
ARIMA-Prognose-Indikator in MQL5

Meteorologen lesen keine Teeblätter, wenn sie Wettervorhersagen machen. Sie analysieren, was in der Vergangenheit geschehen ist, um zu verstehen, was morgen geschehen wird. Das ARIMA-Modell funktioniert ähnlich, untersucht aber nicht die Wolken und den Luftdruck, sondern die Preise auf den Finanzmärkten.
ARIMA steht für das Modell „Autoregressive Integrated Moving Average“. Es mag kompliziert klingen, ist aber in Wirklichkeit ein logisch strukturiertes Modell. Stellen Sie sich vor, Sie versuchen vorherzusagen, wie viel das Währungspaar EUR/USD morgen kosten wird, und zwar auf der Grundlage der Kursentwicklung der letzten Tage.
Die drei Säulen des ARIMA-Modells
Autoregression (AR) – Erinnerung an die Vergangenheit
Der erste Teil des Modells wird als Autoregression bezeichnet. Dieser Fachausdruck bedeutet etwas ganz Einfaches: Der heutige Kurs hängt vom gestrigen, vom vorgestrigen und so weiter ab. Es ist, als ob sich der Markt an seine Vergangenheit erinnert und die Zukunft auf dieser Grundlage aufbaut.
Wenn EUR/USD drei Tage in Folge gestiegen ist, besteht die Chance, dass er auch morgen steigen wird. Nicht unbedingt, aber der Trend könnte sich fortsetzen. Der autoregressive Teil des Modells erfasst diese Muster, indem er analysiert, wie stark vergangene Werte die aktuellen beeinflussen.
Mathematik in einfachen Worten: Stellen Sie sich vor, Sie haben den EUR/USD-Wechselkurs der letzten fünf Tage: 1.0800, 1.0825, 1.0850, 1.0875, 1.0900. Autoregression sagt: „Sehen Sie, jeden Tag ist der Wechselkurs um etwa 25 Punkte (0,0025) gestiegen, was bedeutet, dass er morgen bei 1,0925 liegen wird.“ Das Modell ermittelt Koeffizienten – Zahlen, die zeigen, wie stark der Preis von gestern den von heute beeinflusst, der von vorgestern den von heute und so weiter.
Die Formel sieht etwa so aus: morgiger_Preis = 0,7 × heutiger_Preis + 0,2 × gestriger_Preis + 0,1 × vorgestriger_Preis. Diese Koeffizienten (0,7, 0,2, 0,1) werden vom Modell selbst ausgewählt, indem es die Geschichte analysiert. Je höher der Koeffizient, desto stärker ist der Einfluss dieses Tages auf die Prognose.
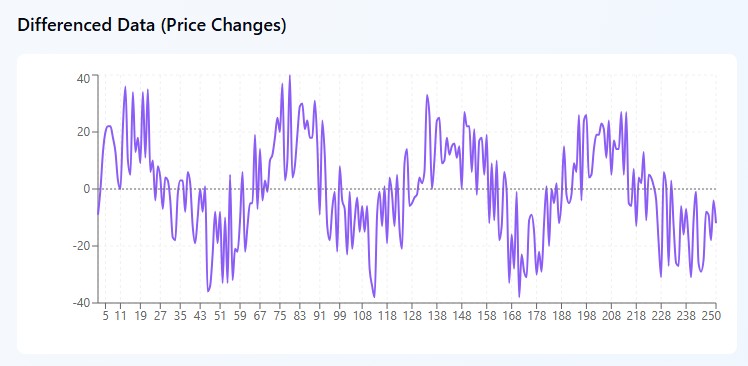
Integration (I) – das Chaos bändigen
Stellen Sie sich vor, Sie schauen auf das EUR/USD-Chart und sehen ein völliges Durcheinander: 1.0800, 1.0850, 1.0820, 1.0880, 1.0860. Der Preis springt hin und her wie ein betrunkener Matrose – auf den ersten Blick unlogisch. Solche Daten werden von Mathematikern als nicht-stationär bezeichnet und bereiten den Händlern Kopfschmerzen.
