
Von der Grundstufe bis zur Mittelstufe: Das Array (I)

Einführung
Der hier dargestellte Inhalt ist ausschließlich für Bildungszwecke bestimmt. Die Anwendung sollte unter keinen Umständen zu einem anderen Zweck als zum Erlernen und Beherrschen der vorgestellten Konzepte verwendet werden.
Im vorigen Artikel, „Von der Grundstufe zur Mittelstufe: Arrays und Zeichenketten (III)“, habe ich anhand von Code, der auf den bisher gezeigten Wissensstand zugeschnitten ist, erklärt und demonstriert, wie die Standardbibliothek Binärwerte in dezimale, oktale und hexadezimale Darstellungen umwandeln kann. Ich habe auch beschrieben, wie eine binäre Zeichenkettendarstellung erzeugt werden kann, die es uns erleichtert, das Ergebnis zu visualisieren.
Zusätzlich zu diesem grundlegenden Konzept habe ich auch gezeigt, wie wir eine Passwortlänge auf der Grundlage einer geheimen Phrase definieren können. Durch einen glücklichen Zufall enthielt das resultierende Kennwort eine sich wiederholende Folge von Zeichen. Dies war ein bemerkenswertes Ergebnis, wenn man bedenkt, dass dies nicht das beabsichtigte Ziel war. In Wirklichkeit war es einfach ein glücklicher Zufall. Sie bietet jedoch eine hervorragende Gelegenheit, verschiedene andere Konzepte und Punkte im Zusammenhang mit Arrays und Strings zu erklären.
Einige Leser erwarten vielleicht, dass ich die Funktionsweise jeder Funktion oder Prozedur in der Standardbibliothek erläutere. Aber das ist nicht meine Absicht. Mein eigentliches Ziel ist es, die Konzepte hinter jeder Entscheidung aufzuzeigen. Je nach Art des Problems, das Sie lösen müssen, können Sie Ihre eigene Wahl treffen. Obwohl wir uns noch auf einem recht grundlegenden Niveau befinden, haben wir bereits einige reale Programmiermöglichkeiten, mit denen wir arbeiten können. Dies ermöglicht uns die Anwendung etwas fortgeschrittenerer Konzepte.
Dies vereinfacht nicht nur den Kodierungsprozess, sondern ermöglicht es Ihnen, liebe Leserin, lieber Leser, auch komplexeren Code leichter zu lesen. Es gibt keinen Grund, sich Sorgen über das zu machen, was kommen wird. Ich werde die Änderungen schrittweise einführen, damit Sie sich mit ihnen vertraut machen und meinen Code bequem lesen können. Ich neige dazu, Ausdrücke auf eine Art und Weise zu minimieren oder zu komprimieren, die für Anfänger verwirrend sein könnte, und ich möchte Sie an diesen Stil gewöhnen.
Beginnen wir also diesen Artikel mit einem Rückblick auf das, was wir im vorangegangenen Artikel behandelt haben. Mit anderen Worten, wir lernen eine von vielen Möglichkeiten kennen, um genau das Ergebnis zu vermeiden, das durch den Faktorisierungsprozess entsteht, der verwendet wird, um ein Passwort aus einer geheimen Phrase zu generieren.
Eine unter vielen Lösungen
Sehr gut. Heute werden wir damit beginnen, den Code etwas eleganter zu gestalten. Der ursprüngliche Code ist unten dargestellt.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
Code 01
Meiner Meinung nach ist dieser Code etwas unelegant. Dies liegt daran, dass die in den Zeilen 16 und 17 deklarierten Variablen nur innerhalb der Schleife in Zeile 21 verwendet werden. Wenn wir später aus irgendeinem Grund eine Variable mit demselben Namen oder einem anderen Typ benötigen, müssten wir zusätzliche Arbeit investieren, um den Code anzupassen. Wie wir in früheren Artikeln gesehen haben, ist es möglich, Variablen direkt innerhalb einer FOR-Schleife zu deklarieren.
