
Neuronale Netze im Trading: Anomalieerkennung im Frequenzbereich (CATCH)

Einführung
Moderne Finanzmärkte arbeiten in Echtzeit und verarbeiten jede Sekunde riesige Datenmengen. Aktienkurse, Wechselkurse, Handelsvolumina, Zinssätze – all dies sind komplexe, hochdimensionale Zeitreihen. Die Analyse solcher Daten ist für Händler und Investoren von entscheidender Bedeutung. Dies hilft ihnen, Marktbewegungen zu antizipieren und verborgene Muster aufzudecken.
Eine der zentralen Herausforderungen bei der Zeitreihenanalyse ist die Erkennung von Anomalien. Plötzliche Preisspitzen, starke Veränderungen der Liquidität oder verdächtige Handelsaktivitäten können auf Marktmanipulation oder Insiderhandel hinweisen. Bleiben diese Signale unbemerkt, kann das schwerwiegende Folgen haben – von erheblichen Verlusten bis hin zum Zusammenbruch ganzer Finanzinstitute.
Anomalien lassen sich im Allgemeinen in zwei Kategorien einteilen: Punktanomalien und Anomalien in Teilsequenzen. Punktuelle Anomalien sind starke Ausreißer, wie z. B. ein plötzlicher Anstieg des Handelsvolumens bei einer einzelnen Aktie. Diese sind mit Standardmethoden relativ leicht zu erkennen. Anomalien in Teilsequenzen sind subtiler – auf den ersten Blick wirken sie normal, weichen jedoch von den etablierten Marktmustern ab. Beispiele sind eine langfristige Verschiebung der Korrelationen zwischen Vermögenswerten oder ein ungewöhnlich sanfter Preisanstieg während eines volatilen Marktes. Diese Anomalien sind besonders wichtig, da sie oft auf versteckte Risiken hinweisen.
Eine der effektivsten Methoden zur Erkennung solcher Muster ist die Umwandlung der Daten in den Frequenzbereich. In dieser Darstellung manifestieren sich die verschiedenen Arten von Anomalien in bestimmten Frequenzbereichen. So wirken sich beispielsweise kurzfristige Volatilitätsspitzen auf hochfrequente Komponenten aus, während breitere Trendänderungen in niederfrequenten Bändern erscheinen. Bei herkömmlichen Methoden gehen jedoch oft wichtige Details verloren, insbesondere im Hochfrequenzbereich, in dem subtile, aber kritische Signale liegen können.
Es ist auch wichtig, die Beziehungen zwischen verschiedenen Marktinstrumenten zu berücksichtigen. Wenn beispielsweise die Ölterminkontrakte stark fallen, während die Aktien von Ölgesellschaften stabil bleiben, kann dies ein Zeichen für eine Marktinkonsistenz sein. Klassische Modelle ignorieren entweder solche Abhängigkeiten oder gehen von zu starren Annahmen aus, was die Vorhersagegenauigkeit verringert.
Eine mögliche Lösung für diese Probleme wird in dem Artikel „CATCH: Channel-Aware Multivariate Time Series Anomaly Detection via Frequency Patching“ vorgeschlagen. Die Autoren stellen das CATCH-Framework vor, das die Fourier-Transformation zur Analyse von Marktdaten im Frequenzbereich nutzt. Um die Erkennung komplexer Anomalien zu verbessern, schlagen sie einen Frequenz-Patching-Mechanismus vor, der das normale Asset-Verhalten mit hoher Präzision modelliert. Ein adaptives Beziehungsmodul identifiziert automatisch sinnvolle Korrelationen zwischen Marktinstrumenten und filtert gleichzeitig Rauschen heraus.
Der CATCH-Algorithmus
Die Architektur von CATCH besteht aus drei Schlüsselmodulen:
- Forward Module,
- Channel Fusion Module (CFM),
- Time-Frequency Reconstruction Module (TFRM).
Die erste Stufe ist das Forward Module. Dazu gehören die Normalisierung der Daten, die Umwandlung der Zeitreihe in den Frequenzbereich mithilfe der schnellen Fourier-Transformation (FFT) und die Aufteilung des Ergebnisses in Frequenz-Patches. Die Fourier-Transformation stellt die Zeitreihe als eine Reihe von orthogonalen trigonometrischen Funktionen dar, wobei sowohl die realen als auch die imaginären Komponenten des Spektrums erhalten bleiben.
Anschließend wird das Spektrum in L Frequenz-Patches der Größe P mit dem Schritt S unterteilt. Sowohl der Real- als auch der Imaginärteil werden mit denselben Parametern gepatcht und anschließend zu einem einheitlichen Tensor zusammengefügt.
Diese Patches werden dann mithilfe einer Projektionsschicht in einen latenten Raum projiziert:
![]()
Dieser Schritt ist wichtig, da er die Dimensionalität reduziert und gleichzeitig die informativsten Merkmale beibehält. Dies verbessert die Verallgemeinerungsfähigkeit des Modells und die Genauigkeit der Erkennung von Anomalien.
