
Von der Grundstufe bis zur Mittelstufe: Definitionen (I)

Einführung
Die hier zur Verfügung gestellten Materialien sind ausschließlich für Bildungszwecke bestimmt. Sie sollte in keiner Weise als endgültige Bewerbung angesehen werden. Es geht nicht darum, die vorgestellten Konzepte zu erforschen.
Im vorherigen Artikel „Von der Grundstufe zur Mittelstufe: Rekursion“ haben wir besprochen, was Rekursion ist und wie sie als sehr nützliche Programmiertechnik in verschiedenen Szenarien verwendet werden kann. Sie ermöglicht es uns, Mechanismen und Implementierungen auf einfache Weise zu erstellen. Allerdings muss man damit rechnen, dass der Code manchmal langsamer läuft, daher sollte man in solchen Fällen Geduld haben.
Aber im Allgemeinen hilft uns die Rekursion und macht unser Leben viel einfacher. Daher sollte es ein Lerngegenstand für diejenigen sein, die ein erfahrener Spezialist werden wollen (oder zumindest ein gutes Verständnis der mit der Programmierung verbundenen Dinge im Allgemeinen haben).
Dieser Artikel befasst sich mit dem Thema, das bereits zuvor behandelt wurde: die Verwendung von Definitionen, sowohl um Makros zu erstellen als auch um bestimmte Teile zu deklarieren und genauer zu kontrollieren, die von uns oder von anderen Programmierern implementiert werden, deren Code Sie interessiert und die Sie kontrolliert ändern möchten, um bestimmte Ziele zu erreichen.
Welche Definitionen werden wir haben?
Definitionen können innerhalb ein und desselben Codes unterschiedliche Formen annehmen und je nach Sprache und Ziel, das der Programmierer erreichen möchte, geringfügige Änderungen in Bezug auf Konzepte und Verwendungszweck erfahren. Im Allgemeinen hilft uns die Definition, den Code einfach, schnell und sicher zu kontrollieren und zu ändern, indem wir Makros, Kompilieranweisungen oder spezielle Konstanten deklarieren. Auf jeden Fall werden Ihnen die Definitionen gefallen, und Sie werden sie sehr mögen, wenn Sie versuchen zu verstehen, wie sie funktionieren, und werden daran arbeiten, sie so oft wie möglich zu verwenden. Vor allem aber werden Sie Spaß an der Verwendung von Definitionen haben, wenn Sie gerne kleinere Änderungen an Ihrem Code vornehmen, um die Ergebnisse dieser Änderungen zu testen. Dies ist dank der Definitionen möglich, die dies auf sehr einfache und praktische Weise ermöglichen.
Außerdem werden wir uns die Definitionen ansehen, die sich an der Verwendung von Kompilieranweisungen orientieren. Es gibt auch andere Arten von Definitionen, die bei der Verwendung externer Programmierung sowie beim Import von in anderen Umgebungen erstelltem Code zur gemeinsamen Verwendung mit MQL5 erstellt werden. Diese Definitionen setzen jedoch voraus, dass wir Erfahrung in der eingebetteten Programmierung haben, auch wenn wir nur MQL5 als Hauptsprache verwenden werden.
Mit MQL5 können Sie zum Beispiel Code und Funktionen importieren, die von anderen Programmierern erstellt wurden, typischerweise in C oder C++. So können Sie dem MetaTrader 5 Funktionen oder Elemente von persönlichem Interesse hinzufügen, wie z. B. einen Videoplayer, oder sogar ein Dienstprogramm zur Erstellung fortgeschrittener wissenschaftlicher Charts entwickeln, mit der Möglichkeit, eine Sprache wie LaTeX zu verwenden, die es Ihnen ermöglicht, mathematische Ausdrücke zu formatieren, falls Sie diese nicht kennen. Es ist übrigens sehr interessant.
Da wir uns auf Kompilieranweisungen als Mittel zur Erstellung von Definitionen konzentrieren werden, wird das Thema viel einfacher und angenehmer sein. Und ich bin sicher, dass Sie es schnell verstehen werden, da wir es in der einen oder anderen Form bereits in früheren Artikeln vorgestellt haben. Wir beginnen also mit der Richtlinie #define selbst.