Passen Sie jetzt gut auf, liebe Leserin, lieber Leser. Wenn mehr als eine Variable deklariert wird, die nur für die Verwendung innerhalb einer FOR-Schleife bestimmt ist, müssen alle vom gleichen Typ sein. Es ist NICHT MÖGLICH, im ersten Ausdruck einer FOR-Schleife Variablen unterschiedlichen Typs zu deklarieren und zu initialisieren. Wir müssen hier also eine kleine Entscheidung treffen. Die Variablen „pos“ und „i“, die in den Zeilen 16 und 17 deklariert werden, sind vom Typ uchar, während die Variable „c“, die innerhalb der FOR-Schleife deklariert wird, vom Typ int ist. Wir können entweder „pos“ und „i“ in int ändern, oder „c“ in uchar ändern. Meiner Meinung nach ist es nicht sehr sinnvoll, wenn ein Satz mehr als 255 Zeichen umfasst. Daher können wir uns auf einen Mittelweg einigen und alle drei Variablen als Variablen vom Typ ushort definieren, da sie ausschließlich als Indexierungsvariablen verwendet werden. Mit dieser Erklärung im Hinterkopf, ändern wir Code 01 in Code 02.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+
Code 02
Trotz der scheinbaren Komplexität von Code 02 erfüllt er die gleiche Aufgabe wie Code 01. Ich möchte jedoch Ihre Aufmerksamkeit auf Zeile 20 lenken. Beachten Sie, dass wir im ersten Ausdruck der for-Schleife nun alle Variablen deklarieren, die ausschließlich innerhalb der Schleife verwendet werden sollen. Schauen Sie sich den dritten Ausdruck der FOR-Anweisung genau an. In diesem Fall wäre es nicht möglich, den Wert der Variablen „i“ auf diese Weise anzupassen, ohne den ternären Operator zu verwenden. Es ist jedoch wichtig zu beachten, dass diese Anpassung lediglich sicherstellt, dass der Index innerhalb der Grenzen des Arrays bleibt, da die eigentliche Erhöhung in Zeile 23 durchgeführt wird.
Trotz dieser Änderung bleibt die Ausgabe genau gleich. Das heißt, wenn Sie den Code ausführen, werden Sie auf Ihrem Terminal etwas sehen, das dem unten gezeigten Bild ähnelt.
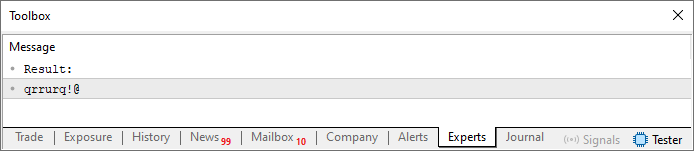
Abbildung 01
Lassen Sie uns ein wenig nachdenken. Die Wiederholung der Symbole in der Ausgabezeichenfolge geschieht, weil wir in Zeile 27 auf dieselbe Position in der Zeichenfolge szCodePhrase verweisen. Mit anderen Worten: Durch die Reduzierung der Werte auf die in Zeile 13 definierte Länge der Zeichenkette wird wiederholt auf dieselbe Stelle verwiesen. Aber (und das ist der wichtige Moment), wenn wir die aktuelle Position mit der vorherigen addieren, können wir einen neuen Index erstellen, der sich von dem letzten völlig unterscheidet. Da die Zeichenkette in Zeile 13 keine sich wiederholenden Zeichen enthält, würde auch die Ausgabezeichenkette, d. h. unser Kennwort, keine sich wiederholenden Zeichen enthalten.
Es gibt etwas Wichtiges zu bedenken: Diese Technik funktioniert nicht immer. Das liegt daran, dass die Anzahl der Zeichen in der in Zeile 13 definierten Zeichenkette möglicherweise nicht ideal ist. In einem anderen Szenario könnten die Werte in einen perfekten Zyklus fallen. Dies geschieht, weil wir im Wesentlichen mit einer Schleife von Zeichen oder Symbolen arbeiten, die in Zeile 13 deklariert werden, wobei das erste Zeichen (eine schließende Klammer) mit dem letzten Zeichen, der Zahl 9, verknüpft ist. Das ist wie eine Schlange, die sich in den eigenen Schwanz beißt.
Viele Nicht-Programmierer verstehen dieses Konzept nicht. Aber solche Dinge tauchen bei der Arbeit mit Code immer in der einen oder anderen Form auf.
Gut, nachdem ich nun erklärt habe, was wir tun werden, schauen wir uns den Code an. Sie ist unten abgebildet.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 0) + psw[c]) % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+s
Code 03
Dieser Ansatz ist sehr interessant. Beachten Sie, dass ich kaum etwas am Code geändert habe. Nur Zeile 27 ist neu. Ich habe etwas sehr Ähnliches gemacht wie im dritten Ausdruck der for-Schleife, den Sie in Zeile 20 sehen können. Doch bevor wir darauf eingehen, wollen wir uns das Ergebnis ansehen. Sie ist gleich unten zu sehen.