Aber hier ist der Trick: Anstatt zu versuchen, in den Preisen einen Sinn zu erkennen, macht ARIMA einen klugen Zug. ARIMA betrachtet dabei nicht den absoluten Wert des Währungspaars, sondern dessen tägliche Veränderung. Nehmen Sie die gleichen Zahlen und zählen Sie die Unterschiede: +50 Punkte, -30 Punkte, +60 Punkte, -20 Punkte. Und plötzlich wird aus dem Chaos ein Muster! Der Markt schwankt zwischen einem Anstieg von 50-60 Punkten und einem Rückgang von 20-30 Punkten.
Es ist, als ob man nicht darauf achtet, wo das Pendel steht, sondern nur darauf, in welche Richtung und mit welcher Kraft es schwingt. Mathematisch ist alles ganz einfach: Wir nehmen den heutigen Preis, ziehen den gestrigen Preis ab und erhalten die Veränderung. Manchmal sollte man noch weitergehen und die „Änderung der Änderungen“ – also die Differenzierung zweiter Ordnung – anwenden. Es klingt beängstigend, aber das Prinzip bleibt dasselbe: die Suche nach Mustern, wo es auf den ersten Blick keine gibt.
Gleitender Durchschnitt (MA) – aus Fehlern lernen
Und nun das Interessanteste: Das Modell kann aus seinen eigenen Fehlern lernen. Es klingt wie Science-Fiction, aber die Logik ist einfach. Als ARIMA gestern einen EUR/USD-Kurs von 1,0800 vorhersagte, der tatsächlich bei 1,0825 notierte, war dieser 25-Punkte-Fehler nicht nur eine ärgerliche Ungenauigkeit. Dies ist eine Information!
Stellen Sie sich einen Freund vor, der immer genau 10 Minuten zu spät kommt. Wenn er sagt: „Ich bin um sechs Uhr da“, wissen Sie bereits, dass es in Wirklichkeit 6:10 Uhr sein wird. Das Modell tut dasselbe mit seinen Fehlern. Wenn er an drei aufeinander folgenden Tagen einen Preis vorhersagt, der 10 Punkte unter dem tatsächlichen liegt, merkt er sich diese Fehler und fügt beim nächsten Mal mental hinzu: „Normalerweise unterschätze ich die Werte um 10 Punkte, was bedeutet, dass die Prognose angepasst werden muss.“
Die Formel könnte etwa so aussehen: „Korrektur = 0,5 × Fehler von gestern + 0,3 × Fehler von vorgestern“. Das Modell macht nicht nur Fehler, sondern es macht sie auf kluge Weise, indem es jeden Fehler nutzt.
Wie ARIMA die Marktpsychologie nutzt
Trägheit der Bewegung
Märkte haben eine gewisse Trägheit. Wenn der EUR/USD mehrere Tage hintereinander steigt, wollen alle ihn kaufen, was den Kurs noch weiter nach oben treibt. ARIMA fängt genau diese Trägheit ein.
In der Praxis: Der Kurs steigt fünf Tage lang von 1,0800 auf 1,0900 (+20 Punkte täglich). Das Modell legt viel Gewicht auf die letzten Tage und sagt eine Fortsetzung des Trends voraus.
Rückkehr zum Mittelwert
Gleichzeitig streben die Märkte nach einem „fairen“ Niveau. Wenn der Kurs stark in eine Richtung abgewichen ist, versucht er früher oder später, wieder zurückzukommen.
Ein Beispiel: EUR/USD wird normalerweise in einer Spanne von 1,0800-1,0900 gehandelt. Wenn er aufgrund der Nachrichten auf 1,1000 gesprungen ist, berücksichtigt das Modell durch die Komponente des gleitenden Durchschnitts, dass solche extremen Bewegungen normalerweise angepasst werden.
Zyklische Muster
Viele Währungspaare weisen ein zyklisches Verhalten auf – wöchentliche, monatliche oder saisonale Muster. ARIMA kann sie aufgreifen, wenn es richtig eingestellt ist.
Nachteile des Modells: wenn ARIMA nicht funktioniert
ARIMA ist nicht der magische Gral. Sie beruht auf der Annahme, dass die Zukunft der Vergangenheit ähnelt. Wenn diese Annahme nicht eingehalten wird, macht das Modell ungenaue Vorhersagen.