Diese Kompilierungsrichtlinie ist sehr spezifisch. Das liegt daran, dass wir bei seiner Verwendung eine Konstante oder ein Makro erstellen können. Das ist im Grunde alles, was wir mit dieser Richtlinie tun können. Wie die Direktive #include, die bereits in einem anderen Artikel behandelt wurde, in diesem Fall „Von der Grundstufe bis zur Mittelstufe: Die Direktive Include“. Diese Direktive #define ermöglicht es uns zusammen mit anderen Kompilierungsdirektiven, eine Reihe von kleinen, leicht zu erstellenden und zu ändernden Einstellungen zu erzeugen. Im vorigen Artikel haben wir zum Beispiel den folgenden Code gesehen:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const uchar who = 6; 07. 08. Print("Result: ", Fibonacci_Recursive(who)); 09. Print("Result: ", Fibonacci_Interactive(who)); 10. } 11. //+------------------------------------------------------------------+ 12. uint Fibonacci_Recursive(uint arg) 13. { 14. if (arg <= 1) 15. return arg; 16. 17. return Fibonacci_Recursive(arg - 1) + Fibonacci_Recursive(arg - 2); 18. } 19. //+------------------------------------------------------------------+ 20. uint Fibonacci_Interactive(uint arg) 21. { 22. uint v, i, c; 23. 24. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 25. v += i; 26. 27. return (c == arg ? i : v); 28. } 29. //+------------------------------------------------------------------+
Code 01
Beachten Sie, dass wir in Zeile 6 eine Konstante vom Typ uchar definiert haben. Beachten Sie jedoch, dass die Funktionen, die einen Wert empfangen müssen, einen Wert vom Typ uint erwarten, wie in den Zeilen 12 und 20 zu sehen ist. Aber man sollte sich nicht ständig darauf einstellen. Dann können wir eine Kompilierungsrichtlinie verwenden, um Dinge wie diese schöner zu machen. Gleichzeitig kann es in einigen Fällen den Code etwas schneller machen. Nachfolgend sehen Sie, warum die Verwendung einer Kompilierungsanweisung anstelle einer Konstante unseren Code etwas schneller machen kann, sowie andere Dinge, die ebenfalls zur Verbesserung der Gesamtleistung beitragen.
Angenommen, wir wollen hier eine Kompilierrichtlinie verwenden, kann Code 01 wie folgt umgeschrieben werden:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define def_Fibonacci_Element 6 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. Print("Result: ", Fibonacci_Recursive(def_Fibonacci_Element)); 09. Print("Result: ", Fibonacci_Interactive(def_Fibonacci_Element)); 10. } 11. //+------------------------------------------------------------------+ . . .
Code 02
Natürlich werden wir nicht den gesamten Code wiederholen, denn das ist nicht nötig. Aber sehen Sie sich an, wie wir es umgesetzt haben. Es scheint keinen Unterschied zu machen, aber es gibt wirklich einen Unterschied, mein lieber Leser. Für diejenigen, die den Code lesen, mag es gleich aussehen, aber für den Compiler ist Code 01 anders als Code 02, weil wir in Code 02 die #define-Direktive verwenden.
Der Compiler sieht also den unten abgebildeten Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. Print("Result: ", Fibonacci_Recursive(6)); 07. Print("Result: ", Fibonacci_Interactive(6)); 08. } 09. //+------------------------------------------------------------------+ . . .
Code 03
Aber Moment mal: Das entspricht dem Code 01. Daher ist es nicht sinnvoll, diese Richtlinie zu verwenden. Im Grunde ist alles sehr logisch. Wir dürfen nur nicht vergessen, dass wir hier an Dingen zu Bildungszwecken interessiert sind. Es kann eine große Anzahl von Positionen in unserem Code geben, die einen bestimmten Wert verwenden müssen. Wenn wir eine Konstante verwenden, selbst wenn es sich um eine globale Konstante handelt, können wir irgendwann Probleme bekommen, weil diese Konstante existiert.
Wenn wir jedoch eine Definition wie in Code 02 verwenden, können wir viel mehr Kontrolle über den Code gewinnen. Außerdem wird eine Konstante, sofern sie nicht global ist, nur innerhalb der Prozedur, in der sie deklariert wurde, gespeichert bzw. sichtbar. Andererseits ist es eine Richtlinie - ja, denn wenn sie einmal deklariert ist, können wir sie überall im Code ohne Probleme verwenden, solange sie existiert. Denn im Gegensatz zu globalen Konstanten kann eine Richtlinie jederzeit zerstört werden, ihr Wert kann geändert werden, oder sie kann sogar eine völlig andere Funktion haben als eine andere Richtlinie mit demselben Namen.
