
MQL5におけるARIMA予測指標

気象学者は天気予報をおこなう際に勘に頼るのではなく、過去のデータを分析して将来を予測します。ARIMAモデルもこれと同様で、雲や気圧の代わりに金融市場の価格データを分析します。
ARIMAとは「自己回帰和分移動平均Autoregressive Integrated Moving Average)」モデルの略です。一見複雑に聞こえますが、実際には論理的に構造化されたモデルです。たとえば、過去数日のEUR/USDの値動きをもとに、翌日の価格を予測するようなイメージです。
ARIMAモデルの3つの柱
自己回帰(AR):過去の記憶
モデルの最初の要素は自己回帰です。これは専門的な用語ですが、意味はシンプルで「今日の価格は昨日や一昨日など過去の価格に依存する」という考え方です。つまり、市場は過去を記憶し、それを基に未来を形成していると捉えます。
EUR/USDが3日連続で上昇している場合、翌日も上昇する可能性があります。必ずしもそうなるわけではありませんが、トレンドが継続することはあり得ます。自己回帰の部分は、このような過去の値が現在にどの程度影響を与えるかを分析してパターンを捉えます。
数式を簡単に説明すると、たとえば、過去5日間のEUR/USDレートが1.0800、1.0825、1.0850、1.0875、1.0900であったとします。この場合、毎日約25ポイント(0.0025)ずつ上昇しているため、「明日は約1.0925になる」と予測できます。自己回帰モデルは、過去の値が現在の値にどれくらい影響するかを示す係数(パラメータ)を自動的に算出します。
たとえば、「明日の価格 = 0.7 x 今日の価格 + 0.2 x 昨日の価格 + 0.1 x 一昨日の価格」のような式になります。ここでの0.7、0.2、0.1といった係数は、モデルが過去データを分析して決定します。係数が大きいほど、その日の価格が予測に与える影響が大きいことを意味します。
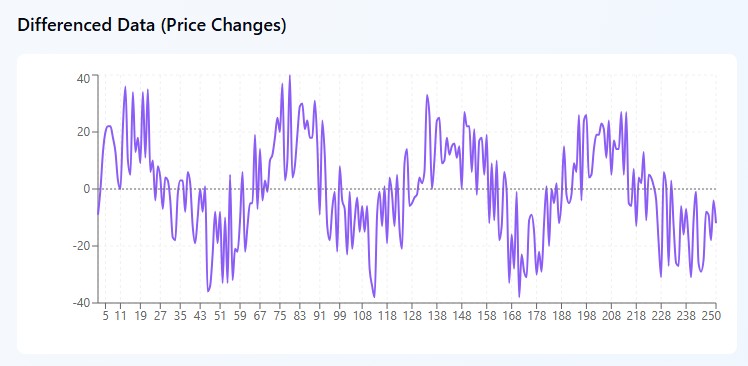
和分(I):カオスを整える
EUR/USDのチャートを見ていると、1.0800、1.0850、1.0820、1.0880、1.0860のように完全にバラバラな動きに見えることがあります。価格が前後に激しく動き、一見すると規則性がないように見えます。このようなデータは数学的には「非定常」と呼ばれ、トレーダーにとっては扱いづらいものです。
しかし、ここに工夫があります。ARIMAは価格そのものを理解しようとするのではなく、賢く発想を切り替えます。通貨ペアの値段そのものではなく、「1日でどれだけ変化したか」に注目します。同じ数値から差分を計算すると、+50ポイント、-30ポイント、+60ポイント、-20ポイントとなります。すると突然、カオスがパターンに変わります。市場は50〜60ポイントの上昇と20〜30ポイントの下落の間で揺れていることが分かります。
まるで振り子が「どこにあるか」ではなく、「どちらの方向に、どの程度の強さで振れているか」だけを見ているようなものです。数学的には単純で、今日の価格から昨日の価格を引いて変化量を求めます。場合によってはさらに進んで、「変化の変化」、つまり二階差分を取ることもあります。少し難しそうに聞こえますが、基本的な考え方は同じで、一見すると存在しないように見えるパターンを見つけるための手法です。
移動平均線(MA):誤差から学ぶ
ここからがARIMAの面白いところで、モデルは自分の誤差から学習します。一見するとSFのようですが、ロジックは非常に実用的です。たとえば、昨日の予測でEUR/USDを1.0800と見積もったものの、実際の価格が1.0825だった場合、この25ポイントの誤差は単なるズレではなく「有用な情報」です。
たとえば、いつも10分遅れてくる友人を想像してください。「6時に行く」と言われたら、実際は6時10分だと予測できます。同様にモデルも、自身の予測誤差の傾向を記憶します。3日連続で実際より10ポイント低く予測していた場合、次の予測では「通常10ポイント過小評価する傾向があるため補正が必要」と判断します。
数式的には「補正値 = 0.5 x 昨日の誤差 + 0.3 x 一昨日の誤差」のように表現できます。このように、モデルは単に誤差を出すのではなく、その誤差を活用してより精度の高い予測へと改善していきます。
ARIMAが市場心理をどのように捉えるか
慣性
市場には慣性があります。EUR/USDが数日連続で上昇すると、多くの参加者が「買いたい」と考えるようになり、その結果さらに価格が押し上げられます。ARIMAはまさにこの慣性を捉えます。
実務的な例として、レートが1.0800から1.0900まで5日間連続で上昇し、毎日+20ポイントずつ伸びているとします。この場合、モデルは直近のデータに大きな重みを置き、トレンドの継続を予測します。
平均回帰
一方で、市場は「適正な水準」に戻ろうとする性質も持っています。価格が一方向に大きく乖離した場合、いずれ元の水準に戻ろうとします。
たとえば、EUR/USDが通常1.0800〜1.0900のレンジで推移しているとします。ニュースによって1.1000まで急騰した場合、モデルは移動平均(MA)コンポーネントを通じて、このような極端な動きは通常調整されることを考慮します。
周期的パターン
多くの通貨ペアは、週次、月次、季節性などの周期的な挙動を示します。ARIMAは、適切に設定されていれば、これらのパターンも捉えることができます。
