Teoría de categorías en MQL5 (Parte 22): Una mirada distinta a las medias móviles
Introducción
El tema central de esta serie de artículos siempre ha sido la teoría de categorías. Hemos hablado mucho sobre la previsión de series temporales porque resulta relevante para la mayoría de los tráders y estos constituyen la mayoría de los participantes en esta plataforma. No obstante, otras aplicaciones relevantes adicionales incluyen la valoración, el riesgo, la distribución del portafolio y muchas otras. Echando un vistazo rápido al ejemplo de valoración, podemos ver muchas formas en que se puede usar la teoría de categorías para valorar las acciones. Por ejemplo, si tomamos los indicadores clave de una acción para que cada uno de ellos sea un objeto en la categoría, entonces los morfismos (o los los grafos camino) que vinculan estas diferentes métricas (por ejemplo, ingresos, deuda, etc.) se pueden asignar a diferentes clases de estimación (por ejemplo, A+, A, B, etc.). Al mismo tiempo, tras obtener los indicadores de una determinada acción, podemos determinar su pertenencia a una clase concreta. Este es un enfoque simplificado y pretende servir solo como guía sobre lo que podemos hacer en esta área.
Pero regresemos a las series temporales. Mucha gente piensa que las medias móviles suponen una representación demasiado simplificada. Sin embargo, resultan muy importantes para el análisis técnico, principalmente porque su concepto subyace en muchos otros indicadores, como las Bandas de Bollinger, MACD, etc. Estos pueden percibirse como una visión menos volátil de la acción del precio, lo cual es importante dada la cantidad de ruido blanco en los mercados.
En este artículo continuaremos el análisis de las transformaciones naturales. En el artículo anterior, exploramos la capacidad de las transformaciones naturales para cerrar la brecha entre conjuntos de datos relacionados de diferentes dimensiones. El concepto de "dimensiones" se usa aquí para representar el número de columnas de un conjunto de datos. Así, al igual que antes, nos enfrentaremos a dos categorías: una con una serie "simple" de precios brutos y la otra con una serie "compleja" de precios medios móviles. Nuestro objetivo será mostrar el uso de la teoría de categorías para el pronóstico de series temporales con un alcance de solo tres funtores.
