
MQL5中的ARIMA预测指标

气象学家在制作天气预报时,并不是在占卜。他们通过分析过去发生的情况,来推断明天可能发生什么。ARIMA 模型的工作原理与此类似,只不过它研究的不是云层和气压,而是金融市场上的价格数据。
ARIMA 是“自回归积分移动平均”(Autoregressive Integrated Moving Average)模型的缩写。这个名字听起来挺复杂,其实逻辑很简单。想象一下,你试图根据 EUR/USD 货币对过去几天的表现,来预测它明天的价格。
ARIMA模型的三大支柱
自回归(AR)——对过去的记忆
模型的第一部分称为“自回归”。这个专业术语的含义很简单:今天的价格取决于昨天、前天,甚至更早之前的价格。这就好像市场拥有记忆,并基于过去构建未来。
如果 EUR/USD 连续三天上涨,那么明天继续上涨的可能性就存在。虽然并非绝对,但趋势可能会延续。模型的自回归部分正是通过分析历史数值对当前值的影响程度,来捕捉这类规律。
用简单的数学语言来说:假设你拥有过去五天的 EUR/USD 汇率数据:1.0800、1.0825、1.0850、1.0875、1.0900。自回归会告诉你:“看,每天汇率大约上涨 25 个点(0.0025),所以明天大概在 1.0925 左右。”模型会自动找出一些系数——这些数字反映了昨天、前天等的价格对今天价格的影响强度。
公式大致如下:明天价格 = 0.7 × 今天价格 + 0.2 × 昨天价格 + 0.1 × 前天价格。其中的系数 0.7、0.2、0.1 是由模型通过分析历史数据自动确定的。系数越大,表示该天价格对预测结果的影响越强。
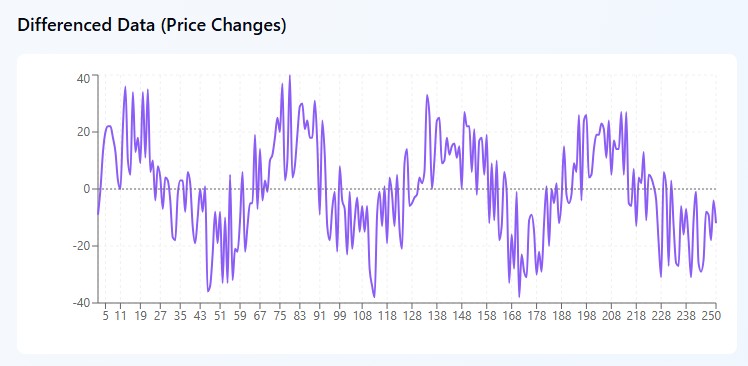
积分(I)— 驾驭混沌
想象你正在查看 EUR/USD 的图表,看到的数据杂乱无章:1.0800、1.0850、1.0820、1.0880、1.0860。价格像喝醉的水手一样上下跳动,乍一看毫无逻辑。数学家称这类数据为“非平稳序列”,而交易者则称之为“头疼之源”。
但 ARIMA 有个妙招:ARIMA它不直接尝试理解价格本身,而是能更进一步。即它并不关心汇率价格的绝对数值,而是关注价格每日的变化量。拿上面的数字为例,计算它们的差值:+50 点、-30 点、+60 点、-20 点。突然间,混乱中出现了规律!市场似乎在“上涨 50–60 点”和“下跌 20–30 点”之间摆动。
这就像你不是在观察钟摆的位置,而是在关注它摆动的方向和力度。从数学角度看,这很简单:用今天的价格减去昨天的价格,得到变化量。有时甚至需要进一步计算“变化的变化”,也就是二阶差分。听起来吓人,但原理不变:在看似无序的数据中寻找潜在模式。
移动平均(MA)—— 从错误中学习
最有趣的部分来了:模型能够从自身的错误中学习。这听起来像科幻情节,但逻辑非常直接。当 ARIMA 昨天预测 EUR/USD 为 1.0800,而实际成交价是 1.0825 时,这 25 个点的误差不仅仅是一个令人烦恼的偏差。它本身就是信息!
