, MA) como se describe a continuación.
Parte autorregresiva AR(p)
El componente autorregresivo (AR) construye una tendencia a partir de valores pasados en el marco AR para modelos predictivos. Para mayor claridad, el "marco de autorregresión" funciona como un modelo de regresión en el que se utilizan los desfases de los valores pasados de la propia serie temporal como regresores.
Esta parte se calcula mediante la siguiente fórmula:
![]()
Donde:
-
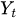 es el valor actual de la serie temporal en el instante t.
es el valor actual de la serie temporal en el instante t. -
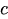 es el término constante.
es el término constante. -
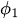 a
a 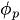 son los parámetros autorregresivos (coeficientes) que indican en qué medida cada valor atrasado contribuye al valor actual.
son los parámetros autorregresivos (coeficientes) que indican en qué medida cada valor atrasado contribuye al valor actual. -
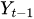 a
a 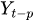 son los valores rezagados de la serie temporal.
son los valores rezagados de la serie temporal. -
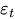 es el término de error en el instante t.
es el término de error en el instante t.
Parte I(d) integrada
La parte integrada (I) implica la diferenciación del componente de la serie temporal teniendo en cuenta que nuestra serie temporal debe ser estacionaria, lo que significa que la media y la varianza deben permanecer constantes durante un período de tiempo.
Básicamente, restamos una observación de otra para eliminar las tendencias y la estacionalidad. Al realizar la diferenciación, obtenemos la estacionariedad. Este paso es necesario porque ayuda a que el modelo se ajuste a los datos y no al ruido.
Parte de media móvil MA(q)
El componente de media móvil (MA) se centra en la relación entre una observación y un error residual. Al analizar cómo se relaciona la observación actual con los errores del pasado, podemos inferir información útil sobre cualquier posible tendencia en nuestros datos.
Podemos considerar los residuos entre uno de estos errores, y el concepto del modelo de media móvil estima o considera su impacto en nuestra última observación. Esto resulta especialmente útil para rastrear y detectar cambios a corto plazo en los datos o perturbaciones aleatorias. En la parte (MA) de una serie temporal, podemos obtener información valiosa sobre su comportamiento, lo que a su vez nos permite pronosticar y predecir con mayor precisión.
![]()
Donde:
-
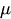 es una constante.
es una constante. -
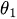 es el parámetro MA.
es el parámetro MA. -
 es el error anterior.
es el error anterior. -
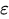 es el error actual.
es el error actual.
Modelo ARIMA en Python
Así pues, un modelo ARIMA es simplemente una combinación de las tres partes descritas anteriormente: las partes AR, I y MA, tal como se han descrito anteriormente. Su ecuación ahora queda así:
![]()
Ahora bien, el reto en los modelos ARIMA consiste en encontrar los parámetros adecuados (los valores p, d y q). Dado que estos valores son los que determinan el funcionamiento del modelo, vamos a entender cómo encontrarlos.
Encontrar el orden del término AR (p)
Podemos determinar el número necesario de términos AR analizando el gráfico de autocorrelación parcial (PACF).
La autocorrelación parcial puede definirse como la correlación entre la serie y su(s) retardo(s), una vez excluidas las contribuciones de los retardos intermedios. Así pues, la función de autocorrelación parcial (PACF) transmite, en cierto modo, la correlación pura entre un retardo y la serie. De esta forma, sabremos si ese retardo es necesario en el término AR o no.
Comience instalando todas las dependencias en el símbolo del sistema (CMD). El archivo requirements.txt se adjunta al final de esta publicación.
pip install -r requirements.txt
Importaciones.
# Importing required libraries import pandas as pd import numpy as np import MetaTrader5 as mt5 # Use auto_arima to automatically select best ARIMA parameters import seaborn as sns import matplotlib.pyplot as plt import warnings import os # Suppress warning messages for cleaner output warnings.filterwarnings("ignore") # Set seaborn plot style for better visualization sns.set_style("darkgrid")
Obtener los datos de MetaTrader 5.
# Getting (EUR/USD OHLC data) from MetaTrader5 mt5_exe_file = r"c:\Users\Omega Joctan\AppData\Roaming\Pepperstone MetaTrader 5\terminal64.exe" # Change this to your MetaTrader5 path if not mt5.initialize(mt5_exe_file): print("Failed to initialize Metatrader5, error = ",mt5.last_error) exit() # select a symbol into the market watch symbol = "EURUSD" timeframe = mt5.TIMEFRAME_D1 if not mt5.symbol_select(symbol, True): print(f"Failed to select {symbol}, error = {mt5.last_error}") mt5.shutdown() exit() rates = mt5.copy_rates_from_pos(symbol, timeframe, 1, 1000) # Get 1000 bars historically df = pd.DataFrame(rates) print(df.head(5)) print(df.shape)
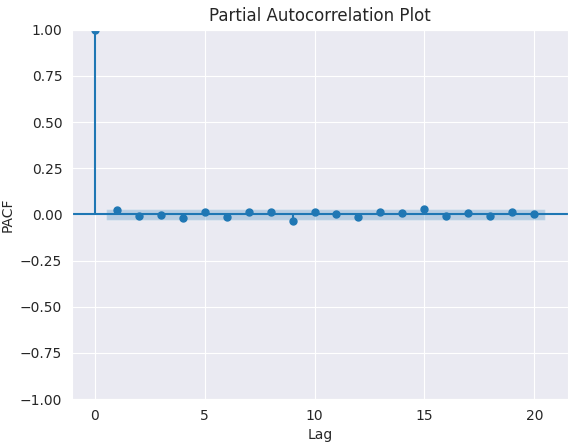
Gráfico PACF.