Das Modell leistet keine gute Arbeit, wenn:
- unerwartete Wirtschaftsnachrichten veröffentlicht werden,
- die Geldpolitik der Zentralbanken sich ändert,
- geopolitische Krisen stattfinden und
- der Markt in einen neuen Modus übergeht (z. B. von einem Trend zu einer Seitwärtsbewegung).
ARIMA schneidet am besten ab bei:
- stabile Marktbedingungen,
- Zeiträumen ohne starke grundlegende Veränderungen,
- bei Instrumenten mit ausgeprägten technischen Mustern.
Praktische Umsetzung in MQL5
Bei der Implementierung eines funktionierenden ARIMA-Indikators geht es um mehr als nur um Formeln. Wir benötigen eine ausgeklügelte Architektur, die die Datenverarbeitung in Echtzeit ermöglicht.
Ein Modul, das die Koeffizienten des Modells auswertet, ist das Herzstück des Indikators. Es verwendet die Maximum-Likelihood-Methode. Das hört sich kompliziert an, ist aber nur eine Methode, um die Parameter zu finden, bei denen das Modell die beobachteten Daten am besten erklärt.
Die Datenstruktur des Indikators umfasst mehrere miteinander verbundene Puffer: den Hauptpuffer für Prognosewerte „ForecastBuffer“, den Hilfspuffer für historische Preise „PriceBuffer“ und den Fehlerpuffer „ErrorBuffer“ zur Speicherung der Modellresiduen. Diese Anordnung gewährleistet eine optimale Speichernutzung und eine hohe Rechengeschwindigkeit.
Die Initialisierung des Systems umfasst die Erstellung von dynamischen Arrays zur Speicherung der anfänglichen Preisdaten, einer differenzierten Reihe, der Koeffizienten der Autoregression und eines gleitenden Durchschnitts sowie eines Arrays für die Residuen. Die Anfangswerte der Koeffizienten werden auf 0,1 gesetzt, was die Stabilität des Optimierungsalgorithmus in der Anfangsphase gewährleistet.
int OnInit() { // Setting indicator buffers for visualizing results SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); SetIndexBuffer(1, PriceBuffer, INDICATOR_CALCULATIONS); SetIndexBuffer(2, ErrorBuffer, INDICATOR_CALCULATIONS); // Setting time series mode for correct operation with historical data ArraySetAsSeries(ForecastBuffer, true); ArraySetAsSeries(PriceBuffer, true); ArraySetAsSeries(ErrorBuffer, true); // Configuring forecast display with corresponding time shift PlotIndexSetString(0, PLOT_LABEL, "ARIMA Forecast"); PlotIndexSetInteger(0, PLOT_SHIFT, forecast_bars); // Initializing working arrays with predefined sizes ArrayResize(prices, lookback); ArrayResize(differenced, lookback); ArrayResize(ar_coeffs, p); ArrayResize(ma_coeffs, q); ArrayResize(errors, lookback); // Setting initial values of model coefficients for(int i = 0; i < p; i++) ar_coeffs[i] = 0.1; for(int i = 0; i < q; i++) ma_coeffs[i] = 0.1; return(INIT_SUCCEEDED); }
Eingangsparameter des Modells
Der Indikator wird durch ein System von Eingabeparametern konfiguriert, von denen jeder eine entscheidende Rolle bei der Bestimmung des Verhaltens des Modells spielt. Der Parameter lookback bestimmt die Menge der historischen Daten, die zum Trainieren des Modells verwendet werden, der Parameter forecast_bars gibt den Prognosehorizont an, und das Dreiergespann der Parameter p, d, q bestimmt die Spezifikation des ARIMA-Modells.
//--- Input parameters of model configuration input int lookback = 200; // Lookback period for ARIMA input int forecast_bars = 20; // Number of forecast time intervals input int p = 3; // Order of autoregressive component input int d = 1; // Degree of differentiation of a time series input int q = 2; // Order of moving average component input double learning_rate = 0.01; // Learning rate coefficient input int max_iterations = 100; // Maximum number of optimization iterations
Methodik zur Schätzung der Modellparameter
Das zentrale Element des Algorithmus ist die Funktion zur Berechnung der logarithmischen Likelihood-Funktion, die als Kriterium für die Qualität der Anpassung des Modells an die beobachteten Daten dient. Die Implementierung dieser Funktion basiert auf der Annahme einer Normalverteilung der Modellresiduen, was die Verwendung eines analytischen Ausdrucks für die Wahrscheinlichkeitsdichte ermöglicht.
