
Neuronale Netze im Trading: Adaptive Erkennung von Marktanomalien (DADA)

Einführung
Mit dem Fortschritt der Technologie und der Automatisierung von Prozessen sind Zeitreihen zu einem festen Bestandteil der Finanzmarktanalyse geworden. Eine wirksame Erkennung von Anomalien in den Marktdaten ermöglicht es, potenzielle Bedrohungen wie starke Preisschwankungen, Marktmanipulation von Vermögenswerten und Liquiditätsveränderungen frühzeitig zu identifizieren. Dies ist besonders wichtig für den algorithmischen Handel, das Risikomanagement und die Bewertung der Stabilität des Finanzsystems. Plötzliche Spitzen in der Volatilität, Abweichungen im Handelsvolumen oder ungewöhnliche Korrelationen zwischen Handelsinstrumenten können auf Ausfälle, spekulative Aktivitäten oder sogar Marktkrisen hinweisen.
Moderne Methoden zur Erkennung von Anomalien, die auf Deep Learning basieren, sind zwar sehr erfolgreich, haben aber auch ihre Grenzen. In den meisten Fällen erfordern solche Ansätze ein separates Training für jeden neuen Datensatz, was ihre Anwendung unter realen Bedingungen erschwert. Die Finanzdaten ändern sich ständig, und ihre historischen Muster wiederholen sich nicht immer.
Eines der Hauptprobleme ist die unterschiedliche Struktur der Daten auf den verschiedenen Märkten. Moderne Algorithmen verwenden in der Regel Autoencoder, um sich das normale Marktverhalten zu „merken“, da Anomalien selten auftreten. Wenn ein Modell jedoch zu viele Informationen speichert, fängt es an, das Marktrauschen zu berücksichtigen, was die Genauigkeit der Erkennung von Anomalien verringert. Umgekehrt kann eine übermäßige Komprimierung dazu führen, dass wichtige Muster verloren gehen. Die meisten Ansätze verwenden ein festes Kompressionsverhältnis, was die Fähigkeit des Modells zur Anpassung an unterschiedliche Marktbedingungen einschränkt.
Eine weitere Herausforderung ist die Vielfalt der Anomalien. Viele Modelle werden nur für normale Daten trainiert, aber ohne das Verständnis von Anomalien sind diese schwer zu erkennen. So kann zum Beispiel eine starke Preisspitze auf einem Markt eine Anomalie sein, auf einem anderen aber ein normales Ereignis. Bei einigen Vermögenswerten sind Anomalien mit plötzlichen Liquiditätsschüben verbunden, bei anderen mit unerwarteten Korrelationen. Infolgedessen kann ein Modell entweder wichtige Signale übersehen oder zu viele falsche Signale erzeugen.
Um diese Probleme zu lösen, haben die Autoren von „Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders“ ein neues DADA-Framework vorgeschlagen, das eine adaptive Informationskompression und zwei unabhängige Decoder verwendet. Im Gegensatz zu herkömmlichen Methoden passt sich DADA flexibel an unterschiedliche Daten an. Anstelle einer festen Komprimierungsstufe werden mehrere Optionen verwendet, von denen die jeweils geeignetste ausgewählt wird. Auf diese Weise lassen sich die Merkmale der Marktdaten besser erfassen und wichtige Muster erhalten.
Im Ausgabeteil des Modells werden zwei Decoder eingesetzt. Ein Decoder wird für normale Daten verwendet, während der andere für anomale Daten zuständig ist. Der erste Decoder lernt, die Zeitreihe zu rekonstruieren, während der zweite auf anomale Beispiele trainiert wird. Dies ermöglicht eine klare Trennung zwischen normalem Verhalten und Anomalien und verringert gleichzeitig die Wahrscheinlichkeit von Fehlsignalen.
Der DADA-Algorithmus
Zeitreihen sind Datenfolgen, die sich im Laufe der Zeit verändern. Jede Abweichung vom normalen Datenverhalten kann auf Krisen, Ausfälle oder betrügerische Aktivitäten hinweisen. Um solche Anomalien effektiv zu erkennen, setzt das DADA-Framework (Detector with Adaptive Bottlenecks and Dual Adversarial Decoders) Deep-Learning-Methoden für die adaptive Zeitreihenanalyse und die Erkennung anomaler Muster ein. Ein wesentliches Merkmal des DADA ist seine Universalität. Es erfordert keine vorherige Anpassung an einen bestimmten Bereich und kann mit einem breiten Spektrum an Eingabedaten arbeiten.
Das DADA-Framework basiert auf der Idee der maskierungsbasierten Datenrekonstruktion und ist damit ein effektives Werkzeug zur Analyse zeitlicher Abhängigkeiten und zur Identifizierung von Abweichungen von der Norm. Mit dieser Methode kann sich das Modell nicht nur Muster in den Daten einprägen, sondern auch lernen, deren Struktur zu verstehen, indem es fehlende oder beschädigte Segmente rekonstruiert.
Der Trainingsprozess beinhaltet die Arbeit mit zwei Arten von Sequenzen: normale und anomale. Im Gegensatz zu herkömmlichen Ansätzen, die eine manuelle Kennzeichnung anomaler Daten erfordern, verwendeten die Autoren des DADA-Frameworks einen generativen Ansatz, bei dem den ursprünglichen Zeitreihen künstliches Rauschen hinzugefügt wurde. Dieser Ansatz vereinfacht nicht nur die Datenaufbereitung durch den Wegfall der manuellen Arbeit, sondern macht das Modell auch universeller. Es lernt, verschiedene Arten von Abweichungen zu erkennen: Spitzen, Ausreißer, Trendverschiebungen, Veränderungen der Volatilität und andere Muster.
In der ersten Stufe werden die Originaldaten in Segmente (Patches) unterteilt, auf die eine zufällige Maskierung angewendet wird. Dies ist notwendig, um das Modell zu trainieren und fehlende Teile der Daten zu rekonstruieren. Sie verbessert die Fähigkeit, Anomalien und versteckte Muster zu erkennen.
Anschließend werden die Segmente in einen Encoder eingespeist, wo sie in eine kompakte latente Darstellung umgewandelt werden. Der Encoder lernt, die wichtigsten Merkmale der Zeitreihe zu extrahieren, während Rauschen und unbedeutende Details ignoriert werden. Durch diesen Ansatz kann das Modell besser verallgemeinert werden und mit Daten unterschiedlicher Art arbeiten, seien es Preischarts auf den Finanzmärkten, Zeitreihen zum Handelsvolumen oder andere Indikatoren.
Eine der Schlüsselkomponenten des Modells ist der adaptive Engpassmechanismus, der den Grad der Informationskompression in Abhängigkeit von der Struktur und Qualität der Daten reguliert. Wenn die Daten ein aussagekräftiges Signal enthalten, behält das Modell mehr Details bei; wenn die Informationen redundant oder stark verrauscht sind, wird die Komprimierung erhöht, was dazu beiträgt, Störungen zu minimieren und die Erkennung von Anomalien zu verbessern.
Das Adaptive Bottleneck Module (AdaBN) passt den Grad der Datenkompression dynamisch an. Dieser Mechanismus besteht aus einem Pool von kleinen Modellen, die Autoencodern ähneln. Jeder von ihnen hat eine latente Darstellung unterschiedlicher Größe:
![]()
wobei DownNeti(•) eine Komprimierung der analysierten Daten vornimmt und UpNeti(•) sie rekonstruiert.
Ein adaptiver Router wählt den optimalen Pfad auf der Grundlage der Analyse der Eingabedaten:
![]()
wobei Wrouter und Wnoise trainierbare Matrizen sind.
Für die Komprimierung jedes Segments werden die besten geeigneten Pfade k mit dem höchsten Wert von R(z) verwendet.
Nach der Kodierung werden die latenten Repräsentationen an zwei parallele Decoder weitergeleitet. Einer davon ist auf die Rekonstruktion normaler Daten ausgelegt und wird so trainiert, dass der Rekonstruktionsfehler minimiert wird. Der zweite Decoder dient der Erkennung von Anomalien, indem er eine maximale Abweichung zwischen rekonstruierten und ursprünglichen Werten erzeugt. Durch diesen adversarialen Prozess kann das Modell effektiv zwischen Standardmustern und unerwarteten Abweichungen unterscheiden.
Während der Tests und des praktischen Einsatzes ist der Anomalie-Decoder deaktiviert, und die Auswertung erfolgt ausschließlich mit dem normalen Decoder. Wenn das Modell die Daten mit hoher Genauigkeit rekonstruiert, entspricht die Zeitreihe einem normalen Verhalten. Wenn die Rekonstruktion mit erheblichen Fehlern einhergeht, deutet dies auf eine mögliche Anomalie hin.
Nachfolgend ist die Visualisierung des DADA-Frameworks der Autoren dargestellt.

Implementierung mit MQL5
Nachdem wir die theoretischen Aspekte des DADA-Frameworks besprochen haben, gehen wir zum praktischen Teil unserer Arbeit über, in dem wir eine Implementierung unserer eigenen Interpretation der vorgeschlagenen Ansätze in MQL5 betrachten. Das Schlüsselelement dieses Frameworks ist das Modul für adaptive Engpässe. Wir beginnen unsere Arbeit mit seiner Konstruktion.
Ich glaube, ich bin nicht der Einzige, dem die Ähnlichkeit mit dem zuvor implementierten Modul Mixture of Experts aufgefallen ist. Es gibt jedoch einen wichtigen Unterschied. Bei dem von uns konstruierten CNeuronMoE-Objekt wird von der Verwendung von Mini-Modellen mit identischer Architektur ausgegangen. In diesem Fall müssen wir jedoch die Größe der latenten Zustandsschicht für jedes Modell variieren, um sie an die verschiedenen Datenmerkmale anzupassen. Diese Option kann nicht mehr wie bisher mit Faltungsschichtobjekten implementiert werden. Natürlich kann jedes Modell separat erstellt werden und die Daten werden nacheinander durch die Modelle geleitet. Dies führt jedoch zu einer geringeren Effizienz der Hardware und höheren Kosten für Training und Bereitstellung.
Um diese Probleme zu beseitigen, wurde beschlossen, ein neues Objekt für eine Faltungsschicht mit mehreren Fenstern zu entwickeln. Es basiert auf der Idee, gleichzeitig mehrere Varianten von Faltungsfenstergrößen zu verwenden. Dadurch kann das Modell Daten auf verschiedenen Granularitätsebenen in parallelen Berechnungsströmen analysieren. Ein solcher Ansatz macht die Architektur flexibler, verbessert die Qualität der Eingangsdatenverarbeitung und ermöglicht eine effizientere Nutzung der Rechenressourcen. Dadurch kann sich das Modell besser an verschiedene zeitliche Strukturen in den Eingabedaten anpassen und eine hohe Genauigkeit und Leistung gewährleisten.
Konstruktion von Algorithmen auf der OpenCL-Programmseite
Wie üblich wird der Großteil der mathematischen Operationen in den OpenCL-Kontext ausgelagert. Hier implementieren wir den Kernel FeedForwardMultWinConv, in dem wir den Vorwärtsdurchlauf unserer neuen Schicht organisieren.
__kernel void FeedForwardMultWinConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, __global const int *windows_in, const int inputs, const int windows_total, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t outputs = get_global_size(0);
Die Kernelparameter umfassen Zeiger auf vier Datenpuffer sowie vier Konstanten, die die Struktur der Eingabe- und Ausgabedaten festlegen.
Beachten Sie, dass einer der globalen Puffer (windows_in) ganzzahlige Werte enthält. Sie speichert die Größen der Faltungsfenster. Es wird davon ausgegangen, dass der Eingangsdatenpuffer (matrix_i) eine Folge von Segmenten enthält. Innerhalb jedes Segments werden die Daten für jedes Faltungsfenster nacheinander angeordnet.
Wir planen, diesen Kernel in einem zweidimensionalen Aufgabenraum aufzurufen. Die Größe der ersten Dimension gibt die Anzahl der Werte im Ergebnispuffer für jede univariate Sequenz an, während die zweite Dimension die Anzahl dieser univariaten Sequenzen darstellt.
Es sollte klargestellt werden, dass sich die erste Dimension speziell auf die Anzahl der Werte im Ergebnispuffer bezieht, nicht auf die Anzahl der Elemente in der univariaten Folge. Mit anderen Worten: Die Größe der ersten Dimension entspricht dem Produkt aus der Anzahl der analysierten Segmente in der univariaten Sequenz und der Anzahl der verwendeten Filter und Faltungsfenster. Gleichzeitig verwendet jedes Element unabhängig von der Größe des Faltungsfensters die gleiche Anzahl von Filtern. Dies ist notwendig, um die Konsistenz der Formate der aus der komprimierten Darstellung rekonstruierten Daten zu gewährleisten.
Im Kernelkörper bestimmen wir zunächst den aktuellen Thread in beiden Dimensionen des zweidimensionalen Aufgabenraums.
Als Nächstes müssen Offsets in den globalen Datenpuffern bestimmt werden, um auf die benötigten Elemente zugreifen zu können. Der Thread-Identifikator in der ersten Dimension verweist eindeutig auf ein Element des Ergebnispuffers innerhalb der analysierten univariaten Sequenz. Die Bestimmung der Offsets in den übrigen Datenpuffern erfordert jedoch zusätzliche Arbeit.
Zunächst bestimmen wir die Position des Elements innerhalb des analysierten Segments. Dazu nehmen wir den Rest der Division des Thread-Identifikators der ersten Dimension durch die Gesamtzahl der Elemente im Ergebnispuffer für ein einzelnes Segment.
const int id = i % (window_out * windows_total);
Anschließend bereiten wir mehrere lokale Variablen vor, um Zwischenwerte vorübergehend zu speichern.
int step = 0; int shift_in = 0; int shift_weight = 0; int window_in = 0; int window = 0;
Als Nächstes organisieren wir eine Schleife, um über alle Werte im Faltungsfensterpuffer zu iterieren.
#pragma unroll for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; step += win;
Innerhalb der Schleife berechnen wir die Summe aller Faltungsfenster, was uns die Größe eines einzelnen Segments im Eingangsdatenpuffer liefert. Zusätzlich wird in dieser Schleife der Offset innerhalb des aktuellen Segments zum benötigten Faltungsfenster (shift_in), die Größe des analysierten Faltungsfensters (window_in) und der Offset im trainierbaren Parameterpuffer zum Beginn der Matrixelemente des benötigten Faltungsfensters (shift_weight) bestimmt.
if((w * window_out) < id) { shift_in = step; window_in = win; shift_weight += (win + 1) * window_out; } }
Als Nächstes bestimmen wir die Anzahl der vollständigen Segmente, die dem aktuellen Element im Ergebnispuffer vorausgehen (steps), und addieren den entsprechenden Offset im Eingabedatenpuffer, um das gewünschte Segment zu erreichen.
int steps = (int)(i / (window_out * windows_total)); shift_in += steps * step + v * inputs;
Zu dem Offset im trainierbaren Parameterpuffer wird eine Korrektur für den entsprechenden Filter hinzugefügt. Dazu nehmen wir den Rest der Division der Position des analysierten Elements innerhalb des aktuellen Segments des Ergebnispuffers. Dies gibt uns den Index des Elements innerhalb der Ergebnisse des aktuellen Faltungsfensters. Dieser Wert gibt im Wesentlichen den gewünschten Filter an. Die Anzahl der trainierbaren Parameter in jedem Filter ist gleich der Größe des Faltungsfensters plus dem Bias-Element. Multipliziert man also den Filterindex mit der Anzahl der trainierbaren Parameter, erhält man den erforderlichen Offset.
shift_weight += (id % window_out) * (window_in+1);
Nach Abschluss der vorbereitenden Schritte organisieren wir eine Schleife, um den Wert des aktuellen Elements in einer lokalen Variablen zu berechnen.
float sum = matrix_w[shift_weight + window_in]; #pragma unroll for(int w = 0; w < window_in; w++) if((shift_in + w) < inputs) sum += IsNaNOrInf(matrix_i[shift_in + w], 0) * matrix_w[shift_weight + w];
Der erhaltene Wert wird dann mit Hilfe der Aktivierungsfunktion angepasst und in dem entsprechenden Element des globalen Ergebnispuffers gespeichert.
matrix_o[v * outputs + i] = Activation(sum, activation); }
Nachdem wir den Algorithmus für den Vorwärtsdurchlauf konstruiert haben, fahren wir mit der Organisation der Backpropagation fort. Hier erstellen wir zunächst den Kernel CalcHiddenGradientMultWinConv, um die Fehlergradienten bis auf die Ebene der Eingabedaten zu verteilen. Die Struktur der Parameter dieses Kerns entspricht weitgehend der des Kerns für den Vorwärtsdurchlauf. Wir fügen nur Zeiger auf die entsprechenden Gradientenpuffer hinzu.
__kernel void CalcHiddenGradientMultWinConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_ig, __global const float *matrix_og, __global const int *windows_in, const int outputs, const int windows_total, const int window_out, const int activation ) { const size_t i = get_global_id(0); const size_t v = get_global_id(1); const size_t inputs = get_global_size(0);
Auch dieser Kernel arbeitet in einem zweidimensionalen Aufgabenraum. Diesmal gibt die erste Dimension jedoch den Offset im Eingabedatenpuffer an, da wir auf der Eingabedatenebene die Gradientenwerte aller Filter aggregieren müssen.
Wie üblich identifiziert der Kernel zunächst den Thread über alle Dimensionen des Aufgabenraums. Dann organisieren wir eine Schleife, um alle Faltungsfenster zu summieren, um die Größe eines einzelnen Segments im Eingangsdatenpuffer zu bestimmen.
int step = 0; #pragma unroll for(int w = 0; w < windows_total; w++) step += windows_in[w];
Auf diese Weise können wir den Index des Segments, das dem analysierten Element entspricht, und den Versatz innerhalb dieses Segments bestimmen.
int steps = (int)(i / step); int id = i % step;
Als Nächstes deklarieren wir mehrere lokale Variablen für die temporäre Datenspeicherung und organisieren eine weitere Schleife. Innerhalb dieser Schleife werden die Größe des analysierten Faltungsfensters (window_in), der Index des Faltungsfensters (window) und der Offset innerhalb des aktuellen Segments zum Beginn des aktuellen Faltungsfensters (before) bestimmt.
int window = 0; int before = 0; int window_in = 0; #pragma unroll for(int w = 0; w < windows_total; w++) { window_in = windows_in[w]; if((before + window_in) >= id) break; window = w + 1; before += window_in; }
Mit diesen Werten lässt sich der Offset im Ergebnispuffer (shift_out) und im Parametertensor (shift_weight) bestimmen.
int shift_weight = (before + window) * window_out + id - before; int shift_out = (steps * windows_total + window) * window_out + v * outputs;
Zu diesem Zeitpunkt ist die Vorbereitungsphase abgeschlossen, und wir haben genügend Informationen, um die Fehlergradienten zu akkumulieren. Wir organisieren eine weitere Schleife, in der wir die Gradientenwerte aller Filter sammeln und dabei die entsprechenden Gewichte berücksichtigen.
float sum = 0; #pragma unroll for(int w = 0; w < window_out; w++) sum += IsNaNOrInf(matrix_og[shift_out + w], 0) * matrix_w[shift_weight + w * (window_in + 1)];
Der resultierende Wert wird mit Hilfe der Ableitung der Aktivierungsfunktion der Eingabeschicht angepasst, und das Ergebnis wird im entsprechenden Element des globalen Gradientenpuffers gespeichert.
matrix_ig[v * inputs + i] = Deactivation(sum, matrix_i[v * inputs + i], activation); }
Der dritte Schritt unserer Arbeit besteht darin, den Prozess der Verteilung des Fehlergradienten auf die Ebene der Gewichtskoeffizienten zu konstruieren und sie zu aktualisieren, um den Gesamtmodellfehler zu minimieren. Im Rahmen dieser Arbeit implementieren wir den Optimierungsalgorithmus Adam in den Kernel UpdateWeightsMultWinConvAdam.
Um diesen Algorithmus korrekt zu konstruieren, erweitern wir die Anzahl der Kernelparameter, indem wir spezifische Konstanten und zwei globale Puffer für die Momente hinzufügen.
__kernel void UpdateWeightsMultWinConvAdam(__global float *matrix_w, __global const float *matrix_og, __global const float *matrix_i, __global float *matrix_m, __global float *matrix_v, __global const int *windows_in, const int windows_total, const int window_out, const int inputs, const int outputs, const float l, const float b1, const float b2 ) { const size_t i = get_global_id(0); // weight shift const size_t v = get_local_id(1); // variable const size_t variables = get_local_size(1);
Dieser Kernel ist ebenfalls für die Verwendung in einem zweidimensionalen Aufgabenraum vorgesehen. Dieses Mal gibt die erste Dimension das optimierte Element im globalen Puffer der trainierbaren Parameter an. Es gibt jedoch eine wichtige Nuance. Bei der Arbeit mit mehrdimensionalen Zeitreihen wird jede univariate Sequenz mit gemeinsamen trainierbaren Parametern analysiert. Daher müssen wir in diesem Stadium die Fehlergradienten aus allen univariaten Sequenzen aggregieren. Um die parallele Verarbeitung einzelner univariater Sequenzen zu organisieren, verteilen wir sie entlang der zweiten Dimension des Aufgabenraums und gruppieren sie in Arbeitsgruppen, um den Datenaustausch zu ermöglichen. Gerade für den Datenaustausch innerhalb einer Workgroup legen wir ein Array im lokalen Speicher von OpenCL an.
__local float temp[LOCAL_ARRAY_SIZE];
Als Nächstes gehen wir zur Vorbereitungsphase über, in der wir die Offsets in den Datenpuffern bestimmen. Der vielleicht einfachste Schritt ist die Bestimmung der Schrittweite im Ergebnispuffer (step_out). Sie ist gleich dem Produkt aus der Anzahl der Faltungsfenster pro Segment und der Anzahl der Filter.
int step_out = window_out * windows_total;
Um die übrigen Parameter zu erhalten, sind zusätzliche Arbeiten erforderlich. Zunächst deklarieren wir lokale Variablen, um Zwischenergebnisse zu speichern.
int step_in = 0; int shift_in = 0; int shift_out = 0; int window = 0; int number_w = 0;
Dann organisieren wir eine Schleife, um über die Werte im globalen Puffer der Faltungsfenstergrößen zu iterieren.
#pragma unroll for(int w = 0; w < windows_total; w++) { int win = windows_in[w]; if((step_in + w)*window_out <= i && (step_in + win + w + 1)*window_out > i) { shift_in = step_in; shift_out = (step_in + w + 1) * window_out; window = win; number_w = w; } step_in += win; }
Innerhalb dieser Schleife bestimmen wir den Offset zum gewünschten Faltungsfenster in den Eingangsdatenpuffern (shift_in) und Ergebnispuffern (shift_out), die Größe des Faltungsfensters (window) und seinen Index im Puffer (number_w). Darüber hinaus wird die Summe aller Faltungsfenster (step_in) berechnet, die die Segmentgröße angibt. Dieser Wert wird auch als Schrittweite für den Eingangsdatenpuffer verwendet.
Es ist wichtig zu beachten, dass nicht jeder trainierbare Parameter mit dem Eingabedatenpuffer verbunden ist, da das Bias-Element vorhanden ist. Wir führen daher ein Kennzeichen ein, um solche Elemente zu erkennen.
bool bias = ((i - (shift_in + number_w) * window_out) % (window + 1) == window);
Als Nächstes wird der Offset an das gewünschte Element im Ergebnispuffer angepasst.
int t = (i - (shift_in + number_w) * window_out) / (window + 1); shift_out += t + v * outputs;
Ein ähnlicher Vorgang wird durchgeführt, um den Offset im globalen Eingangsdatenpuffer anzupassen.
shift_in += (i - (shift_in + number_w) * window_out) % (window + 1) + v * inputs;
Damit ist die Vorbereitungsphase abgeschlossen, und es kann direkt mit der Bestimmung des Gradienten des analysierten Parameters begonnen werden. Dazu organisieren wir eine Schleife, die Gradientenwerte von allen Elementen des Ergebnispuffers sammelt, bei deren Berechnung der zu optimierende Parameter im aktuellen Thread beteiligt war.
float grad = 0; int total = (inputs + step_in - 1) / step_in; #pragma unroll for(int t = 0; t < total; t++) { int sh_out = t * step_out + shift_out; if(bias && sh_out < outputs) { grad += IsNaNOrInf(matrix_og[sh_out], 0); continue; }
Bei den Bias-Elementen werden die Gradientenwerte einfach summiert, während die anderen Parameter auf der Grundlage des entsprechenden Elements der Eingabedaten angepasst werden.
int sh_in = t * step_in + shift_in; if(sh_in >= inputs) break; grad += IsNaNOrInf(matrix_og[sh_out] * matrix_i[sh_in], 0); }
Es ist zu beachten, dass wir in dieser Schleife nur Fehlerwerte innerhalb einer einzigen univariaten Sequenz sammeln. Wie bereits erwähnt, wird der optimierte Parameter jedoch für alle Sequenzen der mehrdimensionalen Zeitreihe verwendet. Daher müssen wir vor der Parameteroptimierung die Werte aller univariaten Sequenzen, die innerhalb der Arbeitsgruppe berechnet wurden, zusammenfassen. Um dies zu erreichen, summieren wir in der ersten Stufe einzelne Werte zu Elementen eines lokalen Arrays.
//--- sum const uint ls = min((uint)variables, (uint)LOCAL_ARRAY_SIZE); #pragma unroll for(int s = 0; s < (int)variables; s += ls) { if(v >= s && v < (s + ls)) temp[v % ls] = (i == 0 ? 0 : temp[v % ls]) + grad; barrier(CLK_LOCAL_MEM_FENCE); }
Dann addieren wir die in den Elementen des lokalen Arrays angesammelten Werte.
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(v < ls) temp[v] += (v < count && (v + count) < ls ? temp[v + count] : 0); if(v + count < ls) temp[v + count] = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Nachdem wir den Gesamtfehlergradienten aller Threads in der Arbeitsgruppe erhalten haben, können wir den Wert des analysierten Parameters aktualisieren. Für diesen Vorgang ist nur ein einziger Thread erforderlich.
if(v == 0) { grad = temp[0]; float mt = IsNaNOrInf(clamp(b1 * matrix_m[i] + (1 - b1) * grad, -1.0e5f, 1.0e5f), 0); float vt = IsNaNOrInf(clamp(b2 * matrix_v[i] + (1 - b2) * pow(grad, 2), 1.0e-6f, 1.0e6f), 1.0e-6f); float weight = clamp(matrix_w[i] + IsNaNOrInf(l * mt / sqrt(vt), 0), -MAX_WEIGHT, MAX_WEIGHT); matrix_w[i] = weight; matrix_m[i] = mt; matrix_v[i] = vt; } }
Als Ergebnis dieser Operationen aktualisieren wir den Wert des analysierten Parameters und die entsprechenden Momente in den globalen Datenpuffern.
An diesem Punkt schließen wir die Konstruktion der Algorithmen der Mehrfenster-Faltungsschicht in unserem OpenCL-Programm ab. Der vollständige Quellcode ist im Anhang zu finden.
Multi-Window Convolutional Layer Objekt
Der nächste Schritt unserer Arbeit besteht darin, die zuvor konstruierten Algorithmen der Mehrfenster-Faltungsschicht in das Hauptprogramm zu integrieren. Zu diesem Zweck erstellen wir ein neues Objekt CNeuronMultiWindowsConvOCL, in dem wir die Prozesse zur Verwaltung der im OpenCL-Kontext erstellten Kernel implementieren. Die Struktur des neuen Objekts wird im Folgenden dargestellt.
class CNeuronMultiWindowsConvOCL : public CNeuronConvOCL { protected: int aiWindows[]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronMultiWindowsConvOCL(void) { activation = SoftPlus; iWindow = -1; } ~CNeuronMultiWindowsConvOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronMultiWindowsConvOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); //--- virtual void SetOpenCL(COpenCLMy *obj); };
Im Wesentlichen stellt das neue Objekt CNeuronMultiWindowsConvOCL eine modifizierte Version einer Standard-Faltungsschicht dar. Daher ist es logisch, sie von der übergeordneten Klasse abzuleiten. Auf diese Weise können wir die grundlegende Faltungslogik übernehmen und doppelten Code vermeiden.
In der vorgestellten Struktur finden wir die bekannte Reihe von überschriebenen virtuellen Methoden. Der Hauptunterschied des neuen Objekts liegt jedoch darin, dass es gleichzeitig mit mehreren Faltungsfenstergrößen arbeitet. Dies erfordert die Schaffung zusätzlicher Datenspeicherelemente und Schnittstellen, um sie in den OpenCL-Kontext zu übertragen. Um dies zu erreichen, deklarieren wir ein zusätzliches Array aiWindows und ändern die Parameter der Objektinitialisierungsmethode Init.
bool CNeuronMultiWindowsConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &windows[], uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(windows.Size() <= 0 || ArrayCopy(aiWindows, windows) < int(windows.Size())) return false;
Es ist wichtig zu betonen, dass wir trotz aller Änderungen, die in den Algorithmus von CNeuronMultiWindowsConvOCL eingeführt wurden, alles getan haben, um die Logik und die Funktionalität der Basisklasse zu erhalten. Dies vereinfacht nicht nur die Integration des neuen Objekts in die bestehende Architektur, sondern ermöglicht auch die Wiederverwendung von bereits getesteten und debuggten Mechanismen.
Der Initialisierungsalgorithmus des Objekts beginnt mit der Überprüfung der Größe des in den Parametern empfangenen Faltungsfenster-Arrays und dem Kopieren seiner Werte in ein speziell erstelltes internes Array.
Als Nächstes bestimmen wir die Summe aller Faltungsfenster, wobei wir zu jedem ein Bias-Element hinzufügen.
int window = 0; for(uint i = 0; i < aiWindows.Size(); i++) window += aiWindows[i] + 1;
Dies mag wie ein nicht offensichtlicher, aber notwendiger Vorgang erscheinen. Der Grund dafür ist, dass wir für jedes Faltungsfenster eine Gewichtsmatrix der Größe (Windowi + 1) * Filters erzeugen müssen. Die Gesamtgröße des Parameterpuffers beträgt somit:
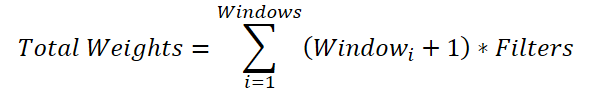
Die gemeinsame Variable für die Anzahl der Filter kann aus der Summierung herausgenommen werden:
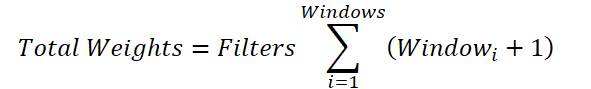
Ersetzt man die Summe der Fenster durch einen Gesamtwert, so erhält man die Formel zur Bestimmung der Anzahl der trainierbaren Parameter für ein einzelnes Faltungsfenster. In der übergeordneten Klasse kann jedoch nur ein Bias-Element hinzugefügt werden, anstatt eines pro Faltungsfenster, wie hier erforderlich. Daher addieren wir ein Bias-Element für jedes Fenster zur Gesamtsumme, dekrementieren dann den resultierenden Wert um eins und übergeben ihn als Fenstergröße und Faltungsschrittweite an die Initialisierungsmethode der Elternklasse.
window--; if(!CNeuronConvOCL::Init(numOutputs, myIndex, open_cl, window, window, window_out, units_count * aiWindows.Size()*variables, 1, ADAM, batch)) return false;
Da wir die gleichen Parameter für alle univariaten Sequenzen verwenden wollen, setzen wir ihre Anzahl auf 1. Gleichzeitig erhöhen wir die Anzahl der Elemente in der Sequenz, indem wir sie mit der Anzahl der Faltungsfenster und univariaten Sequenzen multiplizieren.
Dieser Ansatz ermöglicht es uns, alle vererbten Datenpuffer mit den erforderlichen Größen zu initialisieren, einschließlich der Initialisierung des Puffers der trainierbaren Parameter mit Zufallswerten.
Als Nächstes erstellen wir einen globalen Datenpuffer, um das Array der Faltungsfenster in den OpenCL-Kontext zu übertragen. Wie erwartet, werden die Werte dieses Puffers bei der Objektinitialisierung gesetzt und bleiben während des Trainings und des Modellbetriebs unverändert. Daher wird der Puffer nur innerhalb von OpenCL erstellt, während unser Objekt nur einen Zeiger darauf speichert.
iVariables = variables; iWindow = OpenCL.AddBufferFromArray(aiWindows, 0, aiWindows.Size(), CL_MEM_READ_ONLY); if(iWindow < 0) return false; //--- return true; }
Wir überprüfen die Korrektheit der Erstellung des globalen Puffers anhand des zurückgegebenen Handles und schließen die Initialisierungsmethode des neuen Objekts ab, wobei wir ein boolesches Ergebnis der Operation an das aufrufende Programm zurückgeben.
Nach der Initialisierung des neuen Objekts überschreiben wir die Methode für den Vorwärtsdurchlauf CNeuronMultiWindowsConvOCL::feedForward. Wie Sie vielleicht schon erraten haben, wird hier der zuvor erstellte Kernel FeedForwardMultWinConv zur Ausführung in die Warteschlange gestellt. Trotz der Anwendung eines Standardverfahrens für solche Fälle gibt es jedoch einige Nuancen, die zu beachten sind.
bool CNeuronMultiWindowsConvOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false;
Die Methode erhält einen Zeiger auf das Eingabedatenobjekt, dessen Gültigkeit sofort überprüft wird.
Nachdem die Validierungsprüfungen erfolgreich bestanden wurden, initialisieren wir die Parameter des zweidimensionalen Ausführungsraums.
uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {Neurons() / iVariables, iVariables};
Wie bereits in der Kernel-Beschreibung erwähnt, entspricht die zweite Dimension der Anzahl der univariaten Sequenzen in den Eingabedaten. Die Anzahl der Threads in der ersten Dimension wird bestimmt, indem die Gesamtzahl der Elemente im Ergebnispuffer unseres Objekts durch die Anzahl der univariaten Sequenzen geteilt wird.
Anschließend werden die Daten an die Kernel-Parameter übergeben.
ResetLastError(); int kernel = def_k_FeedForwardMultWinConv; if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_i, NeuronOCL.getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_o, getOutputIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_matrix_w, WeightsConv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(kernel, def_k_ffmwc_windows_in, iWindow)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
Es ist erwähnenswert, dass der zuvor gespeicherte Handle als Puffer für die Größe des Faltungsfensters übergeben wird. In der Zwischenzeit wird die Dimensionalität der Eingabedatenfolge bestimmt, indem die Größe des Eingabedatenpuffers durch die Anzahl der univariaten Sequenzen dividiert wird.
if(!OpenCL.SetArgument(kernel, def_k_ffmwc_inputs, NeuronOCL.Neurons() / iVariables)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_window_out, iWindowOut)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_windows_total, (int)aiWindows.Size())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(kernel, def_k_ffmwc_activation, (int)activation)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.Execute(kernel, 2, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Nach erfolgreicher Übergabe aller Parameter starten wir die Ausführung des Kernels und schließen die Methode ab, indem wir ein boolesches Ergebnis an das aufrufende Programm zurückgeben.
In ähnlicher Weise werden Kernel für die Organisation der Backpropagation-Prozesse in die Warteschlange gestellt. Die einzigen Unterschiede bestehen darin, dass wir bei der Verteilung der Fehlergradienten die Aktivierungsfunktion der Eingabeschicht angeben und bei den Operationen zur Parameteroptimierung die Bildung von Arbeitsgruppen innerhalb der zweiten Dimension des Aufgabenraums sicherstellen.
bool CNeuronMultiWindowsConvOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(!OpenCL || !NeuronOCL) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {WeightsConv.Total(), iVariables}; uint local_work_size[2] = {1, iVariables}; //--- ......... ......... ......... //--- if(!OpenCL.Execute(kernel, 2, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
An dieser Stelle schließen wir die Diskussion über die Algorithmen zur Konstruktion der Mehrfenster-Faltungsschicht ab. Der vollständige Code des Objekts CNeuronMultiWindowsConvOCL und alle seine Methoden sind im Anhang zu finden.
Wir sind fast am Ende des Artikels angelangt, doch unsere Arbeit ist noch nicht beendet. Machen wir eine kurze Pause und setzen wir unsere Interpretation der von den Autoren des DADA-Frameworks vorgeschlagenen Ansätze im nächsten Artikel fort.
Schlussfolgerung
Moderne Finanzmärkte sind nicht nur durch große Datenmengen, sondern auch durch eine hohe Variabilität gekennzeichnet. Dies macht die Erkennung von Anomalien zu einer besonders schwierigen Aufgabe. Das DADA-Framework schlägt einen grundlegend neuen Ansatz vor, der adaptive Engpässe und duale Paralleldecoder für eine genauere Zeitreihenanalyse kombiniert. Sein Hauptvorteil ist die Fähigkeit, sich dynamisch an unterschiedliche Datenstrukturen anzupassen, ohne dass eine vorherige Anpassung erforderlich ist, was es zu einem universellen Werkzeug macht.
Im praktischen Teil dieses Artikels haben wir damit begonnen, unsere eigene Interpretation der von den Autoren des DADA-Frameworks vorgeschlagenen Ansätze unter Verwendung von MQL5 umzusetzen. Unsere Arbeit ist jedoch noch nicht abgeschlossen, und wir werden sie im nächsten Artikel fortsetzen.
Referenzen
- Towards a General Time Series Anomaly Detector with Adaptive Bottlenecks and Dual Adversarial Decoders
- Andere Artikel dieser Serie
In diesem Artikel verwendete Programme
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Probenahme |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Probenahme mit der Methode Real-ORL |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für Modelltests |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Code-Bibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17549
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.