
Winkelanalyse von Preisbewegungen: Ein hybrides Modell zur Prognose von Finanzmärkten

Stellen Sie sich einen erfahrenen Bergsteiger vor, der am Fuße eines Berges steht und dessen Hänge sorgfältig studiert, bevor er sich an den Aufstieg macht. Was kann er sehen? Nicht nur ein chaotisches Durcheinander von Felsen und Felsvorsprüngen, sondern auch die Geometrie der Route – Aufstiegswinkel, Steilheit der Hänge, Kurven der Grate. Diese geometrischen Merkmale des Geländes bestimmen, wie schwierig der Weg zum Gipfel sein wird.
Die Welt der Finanzmärkte ähnelt in bemerkenswerter Weise einer Berglandschaft. Die Preischarts erschaffen ihr eigenes Terrain mit Gipfeln, Tälern, sanften Hängen und steilen Klippen. Und so wie ein Bergsteiger einen Berg an seiner Geometrie abliest, spürt ein erfahrener Händler intuitiv die Aussagekraft der Winkel von Preisbewegungen. Was aber, wenn diese Intuition in eine exakte Wissenschaft verwandelt werden könnte? Was wäre, wenn die Winkel der Preisbewegungen nicht nur visuelle Muster sind, sondern mathematisch signifikante Indikatoren für die Zukunft?
In der ruhigen Arbeitsumgebung eines Algo-Traders, weit weg vom Lärm der Handelsplattformen, stellte ich mir genau diese Frage. Und die Antwort war so faszinierend, dass sie mein Verständnis von der Natur der Märkte veränderte.
Die Anatomie der Preisbewegung
Tausende von Kerzen werden jeden Tag auf den Charts von Währungspaaren, Aktien und Futures geboren. Sie bilden Muster, bilden Trends und schaffen Widerstände und Unterstützungen. Doch hinter diesen vertrauten Bildern verbirgt sich ein mathematisches Gebilde, das wir nur selten wahrnehmen, nämlich die Winkel zwischen aufeinanderfolgenden Preispunkten.
Werfen Sie einen Blick auf das übliche EURUSD-Chart. Was können Sie sehen? Linien und Bars? Stellen Sie sich nun vor, dass jedes Segment zwischen zwei aufeinanderfolgenden Punkten einen bestimmten Winkel mit der horizontalen Achse bildet. Dieser Winkel hat einen exakten mathematischen Wert. Ein positiver Winkel bedeutet eine Aufwärtsbewegung, ein negativer Winkel eine Abwärtsbewegung. Je größer der Winkel ist, desto steiler ist die Preisbewegung.
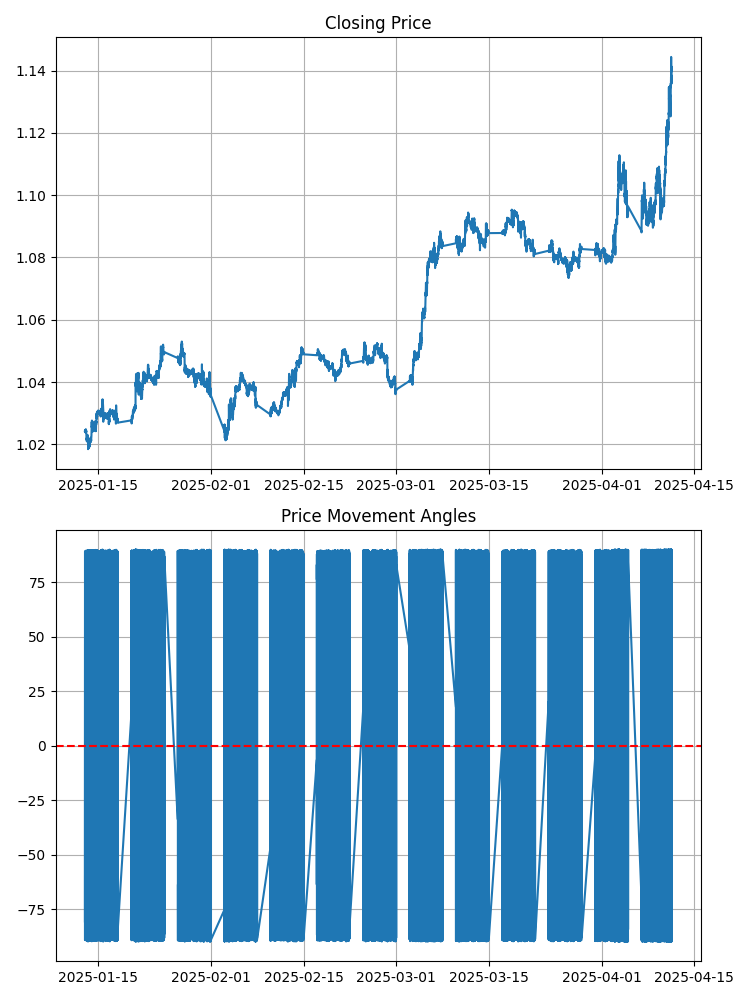
Klingt einfach? Doch hinter dieser Einfachheit verbirgt sich eine erstaunliche Tiefe. Denn die Winkel sind nicht gleich. Sie bilden ihr eigenes Muster, ihre eigene Melodie. Und diese Melodie enthält, wie sich herausstellt, den Schlüssel zur künftigen Marktbewegung.
Händler untersuchen seit Jahrzehnten die Steigung von Trendlinien, aber dies ist nur eine grobe Schätzung. Dabei geht es um präzise mathematische Winkel zwischen jeweils zwei aufeinanderfolgenden Preispunkten. Das ist wie der Unterschied zwischen einer groben Skizze eines Berges und einer detaillierten topografischen Abbildung mit den genauen Winkeln der einzelnen Hänge.
