
Indicador de pronóstico ARIMA en MQL5

Los meteorólogos no leen las hojas de té cuando hacen pronósticos del tiempo: analizan lo que ocurrió en el pasado para entender lo que sucederá mañana. El modelo ARIMA funciona de forma similar, pero en lugar de nubes y presión, estudia los precios en los mercados financieros.
ARIMA significa Modelo de Media Móvil Integrada Autorregresiva. Suena imponente, pero en realidad es un sistema bastante lógico. Imagínese que está intentando predecir cuánto costará el par EUR/USD mañana basándose en su rendimiento en los últimos días.
Los tres pilares del modelo ARIMA
Autorregresión (AR) - memoria del pasado
La primera parte del modelo se llama autorregresión. Esta hermosa palabra significa algo simple: el precio de hoy depende del de ayer, del de anteayer, y así sucesivamente. Es como si el mercado recordara su pasado y construyera el futuro usándolo como base.
Si el EUR/USD ha subido durante tres días seguidos, existe la posibilidad de que suba también mañana; no necesariamente, pero la tendencia puede continuar. La parte autorregresiva del modelo capta estos patrones analizando cuánto influyen los valores pasados en el presente.
Los cálculos en términos simples: imagine que tiene el tipo de cambio EUR/USD de los últimos cinco días: 1.0800, 1.0825, 1.0850, 1.0875, 1.0900. La autorregresión dice: “Mire, cada día la tasa ha crecido unos 25 puntos (0,0025), lo que significa que mañana estará alrededor de 1,0925”. El modelo encuentra coeficientes (números que muestran en qué medida el precio de ayer influye en el precio de hoy, el precio de anteayer influye en el precio de hoy, y así sucesivamente).
La fórmula se parece a esto: precio_de_mañana = 0,7 × precio_de_hoy + 0,2 × precio_de_ayer + 0,1 × precio_del_día_anteayer. El modelo selecciona estos coeficientes 0,7, 0,2, 0,1 mediante el análisis de la historia. Cuanto mayor sea el coeficiente, mayor será la influencia de ese día en el pronóstico.
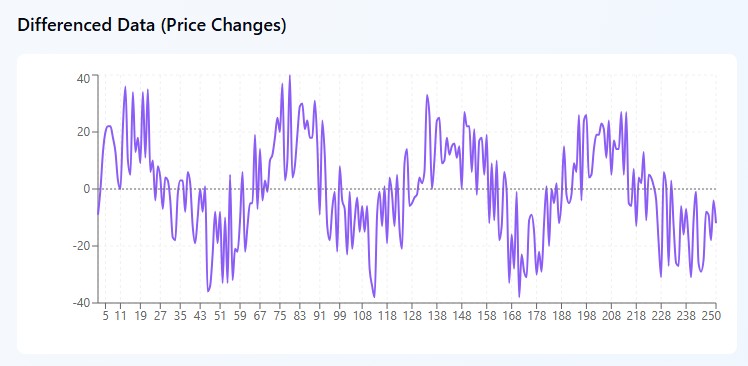
Integración (I) - domando el caos
Imagínese mirar el gráfico EUR/USD y ver un completo desastre: 1.0800, 1.0850, 1.0820, 1.0880, 1.0860. El precio salta de un lado a otro sin control: a primera vista no hay lógica. Este es exactamente el tipo de datos que los matemáticos llaman no estacionarios y los traders llaman un dolor de cabeza.
Pero aquí está el truco: en lugar de intentar encontrar significado en los precios mismos, ARIMA hace un movimiento inteligente. No se fija en cuánto vale un par de divisas, sino en cuánto ha cambiado en un día. Tomamos los mismos números y calculamos las diferencias: +50 puntos, -30 puntos, +60 puntos, -20 puntos. ¡Y de repente el caos se convierte en patrón! El mercado fluctúa entre una subida de 50-60 puntos y una caída de 20-30 puntos.
Es como si no prestáramos atención a dónde estaba el péndulo, sino solo a en qué dirección y con qué fuerza se balanceaba. Matemáticamente, es simple: tomamos el precio de hoy, le restamos el de ayer y obtenemos el cambio. A veces es necesario ir más allá y realizar el “cambio en los cambios”, es decir, la diferenciación de segundo orden. Suena muy serio, pero el principio sigue siendo el mismo: buscamos patrones donde, a primera vista, no los hay.