información general
En primer lugar, veremos algunas definiciones básicas de lo que estudiaremos aquí. Un funtor es una función que muestra dos categorías. Aquí nos ocuparemos de tres. A continuación presentaremos las categorías de forma esquemática:
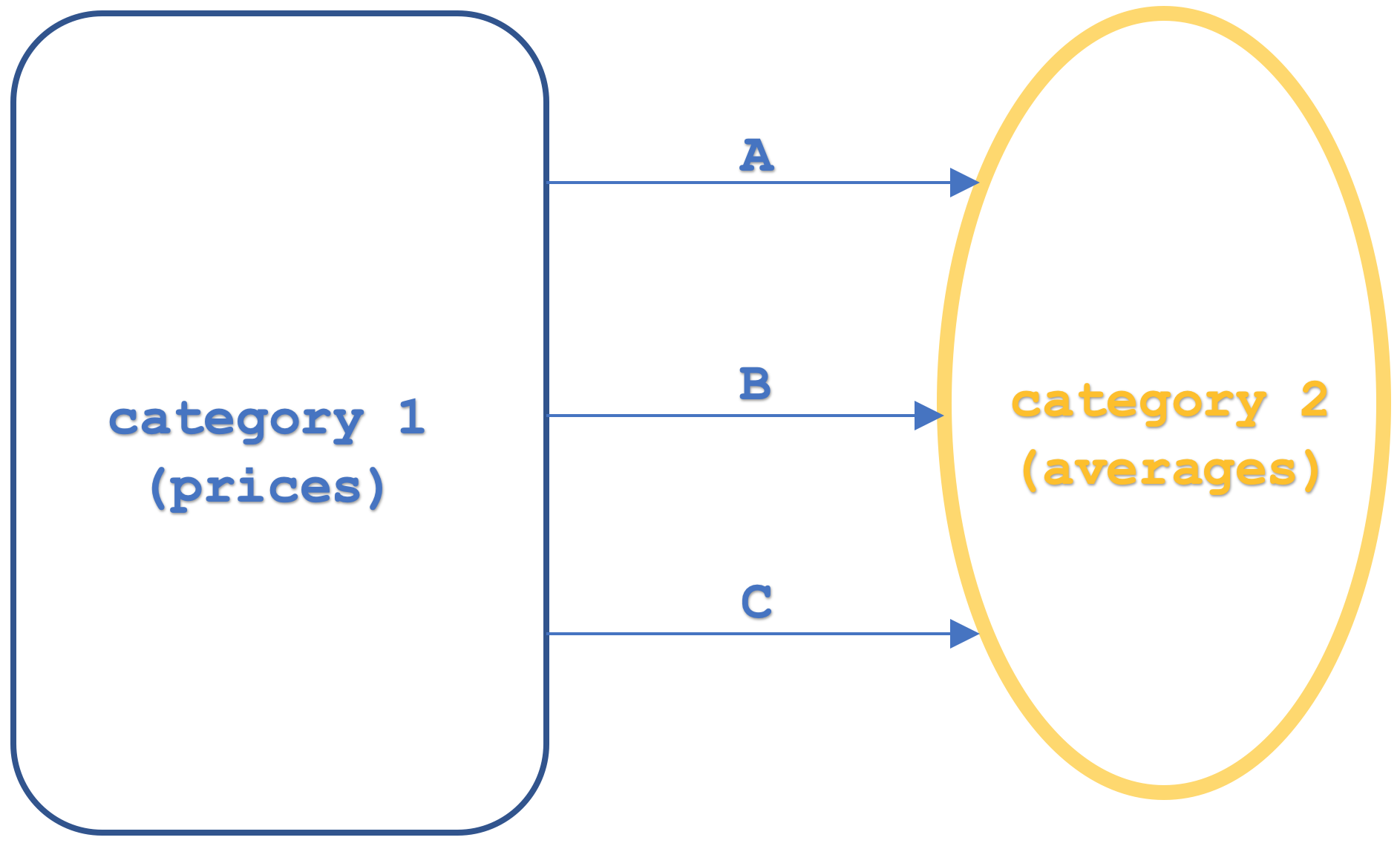
En nuestra categoría de dominio existen objetos con valores de precio en intervalos temporales específicos, así como objetos de codominio con valores de precio media móvil también en intervalos temporales similares. Hemos identificado tres funtores, a saber, A, B y C. En artículos recientes, hemos introducido funtores que relacionan categorías. Lo nuevo aquí será la adición de un tercer funtor. Esto servirá a nuestros propósitos porque muestra las transformaciones naturales en una disposición "vertical". La configuración "vertical" se indica en el esquema, pero para evitar cualquier ambigüedad futura, "vertical" se referirá a transformaciones naturales entre funtores que tienen el mismo dominio y categoría de codominio. Esto significará que si las categorías estuvieran esquemáticamente dispuestas verticalmente y nuestras transformaciones naturales parecieran apuntar en una dirección horizontal, las transformaciones naturales todavía estarían en una disposición "vertical".
Las medias móviles se utilizan comúnmente como indicadores comerciales, monitoreando sus puntos de cruce. Estos pueden ser los puntos donde cruzan el precio básico, así que el cruce del pico será bajista porque representará una barrera de resistencia, mientras que el cruce del valle será alcista porque indicará apoyo. No obstante, la mayoría de las veces estos puntos de intersección se encontrarán entre dos medias móviles de diferentes periodos. Por lo tanto, normalmente, cuando una media de periodo más corto cruza una media de periodo más largo, tendremos una configuración alcista ya que la media móvil más larga y, por lo tanto, menos volátil indicará apoyo y, a la inversa, si la media de periodo más corto rompe más abajo, tanto más tiempo será bajista. Para ello, en este modelo, cada funtor representará un periodo de promediación específico. Por lo tanto, el funtor A será el más corto de los tres, mientras que el funtor B tendrá un periodo intermedio y el funtor C tendrá el periodo de promediación más largo.