Gann-Winkelanalyse: Von Klassikern zu Innovationen
Die Idee der Verwendung von Winkeln zur Analyse von Preisbewegungen ist nicht neu. Sie geht auf die Arbeiten des legendären Händlers und Analysten William Delbert Gann zurück. Bereits Anfang des 20. Jahrhunderts schlug er sein System der Winkelanalyse für die Finanzmärkte vor. Wir haben hier einen Indikator erstellt, der darauf basiert.
Das Konzept von Gann begegnete mir zum ersten Mal vor vielen Jahren beim Studium klassischer Werke zur technischen Analyse. Die Idee selbst hat mich fasziniert: Gann vertrat die Ansicht, dass es eine mathematische Beziehung zwischen Preis und Zeit gibt, die durch die Steigung spezieller Linien auf dem Chart ausgedrückt werden kann. Er glaubte, dass diese Winkel eine fast mystische Vorhersagekraft haben, und entwickelte ein ganzes System von „Gann-Winkeln“: Linien, die in bestimmten Winkeln von wichtigen Punkten auf dem Chart gezogen werden.
Der klassische Ansatz von Gann hatte jedoch zwei wesentliche Nachteile. Erstens war er zu subjektiv: Verschiedene Analysten konnten dieselben Winkelkonstruktionen völlig unterschiedlich interpretieren. Zweitens war sein System für Papiercharts mit einem bestimmten Maßstab konzipiert, was seine Anwendung auf moderne digitale Analysen problematisch machte.
Ich konnte nicht umhin, mich zu fragen: Was wäre, wenn Gann mit seinem Grundkonzept richtig lag, aber einfach keinen Zugang zu modernen Computerwerkzeugen hatte? Was wäre, wenn seine Intuition über die Bedeutung von Winkeln richtig ist, aber einen anderen, strengeren mathematischen Ansatz erfordert?
Die Inspiration kam unerwartet, als ich eine Dokumentation über Teilchenphysik sah. Die Wissenschaftler analysierten die Trajektorien von Elementarteilchen, indem sie deren Ablenkungswinkel nach Kollisionen maßen. Diese Winkel enthielten wichtige Informationen über die Eigenschaften von Teilchen und die zwischen ihnen wirkenden Kräfte.
Und dann dämmerte es mir: Die Preisbewegungen auf dem Markt sind auch eine Art Trajektorie, ein Ergebnis des „Zusammenstoßes“ der Marktkräfte! Was wäre, wenn wir, anstatt subjektiv Gann-Linien zu zeichnen, den Winkel zwischen zwei aufeinanderfolgenden Punkten auf einem Preischart genau messen würden? Was wäre, wenn wir daraus mithilfe des maschinellen Lernens eine strenge mathematische Analyse machen würden?
Im Gegensatz zum klassischen Gann-Ansatz, bei dem die Winkel von einigen signifikanten Punkten aus gemessen werden, habe ich mich entschieden, den Winkel zwischen jeweils zwei aufeinanderfolgenden Preispunkten zu messen. So erhalten wir einen kontinuierlichen Strom von Winkeldaten, eine Art „Kardiogramm“ des Marktes. Es war von entscheidender Bedeutung, das Skalierungsproblem zu lösen, da die Zeitachse und die Preisachse im Chart unterschiedliche Maßeinheiten haben.
Die Lösung bestand darin, die Achsen zu normalisieren und sie auf vergleichbare Maßstäbe zu bringen, wobei der Änderungsbereich der einzelnen Variablen berücksichtigt wurde. Dies ermöglichte es uns, mathematisch korrekte Winkel zu erhalten, unabhängig von den absoluten Preiswerten oder dem Zeitintervall.
Im Gegensatz zu Gann, der seine Analyse auf geometrische Konstruktionen und Intuition stützte, beschloss ich, mich auf objektive mathematische Methoden und maschinelle Lernalgorithmen zu stützen. Anstatt nach „magischen“ Winkeln von 45° oder 26,25° (Ganns Lieblingswinkel) zu suchen, lassen wir den Algorithmus bestimmen, welche Winkelmuster für die Vorhersage künftiger Bewegungen am aussagekräftigsten sind.
Interessanterweise hat die Analyse der Ergebnisse gezeigt, dass einige der vom Algorithmus identifizierten Muster tatsächlich Ganns Beobachtungen widerspiegeln, dass sie aber auch eine strenge mathematische Form und statistische Bestätigung erhalten. So legte Gann beispielsweise besonderen Wert auf die 1:1 (45°)-Linie, und auch unser Modell zeigte, dass ein Wechsel des Winkelvorzeichens von Werten nahe Null zu positiven Werten nahe 45° oft einer starken Richtungsbewegung vorausgeht.
So entstand die in diesem Artikel beschriebene Methode der Winkelanalyse, die sich auf die klassischen Ideen von Gann stützt, diese aber durch die Brille der modernen Mathematik und des maschinellen Lernens neu interpretiert. Die philosophische Essenz von Ganns Ansatz, die Suche nach geometrischen Mustern am Schnittpunkt von Preis und Zeit, wird beibehalten. Die Methode verwandelt sie von einer Kunst in eine strenge Wissenschaft.
Vielleicht hätte sich Gann selbst darüber gefreut, dass sich seine Ideen mithilfe von Technologien entwickelt haben, die es zu seiner Zeit noch nicht gab. Wie Isaac Newton sagte: „Wenn ich weiter gesehen habe als andere, dann nur, weil ich auf den Schultern von Giganten stand.“ Unser modernes Analysesystem der Winkel führt diesen Ansatz weiter, wobei wir dem Giganten der technischen Analyse, der diesen Ansatz inspiriert hat, großen Dank schulden.