Gehen wir nun einen nach dem anderen durch, da jeder der hier genannten Punkte wichtig ist und Sie ihn vielleicht irgendwann einmal brauchen. Schauen wir uns zuerst das Problem der Sichtbarkeit an. Es ist ein ziemlich einfacher Fall, wie Sie im untenstehenden Code sehen können:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define def_Fibonacci_Element_Default 6 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. Print("Result: ", Fibonacci_Recursive()); 09. Print("Result: ", Fibonacci_Interactive()); 10. } 11. //+------------------------------------------------------------------+ 12. uint Fibonacci_Recursive(uint arg = def_Fibonacci_Element_Default) 13. { 14. if (arg <= 1) 15. return arg; 16. 17. return Fibonacci_Recursive(arg - 1) + Fibonacci_Recursive(arg - 2); 18. } 19. //+------------------------------------------------------------------+ 20. uint Fibonacci_Interactive(uint arg = def_Fibonacci_Element_Default) 21. { 22. uint v, i, c; 23. 24. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 25. v += i; 26. 27. return (c == arg ? i : v); 28. } 29. //+------------------------------------------------------------------+
Code 04
Beachten Sie Folgendes: In Zeile 4 deklarieren wir eine Kompilieranweisung für einen konstanten Typ. Sie ist im gesamten Code sichtbar und hat den gleichen Typ und das gleiche erwartete Ergebnis, wenn wir einen Standardwert für ein Argument in einer Funktion oder Prozedur definieren. Die gleiche Kompilieranweisung kann jedoch auch durch eine globale Konstante ersetzt werden. Aber hier wird es interessant, denn mit einer Konstanten können wir nicht das tun, was der folgende Code zeigt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define def_Fibonacci_Element_Default 6 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. Print("Result: ", Fibonacci_Recursive()); 09. Print("Result: ", Fibonacci_Interactive()); 10. } 11. //+------------------------------------------------------------------+ 12. uint Fibonacci_Recursive(uint arg = def_Fibonacci_Element_Default) 13. { 14. if (arg <= 1) 15. return arg; 16. 17. return Fibonacci_Recursive(arg - 1) + Fibonacci_Recursive(arg - 2); 18. } 19. //+------------------------------------------------------------------+ 20. #undef def_Fibonacci_Element_Default 21. //+------------------------------------------------------------------+ 22. uint Fibonacci_Interactive(uint arg = def_Fibonacci_Element_Default) 23. { 24. uint v, i, c; 25. 26. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 27. v += i; 28. 29. return (c == arg ? i : v); 30. } 31. //+------------------------------------------------------------------+
Code 05
Beachten Sie, dass wir in Zeile 20 dieses Codes eine weitere Kompilieranweisung verwenden. Dies ist #undef. Mit dieser Richtlinie können wir eine Richtlinie entfernen oder zerstören, die mit dem in #undef directive enthaltenen Namen definiert ist. Solche Funktionen sind sehr nützlich. Bevor wir jedoch über kritischere Dienstprogramme sprechen, müssen wir erörtern, was passiert, wenn wir versuchen, Code 05 zu kompilieren. Beim Versuch zu kompilieren, meldet der Compiler den folgenden Fehler:

Abbildung 01
Das zeigt an, dass der Fehler in Zeile 22 aufgetreten ist. Die Konstante def_Fibonacci_Element_Default wurde jedoch in Zeile 20 zerstört. Wenn der Compiler also versucht, die genannte Konstante in der Datenbank zu finden, um den Code zu kompilieren, wird er sie nicht finden. Dies führt zu dem Fehler, den Sie in Abbildung 01 sehen. Aus diesem Grund haben viele Programmierer die Angewohnheit, dem Fehler ein Präfix voranzustellen, um die Art des generierten Fehlers zu identifizieren. Dies ist keine Regel, sondern eine gute Programmierpraxis. Ich möchte zum Beispiel jeder definierten Konstante das Präfix def_ voranstellen, damit ich eine allgemeine Konstante von einer Kompilieranweisung unterscheiden kann.
„Okay, aber was ist, wenn wir einen anderen Wert für die Richtlinie deklarieren wollen, gleich nachdem sie zerstört wurde, können wir das tun?“ Natürlich, mein lieber Leser! Aber wir müssen einfach vorsichtig sein. Später werde ich Ihnen zeigen, wie Sie dies vermeiden und unnötige Kopfschmerzen vermeiden können. Es ist kein 100%iges Instrument, aber es hilft zumindest. Wir werden jedoch sehen, was passiert, wenn wir die Richtlinie wie vorgeschlagen ändern.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define def_Fibonacci_Element_Default 6 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. Print("Result: ", Fibonacci_Recursive()); 09. Print("Result: ", Fibonacci_Interactive()); 10. } 11. //+------------------------------------------------------------------+ 12. uint Fibonacci_Recursive(uint arg = def_Fibonacci_Element_Default) 13. { 14. if (arg <= 1) 15. return arg; 16. 17. return Fibonacci_Recursive(arg - 1) + Fibonacci_Recursive(arg - 2); 18. } 19. //+------------------------------------------------------------------+ 20. #undef def_Fibonacci_Element_Default 21. //+----------------+ 22. #define def_Fibonacci_Element_Default 7 23. //+------------------------------------------------------------------+ 24. uint Fibonacci_Interactive(uint arg = def_Fibonacci_Element_Default) 25. { 26. uint v, i, c; 27. 28. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 29. v += i; 30. 31. return (c == arg ? i : v); 32. } 33. //+------------------------------------------------------------------+
Code 06
In Code 06 sehen wir also, wie der Vorschlag umgesetzt wurde. Beachten Sie, dass wir in Zeile 22 einen neuen Wert für die Richtlinie definieren, und wenn dieser Code ausgeführt wird, sieht das Ergebnis wie unten dargestellt aus:
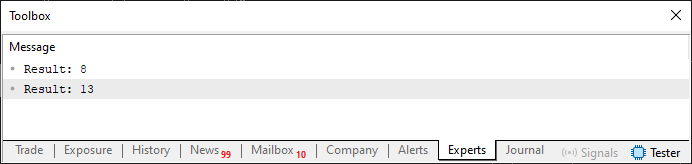
Abbildung 02
Wie Sie bemerkt haben, sind die Ergebnisse unterschiedlich, aber das ist gerade wegen der Änderung des Wertes zu erwarten. Wäre die in Zeile 4 definierte Direktive eine globale Konstante, könnten wir die in Zeile 22 gezeigte Änderung nicht vornehmen und die globale Konstante auch nicht aus anderen Teilen des Codes entfernen. Dies ist die Grundlage, die Sie versuchen sollten zu verstehen. Es ist nicht nur etwas, das man auswendig lernen muss, sondern etwas, das man verstehen und annehmen muss.
