Diskussion zum Artikel "Entwicklung eines Expert Advisors für mehrere Währungen (Teil 19): In Python implementierte Stufen erstellen"
Hallo,
wir starten Python, indem wir den Shell-Befehl in diesem Code ausführen:
//+------------------------------------------------------------------+ //| Starten Sie eine Aufgabe| //+------------------------------------------------------------------+ void COptimizerTask::Start() { PrintFormat(__FUNCTION__" | Task ID = %d\n%s", m_id, m_setting); // Wenn es sich um eine EA-Optimierungsaufgabe handelt if(m_type == TASK_TYPE_EX5) { // Start einer neuen Optimierungsaufgabe im Prüfgerät MTTESTER::CloseNotChart(); MTTESTER::SetSettings2(m_setting); MTTESTER::ClickStart(); // Aktualisieren des Aufgabenstatus in der Datenbank DB::Connect(); string query = StringFormat( "UPDATE tasks SET " " status='Processing' " " WHERE id_task=%d", m_id); DB::Execute(query); DB::Close(); // Wenn es sich um eine Aufgabe zur Ausführung eines Python-Programms handelt } else if (m_type == TASK_TYPE_PY) { PrintFormat(__FUNCTION__" | SHELL EXEC: %s", m_pythonPath); // Aufruf einer Funktion des Betriebssystems (Windows) zur Ausführung eines Shell-Befehls ShellExecuteW(NULL, NULL, m_pythonPath, m_setting, NULL, 1); } }