Der Tanz der Winkel
Mit einer Methode zur genauen Messung von Winkeln bewaffnet, gingen wir zum nächsten Meilenstein der Forschung über – der Beobachtung. Monatelang haben wir den Tanz der Winkel auf den EURUSD-Charts beobachtet und jede Bewegung, jede Wendung aufgezeichnet.
Und allmählich begannen sich aus dem Datenchaos Muster herauszukristallisieren. Die Winkel haben sich nicht zufällig bewegt. Sie bildeten Sequenzen, die bestimmten Preisbewegungen immer wieder vorausgingen. Wir haben festgestellt, dass vor einem signifikanten Preisanstieg häufig eine bestimmte Abfolge von Winkeln zu beobachten war – zunächst kleine negative, dann neutrale und schließlich eine Reihe positiver Winkel mit zunehmender Amplitude.
Es erinnerte mich an ein Kinderspielzeug, einen Kreisel. Bevor er nach oben schießt, schwankt er zunächst leicht, als ob er seine Kräfte sammelt. Der Markt scheint nach dem gleichen Prinzip zu funktionieren. Vor einer starken Bewegung „schwankt“ er gewissermaßen und bildet dabei eine charakteristische Winkelabfolge.
Doch Beobachtungen, so faszinierend sie auch sein mögen, reichen nicht aus, um eine zuverlässige Handelsstrategie zu entwickeln. Wir mussten unsere Vermutungen mit mathematischer Präzision bestätigen. Hier kommt das maschinelle Lernen ins Spiel, unser treuer Helfer beim Entschlüsseln komplexer Muster.
Von der Idee zum Code: Erstellen eines Winkelanalysators
Theorie ist eine gute Sache, aber ohne praktische Umsetzung bleiben es nur schöne Worte. Zunächst mussten wir uns Marktdaten beschaffen und lernen, mit ihnen zu arbeiten. Als Werkzeug haben wir Python und die MetaTrader 5-Bibliothek gewählt, die es uns ermöglicht, Daten direkt vom Handelsterminal abzurufen.
Hier ist der Code, der den Preisverlauf lädt:
import MetaTrader5 as mt5 from datetime import datetime, timedelta import pandas as pd import numpy as np import math def get_mt5_data(symbol='EURUSD', timeframe=mt5.TIMEFRAME_M5, days=60): if not mt5.initialize(): print(f"Initialization error MT5: {mt5.last_error()}") return None # Determine period for downloading data start_date = datetime.now() - timedelta(days=days) rates = mt5.copy_rates_range(symbol, timeframe, start_date, datetime.now()) mt5.shutdown() # Transform data into convenient format df = pd.DataFrame(rates) df['time'] = pd.to_datetime(df['time'], unit='s') return df
Dieser kleine Codeabschnitt ist Ihre Eintrittskarte in die Welt der Marktdaten. Er stellt eine Verbindung zum MetaTrader 5 her, lädt den Preisverlauf für eine bestimmte Anzahl von Tagen herunter und wandelt ihn in ein für die Analyse geeignetes Format um.
Nun müssen wir die Winkel zwischen den aufeinanderfolgenden Punkten berechnen. Hier stellt sich jedoch ein Problem: Wie kann man einen Winkel in einem Chart korrekt messen, in dem die Zeitachse und die Preisachse völlig unterschiedliche Skalen haben? Wenn Sie einfach die Koordinaten der Punkte verwenden, sind die Winkel bedeutungslos.
Die Lösung besteht darin, die Achsen zu normalisieren. Wir müssen die Zeit- und Preisskala auf ein vergleichbares Niveau bringen:
def calculate_angle(p1, p2): # p1 и p2 - tuples (time_normalized, price) x1, y1 = p1 x2, y2 = p2 # Handling vertical lines if x2 - x1 == 0: return 90 if y2 > y1 else -90 # Calculating an angle in radians and convert it to degrees angle_rad = math.atan2(y2 - y1, x2 - x1) angle_deg = math.degrees(angle_rad) return angle_deg def create_angular_features(df): # Create copy DataFrame angular_df = df.copy() # Normalizing time series for correct calculation of angles angular_df['time_num'] = (angular_df['time'] - angular_df['time'].min()).dt.total_seconds() # Find ranges for normalization time_range = angular_df['time_num'].max() - angular_df['time_num'].min() price_range = angular_df['close'].max() - angular_df['close'].min() # Normalization for comparable scales scale_factor = price_range / time_range angular_df['time_scaled'] = angular_df['time_num'] * scale_factor # Calculate angles between sequential points angles = [] angles.append(np.nan) # Angle not defined for the first point for i in range(1, len(angular_df)): current_point = (angular_df['time_scaled'].iloc[i], angular_df['close'].iloc[i]) prev_point = (angular_df['time_scaled'].iloc[i-1], angular_df['close'].iloc[i-1]) angle = calculate_angle(prev_point, current_point) angles.append(angle) angular_df['angle'] = angles return angular_df
Diese Funktionen sind das Herzstück unserer Methode. Der erste berechnet den Winkel zwischen zwei Punkten, der zweite bereitet die Daten auf und berechnet die Winkel für die gesamte Zeitreihe. Nach der Bearbeitung erhält jeder Punkt auf dem Chart seinen eigenen Winkel – ein mathematisches Merkmal der Preissteigung.