モデルの欠点:ARIMAが機能しない場合
ARIMAは万能ではありません。このモデルは「未来は過去に似ている」という前提に基づいています。この前提が崩れると、予測精度は低下します。
ARIMAがうまく機能しない状況
- 予期しない経済ニュースが発表された場合
- 中央銀行の金融政策が変更された場合
- 地政学的な危機が発生した場合
- 市場の状態が変化した場合(例:トレンド相場からレンジ相場への移行)
ARIMAが有効に機能する場面
- 市場が安定している状況
- 強いファンダメンタル変化がない期間
- テクニカルなパターンが明確に現れている銘柄
MQL5での実践的な実装
実際に動作するARIMAインジケーターを実装するには、単に数式を組み込むだけでは不十分です。リアルタイムのデータ処理に対応できる、しっかりと設計されたアーキテクチャが必要です。
インジケーターの中核となるのは、モデルの係数を推定するモジュールです。このモジュールでは最尤推定を使用します。一見複雑に聞こえますが、要するに「観測データを最もよく説明できるパラメータを見つける手法」です。
インジケーターのデータ構造は、相互に関連した複数のバッファで構成されます。具体的には、予測値を格納するメインバッファForecastBuffer、過去価格を保持する補助バッファPriceBuffer、そしてモデルの残差を保存するErrorBufferです。この構成により、メモリ使用効率と計算速度の最適化が実現されます。
システムの初期化では、初期価格データを格納する動的配列、差分系列、自己回帰係数および移動平均係数、さらに残差配列を生成します。係数の初期値は0.1に設定されており、これによって最適化アルゴリズムの初期段階での安定性が確保されます。
int OnInit() { // Setting indicator buffers for visualizing results SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); SetIndexBuffer(1, PriceBuffer, INDICATOR_CALCULATIONS); SetIndexBuffer(2, ErrorBuffer, INDICATOR_CALCULATIONS); // Setting time series mode for correct operation with historical data ArraySetAsSeries(ForecastBuffer, true); ArraySetAsSeries(PriceBuffer, true); ArraySetAsSeries(ErrorBuffer, true); // Configuring forecast display with corresponding time shift PlotIndexSetString(0, PLOT_LABEL, "ARIMA Forecast"); PlotIndexSetInteger(0, PLOT_SHIFT, forecast_bars); // Initializing working arrays with predefined sizes ArrayResize(prices, lookback); ArrayResize(differenced, lookback); ArrayResize(ar_coeffs, p); ArrayResize(ma_coeffs, q); ArrayResize(errors, lookback); // Setting initial values of model coefficients for(int i = 0; i < p; i++) ar_coeffs[i] = 0.1; for(int i = 0; i < q; i++) ma_coeffs[i] = 0.1; return(INIT_SUCCEEDED); }
モデルの入力パラメータ
インジケーターは入力パラメータによって構成されており、それぞれがモデルの挙動を決定する上で重要な役割を果たします。lookbackパラメータは、モデルの学習に使用する過去データの量を決定します。forecast_barsパラメータは予測期間(何本先まで予測するか)を指定します。また、パラメータの組(p, d, q)は、ARIMAモデルの次数(モデル構造)を定義します。
//--- Input parameters of model configuration input int lookback = 200; // Lookback period for ARIMA input int forecast_bars = 20; // Number of forecast time intervals input int p = 3; // Order of autoregressive component input int d = 1; // Degree of differentiation of a time series input int q = 2; // Order of moving average component input double learning_rate = 0.01; // Learning rate coefficient input int max_iterations = 100; // Maximum number of optimization iterations