from statsmodels.graphics.tsaplots import plot_pacf import matplotlib.pyplot as plt plt.figure(figsize=(6,4)) plot_pacf(series.diff().dropna(), lags=5) plt.title("Partial Autocorrelation Plot") plt.xlabel('Lag') # X-axis label plt.ylabel('PACF') # Y-axis label plt.savefig("pacf plot.png") plt.show()
Resultados.
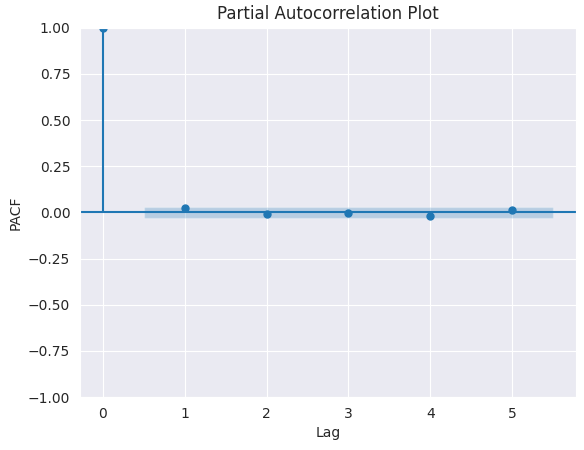
Para determinar el valor correcto de p, buscamos el retardo después del cual la función de autocorrelación parcial (PACF) deja de ser significativa en el gráfico (disminuye cerca de cero y permanece insignificante). Ese valor de retardo es el candidato correcto para p.
Según el gráfico anterior, el valor p correcto es 0 (todos los desfases posteriores a 0 son insignificantes).
Determinación del orden de diferenciación (d) en un modelo ARIMA
Como se explicó anteriormente, el propósito de diferenciar una serie temporal es hacerla estacionaria, ya que el modelo ARIMA asume la estacionariedad, pero debemos tener cuidado de no subdiferenciar ni sobrediferenciar una serie temporal.
El orden correcto de diferenciación es el mínimo necesario para obtener una serie casi estacionaria, que oscile alrededor de una media definida y cuyo gráfico de la función de autocorrelación (ACF) llegue a cero con bastante rapidez.
Si las autocorrelaciones son positivas para un número elevado de retardos (10 o más), entonces es necesario diferenciar aún más la serie. Por otro lado, si el retardo 1 de la autocorrelación es demasiado negativo, entonces es probable que la serie esté sobrediferenciada.
Si no podemos decidir entre dos órdenes de diferenciación, entonces elegimos el orden que produce la menor desviación estándar en la serie diferenciada.
Utilizando los precios de cierre del EURUSD, encontremos el orden correcto de diferenciación.
En primer lugar, debemos comprobar si la serie dada es estacionaria (en este caso, los precios de cierre) utilizando la prueba de Dickey-Fuller aumentada (prueba ADF), del paquete statsmodels en Python. Verificamos la estacionariedad porque solo queremos encontrar el orden de diferenciación para una serie no estacionaria.
La hipótesis nula (Ho) de la prueba ADF es que la serie temporal no es estacionaria. Por lo tanto, si el valor p de la prueba es menor que el nivel de significancia (0,05), rechazamos la hipótesis nula e inferimos que la serie temporal es efectivamente estacionaria.
Entonces, en nuestro caso, si el valor P > 0,05, procedemos a encontrar el orden correcto de diferenciación.
Incluso antes de la prueba ADF, podemos observar en el gráfico de líneas que los precios de cierre del EURUSD no son estacionarios.
plt.figure(figsize=(7,5)) sns.lineplot(df, x=df.index, y="Close") plt.savefig("close prices.png")
Resultados.
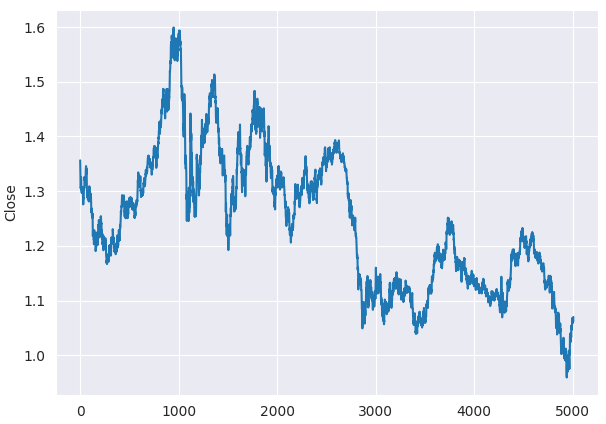
Comprobación de la estacionariedad.
from statsmodels.tsa.stattools import adfuller series = df["Close"] result = adfuller(series) print(f'p-value: {result[1]}')
Resultados.
p-value: 0.3707268514544181
Como puede verse, el valor p es mucho mayor que el nivel de significancia (0,05). Diferenciemos la serie una vez, luego dos veces, y veamos cómo queda el gráfico de autocorrelación.
