
Prognose von Renko-Bars mit CatBoost AI

Einführung
In der Stille meines Arbeitszimmers leuchtet nur der Bildschirm. Das MetaTrader 5-Terminal liefert die neuesten Tick-Daten, und der von mir entwickelte Algorithmus verwandelt das Marktchaos methodisch in ein geordnetes System von Renko-Bars. Drei Uhr morgens ist die Zeit, in der echte Handelsstrategien geboren werden. Ich fahre mir mit der Hand über mein unrasiertes Kinn und nehme einen Schluck von meinem inzwischen kalten Kaffee, meinem Lieblingskaffee Carte Noir. Die Genauigkeit des Modells von 59,27 % ist ein Sieg. Ein echter Sieg für diejenigen, die die Unberechenbarkeit der Finanzmärkte verstehen.
Als die traditionelle Analyse machtlos wurde
Vor fast 10 Jahren bin ich mit der Überzeugung in den Markt gegangen, dass die technische Analyse das Evangelium des Händlers ist. Ich zeichnete Unterstützungs- und Widerstandslinien, beobachtete die Überkreuzung gleitender Durchschnitte, suchte nach Divergenzen beim RSI und MACD, aber Jahr für Jahr musste ich feststellen, dass die Effizienz dieser Methoden abnahm. Der Markt veränderte sich, die Algorithmen des Hochfrequenzhandels veränderten sein Wesen, und die klassischen Methoden boten nicht mehr denselben Vorteil.
Eines Tages, nach einer besonders schlechten Handelswoche, fragte ich mich: Was wäre, wenn alle Bücher zur technischen Analyse, die im letzten Jahrhundert geschrieben wurden, nur noch unterhaltsame Fiktion wären? Diese Frage brachte mich dazu, meinen Handelsansatz radikal zu überdenken, und schließlich zur Entwicklung eines auf maschinellem Lernen basierenden Renko-Bar-Prognosesystems.
Renko-Bars – Das digitale Zen eines Traders
Ich lernte Renko-Charts zum ersten Mal auf einer Konferenz in Singapur kennen. Ein japanischer Händler, dessen Namen ich nicht preiszugeben versprach, zeigte mir sein Terminal mit ungewöhnlichen rechteckigen Blöcken anstelle der üblichen Kerzen. „Das sind Renko-Charts“, sagte er, „Charts, die nur das zeigen, was zählt – die Kursbewegung.“
In einer Welt, die von Informationen übersättigt ist, bieten Renko-Charts digitales Zen – sie entfernen das Rauschen, den Zeitfaktor und alles andere, was von der wahren Bewegung des Marktes ablenkt. Jeder neue Block wird nur gebildet, wenn sich der Kurs um eine bestimmte Strecke nach oben oder unten bewegt. In dieser Einfachheit liegt eine unglaubliche Kraft verborgen.
Ich habe angefangen, mit Renko-Charts für verschiedene Instrumente zu experimentieren. EURUSD, GBPUSD, DAX, S&P 500 – bei all diesen Instrumenten machten Renko-Charts die Marktstruktur für mich klarer und transparenter. Die manuelle Analyse erforderte jedoch Zeit, und die ist immer knapp bemessen. Und dann habe ich mich dem maschinellen Lernen zugewandt.
CatBoost – Der Algorithmus, der die globalen Märkte eroberte
Die Wahl des Algorithmus war nicht weniger wichtig als die Wahl der Handelsstrategie. Nachdem ich Dutzende verschiedener Modelle für maschinelles Lernen ausprobiert hatte, entschied ich mich für CatBoost, einen von Yandex entwickelten Gradient-Boosting-Algorithmus. Es war Liebe auf den ersten Lauf
# Initialize the CatBoost model params = { 'iterations': 300, 'learning_rate': 0.05, 'depth': 5, 'loss_function': 'Logloss', 'random_seed': 42, 'verbose': False } model = CatBoostClassifier(**params) model.fit(X_train, y_train, eval_set=(X_test, y_test), early_stopping_rounds=30, verbose=False)
CatBoost kann nicht nur gut mit kategorischen Merkmalen umgehen, was für die Analyse von Renko-Bar-Mustern entscheidend ist, sondern ist auch resistent gegen Überanpassung und schnell genug, um jeden Tag mit neuen Daten neu trainiert zu werden.