Likelihood-Funktion und Berechnung der Residuen
Der Algorithmus zur Berechnung der Log-Likelihood-Funktion ist ein iterativer Prozess, bei dem für jeden Zeitpunkt die Residuen des Modells als Differenz zwischen dem beobachteten Wert und der Modellprognose berechnet werden. Die autoregressive Komponente wird als lineare Kombination der früheren Werte der differenzierten Reihen gebildet, während die Komponente des gleitenden Durchschnitts frühere Werte der Modellfehler verwendet.
double ComputeLogLikelihood(double &data[], double &ar[], double &ma[]) { double ll = 0.0; double residuals[]; ArrayResize(residuals, lookback); ArrayInitialize(residuals, 0.0); // Iterative calculation of model residuals for(int i = p; i < lookback; i++) { double ar_part = 0.0; double ma_part = 0.0; // Forming autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar[j] * data[i - j - 1]; // Forming moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma[j] * errors[i - j - 1]; // Calculating residuals and updating the error array residuals[i] = data[i] - (ar_part + ma_part); errors[i] = residuals[i]; // Accumulating log-likelihood function ll -= 0.5 * MathLog(2 * M_PI) + 0.5 * residuals[i] * residuals[i]; } return ll; }
Verfahren zur Optimierung der Koeffizienten
Das Verfahren zur Optimierung der Koeffizienten wird mit der Methode des Gradientenabstiegs mit einer adaptiven Schrittweite durchgeführt. Der Algorithmus aktualisiert die Koeffizientenwerte iterativ in der Richtung, die dem Gradienten der Zielfunktion entgegengesetzt ist, um die Konvergenz zum lokalen Optimum der Wahrscheinlichkeitsfunktion sicherzustellen.
void OptimizeCoefficients(double &data[]) { double temp_ar[], temp_ma[]; ArrayCopy(temp_ar, ar_coeffs); ArrayCopy(temp_ma, ma_coeffs); double best_ll = -DBL_MAX; double grad_ar[], grad_ma[]; ArrayResize(grad_ar, p); ArrayResize(grad_ma, q); // Iterative optimization process for(int iter = 0; iter < max_iterations; iter++) { ArrayInitialize(grad_ar, 0.0); ArrayInitialize(grad_ma, 0.0); // Calculating gradients of likelihood function for(int i = p; i < lookback; i++) { double ar_part = 0.0, ma_part = 0.0; // Forming model components for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += temp_ar[j] * data[i - j - 1]; for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += temp_ma[j] * errors[i - j - 1]; double residual = data[i] - (ar_part + ma_part); // Accumulating gradients by AR coefficients for(int j = 0; j < p && i - j - 1 >= 0; j++) grad_ar[j] += -residual * data[i - j - 1]; // Accumulating gradients by MA coefficients for(int j = 0; j < q && i - j - 1 >= 0; j++) grad_ma[j] += -residual * errors[i - j - 1]; } // Updating coefficients according to the gradient descent rule for(int j = 0; j < p; j++) temp_ar[j] += learning_rate * grad_ar[j] / lookback; for(int j = 0; j < q; j++) temp_ma[j] += learning_rate * grad_ma[j] / lookback; // Evaluating quality of current approximation double current_ll = ComputeLogLikelihood(data, temp_ar, temp_ma); // Stopping criterion and updating the optimal solution if(current_ll > best_ll) { best_ll = current_ll; ArrayCopy(ar_coeffs, temp_ar); ArrayCopy(ma_coeffs, temp_ma); } else { break; // Premature stop in the absence of improvement } } }
Besonderes Augenmerk wird auf die Berechnung der partiellen Ableitungen der Likelihood-Funktion für jeden der optimierten Parameter gelegt. Die Gradienten für die Autoregressionskoeffizienten werden als Summe der Produkte der Residuen mit den entsprechenden Verzögerungswerten der differenzierten Reihen berechnet. Die Gradienten für die Koeffizienten des gleitenden Durchschnitts werden durch die Produkte der Residuen mit den vorherigen Fehlerwerten bestimmt.