# Original Series fig, axes = plt.subplots(3, 2, sharex=True, figsize=(9, 9)) axes[0, 0].plot(series); axes[0, 0].set_title('Original Series') plot_acf(series, ax=axes[0, 1]) # 1st Differencing axes[1, 0].plot(series.diff().dropna()); axes[1, 0].set_title('1st Order Differencing') plot_acf(series.diff().dropna(), ax=axes[1, 1]) # 2nd Differencing axes[2, 0].plot(series.diff().diff()); axes[2, 0].set_title('2nd Order Differencing') plot_acf(series.diff().diff().dropna(), ax=axes[2, 1]) plt.savefig("acf plots.png") plt.show()
Resultados.
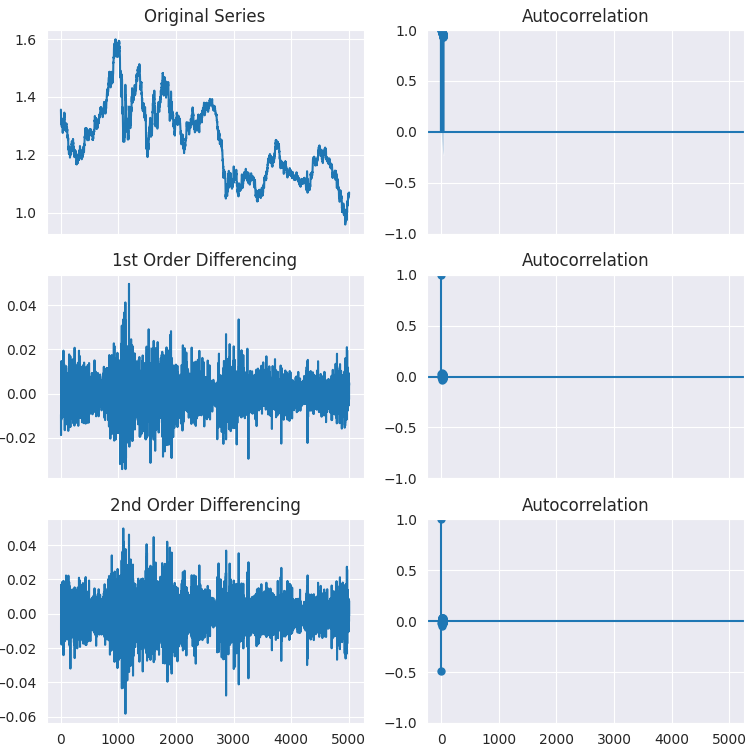
Como se puede observar en los gráficos, la primera diferenciación cumple su función, ya que no se observa ninguna diferencia significativa en el resultado de la estacionariedad en la segunda diferenciación. Esto puede verificarse una vez más mediante la prueba ADF.
result = adfuller(series.diff().dropna()) print(f'p-value d=1: {result[1]}') result = adfuller(series.diff().diff().dropna()) print(f'p-value d=2: {result[1]}')
Resultados.
p-value d=1: 0.0 p-value d=2: 0.0
Encontrar el orden del término MA (q)
Al igual que analizamos el gráfico PACF para el número de términos AR (p), analizaremos el gráfico ACF para el número de términos MA. Nuevamente, el término MA se relaciona, técnicamente, con los errores de pronóstico rezagados.
El gráfico ACF nos indica cuántos términos MA se requieren para eliminar cualquier autocorrelación en la serie estacionaria.
plt.figure(figsize=(7,5)) plot_pacf(series.diff().dropna(), lags=20) plt.title("Partial Autocorrelation Plot") plt.xlabel('Lag') # X-axis label plt.ylabel('PACF') # Y-axis label plt.savefig("pacf plot finding q.png") plt.show()
Resultados.
El mejor valor de q es 0.
Dado que los métodos descritos anteriormente para hallar los valores de p, d y q son rudimentarios y manuales, podemos automatizar este proceso y hallar los parámetros sin mucha dificultad utilizando una función de utilidad de pmdarima llamada auto_arima.
from pmdarima.arima import auto_arima model = auto_arima(series, seasonal=False, trace=True) print(model.summary())
Resultados.
Performing stepwise search to minimize aic ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=-35532.282, Time=3.21 sec ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=-35537.068, Time=0.49 sec ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=-35537.492, Time=0.59 sec ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=-35537.511, Time=0.74 sec ARIMA(0,1,0)(0,0,0)[0] : AIC=-35538.731, Time=0.25 sec ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=-35535.683, Time=1.22 sec Best model: ARIMA(0,1,0)(0,0,0)[0] Total fit time: 6.521 seconds
Y así, sin más, obtuvimos los mismos parámetros que al realizar el análisis manual.