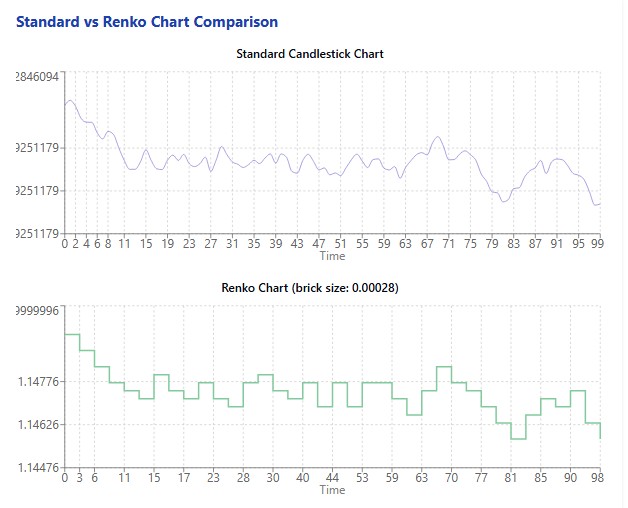
Zu Beginn meines Experiments lud ich 60 Tage EURUSD-Daten herunter – über 12.000 Fünf-Minuten-Bars. Diese Daten wurden in 11.578 Renko-Bars mit einer algorithmisch berechneten optimalen Blockgröße von 0,00028 Kurseinheiten umgewandelt. Die Aufbereitung der Merkmale ergab 11.572 Trainingsbeispiele für das Modell.
Nun ist der Moment der Wahrheit gekommen: das Training des CatBoost-Modells mit den vorbereiteten Daten.
Offenbarung in Zahlen: Was das Experiment gezeigt hat
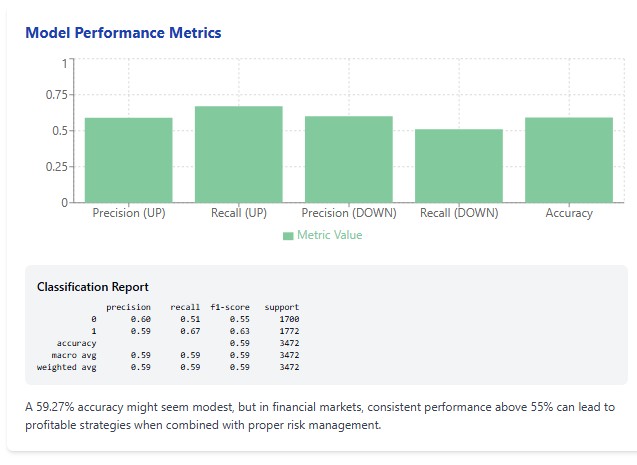
Als der Algorithmus mit dem Training fertig war und ich die Ergebnisse sah, war das wie eine Offenbarung. Die Genauigkeit des Modells auf dem Testsatz betrug 59,27 %. Für jemanden, der keine Erfahrung im Handel hat, mag diese Zahl bescheiden erscheinen. Aber für diejenigen, die mit den brutalen Statistiken des Finanzmarkthandels vertraut sind, ist dies ein bemerkenswertes Ergebnis.
Es lohnt sich, an die berühmte Studie der University of Michigan zu erinnern, die gezeigt hat, dass die meisten aktiv verwalteten Fonds nicht besser abschneiden als eine einfache Buy-and-Hold-Strategie. Diese Fonds beschäftigen brillante Analysten, die über einen Doktortitel verfügen und Zugang zu Insiderinformationen haben. Vor diesem Hintergrund wirkt eine Genauigkeit von 59,27 % nicht nur gut, sondern geradezu phänomenal.