Algorithmus zur Vorhersage und Umkehrung der Differenzierung
Die Prognosewerte werden rekursiv erzeugt, ausgehend vom letzten beobachteten Wert der Zeitreihe. Bei jedem Prognoseschritt wird die autoregressive Komponente als Linearkombination der früheren Werte der differenzierten Reihe mit den entsprechenden Koeffizienten berechnet. Die Komponente des gleitenden Durchschnitts wird auf ähnliche Weise gebildet, nämlich durch eine gewichtete Summe der früheren Residuen des Modells.
Das grundlegende Berechnungsverfahren
Die Funktion OnCalculate dient als Rechenkern, der alle Komponenten des Algorithmus in eine einheitliche Datenverarbeitungspipeline integriert. Die Funktion übernimmt die sequenzielle Verarbeitung der eingehenden Marktdaten, die Anwendung des Differenzierungsverfahrens, die Optimierung der Modellparameter und die Generierung von Prognosewerten.
int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { ArraySetAsSeries(close, true); ArraySetAsSeries(time, true); // Checking sufficiency of historical data if(rates_total < lookback + forecast_bars) return(0); // Forming array of closing prices for(int i = 0; i < lookback; i++) { prices[i] = close[i]; PriceBuffer[i] = close[i]; } // Applying differentiation procedure for(int i = 0; i < lookback - d; i++) { if(d == 1) differenced[i] = prices[i] - prices[i + 1]; else if(d == 2) differenced[i] = (prices[i] - prices[i + 1]) - (prices[i + 1] - prices[i + 2]); else differenced[i] = prices[i]; } // Optimizing AR and MA coefficients ArrayInitialize(errors, 0.0); OptimizeCoefficients(differenced); // Generating ARIMA forecast double forecast[]; ArrayResize(forecast, forecast_bars); double undiff[]; ArrayResize(undiff, forecast_bars); // Initializing forecasting process forecast[0] = prices[0]; undiff[0] = prices[0]; // Iterative forecast generation for(int i = 1; i < forecast_bars; i++) { double ar_part = 0.0; double ma_part = 0.0; // Calculating autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar_coeffs[j] * (j < lookback ? differenced[j] : forecast[i - j - 1]); // Calculating moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma_coeffs[j] * errors[j]; // Forming forecast value forecast[i] = ar_part + ma_part; // Procedure of reversal of differentiation if(d == 1) undiff[i] = undiff[i - 1] + forecast[i]; else if(d == 2) undiff[i] = undiff[i - 1] + (undiff[i - 1] - (i >= 2 ? undiff[i - 2] : prices[1])) + forecast[i]; else undiff[i] = forecast[i]; // Updating error array for following iterations errors[i % lookback] = forecast[i] - (i < lookback ? differenced[i] : 0.0); } // Filling output buffer with forecast values for(int i = 0; i < forecast_bars; i++) { ForecastBuffer[i] = undiff[i]; } // Extending historical data for continuous display for(int i = forecast_bars; i < lookback; i++) { ForecastBuffer[i] = prices[i - forecast_bars]; } return(rates_total); }
Das Verfahren der umgekehrten Differenzierung ist ein wichtiger Meilenstein, der die korrekte Wiederherstellung der ursprünglichen Skala der Prognosewerte gewährleistet. Für den Fall der Differenzierung erster Ordnung wird jeder Prognosewert durch Summierung des vorhergehenden undifferenzierten Wertes mit der entsprechenden Prognose der ersten Differenz ermittelt. Bei der Differenzierung zweiter Ordnung wird eine komplexere rekursive Formel verwendet, die die Krümmung der Zeitreihe berücksichtigt.
Rechnerische Aspekte und Leistungsoptimierung
Die Leistung des Algorithmus wird weitgehend durch die richtige Organisation des Rechenprozesses und die optimale Nutzung der Prozessorressourcen bestimmt. Die Hauptfunktion OnCalculate ist so strukturiert, dass die Anzahl der redundanten Berechnungen beim Eintreffen neuer Marktdaten minimiert wird.