Die zweite Komponente ist das Channel Fusion Module (CFM), das die Abhängigkeiten zwischen den Kanälen innerhalb jedes Frequenzbandes erfasst. Dies wird durch einen Channel-Masked Transformer (CMT) erreicht. Eine Kanalmaske M wird von einem Maskengenerator (MG) erzeugt. MG konstruiert probabilistische Matrizen D und binarisiert sie mittels Bernoulli-Resampling. Hohe Werte in D entsprechen Einsen in M, was auf Abhängigkeiten zwischen den Kanälen hinweist.
Der CMT verarbeitet Patches mithilfe von maskierter Aufmerksamkeit, die durch die folgenden Ausdrücke beschrieben werden kann:

Für eine wirksame Optimierung im Zusammenhang mit der Maskenerstellung und der Anpassung des Aufmerksamkeitsmechanismus ist es wichtig, klare Optimierungsziele zu definieren, die zur Verbesserung der Qualität der resultierenden Masken beitragen. Der Kerngedanke besteht darin, die Aufmerksamkeitsgewichte zwischen relevanten Kanälen, die durch die Maske identifiziert wurden, explizit zu erhöhen. Dadurch wird der Aufmerksamkeitsmechanismus auf die aussagekräftigsten Korrelationen ausgerichtet und die Gesamtleistung des Modells verbessert.
Ein großer Vorteil dieses Ansatzes ist, dass er die negativen Auswirkungen der Einbeziehung irrelevanter Kanäle in den Aufmerksamkeitsprozess vermeidet. Indem sich der Mechanismus der maskierten Aufmerksamkeit nur auf die informativsten Kanäle konzentriert, reduziert er Rauschen und Verzerrungen. Dieser Ansatz ermöglicht es uns, die Stabilität des Aufmerksamkeitsmechanismus zu erreichen, was das Modell in dynamischen Umgebungen robuster und genauer macht.
Der nächste Schritt ist die iterative Optimierung des Maskengenerators, um die Korrelationen zwischen den Kanälen zu verfeinern. Dazu gehört die Feinabstimmung des Aufmerksamkeitsmechanismus innerhalb der maskierten Transformer-Schicht im Kontext der Kanäle, um alle relevanten Beziehungen zwischen den Kanälen besser zu erfassen.
Um die Maskierung zu optimieren, führen die Autoren eine ClusteringLoss-Funktion ein.
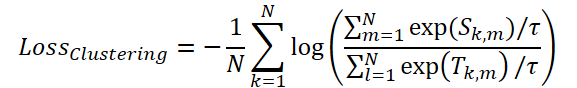
Schließlich wendet das Time-Frequency Reconstruction Module (TFRM) die inverse Fourier-Transformation (iFFT) an, um die Zeitreihen zu rekonstruieren.
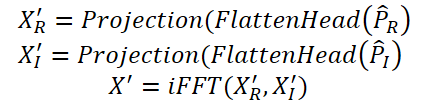
Anomalien werden anhand des Rekonstruktionsfehlers erkannt.
Durch die kombinierte Analyse im Zeit- und Frequenzbereich bietet das CATCH-Modell eine robuste und zuverlässige Erkennung von Anomalien.
Eine Visualisierung des CATCH-Frameworks ist unten abgebildet.

Implementierung in MQL5
Nachdem wir die theoretischen Aspekte des CATCH-Frameworks erläutert haben, gehen wir nun zum praktischen Teil des Artikels über, in dem wir unsere Interpretation der vorgeschlagenen Ansätze mit MQL5 umsetzen.
Zunächst ist es wichtig zu wissen, dass fast alle Operationen in diesem Framework im Frequenzbereich durchgeführt werden. Dies ist ein entscheidendes Merkmal, das sowohl den Ansatz der Datenverarbeitung als auch die Wahl der mathematischen Werkzeuge bestimmt.
Die Darstellung von Signalen im Frequenzbereich erfolgt bekanntlich mit komplexen Zahlen. Daher ist eine effiziente Verarbeitung komplexer Daten, einschließlich arithmetischer Operationen, für eine korrekte Systemleistung unerlässlich.
Wir haben uns bereits mit ähnlichen Herausforderungen bei der Arbeit am Framework ATFNet befasst. Damals haben wir Grundsätze für die Verarbeitung von Spektraldaten aufgestellt und methodische Ansätze entwickelt, die jetzt wiederverwendet werden können. Diese früheren Implementierungen vereinfachen die Umsetzung erheblich.
Komplexe Faltungsschicht
Wir beginnen mit dem Entwurf einer Faltungsschicht, die mit komplexen Werten arbeiten kann. In der Praxis gehören Faltungsschichten zu den effektivsten Werkzeugen für die Verarbeitung multivariater Sequenzen. Aus diesem Grund legen wir großen Wert auf die Entwicklung dieser Komponente.
Wie üblich beginnen wir mit der Implementierung der wichtigsten Algorithmen in OpenCL. Durch die Implementierung von Schlüsseloperationen auf GPU-Ebene können wir ein Maximum an Parallelität erreichen, was für die Verarbeitung multivariater Daten entscheidend ist. Im Gegensatz zu sequenziellen Berechnungen in einer CPU verarbeiten GPU-Kerne verschiedene Teile der Aufgabe gleichzeitig, was zu erheblichen Geschwindigkeitssteigerungen führt – sowohl beim Training als auch in der Produktion.
Der Vorwärtsdurchlauf ist im Kernel FeedForwardComplexConv implementiert. Dieser Kernel erhält Zeiger auf drei Datenpuffer zusammen mit mehreren Konstanten, die die Datenstruktur definieren.
Es ist wichtig zu beachten, dass alle Puffer den Vektortyp float2 verwenden. Der Grund für diese Wahl ist die Notwendigkeit, komplexe Zahlen, bei denen jeder Wert aus einer realen und einer imaginären Komponente besteht, effizient zu verarbeiten.
Die Verwendung von float2 bietet mehrere entscheidende Vorteile:
- Optimierter Speicherzugriff: Die Vektordarstellung ermöglicht das gleichzeitige Lesen und Schreiben von zwei Werten, wodurch die Speicheroperationen reduziert werden.
- Hardware-Beschleunigung: OpenCL unterstützt Vektortypen auf Hardware-Ebene, wodurch arithmetische Berechnungen beschleunigt werden.
- Sauberere Datendarstellung: float2 macht den Code intuitiver, da jede Variable direkt einer komplexen Zahl entspricht.
__kernel void FeedForwardComplexConv(__global const float2 *matrix_w, __global const float2 *matrix_i, __global float2 *matrix_o, const int inputs, const int step, const int window_in, const int activation ) { const size_t i = get_global_id(0); const size_t units = get_global_size(0); const size_t out = get_global_id(1); const size_t w_out = get_global_size(1); const size_t var = get_global_id(2); const size_t variables = get_global_size(2);
Der Kernel ist so konzipiert, dass er in einem dreidimensionalen Ausführungsraum arbeitet. Die erste Dimension entspricht der Anzahl der Elemente in der Folge. Die zweite Dimension entspricht der Anzahl der Filter, während die dritte Dimension die Anzahl der unabhängigen Einheitssequenzen innerhalb des gesamten Eingangstensors darstellt. Zu Beginn des Kernels wird der aktuelle Ausführungsthread in allen Dimensionen dieses Raums bestimmt, die resultierenden Indizes werden in lokalen Konstanten und die resultierenden Indizes in lokalen Konstanten gespeichert.
Auf der Grundlage dieser Indizes werden dann die Offsets innerhalb der Datenpuffer berechnet. Dieser Schritt spiegelt die Logik wider, die in der zuvor implementierten Faltungsschicht für komplexwertige Daten verwendet wurde, was durch die Darstellung komplexer Zahlen mit Vektor-Datentypen ermöglicht wird.
int w_in = window_in; int shift_out = w_out * (i + units * var); int shift_in = step * i + inputs * var; int shift = (w_in + 1) * (out + var * w_out); int stop = (w_in <= (inputs - shift_in) ? w_in : (inputs - shift_in)) + inputs * var;
Damit ist die Vorbereitungsphase abgeschlossen. Gehen wir nun zur Faltungsoperation über. In diesem Fall handelt es sich sowohl bei den Eingangsdaten als auch bei den Filterparametern um komplexe Werte. Das Ergebnis der Berechnung ist ebenfalls eine komplexe Zahl. Alle mathematischen Operationen werden mit den zuvor implementierten Funktionen für komplexe Grundrechenarten durchgeführt.
Zunächst deklarieren wir eine lokale Variable zur Speicherung von Zwischenergebnissen und initialisieren sie mit dem Bias-Term des Filters.
float2 sum = ComplexMul((float2)(1, 0), matrix_w[shift + w_in]); #pragma unroll for(int k = 0; k <= stop; k ++) sum += IsNaNOrInf2(ComplexMul(matrix_i[shift_in + k], matrix_w[shift + k]), (float2)0);
Dann führen wir eine Schleife aus, in der der Eingangsdatenvektor elementweise mit dem entsprechenden Filtervektor multipliziert wird, wobei die Ergebnisse in der lokalen Variablen akkumuliert werden.
Danach wird die entsprechende Aktivierungsfunktion angewendet und der Endwert in den Ausgabepuffer geschrieben.
switch(activation) { case 0: sum = ComplexTanh(sum); break; case 1: sum = ComplexDiv((float2)(1, 0), (float2)(1, 0) + ComplexExp(-sum)); break; case 2: if(sum.x < 0) { sum.x *= 0.01f; sum.y *= 0.01f; } break; default: break; } matrix_o[out + shift_out] = sum; }
Der nächste Schritt ist die Implementierung des Backpropagation. Betrachten wir den Kernel, der für die Weitergabe des Fehlergradienten CalcHiddenGradientComplexConv verantwortlich ist. Auch hier verwenden wir die vektorielle Darstellung der komplexen Zahlen. Die Methodenparameter enthalten Puffer für Fehlergradienten in den entsprechenden Stufen.
__kernel void CalcHiddenGradientComplexConv(__global const float2 * matrix_w, __global const float2 * matrix_g, __global const float2 * matrix_o, __global float2 * matrix_ig, const int outputs, const int step, const int window_in, const int window_out, const int activation, const int shift_out ) { const size_t i = get_global_id(0); const size_t inputs = get_global_size(0); const size_t var = get_global_id(1); const size_t variables = get_global_size(1);
Es ist wichtig zu beachten, dass der Zweck dieses Vorgangs darin besteht, den Fehlergradienten zurück zu den Eingabedaten zu übertragen, und zwar im Verhältnis zu ihrem Beitrag zur Ausgabe des Modells. Diese Anforderung führt zu einer Änderung des Kernel-Ausführungsraums. In dieser Implementierung wird ein zweidimensionaler Raum verwendet. Die erste Dimension entspricht den Elementen der Eingangssequenz, die zweite der univariaten Sequenz der multivariaten Reihe.
Wie zuvor beginnt der Kernel mit der Identifizierung des aktuellen Ausführungsthreads über alle Dimensionen hinweg. Die erhaltenen Indizes werden in lokalen Konstanten gespeichert.
Anschließend werden die Offsets innerhalb der Datenpuffer berechnet. Ein wichtiges Detail dabei ist, dass ein einzelnes Eingabeelement an mehreren Faltungsoperationen teilnehmen kann, abhängig von der Schrittweite des Faltungsfensters. Folglich muss der Gradient über alle diese Vorgänge hinweg aggregiert werden. Dazu legen wir die Bereiche fest, in denen der Gradient akkumuliert wird.
float2 sum = (float2)0; float2 out = matrix_o[i]; int start = i - window_in + step; start = max((start - start % step) / step, 0) + var * inputs; int stop = (i + step - 1) / step; if(stop > (outputs / window_out)) stop = outputs / window_out; stop += var * outputs;
Sobald die Vorbereitung abgeschlossen ist, durchläuft eine Schleife diese Bereiche mit dem angegebenen Schritt und summiert die Gradienten unter Berücksichtigung der entsprechenden Filtergewichte.
#pragma unroll for(int h = 0; h < window_out; h ++) { for(int k = start; k < stop; k++) { int shift_g = k * window_out + h; int shift_w = (stop - k - 1) * step + i % step + h * (window_in + 1); if(shift_g >= outputs || shift_w >= (window_in + 1) * window_out) break; sum += ComplexMul(matrix_g[shift_out + shift_g], matrix_w[shift_w]); } } sum = IsNaNOrInf2(sum, (float2)0);
Der resultierende Wert wird dann durch die Ableitung der Aktivierungsfunktion, die auf die Eingabedaten angewendet wird, angepasst.
switch(activation) { case 0: sum = ComplexMul(sum, (float2)1.0f - ComplexMul(out, out)); break; case 1: sum = ComplexMul(sum, ComplexMul(out, (float2)1.0f - out)); break; case 2: if(out.x < 0.0f) { sum.x *= 0.01f; sum.y *= 0.01f; } break; default: break; } matrix_ig[i] = sum; }
Das Ergebnis wird in dem entsprechenden Element des globalen Datenpuffers gespeichert.
Den vollständigen Code für die oben vorgestellten Kernel finden Sie im Anhang. Der Anhang enthält auch den vollständigen Code für die Kernel zur Optimierung der trainierbaren Filterparameter, den Sie am besten selbst studieren. Wir werden nun dazu übergehen, den Arbeitsablauf im Hauptprogramm zu organisieren.
In diesem Stadium führen wir ein neues Objekt CNeuronComplexConvOCL ein. Seine Struktur ist unten dargestellt.
class CNeuronComplexConvOCL : public CNeuronConvOCL { protected: //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL); public: CNeuronComplexConvOCL(void) { activation = None; } ~CNeuronComplexConvOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) const { return defNeuronComplexConvOCL; } };
Diese Klasse erbt vom Objekt der Faltungsschicht, das für reale Werte verwendet wird. Auf diese Weise können wir die bestehende Infrastruktur, einschließlich interner Objekte und Schnittstellen, wiederverwenden. Es sind jedoch noch einige Anpassungen der vererbten Methoden erforderlich.
Dies gilt in erster Linie für die Methoden der Vorwärts- und Backpropagation. Diese werden überschrieben, um mit den oben beschriebenen neuen OpenCL-Kerneln zu arbeiten. Das Einreihen dieser Kernel in die Ausführungswarteschlange erfolgt nach dem Standardverfahren. Wir werden hier also nicht ins Detail gehen. Die vollständige Umsetzung ist in den Anhängen enthalten.
Dennoch lohnt es sich, die neue Objektinitialisierungsmethode genauer zu betrachten, da die Arbeit mit komplexen Zahlen Auswirkungen auf die Behandlung von Datenpuffern hat. Obwohl MQL5 von Haus aus komplexe Zahlen unterstützt, haben wir uns entschieden, keine neuen Puffertypen einzuführen. Stattdessen haben wir die Größe der vorhandenen Puffer erhöht. Dieser Ansatz macht die Lösung universeller und vermeidet die Notwendigkeit umfangreicher Änderungen an bestehenden Methoden.
Die Struktur der Parameter der Initialisierungsmethode wird vollständig von der übergeordneten Klasse geerbt.
bool CNeuronComplexConvOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint step, uint window_out, uint units_count, uint variables, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, 2 * units_count * window_out * variables, optimization_type, batch)) return false;
Innerhalb der Methode rufen wir zunächst die entsprechende Methode der vollständig verbundenen Schicht auf, die als Basisklasse für alle neuronalen Netzwerkschichten in unserer Bibliothek dient, einschließlich der Faltungsschicht. Aufgrund der unterschiedlichen Puffergrößen können wir die Methode der unmittelbaren Elternklasse nicht direkt verwenden.
Beachten Sie, dass wir bei der Angabe der Größe des mit der übergeordneten Methode erstellten Objekts das Doppelte der berechneten Größe festlegen. Wie erwartet, ist dies notwendig, um sowohl den Real- als auch den Imaginärteil komplexer Werte zu speichern.
Als Nächstes speichern wir die Architekturkonstanten des Objekts in internen Variablen.
iWindow = (int)window; iStep = MathMax(step, 1); activation = None; iWindowOut = window_out; iVariables = variables;
Anschließend werden die geerbten Datenpuffer initialisiert. Zunächst wird geprüft, ob der Puffer für trainierbare Parameter gültig ist, und bei Bedarf ein neuer angelegt.
if(CheckPointer(WeightsConv) == POINTER_INVALID) { WeightsConv = new CBufferFloat(); if(CheckPointer(WeightsConv) == POINTER_INVALID) return false; }
Bei der Bestimmung der Größe dieses Puffers werden wiederum komplexe Werte berücksichtigt. Wir verdoppeln die erwartete Größe entsprechend.
int count = (int)(2 * (iWindow + 1) * iWindowOut * iVariables); if(!WeightsConv.Reserve(count)) return false;
Der Puffer wird dann mit Zufallswerten initialisiert.
float k = (float)(1 / sqrt(iWindow + 1)); for(int i = 0; i < count; i++) { if(!WeightsConv.Add((GenerateWeight() * 2 * k - k)*WeightsMultiplier)) return false; } if(!WeightsConv.BufferCreate(OpenCL)) return false;
Schließlich weisen wir je nach gewählter Optimierungsmethode die erforderliche Anzahl von Puffern für die Speicherung der Momentum-Terme des Optimierers zu. Diese Puffer werden zunächst mit Nullen gefüllt.
if(optimization == SGD) { if(CheckPointer(DeltaWeightsConv) == POINTER_INVALID) { DeltaWeightsConv = new CBufferFloat(); if(CheckPointer(DeltaWeightsConv) == POINTER_INVALID) return false; } if(!DeltaWeightsConv.BufferInit(count, 0.0)) return false; if(!DeltaWeightsConv.BufferCreate(OpenCL)) return false; } else { if(CheckPointer(FirstMomentumConv) == POINTER_INVALID) { FirstMomentumConv = new CBufferFloat(); if(CheckPointer(FirstMomentumConv) == POINTER_INVALID) return false; } if(!FirstMomentumConv.BufferInit(count, 0.0)) return false; if(!FirstMomentumConv.BufferCreate(OpenCL)) return false; //--- if(CheckPointer(SecondMomentumConv) == POINTER_INVALID) { SecondMomentumConv = new CBufferFloat(); if(CheckPointer(SecondMomentumConv) == POINTER_INVALID) return false; } if(!SecondMomentumConv.BufferInit(count, 0.0)) return false; if(!SecondMomentumConv.BufferCreate(OpenCL)) return false; } //--- return true; }
Am Ende der Methode wird ein boolesches Ergebnis zurückgegeben, das angibt, ob die Vorgänge erfolgreich ausgeführt wurden.
Damit ist unsere Betrachtung der Algorithmen für Faltungsschichten mit komplexwertigen Daten abgeschlossen. Die vollständige Implementierung dieser Klasse und aller ihrer Methoden finden Sie im Anhang.
Komplexes Modul für maskierte Aufmerksamkeit
Die nächste wichtige Komponente, die wir aufbauen werden, ist ein Modul für maskierte Aufmerksamkeit für komplexwertige Daten, das den Kernel des Channel Fusion Module bildet.
Wir haben bereits früher maskierte Aufmerksamkeitsmechanismen für realwertige Daten implementiert. Unsere Aufgabe besteht nun darin, diesen Ansatz auf komplexe Zahlen auszudehnen und dabei einige wichtige Merkmale des CATCH-Framework zu berücksichtigen.
Wie üblich beginnt die Entwicklung in OpenCL. Der Vorwärtsdurchlauf ist im MaskAttentionComplex-Kernel implementiert. Dieser Kernel benötigt Zeiger auf fünf Datenpuffer und zwei Konstanten, die die Struktur der Eingabedaten definieren. Da wir mit komplexen Zahlen arbeiten, verwenden die Puffer für Eingangs- und Ausgangsdaten den Vektortyp float2. In der Zwischenzeit enthalten die Maskenmatrix und die Puffer für die Aufmerksamkeitskoeffizienten immer noch reale Werte, da sie Wahrscheinlichkeitsverteilungen darstellen.
__kernel void MaskAttentionComplex(__global const float2 *q, __global const float2 *kv, __global float2 *scores, __global const float *masks, __global float2 *out, const int dimension, const int heads_kv ) { //--- init const int q_id = get_global_id(0); const int k = get_local_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int kunits = get_local_size(1); const int heads = get_global_size(2);
Der Kernel arbeitet in einem dreidimensionalen Ausführungsraum. Die erste Dimension entspricht der Größe des Query-Tensors und gibt die Anzahl der zu analysierenden Elemente an. Die zweite Dimension entspricht dem Key-Tensor mit der Anzahl der Elemente, die zur Berechnung der Abhängigkeiten verwendet werden. Entlang dieser Dimension werden die Threads in Arbeitsgruppen eingeteilt. Die dritte Dimension stellt die Anzahl der Aufmerksamkeitsköpfe dar. Zu Beginn der Ausführung identifiziert jeder Thread seine Position in diesem Raum und speichert die Indizes in lokalen Konstanten.
Anhand dieser Indizes werden die Offsets für alle Datenpuffer berechnet.
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h); const int shift_k = dimension * (2 * heads_kv * k + h_kv); const int shift_v = dimension * (2 * heads_kv * k + heads_kv + h_kv); const int shift_s = kunits * (q_id * heads + h) + k;
Der Maskenwert wird dann in eine lokale Variable geladen.
const float mask = IsNaNOrInf(masks[shift_s], 0);
Es ist wichtig zu beachten, dass der Kernel einen Maskentensor erwartet, der bereits die Aufmerksamkeitsköpfe berücksichtigt. Mit anderen Worten: Jeder Aufmerksamkeitskopf hat seine eigene Kanalmaskenmatrix.
Als Nächstes deklarieren wir ein Array im lokalen OpenCL-Kontextspeicher, das wir für den Datenaustausch innerhalb der Arbeitsgruppe verwenden werden.
const uint ls = min((uint)kunits, (uint)LOCAL_ARRAY_SIZE); float2 koef = (float2)(fmax((float)sqrt((float)dimension), (float)1), 0); __local float2 temp[LOCAL_ARRAY_SIZE];
Damit sind die vorbereitenden Arbeiten abgeschlossen, und wir gehen direkt zu den Rechenoperationen über. Zunächst müssen wir die Aufmerksamkeitskoeffizienten berechnen. Dazu führen wir eine Schleife über die entsprechenden Vektoren Query und Key aus. Das Exponential ihres Produkts wird mit der Maske multipliziert.
//--- Score float score = 0; float2 score2 = (float2)0; if(ComplexAbs(mask) >= 0.01) { for(int d = 0; d < dimension; d++) score2 = IsNaNOrInf2(ComplexMul(q[shift_q + d], kv[shift_k + d]), (float2)0); score = IsNaNOrInf(ComplexAbs(ComplexExp(ComplexDiv(score, koef))) * mask, 0); }
Beachten Sie, dass dieser Vorgang nur durchgeführt wird, wenn der Maskenwert einen vordefinierten Schwellenwert überschreitet. Dadurch wird der Einfluss irrelevanter Kanäle effektiv eliminiert.
Die resultierenden Werte müssen dann mit der Funktion SoftMax normalisiert werden, um eine geeignete Wahrscheinlichkeitsverteilung zu erhalten. Dazu addieren wir die Werte für die gesamte Arbeitsgruppe. Zunächst werden die Teilsummen innerhalb der Elemente des lokalen Arrays berechnet.
//--- sum of exp #pragma unroll for(int i = 0; i < kunits; i += ls) { if(k >= i && k < (i + ls)) temp[k % ls].x = (i == 0 ? 0 : temp[k % ls].x) + score; barrier(CLK_LOCAL_MEM_FENCE); }
Anschließend werden diese Teilsummen zu einer Endsumme zusammengerechnet.
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(k < ls) temp[k].x += (k < count && (k + count) < kunits ? temp[k + count].x : 0); if(k + count < ls) temp[k + count].x = 0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Nach allen Iterationen enthält das erste Element des lokalen Arrays die Gesamtsumme für die gesamte Arbeitsgruppe. Jeder Thread teilt dann seinen Aufmerksamkeitskoeffizienten durch diese Summe, um einen normalisierten Wert zu erhalten. Das Ergebnis wird in den globalen Ausgabepuffer geschrieben.
//--- score if(temp[0].x > 0) score = score / temp[0].x; scores[shift_s] = score;
Als Nächstes berechnen wir die endgültige Darstellung jedes Elements unter Berücksichtigung der Beiträge aus anderen Kanälen. Dazu wird der Vektor der Aufmerksamkeitskoeffizienten mit der Wertematrix multipliziert. Dieser Prozess wird durch die Notwendigkeit erschwert, Operationen in parallelen Arbeitsgruppen-Threads durchzuführen, da jeder Thread nur einen Aufmerksamkeitskoeffizienten enthält. Daher erfordert der Prozess eine verschachtelte Schleifenstruktur. Die äußere Schleife durchläuft die Elemente der entsprechenden Zeile in der Wertematrix.
//--- out #pragma unroll for(int d = 0; d < dimension; d++) { float2 val = (score > 0 ? ComplexMul(kv[shift_v + d], (float2)(score,0)) : (float2)0);
Innerhalb der Schleife lädt jeder Thread den entsprechenden Wert aus dem globalen Speicher, multipliziert ihn mit seinem Aufmerksamkeitskoeffizienten und speichert das Ergebnis in einer lokalen Variablen. Um den kostspieligen globalen Speicherzugriff zu verringern, wird dieser Schritt nur durchgeführt, wenn der Aufmerksamkeitskoeffizient größer als Null ist. Andernfalls wird die Variable sicher auf Null initialisiert, ohne auf den globalen Speicher zuzugreifen.
Der nächste Schritt besteht darin, diese Zwischenergebnisse über die Threads innerhalb der Arbeitsgruppe zu summieren. Hier verwenden wir ein Verfahren, das der Summierung der Aufmerksamkeitskoeffizienten ähnelt. Zunächst addieren wir die Teilergebnisse im lokalen Array.
#pragma unroll for(int i = 0; i < kunits; i += ls) { if(k >= i && k < (i + ls)) temp[k % ls] = (i == 0 ? (float2)0 : temp[k % ls]) + val; barrier(CLK_LOCAL_MEM_FENCE); }
Und dann summieren wir die Werte der Elemente des lokalen Arrays.
uint count = ls; #pragma unroll do { count = (count + 1) / 2; if(k < ls) temp[k] += (k < count && (k + count) < kunits ? temp[k + count] : (float2)0); if((k + count) < ls) temp[k + count] = (float2)0; barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
Es wird nur ein einziger Thread benötigt, um das Endergebnis in den globalen Puffer zu schreiben.
//--- if(k == 0) out[shift_q + d] = temp[0]; barrier(CLK_LOCAL_MEM_FENCE); } }
Bevor zur nächsten Iteration übergegangen wird, werden alle Threads in der Arbeitsgruppe synchronisiert.
Nachdem alle Iterationen abgeschlossen sind, wird die Kernelausführung beendet.
Der nächste Schritt ist die Implementierung von Backpropagation durch den komplexen Mechanismus der maskierten Aufmerksamkeit. Wir implementieren dies im Kernel MaskAttentionGradientsComplex.
__kernel void MaskAttentionGradientsComplex(__global const float2 *q, __global float2 *q_g, __global const float2 *kv, __global float2 *kv_g, __global const float *scores, __global const float *mask, __global float *mask_g, __global const float2 *gradient, const int kunits, const int heads_kv ) { //--- init const int q_id = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int qunits = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
Die Struktur dieses Kerns ähnelt weitgehend der des Vorwärtsdurchlaufs. Wir fügen lediglich globale Puffer für die Speicherung von Fehlergradienten hinzu. Der Ausführungsbereich ist jedoch leicht verändert. Es bleibt dreidimensional, aber die zweite Dimension stellt nun die Größe der internen Vektoren dar, und die Threads sind nicht mehr in Arbeitsgruppen gruppiert.
Im Kernelkörper identifizieren wir den aktuellen Thread über alle Dimensionen des Aufgabenraums und speichern die erhaltenen Werte in lokalen Konstanten. Wie zuvor verwenden wir sie, um Offsets in globalen Datenpuffern zu bestimmen.
const int h_kv = h % heads_kv; const int shift_q = dimension * (q_id * heads + h) + d; const int shift_s = (q_id * heads + h) * kunits; const int shift_g = h * dimension + d; float2 koef = (float2)(fmax(sqrt((float)dimension), (float)1), 0);
Nach Abschluss der vorbereitenden Arbeiten gehen wir direkt zur Erfassung der Fehlergradienten über. Zunächst definieren wir den Fehler auf der Ebene des Value-Tensor.
Erinnern Sie sich, dass der Value-Tensor verwendet wird, um alle Elemente der Ausgabesequenz durch Multiplikation mit der Aufmerksamkeitsmatrix zu erzeugen. Daher werden die Gradienten aus der Aufmerksamkeitsausgabe zurück in den Value-Tensor übertragen, gewichtet mit den entsprechenden Aufmerksamkeitskoeffizienten. Dies wird durch ein System von Schleifen realisiert.
//--- Calculating Value's gradients int step_score = kunits * heads; if(h < heads_kv) { #pragma unroll for(int v = q_id; v < kunits; v += qunits) { float2 grad = (float2)0; for(int hq = h; hq < heads; hq += heads_kv) { int shift_score = hq * kunits + v; for(int g = 0; g < qunits; g++) { float sc = IsNaNOrInf(scores[shift_score + g * step_score], 0); if(sc > 0) grad += ComplexMul(gradient[shift_g + dimension * (hq - h + g * heads)], (float2)(sc, 0)); } } int shift_v = dimension * (2 * heads_kv * v + heads_kv + h) + d; kv_g[shift_v] = grad; } }
Als Nächstes propagieren wir den Fehlergradienten auf die Ebene des Abfragetensors. Jedes Element des Query-Tensors beeinflusst nur ein einziges Ausgabeelement. Daher kann der entsprechende Gradient in einer lokalen Variablen gespeichert werden, um den globalen Speicherzugriff zu minimieren.
//--- Calculating Query's gradients float2 grad = 0; float2 out_g = IsNaNOrInf2(gradient[shift_g + q_id * dimension], (float2)0); int shift_val = (heads_kv + h_kv) * dimension + d; int shift_key = h_kv * dimension + d; #pragma unroll for(int k = 0; (k < kunits && ComplexAbs(out_g) != 0); k++) { float2 sc_g = 0; float2 sc = (float2)(scores[shift_s + k], 0); for(int v = 0; v < kunits; v++) sc_g += IsNaNOrInf2(ComplexMul( ComplexMul((float2)(scores[shift_s + v], 0), out_g * kv[shift_val + 2 * v * heads_kv * dimension]), ((float2)(k == v, 0) - sc)), (float2)0); float m = mask[shift_s + k]; mask_g[shift_s + k] = IsNaNOrInf(sc.x / m * sc_g.x + sc.y / m * sc_g.y, 0); grad += IsNaNOrInf2(ComplexMul(sc_g, kv[shift_key + 2*k*heads_kv*dimension]), (float2)0); } q_g[shift_q] = IsNaNOrInf2(ComplexDiv(grad, koef), (float2)0);
Bei der Erzeugung des resultierenden Wertes interagieren wir jedoch mit einer ganzen Reihe von Key- und Value-Tensorwerten. Um den erforderlichen Fehlerwert zu erhalten, propagieren wir den Gradienten zunächst auf die Aufmerksamkeitskoeffizientenmatrix und übertragen ihn erst dann auf den Abfragetensor.
Beachten Sie, dass wir hier auch den Fehlergradienten auf die Kanalmaskierungsmatrix übertragen.
Schließlich werden die Gradienten auf den Key-Tensor übertragen. Der Algorithmus ist dem der Query sehr ähnlich, mit dem Unterschied, dass die Berechnung entlang der Spalten der Aufmerksamkeitsmatrix erfolgt.
//--- Calculating Key's gradients if(h < heads_kv) { #pragma unroll for(int k = q_id; k < kunits; k += qunits) { int shift_k = dimension * (2 * heads_kv * k + h_kv) + d; grad = 0; for(int hq = h; hq < heads; hq++) { int shift_score = hq * kunits + k; float2 val = IsNaNOrInf2(kv[shift_k + heads_kv * dimension], (float2)0); for(int scr = 0; scr < qunits; scr++) { float2 sc_g = (float2)0; int shift_sc = scr * kunits * heads; float2 sc = (float2)(IsNaNOrInf(scores[shift_sc + k], 0), 0); if(ComplexAbs(sc) == 0) continue; for(int v = 0; v < kunits; v++) sc_g += IsNaNOrInf2( ComplexMul( ComplexMul((float2)(scores[shift_sc + v], 0), gradient[shift_g + scr * dimension]), ComplexMul(val, ((float2)(k == v, 0) - sc))), (float2)0); grad += IsNaNOrInf2(ComplexMul(sc_g, q[shift_q + scr * dimension]), (float2)0); } } kv_g[shift_k] = IsNaNOrInf2(ComplexDiv(grad, koef), (float2)0); } } }
Damit ist unser Überblick über die Algorithmen zur Implementierung komplexwertiger maskierter Aufmerksamkeit in OpenCL abgeschlossen. Die vollständigen Kernel-Implementierungen finden Sie in den Anhängen.
Der nächste Schritt besteht darin, die Logik der maskierten Aufmerksamkeit im Hauptprogramm zu implementieren. Wir werden dies im nächsten Artikel behandeln.
Schlussfolgerung
In diesem Artikel haben wir die theoretischen Grundlagen des CATCH-Frameworks untersucht, der die Fourier-Transformation mit Frequenz-Patching kombiniert, um Anomalien in multivariaten Zeitreihen zu erkennen. Sein Hauptvorteil liegt in seiner Fähigkeit, komplexe Marktmuster aufzudecken, die bei einer reinen Zeitdatenanalyse verborgen bleiben.
Die Darstellung im Frequenzbereich ermöglicht einen tieferen Einblick in die Marktdynamik, während Frequenz-Patching die Analyse an veränderte Bedingungen anpasst. Darüber hinaus erfasst CATCH die Beziehungen zwischen den Vermögenswerten und ist damit empfindlicher gegenüber systemischen Anomalien. Im Gegensatz zu herkömmlichen Methoden erkennt es nicht nur offensichtliche Spitzen und Ausreißer, sondern auch subtile, verborgene Abhängigkeiten, die auf bevorstehende Veränderungen der Markttrends hinweisen können.
Im praktischen Teil haben wir damit begonnen, unsere eigene Version des Frameworks in MQL5 zu implementieren. Im nächsten Artikel werden wir diese Arbeit fortsetzen und schließlich die Leistung der implementierten Lösungen anhand echter historischer Daten bewerten.
Verwandte Links
- CATCH: Channel-Aware multivariate Time Series Anomaly Detection via Frequency Patching
- Andere Artikel dieser Serie
In diesem Artikel verwendete Programme
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Expert Advisor für die Erfassung von Datensätzen |
| 2 | ResearchRealORL.mq5 | Expert Advisor | Expert Advisor für die Erfassung von Datensätzen mit der Methode Real-ORL |
| 3 | Study.mq5 | Expert Advisor | Expert Advisor für das Modelltraining |
| 4 | Test.mq5 | Expert Advisor | Expert Advisor für die Modelltests |
| 5 | Trajectory.mqh | Klassenbibliothek | Struktur der Beschreibung des Systemzustands und der Modellarchitektur |
| 6 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 7 | NeuroNet.cl | Bibliothek | OpenCL-Programmcode |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17649
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.