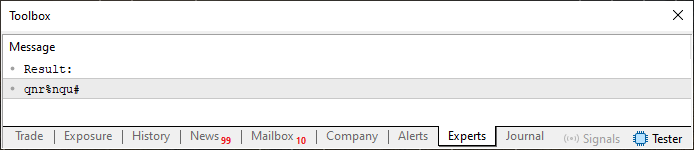
Abbildung 02
Sie werden sehen, dass die wiederholten Zeichen, die wir vorher hatten, nicht mehr vorhanden sind. Durch die Änderung einer einzigen Zeile in Code 03 kann die Situation jedoch noch weiter verbessert werden. Wie in früheren Artikeln erläutert, funktioniert der in Zeile 27 verwendete ternäre Operator wie eine IF-Anweisung. Aus diesem Grund wird der erste berechnete Wert nicht angepasst. Alle nachfolgenden Werte werden jedoch auf der Grundlage des in der vorherigen Iteration verwendeten Index angepasst. Achten Sie hier genau darauf: Der für diese Anpassung verwendete Array-Wert ist nicht der in der Schleife in Zeile 20 berechnete Wert. Sie ist diejenige, die sich aus der in Zeile 13 definierten Zeichenkette ergibt. Um den genauen Wert zu ermitteln, müssen Sie also die ASCII-Tabelle konsultieren und diesen Wert zu dem in der Schleife in Zeile 20 berechneten addieren. Es mag ein wenig verwirrend erscheinen, aber eigentlich ist es ganz einfach, wenn man einmal darüber nachdenkt.
Nun möchte ich Ihre Aufmerksamkeit auf den Nullwert lenken, der im ternären Operator verwendet wird. Aus diesem Grund bleibt der erste Index unverändert. Aber was wäre, wenn wir diese Null durch einen anderen Wert ersetzen würden? Angenommen, wir ändern die Zeile 27 wie unten gezeigt.
psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 5) + psw[c]) % StringLen(szCodePhrase)]);
Das Ergebnis würde ganz anders aussehen, wie Sie in der folgenden Abbildung sehen können.
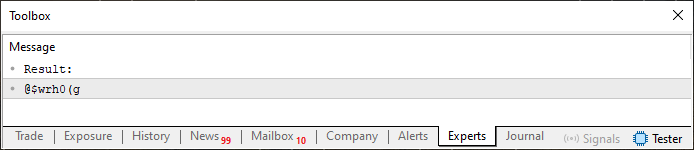
Abbildung 03
Interessant, nicht wahr? Mit einer einfachen Änderung können wir ein Passwort erstellen, das viele als sicher ansehen würden. Und wir haben dies mit einfachen Berechnungen und zwei leicht zu merkenden Sätzen getan. Vergessen Sie nicht, dass wir all dies mit Programmierkenntnissen erreicht haben, die ich noch als Anfänger einstufen würde. Gar nicht schlecht für jemanden, der gerade erst anfängt. Also, liebe Leserinnen und Leser, viel Spaß beim Erkunden und Experimentieren mit neuen Möglichkeiten. Was ich hier gezeigt habe, ist nur ein einfaches, grundlegendes Beispiel, das ein erfahrener Programmierer in wenigen Minuten umsetzen kann.
Gut, das war der einfachste Teil der Demonstration zur Verwendung von Arrays. Wir sind jedoch noch nicht ganz fertig. Bevor wir uns fortgeschritteneren und komplexeren Themen zuwenden können, müssen wir einige zusätzliche Details über Arrays behandeln. Wenden wir uns also einem neuen Thema zu.
Datentypen und ihre Beziehung zu Arrays
Eines der komplexesten, verwirrendsten und am schwierigsten zu beherrschenden Themen der Programmierung ist genau das Thema dieses Abschnitts. Vielleicht und wahrscheinlich haben Sie, liebe Leserin, lieber Leser, noch nicht begriffen, wie komplex dieses Thema wirklich ist. Manche halten sich für gute Programmierer, haben aber keine Ahnung, wie die Dinge zusammenhängen. Infolgedessen behaupten sie, bestimmte Aufgaben seien unmöglich oder schwieriger als sie tatsächlich sind.