Media Móvil (MA): aprendiendo de los errores
Y ahora lo más interesante es que el modelo puede aprender de sus propios errores. Suena a ciencia ficción, pero la lógica es sólida. Cuando ARIMA predijo ayer que el EUR/USD estaría en 1,0800 y en realidad se negociaba en 1,0825, ese error de 25 pips fue más que una desafortunada inexactitud. ¡Es información!
Imagínese a un amigo que siempre llega exactamente 10 minutos tarde. Cuando dice "estaré allí a las seis", ya sabe que realmente serán las 6:10. El modelo hace lo mismo con sus errores. Si predice un precio 10 puntos más bajo que el precio real durante tres días seguidos, recuerda estos errores y mentalmente agrega lo siguiente la próxima vez: "Normalmente subestimo en 10 puntos, esto significa que el pronóstico necesita ser ajustado".
La fórmula podría verse así: "Corrección = 0,5 × error de ayer + 0,3 × error de anteayer." El modelo no solo comete errores: comete errores inteligentes y aprovecha cada paso en falso.
Cómo ARIMA usa la psicología del mercado
Inercia del movimiento
Los mercados tienen inercia. Si el EUR/USD sube durante varios días seguidos, todo el mundo quiere comprarlo, lo cual empuja el precio aún más arriba. ARIMA capta precisamente esta inercia.
En la práctica, el tipo de cambio crece durante cinco días desde 1,0800 hasta 1,0900 (+20 puntos diarios). El modelo da mucho peso a los últimos días y predice una continuación de la tendencia.
Reversión a la media
Al mismo tiempo, los mercados tienden a alcanzar un nivel, por así decirlo, "justo". Si el precio se ha desviado fuertemente en una dirección, tarde o temprano intentará regresar.
Ejemplo: El EUR/USD normalmente cotiza en el rango de 1,0800-1,0900. Si salta a 1,1000 debido a una noticia, el modelo considerará a través del componente de media móvil que ese tipo de movimientos extremos suelen corregirse.
Patrones cíclicos
Muchos pares de divisas exhiben un comportamiento cíclico: patrones semanales, mensuales o estacionales. ARIMA puede captarlos si lo configuramos correctamente.
Desventajas del modelo: cuando ARIMA no funciona
ARIMA no es el Santo Grial. Se basa en el supuesto de que el futuro es similar al pasado. Cuando se infringe este supuesto, el modelo genera predicciones inexactas.
El modelo no funciona bien cuando:
- Salen noticias económicas inesperadas
- La política monetaria de los bancos centrales cambia
- Se producen crisis geopolíticas
- El mercado entra en un nuevo modo (por ejemplo, pasa de una tendencia a un movimiento plano)
ARIMA funciona mejor en:
- Condiciones de mercado estables
- Periodos sin fuertes cambios fundamentales
- En instrumentos con patrones técnicos bien definidos
Implementación práctica en MQL5
Crear un indicador ARIMA funcional es más que solo fórmulas. Se necesita una arquitectura bien pensada que pueda gestionar el procesamiento de datos en tiempo real.
En el corazón del indicador hay un módulo que estima los coeficientes del modelo. Este utiliza el método de máxima verosimilitud: parece complicado, pero es simplemente una forma de encontrar los parámetros en los que el modelo explica mejor los datos observados.
La estructura de datos del indicador incluye varios búferes interconectados: el búfer principal de valores de pronóstico ForecastBuffer, un búfer auxiliar de precios históricos PriceBuffer y un búfer de error ErrorBuffer para almacenar residuos del modelo. Esta organización garantiza un uso óptimo de la memoria y una alta velocidad de procesamiento.
La inicialización del sistema implica la creación de matrices dinámicas para almacenar los datos de precios iniciales, las series diferenciadas, los coeficientes autorregresivos y de media móvil y el array residual. Los valores iniciales de los coeficientes se establecen en 0,1, lo cual garantiza la estabilidad del algoritmo de optimización en la etapa inicial.
int OnInit() { // Setting indicator buffers for visualizing results SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); SetIndexBuffer(1, PriceBuffer, INDICATOR_CALCULATIONS); SetIndexBuffer(2, ErrorBuffer, INDICATOR_CALCULATIONS); // Setting time series mode for correct operation with historical data ArraySetAsSeries(ForecastBuffer, true); ArraySetAsSeries(PriceBuffer, true); ArraySetAsSeries(ErrorBuffer, true); // Configuring forecast display with corresponding time shift PlotIndexSetString(0, PLOT_LABEL, "ARIMA Forecast"); PlotIndexSetInteger(0, PLOT_SHIFT, forecast_bars); // Initializing working arrays with predefined sizes ArrayResize(prices, lookback); ArrayResize(differenced, lookback); ArrayResize(ar_coeffs, p); ArrayResize(ma_coeffs, q); ArrayResize(errors, lookback); // Setting initial values of model coefficients for(int i = 0; i < p; i++) ar_coeffs[i] = 0.1; for(int i = 0; i < q; i++) ma_coeffs[i] = 0.1; return(INIT_SUCCEEDED); }
Parámetros de entrada del modelo
El indicador se configura a través de un sistema de parámetros de entrada, cada uno de los cuales juega un papel crítico en la determinación del comportamiento del modelo. El parámetro lookback determina la cantidad de datos históricos usados para entrenar el modelo, el parámetro forecast_bars especifica el horizonte de pronóstico y el triple de parámetros p, d, q determina la especificación del modelo ARIMA.
//--- Input parameters of model configuration input int lookback = 200; // Lookback period for ARIMA input int forecast_bars = 20; // Number of forecast time intervals input int p = 3; // Order of autoregressive component input int d = 1; // Degree of differentiation of a time series input int q = 2; // Order of moving average component input double learning_rate = 0.01; // Learning rate coefficient input int max_iterations = 100; // Maximum number of optimization iterations
Metodología para la estimación de parámetros del modelo
El elemento central del algoritmo es una función para calcular la función de verosimilitud logarítmica, que sirve como criterio para la calidad del ajuste del modelo a los datos observados. La implementación de esta función se basa en el supuesto de una distribución normal de los residuos del modelo, lo cual permite el uso de una expresión analítica para la densidad de probabilidad.
Función de verosimilitud y cálculo de residuos
El algoritmo para calcular la función de verosimilitud logarítmica es un proceso iterativo en el que, para cada punto temporal, los residuos del modelo se calculan como la diferencia entre el valor observado y el pronóstico del modelo. El componente autorregresivo se forma como una combinación lineal de los valores anteriores de las series diferenciadas, mientras que el componente de media móvil usa los valores anteriores de los errores del modelo.
double ComputeLogLikelihood(double &data[], double &ar[], double &ma[]) { double ll = 0.0; double residuals[]; ArrayResize(residuals, lookback); ArrayInitialize(residuals, 0.0); // Iterative calculation of model residuals for(int i = p; i < lookback; i++) { double ar_part = 0.0; double ma_part = 0.0; // Forming autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar[j] * data[i - j - 1]; // Forming moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma[j] * errors[i - j - 1]; // Calculating residuals and updating the error array residuals[i] = data[i] - (ar_part + ma_part); errors[i] = residuals[i]; // Accumulating log-likelihood function ll -= 0.5 * MathLog(2 * M_PI) + 0.5 * residuals[i] * residuals[i]; } return ll; }
Procedimiento de optimización de coeficientes
El procedimiento de optimización de coeficientes se implementa usando el método de descenso de gradiente con tamaño de paso adaptativo. El algoritmo actualiza iterativamente los valores de los coeficientes en la dirección opuesta al gradiente de la función objetivo, asegurando la convergencia a un óptimo local de la función de verosimilitud.
void OptimizeCoefficients(double &data[]) { double temp_ar[], temp_ma[]; ArrayCopy(temp_ar, ar_coeffs); ArrayCopy(temp_ma, ma_coeffs); double best_ll = -DBL_MAX; double grad_ar[], grad_ma[]; ArrayResize(grad_ar, p); ArrayResize(grad_ma, q); // Iterative optimization process for(int iter = 0; iter < max_iterations; iter++) { ArrayInitialize(grad_ar, 0.0); ArrayInitialize(grad_ma, 0.0); // Calculating gradients of likelihood function for(int i = p; i < lookback; i++) { double ar_part = 0.0, ma_part = 0.0; // Forming model components for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += temp_ar[j] * data[i - j - 1]; for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += temp_ma[j] * errors[i - j - 1]; double residual = data[i] - (ar_part + ma_part); // Accumulating gradients by AR coefficients for(int j = 0; j < p && i - j - 1 >= 0; j++) grad_ar[j] += -residual * data[i - j - 1]; // Accumulating gradients by MA coefficients for(int j = 0; j < q && i - j - 1 >= 0; j++) grad_ma[j] += -residual * errors[i - j - 1]; } // Updating coefficients according to the gradient descent rule for(int j = 0; j < p; j++) temp_ar[j] += learning_rate * grad_ar[j] / lookback; for(int j = 0; j < q; j++) temp_ma[j] += learning_rate * grad_ma[j] / lookback; // Evaluating quality of current approximation double current_ll = ComputeLogLikelihood(data, temp_ar, temp_ma); // Stopping criterion and updating the optimal solution if(current_ll > best_ll) { best_ll = current_ll; ArrayCopy(ar_coeffs, temp_ar); ArrayCopy(ma_coeffs, temp_ma); } else { break; // Premature stop in the absence of improvement } } }
Se presta especial atención al cálculo de las derivadas parciales de la función de verosimilitud para cada uno de los parámetros optimizados. Los gradientes para los coeficientes autorregresivos se calculan como la suma de los productos de los residuos y los valores retrasados correspondientes de las series diferenciadas, mientras que los gradientes para los coeficientes de media móvil se determinan a través de los productos de los residuos y los valores de error anteriores.