Creación de un modelo ARIMA en EURUSD
Ahora que hemos determinado los valores de p, d y q, tenemos todo lo necesario para ajustar (entrenar) el modelo ARIMA.
from statsmodels.tsa.arima.model import ARIMA arima_model = ARIMA(series, order=(0,1,0)) arima_model = arima_model.fit() print(arima_model.summary())
Resultados.
SARIMAX Results ============================================================================== Dep. Variable: Close No. Observations: 4007 Model: ARIMA(0, 1, 0) Log Likelihood 13987.647 Date: Mon, 26 May 2025 AIC -27973.293 Time: 16:59:38 BIC -27966.998 Sample: 0 HQIC -27971.062 - 4007 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 5.427e-05 7.78e-07 69.768 0.000 5.27e-05 5.58e-05 =================================================================================== Ljung-Box (L1) (Q): 1.47 Jarque-Bera (JB): 1370.86 Prob(Q): 0.22 Prob(JB): 0.00 Heteroskedasticity (H): 0.49 Skew: 0.09 Prob(H) (two-sided): 0.00 Kurtosis: 5.86 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
Ahora vamos a entrenar este modelo con algunos datos y usarlo para hacer predicciones sobre datos fuera de la muestra, de forma similar a como lo hacemos con los modelos clásicos de aprendizaje automático.
Comenzando por dividir los datos en muestras de entrenamiento y de prueba.
series = df["Close"] train_size = int(len(series) * 0.8) train, test = series[:train_size], series[train_size:]
Ajustando el modelo a los datos de entrenamiento.
from statsmodels.tsa.arima.model import ARIMA arima_model = ARIMA(train, order=(0,1,0)) arima_model = arima_model.fit() print(arima_model.summary())
Realizar predicciones a partir de los datos de entrenamiento.
predicted = arima_model.predict(start=1, end=len(train))
Visualizando el resultado.
plt.figure(figsize=(7,4)) plt.plot(train.index, train, label='Actual') plt.plot(train.index, predicted, label='Forecasted mean', linestyle='--') plt.title('Actual vs Forecast') plt.legend() plt.show()
Resultados.
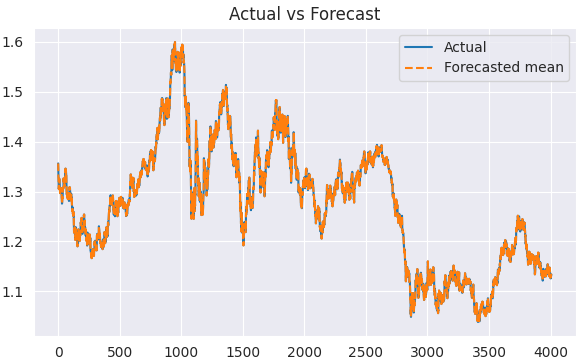
Ahora que tenemos los valores reales y los pronosticados, podemos evaluar el modelo utilizando cualquier técnica de evaluación o función de pérdida que elijamos.
Pero antes de eso, busquemos la manera de utilizar este modelo ARIMA para hacer predicciones sobre los datos fuera de la muestra.
Predicciones fuera de muestra utilizando ARIMA
A diferencia de los algoritmos clásicos de aprendizaje automático, estos modelos tradicionales de pronóstico de series temporales adoptan un enfoque diferente a la hora de realizar predicciones sobre información que no han visto antes.
En los marcos de aprendizaje automático clásicos y las bibliotecas de Python, un método llamado predict, cuando se llama con una matriz de datos, hace una pronóstico de series temporales/adivina el/los siguiente/s valor/es (futuro/s), pero la función predict que ofrece el módulo ARIMA hace un trabajo bastante diferente.
En los modelos ARIMA, este método no predice necesariamente el futuro; solo resulta útil a la hora de realizar predicciones basadas en los datos de la muestra (la información ya presente en el modelo), es decir, los datos de entrenamiento.
Para comprender esto, analicemos la diferencia entre predecir y pronosticar.
Predecir consiste en estimar valores desconocidos (futuros o de otro tipo) utilizando cualquier modelo, mientras que pronosticar se refiere a predecir valores futuros en una serie temporal de datos aprovechando patrones y dependencias temporales.
La pronóstico de series temporales puede aplicarse a problemas como clasificar la dirección del mercado o estimar el próximo precio de cierre, mientras que el pronóstico se usa para anticipar valores futuros de una serie temporal a partir de sus patrones temporales.
En el modelo ARIMA, el método de pronóstico de series temporales se utiliza normalmente para realizar pronósticos de los valores pasados de los que el modelo ha aprendido; por eso toma el índice inicial y el índice final. También puede tomar la cantidad de pasos en el pasado que desea predecir (evaluar).
predicted = arima_model.predict(start=1, end=len(train))
print(arima_model.predict(steps=10))
Para calcular los valores futuros, debemos utilizar un método denominado forecast().