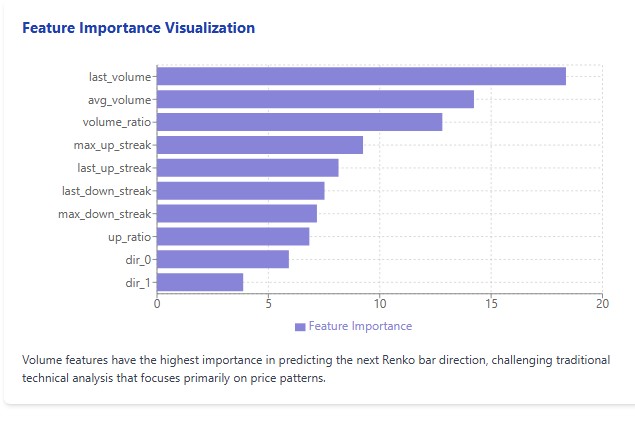
Noch überraschender war jedoch die Analyse der Bedeutung der Merkmale. Entgegen allen Regeln der technischen Analyse erwiesen sich die Volumenindikatoren als wesentlich wichtiger als die Kursmuster. Last_volume mit einem Wert von 18,36, avg_volume mit 14,23 und volume_ratio mit 12,81 belegten die ersten drei Plätze. Es folgten die Parameter der aufeinanderfolgenden Kursbewegungen.
Ich stieß in einem bekannten sozialen Netzwerk mehrmals auf einen erfolgreichen Händler, der sagte, dass der Heilige Gral in der Aufteilung des Volumens in Renko-Blöcke und Volumen-Cluster liegt. Vielleicht sind diese Ergebnisse gar nicht zufällig und haben eine Bedeutung?
Die Kunst der Renko-Bars
Die Arbeit mit Renko-Charts beginnt mit der Bestimmung der optimalen Blockgröße. Es ist wie beim Einstellen eines Mikroskops: Bei zu geringer Vergrößerung sieht man keine Details, während bei zu starker Vergrößerung das Gesamtbild verzerrt wird. Die Renko-Blockgröße ist eine Art Auflösung, mit der wir den Markt betrachten.
# Create Renko bars with adaptive block size def create_renko_bars(df, brick_size=None): if brick_size is None: # Calculate ATR to determine block size df['tr'] = np.maximum( df['high'] - df['low'], np.maximum( np.abs(df['high'] - df['close'].shift(1)), np.abs(df['low'] - df['close'].shift(1)) ) ) df['atr'] = df['tr'].rolling(window=14).mean() brick_size = df['atr'].mean() * 0.5 print(f"Renko block size: {brick_size:.5f}") # Create Renko bars renko_bars = [] current_price = df.iloc[0]['close'] # ... the rest of the code
Nach vielen Experimenten bin ich zu dem Schluss gekommen, dass die beste Methode zur Bestimmung der Blockgröße der ATR-Indikator (Average True Range) ist. Bei diesem Ansatz wird die Blockgröße an die aktuelle Volatilität des Instruments angepasst.
Im Falle von EURUSD ermittelte der Algorithmus eine optimale Blockgröße von 0,00028 Kurseinheiten, was etwa 2,8 Pips entspricht. Auf den ersten Blick mag dies unbedeutend erscheinen, aber gerade diese Granularität ermöglicht es uns, signifikante Bewegungen zu erfassen und das Marktrauschen herauszufiltern.
Die Erstellung von Renko-Bars ist nicht nur eine mechanische Umwandlung von Kursdaten. Es ist die Kunst, das Signal aus dem Rauschen zu extrahieren und eine sinnvolle Bewegung aus einem Meer von Vibrationen zu isolieren. Und als ich die umgewandelten Daten auf dem Chart sah, erschien ein kristallklares Bild des Marktes vor meinen Augen – eine Leiter aus roten und grünen Blöcken, die die wahre Kursbewegung ohne die durch den Zeitfaktor verursachten Verzerrungen widerspiegelte.
Merkmalsbildung: Was für Prognosen wirklich wichtig ist
Der Erfolg eines jeden Modells für maschinelles Lernen hängt in hohem Maße von der Qualität und Relevanz seiner Merkmale ab. Um die Richtung des nächsten Renko-Bars vorherzusagen, habe ich ein mehrstufiges System von Merkmalen entwickelt, das sowohl die Geschichte der Bewegungen als auch die Volumeneigenschaften berücksichtigt.