Okay, wir haben gesehen, dass die Kompilieranweisungen #define und #undef auf einfache Weise zusammen verwendet werden können. Denn, wie ich kürzlich erwähnte, gibt es raffiniertere Möglichkeiten, diese beiden Direktiven zusammen zu verwenden. Dazu müssen wir jedoch andere Richtlinien verwenden, die die Arbeit vereinfachen und die Kontrolle erleichtern.
Kontrolle der Codeversion
Eine der interessantesten Anwendungen der Direktiven #define und #undef ist die Kontrolle von Versionen desselben Codes. Da dieser Code zur Berechnung eines Elements in der Fibonacci-Folge sehr einfach zu verstehen ist, werden wir ihn zur Erklärung der Versionskontrolle verwenden.
Angenommen, wir wissen nicht, wie wir eine Version der iterativen Berechnung für ein bestimmtes Element der Fibonacci-Folge erstellen können, oder wir möchten eine Berechnung erstellen, die sich von der bisher im Code gezeigten unterscheidet. Sie denken vielleicht, dass dies einfach zu machen ist, aber früher oder später werden Sie einen Fehler machen. Wenn Sie jedoch Kompilieranweisungen verwenden, wird das Risiko eines Fehlers stark reduziert. Zum Beispiel können wir Berechnungen isolieren, um zu entscheiden, ob wir iterative oder rekursive Berechnungen wünschen. Erstellen Sie dazu einfach etwas Ähnliches wie unten abgebildet:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define DEF_INTERACTIVE 05. //+----------------+ 06. #define def_Fibonacci_Element_Default 6 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. Print("Result: ", Fibonacci()); 11. } 12. //+------------------------------------------------------------------+ 13. #ifndef DEF_INTERACTIVE 14. //+----------------+ 15. uint Fibonacci(uint arg = def_Fibonacci_Element_Default) 16. { 17. if (arg <= 1) 18. return arg; 19. 20. return Fibonacci(arg - 1) + Fibonacci(arg - 2); 21. } 22. //+----------------+ 23. #endif 24. //+------------------------------------------------------------------+ 25. #ifdef DEF_INTERACTIVE 26. //+----------------+ 27. uint Fibonacci(uint arg = def_Fibonacci_Element_Default) 28. { 29. uint v, i, c; 30. 31. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 32. v += i; 33. 34. return (c == arg ? i : v); 35. } 36. //+----------------+ 37. #endif 38. //+------------------------------------------------------------------+
Code 07
Hier zeigen wir die erste Alternative, um zu sehen, was wir tun können. Beachten Sie, dass wir in Zeile 4 von Code 07 eine Definition erstellen. Sie muss nicht notwendigerweise einen Wert enthalten, sie muss nur existieren, oder besser gesagt, es muss für den Compiler möglich sein, sie zu sehen. Beachten Sie, dass wir in Zeile 10 nur eine Fibonacci-Funktion haben. Aber ich frage Sie: Welche wird verwendet - die in Zeile 15 oder die in Zeile 27? An dieser Stelle könnte man sagen: Das ist sinnlos. Kann es zwei Funktionen mit demselben Namen geben? Ja, aber darüber reden wir ein andermal. Konzentrieren wir uns zunächst auf das, was in Code 07 gezeigt wird.
Wenn Sie noch nie ein solches Bauwerk gesehen haben, werden Sie es schwer haben zu verstehen, was hier vor sich geht. Auf den ersten Blick ergibt das keinen Sinn. Aber sehen Sie sich den Code genau an. Beachten Sie, dass wir in Zeile 13 eine weitere Kompilieranweisung verwenden. Dies prüft, ob die deklarierte Direktive existiert oder nicht, und der Code zwischen den angegebenen Direktiven #ifndef und #endif wird nur kompiliert, wenn die Direktive NICHT EXISTIERT. Andernfalls wird der Code nicht kompiliert. Etwas Ähnliches passiert in Zeile 25, wo der Code nur kompiliert wird, wenn die Richtlinie EXISTIERT. Das heißt, da Zeile 4 die Richtlinie definiert, in der wir den Code verwenden wollen, wird nur der Code zwischen den Zeilen 25 und 37 kompiliert. In der Zwischenzeit wird der Code zwischen den Zeilen 13 und 23 ignoriert.