Como se ha mencionado anteriormente, los modelos tradicionales basados en series temporales, como el ARIMA, se basan en los valores anteriores para predecir los siguientes, tal y como se puede observar en su fórmula de la figura 03.
Esto significa que debemos actualizar constantemente el modelo con nueva información para que siga siendo relevante. Por ejemplo, para que un modelo ARIMA haga una pronóstico de series temporales del precio de cierre de mañana del EURUSD, este modelo debe recibir como entrada el precio de cierre de hoy del mismo instrumento (símbolo); lo mismo se aplica para mañana y el día siguiente.
Esto es bastante diferente de lo que hacemos en el aprendizaje automático clásico.
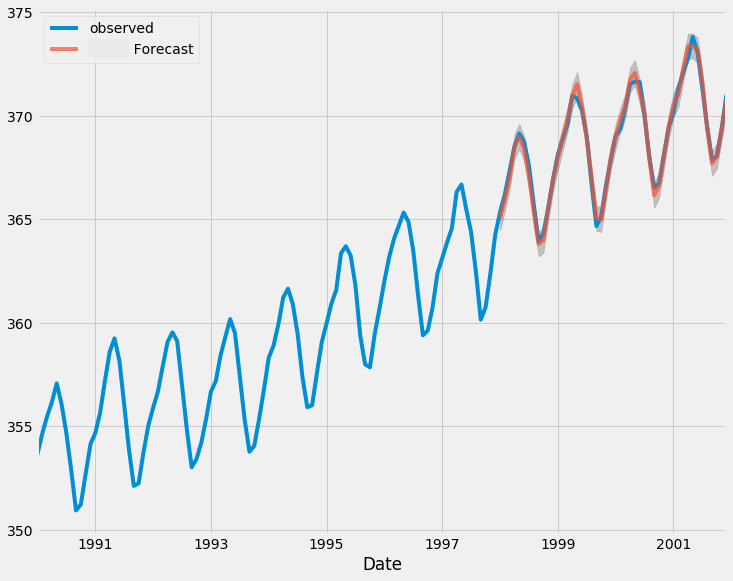
Ahora vamos a hacer predicciones con datos fuera de la muestra.
# Fit initial model model = ARIMA(train, order=(0, 1, 0)) results = model.fit() # Initialize forecasts forecasts = [results.forecast(steps=1).iloc[0]] # First forecast # Update with test data iteratively for i in range(len(test)): # Append new observation without refitting results = results.append(test.iloc[i:i+1], refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) forecasts = forecasts[:-1] # remove the last element which is the predicted next value # Compare forecasts vs actual test data plt.plot(test.index, test, label="Actual") plt.plot(test.index, forecasts, label="Forecast", linestyle="--") plt.legend()
El método append inserta información nueva (actual) en el modelo. En este caso, se utiliza el precio de cierre actual del EURUSD para pronosticar el próximo precio de cierre.
refit=False garantiza que el modelo no se vuelva a entrenar. Esto hace que sea una forma eficaz de actualizar el modelo ARIMA.
Vamos a crear una función con un par de métricas de evaluación que podamos usar para evaluar el rendimiento del modelo ARIMA.
import sklearn.metrics as metric from statsmodels.tsa.stattools import acf from scipy.stats import pearsonr def forecast_accuracy(forecast, actual): # Convert to numpy arrays if they aren't already forecast = np.asarray(forecast) actual = np.asarray(actual) metrics = { 'mape': metric.mean_absolute_percentage_error(actual, forecast), 'me': np.mean(forecast - actual), # Mean Error 'mae': metric.mean_absolute_error(actual, forecast), 'mpe': np.mean((forecast - actual) / actual), # Mean Percentage Error 'rmse': metric.mean_squared_error(actual, forecast, squared=False), 'corr': pearsonr(forecast, actual)[0], # Pearson correlation 'minmax': 1 - np.mean(np.minimum(forecast, actual) / np.maximum(forecast, actual)), 'acf1': acf(forecast - actual, nlags=1)[1], # ACF of residuals at lag 1 "r2_score": metric.r2_score(forecast, actual) } return metrics
forecast_accuracy(forecasts, test)
Resultados.
{'mape': 0.0034114761554881936,
'me': 6.360279441117738e-05,
'mae': 0.0037872155688622737,
'mpe': 6.825424905960248e-05,
'rmse': 0.005018824533752777,
'corr': 0.99656297100796,
'minmax': 0.0034008221524469695,
'acf1': 0.04637470541528736,
'r2_score': 0.9931220697334551} El valor de MAPE de 0,003 sugiere, según la interpretación del autor, una precisión aproximada del 99,996%; un valor similar también puede observarse en el r2_score.
A continuación se muestra el gráfico que compara los resultados reales y previstos de la muestra de prueba.