# Prepare features for the model def prepare_features(renko_df, lookback=5): features = [] targets = [] for i in range(lookback, len(renko_df) - 1): window = renko_df.iloc[i-lookback:i] feature_dict = { # Directions of the last n bars **{f'dir_{j}': window['direction'].iloc[-(j+1)] for j in range(lookback)}, # Movement statistics 'up_ratio': (window['direction'] > 0).mean(), 'max_up_streak': window['consec_up_streak'].max(), 'max_down_streak': window['consec_down_streak'].max(), 'last_up_streak': window['consec_up_streak'].iloc[-1], 'last_down_streak': window['consec_down_streak'].iloc[-1], # Volume 'last_volume': window['volume'].iloc[-1], 'avg_volume': window['volume'].mean(), 'volume_ratio': window['volume'].iloc[-1] / window['volume'].mean() if window['volume'].mean() > 0 else 1 } features.append(feature_dict) # Direction of the next bar (1 - up, 0 - down) next_direction = 1 if renko_df.iloc[i+1]['direction'] > 0 else 0 targets.append(next_direction) return pd.DataFrame(features), np.array(targets)
Zunächst habe ich die offensichtlichen Merkmale aufgenommen – die Richtungen der letzten paar Bars. Dann fügte ich statistische Metriken hinzu – das Verhältnis von aufsteigenden und absteigenden Bars, die Länge der aufeinanderfolgenden Bewegungen in einer Richtung, maximale Serien. Und schließlich habe ich Volumenindikatoren aufgenommen – das Volumen der letzten Bar, das durchschnittliche Volumen für den Zeitraum, das Verhältnis des aktuellen Volumens zum Durchschnitt.
Zu meiner Überraschung waren es die Volumenindikatoren, die sich als die wichtigsten für die Prognose herausstellten. Das hat mein Verständnis von Kursanalyse verändert. Jahrelang habe ich mich, wie die meisten Händler, auf Kerzenformen, Muster und Trendlinien konzentriert. Und die Antwort war von Anfang an das Volumen – eine Kennzahl, die im Devisenhandel aufgrund der dezentralen Natur des Marktes oft ignoriert wird.
Die endgültige Merkmalskonstellation umfasste 14 Parameter, die sich im Hinblick auf das Gleichgewicht zwischen der Komplexität des Modells und seiner Prognosekraft als optimal erwiesen. Mehr Merkmale führten zu einer Überanpassung, weniger Merkmale zu einer Unteranpassung.