Ist das nicht richtig? Lassen Sie uns dies praktisch testen. Um dies wirklich akzeptabel zu machen, fügen wir dem Code 07 eine kleine Zeile hinzu, sodass er wie folgt aussehen wird:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define DEF_INTERACTIVE 05. //+----------------+ 06. #define def_Fibonacci_Element_Default 6 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. Print("Result: ", Fibonacci()); 11. } 12. //+------------------------------------------------------------------+ 13. #ifndef DEF_INTERACTIVE 14. //+----------------+ 15. uint Fibonacci(uint arg = def_Fibonacci_Element_Default) 16. { 17. Print("Testing ", __LINE__); 18. if (arg <= 1) 19. return arg; 20. 21. return Fibonacci(arg - 1) + Fibonacci(arg - 2); 22. } 23. //+----------------+ 24. #endif 25. //+------------------------------------------------------------------+ 26. #ifdef DEF_INTERACTIVE 27. //+----------------+ 28. uint Fibonacci(uint arg = def_Fibonacci_Element_Default) 29. { 30. uint v, i, c; 31. 32. Print("Testing ", __LINE__); 33. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 34. v += i; 35. 36. return (c == arg ? i : v); 37. } 38. //+----------------+ 39. #endif 40. //+------------------------------------------------------------------+
Code 08
Wenn wir Code 08 ausführen, sehen wir Folgendes:
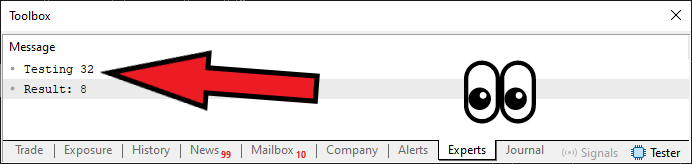
Abbildung 03
Ändern wir nun die Zeile 4 wie unten dargestellt:
// #define DEF_INTERACTIVE Kompilieren Sie den Code 08 erneut, und das Ergebnis wird wie folgt aussehen:
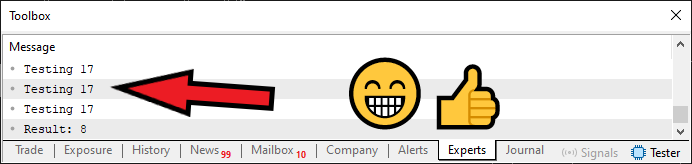
Abbildung 04
Das ist es! Es ist bewiesen: Es funktioniert. In der einen Version verwenden wir rekursive Berechnungen, in der anderen iterative Berechnungen. Und um auszuwählen, welche Version verwendet werden soll, genügt es, eine Codezeile zu ändern. Ist eine solche Implementierung und Verwendung von Direktiven in unserem Code nicht interessant? Aber es geht nicht nur darum. Wir können etwas noch viel Interessanteres tun. Bitte beachten Sie, dass der gezeigte Code auf eine viel einfachere Weise wiederhergestellt werden kann.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define DEF_INTERACTIVE "Interactive" 05. //+----------------+ 06. #define def_Fibonacci_Element_Default 6 07. //+------------------------------------------------------------------+ 08. void OnStart(void) 09. { 10. Print("Result to ", 11. #ifdef DEF_INTERACTIVE 12. DEF_INTERACTIVE, " : " 13. #else 14. "Recursive : " 15. #endif 16. , Fibonacci()); 17. } 18. //+------------------------------------------------------------------+ 19. uint Fibonacci(uint arg = def_Fibonacci_Element_Default) 20. { 21. #ifdef DEF_INTERACTIVE 22. 23. uint v, i, c; 24. 25. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 26. v += i; 27. 28. return (c == arg ? i : v); 29. 30. #else 31. 32. if (arg <= 1) 33. return arg; 34. 35. return Fibonacci(arg - 1) + Fibonacci(arg - 2); 36. 37. #endif 38. } 39. //+------------------------------------------------------------------+
Code 09
In Code 09 verwenden wir Direktiven in einer besser organisierten Weise, weil wir mehrere Dinge steuern können, indem wir nur eine Codezeile ändern, wie wir es in Code 08 getan haben. Wir werden also wie folgt vorgehen: Zunächst führen wir den Code wie oben gezeigt aus, d. h. mit der vorhandenen Zeile 4. Das Ergebnis der Ausführung ist unten zu sehen:
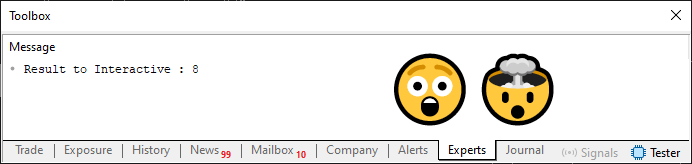
Abbildung 05
Wird Zeile 4 in der gleichen Weise wie in Code 08 angeordnet, ergibt sich bei der Ausführung von Code 09 folgendes Ergebnis:
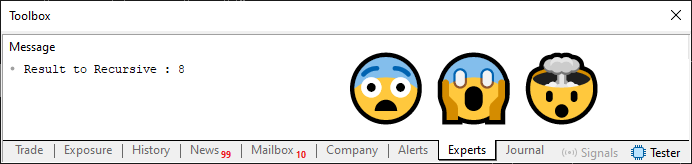
Abbildung 06
„Ist das nicht verrückt? Jetzt bin ich sehr daran interessiert, dies zu verstehen, denn ich habe nicht verstanden, was im Code 09 passiert ist. Könnten Sie mir also bitte erklären, was passiert ist und warum solche Ergebnisse erzielt wurden?“. Natürlich kann ich das, mein lieber Leser. Genau aus diesem Grund wurde dieser Artikel geschrieben.