想象一个总是迟到整整 10 分钟的朋友。当他说“我六点到”时,你心里已经明白他其实是 6:10 到。模型对待自己的错误也是如此。如果它连续三天预测的价格都比实际低 10 个点,它就会记住这个规律,并在下次预测时自动调整:“我通常低估 10 个点,所以下次预报要加上这个修正值。”
公式可能类似于:“修正值 = 0.5 × 昨天的误差 + 0.3 × 前天的误差”。模型不光会犯错,还会“聪明”地利用这些错误,优化后面的预测。
ARIMA 如何利用市场心理
运动的惯性
市场具有惯性。如果 EUR/USD 连续几天上涨,越来越多的人愿意买入,从而推动价格进一步走高。ARIMA 正好能捕捉这种惯性。
实际案例:汇率连续五天从 1.0800 涨至 1.0900(每天约 +20 点)。模型会赋予近期数据更高权重,并预测趋势将继续。
均值回归
与此同时,市场也倾向于回归“合理”水平。如果价格大幅偏离某一方向,迟早会试图回调。
举例:EUR/USD 通常在 1.0800–1.0900 区间波动。若因突发新闻跳涨至 1.1000,模型会通过移动平均组件意识到:此类极端走势通常会被修正。
周期性模式
许多货币对表现出周期性行为——周度、月度或季节性规律。只要设置得当,ARIMA 就能识别这些模式。
模型的局限性:ARIMA 何时失效?
ARIMA 并非万能钥匙。它的基本假设是“未来会与过去相似”。一旦这一假设被打破,模型的预测就会失准。
在以下情况下,模型表现不佳:
- 突发经济数据发布
- 央行货币政策发生转变
- 地缘政治危机爆发
- 市场进入新状态(例如从趋势市转为震荡市)
ARIMA 最适合应用于:
- 市场条件稳定时期
- 无重大基本面变化的阶段
- 具有明显技术形态的交易品种
MQL5中的实现
实现一个可用的 ARIMA 指标,远不止套用公式那么简单。我们需要一套精密的架构,以支持实时数据处理。
该指标的核心是一个用于估算模型系数的模块。它采用最大似然估计法。听起来复杂,其实只是一种寻找最优参数的方法,使模型能最好地解释观测到的数据。
指标的数据结构包含多个相互关联的缓冲区:ForecastBuffer:主缓冲区,存储预测值;PriceBuffer:辅助缓冲区,存储历史价格;ErrorBuffer:误差缓冲区,保存模型残差。这种设计确保了内存使用的高效性和计算速度的最优化。
系统初始化过程包括创建动态数组,用于存储原始价格数据、差分序列、自回归系数、移动平均系数以及残差数组。系数的初始值设为 0.1,以保证优化算法在起步阶段的稳定性。
int OnInit() { // Setting indicator buffers for visualizing results SetIndexBuffer(0, ForecastBuffer, INDICATOR_DATA); SetIndexBuffer(1, PriceBuffer, INDICATOR_CALCULATIONS); SetIndexBuffer(2, ErrorBuffer, INDICATOR_CALCULATIONS); // Setting time series mode for correct operation with historical data ArraySetAsSeries(ForecastBuffer, true); ArraySetAsSeries(PriceBuffer, true); ArraySetAsSeries(ErrorBuffer, true); // Configuring forecast display with corresponding time shift PlotIndexSetString(0, PLOT_LABEL, "ARIMA Forecast"); PlotIndexSetInteger(0, PLOT_SHIFT, forecast_bars); // Initializing working arrays with predefined sizes ArrayResize(prices, lookback); ArrayResize(differenced, lookback); ArrayResize(ar_coeffs, p); ArrayResize(ma_coeffs, q); ArrayResize(errors, lookback); // Setting initial values of model coefficients for(int i = 0; i < p; i++) ar_coeffs[i] = 0.1; for(int i = 0; i < q; i++) ma_coeffs[i] = 0.1; return(INIT_SUCCEEDED); }
模型的输入参数
该指标通过一组输入参数进行配置,每个参数都对模型行为起关键作用。lookback:决定用于训练模型的历史数据长度;forecast_bars:指定预测的时间跨度;p, d, q 三个参数:定义 ARIMA 模型的具体特征。
//--- Input parameters of model configuration input int lookback = 200; // Lookback period for ARIMA input int forecast_bars = 20; // Number of forecast time intervals input int p = 3; // Order of autoregressive component input int d = 1; // Degree of differentiation of a time series input int q = 2; // Order of moving average component input double learning_rate = 0.01; // Learning rate coefficient input int max_iterations = 100; // Maximum number of optimization iterations
模型参数估计方法
算法的核心是对数似然函数的计算函数,用它衡量模型拟合数据的好坏。该函数的实现基于模型残差服从正态分布的假设,从而可使用概率密度的解析表达式。
似然函数与残差计算