Prognose in Aktion: Von der Theorie zur Praxis
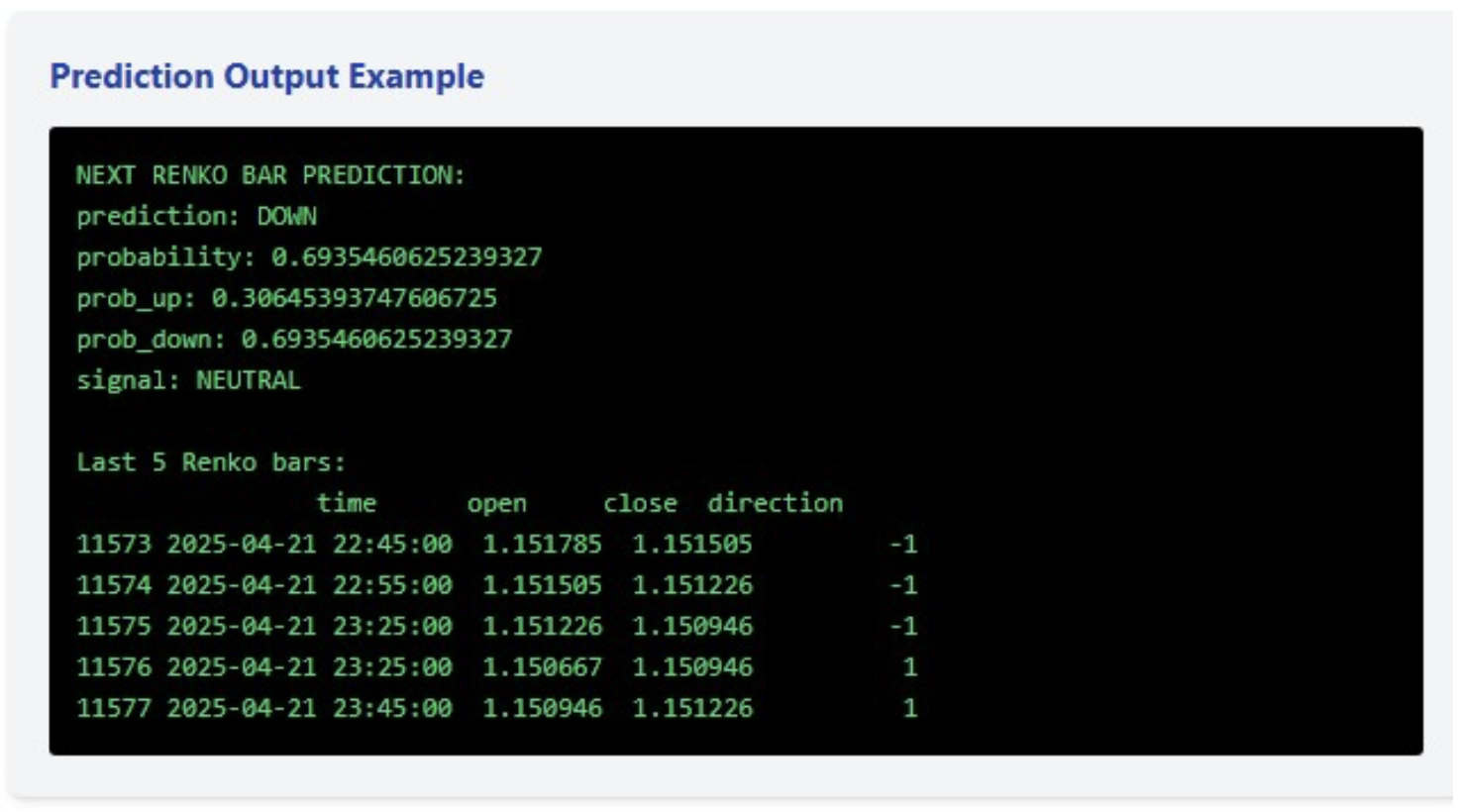
Das konstruierte Modell liefert nicht nur eine binäre Prognose über die Richtung der nächsten Bar, sondern auch die Wahrscheinlichkeit dieser Bewegung. Im letzten Beispiel hat das Modell einen Rückgang mit einer Wahrscheinlichkeit von 69,35 % vorhergesagt, was eine recht sichere Prognose ist, aber nicht ausreicht, um ein Handelssignal zu generieren (für das ich den Schwellenwert auf 75 % festgelegt habe).
# Forecast the next bar def predict_next_bar(model, renko_df, lookback=5, feature_names=None): if len(renko_df) < lookback: return {"error": "Insufficient data"} window = renko_df.iloc[-lookback:] feature_dict = { **{f'dir_{j}': window['direction'].iloc[-(j+1)] for j in range(lookback)}, 'up_ratio': (window['direction'] > 0).mean(), 'max_up_streak': window['consec_up_streak'].max(), 'max_down_streak': window['consec_down_streak'].max(), 'last_up_streak': window['consec_up_streak'].iloc[-1], 'last_down_streak': window['consec_down_streak'].iloc[-1], 'last_volume': window['volume'].iloc[-1], 'avg_volume': window['volume'].mean(), 'volume_ratio': window['volume'].iloc[-1] / window['volume'].mean() if window['volume'].mean() > 0 else 1 } X_pred = pd.DataFrame([feature_dict]) # Make sure all the features are present if feature_names: for feature in feature_names: if feature not in X_pred.columns: X_pred[feature] = 0 X_pred = X_pred[feature_names] prob = model.predict_proba(X_pred)[0] prediction = model.predict(X_pred)[0] return { 'prediction': 'UP' if prediction == 1 else 'DOWN', 'probability': prob[prediction], 'prob_up': prob[1], 'prob_down': prob[0], 'signal': 'BUY' if prob[1] > 0.75 else 'SELL' if prob[0] > 0.75 else 'NEUTRAL' }
Der wahre Wert liegt jedoch nicht in einer einzelnen Prognose, sondern in einem umfassenden Handelssystem. Die letzten fünf Renko-Bars zeigen eine interessante Dynamik: drei aufeinanderfolgende Rückgänge, gefolgt von zwei Anstiegen. Dieser Mikroaufwärtstrend in Verbindung mit einer Abwärtsprognose mit einer hohen, aber nicht ausreichenden Signalwahrscheinlichkeit deutet auf eine mögliche Konsolidierung und Unsicherheit auf dem Markt hin.