Wobei:
- m_pythonPath ein Pfad zu Python auf dem aktuellen Computer ist;
- m_setting ist ein String mit dem Namen des ausgeführten Python-Programms und dessen Kommandozeilenargumenten
hallo
zuerst habe ich Satge 1 optimiert und abgeschlossen
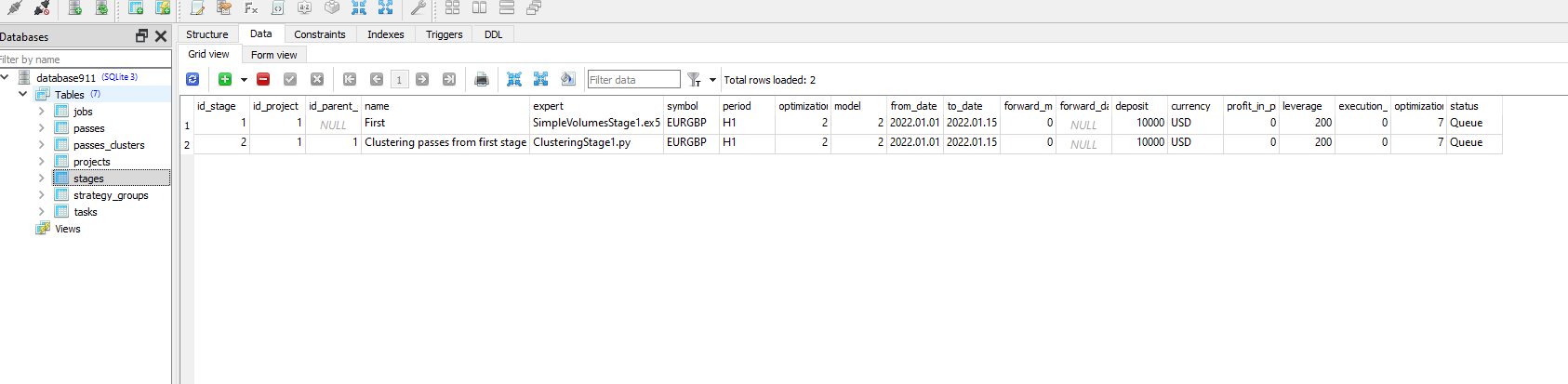
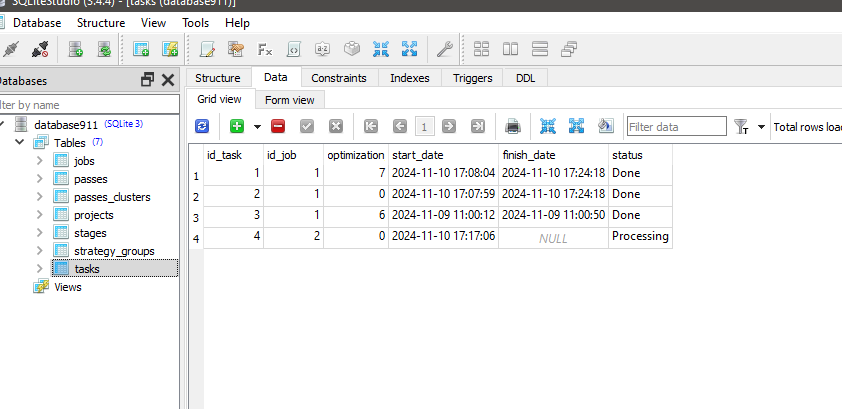
dann fügte ich ClusteringStage1.py und Task und Job zur Datenbank hinzu und optimierte erneut, aber es funktionierte nicht, nur diese Meldung :
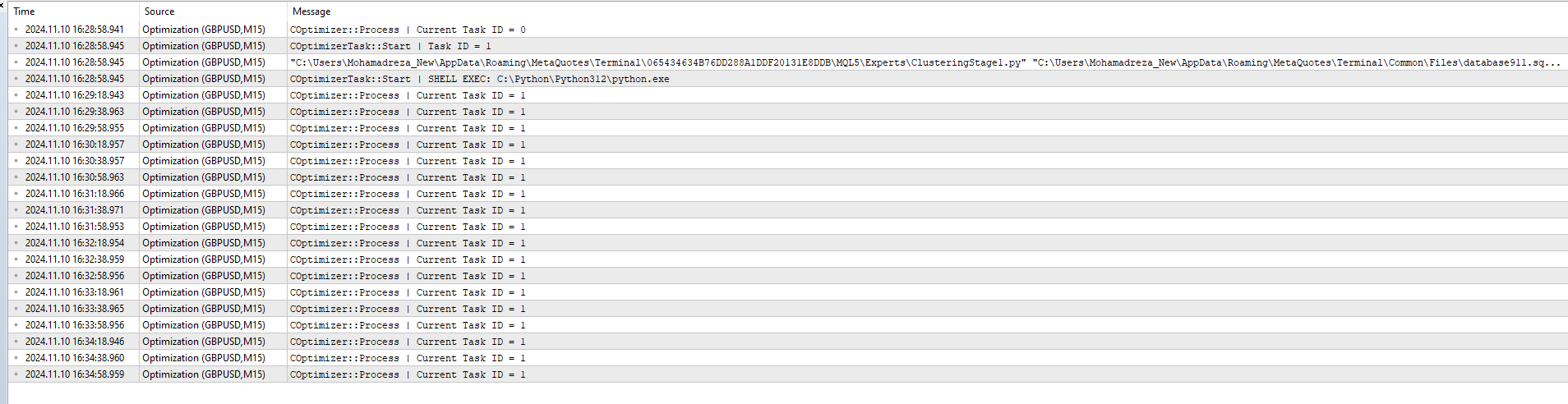
2024.11.10 16:35:18.952 Optimierung ( GBPUSD , M15) COptimizer::Process | Current Task ID = 1
{kind=link}
Hallo
es scheint, dass die Ausführung des Python-Programms den Status der Aufgabe mit id_task=1 nicht ändert.
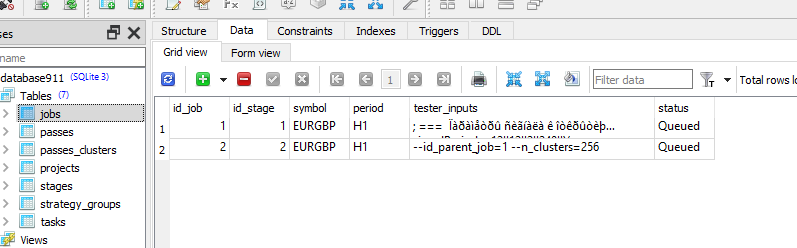
Überprüfen Sie, ob Sie im Auftrag für diese Aufgabe die richtigen Werte in der Spalte [tester_inputs] haben. Das sind:
--id_parent_job=1 --n_clusters=256
wobei 1 id_job für den Job der ersten Stufe ist. In Ihrem Fall kann es ein anderer Zahlenwert sein.
Sie können auch versuchen, das Python-Programm mit den aktuellen Parametern manuell von der Kommandozeile aus zu starten, dann können Sie mögliche Fehlermeldungen sehen
Hallo
Es scheint, dass die Ausführung von Python-Programm nicht den Status für Aufgabe mit id_task =1 ändern.
Überprüfen Sie, ob Sie im Auftrag für diese Aufgabe die richtigen Werte in der Spalte [tester_inputs] haben. Das sind:
wobei 1 id_job für den Auftrag der ersten Stufe ist. In Ihrem Fall kann es ein anderer Zahlenwert sein.
Sie können auch versuchen, das Python-Programm mit den aktuellen Parametern manuell von der Kommandozeile aus zu starten, dann können Sie mögliche Fehlermeldungen sehen
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
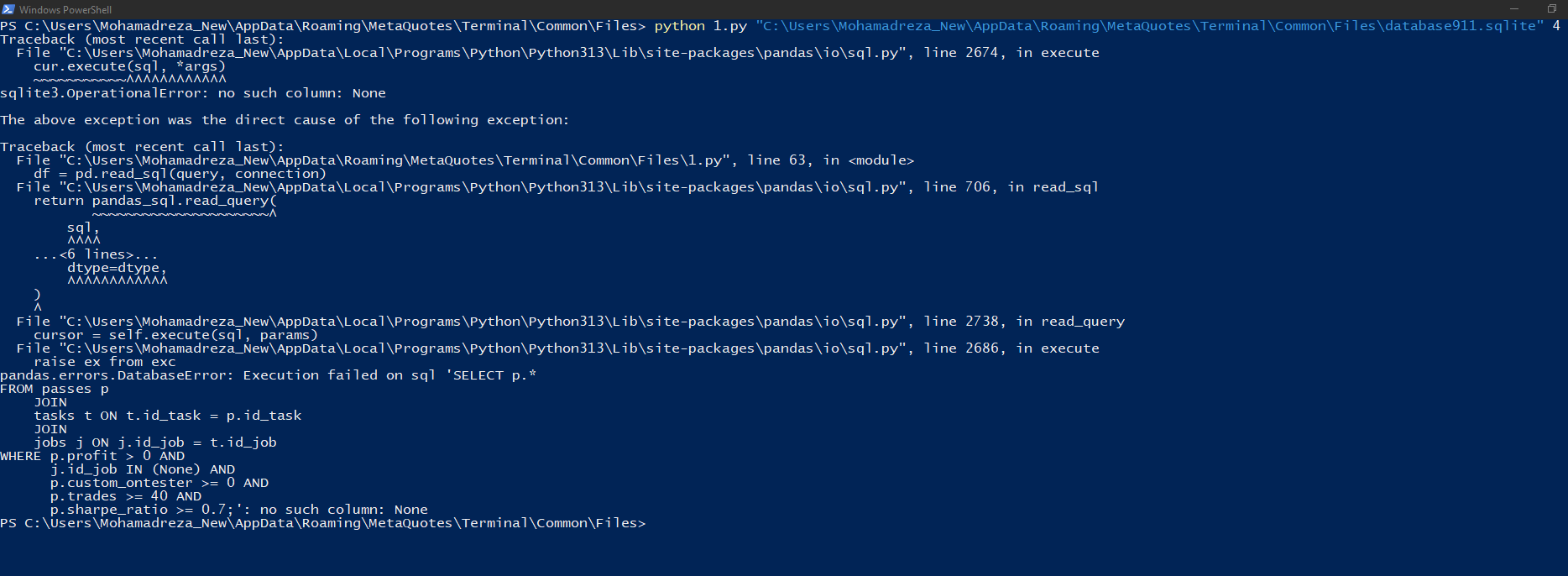
Ich führe die Powershell aus und sehe dies
Versuchen Sie, es so auszuführen:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" usage: ClusteringStage1.py [-h] [--id_parent_job ID_PARENT_JOB] [--n_clusters N_CLUSTERS] [--min_custom_ontester MIN_CUSTOM_ONTESTER] [--min_trades MIN_TRADES] [--min_sharpe_ratio MIN_SHARPE_RATIO] db_path id_task ClusteringStage1.py: error: the following arguments are required: db_path, id_task
Wir müssen die Argumente festlegen: db_path, id_task. Dann erhalten wir die Fehlermeldung, die Sie gepostet haben:
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 Traceback (most recent call last): File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2674, in execute cur.execute(sql, *args) sqlite3.OperationalError: no such column: None The above exception was the direct cause of the following exception: Traceback (most recent call last): ... File "C:\Python\Python312\Lib\site-packages\pandas\io\sql.py", line 2686, in execute raise ex from exc pandas.errors.DatabaseError: Execution failed on sql 'SELECT p.* FROM passes p JOIN tasks t ON t.id_task = p.id_task JOIN jobs j ON j.id_job = t.id_job WHERE p.profit > 0 AND j.id_job IN (None) AND p.custom_ontester >= 0 AND p.trades >= 40 AND p.sharpe_ratio >= 0.7;': no such column: None
Wir müssen auch zwei Argumente festlegen: --id_parent_job=1 --n_clusters=256
C:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911>python -u "c:\Program Files\MetaTrader 5\MQL5\Experts\Articles\2024-09-18.15911\ClusteringStage1.py" "C:\Users\Antekov\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
Was erhalten Sie?