Si observamos las categorías analizadas, podría resultar útil esbozar por qué estas dos series temporales se corresponden con los axiomas de las categorías. Le recordamos que ya hemos visto cómo los órdenes (a los que las series temporales están más cercanas) se pueden interpretar como categorías, aunque no menos axiomas de la categoría son los objetos, los morfismos, los morfismos de identidad y las asociaciones. Las categorías de dominio y codominio representan series temporales de los precios, por lo que las ilustraciones de una son fáciles de inferir de la otra. Por lo tanto, si nos centramos en la categoría (área) de precios brutos, cada punto de precio será un objeto que constará de dos elementos: el tiempo y el precio. Los morfismos serán asignaciones secuenciales entre los puntos de precio, ya que cada punto de precio seguirá a otro. El morfismo de identidad en cada punto de precio puede considerarse como una media móvil durante un periodo igual a uno. Esto es lo mismo que una serie de precios, pero la media durante un periodo proporciona la relación de identidad. Finalmente, la composición con asociación se deducirá fácilmente ya que se darán tres puntos de precio sucesivos L, M y N.
L o (M o N) = (L o M) o N
El precio después de un morfismo de M a N, cuando está asociado a un morfismo de L, será el mismo que el precio en N cuando está asociado al resultado de un morfismo de L a M.
Categorías y funtores
Nuestra categoría 1, que será la categoría de dominio para todos los funtores, como ya hemos mencionado, contendrá la serie temporal de precios brutos a partir de la cual los funtores mostrarán sus medias.
Por lo tanto, habrá solo 4 funtores en esta categoría, de los cuales solo 3 serán de nuestro interés. Lo primero que merece la pena mencionar es el funtor de identidad. Esto se debe a que las categorías y funtores se comportan de forma muy similar a los objetos y morfismos, por lo que la identidad será necesaria. Los tres funtores restantes, que, como hemos mencionado, representan diferentes implementaciones de la media móvil, tendrán cada uno un periodo especificado por parámetros de entrada de números enteros, a saber, m_funtor_a, m_funtor_b y m_funtor_c para los funtores A, B y C respectivamente.