Gerade solche Phasen sind für den Handel besonders riskant, und das System erkannte diesen Zustand korrekt, ohne trotz der relativ hohen Abwärtswahrscheinlichkeit ein Signal zu erzeugen.
Ein Blick unter die Haube: Systemarchitektur
Bei dem entwickelten System handelt es sich um einen mehrschichtigen Mechanismus, bei dem jede Komponente ihre Rolle innerhalb des gesamten Prognoserahmens spielt. Schauen wir uns die Schlüsselelemente dieser Architektur an.
python# Main function def main(): # Get EURUSD data print("Load EURUSD data from MetaTrader5...") df = get_mt5_data(symbol='EURUSD', days=60) if df is None or len(df) == 0: print("Unable to retrieve data") return print(f"Loaded {len(df)} bars") # Create Renko bars print("Creating Renko bars...") renko_df, brick_size = create_renko_bars(df) print(f"Created {len(renko_df)} Renko bars") # Prepare features print("Preparing features...") X, y = prepare_features(renko_df) print(f"Prepared {len(X)} samples") # Train the model print("Training the model...") model, X_test, y_test = train_model(X, y) # Next bar forecast feature_names = X.columns.tolist() prediction = predict_next_bar(model, renko_df, feature_names=feature_names) print("\nNEXT RENKO BAR FORECAST:") for k, v in prediction.items(): print(f"{k}: {v}") # Info about the latest bars print("\nLast 5 Renko bars:") print(renko_df.tail(5)[['time', 'open', 'close', 'direction']])
Die Grundlage des Systems ist ein Modul zum Herunterladen von Daten aus MetaTrader 5. Die Integration mit MetaTrader 5 ermöglicht es uns, aktuelle Marktdaten nahezu in Echtzeit zu erhalten. Dieses Modul verwendet die offizielle MetaTrader 5 API, die Zuverlässigkeit und Stabilität gewährleistet.
Die nächste Ebene ist die Umwandlung gewöhnlicher zeitbasierter Kursbalken in Renko-Bars. Der Algorithmus berechnet die optimale Blockgröße auf der Grundlage der ATR und führt eine Transformation unter Berücksichtigung von Volumen und Zeit durch. Ein wesentliches Merkmal der Implementierung ist die Berechnung der sequenziellen Bewegungen und ihrer Eigenschaften direkt während der Bildung der Renko-Bars, was die Effizienz des gesamten Systems erhöht.

Das Herzstück des Systems ist das Modul zur Erzeugung von Merkmalen und zum Training des Modells. Hier wird jede Renko-Bar in eine Reihe von numerischen Merkmalen umgewandelt, die dann in den CatBoost-Algorithmus eingespeist werden. Die Auswahl der optimalen Modellparameter erfolgt durch Kreuzvalidierung, wobei die Besonderheiten von Finanzzeitreihen berücksichtigt werden.
Schließlich erstellt das Prognosemodul auf der Grundlage des trainierten Modells und der aktuellen Daten eine Prognose und erzeugt bei Erreichen einer bestimmten Konfidenzschwelle ein Handelssignal.
Das gesamte System ist in Python geschrieben und verwendet die Bibliotheken numpy, pandas, MetaTrader 5 und catboost. Die Wahl von Python ist nicht nur auf die einfache Entwicklung zurückzuführen, sondern auch auf die vielfältigen Möglichkeiten zur Datenanalyse und Visualisierung der Ergebnisse.