Das Differenzierungsverfahren wird für verschiedene Transformationsordnungen durchgeführt. Für die Differenzierung erster Ordnung wird eine einfache Differenz zwischen benachbarten Beobachtungen berechnet, während für die zweite Ordnung eine Formel für die zweite Differenz verwendet wird. Damit können Sie nicht nur den Trend eliminieren, sondern auch Veränderungen in der Trendrate.
Ein kritischer Aspekt der Implementierung ist die Speicherverwaltung und der korrekte Betrieb mit Arrays variabler Länge. Die Verwendung der Funktionen ArrayResize und ArraySetAsSeries stellt sicher, dass sich die Datenstruktur an die sich ändernden Modellparameter und Datenorganisationsmerkmale in MetaTrader 5 anpasst.
Kalibrierung der Parameter und Anpassung an die Marktbedingungen
Die erfolgreiche Anwendung des ARIMA-Modells unter realen Handelsbedingungen erfordert eine sorgfältige Kalibrierung der Parameter in Abhängigkeit von den Besonderheiten eines bestimmten Finanzinstruments und dem Zeithorizont der Analyse. Der Lookback-Parameter bestimmt die Tiefe der historischen Analyse und sollte so groß sein, dass die statistische Signifikanz der Schätzungen gewährleistet ist, aber nicht so groß, dass veraltete Informationen einbezogen werden.
Die Wahl der Ordnungen p, d und q des Modells ist ein Kompromiss zwischen der Genauigkeit der Datenbeschreibung und der Komplexität der Berechnung. Eine Erhöhung der Ordnung der Autoregression p ermöglicht komplexere Zeitabhängigkeiten. Eine zu starke Verkomplizierung des Modells kann jedoch zu einer Überanpassung führen und die Vorhersagequalität auf der Grundlage neuer Daten verringern.
Der Parameter learning_rate muss besonders sorgfältig eingestellt werden, da ein zu großer Wert zu Schwankungen im Optimierungsalgorithmus führen kann, während ein zu kleiner Wert die Konvergenz zum Optimum verlangsamt.
Statistische Validierung und Bewertung der Prognosequalität
Eine objektive Bewertung der Indikatorqualität erfordert die Anwendung einer Reihe von statistischen Kriterien, die eine Quantifizierung der Prognosegenauigkeit ermöglichen. Zu den aussagekräftigsten Metriken gehören der durchschnittliche absolute Fehler, der mittlere quadratische Fehler und das Bestimmtheitsmaß.
Kennzahlen der Prognosequalität
Die Implementierung von Funktionen zur Bewertung der Prognosequalität ermöglicht eine quantitative Analyse der Modellleistung und einen Vergleich verschiedener ARIMA-Spezifikationen. Der durchschnittliche absolute Fehler ist ein intuitives Maß für die Abweichung der Prognosen von den tatsächlichen Werten, ausgedrückt in Maßeinheiten der ursprünglichen Zeitreihe.
// Function of calculating average absolute error double CalculateMAE(double &actual[], double &predicted[], int size) { double mae = 0.0; for(int i = 0; i < size; i++) { mae += MathAbs(actual[i] - predicted[i]); } return mae / size; } // Function of calculating the root mean square error double CalculateRMSE(double &actual[], double &predicted[], int size) { double mse = 0.0; for(int i = 0; i < size; i++) { double error = actual[i] - predicted[i]; mse += error * error; } return MathSqrt(mse / size); } // Determination coefficient calculation function double CalculateR2(double &actual[], double &predicted[], int size) { double actual_mean = 0.0; for(int i = 0; i < size; i++) actual_mean += actual[i]; actual_mean /= size; double ss_tot = 0.0, ss_res = 0.0; for(int i = 0; i < size; i++) { ss_tot += (actual[i] - actual_mean) * (actual[i] - actual_mean); ss_res += (actual[i] - predicted[i]) * (actual[i] - predicted[i]); } return 1.0 - (ss_res / ss_tot); }
Diagnostik der Modellresiduen
Die Analyse der Modellresiduen ist ein entscheidender Aspekt der Validierung, der es uns ermöglicht, systematische Abweichungen von den Modellannahmen zu ermitteln. Der Ljung-Box-Test für die Autokorrelation der Residuen ermöglicht eine Überprüfung der Angemessenheit der Modellspezifikation, während der Jarque-Bera-Test die Beurteilung der Normalität der Verteilung der Residuen ermöglicht.
// Function for calculating autocorrelation function of the residuals double CalculateAutocorrelation(double &residuals[], int lag, int size) { double mean = 0.0; for(int i = 0; i < size; i++) mean += residuals[i]; mean /= size; double numerator = 0.0, denominator = 0.0; for(int i = lag; i < size; i++) { numerator += (residuals[i] - mean) * (residuals[i - lag] - mean); } for(int i = 0; i < size; i++) { denominator += (residuals[i] - mean) * (residuals[i] - mean); } return numerator / denominator; } // Ljung-Box statistic for testing autocorrelation double LjungBoxTest(double &residuals[], int max_lag, int size) { double lb_stat = 0.0; for(int k = 1; k <= max_lag; k++) { double rho_k = CalculateAutocorrelation(residuals, k, size); lb_stat += (rho_k * rho_k) / (size - k); } return size * (size + 2) * lb_stat; }
Das Verfahren der Kreuzvalidierung ermöglicht es uns, die Robustheit des Modells gegenüber Veränderungen innerhalb der Trainingsstichprobe zu bewerten. Die Methode des rollenden Fensters ermöglicht eine realistischere Bewertung der Prognosequalität unter handelsnahen Bedingungen, wenn ein Modell sukzessive auf neue Daten angewendet wird, ohne die Parameter zu ändern.
Die Analyse der Modellresiduen liefert wichtige Informationen über die Eignung der Modellannahmen für die Merkmale der realen Daten. Tests auf Autokorrelation der Residuen ermöglichen es, nicht berücksichtigte zeitliche Abhängigkeiten zu identifizieren, während Tests auf Normalverteilung der Residuen die Korrektheit des verwendeten statistischen Modells überprüfen.
Das Ergebnis des Indikators ist eine Prognose für den angegebenen Zeitraum:
Aussichten für die Entwicklung und Änderung von Algorithmen
Die moderne Forschung auf dem Gebiet der Finanzzeitreihenanalyse eröffnet weitreichende Möglichkeiten für die Weiterentwicklung des grundlegenden ARIMA-Modells. Die Einbeziehung saisonaler Komponenten in das SARIMA-Modell ermöglicht es uns, zyklische Muster zu berücksichtigen, die für viele Finanzinstrumente charakteristisch sind. Regularisierungsmethoden wie die L1- und L2-Penalisierung können die Robustheit des Modells gegenüber Ausreißern verbessern und eine Überanpassung verhindern.
Adaptive Algorithmusänderungen mit dynamischen Änderungen der Modellparameter in Abhängigkeit von den aktuellen Marktbedingungen sind für den Hochfrequenzhandel von besonderem Interesse. Die Integration von Methoden des maschinellen Lernens kann eine automatische Auswahl der optimalen Modellspezifikation ermöglichen, ohne dass ein Analytiker beteiligt ist.
Mehrdimensionale Erweiterungen des ARIMA-Modells eröffnen die Möglichkeit der gleichzeitigen Modellierung mehrerer miteinander verbundener Finanzinstrumente. Dies ist besonders wichtig für das Portfoliomanagement und Arbitragestrategien.
Abschließende Überlegungen
Die vorgestellte Implementierung des ARIMA-Indikators in der MQL5-Umgebung demonstriert die Möglichkeit einer erfolgreichen Anpassung klassischer ökonometrischer Methoden an die Aufgaben des algorithmischen Handels. Die strikte Einhaltung der statistischen Methodik in Verbindung mit einer effizienten Softwareimplementierung gewährleistet die Schaffung eines zuverlässigen Instruments für die Analyse von Finanzzeitreihen.
Die praktische Anwendung des Indikators erfordert ein tiefes Verständnis sowohl der mathematischen Grundlagen eines Modells als auch der Besonderheiten des Marktes, auf dem es eingesetzt wird. Das Modell schneidet auf Märkten, die durch instabile Trends gekennzeichnet sind, deutlich schlechter ab.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/18253
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Wo befindet sich das Differenzial?
Die Kombination von Renko und Arima sollte stabiler sein.
Ja, ich benutze es auch.