Wir interessieren uns nicht nur für die Vergangenheit, sondern auch für die Zukunft. Es ist wichtig zu verstehen, wie sich die Winkel auf die bevorstehende Preisbewegung beziehen. Dazu fügen Sie unserem DataFrame Informationen über zukünftige Preisänderungen hinzu:
def add_future_price_info(angular_df, prediction_period=24): # Add future price direction future_directions = [] for i in range(len(angular_df)): if i + prediction_period < len(angular_df): # 1 = growth, 0 = fall future_dir = 1 if angular_df['close'].iloc[i + prediction_period] > angular_df['close'].iloc[i] else 0 future_directions.append(future_dir) else: future_directions.append(np.nan) angular_df['future_direction'] = future_directions # Calculate magnitude of the future change (in percent) future_changes = [] for i in range(len(angular_df)): if i + prediction_period < len(angular_df): pct_change = (angular_df['close'].iloc[i + prediction_period] - angular_df['close'].iloc[i]) / angular_df['close'].iloc[i] * 100 future_changes.append(pct_change) else: future_changes.append(np.nan) angular_df['future_change_pct'] = future_changes return angular_df
Jetzt kennen wir für jeden Punkt im Chart nicht nur seinen Winkel, sondern auch, was mit dem Preis nach einer bestimmten Anzahl von Bars in der Zukunft geschehen wird. Dies ist ein idealer Datensatz für das Training eines maschinellen Lernmodells.
Aber ein Winkel ist nicht genug. Die Schlüsselrolle spielen die Winkelsequenzen – ihre Muster, Trends und statistischen Merkmale. Für jeden Punkt im Chart sollten wir eine Reihe von Merkmalen erstellen, die das Winkelverhalten beschreiben:
def prepare_features(angular_df, lookback=15): features = [] targets_class = [] # For classification (direction) targets_reg = [] # For regression (percent change) # Discard strings with NaN filtered_df = angular_df.dropna(subset=['angle', 'future_direction', 'future_change_pct']) # Check if there is enough data if len(filtered_df) <= lookback: print("Not enough data for analysis") return None, None, None for i in range(lookback, len(filtered_df)): # Get latest lookback of bars window = filtered_df.iloc[i-lookback:i] # Take last angles as a sequence feature_dict = { f'angle_{j}': window['angle'].iloc[j] for j in range(lookback) } # Add derivative characteristics of angles feature_dict.update({ 'angle_mean': window['angle'].mean(), 'angle_std': window['angle'].std(), 'angle_min': window['angle'].min(), 'angle_max': window['angle'].max(), 'angle_last': window['angle'].iloc[-1], 'angle_last_3_mean': window['angle'].iloc[-3:].mean(), 'angle_last_5_mean': window['angle'].iloc[-5:].mean(), 'angle_last_10_mean': window['angle'].iloc[-10:].mean(), 'positive_angles_ratio': (window['angle'] > 0).mean(), 'current_price': window['close'].iloc[-1], 'price_std': window['close'].std(), 'price_change_pct': (window['close'].iloc[-1] - window['close'].iloc[0]) / window['close'].iloc[0] * 100, 'high_low_range': (window['high'].max() - window['low'].min()) / window['close'].iloc[-1] * 100, 'last_tick_volume': window['tick_volume'].iloc[-1], 'avg_tick_volume': window['tick_volume'].mean(), 'tick_volume_ratio': window['tick_volume'].iloc[-1] / window['tick_volume'].mean() if window['tick_volume'].mean() > 0 else 1, }) features.append(feature_dict) targets_class.append(filtered_df.iloc[i]['future_direction']) targets_reg.append(filtered_df.iloc[i]['future_change_pct']) return pd.DataFrame(features), np.array(targets_class), np.array(targets_reg)
Diese Funktion verwandelt einfache Zeitreihen in einen umfangreichen Datensatz für maschinelles Lernen. Für jeden Punkt im Chart werden mehr als 30 Merkmale erstellt, die das Verhalten der Winkel in den letzten paar Bars charakterisieren. Dieses „Porträt“ der Winkelcharakteristika wird die Eingangsdaten für unsere Modelle sein.
Maschinelles Lernen enthüllt die Geheimnisse der Winkel
Jetzt, da wir die Daten und Merkmale haben, ist es an der Zeit, Modelle zu trainieren, die nach Mustern in den Daten suchen. Wir haben uns für die CatBoost-Bibliothek entschieden, einen modernen Gradient-Boosting-Algorithmus, der besonders gut mit Zeitreihen funktioniert.