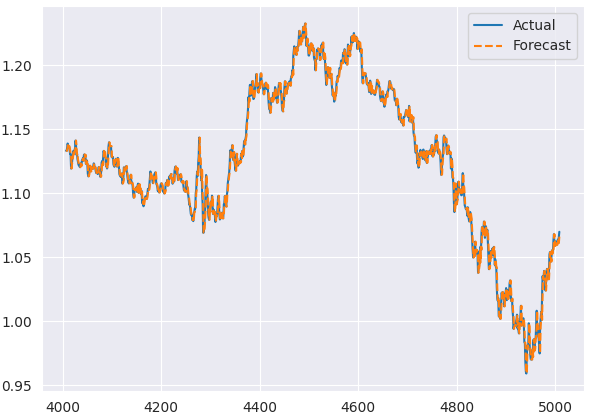
Gráficos de residuos del modelo ARIMA
ARIMA incluye métodos para visualizar los residuos y así comprender mejor el modelo.
results.plot_diagnostics(figsize=(8,8)) plt.show()
Resultados.
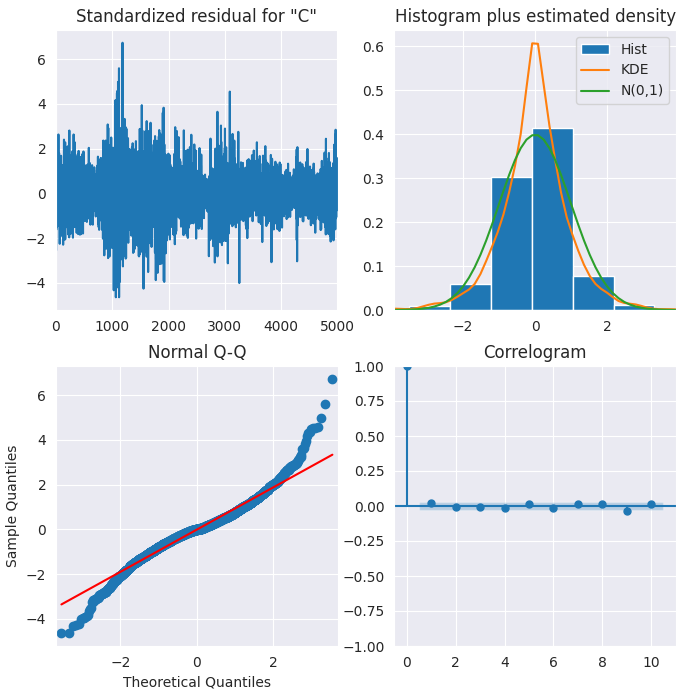
Residuo estandarizado
Los errores residuales parecen fluctuar alrededor de una media de cero y tienen una varianza uniforme.
Histograma
El gráfico de densidad sugiere una distribución normal con la media ligeramente desplazada hacia la derecha.
Cuantiles teóricos
La mayoría de los puntos coinciden perfectamente con la línea roja. Cualquier desviación significativa implicaría que la distribución está sesgada.
Correlograma
El correlograma (o gráfico ACF) muestra que los errores residuales no están autocorrelacionados. El gráfico ACF implicaría que existe algún patrón en los errores residuales que no se explican en el modelo, por lo que necesitaremos buscar más X (predictores) para el modelo.
En general, el modelo parece ser adecuado.
Modelo SARIMA
El modelo ARIMA simple tiene un problema. No admite la estacionalidad.
La estacionalidad se refiere a patrones recurrentes en los datos financieros que se repiten a intervalos fijos, como por ejemplo cada hora, día, semana, mes, trimestre y año.
Con frecuencia observamos que los instrumentos presentan ciertos patrones repetitivos. Por ejemplo, las acciones minoristas suelen dispararse en el cuarto trimestre (temporada de compras navideñas), mientras que algunas acciones energéticas pueden seguir patrones climáticos estacionales; en los instrumentos de divisas podemos observar una mayor volatilidad del mercado durante ciertas sesiones de negociación, etc.
Si los datos de la serie temporal presentan una estacionalidad observable o definida, entonces deberíamos optar por el modelo ARIMA estacional (o SARIMA, por sus siglas en inglés), ya que utiliza la diferenciación estacional.
Componentes del modelo SARIMAX(p, d, q)x(P, D, Q, S)
- Autorregresión (AR)
Como se describió anteriormente, la autorregresión examina los valores pasados de la serie temporal para predecir los valores actuales. - Media móvil (MA)
El componente de media móvil sigue modelando los errores pasados de predicción. - Integración (I)
La integración siempre está presente para hacer que la serie temporal sea estacionaria. - Componente estacional (S)
El componente estacional capta las variaciones que se repiten a intervalos regulares.
La diferenciación estacional es similar a la diferenciación regular, pero, en lugar de restar términos consecutivos, restamos el valor de la temporada anterior.
Antes de aplicar el modelo SARIMAX, determinemos los parámetros adecuados para él utilizando auto_arima.
from pmdarima.arima import auto_arima # Auto-fit SARIMA (automatically detects P, D, Q, S) auto_model = auto_arima( series, seasonal=True, # Enable seasonality m=5, # Weeky cycle (5 days) for daily data trace=True, # Show search progress stepwise=True, # Faster optimization suppress_warnings=True, error_action="ignore" ) print(auto_model.summary())
Resultados.