Ich führe Folgendes aus
python -u "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1. py.py" "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=256
und erhalte folgende Fehlermeldung
ValueError: n_samples=150 sollte >= n_clusters=256 sein.
Dann ändere ich n_clusters=150 und führe aus
python -u "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\4B1CE69F577705455263BD980C39A82C\MQL5\Experts\ClusteringStage1.py" "C:\Benutzer\Mohamadreza_New\AppData\Roaming\MetaQuotes\Terminal\Common\Files\database911.sqlite" 4 --id_parent_job=1 --n_clusters=150
und ich denke, es hat funktioniert. aber in der Datenbank keine Änderung
Danach habe ich versucht, mit n_samples=150 zu optimieren , aber es hat nicht funktioniert .
Interessanter Artikel! Dann werde ich die ganze Serie lesen.
Для исправления этой досадной нелепости мы можем пойти двумя путями. Первый состоит в том, чтобы найти готовую реализацию алгоритма кластеризации, написанную на MQL5 или написать её самостоятельно, если поиск не даст хороших результатов. Второй путь подразумевает добавление возможности запускать на нужных стадиях процесса автоматической оптимизации не только советники, написанные на MQL5, но и программы на Python.
Warum haben sie die Funktionalität der AlgLib-Bibliothek aufgegeben?
#include <Math\Alglib\alglib.mqh> Minus nur bei der Geschwindigkeit, aber hauptsächlich, weil Python die Berechnungen auf allen Kernen parallelisiert.
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Neuer Artikel Entwicklung eines Expert Advisors für mehrere Währungen (Teil 19): In Python implementierte Stufen erstellen :
Für das Clustering haben wir die fertige Python-Bibliothek scikit-learn verwendet, genauer gesagt, die Implementierung des Algorithmus K-Means. Dies ist nicht der einzige Clustering-Algorithmus, aber die Betrachtung anderer möglicher Algorithmen, der Vergleich und die Auswahl des besten Algorithmus, wie er auf dieses Problem angewandt wurde, überstieg die akzeptablen Grenzen. Daher wurde im Wesentlichen der erste Algorithmus verwendet, der zur Verfügung stand, und die damit erzielten Ergebnisse erwiesen sich als recht gut.
Die Verwendung dieser speziellen Implementierung machte es jedoch erforderlich, ein kleines Python-Programm auszuführen. Dies war kein allzu großes Problem, als wir die meisten Vorgänge noch manuell durchführten. Aber jetzt, wo wir erhebliche Fortschritte bei der Automatisierung des gesamten Prozesses des Testens und der Auswahl guter Gruppen einzelner Handelsstrategie-Instanzen gemacht haben, sieht es schlecht aus, wenn selbst ein einfacher manueller Vorgang in der Mitte einer Pipeline von sequentiell ausgeführten Optimierungsaufgaben steht.
Um dies zu beheben, können wir zwei Wege einschlagen. Die erste besteht darin, eine fertige MQL5-Implementierung des Clustering-Algorithmus zu finden oder ihn selbst zu implementieren. Die zweite beinhaltet die Möglichkeit, nicht nur in MQL5 geschriebene EAs zu starten, sondern auch Python-Programme in den erforderlichen Phasen der automatischen Optimierung.
Autor: Yuriy Bykov