Eine Besonderheit unseres Ansatzes ist, dass wir nicht ein, sondern zwei Modelle trainieren:
from catboost import CatBoostClassifier, CatBoostRegressor from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score, mean_squared_error def train_hybrid_model(X, y_class, y_reg, test_size=0.3): # Splitting data into training and test X_train, X_test, y_class_train, y_class_test, y_reg_train, y_reg_test = train_test_split( X, y_class, y_reg, test_size=test_size, random_state=42, shuffle=True ) # Parameters for classification model params_class = { 'iterations': 500, 'learning_rate': 0.03, 'depth': 6, 'loss_function': 'Logloss', 'random_seed': 42, 'verbose': False } # Parameters for regression model params_reg = { 'iterations': 500, 'learning_rate': 0.03, 'depth': 6, 'loss_function': 'RMSE', 'random_seed': 42, 'verbose': False } # Training classification model (directional prediction) print("Training classification model...") model_class = CatBoostClassifier(**params_class) model_class.fit(X_train, y_class_train, eval_set=(X_test, y_class_test), early_stopping_rounds=50, verbose=False) # Checking classification accuracy y_class_pred = model_class.predict(X_test) accuracy = accuracy_score(y_class_test, y_class_pred) print(f"Classification accuracy: {accuracy:.4f} ({accuracy*100:.2f}%)") # Training regression model (forecast of percentage change) print("\nTraining regression model...") model_reg = CatBoostRegressor(**params_reg) model_reg.fit(X_train, y_reg_train, eval_set=(X_test, y_reg_test), early_stopping_rounds=50, verbose=False) # Checking regression accuracy y_reg_pred = model_reg.predict(X_test) rmse = np.sqrt(mean_squared_error(y_reg_test, y_reg_pred)) print(f"RMSE regressions: {rmse:.4f}") # Print importance of features print("\nImportance of features for classification:") feature_importance = model_class.get_feature_importance(prettified=True) print(feature_importance.head(5)) return model_class, model_reg
Das erste Modell (Klassifikator) sagt die Richtung der Preisbewegung voraus – aufwärts oder abwärts. Das zweite Modell (Regressor) schätzt das Ausmaß dieser Bewegung als Prozentsatz. Zusammen ergeben sie eine vollständige Prognose der künftigen Preisentwicklung.
Nach dem Training können wir diese Modelle nutzen, um Echtzeitprognosen zu erstellen:
def predict_future_movement(model_class, model_reg, angular_df, lookback=15): # Get latest data if len(angular_df) < lookback: print("Not enough data for forecast") return None # Get latest lookback of bars last_window = angular_df.tail(lookback) # Form features as during training feature_dict = { f'angle_{j}': last_window['angle'].iloc[j] for j in range(lookback) } # Add derivative characteristics feature_dict.update({ 'angle_mean': last_window['angle'].mean(), 'angle_std': last_window['angle'].std(), 'angle_min': last_window['angle'].min(), 'angle_max': last_window['angle'].max(), 'angle_last': last_window['angle'].iloc[-1], 'angle_last_3_mean': last_window['angle'].iloc[-3:].mean(), 'angle_last_5_mean': last_window['angle'].iloc[-5:].mean(), 'angle_last_10_mean': last_window['angle'].iloc[-10:].mean(), 'positive_angles_ratio': (last_window['angle'] > 0).mean(), 'current_price': last_window['close'].iloc[-1], 'price_std': last_window['close'].std(), 'price_change_pct': (last_window['close'].iloc[-1] - last_window['close'].iloc[0]) / last_window['close'].iloc[0] * 100, 'high_low_range': (last_window['high'].max() - last_window['low'].min()) / last_window['close'].iloc[-1] * 100, 'last_tick_volume': last_window['tick_volume'].iloc[-1], 'avg_tick_volume': last_window['tick_volume'].mean(), 'tick_volume_ratio': last_window['tick_volume'].iloc[-1] / last_window['tick_volume'].mean() if last_window['tick_volume'].mean() > 0 else 1, }) # Convert to format for model X_pred = pd.DataFrame([feature_dict]) # Model predictions direction_proba = model_class.predict_proba(X_pred)[0] direction = model_class.predict(X_pred)[0] change_pct = model_reg.predict(X_pred)[0] # Form result result = { 'direction': 'UP' if direction == 1 else 'DOWN', 'probability': direction_proba[int(direction)], 'change_pct': change_pct, 'current_price': last_window['close'].iloc[-1], 'predicted_price': last_window['close'].iloc[-1] * (1 + change_pct/100), } # Form signal if direction == 1 and direction_proba[1] > 0.7 and change_pct > 0.5: result['signal'] = 'STRONG_BUY' elif direction == 1 and direction_proba[1] > 0.6: result['signal'] = 'BUY' elif direction == 0 and direction_proba[0] > 0.7 and change_pct < -0.5: result['signal'] = 'STRONG_SELL' elif direction == 0 and direction_proba[0] > 0.6: result['signal'] = 'SELL' else: result['signal'] = 'NEUTRAL' return result
Diese Funktion analysiert die neuesten Daten und erstellt eine Prognose über die zukünftige Preisentwicklung. Sie sagt nicht nur die Richtung voraus, sondern schätzt auch die Wahrscheinlichkeit und das Ausmaß dieser Bewegung und bildet so ein spezifisches Handelssignal.