对数似然函数的计算是一个迭代过程:在每个时间点,将观测值与模型预测值之差作为残差。自回归部分由差分序列的前期值线性组合而成,而移动平均部分则利用模型前期的误差值。
double ComputeLogLikelihood(double &data[], double &ar[], double &ma[]) { double ll = 0.0; double residuals[]; ArrayResize(residuals, lookback); ArrayInitialize(residuals, 0.0); // Iterative calculation of model residuals for(int i = p; i < lookback; i++) { double ar_part = 0.0; double ma_part = 0.0; // Forming autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar[j] * data[i - j - 1]; // Forming moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma[j] * errors[i - j - 1]; // Calculating residuals and updating the error array residuals[i] = data[i] - (ar_part + ma_part); errors[i] = residuals[i]; // Accumulating log-likelihood function ll -= 0.5 * MathLog(2 * M_PI) + 0.5 * residuals[i] * residuals[i]; } return ll; }
系数优化过程
系数优化采用带自适应步长的梯度下降法。算法沿着梯度反方向不断更新系数,确保收敛到局部最优解。
void OptimizeCoefficients(double &data[]) { double temp_ar[], temp_ma[]; ArrayCopy(temp_ar, ar_coeffs); ArrayCopy(temp_ma, ma_coeffs); double best_ll = -DBL_MAX; double grad_ar[], grad_ma[]; ArrayResize(grad_ar, p); ArrayResize(grad_ma, q); // Iterative optimization process for(int iter = 0; iter < max_iterations; iter++) { ArrayInitialize(grad_ar, 0.0); ArrayInitialize(grad_ma, 0.0); // Calculating gradients of likelihood function for(int i = p; i < lookback; i++) { double ar_part = 0.0, ma_part = 0.0; // Forming model components for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += temp_ar[j] * data[i - j - 1]; for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += temp_ma[j] * errors[i - j - 1]; double residual = data[i] - (ar_part + ma_part); // Accumulating gradients by AR coefficients for(int j = 0; j < p && i - j - 1 >= 0; j++) grad_ar[j] += -residual * data[i - j - 1]; // Accumulating gradients by MA coefficients for(int j = 0; j < q && i - j - 1 >= 0; j++) grad_ma[j] += -residual * errors[i - j - 1]; } // Updating coefficients according to the gradient descent rule for(int j = 0; j < p; j++) temp_ar[j] += learning_rate * grad_ar[j] / lookback; for(int j = 0; j < q; j++) temp_ma[j] += learning_rate * grad_ma[j] / lookback; // Evaluating quality of current approximation double current_ll = ComputeLogLikelihood(data, temp_ar, temp_ma); // Stopping criterion and updating the optimal solution if(current_ll > best_ll) { best_ll = current_ll; ArrayCopy(ar_coeffs, temp_ar); ArrayCopy(ma_coeffs, temp_ma); } else { break; // Premature stop in the absence of improvement } } }
特别需要注意的是,需为每个优化参数计算似然函数的偏导数。自回归系数的梯度等于残差与对应滞后差分值的乘积之和。而移动平均系数的梯度则由残差与前期误差值的乘积决定。
预测算法与微分逆运算
预测值从时间序列最后一个观测值开始递归生成。在每一步预测中,自回归部分由差分序列的前期值与相应系数的线性组合计算得出。移动平均部分则通过前期模型残差的加权和形成。
基本计算流程
OnCalculate 函数是整个算法的计算核心,将所有组件整合为一个统一的数据处理流水线。该函数依次处理市场数据、计算差分、优化模型参数及生成预测值。
int OnCalculate(const int rates_total, const int prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int &spread[]) { ArraySetAsSeries(close, true); ArraySetAsSeries(time, true); // Checking sufficiency of historical data if(rates_total < lookback + forecast_bars) return(0); // Forming array of closing prices for(int i = 0; i < lookback; i++) { prices[i] = close[i]; PriceBuffer[i] = close[i]; } // Applying differentiation procedure for(int i = 0; i < lookback - d; i++) { if(d == 1) differenced[i] = prices[i] - prices[i + 1]; else if(d == 2) differenced[i] = (prices[i] - prices[i + 1]) - (prices[i + 1] - prices[i + 2]); else differenced[i] = prices[i]; } // Optimizing AR and MA coefficients ArrayInitialize(errors, 0.0); OptimizeCoefficients(differenced); // Generating ARIMA forecast double forecast[]; ArrayResize(forecast, forecast_bars); double undiff[]; ArrayResize(undiff, forecast_bars); // Initializing forecasting process forecast[0] = prices[0]; undiff[0] = prices[0]; // Iterative forecast generation for(int i = 1; i < forecast_bars; i++) { double ar_part = 0.0; double ma_part = 0.0; // Calculating autoregressive component for(int j = 0; j < p && i - j - 1 >= 0; j++) ar_part += ar_coeffs[j] * (j < lookback ? differenced[j] : forecast[i - j - 1]); // Calculating moving average component for(int j = 0; j < q && i - j - 1 >= 0; j++) ma_part += ma_coeffs[j] * errors[j]; // Forming forecast value forecast[i] = ar_part + ma_part; // Procedure of reversal of differentiation if(d == 1) undiff[i] = undiff[i - 1] + forecast[i]; else if(d == 2) undiff[i] = undiff[i - 1] + (undiff[i - 1] - (i >= 2 ? undiff[i - 2] : prices[1])) + forecast[i]; else undiff[i] = forecast[i]; // Updating error array for following iterations errors[i % lookback] = forecast[i] - (i < lookback ? differenced[i] : 0.0); } // Filling output buffer with forecast values for(int i = 0; i < forecast_bars; i++) { ForecastBuffer[i] = undiff[i]; } // Extending historical data for continuous display for(int i = forecast_bars; i < lookback; i++) { ForecastBuffer[i] = prices[i - forecast_bars]; } return(rates_total); }
差分逆运算是确保预测值恢复原始量纲的关键步骤。对于一阶差分,将前一个未差分值与对应的一阶差分预测值相加得到每个预测值。若使用二阶差分,则需采用更复杂的递归公式,以考虑时间序列的曲率变化。
计算性能与优化
算法的性能很大程度上取决于计算流程的组织方式以及对处理器资源的高效利用。主函数 OnCalculate 的结构设计旨在最小化新市场数据到来时的冗余计算。
针对不同的变换阶数,实施了相应的微分过程。一阶微分只需计算相邻观测值的简单差值;二阶微分则使用二次微分公式。这不仅消除了趋势,还消除了趋势变化率的影响。
实现中的一个关键环节是内存管理及正确操作长度变化的数组。使用 ArrayResize 和 ArraySetAsSeries 函数可确保数据结构适应不断变化的模型参数,并符合 MetaTrader 5 中的数据组织特性。
参数校准与市场适应性
要在真实交易环境中成功应用 ARIMA 模型,必须仔细校准参数,同时考虑特定金融工具的特性和分析的时间范围。lookback 参数决定了历史分析的深度:既要足够大以保证统计显著性,又不能过大以免纳入过时信息。
选择模型的 p、d、q 阶数,是在数据拟合精度与计算复杂度之间的权衡。提高自回归阶数 p 可以捕捉更复杂的时间依赖关系。但过度复杂化可能导致过拟合,降低对新数据的预测质量。
学习率参数 learning_rate 需要特别精细的调整:值太大会导致优化算法震荡,值太小则会延缓收敛速度。
统计验证与预测质量评估
要客观评估指标好坏,得用一套统计标准,量化预测准不准。最具信息量的指标包括:平均绝对误差(MAE)、均方根误差(RMSE)和决定系数(R²)。
预测质量的度量
实现一个预测质量评估函数,用于定量分析模型的表现,对比不同 ARIMA 参数的效果。平均绝对误差反映了预测值与实际值偏差的直观度量,单位与原时间序列一致。
// Function of calculating average absolute error double CalculateMAE(double &actual[], double &predicted[], int size) { double mae = 0.0; for(int i = 0; i < size; i++) { mae += MathAbs(actual[i] - predicted[i]); } return mae / size; } // Function of calculating the root mean square error double CalculateRMSE(double &actual[], double &predicted[], int size) { double mse = 0.0; for(int i = 0; i < size; i++) { double error = actual[i] - predicted[i]; mse += error * error; } return MathSqrt(mse / size); } // Determination coefficient calculation function double CalculateR2(double &actual[], double &predicted[], int size) { double actual_mean = 0.0; for(int i = 0; i < size; i++) actual_mean += actual[i]; actual_mean /= size; double ss_tot = 0.0, ss_res = 0.0; for(int i = 0; i < size; i++) { ss_tot += (actual[i] - actual_mean) * (actual[i] - actual_mean); ss_res += (actual[i] - predicted[i]) * (actual[i] - predicted[i]); } return 1.0 - (ss_res / ss_tot); }
模型残差诊断
残差分析是验证的关键,能帮我们发现是不是系统性地偏离了模型假设。Ljung-Box 检验用于检测残差的自相关性,以验证模型设定是否充分;Jarque-Bera 检验则用于评估残差分布的正态性。
// Function for calculating autocorrelation function of the residuals double CalculateAutocorrelation(double &residuals[], int lag, int size) { double mean = 0.0; for(int i = 0; i < size; i++) mean += residuals[i]; mean /= size; double numerator = 0.0, denominator = 0.0; for(int i = lag; i < size; i++) { numerator += (residuals[i] - mean) * (residuals[i - lag] - mean); } for(int i = 0; i < size; i++) { denominator += (residuals[i] - mean) * (residuals[i] - mean); } return numerator / denominator; } // Ljung-Box statistic for testing autocorrelation double LjungBoxTest(double &residuals[], int max_lag, int size) { double lb_stat = 0.0; for(int k = 1; k <= max_lag; k++) { double rho_k = CalculateAutocorrelation(residuals, k, size); lb_stat += (rho_k * rho_k) / (size - k); } return size * (size + 2) * lb_stat; }
交叉验证能评估模型对训练样本变化的稳健性。滑动窗口法能在接近真实交易的环境下提供更现实的预测质量评估——即在不重新调整参数的情况下,将模型依次应用于新数据。
残差分析提供了关于模型假设是否契合真实数据特征的重要信息。自相关检验可揭示未被捕捉的时间依赖性,而正态性检验则验证所用统计模型的正确性。
该指标的最终输出将是针对指定周期的预测结果:
算法发展与改进前景
金融时间序列分析领域的现代研究为 ARIMA 基础模型的发展开辟了广阔空间。在 SARIMA 里加上季节性成分,就能解释许多金融工具特有的周期性规律。正则化方法(如 L1 和 L2 惩罚项)能提升模型对异常值的鲁棒性,并防止过拟合。
对于高频交易而言,尤其值得关注的是自适应算法改进——即根据当前市场状况动态调整模型参数。机器学习方法的集成可实现模型规格的自动优选,无需人工分析师介入。
ARIMA 模型的多维扩展则为同时建模多个相关联的金融工具提供了可能。这对投资组合管理和套利策略尤为重要。
后记
本文展示的 MQL5 环境下 ARIMA 指标的实现,证明了经典计量经济学方法成功适配算法交易任务的可行性。只要严格按统计方法论来,配上高效的代码实现,就能做出靠谱的分析工具。
该指标的实际应用,要求使用者既深入理解模型的数学基础,又熟悉其所应用市场的具体特性。在趋势不稳定的市场中,该模型的表现会显著下降。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18253
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

差分部分在哪里?
将 Renko 和 Arima 结合起来应该更稳定。
是的,我也在用。