La segunda categoría, que constituye el codominio de nuestros tres funtores, tendrá tres objetos, cada uno con precios medios móviles en la serie temporal. Por consiguiente, cada funtor de la serie de precios brutos en la categoría 1 se asignará a su propio objeto en la categoría 2.
La categoría 2 tendrá un único funtor inicial que, como ya hemos dicho, será idéntico. Los morfismos entre estos objetos serán equivalentes a transformaciones naturales según las definiciones que hemos comentado en nuestros últimos artículos. Todo esto se puede resumir usando un esquema un poco más detallado, que vemos a continuación:
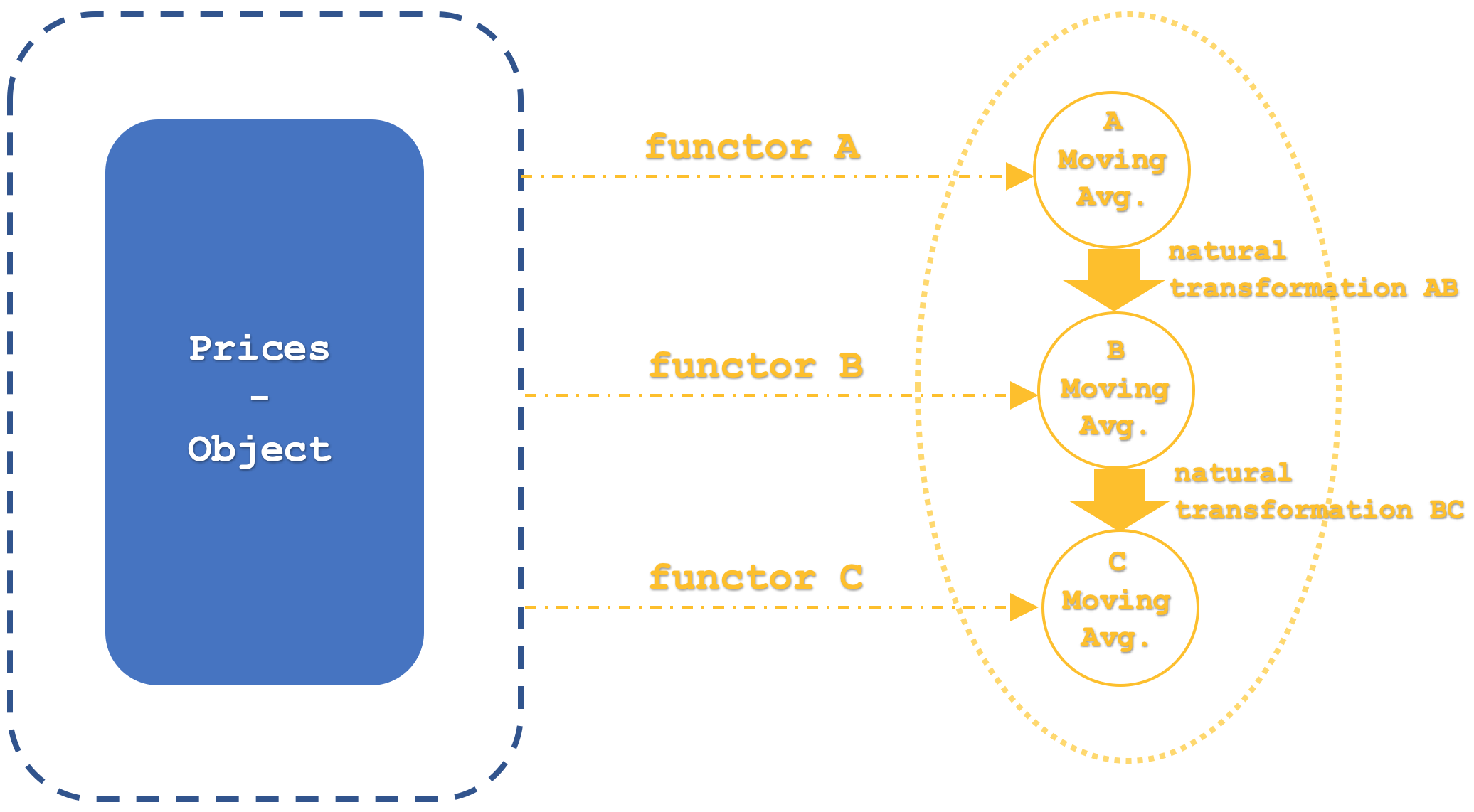
Nuestra representación de funtores para este artículo no utilizará algoritmos de terceros, como el perceptrón multicapa, el bosque aleatorio o el análisis discriminante lineal, como hemos usado en artículos recientes. Más bien será un algoritmo de media móvil, y las transformaciones naturales serán aún más sencillas ya que supondrán la diferencia aritmética entre los valores finales de los dos funtores en cuestión.
Transformaciones naturales
Identificar transformaciones naturales en el contexto de las finanzas es como explorar un nuevo territorio. Existen pocos materiales y enlaces sobre el tema. A menudo se utilizan o consideran otros métodos, como la correlación, que tiene dos implementaciones principales: Pearson y Spearman Existen otros métodos que se pueden usar para la comparación, pero en este artículo usaremos la correlación de Spearman como parte de nuestro algoritmo de generación de señales.
Entonces, la conversión natural entre dos funtores supondrá la diferencia neta en los objetos objetivo de los funtores. En nuestro caso tendremos 3 funtores, lo cual implicará 3 posibles transformaciones naturales. Sin embargo, nos centraremos solo en dos transformaciones, a saber, la transformación entre el funtor A y el funtor B, que podemos llamar AB, y entre el funtor B y el funtor C, que llamaremos BC. Utilizando estos dos funtores, queremos crear dos búferes de datos para cada uno. Por ello, realizaremos un seguimiento de las diferencias correspondientes en las medias móviles y las registraremos en los arrays correspondientes, creando así dos búferes de datos. Monitorearemos el coeficiente de correlación del búfer. El seguimiento de este valor supondrá la esencia de nuestra señal comercial. Un valor positivo debería indicar que los mercados están en tendencia, mientras que un valor negativo indicará que los mercados están planos.