Schlussfolgerungen und Aussichten: Die Zukunft des algorithmischen Handels
Nachdem ich das Prognosesystem für Renko-Bars entwickelt und getestet hatte, kam ich zu mehreren wichtigen Schlussfolgerungen, die Ihre Sichtweise auf den algorithmischen Handel verändern könnten.
Erstens sind die klassischen Methoden der technischen Analyse den modernen Algorithmen des maschinellen Lernens in ihrer Effizienz unterlegen. Eine Genauigkeit von 59,27 % mag nicht beeindruckend klingen, aber sie übertrifft die meisten technischen Indikatoren über lange Zeiträume hinweg.
Zweitens erwiesen sich die Volumenindikatoren bei der Prognose von Marktbewegungen als wesentlich wichtiger als die Kursmuster. Dies widerspricht vielen klassischen Handelslehrbüchern, wird aber durch die Ergebnisse von Simulationen auf realen Daten bestätigt.
Drittens entfernen Renko-Charts das Rauschen aus den Kursdaten und ermöglichen es den Algorithmen des maschinellen Lernens, konsistentere Muster in den Marktbewegungen zu erkennen.
Aber das Wichtigste ist, dass dies erst der Anfang ist. Ich sehe ein großes Potenzial für die weitere Entwicklung des Systems. Künftig ließen sich zudem Fundamentaldaten, Nachrichtenereignisse und Stimmungsanalysen aus sozialen Medien integrieren. Eine Ausweitung auf andere Instrumente und Zeiträume kann ebenfalls in Betracht gezogen werden. Es könnte ein Ensemble von Modellen erstellt werden, um die Prognosegenauigkeit zu verbessern.
Schlussfolgerung
Die Welt des algorithmischen Handels steht vor einer neuen Revolution, und die Kombination von Renko-Charts mit modernen Algorithmen des maschinellen Lernens könnte einer der Treiber sein. Ich lade alle, die sich für dieses Thema interessieren, ein, in die Welt der Daten, Algorithmen und Prognosen einzutauchen. Die Zukunft des Handels ist da – und sie ist algorithmisch.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17531
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Sie können nicht mehr als 63 Prozent bekommen. Welche Zeichen auch immer hinzugefügt werden. 63 für Forex ist ein Fiasko
Bei Midas (multimodular, wo viele Module ihre Signale zu einem einzigen Signal zusammenfassen) habe ich mehr als 75 % bekommen. Aber dann entsteht ein anderes Problem - Signale einmal im Monat und eine Hälfte))))Je zuverlässiger das Signal, desto seltener kommt es vor...Deshalb habe ich begonnen, über hohe Winrate in den letzten Roboter zu vergessen, ich versuche, die Tiefe der Bewegungen vorherzusagen, um das Risiko zu nehmen, in 1:3, 1:4, etc. zu profitieren. Ich habe die Markierungen so eingerichtet, dass sie den Modellen durch DQN Boni für die korrekte Markierung von tiefen Bewegungen geben....Das führte schließlich zum Roboter LSTM Europe.
Ich habe über 75% auf Midas (multi-modular, wo viele Module kombinieren ihre Signale in ein einziges Signal). Aber dann entsteht ein anderes Problem - Signale einmal pro Monat und eine Hälfte))))Je zuverlässiger das Signal, desto seltener tritt es auf...Deshalb habe ich begonnen, über hohe Rentabilität in den letzten Robotern zu vergessen, ich versuche, die Tiefe der Bewegungen vorherzusagen, um das Risiko einzugehen, in 1:3, 1:4, etc. zu profitieren. Ich habe Marken in einer Weise, dass sie geben Boni für Modelle durch DQN für die korrekte Kennzeichnung von tiefen Bewegungen....Dies führte schließlich in den Roboter LSTM Europa.
75 auf LTSM bei lookback = 5 bars_ahead = 1, aber das ist für den Binärhandel, nicht für Forex.
Und wo ist die KI? Oder haben Sie Catbust in diesen Rang erhoben?
Sie sollten eine Art Test oder so etwas machen. 58% ist okay? Diese Genauigkeit ist nur ein Richtwert. Der Hauptindikator ist die Bilanz des Tests auf der Grundlage der empfangenen Signale.
Das ist uninteressant.