Was wir im Code 09 gemacht haben, war nur ein kleiner Scherz, um zu zeigen, dass wir mit weniger viel mehr erreichen können. Ich weiß, dass es vielen Menschen schwer fällt, die Denkweise von Programmierern zu verstehen, aber eigentlich ist es gar nicht so schwer. Gute Programmierer sind immer auf der Suche nach Möglichkeiten, Arbeit zu sparen und die Leistung zu steigern. Und in Code 09 tun wir genau das, allerdings auf eine etwas kreativere Art und Weise.
Ich denke, Sie haben die Idee hinter der Direktive #ifdef verstanden, aber lassen Sie es uns noch interessanter machen. Die IF-Anweisung, die wir in einem anderen Artikel besprochen haben, funktioniert in den Direktiven #ifdef und #ifndef genau gleich. Das heißt, dass alles, was sich innerhalb des Fragments befindet, entweder ausgeführt wird oder nicht. In der if-Anweisung wird der Abschnitt jedoch durch öffnende und schließende Klammern abgegrenzt. Hier wird die Direktive #ifdef oder #ifndef durch die #endif-Anweisung abgeschlossen. IMMER. Es kann jedoch vorkommen, dass wir etwas getestet haben und die Richtlinienanweisungen nicht wiederholen wollten. In diesem Fall können wir innerhalb des konstruierten Abschnitts der Direktive #ifdef oder #ifndef die Direktive #else platzieren.
Beachten Sie, dass wir genau wie bei der if-Anweisung, wenn der Ausdruck als wahr ausgewertet wird und wir das ausführen können, was in else steht, das mit der if-Anweisung verbunden ist, können wir hier dasselbe mit den Direktiven #ifdef und #ifndef tun. Das heißt, wenn wir verstehen, wie die IF-Anweisung funktioniert, können wir ähnliche Direktiven besser implementieren und verwenden, da wir #ifdef- und #ifndef-Direktiven platzieren können, um bestimmte Teile desselben Codes zu testen, den wir implementieren wollen.
Obwohl wir das hier nicht tun, sollten Sie verstehen, dass es möglich ist. Kehren wir nun zum eigentlichen Code zurück. Beachten Sie, dass wir in Zeile 4 etwas definieren. Dagegen können wir die Direktiven #ifdef und #ifndef verwenden, um unseren eigenen Code zu modellieren. Man könnte sich jedoch fragen, ob wir während dieser Definition in Zeile 4 dasselbe tun wie in Zeile 6, und ob dies mit den Kompilierungsanweisungen #ifdef und #ifndef in Konflikt geraten könnte. Nein, das ist nicht der Fall. Dies geschieht, weil #ifdef und #ifndef prüfen, ob es eine Definition gibt oder nicht. In der Tat gibt es die Direktive #if, aber nicht in MQL5, sondern in C und C++, wo wir den Wert, den wir in der Direktive zugewiesen haben, überprüfen können. Ich glaube jedoch, dass aus Gründen der Einfachheit der Sprache die Direktive #if nicht aufgenommen wurde, sondern nur #ifdef- und #ifndef.
Sie können also der Direktive einen Wert zuweisen und ihn in eine benannte Konstante umwandeln, wie in Zeile 12 gezeigt, und ihn verwenden. Von nun an können wir die Richtlinie wie eine normale Konstante verwenden, sodass es für diejenigen, die die Artikel gelesen haben und verstehen, wie Code 09 funktioniert, völlig klar ist. Aber wir können noch etwas Interessanteres tun, das uns helfen wird zu verstehen, wie man Daten mit Kompilieranweisungen manipuliert, und das uns im täglichen Leben nützlich sein kann.
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define DEF_INTERACTIVE 05. //+----------------+ 06. #ifdef DEF_INTERACTIVE 07. #define def_OPERATION "Interactive" 08. #else 09. #define def_OPERATION "Recursive" 10. #endif 11. //+----------------+ 12. #define def_Fibonacci_Element_Default 11 13. //+----------------+ 14. #define def_MSG_TERMINAL "Result of " + def_OPERATION + " operation of element" 15. //+------------------------------------------------------------------+ 16. void OnStart(void) 17. { 18. Print(def_MSG_TERMINAL, " ", def_Fibonacci_Element_Default, " : ", Fibonacci()); 19. } 20. //+------------------------------------------------------------------+ 21. uint Fibonacci(uint arg = def_Fibonacci_Element_Default) 22. { 23. #ifdef DEF_INTERACTIVE 24. 25. uint v, i, c; 26. 27. for (c = 0, i = 0, v = 1; c < arg; i += v, c += 2) 28. v += i; 29. 30. return (c == arg ? i : v); 31. 32. #else 33. 34. if (arg <= 1) 35. return arg; 36. 37. return Fibonacci(arg - 1) + Fibonacci(arg - 2); 38. 39. #endif 40. } 41. //+------------------------------------------------------------------+
Code 10
Code 10 scheint sehr komplex und für diejenigen, die ihn nicht kennen, schwer zu verstehen zu sein. Dies scheint sehr schwer zu verstehen. Allerdings ist nichts, was in diesem Code 10 getan wird, neu, da alles, was getan wird, bereits in diesem Artikel erklärt wurde. Aber es kann ein bisschen verwirrend sein, wenn man nicht praktiziert, was in diesem Artikel gezeigt wurde. Da viele dieser Codes in der Anwendung zur Verfügung stehen werden und ihr Zweck nur darin besteht, zu zeigen, was geändert werden sollte, können Sie sie im wirklichen Leben verwenden und jedes hier gezeigte Detail studieren.
Wie auch immer, schauen wir mal, was passiert, wenn wir Code 10 ausführen. Lassen wir zunächst die in Zeile 4 angegebene Richtlinie ihre Arbeit tun. Zu diesem Zweck sollten wir den Code wie oben gezeigt kompilieren. Daraus ergibt sich das Folgende:
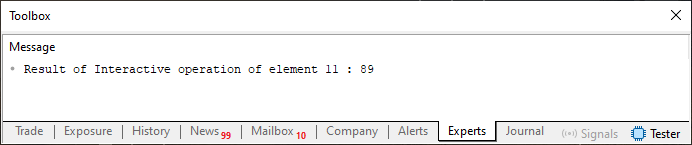
Abbildung 07
Versuchen Sie nun zu verstehen, was vor der Änderung des Codes geschah, wie im folgenden Ausschnitt gezeigt. Das wird die Arbeit in Zukunft sehr erleichtern. Wenn Sie verstanden haben, wie die in Abbildung 07 gezeigte Ausgabe erstellt wurde, ändern Sie den Code wie im folgenden Ausschnitt gezeigt:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. // #define DEF_INTERACTIVE 05. //+----------------+ 06. #ifdef DEF_INTERACTIVE 07. #define def_OPERATION "Interactive" 08. #else 09. #define def_OPERATION "Recursive" 10. #endif 11. //+----------------+ 12. #define def_Fibonacci_Element_Default 11 13. //+----------------+ 14. #define def_MSG_TERMINAL "Result of " + def_OPERATION + " operation of element" 15. //+------------------------------------------------------------------+ . . .
Ausschnitt aus Code 10
Seien Sie vorsichtig, das unten gezeigte Snippet sollte nicht wie Code 10 aussehen. Es ist zwar kaum spürbar, aber es gibt tatsächlich Veränderungen. Diese Änderung erfolgt genau in Zeile 4, wo wir die Definition in einen Kommentar umwandeln. Da es sich um einen Kommentar handelt, wird der Compiler diese Zeile ignorieren. Die Definition scheint also nicht umgesetzt worden zu sein.
Auch wenn es den Anschein hat, dass es für den Code absolut keine Bedeutung hat, führt diese einfache Tatsache dazu, dass der Compiler einen Code erzeugt, der sich von dem vorherigen unterscheidet. Wenn der neue Code ausgeführt wird, sehen wir im Terminal, was in der folgenden Abbildung dargestellt ist:
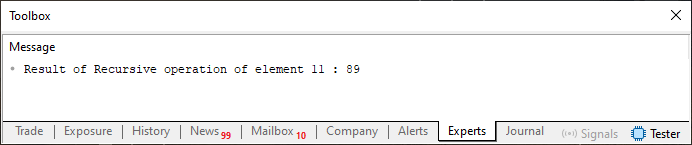
Abbildung 08
Ich denke, es ist jetzt klar, wie die Definition und die Anweisungen #ifdef, #ifndef, #else und #endif zu verwenden sind. Eine weitere Verwendung von #define muss jedoch noch diskutiert werden. Erinnern Sie sich, dass wir zu Beginn des Artikels erwähnten, dass diese Richtlinie zwei Zwecken dienen kann Die erste ist die, die wir in diesem Artikel besprochen haben, und die Sie mit den Codes in der Anwendung üben können.
Dadurch können Sie #define verwenden, um die unnötige Erstellung einer globalen Variablen zu vermeiden, und es erleichtert die einfache, schnelle und effiziente Analyse und Implementierung verschiedener Versionen desselben Codes. Und das ist für Anfänger sehr wertvoll. Für erfahrene Programmierer ist dies ein wenig trivial, da sie solche Dinge fast automatisch verwenden, da sie das Leben viel einfacher machen. Ich wünschte, wir hätten die Direktive #if von C und C++. Aber es gibt keinen Grund zur Sorge, alles ist so, wie es sein sollte.
Die zweite Möglichkeit, #define zu verwenden, besteht darin, ein Makro zu erstellen. Da Makros jedoch Zeit brauchen, um ohne Eile analysiert zu werden, habe ich beschlossen, sie vorerst nicht einzubeziehen, da sie sonst zu komplex werden könnten, um sie zu verstehen. Das liegt daran, dass Makros keine einfachen Codeschnipsel sind, wie sich viele Leute vielleicht vorstellen. Bei richtiger Verwendung sind Makros ein sehr nützliches Werkzeug, aber wenn sie missverstanden und missbraucht werden, können sie den Code sehr verwirrend und komplex machen.