Algoritmo para pronosticar e invertir la diferenciación
La generación de valores de pronóstico se realiza de forma recursiva, a partir del último valor observado de la serie temporal. En cada paso del pronóstico, el componente autorregresivo se calcula como una combinación lineal de los valores anteriores de las series diferenciadas con los coeficientes correspondientes. El componente de media móvil se forma de manera similar, a través de una suma ponderada de los residuos del modelo anterior.
Procedimiento básico de cálculo
La función central OnCalculate representa el núcleo del proceso computacional, integrando todos los componentes del algoritmo en un único flujo de procesamiento de datos. La función efectúa el procesamiento secuencial de los datos entrantes del mercado, la aplicación del procedimiento de diferenciación, la optimización de los parámetros del modelo y la generación de valores de pronóstico.
int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { ArraySetAsSeries(close, true); ArraySetAsSeries(time, true); // Checking sufficiency of historical data if(rates_total < lookback + forecast_bars) return(0); // Forming array of closing prices for(int i = 0; i < lookback; i++) { prices[i] = close[i]; PriceBuffer[i] = close[i]; } // Applying differentiation procedure for(int i = 0; i < lookback - d; i++) { if(d == 1) differenced[i] = prices[i] - prices[i + 1]; else if(d == 2) differenced[i] = (prices[i] - prices[i + 1]) - (prices[i + 1] - prices[i + 2]); else differenced[i] = prices[i]; } // Optimizing AR and MA coefficients ArrayInitialize(errors, 0.0); OptimizeCoefficients(differenced); // Generating ARIMA forecast double forecast[]; ArrayResize(forecast, forecast_bars); double undiff[]; ArrayResize(undiff, forecast_bars); // Initializing forecasting process forecast[0] = prices[0]; undiff[0] = prices[0]; // Iterative forecast generation for(int i = 1; i < forecast_bars; i++) { double ar_part = 0.0; double ma_part = 0.0; // Calculating autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar_coeffs[j] * (j < lookback ? differenced[j] : forecast[i - j - 1]); // Calculating moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma_coeffs[j] * errors[j]; // Forming forecast value forecast[i] = ar_part + ma_part; // Procedure of reversal of differentiation if(d == 1) undiff[i] = undiff[i - 1] + forecast[i]; else if(d == 2) undiff[i] = undiff[i - 1] + (undiff[i - 1] - (i >= 2 ? undiff[i - 2] : prices[1])) + forecast[i]; else undiff[i] = forecast[i]; // Updating error array for following iterations errors[i % lookback] = forecast[i] - (i < lookback ? differenced[i] : 0.0); } // Filling output buffer with forecast values for(int i = 0; i < forecast_bars; i++) { ForecastBuffer[i] = undiff[i]; } // Extending historical data for continuous display for(int i = forecast_bars; i < lookback; i++) { ForecastBuffer[i] = prices[i - forecast_bars]; } return(rates_total); }
El procedimiento de inversión es un paso crítico para garantizar que la escala original de los valores predichos se restaure como es debido. Para el caso de diferenciación de primer orden, cada valor predicho se obtiene sumando el valor indiferenciado anterior con el pronóstico de primera diferencia correspondiente. Al usar la diferenciación de segundo orden, se aplica una fórmula recursiva más compleja que considera la curvatura de la serie temporal.
Aspectos computacionales y optimización del rendimiento
La eficiencia del algoritmo está determinada en gran medida por la correcta organización del proceso computacional y el uso óptimo de los recursos del procesador. La función principal OnCalculate se ha estructurado para minimizar la cantidad de cálculos redundantes cuando llegan nuevos datos del mercado.
El procedimiento de diferenciación se implementa considerando diferentes órdenes de transformación. Para la diferenciación de primer orden, se calcula una diferencia simple entre observaciones adyacentes, mientras que para la diferenciación de segundo orden, se usa una fórmula de segunda diferencia para eliminar no solo la tendencia sino también los cambios en la tasa de tendencia.
Un aspecto crítico de la implementación es la gestión de la memoria y el manejo correcto de matrices de longitud variable. El uso de las funciones ArrayResize y ArraySetAsSeries garantiza que la estructura de datos se adapte a los parámetros cambiantes del modelo y a las características de organización de datos en MetaTrader 5.
Calibración de parámetros y adaptación a las condiciones del mercado
La aplicación exitosa del modelo ARIMA en condiciones comerciales reales requiere una calibración cuidadosa de los parámetros, teniendo en cuenta las características concretas de un instrumento financiero particular y el horizonte temporal del análisis. El parámetro lookback determina la profundidad del análisis histórico y debe ser suficiente para garantizar la significación estadística de las estimaciones, pero no tan grande como para incluir información obsoleta.
La elección de los órdenes p, d y q del modelo supone un equilibrio entre la precisión de la descripción de los datos y la complejidad computacional. Aumentar el orden de autorregresión p nos permite considerar dependencias temporales más complejas; sin embargo, una complejidad excesiva del modelo puede conducir a un sobreajuste y a una disminución de la calidad del pronóstico en nuevos datos.
El parámetro de tasa de aprendizaje learning_rate necesita un ajuste especialmente cuidadoso, ya que un valor demasiado grande puede provocar oscilaciones en el algoritmo de optimización, mientras que un valor demasiado pequeño ralentiza la convergencia hacia el óptimo.
Validación estadística y evaluación de la calidad de los pronósticos
Una evaluación objetiva de la calidad del rendimiento del indicador requiere el uso de un conjunto de criterios estadísticos que permitan una caracterización cuantitativa de la precisión del pronóstico. Entre las métricas más informativas cabe destacar el error absoluto medio, el error cuadrático medio y el coeficiente de determinación.
Métricas de calidad del pronóstico
La implementación de funciones de evaluación de la calidad del pronóstico permite el análisis cuantitativo del rendimiento del modelo y la comparación de diferentes especificaciones ARIMA. El error absoluto medio ofrece una medida intuitiva de la desviación de los pronósticos respecto de los valores reales, expresada en unidades de la serie temporal original.
// Function of calculating average absolute error double CalculateMAE(double &actual[], double &predicted[], int size) { double mae = 0.0; for(int i = 0; i < size; i++) { mae += MathAbs(actual[i] - predicted[i]); } return mae / size; } // Function of calculating the root mean square error double CalculateRMSE(double &actual[], double &predicted[], int size) { double mse = 0.0; for(int i = 0; i < size; i++) { double error = actual[i] - predicted[i]; mse += error * error; } return MathSqrt(mse / size); } // Determination coefficient calculation function double CalculateR2(double &actual[], double &predicted[], int size) { double actual_mean = 0.0; for(int i = 0; i < size; i++) actual_mean += actual[i]; actual_mean /= size; double ss_tot = 0.0, ss_res = 0.0; for(int i = 0; i < size; i++) { ss_tot += (actual[i] - actual_mean) * (actual[i] - actual_mean); ss_res += (actual[i] - predicted[i]) * (actual[i] - predicted[i]); } return 1.0 - (ss_res / ss_tot); }
Diagnóstico de residuos del modelo
El análisis de los residuos del modelo supone un aspecto crítico de la validación que permite la identificación de desviaciones sistemáticas de los supuestos del modelo. La prueba de Ljung-Box para la autocorrelación de residuos ofrece una verificación de la adecuación de la especificación del modelo, mientras que la prueba de Jarque-Bera permite evaluar la normalidad de la distribución de residuos.
// Function for calculating autocorrelation function of the residuals double CalculateAutocorrelation(double &residuals[], int lag, int size) { double mean = 0.0; for(int i = 0; i < size; i++) mean += residuals[i]; mean /= size; double numerator = 0.0, denominator = 0.0; for(int i = lag; i < size; i++) { numerator += (residuals[i] - mean) * (residuals[i - lag] - mean); } for(int i = 0; i < size; i++) { denominator += (residuals[i] - mean) * (residuals[i] - mean); } return numerator / denominator; } // Ljung-Box statistic for testing autocorrelation double LjungBoxTest(double &residuals[], int max_lag, int size) { double lb_stat = 0.0; for(int k = 1; k <= max_lag; k++) { double rho_k = CalculateAutocorrelation(residuals, k, size); lb_stat += (rho_k * rho_k) / (size - k); } return size * (size + 2) * lb_stat; }
El procedimiento de validación cruzada nos permite evaluar la robustez del modelo ante cambios en la composición de la muestra de entrenamiento. El método de ventana deslizante hace posible una evaluación más realista de la calidad del pronóstico en condiciones cercanas a las del comercio real, cuando el modelo se aplica sucesivamente a nuevos datos sin revisar los parámetros.
El análisis de los residuos del modelo proporciona información importante sobre la idoneidad de los supuestos del modelo para las características de los datos reales. Las pruebas de autocorrelación de residuos permiten identificar dependencias temporales no consideradas, mientras que las pruebas de normalidad de distribución de residuos comprueban la exactitud del modelo estadístico utilizado.
El resultado del indicador será un pronóstico para el periodo especificado:
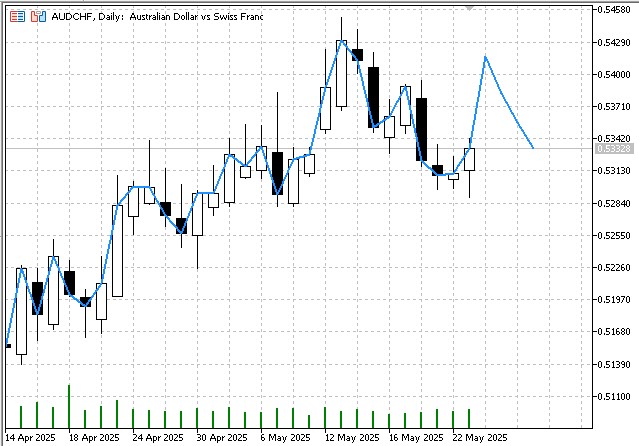
Perspectivas de desarrollo y modificación del algoritmo
La investigación moderna en el campo del análisis de series temporales financieras descubre amplias oportunidades para el desarrollo del modelo ARIMA básico. La inclusión de componentes estacionales en el modelo SARIMA nos permite considerar los patrones cíclicos característicos de muchos instrumentos financieros. Los métodos de regularización, como la penalización L1 y L2, pueden mejorar la robustez del modelo ante valores atípicos y evitar el sobreajuste.
Las modificaciones adaptativas del algoritmo, que implican cambios dinámicos en los parámetros del modelo dependiendo de las condiciones actuales del mercado, resultan de particular interés para el trading de alta frecuencia. La integración de métodos de aprendizaje automático puede posibilitar la selección automática de la especificación óptima del modelo sin la participación de un analista.
Las extensiones multidimensionales del modelo ARIMA abren posibilidades para el modelado simultáneo de varios instrumentos financieros interrelacionados, lo cual resulta particularmente relevante para la gestión de carteras y estrategias de arbitraje.
Reflexiones finales
La implementación presentada del indicador ARIMA en el entorno MQL5 demuestra la posibilidad de adaptar con éxito los métodos econométricos clásicos a las tareas de trading algorítmico. La estricta adhesión a la metodología estadística combinada con la implementación eficiente del software garantiza la creación de una herramienta fiable para el análisis de series temporales financieras.
La aplicación práctica del indicador requiere una comprensión profunda tanto de los fundamentos matemáticos del modelo como de las características específicas del mercado en el que se aplica. El modelo funciona claramente peor en sistemas con tendencias inestables.
Traducción del ruso hecha por MetaQuotes Ltd.
Artículo original: https://www.mql5.com/ru/articles/18253
Advertencia: todos los derechos de estos materiales pertenecen a MetaQuotes Ltd. Queda totalmente prohibido el copiado total o parcial.
Este artículo ha sido escrito por un usuario del sitio web y refleja su punto de vista personal. MetaQuotes Ltd. no se responsabiliza de la exactitud de la información ofrecida, ni de las posibles consecuencias del uso de las soluciones, estrategias o recomendaciones descritas.

- Aplicaciones de trading gratuitas
- 8 000+ señales para copiar
- Noticias económicas para analizar los mercados financieros
Usted acepta la política del sitio web y las condiciones de uso
¿Dónde está la parte diferencial?
Combinando Renko y Arima debería ser más estable.
Sí, yo también lo uso.