Praxistest: Teststrategie
Theorie ist gut, aber die Praxis ist wichtiger. Wir wollten die Leistung unserer Methode anhand historischer Daten testen. Zu diesem Zweck haben wir eine Backtesting-Funktion implementiert:
def backtest_strategy(angular_df, model_class, model_reg, lookback=15): # Filter data clean_df = angular_df.dropna(subset=['angle']) # To store results signals = [] actual_changes = [] timestamps = [] # Modelling trading based on historical data for i in range(lookback, len(clean_df) - 24): # 24 bars - forecast horizon # Data at the time of decision window_df = clean_df.iloc[:i] # Get prediction prediction = predict_future_movement(model_class, model_reg, window_df, lookback) if prediction: # Record signal (1 = buy, -1 = sell, 0 = neutral) if prediction['signal'] in ['BUY', 'STRONG_BUY']: signals.append(1) elif prediction['signal'] in ['SELL', 'STRONG_SELL']: signals.append(-1) else: signals.append(0) # Record actual change actual_change = (clean_df.iloc[i+24]['close'] - clean_df.iloc[i]['close']) / clean_df.iloc[i]['close'] * 100 actual_changes.append(actual_change) # Record time timestamps.append(clean_df.iloc[i]['time']) # Result analysis signals = np.array(signals) actual_changes = np.array(actual_changes) # Calculate P&L for signals (except neutral ones) active_signals = signals != 0 pnl = signals[active_signals] * actual_changes[active_signals] # Statistics win_rate = np.sum(pnl > 0) / len(pnl) avg_win = np.mean(pnl[pnl > 0]) if np.any(pnl > 0) else 0 avg_loss = np.mean(pnl[pnl < 0]) if np.any(pnl < 0) else 0 profit_factor = abs(np.sum(pnl[pnl > 0]) / np.sum(pnl[pnl < 0])) if np.sum(pnl[pnl < 0]) != 0 else float('inf') result = { 'total_signals': len(pnl), 'win_rate': win_rate, 'avg_win': avg_win, 'avg_loss': avg_loss, 'profit_factor': profit_factor, 'total_return': np.sum(pnl) } return result
Ergebnisse, die für sich selbst sprechen
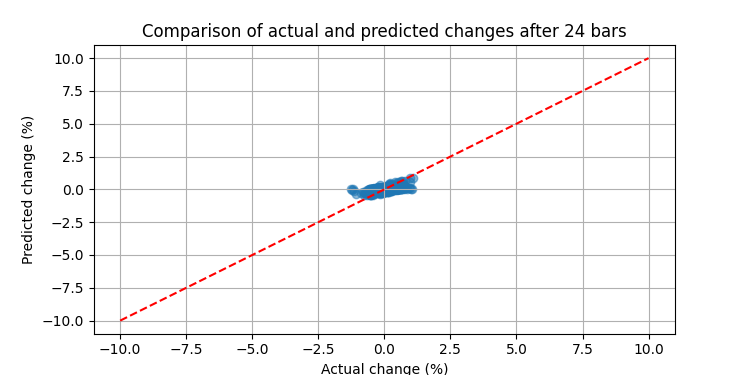
Als wir unser System mit echten EURUSD-Daten ausprobierten, übertrafen die Ergebnisse die Erwartungen. Der Backtest über drei Monate ergab folgende Resultate:
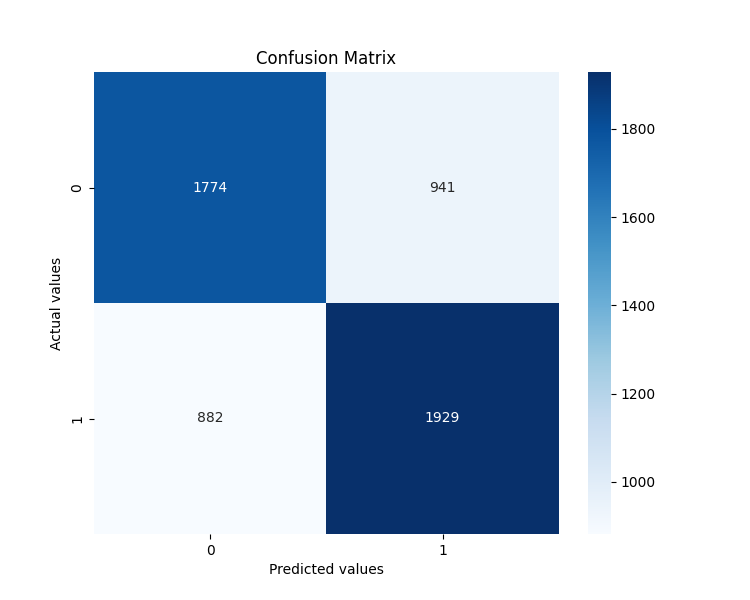
Als besonders interessant erwies sich die Analyse der Bedeutung von Merkmalen. Im Folgenden sind die 5 wichtigsten Faktoren aufgeführt, die die Prognose am stärksten beeinflusst haben:
- angle_last – ist der letzte Winkel vor dem vorhergesagten Punkt
- angle_last_3_mean – ist der Durchschnittswert der letzten drei Winkel
- positive_angles_ratio – ist das Verhältnis von positiven und negativen Winkeln
- angle_std – ist die Standardabweichung der Winkel
- angle_max – ist der maximale Winkel in der Sequenz
Dies bestätigte unsere Hypothese: Die Winkel enthalten in der Tat Vorhersageinformationen über künftige Preisbewegungen. Die allerletzten Winkel sind besonders wichtig. Sie sind wie die letzten Töne vor dem Höhepunkt eines Musikstücks, an denen ein erfahrener Hörer das Ende ablesen kann.
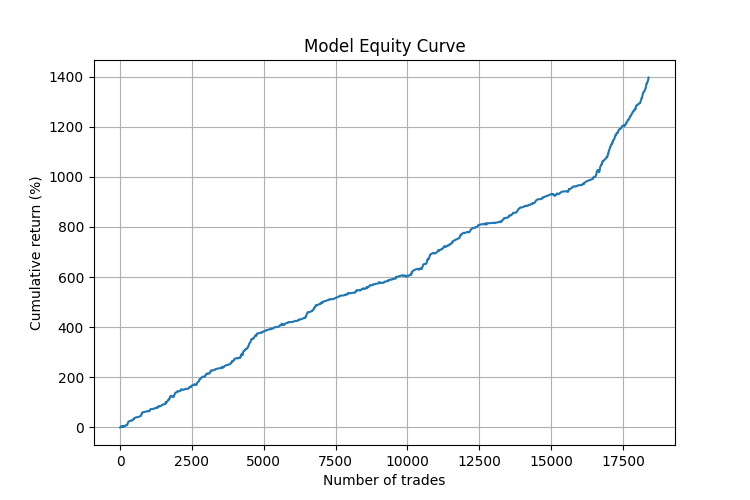
Eine genauere Analyse zeigte, dass das Modell unter bestimmten Marktbedingungen besonders gut funktioniert:
- In Zeiten von Richtungsbewegungen (Trends) erreichte die Genauigkeit der Prognosen 75 %.