Bevor ich diesen Artikel beende, möchte ich noch auf eine letzte Sache eingehen. Dies ist eher ein BONUS für Sie, weil Sie genug Geduld hatten, bis zum Ende zu lesen, und weil Sie sicher schon mit der Verwendung der #define-Direktive experimentieren wollen.
Dieser Bonus ist die Möglichkeit, mehrere einfache Befehle innerhalb von MQL5 ohne Änderungen zu erstellen, sodass sie ein wenig mehr Sinn machen. Wir werden mehr darüber sprechen, wenn wir die Diskussion über Makros beendet haben, aber dies dient jetzt schon als Vorschau auf das nächste Thema.
Sie haben es vielleicht noch nicht bemerkt, aber wenn wir die Direktive #define verwenden, teilen wir dem Compiler mit, dass ein bestimmter Text durch einen anderen ersetzt werden soll. Mit diesem Konzept können wir eine alternative Syntax erstellen, ohne etwas an der Art und Weise zu ändern, wie wir Codes erstellen.
Um dies zu verdeutlichen, betrachten wir den folgenden Code:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #define BEGIN_PROC { 05. #define END_PROC } 06. #define RETURN return 07. #define ENTER_POINT void OnStart (void) 08. #define Z_SET_NUMBERS long 09. #define EQUAL == 10. #define IS = 11. #define MINOR < 12. #define OR || 13. #define MORE += 14. //+------------------------------------------------------------------+ 15. #define DEF_INTERACTIVE 16. //+----------------+ 17. #ifdef DEF_INTERACTIVE 18. #define def_OPERATION "Interactive" 19. #else 20. #define def_OPERATION "Recursive" 21. #endif 22. //+----------------+ 23. #define def_Fibonacci_Element_Default 11 24. //+----------------+ 25. #define def_MSG_TERMINAL "Result of " + def_OPERATION + " operation of element" 26. //+------------------------------------------------------------------+ 27. ENTER_POINT BEGIN_PROC 28. Print(def_MSG_TERMINAL, " ", def_Fibonacci_Element_Default, " : ", Fibonacci()); 29. END_PROC 30. //+------------------------------------------------------------------+ 31. Z_SET_NUMBERS Fibonacci(Z_SET_NUMBERS arg IS def_Fibonacci_Element_Default) 32. BEGIN_PROC 33. #ifdef DEF_INTERACTIVE 34. 35. Z_SET_NUMBERS v, i, c; 36. 37. for (c IS 0, i IS 0, v IS 1; c MINOR arg; i MORE v, c MORE 2) 38. v MORE i; 39. 40. RETURN (c EQUAL arg ? i : v); 41. 42. #else 43. 44. if ((arg EQUAL 1) OR (arg MINOR 1)) 45. RETURN arg; 46. 47. RETURN Fibonacci(arg - 1) + Fibonacci(arg - 2); 48. 49. #endif 50. END_PROC 51. //+------------------------------------------------------------------+
Code 11
Dieser Code funktioniert genauso wie Code 10, aber hier schaffen wir etwas ganz anderes als die Standards, die viele Menschen tatsächlich verwenden. Der Compiler versteht jedoch Code 11 sehr gut, so gut, dass er die gleichen Ergebnisse wie Code 10 liefert.
Aber wenn man sich das ansieht, könnte man denken: „Mann, das ist nicht MQL5.“ Dank der Informationen in diesem Artikel können wir jedoch einen genaueren Blick darauf werfen und sehen, dass der Code, auch wenn er anders ist, reines und einfaches MQL5 ist, nur anders geschrieben, hauptsächlich darauf ausgerichtet, einer weniger mathematischen und natürlicheren Sprache zu ähneln.
Beachten Sie, dass nach dem Hinzufügen der Definitionen (was zwischen den Zeilen 4 und 13 geschah) der Rest des Codes, vor allem aber ab Zeile 27, völlig anders aussieht. Viele mögen sogar sagen, dass dadurch keine ausführbare Datei erstellt wird. Aber zur Überraschung aller funktioniert dieser Code tatsächlich.
Abschließende Überlegungen
In diesem Artikel haben wir einige Dinge implementiert, die viele von Ihnen vielleicht seltsam und aus dem Zusammenhang gerissen finden, die aber, wenn sie richtig angewendet werden, Ihre Lernphase viel lustiger und aufregender machen, da Sie ziemlich interessante Dinge bauen und die Syntax der MQL5-Sprache selbst besser verstehen können. Da das hier vorgestellte Material gründlich studiert und geübt werden muss, schließen wir diesen Artikel mit diesem Punkt ab. Im nächsten Artikel werden wir die zweite Möglichkeit der Verwendung der Direktive #define besprechen. Üben und studieren Sie daher den heutigen Stoff, um nicht mit dem Stoff des nächsten Artikels durcheinander zu kommen.
In der Anwendung finden Sie die fünf hier abgebildeten Codes. Also, viel Vergnügen.
Übersetzt aus dem Portugiesischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/pt/articles/15573
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.