Performing stepwise search to minimize aic ARIMA(2,1,2)(1,0,1)[5] intercept : AIC=-35529.092, Time=3.81 sec ARIMA(0,1,0)(0,0,0)[5] intercept : AIC=-35537.068, Time=0.29 sec ARIMA(1,1,0)(1,0,0)[5] intercept : AIC=-35536.573, Time=0.97 sec ARIMA(0,1,1)(0,0,1)[5] intercept : AIC=-35536.570, Time=4.38 sec ARIMA(0,1,0)(0,0,0)[5] : AIC=-35538.731, Time=0.21 sec ARIMA(0,1,0)(1,0,0)[5] intercept : AIC=-35536.048, Time=0.67 sec ARIMA(0,1,0)(0,0,1)[5] intercept : AIC=-35536.024, Time=0.87 sec ARIMA(0,1,0)(1,0,1)[5] intercept : AIC=-35534.248, Time=0.92 sec ARIMA(1,1,0)(0,0,0)[5] intercept : AIC=-35537.492, Time=0.37 sec ARIMA(0,1,1)(0,0,0)[5] intercept : AIC=-35537.511, Time=0.55 sec ARIMA(1,1,1)(0,0,0)[5] intercept : AIC=-35535.683, Time=0.57 sec Best model: ARIMA(0,1,0)(0,0,0)[5] Total fit time: 13.656 seconds SARIMAX Results ============================================================================== Dep. Variable: y No. Observations: 5009 Model: SARIMAX(0, 1, 0) Log Likelihood 17770.365 Date: Tue, 27 May 2025 AIC -35538.731 Time: 11:16:40 BIC -35532.212 Sample: 0 HQIC -35536.446 - 5009 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 4.846e-05 6.06e-07 80.005 0.000 4.73e-05 4.96e-05 =================================================================================== Ljung-Box (L1) (Q): 2.42 Jarque-Bera (JB): 2028.68 Prob(Q): 0.12 Prob(JB): 0.00 Heteroskedasticity (H): 0.34 Skew: 0.08 Prob(H) (two-sided): 0.00 Kurtosis: 6.11 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
Aunque no es necesario volver a ajustar el modelo manualmente, ya que `auto_arima` devuelve un modelo SARIMAX, el reajuste manual de un modelo SARIMAX nos permite tener un mayor control sobre los resultados, así que vamos a hacerlo de nuevo.
from statsmodels.tsa.statespace.sarimax import SARIMAX model = SARIMAX( train, order=auto_model.order, # Non-seasonal (p,d,q) seasonal_order=auto_model.order+(5,), # Seasonal (P,D,Q,S) enforce_stationarity=False ) results = model.fit() print(results.summary())
Resultados.
SARIMAX Results ========================================================================================= Dep. Variable: Close No. Observations: 4007 Model: SARIMAX(0, 1, 0)x(0, 1, 0, 5) Log Likelihood 12613.829 Date: Tue, 27 May 2025 AIC -25225.658 Time: 11:16:41 BIC -25219.364 Sample: 0 HQIC -25223.427 - 4007 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 0.0001 1.68e-06 63.423 0.000 0.000 0.000 =================================================================================== Ljung-Box (L1) (Q): 3.42 Jarque-Bera (JB): 676.61 Prob(Q): 0.06 Prob(JB): 0.00 Heteroskedasticity (H): 0.48 Skew: -0.01 Prob(H) (two-sided): 0.00 Kurtosis: 5.01 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
Dado que el modelo devuelto por auto_model es un ARIMA(p,d,q), a pesar de haber establecido el valor de estacionalidad en «true». Tenemos que añadir el valor 5 a una tupla al declarar el modelo SARIMAX para garantizar que el modelo sea ahora (p,d,q,s).
Antes de visualizar y analizar los resultados reales y previstos, debemos eliminar de nuestra matriz los primeros elementos, que corresponden a la ventana estacional. Los valores anteriores a este son incompletos.
predicted = results.predict(start=1, end=len(train)) clean_train = train[5:] clean_predicted = predicted[5:] plt.figure(figsize=(7,4)) plt.plot(clean_train.index[5:], clean_train[5:], label='Actual') plt.plot(clean_train.index[5:], clean_predicted[5:], label='Forecasted mean', linestyle='--') plt.title('Actual vs Forecast') plt.legend() plt.savefig("sarimax train actual&forecast plot.png") plt.show()
Resultados.
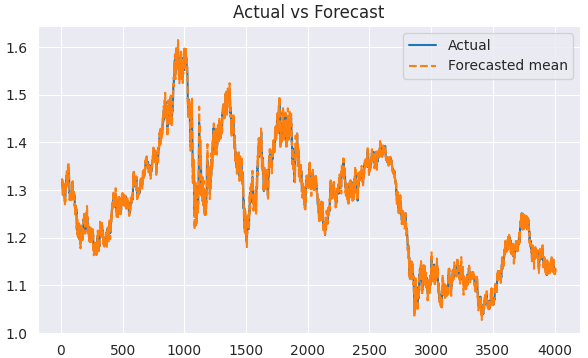
Podemos evaluar este modelo de forma similar a como evaluamos el modelo ARIMA.