Wenn Sie sich allmählich in dieses Thema vertiefen, werden Sie beginnen, viele andere Konzepte zu verstehen, die auf den ersten Blick nicht miteinander verbunden zu sein scheinen, aber auf einer tieferen Ebene sind sie alle grundlegend miteinander verbunden.
Denken wir zunächst an den Computerspeicher. Dabei spielt es keine Rolle, ob es sich um einen 8-Bit-, 16-Bit-, 32-Bit- oder 64-Bit-Prozessor handelt, oder sogar um einen ungewöhnlichen wie 48-Bit. Das ist unerheblich. Ebenso spielt es keine Rolle, ob wir es mit einem binären, oktalen, hexadezimalen oder einem anderen Zahlensystem zu tun haben. Auch das macht keinen Unterschied. Entscheidend ist, wie die Datenstrukturen aufgebaut sind. Wer hat zum Beispiel beschlossen, dass ein Byte acht Bits haben muss? Und warum acht? Könnten es nicht auch zehn oder zwölf Bits sein?
Vielleicht macht dieser Gedankengang im Moment nicht viel Sinn. Das liegt daran, dass es wirklich schwierig ist, jahrzehntelange Erfahrung in etwas zu destillieren, das für Anfänger verständlich ist. Ohne sich vorschnell in bestimmte Konzepte zu vertiefen, kann die Erörterung von Themen wie diesem recht schwierig sein. Aber auf der Grundlage dessen, was wir bereits in früheren Artikeln behandelt haben, können wir hier ein wenig Spaß haben. Lassen Sie uns mit einem Array eines Datentyps und einer Variablen eines völlig anderen Typs arbeiten. Es gibt jedoch eine kleine Regel: Der verwendete Datentyp des Arrays DARF NICHT DERSELBE sein wie der der Variablen. Dennoch können wir dafür sorgen, dass sie miteinander kommunizieren und sogar den gleichen Wert haben, wenn wir ein paar einfache Regeln beachten.
Klingt kompliziert und nach etwas, für das man viel mehr Programmierkenntnisse braucht, oder? Probieren wir es aus und überzeugen wir uns selbst. Um die Sache noch angenehmer zu machen, bringen wir die Funktion aus dem vorherigen Artikel zurück - die Funktion, mit der wir Binärwerte in andere Formate umwandeln.
Das klingt nach einem guten Plan. Und da wir diese Art der Implementierung ausgiebig verwenden werden, um verschiedene Konzepte zu erklären, sollten wir diese Funktion in eine Header-Datei aufnehmen. Dies führt uns zu dem unten dargestellten Code.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
Code 04
Ein wichtiges Detail: Da es sich bei Code 04 um eine Header-Datei handelt, die ausschließlich für Tutorial-Skripte bestimmt ist, wird sie in einem Ordner innerhalb des Skript-Verzeichnisses abgelegt. Wie ich bereits erklärt habe, hat dies besondere Auswirkungen auf alles, was hier geschaffen wird, und ich werde diese Erklärung nicht wiederholen. Lassen Sie uns also weitermachen. Großartig. Beachten Sie dies, liebe Leserin, lieber Leser: Alle Werte, die wir konvertieren werden, sollten als vorzeichenlose Werte behandelt werden, zumindest bis wir dieses kleine Detail in der in Code 04 gezeigten Funktion korrigieren.
Sobald dies geschehen ist, können wir testen, ob alles richtig funktioniert. Dazu verwenden wir ein einfaches Skript:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation via standard library.\n" + 11. "Decimal: %I64u\n" + 12. "Octal : %I64o\n" + 13. "Hex : %I64X", 14. value, value, value 15. ); 16. PrintFormat("Translation personal.\n" + 17. "Decimal: %s\n" + 18. "Octal : %s\n" + 19. "Hex : %s\n" + 20. "Binary : %s", 21. ValueToString(value, 0), 22. ValueToString(value, 1), 23. ValueToString(value, 2), 24. ValueToString(value, 3) 25. ); 26. } 27. //+------------------------------------------------------------------+
Code 05
Nach der Ausführung dieses Skripts wird die Ausgabe wie in der folgenden Abbildung dargestellt sein:
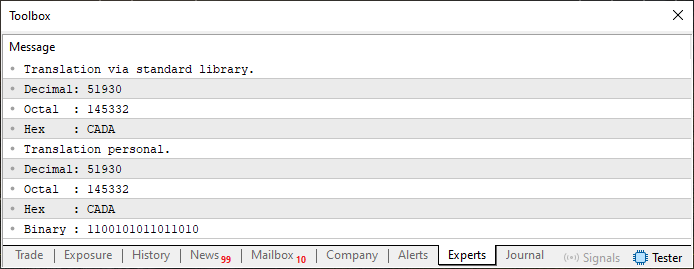
Abbildung 04
Es funktioniert eindeutig. Damit sind wir bereit, mit Arrays und Variablen verschiedener Datentypen zu experimentieren. Dies wird Ihnen helfen, ein sehr merkwürdiges Verhalten zu verstehen, das nur in bestimmten Programmiersprachen auftritt. Zu Beginn nehmen wir eine kleine Änderung an Code 05 vor. Diese Version wird als Ausgangspunkt dienen, den ich „NULLPUNKT“ nennen werde. Dies ist im Folgenden dargestellt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA}; 09. ushort value = 0; 10. 11. value = (array[0] << 8) | (array[1]); 12. 13. PrintFormat("Translation personal.\n" + 14. "Decimal: %s\n" + 15. "Octal : %s\n" + 16. "Hex : %s\n" + 17. "Binary : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2), 21. ValueToString(value, 3) 22. ); 23. } 24. //+------------------------------------------------------------------+
Code 06
Jetzt bitte ich Sie, liebe Leserin, lieber Leser, alle Ablenkungen und alles, was Ihre Aufmerksamkeit ablenken könnte, beiseite zu legen. Ich möchte, dass Sie sich von jetzt an voll und ganz auf das konzentrieren, was wir erforschen werden. Denn was ich jetzt erklären werde, ist etwas, das viele Programmieranfänger extrem verwirrt. Nicht alle Programmierer, aber vor allem diejenigen, die bestimmte Sprachen verwenden, wie z. B. MQL5.
Bevor wir uns in eine Erklärung vertiefen, wollen wir uns das Ergebnis der Ausführung von Code 06 ansehen. Sie können es gleich unten sehen:
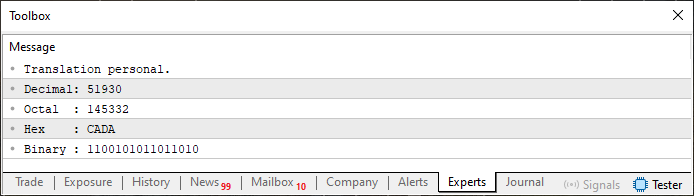
Abbildung 05
Was Sie hier im Code 06 sehen, bildet die Grundlage für eine breite Palette von Konzepten. Wenn Sie in der Lage sind, diesen Code wirklich zu verstehen, werden Sie alle folgenden Themen mit Leichtigkeit nachvollziehen können. Das liegt daran, dass viele dieser Themen in irgendeiner Weise mit dem zu tun haben, was dieser Code tut.
Auf den ersten Blick ist Ihnen vielleicht nicht klar, wie komplex dieser scheinbar einfache Code wirklich ist, oder was alles erreicht werden kann, nur weil diese Implementierung möglich ist. Also lassen wir es langsam angehen. Für diejenigen, die bereits über einige Erfahrung verfügen, wird nichts von dem, was folgt, neu sein. Aber für diejenigen, die noch lernen, könnten die Erklärungen hier verwirrend erscheinen.
Na gut, vielleicht bin ich ein bisschen zu weit gegangen. Spulen wir also ein wenig zurück und fragen: Welchen Teil des Code 06 verstehen Sie nicht, wenn Sie sich nur auf das stützen, was bisher erklärt wurde? Höchstwahrscheinlich sind es die Zeilen 8 und 11. Für jemanden, der gerade erst anfängt, scheinen diese Zeilen nicht viel Sinn zu machen. In früheren Abschnitten desselben Artikels haben wir etwas Ähnliches gesehen. Schauen Sie sich Code 03 an, insbesondere die Zeilen 15, 20, 23 und 27.
Im Code 06 funktionieren die Dinge jedoch ein wenig anders - nicht ganz, aber genug, um Verwirrung zu stiften. Und vielleicht liegt das daran, dass ich einen Fehler gemacht habe, indem ich Arrays verwendet habe, bevor ich sie richtig erklärt habe. Dafür möchte ich mich entschuldigen. Vor allem, wenn Sie sich jetzt ein wenig verloren fühlen, wie es der Fall sein könnte, wenn Sie die Ausgabe in Abbildung 05 sehen, die sich aus der Ausführung von Code 06 ergibt.
Lassen Sie uns also einen Schritt zurücktreten und die Dinge richtig angehen. Beginnen wir mit Zeile 11 von Code 06. Was wir dort haben, entspricht der folgenden Codezeile, die gerade unten gezeigt wird:
value = (0xCA << 8) | (0xDA);
Auf den ersten Blick mag dies ein wenig kompliziert erscheinen. Auch wenn wir bereits besprochen haben, wie der Verschiebeoperator funktioniert. Wenden wir uns einer visuellen Hilfe zu. Das macht die Dinge viel einfacher zu verstehen.
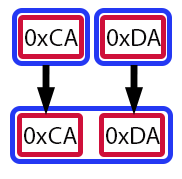
Abbildung 06
In dieser Abbildung steht jedes rote Rechteck für ein Byte oder, genauer gesagt, für einen Wert vom Typ uchar. Die blauen Rechtecke stellen Variablen dar. Die Pfeile zeigen an, wie sich die Werte während des Prozesses bewegen und verändern. Mit anderen Worten: Abbildung 06 zeigt, wie der Wert der Variablen value in Zeile 11 gebildet wurde. Mal sehen, ob ich das richtig verstanden habe: Sie sagen, dass, obwohl Wert vom Typ ushort ist, wir Werte vom Typ uchar in sie einfügen können? Und dabei können wir einen völlig neuen Wert konstruieren? Genau, lieber Leser. Aber das ist noch nicht alles. Wir sollten es langsam angehen, damit wir das Konzept vollständig verstehen können.
Wie Sie bereits wissen, ist der in Zeile 8 definierte Speicherbereich ein konstanter Bereich. Aber da ist noch etwas anderes. Da wir in diesem Speicherblock Werte initialisieren, könnte man ihn als eine Art ROM-Cartridge betrachten, ähnlich wie die Cartridges der Old-School-Spiele, die in alten Videospielkonsolen verwendet wurden.

Abbildung 07
Es mag seltsam klingen, von der Erstellung eines ROM in einem RAM zu sprechen, aber ja, das ist im Wesentlichen das, was Zeile 8 tut.
Aber warten Sie ab. Wie groß ist das ROM, das wir gerade in Zeile 8 erstellt haben? Es kommt darauf an, lieber Leser. Und nein, ich versuche nicht, der Frage auszuweichen. Ich bin ganz ehrlich. Glücklicherweise gibt es in der Standardbibliothek eine Funktion, mit der wir die Größe des zugewiesenen Blocks bestimmen können. Denken Sie daran, dass ein Array eine Zeichenkette ist - aber eine Zeichenkette ist eine besondere Art von Array, wie wir bereits besprochen haben. Im Gegensatz zu den Arrays, die in den vorherigen Beispielen verwendet wurden, wo wir Passwörter aus einfachen Phrasen generiert haben, ist das Array in Code 06 ein reines Array. Das heißt, es handelt sich nicht um eine Zeichenkette, sondern um eine beliebige Art von Wert. Da wir es jedoch als Array von uchar deklariert haben, schränken wir den Bereich der Werte ein, die wir darin speichern können. Hier wird es interessant: Wir können einen größeren Typ verwenden, um die im Array gespeicherten Werte zu interpretieren.
Dazu benötigen wir einen Datentyp, der alle Bits des Arrays aufnehmen kann. Das ist genau das, was Image 06 zu zeigen versucht. Der blaue Bereich stellt die Sammlung von Bits dar, aus denen das Array besteht, das als eine Einheit betrachtet wird. Um dieses Konzept noch deutlicher zu machen, fügen wir der Zeile 08 ein paar weitere Informationen hinzu und sehen, was passiert. Aber um die Dinge einfach zu halten, müssen wir den Code wie unten gezeigt anpassen.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+
Code 07
Ja, ich weiß. Was wir im Code 07 tun, mag wie völliger Wahnsinn erscheinen. Aber sehen Sie sich das Ergebnis an, das wir erhalten, wenn wir diesen Code ausführen. Sie können es unten sehen.
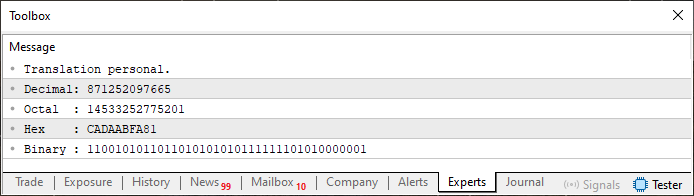
Abbildung 08
Das ist das, was man als völlig verrückt bezeichnen könnte. Aber wie Sie sehen können, liebe Leserin, lieber Leser, funktioniert es. Mit anderen Worten: Wir haben binäre, hexadezimale und dezimale Werte in einem einzigen Array kombiniert. Und am Ende haben wir einen kleinen ROM-ähnlichen Speicherblock gebaut, der eine Art von Information enthält. Aber das Tollste ist: Was Sie hier sehen, ist nur die Spitze eines riesigen Eisbergs.
Bevor wir tiefer eintauchen, sollten wir uns einen Moment Zeit nehmen, um zu verstehen, was hier eigentlich passiert ist und welche Einschränkungen und Vorsichtsmaßnahmen wir bei der Arbeit mit dieser Art von Einrichtung beachten müssen.
Sie haben vielleicht bemerkt, dass ich in Zeile acht einfach weitere Daten hinzugefügt habe. Wie viele Daten können wir dort maximal ablegen? Die Antwort lautet: EINE UNENDLICHE MENGE, oder zumindest so viel, wie Ihr System zulässt. In der Praxis hängt die Menge der Daten, die Sie aufnehmen können, ausschließlich von der Speicherkapazität Ihres Computers ab. Während wir jedoch in Zeile 8 praktisch unbegrenzt viele Werte in das Array eingeben können, gilt dies nicht für die Variable „value“. An dieser Stelle kommt eine harte Grenze ins Spiel. In diesem Beispiel wollte ich Ihnen, lieber Leser, die Freiheit geben, so viel wie möglich zu experimentieren. Ich habe also die maximale Bitkapazität verwendet, die derzeit in MQL5 unterstützt wird - 64 Bit oder acht Byte. Bedeutet das, dass wir nur acht Bytes in der Wertvariablen speichern können? Nicht ganz. Das bedeutet Folgendes: Sobald Sie 64 Bit erreicht haben, überschreiben alle neuen Daten die alten Werte. So entsteht ein Datenflussmodell, das wir später noch genauer untersuchen werden.
Es ist wichtig zu wissen, dass die Variable bis zu 64 Bits enthalten kann. Aber das bedeutet nicht unbedingt acht Werte. Und genau hier fangen die Dinge an, schwierig zu werden für diejenigen, die sich direkt auf diesen Artikel stürzen, ohne die früheren Artikel zu lesen oder zu üben, was dort erklärt wurde.
Bevor wir nun in die Schleife in Zeile 11 eintauchen und untersuchen, was in Zeile 12 passiert, wollen wir ein kleines Detail in Code 07 ändern. Durch diese Änderung wird das Konzept der Array-Größe und die darin enthaltene Informationsmenge viel klarer. Diese kleine Änderung ist in der folgenden Codezeile zu sehen.
const ushort array[] = {0xCADA, B'1010101111111010', 0x81}; Wenn Sie sich nun die geänderte Zeile oben ansehen, werden Sie feststellen, dass unser Array nicht mehr fünf Elemente hat, sondern nur noch drei. Und es ist wichtig zu beachten, dass wir, obwohl wir die Anzahl der Elemente geändert haben, immer noch fast die gleiche Menge an Speicher verwenden. Der Unterschied ist, dass wir jetzt 8 Bit Speicherplatz verschwenden. Das liegt daran, dass im Gegensatz zu Code 07, wo jedes Byte vollständig genutzt wurde, in dieser neuen Struktur der letzte Wert im Array nur 8 der 16 verfügbaren Bits verwendet. Das mag wie ein akzeptables Maß an Verschwendung erscheinen. Darauf werden wir später noch eingehen. Denken Sie daran: Der verwendete Datentyp beeinflusst die Speichernutzung. In einigen Fällen beeinflusst sie auch das Verhalten Ihres Codes.
Es gibt jedoch ein noch schlimmeres Szenario: wenn Sie etwas wie die unten gezeigte Zeile verwenden.
const int array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; Ich weiß, dass sich viele Entwickler nicht darum kümmern, für jede Variable den am besten geeigneten Datentyp zu verwenden. Aber auch wenn es ein Problem mit der Verwendung dieser Zeile in Code 07 zu geben scheint (und in unserem aktuellen Fall gibt es wirklich keins), verschwenden Sie nicht mehr nur 8 Bits pro Element. Sie verschwenden jetzt 16 Bits pro Element im Array. Bei fünf Elementen sind das 80 Bits oder 10 Bytes, was mehr ist als die Breite des Passworts, das wir am Anfang des Artikels erstellt haben.
Auch diese Speicherverschwendung mag vernachlässigbar erscheinen, vor allem wenn man bedenkt, dass die heutigen Rechner oft mit 32 GB oder mehr RAM ausgestattet sind. Und selbst mit diesem Abfall in unserem aktuellen Beispiel wird sich das Verhalten des Codes nicht ändern. Dies ist der Logik in den Zeilen 11 und 12 zu verdanken, die wir nun aufschlüsseln werden.
Hier teilen wir dem Code mit, dass für jedes Element im Array der in „value“ gespeicherte Wert um 8 Bit nach links verschoben werden soll, um Platz für das neue Element zu schaffen. Genau das passiert in Zeile 12. Diese Zeile zielt jedoch speziell auf ein bestimmtes Element in dem durch die Variable „c“ angegebenen Array ab. Woher wissen wir, wie viele Elemente sich in dem Array befinden? Schauen Sie sich Zeile 11 an. Der zweite Ausdruck in der for-Schleifenbedingung liefert diese Informationen. Was wir hier tun, ist der Aufruf einer Standardbibliotheksfunktion in MQL5.
Diese Funktion ist äquivalent zur Verwendung von ArraySize(). Auf diese Weise bestimmen wir, wie viele Elemente in der Matrix vorhanden sind, unabhängig davon, wie viele Bits jedes Element tatsächlich verwendet.
Um mit diesem Verhalten zu experimentieren, ändern Sie den Code einfach so ab, dass er wie die unten gezeigte Version aussieht.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. Print("Number of elements in the array: ", ArraySize(array)); 25. } 26. //+------------------------------------------------------------------+
Code 08
Wenn wir Code 08 ausführen, können wir die Anzahl der Elemente im Array sehen, wie im hervorgehobenen Bereich in der folgenden Abbildung dargestellt.
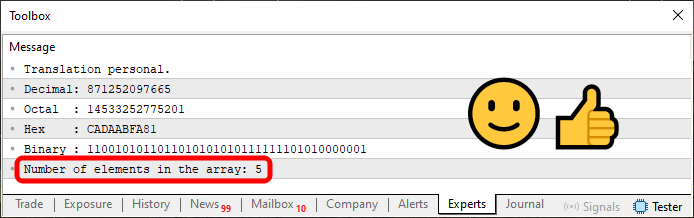
Abbildung 09
Abschließende Überlegungen
Nun, mein lieber Leser, dieser Artikel enthält bereits eine Fülle von Material, das Sie studieren und aufnehmen sollten. Deshalb gebe ich Ihnen etwas Zeit, um alles, was wir bisher behandelt haben, zu wiederholen und zu üben. Versuchen Sie, diese grundlegenden Konzepte im Zusammenhang mit der Arbeit mit Arrays wirklich zu verstehen. Auch wenn die in diesem Artikel verwendeten Arrays vom Typ ROM sind, was bedeutet, dass ihr Inhalt nicht verändert werden kann, ist es dennoch von entscheidender Bedeutung, dass Sie Ihr Bestes tun, um zu verstehen, was hier erklärt wird. Ich weiß, dass es schwierig sein kann, dieses Material auf einmal zu verdauen, aber ich ermutige Sie, sich die Mühe zu machen und in Ihrem Streben nach einem tieferen Verständnis engagiert zu bleiben.
Die Beherrschung der Konzepte in diesem und den vorangegangenen Artikeln wird Ihre Entwicklung als Programmierer erheblich unterstützen. Und da die Materie von nun an immer komplexer wird, werden Sie zunehmend gefordert sein. Aber lassen Sie sich von den Schwierigkeiten nicht entmutigen - nehmen Sie sie an. Üben Sie unbedingt und ziehen Sie die beigefügten Dateien zu Rate, um Themen zu verstehen, die im Artikel nicht vollständig dargestellt, aber am Rande erwähnt wurden. Einige Beispiele sind Code-Änderungen, die diskutiert wurden, deren Ergebnisse aber nicht gezeigt wurden. Es ist sehr wichtig, dass Sie verstehen, wie sich diese Veränderungen auf den Speicher auswirken. Viel Spaß beim Erkunden der beigefügten Dateien.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15462
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.