Por lo tanto, nuestra señal se corresponderá con la suma de todos los cambios adicionales en las medias móviles con la señal especificada. Así, si el valor es positivo, indicará un sentimiento alcista, y viceversa, si es negativo, entonces indicará un sentimiento bajista. Esta señal, que siempre producirá un valor en cada barra, se filtrará, como hemos mencionado antes, utilizando la correlación entre dos búferes de transformación naturales. En otras palabras, nuestro sistema preguntará si existe algún beneficio adicional al seguir las evoluciones naturales, dado que ya hemos establecido tendencias para cada media móvil.
Composición vertical de las transformaciones naturales
En el marco de la teoría de categorías, los conceptos de “composición vertical” y su opuesto “composición horizontal” de transformaciones naturales a veces pueden cambiar de significado según el contexto y las convenciones del autor. En algunas fuentes, las transformaciones naturales de funtores con las categorías generales de dominio y codominio se denominan "composiciones horizontales", pero no utilizaremos tal definición. En este artículo y posiblemente en artículos posteriores, denominaremos composición vertical a las transformaciones naturales de funtores con las categorías generales de dominio y codominio.
Entonces, ¿en qué reside la importancia de la composición vertical? La composición vertical es más simple que la horizontal y también ofrece la capacidad de observar dos conjuntos de datos relativamente simples (que pueden considerarse categorías) y establecer entre ellos relaciones especiales que pueden pasarse por alto fácilmente al trabajar con múltiples categorías en entornos más complejos.
Un buen ejemplo será la elección del conjunto de datos de series de precios y del conjunto de datos de media móvil para este artículo. Aparte del trading, un ejemplo más revelador sería la cocina. Vamos a considerar una lista de ingredientes culinarios (categoría de dominio) y varios menús (categoría de codominio). Nuestros funtores simplemente conectarían los ingredientes a los menús correspondientes. Las transformaciones naturales como los funtores y los morfismos conservan las definiciones y la estructura de su origen. Podría parecer algo común, pero supone la piedra angular de la teoría de categorías. Por consiguiente, dados los elementos y la estructura de un objeto (es decir, los menús y sus elementos), las transformaciones naturales entre diferentes menús pueden ayudar a medir y estimar el tiempo relativo requerido para preparar cada plato, o el coste del mismo, y una amplia variedad de otros parámetros, dependiendo de lo que le interese al chef/restaurante. Armados con esta información, podemos utilizar un isomorfismo e investigar la obtención de gradientes considerando un conjunto de menús distintos. Aunque esto se puede hacer usando otros métodos y sistemas, la teoría de categorías ofrece un enfoque cuantificable y que preserva la estructura.