# Initialize forecasts forecasts = [results.forecast(steps=1).iloc[0]] # First forecast # Update with test data iteratively for i in range(len(test)): # Append new observation without refitting results = results.append(test.iloc[i:i+1], refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) clean_test = test[5:] forecasts = forecasts[5:-1] # remove the last element which is the predicted next value and the first 5 items
forecast_accuracy(forecasts, clean_test)
Resultados.
{'mape': 0.004900183060803821,
'me': -6.94082142749275e-06,
'mae': 0.005432456867698095,
'mpe': -7.226495372320155e-06,
'rmse': 0.007127465498996785,
'corr': 0.9931778828074744,
'minmax': 0.004880027322298863,
'acf1': 0.10724254539104018,
'r2_score': 0.9864021833085908} Una precisión del 98,6% según el coeficiente r2. Un valor aceptable.
Finalmente, podemos utilizar el modelo ARIMA para realizar predicciones en tiempo real según los datos recibidos de MetaTrader5.
En primer lugar, tenemos que importar la biblioteca de programación para que nos ayude a hacer predicciones después de un día, ya que entrenamos este modelo en un marco temporal diario.
import schedule # Make realtime predictions based on the recent data from MetaTrader5 def predict_close(): rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 1) if not rates: print(f"Failed to get recent OHLC values, error = {mt5.last_error}") time.sleep(60) rates_df = pd.DataFrame(rates) global results # Get the variable globally, outside the function global forecasts # Append new observation to the model without refitting new_obs_value = rates_df["close"].iloc[-1] new_obs_index = results.data.endog.shape[0] # continue integer index new_obs = pd.Series([new_obs_value], index=[new_obs_index]) # Its very important to continue making predictions where we ended on the training data results = results.append(new_obs, refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) print(f"Current Close Price: {new_obs_value} Forecasted next day Close Price: {forecasts[-1]}")
Programación de las predicciones.
schedule.every(1).days.do(predict_close) # call the predict function after a given time while True: schedule.run_pending() time.sleep(60) mt5.shutdown()
Resultados.
Current Close Price: 1.1374900000000001 Forecasted next day Close Price: 1.1337899981049262 Current Close Price: 1.1372200000000001 Forecasted next day Close Price: 1.1447100065656721
Teniendo en cuenta estos precios de cierre previstos, puede ampliar esto a una estrategia de negociación y realizar operaciones comerciales utilizando MetaTrader 5 y Python.
Reflexiones finales
Tanto ARIMA como SARIMA son modelos de series temporales tradicionales decentes que se han utilizado en múltiples campos e industrias; sin embargo, debe comprender sus limitaciones y desventajas, entre las que se incluyen:
- Suponen que la serie es estacionaria (tras la diferenciación)
No siempre trabajamos con datos estacionarios y, a menudo, queremos utilizar los datos tal como están; diferenciar los datos puede distorsionar la estructura natural y las tendencias que anticipamos. - Supuesto de linealidad
ARIMA es intrínsecamente un modelo lineal; asume que los valores futuros dependen linealmente de los desfases y errores del pasado. Esto es erróneo en los patrones de los mercados financieros y de divisas, ya que los patrones complejos se observan con bastante frecuencia, lo que significa que estos modelos podrían fallar en algún punto. - Modelos univariados
Ambos modelos analizan una variable a la vez. Sabemos que los mercados financieros son complejos y que necesitamos múltiples variables y perspectivas para analizarlos. Estos modelos solo analizan el mercado desde un punto de vista (unidimensional), lo que nos impide tener en cuenta otras variables que podrían resultar útiles.
Si bien es posible agregar variables exógenas al modelo SARIMAX, a menudo resulta insuficiente.
A pesar de sus limitaciones, cuando se utilizan con los parámetros, el tipo de problema y la información adecuados. Un modelo ARIMA simple puede superar a modelos complejos como las redes neuronales recurrentes (RNN) en la pronóstico de series temporales.
Saludos cordiales.
Fuentes y referencias
- https://www.geeksforgeeks.org/python-arima-model-for-time-series-forecasting/
- https://www.machinelearningplus.com/time-series/arima-model-time-series-forecasting-python/
- https://datascientest.com/en/sarimax-model-what-is-it-how-can-it-be-applied-to-time-series
- https://www.kaggle.com/code/prashant111/arima-model-for-time-series-forecasting
Tabla de archivos adjuntos
| Nombre del archivo | Descripción y uso |
|---|---|
| forex_ts_forecasting_using_arima.py | Script de Python que contiene todos los ejemplos comentados en lenguaje Python. |
| requirements.txt | Un archivo de texto que contiene las dependencias de Python y su número de versión. |
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/18247
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
Contenido asombroso.
Exactamente lo que estaba buscando.
Probablemente no voy a utilizarlo en el comercio, pero muy interesante.
La primera vez que oí hablar de ARIMA fue en el libro de Perry J Kaufman Trading Systems & Methods.
¿Alguien ha tenido éxito en el comercio con ARIMA?