モデルパラメータ推定の方法論
アルゴリズムの中核となるのは、対数尤度関数を計算する関数です。この関数は、モデルが観測データにどれだけ適合しているかを評価する指標として機能します。この実装は、モデルの残差が正規分布に従うという仮定に基づいており、その結果として確率密度関数の明示的な式を利用します。
尤度関数と残差の計算
対数尤度関数の計算アルゴリズムは反復的なプロセスです。各時点において、モデルの残差は「観測値とモデル予測値との差」として計算されます。自己回帰成分は、差分系列の過去の値の線形結合として構成されます。一方、移動平均成分は、過去のモデル誤差(残差)の値を使用して構成されます。
double ComputeLogLikelihood(double &data[], double &ar[], double &ma[]) { double ll = 0.0; double residuals[]; ArrayResize(residuals, lookback); ArrayInitialize(residuals, 0.0); // Iterative calculation of model residuals for(int i = p; i < lookback; i++) { double ar_part = 0.0; double ma_part = 0.0; // Forming autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar[j] * data[i - j - 1]; // Forming moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma[j] * errors[i - j - 1]; // Calculating residuals and updating the error array residuals[i] = data[i] - (ar_part + ma_part); errors[i] = residuals[i]; // Accumulating log-likelihood function ll -= 0.5 * MathLog(2 * M_PI) + 0.5 * residuals[i] * residuals[i]; } return ll; }
係数最適化手順
係数の最適化手順は、適応的なステップサイズを用いた勾配降下法によって実装されています。アルゴリズムは、目的関数の勾配と逆方向に係数を反復的に更新し、対数尤度関数の局所最適解へ収束することを目指します。
void OptimizeCoefficients(double &data[]) { double temp_ar[], temp_ma[]; ArrayCopy(temp_ar, ar_coeffs); ArrayCopy(temp_ma, ma_coeffs); double best_ll = -DBL_MAX; double grad_ar[], grad_ma[]; ArrayResize(grad_ar, p); ArrayResize(grad_ma, q); // Iterative optimization process for(int iter = 0; iter < max_iterations; iter++) { ArrayInitialize(grad_ar, 0.0); ArrayInitialize(grad_ma, 0.0); // Calculating gradients of likelihood function for(int i = p; i < lookback; i++) { double ar_part = 0.0, ma_part = 0.0; // Forming model components for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += temp_ar[j] * data[i - j - 1]; for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += temp_ma[j] * errors[i - j - 1]; double residual = data[i] - (ar_part + ma_part); // Accumulating gradients by AR coefficients for(int j = 0; j < p && i - j - 1 >= 0; j++) grad_ar[j] += -residual * data[i - j - 1]; // Accumulating gradients by MA coefficients for(int j = 0; j < q && i - j - 1 >= 0; j++) grad_ma[j] += -residual * errors[i - j - 1]; } // Updating coefficients according to the gradient descent rule for(int j = 0; j < p; j++) temp_ar[j] += learning_rate * grad_ar[j] / lookback; for(int j = 0; j < q; j++) temp_ma[j] += learning_rate * grad_ma[j] / lookback; // Evaluating quality of current approximation double current_ll = ComputeLogLikelihood(data, temp_ar, temp_ma); // Stopping criterion and updating the optimal solution if(current_ll > best_ll) { best_ll = current_ll; ArrayCopy(ar_coeffs, temp_ar); ArrayCopy(ma_coeffs, temp_ma); } else { break; // Premature stop in the absence of improvement } } }
特に重要なのは、各パラメータに関する対数尤度関数の偏微分(勾配)の計算です。自己回帰係数に対する勾配は、「残差」と「差分系列の対応するラグ値」との積の総和として計算されます。一方、移動平均係数に対する勾配は、「残差」と「過去の誤差値」との積によって求められます。
予測アルゴリズムと差分の逆変換
予測値は、時系列の最後の観測値から開始して、再帰的に生成されます。各予測ステップにおいて、自己回帰成分は、差分系列の過去の値と対応する係数との線形結合として計算されます。移動平均成分も同様に、過去のモデル残差の重み付き和として構成されます。
基本的な計算手順
OnCalculate関数は計算処理の中核として機能し、アルゴリズムのすべての構成要素を単一のデータ処理パイプラインに統合します。この関数は、受信したマーケットデータを順次処理し、差分処理の適用、モデルパラメータの最適化、そして予測値の生成までを一連の流れとして実行します。
int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { ArraySetAsSeries(close, true); ArraySetAsSeries(time, true); // Checking sufficiency of historical data if(rates_total < lookback + forecast_bars) return(0); // Forming array of closing prices for(int i = 0; i < lookback; i++) { prices[i] = close[i]; PriceBuffer[i] = close[i]; } // Applying differentiation procedure for(int i = 0; i < lookback - d; i++) { if(d == 1) differenced[i] = prices[i] - prices[i + 1]; else if(d == 2) differenced[i] = (prices[i] - prices[i + 1]) - (prices[i + 1] - prices[i + 2]); else differenced[i] = prices[i]; } // Optimizing AR and MA coefficients ArrayInitialize(errors, 0.0); OptimizeCoefficients(differenced); // Generating ARIMA forecast double forecast[]; ArrayResize(forecast, forecast_bars); double undiff[]; ArrayResize(undiff, forecast_bars); // Initializing forecasting process forecast[0] = prices[0]; undiff[0] = prices[0]; // Iterative forecast generation for(int i = 1; i < forecast_bars; i++) { double ar_part = 0.0; double ma_part = 0.0; // Calculating autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar_coeffs[j] * (j < lookback ? differenced[j] : forecast[i - j - 1]); // Calculating moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma_coeffs[j] * errors[j]; // Forming forecast value forecast[i] = ar_part + ma_part; // Procedure of reversal of differentiation if(d == 1) undiff[i] = undiff[i - 1] + forecast[i]; else if(d == 2) undiff[i] = undiff[i - 1] + (undiff[i - 1] - (i >= 2 ? undiff[i - 2] : prices[1])) + forecast[i]; else undiff[i] = forecast[i]; // Updating error array for following iterations errors[i % lookback] = forecast[i] - (i < lookback ? differenced[i] : 0.0); } // Filling output buffer with forecast values for(int i = 0; i < forecast_bars; i++) { ForecastBuffer[i] = undiff[i]; } // Extending historical data for continuous display for(int i = forecast_bars; i < lookback; i++) { ForecastBuffer[i] = prices[i - forecast_bars]; } return(rates_total); }
差分の逆変換(逆差分)処理は、予測値を元のスケールに正しく復元するための重要なステップです。一次差分の場合、各予測値は「直前の非差分値」と「対応する一次差分の予測値」を加算することで求められます。二次差分を使用する場合は、時系列の曲率を考慮した、より複雑な再帰的計算式が用いられます。
計算面とパフォーマンス最適化
アルゴリズムのパフォーマンスは、計算プロセスの適切な構成とプロセッサリソースの最適な利用に大きく依存します。メインのOnCalculate関数は、新しいマーケットデータが到着した際に不要な再計算を最小限に抑えるよう設計されています。
差分処理は、異なる次数の変換に対応して実装されています。一次差分では隣接する観測値の単純な差分を計算し、二次差分では二階差分の式を使用します。これにより、単にトレンドを除去するだけでなく、トレンドの変化率も除去することが可能です。
実装上の重要なポイントとして、メモリ管理および可変長配列の正しい取り扱いがあります。ArrayResizeおよびArraySetAsSeries関数を使用することで、モデルパラメータの変化やMetaTrader 5におけるデータ構造の特性に柔軟に対応できます。
パラメータの較正と市場状況への適応
実際の取引環境でARIMAモデルを有効に活用するには、対象となる金融商品や分析の時間軸に応じたパラメータの慎重な調整が必要です。lookbackパラメータは履歴データの参照範囲を決定し、統計的に十分なサンプル数を確保できる一方で、古すぎるデータを含まないようにする必要があります。
モデルの次数である(p, d, q)の選択は、データへの適合精度と計算コストとのトレードオフです。自己回帰の次数pを大きくすると、より複雑な時間依存性を捉えられますが、過度に複雑化すると過学習を招き、新規データに対する予測精度が低下する可能性があります。
学習率パラメータlearning_rateは特に慎重に調整する必要があります。値が大きすぎると最適化が振動し、小さすぎると収束が遅くなります。
統計的検証と予測精度の評価
インジケーターの品質を客観的に評価するためには、予測精度を定量化できる複数の統計指標を用いる必要があります。代表的な指標としては、平均絶対誤差(MAE)、二乗平均平方根誤差(RMSE)、決定係数(R²)などが挙げられます。
予測精度指標
予測精度を評価する関数の実装により、モデル性能の定量的な分析や異なるARIMAの仕様の比較が可能になります。平均絶対誤差(MAE)は、予測値と実測値の乖離を直感的に示す指標であり、元の時系列と同じ単位で表現されます。
// Function of calculating average absolute error double CalculateMAE(double &actual[], double &predicted[], int size) { double mae = 0.0; for(int i = 0; i < size; i++) { mae += MathAbs(actual[i] - predicted[i]); } return mae / size; } // Function of calculating the root mean square error double CalculateRMSE(double &actual[], double &predicted[], int size) { double mse = 0.0; for(int i = 0; i < size; i++) { double error = actual[i] - predicted[i]; mse += error * error; } return MathSqrt(mse / size); } // Determination coefficient calculation function double CalculateR2(double &actual[], double &predicted[], int size) { double actual_mean = 0.0; for(int i = 0; i < size; i++) actual_mean += actual[i]; actual_mean /= size; double ss_tot = 0.0, ss_res = 0.0; for(int i = 0; i < size; i++) { ss_tot += (actual[i] - actual_mean) * (actual[i] - actual_mean); ss_res += (actual[i] - predicted[i]) * (actual[i] - predicted[i]); } return 1.0 - (ss_res / ss_tot); }
モデル残差の診断
モデル残差の分析は、検証において非常に重要なステップであり、モデルの仮定からの系統的な偏差を特定することを可能にします。残差の自己相関を確認するリュング・ボックス検定は、モデル仕様の妥当性をチェックする手段として用いられます。また、ジャック–ベラ検定は、残差分布の正規性を評価するために使用されます。
// Function for calculating autocorrelation function of the residuals double CalculateAutocorrelation(double &residuals[], int lag, int size) { double mean = 0.0; for(int i = 0; i < size; i++) mean += residuals[i]; mean /= size; double numerator = 0.0, denominator = 0.0; for(int i = lag; i < size; i++) { numerator += (residuals[i] - mean) * (residuals[i - lag] - mean); } for(int i = 0; i < size; i++) { denominator += (residuals[i] - mean) * (residuals[i] - mean); } return numerator / denominator; } // Ljung-Box statistic for testing autocorrelation double LjungBoxTest(double &residuals[], int max_lag, int size) { double lb_stat = 0.0; for(int k = 1; k <= max_lag; k++) { double rho_k = CalculateAutocorrelation(residuals, k, size); lb_stat += (rho_k * rho_k) / (size - k); } return size * (size + 2) * lb_stat; }
クロスバリデーション手法を用いることで、学習サンプル内の変化に対するモデルの頑健性を評価できます。特にスライディングウィンドウ法は、パラメータを更新せずに新しいデータに逐次適用する状況で、実際の取引に近い条件下での予測精度をより現実的に評価することが可能です。
モデル残差の分析は、モデル仮定が実データの特性に適合しているかを確認する上で重要な情報を提供します。残差の自己相関に対する検定は、モデルで考慮されていない時間依存性を特定するのに役立ちます。また、残差分布の正規性に関する検定は、使用されている統計モデルの妥当性をチェックする手段となります。
インジケーターは、指定した期間に対する予測値を出力します。
アルゴリズムの発展と改良の展望
現代の金融時系列分析の研究は、基本的なARIMAモデルの発展に幅広い可能性を開きます。たとえば、季節成分を含むSARIMAモデルを使用することで、多くの金融商品に見られる周期的パターンを考慮することが可能です。さらに、L1やL2正則化のような手法を導入すると、外れ値に対する頑健性が向上し、過学習を防ぐことができます。
市場の現状に応じてモデルパラメータを動的に変更する適応型アルゴリズムは、特に高頻度取引において有用です。また、機械学習手法を組み合わせることで、アナリストを介さずに最適なモデル仕様を自動的に選択することも可能です。
さらに、ARIMAモデルの多次元拡張により、複数の相互関連する金融商品を同時にモデル化することが可能になります。これはポートフォリオ管理や裁定取引戦略において特に重要です。
最終的な考察
本記事で紹介したMQL5環境におけるARIMAインジケーターの実装は、古典的な計量経済学手法をアルゴリズム取引の課題に適応させる可能性を示しています。統計手法を厳密に遵守しつつ、効果的なソフトウェア実装を組み合わせることで、金融時系列を分析する信頼性の高いツールを構築できます。
インジケーターを実際に活用するには、モデルの数学的基盤と、使用する市場の特性の両方に対する深い理解が必要です。特に、トレンドが不安定な市場では、モデルの性能は大幅に低下します。
MetaQuotes Ltdによってロシア語から翻訳されました。
元の記事: https://www.mql5.com/ru/articles/18253
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
ディファレンシャルの部分はどこですか?
RenkoとArimaを組み合わせれば、より安定するはずだ。
ええ、私も使っています。