Pronóstico del cambio de precio
Al usar una estructura vertical, el pronóstico de cambio de precio se logra registrando y analizando los coeficientes de correlación de nuestros dos búferes de transformación natural. Estos arrays deben inicializarse porque al iniciar el asesor por primera vez, no se cargan suficientes datos para realizar la correlación. El procesamiento de este comportamiento se muestra a continuación:
//+------------------------------------------------------------------+ //| Get Direction function from Natural Transformations. | //+------------------------------------------------------------------+ void CSignalCT::Init(void) { if(!m_init) { m_close.Refresh(-1); int _x=StartIndex(); m_o_prices.Cardinality(m_functor_c+m_functor_c); for(int i=0;i<m_functor_c+m_functor_c;i++) { m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,m_close.GetData(_x+i));m_o_prices.Set(i,m_e_price); } m_o_average_a.Cardinality(m_transformations+1); m_o_average_b.Cardinality(m_transformations+1); m_o_average_c.Cardinality(m_transformations+1); for(int i=0;i<m_transformations+1;i++) { double _a=0.0; for(int ii=i;ii<m_functor_a+i;ii++) { _a+=m_close.GetData(_x+ii); } _a/=m_functor_a; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_a);m_o_average_a.Set(i,m_e_price); // double _b=0.0; for(int ii=i;ii<m_functor_b+i;ii++) { _b+=m_close.GetData(_x+ii); } _b/=m_functor_b; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_b);m_o_average_b.Set(i,m_e_price); // double _c=0.0; for(int ii=i;ii<m_functor_c+i;ii++) { _c+=m_close.GetData(_x+ii); } _c/=m_functor_c; m_e_price.Let();m_e_price.Cardinality(1);m_e_price.Set(0,_c);m_o_average_c.Set(i,m_e_price); } // ArrayResize(m_natural_transformations_ab,m_transformations);ArrayInitialize(m_natural_transformations_ab,0.0); ArrayResize(m_natural_transformations_bc,m_transformations);ArrayInitialize(m_natural_transformations_bc,0.0); for(int i=m_transformations-1;i>=0;i--) { double _a=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_a.Get(i,m_e_price);m_e_price.Get(0,_a); double _b=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_b.Get(i,m_e_price);m_e_price.Get(0,_b); double _c=0.0; m_e_price.Let();m_e_price.Cardinality(1);m_o_average_c.Get(i,m_e_price);m_e_price.Get(0,_c); m_natural_transformations_ab[i]=_a-_b; m_natural_transformations_bc[i]=_b-_c; } m_init=true; } }
Hemos declarado tres marcadores de media móvil para cada funtor y ahora deberemos actualizarlos antes de leer cualquier valor de ellos. El periodo de cada media móvil será un parámetro de entrada, por lo que tendremos m_funtor_a, m_funtor_b y m_funtor_c para los identificadores m_ma_a, m_ma_b y m_ma_c respectivamente. También tendremos dos búferes para cada transformación natural, a saber, m_natural_transformations_ab y m_natural_transformations_bc. El tamaño de estos arrays vendrá dado por el parámetro de entrada m_transformations, por lo que primero deberemos cambiar el tamaño de ambos arrays a su valor. Los objetos en la categoría de codominio, a saber, m_o_average_a, m_o_average_b y m_o_average_c, también deberán cambiarse a este valor más uno para poder obtener todos los incrementos de cambio.
Por consiguiente, el impacto de diferentes periodos de media móvil en la capacidad de pronóstico de este sistema se evaluará con la aparición de las señales generadas al comparar los cambios en la media móvil cuando la correlación de los búferes de transformación natural sea mayor que cero. El comportamiento se implementará en la función GetDirection:
//+------------------------------------------------------------------+ //| Get Direction function from Natural Transformations. | //+------------------------------------------------------------------+ double CSignalCT::GetDirection() { double _r=0.0; Refresh(); MathCorrelationSpearman(m_natural_transformations_ab,m_natural_transformations_bc,_r); return(_r); }
Cada una de las funciones CheckOpenLong y CheckOpenShort que calcularán nuestra "tendencia". Esta tendencia marcará la dirección de la señal, y la "dirección" actuará como un filtro para los mercados planos. La implementación se muestra a continuación:
m_ma_a.Refresh(-1); m_ma_b.Refresh(-1); m_ma_c.Refresh(-1); int _x=StartIndex(); double _trend= (m_ma_a.GetData(0,_x)-m_ma_a.GetData(0,_x+1))+ (m_ma_b.GetData(0,_x)-m_ma_b.GetData(0,_x+1))+ (m_ma_c.GetData(0,_x)-m_ma_c.GetData(0,_x+1));
También necesitaremos una función para actualizar estos valores, muy parecida a la función Init. El código fuente completo se adjunta al final del artículo.
Durante la prueba del par de divisas USDJPY desde el 01.01.1999 hasta el 01.01.2020 en el marco temporal diario, hemos elaborado el siguiente informe con algunas de nuestras configuraciones ideales:

Si intentamos continuar las pruebas con estas configuraciones desde 2020.01.01 hasta 2023.08.01, obtendremos el siguiente informe:

Como siempre, los resultados positivos no implican que tengamos un sistema que funcione, sino que es posible que tengamos algo que pueda probarse durante periodos más prolongados para confirmar nuestros primeros hallazgos.