- Die zuverlässigsten Signale traten nach einer Reihe von Winkeln in eine Richtung auf, auf die eine abrupte Winkeländerung in die entgegengesetzte Richtung folgte.
- Besonders gut war das System bei der Vorhersage von Umkehrungen nach starken Impulsbewegungen.
Es ist bemerkenswert, dass die Strategie stabile Ergebnisse auf verschiedenen Zeitrahmen von M5 bis H4 gezeigt hat. Dies bestätigt die Universalität der Winkelmuster-Methode und ihre Unabhängigkeit von der Zeitskala.
Wie es in der Realität funktioniert
Ein typisches Winkelsignal wird nicht in einem Takt gebildet. Es handelt sich um eine Folge von Winkeln, die ein bestimmtes Muster bilden. Vor einer starken Aufwärtsbewegung ist zum Beispiel oft Folgendes zu beobachten: Eine Reihe von Winkeln schwankt um den Nullpunkt (horizontale Bewegung), dann erscheinen 2-3 kleine negative Winkel (ein kleiner Rückgang), und dann ein scharfer positiver Winkel, gefolgt von mehreren weiteren positiven Winkeln mit zunehmender Amplitude.
Es ist wie beim Start eines Sprinters: Zuerst bringt er sich in den Startblöcken in Position (horizontale Bewegung), dann lehnt er sich leicht zurück, um Schwung aufzubauen (leichter Fall), und schließlich schießt er kraftvoll nach vorne (eine Reihe positiver Winkel).
Aber der Teufel steckt wie immer im Detail. Die Winkelmuster sind nicht immer gleich. Sie hängen vom Währungspaar, dem Zeitrahmen und der allgemeinen Marktvolatilität ab. Außerdem können manchmal ähnliche Muster verschiedene Bewegungen vorhersagen. Deshalb haben wir ihre Interpretation dem maschinellen Lernen anvertraut – der Computer sieht Nuancen, die für das menschliche Auge unsichtbar sind.
Lernen: Der schwierige Weg zum Verständnis
Der Aufbau unseres Systems war, als würde man einem Kind das Lesen beibringen. Zunächst haben wir das Modell darauf trainiert, einzelne „Buchstaben“ – Steigungswinkel – zu erkennen. Dann fassten wir sie zu „Wörtern“, also Winkelsequenzen, zusammen. Und dann – „Sätze“ verstehen und ihr Ende vorhersagen.
Wir haben den CatBoost-Algorithmus verwendet, ein hochmodernes Tool für maschinelles Lernen, das speziell für die Arbeit mit kategorialen Merkmalen optimiert ist. Aber die Technologie ist nur ein Werkzeug. Die eigentliche Herausforderung war eine andere: Wie kann man Marktdaten richtig kodieren? Wie können wir den chaotischen Preistanz in strukturierte Informationen umwandeln, die eine Maschine verstehen kann?
Die Lösung war „Rolling Sampling“ – eine Technik, bei der wir jedes Fenster aus 15 Bars nacheinander analysierten, indem wir eine Bar nach der anderen verschoben. Für jedes dieser Fenster haben wir 15 Winkel sowie zahlreiche abgeleitete Indikatoren berechnet – den Durchschnittswert der Winkel, ihre Varianz, Maxima, Minima und das Verhältnis von positiven und negativen Winkeln.
Anschließend haben wir diese Merkmale mit der zukünftigen Preisentwicklung nach 24 Bars verglichen. Es war, als würde man ein riesiges Wörterbuch zusammenstellen, in dem jede Winkelkombination einer bestimmten Marktbewegung in der Zukunft entsprach.
Das Training dauerte Monate. Das Modell verdaute Gigabytes von Daten und lernte, feine Nuancen von Winkelsequenzen zu erkennen. Aber das Ergebnis war den Zeitaufwand wert. Wir haben ein Instrument erhalten, das den Markt auf eine Weise „hören“ kann, wie es kein menschlicher Händler kann.
Philosophie der Winkelanalyse
Während der Arbeit an diesem Projekt haben wir uns oft gefragt: Warum haben sich die Winkelmerkmale als so effektiv erwiesen? Die Antwort liegt vielleicht in der tiefgreifenden Natur der Finanzmärkte.
Die Märkte sind nicht einfach nur zufällige Preisverläufe, wie einige Theorien behaupten. Es handelt sich um komplexe dynamische Systeme, in denen viele Teilnehmer mit ihren eigenen Motiven, Strategien und Zeithorizonten interagieren. Die Winkel, die wir messen, sind nicht nur geometrische Abstraktionen. Dies ist eine Visualisierung der kollektiven Psychologie des Marktes, des Kräfteverhältnisses zwischen Bullen und Bären, Impulsen und Korrekturen.
Wenn Sie eine Abfolge von Winkeln sehen, sehen Sie in Wirklichkeit die „Fußspuren“ der Marktteilnehmer, ihre Kauf- und Verkaufsentscheidungen, ihre Ängste und Hoffnungen. Und wie sich herausstellte, befanden sich in diesen Spuren versteckte Hinweise auf zukünftige Bewegungen.
In gewisser Weise ist unsere Methode näher an der Analyse physikalischer Prozesse als an der traditionellen technischen Analyse. Wir schauen nicht auf abstrakte Indikatoren, sondern auf die grundlegenden Eigenschaften der Preisbewegung – ihre Richtung, Geschwindigkeit, Beschleunigung (die alle in Winkeln enthalten sind).
Schlussfolgerung: Ein neuer Blick auf den Markt
Unsere Reise in die Welt der Winkelmuster begann mit einer einfachen Frage: „Was, wenn die Winkel der Preissteigung den Schlüssel zu zukünftigen Bewegungen darstellen?“ Heute ist dieses Thema zu einem vollwertigen Handelssystem geworden, zu einer neuen Art, die Märkte zu betrachten.
Wir erheben nicht den Anspruch, einen perfekten Indikator geschaffen zu haben. Einen solchen gibt es nicht. Wir schlagen jedoch vor, die Charts aus einem neuen Winkel zu betrachten – im wörtlichen und übertragenen Sinne. Sehen Sie sie nicht nur als Linien und Bars, sondern als einen geometrischen Code, der mithilfe fortschrittlicher Technologie entschlüsselt werden kann.
Der Handel ist und bleibt ein Spiel der Wahrscheinlichkeiten. Aber je mehr Instrumente Sie haben, um diese Wahrscheinlichkeiten zu analysieren, desto besser sind Ihre Chancen. Die Winkelanalyse ist eines dieser Instrumente, vielleicht das am meisten unterschätzte in der modernen technischen Analyse.
Schließlich ist der Markt ein Tanz der Preise. Und wie bei jedem Tanz kommt es nicht nur darauf an, wohin sich der Tänzer bewegt, sondern auch auf den Winkel, in dem er jeden Schritt macht.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/17219
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Achten Sie bitte auf die Details.
Der Zeitrahmen des Tests war 4 Monate, grob gerechnet 161280 Sekunden. Die Gesamtzahl der Trades betrug mehr als 17500, d.h. die durchschnittliche Handelsdauer beträgt 9 Sekunden. Betrachten Sie die mögliche durchschnittliche Bewegung des EURUSD in 9 Sekunden. Es ist kein Geld zu verdienen. Das Modell sagt größtenteils den letzten Preis voraus, genau wie jedes KI-Modell, das Preisreihen als Input verwendet. KI-Modelle konvergieren sehr schlecht bei Preisreihen, so auch dieses Modell.
Achten Sie bitte auf die Details.
Der Zeitrahmen des Tests betrug 4 Monate, grob berechnet 161280 Sekunden. Insgesamt wurden mehr als 17500 Trades getätigt, so dass die durchschnittliche Handelsdauer 9 Sekunden beträgt. Betrachten Sie die mögliche durchschnittliche Bewegung des EURUSD in 9 Sekunden. Es ist kein Geld zu verdienen. Das Modell sagt größtenteils den letzten Preis voraus, genau wie jedes KI-Modell, das Preisreihen als Input verwendet. KI-Modelle konvergieren sehr schlecht bei Preisreihen, so auch dieses Modell.
Metrik für Reck zurück = 60, vorwärts = 30
Zug-Genauigkeit: 0,9200 | Test-Genauigkeit: 0,8713 | GAP: 0,0486
Zug F1-Ergebnis: 0.9187 | Test F1-Ergebnis: 0.8682 | GAP: 0.0505
Bei kurzen Distanzen taugt CatBoost nichts, das Modell ist übertrainiert
Hallo Aliaksandr
das Problem mit diesem Code ist die Verwendung des
shuffle=True
Argument im train_test_split-Aufruf.
Wenn du es in
shuffle=False
ändern, werden Sie einen enormen Leistungsabfall feststellen. Das liegt daran, dass, auch wenn die Testmenge und die Trainingsmenge im Prinzip aufgeteilt und voneinander getrennt sind, die Aufteilung sehr fein ist und es daher viele sehr ähnliche X-"Werte" zwischen den beiden Mengen gibt. Tatsächlich besteht zwischen jedem X[i] und X[i+1] nur ein Unterschied von 1 Balken, was die Trainingsmenge und die Testmenge in der Praxis sehr ähnlich macht. Daher sind die hervorragenden Ergebnisse, die wir (mit shuffle=True) sehen, im Wesentlichen auf eine Überanpassung zurückzuführen. Entfernt man den Shuffle, besteht die Testmenge aus einer bestimmten Anzahl zusammenhängender Balken (den jüngsten), und der CatBoost-Klassifikator wird darin keine guten Vorhersagen treffen, während umgekehrt die Vorhersage in der Trainingsmenge sehr gut sein kann. Ein klares Zeichen für Overfitting. Dies tritt selbst bei einem sehr kleinen Anteil von Balken in der (nicht gemischten) Testmenge auf, so dass die Leistungsverschlechterung nicht durch eine Änderung der Marktbedingungen erklärt werden kann.
Wieder schrien die Mäuse, stachen und kackten, fraßen aber beharrlich weiter den Kaktus! ;)
Hier ist eine mehr oder weniger fertige Gann-Vorlage für MT4, der Code ist offen.
https://disk.yandex.ru/d/7YhmKzcqttnQnQ
Mit der richtigen Einstellung all dessen, was der TS beschrieben hat, kann man ein paar Stunden im Voraus sehen, dass entweder der Trend oder die Korrektur zu Ende geht. Außerdem kann der Zeitpunkt des Trendendes im Voraus berechnet werden.
Wie man sich richtig aufstellt, kann jeder für sich selbst herausfinden.
P.S. - Gunn hat alles in seinen Werken (Mathematik der Modelle), Sie werden nichts Neues finden oder erfinden, 2x2 wird immer 4 sein. Es ist besser, tiefer in das Studium des Quellenmaterials zu gehen.
Das Muster bestätigt erneut, dass der Trend nachlässt und es sich lohnt, auf eine Reaktion zu warten.