Pruebas al desarrollar un sistema comercial
La clase de señal puede integrarse fácilmente en un sistema comercial nuevo o existente gracias al wizard MQL5. Todo lo que deberemos hacer es crear un nuevo asesor con esta clase de señales como una de las otras señales que el tráder siempre usa o quiere poner a prueba. El parámetro de entrada típico Signal_XXX_Weight (donde XXX será el nombre de la clase de señal), cuyo valor normalmente oscila entre 0,0 y 1,0, se puede optimizar en todas las señales para determinar el peso adecuado para cada una.
La evaluación de dicho sistema comercial deberá basarse en las necesidades del tráder. Suele ser una oscilación entre crecimiento y la preservación del capital. En pocas palabras, podríamos señalar que AHPR (la media aritmética de las operaciones) supone un mejor indicador de crecimiento, mientras que la tasa de recuperación es un indicador de seguridad. Todas estas son estimaciones aproximadas, por lo que los tráders tendrán que trabajar más duro para encontrar algo que les funcione.
Si disponemos de un sistema de medición del rendimiento, el siguiente método, quizás igualmente importante, consistirá en mejorar gradualmente la estrategia sin comprometer sus premisas ni su capacidad para avanzar. No existe un método único que no consista en probar constantemente el rendimiento con pruebas retrospectivas y avanzar con cada iteración o modificación del sistema.
Como siempre, podemos tener un ejemplar de clase final basada en este modelo. Tendremos que hacer algunos cambios, pero la esencia seguirá siendo la misma. En primer lugar, nuestras medias móviles, en lugar de usar el precio de cierre como precio aplicado, utilizarán algo que esté desplazado hacia la volatilidad; podría tratarse de un precio típico o quizás un precio medio. En segundo lugar, la dirección del pronóstico seguirá indicando las correlaciones entre los dos búferes de transformaciones naturales, pero en este caso monitorearemos el cambio actual en el rango de barras para que actúe como nuestra "tendencia". Por consiguiente, una disminución en el rango debería estar respaldada por una correlación positiva (valores superiores a cero). Lo mismo se aplicará al aumento de la volatilidad. Si la correlación es cero o negativa, esto significará que nuestro modelo indica que cualquier cambio actual en la volatilidad puede ignorarse. La implementación se adjunta al final del artículo.
Conclusión
En resumen, la influencia de las transformaciones naturales en la composición vertical suena demasiado académica y arcaica para despertar interés entre la mayoría de la gente. No obstante, observando ilustraciones de indicadores comunes como la media móvil en este artículo, hemos identificado varios patrones en los que hemos podido leer señales de confirmación al pronosticar una serie temporal.
El uso del conocimiento adquirido para desarrollar un sistema comercial fiable supone siempre un punto donde la teoría se encuentra con la práctica y requiere un poco más de trabajo por parte del tráder a la hora de implementarlo. Sin embargo, existe suficiente material de apoyo en Internet para que los tráders interesados pueda continuarlo.
Le recomiendo seguir estudiando estos conceptos más allá del pronóstico de series temporales y en otras áreas del trading y las finanzas, como la estimación o los riesgos.
Enlaces
Los artículos utilizados son principalmente de la Wikipedia.
A continuación adjuntamos los recursos necesarios para implementar los conceptos de la teoría de categorías descritos en este artículo. Estos serán el archivo de clase de teoría de categorías ct_22.mq5 y el archivo final TraillingCT_22_r1.mqh. El archivo de clase deberá colocarse en la carpeta include, mientras que el archivo final deberá colocarse en la carpeta Include\Expert\Trailling. Los lectores que no estén familiarizados con el Wizard MQL5 podrán consultar este artículo, ya que el archivo de señal está diseñado para ser ensamblado en el Wizard.
Traducción del inglés realizada por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/en/articles/13416
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.
- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso