Neuronale Netze leicht gemacht (Teil 45): Training von Fertigkeiten zur Erkundung des Zustands

Einführung
Hierarchische Verstärkungslernalgorithmen können recht komplexe Probleme erfolgreich lösen. Dies wird erreicht, indem das Problem in kleinere Teilaufgaben aufgeteilt wird. Eines der Hauptprobleme in diesem Zusammenhang ist die richtige Auswahl und Ausbildung von Fertigkeiten, die es dem Agenten ermöglichen, effektiv zu handeln und, wenn möglich, die Umwelt so weit wie möglich zu steuern, um das Ziel zu erreichen.
Zuvor haben wir bereits die Algorithmen DIAYN und DADS zum Training von Fertigkeiten kennengelernt. Im ersten Fall lehrten wir Fertigkeiten mit einer größtmöglichen Vielfalt an Verhaltensweisen, um eine maximale Erkundung der Umwelt zu gewährleisten. Gleichzeitig waren wir bereit, Fertigkeiten zu trainieren, die für unsere aktuelle Aufgabe nicht nützlich waren.
Beim zweiten Algorithmus (DADS) haben wir das Erlernen von Fertigkeiten unter dem Aspekt ihrer Auswirkungen auf die Umwelt betrachtet. Unser Ziel war es, die Dynamik der Umwelt vorherzusagen und Fertigkeiten einzusetzen, die es uns ermöglichen, den größtmöglichen Nutzen aus Veränderungen zu ziehen.
In beiden Fällen wurden die Fertigkeiten aus der vorherigen Verteilung als Input für den Agenten verwendet und während des Trainingsprozesses erforscht. Die praktische Anwendung dieses Ansatzes zeigt eine unzureichende Abdeckung des Zustandsraums. Folglich sind geschulte Fertigkeiten nicht in der Lage, mit allen möglichen Umweltzuständen effektiv zu interagieren.
In diesem Artikel schlage ich vor, sich mit der alternativen Methode des Kompetenzerwerbs Explore, Discover and Learn (EDL) vertraut zu machen. EDL geht das Problem aus einem anderen Blickwinkel an, wodurch das Problem der begrenzten Zustandsabdeckung überwunden und ein flexibleres und anpassungsfähigeres Agentenverhalten ermöglicht wird.
1. Der Algorithmus „Explore, Discover and Learn“ (Erforschen, Entdecken und Lernen)
Die Methode „Exploration, Discovery, and Learning“ (EDL) wurde in dem wissenschaftlichen Artikel „Explore, Discover and Learn: Unsupervised Discovery of State-Covering Skills“ im August 2020 vorgestellt Es wird ein Ansatz vorgeschlagen, der es einem Agenten ermöglicht, verschiedene Fertigkeiten in einer Umgebung zu entdecken und zu erlernen, ohne vorheriges Wissen über Zustände und Fertigkeiten. Es ermöglicht auch das Training einer Vielzahl von Fertigkeiten, die sich über verschiedene Zustände erstrecken, was ein effizienteres Erkunden und Lernen eines Agenten in einer unbekannten Umgebung ermöglicht.
Die EDL-Methode hat eine feste Struktur und besteht aus drei Hauptphasen: Erkundung, Entdeckung und Training von Fertigkeiten.
Wir beginnen unsere Erkundung ohne jegliche Vorkenntnisse über die Umgebung und die erforderlichen Fertigkeiten. In diesem Stadium müssen wir eine Trainingsmenge von Ausgangszuständen mit einer maximalen Abdeckung verschiedener Zustände erstellen, die allen möglichen Umweltverhaltensweisen entsprechen. In unserer Arbeit werden wir eine einheitliche Stichprobe von Systemzuständen während des Trainingszeitraums verwenden. Es sind jedoch auch andere Ansätze möglich, insbesondere wenn bestimmte Verhaltensweisen der Agenten trainiert werden sollen. Es ist anzumerken, dass EDL keinen Zugang zu den von der Expertenstrategie erstellten Trajektorien oder Aktionen benötigt. Aber sie schließt ihre Verwendung auch nicht aus.
In der zweiten Phase suchen wir nach Fertigkeiten, die in bestimmten Umweltbedingungen verborgen sind. Der Grundgedanke dieser Methode ist, dass es eine Verbindung zwischen dem Zustand (oder Zustandsraum) der Umgebung und der spezifischen Fertigkeit gibt, die der Agent einsetzen sollte. Wir müssen solche Abhängigkeiten ermitteln.
Es ist anzumerken, dass wir in diesem Stadium noch keine Kenntnisse über die Umweltbedingungen haben. Es gibt nur eine Auswahl an solchen Zuständen. Außerdem fehlt es uns an Wissen über die notwendigen Fertigkeiten. Gleichzeitig haben wir bereits festgestellt, dass die EDL-Methode die Entdeckung von Fertigkeiten ohne einen Lehrer beinhaltet. Der Algorithmus verwendet einen Variations-Autocodierer, um nach den angegebenen Abhängigkeiten zu suchen. Am Eingang und am Ausgang des Modells gibt es Umweltzustände. Im latenten Zustand des Auto-Encoders erwarten wir die Identifizierung einer latenten Fertigkeit, die sich aus dem aktuellen Zustand der Umgebung ergibt. Bei diesem Ansatz baut der Encoder unseres Auto-Encoders eine Funktion auf, die zeigt, wie die Fertigkeit vom aktuellen Zustand der Umgebung abhängt. Der Modelldecoder führt die Umkehrfunktion aus und erstellt eine Abhängigkeit des Zustands von der verwendeten Fertigkeit. Die Verwendung eines Variations-Autocodierers ermöglicht es uns, von einer klaren „State-Skill“-Korrespondenz zu einer bestimmten Wahrscheinlichkeitsverteilung überzugehen. Dies erhöht im Allgemeinen die Stabilität des Modells in einem komplexen stochastischen Umfeld.
Wenn also kein zusätzliches Wissen über Zustände und Fertigkeiten vorhanden ist, bietet uns die Verwendung des Variations-Autocodierers in der EDL-Methode die Möglichkeit, verborgene Fertigkeiten zu erforschen und zu entdecken, die mit verschiedenen Umweltzuständen verbunden sind. Die Entwicklung einer Funktion für die Beziehung zwischen dem Zustand der Umwelt und der erforderlichen Fertigkeit wird es uns ermöglichen, neue Zustände der Umwelt in eine Reihe der wichtigsten Fertigkeiten in der Zukunft zu interpretieren.
Beachten Sie, dass wir bei den zuvor besprochenen Methoden zuerst die Fertigkeiten trainiert haben. Dann suchte der Planer nach einer Strategie, um fertige Fertigkeiten zu nutzen, um das Ziel zu erreichen. Die EDL-Methode verfolgt den entgegengesetzten Ansatz. Wir bauen zunächst Abhängigkeiten zwischen Zustand und Fertigkeiten auf. Danach vermitteln wir die Fertigkeiten. Auf diese Weise können wir die Fertigkeiten genauer auf die jeweiligen Umgebungsbedingungen abstimmen und feststellen, welche Fertigkeiten in bestimmten Situationen am effektivsten eingesetzt werden können.
Der letzte Schritt des Algorithmus ist das Training des Kompetenzmodells (Agent). Hier lernt der Agent eine Strategie, die die gemeinsamen Informationen zwischen Zuständen und verborgenen Variablen maximiert. Der Agent wird mit Methoden des Reinforcement Learning (Verstärkungslernen) trainiert. Die Bildung der Belohnung ist ähnlich aufgebaut wie bei der DADS-Methode, aber die Autoren der Methode haben die Gleichung leicht vereinfacht. Wie Sie sich vielleicht erinnern, wurde die interne Belohnung des Agenten in DADS nach der folgenden Gleichung gebildet:
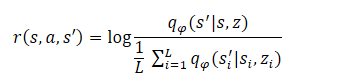
Aus dem Matheunterricht wissen wir, dass
![]()
Folglich:
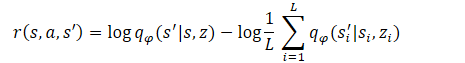
Wie Sie sehen, ist der Subtrahend eine Konstante für alle verwendeten Fertigkeiten. Daher können wir nur den Minuend zur Optimierung der Politik verwenden. Dieser Ansatz ermöglicht es uns, den Umfang der Berechnungen zu reduzieren, ohne die Qualität der Modellschulung zu beeinträchtigen.
![]()
Dieser letzte Schritt kann als Training einer Strategie betrachtet werden, die den Decoder unter einem Markov-Entscheidungsprozess imitiert, d.h. eine Strategie, die die Zustände besucht, die der Decoder für jede versteckte Fertigkeit z erzeugt. Es ist zu beachten, dass die Belohnungsfunktion fest ist, im Gegensatz zu früheren Methoden, bei denen sie sich in Abhängigkeit vom Strategieverhalten ständig ändert. Dadurch wird das Training stabiler und die Konvergenz der Modelle erhöht.
2. Implementierung mittels MQL5
Nachdem wir uns mit den theoretischen Aspekten der EDL-Methode (Exploration, Discovery and Learning) beschäftigt haben, kommen wir nun zum praktischen Teil unseres Artikels. Bevor wir die Methode mit MQL5 implementieren, müssen wir einen Blick auf die Implementierungsmerkmale werfen.
Im Abschnitt „Test“ des vorangegangenen Artikels haben wir die Ähnlichkeit der Ergebnisse bei der Verwendung des One-Hot-Vektors und der vollständigen Verteilung zur Identifizierung der in den Quelldaten des Agenten verwendeten Fertigkeiten nachgewiesen. So können wir je nach Datenlage die eine oder andere Methode anwenden, um den Rechenaufwand zu verringern. Dadurch können wir im Allgemeinen die Anzahl der durchgeführten Operationen verringern. Gleichzeitig sind wir in der Lage, die Geschwindigkeit der Modellschulung und des Betriebs zu erhöhen.
Der zweite Punkt, auf den wir achten müssen, ist, dass wir dem Scheduler (Planer) und dem Agenten dieselben Ausgangsdaten übermitteln (historische Daten zur Preisentwicklung, Parameterwerte und Gleichgewichtszustand). Bei der Eingabe durch den Agenten wird diesen Daten auch die Skill-ID hinzugefügt.
Andererseits haben wir bei der Untersuchung von Auto-Encodern erwähnt, dass der latente Zustand eines Auto-Encoders eine komprimierte Darstellung seiner ursprünglichen Daten ist. Mit anderen Worten: Durch die Verkettung des Vektors der Quelldaten mit dem Vektor der latenten Daten des Variations-Autocodierers werden dieselben Daten zweimal in ihrer vollständigen und komprimierten Darstellung weitergegeben.
Wenn ähnliche Blöcke der vorläufigen Quelldatenverarbeitung verwendet werden, kann dieser Ansatz redundant sein. In dieser Implementierung senden wir also nur den latenten Zustand des Auto-Encoders an den Input des Agenten, der bereits alle notwendigen Informationen enthält. Auf diese Weise können wir den Umfang der durchgeführten Operationen und die Gesamtzeit für das Training der Modelle erheblich reduzieren.
Dieser Ansatz ist natürlich nur möglich, wenn der Scheduler und der Agent ähnliche Ausgangsdaten verwenden. Andere Optionen sind ebenfalls möglich. So kann der Auto-Encoder beispielsweise nur Abhängigkeiten zwischen historischen Daten und einer Fertigkeit herstellen, ohne den Zustand des Kontos zu berücksichtigen. Der Agent ist in der Lage, den Vektor des latenten Zustands des Auto-Encoders und den Vektor der Beschreibung des Zählzustands zu verknüpfen. Es wäre kein Fehler, alle Daten zu verwenden, wie wir es bei der Implementierung der zuvor besprochenen Methoden getan haben. Sie können bei Ihrer Implementierung mit verschiedenen Ansätzen experimentieren.
Alle diese Entscheidungen spiegeln sich notwendigerweise in der Modellarchitektur wider, die wir in der Funktion CreateDescriptions festlegen. In den Methodenparametern übergeben wir Zeiger auf 2 dynamische Arrays, die das Planer- und das Agentenmodell beschreiben. Bitte beachten Sie, dass wir bei der Implementierung der EDL-Methode keinen Discriminator erstellen, da seine Rolle vom Auto-Encoder (Scheduler) Decoder übernommen wird.
bool CreateDescriptions(CArrayObj *actor, CArrayObj *scheduler) { //--- CLayerDescription *descr; //--- if(!actor) { actor = new CArrayObj(); if(!actor) return false; } //--- if(!scheduler) { scheduler = new CArrayObj(); if(!scheduler) return false; }
Zuerst wird der Variations-Autocodierer für den Scheduler erstellt. Wir füttern dieses Modell mit historischen Daten und Kontoständen, was sich in der Größe der Quelldatenschicht widerspiegelt. Wie immer werden die Rohdaten in einer Batch-Normalisierungsschicht vorverarbeitet.
//--- Scheduler scheduler.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr + AccountDescr); descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = 1000; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Danach folgt ein Faltungsblock, um die Dimensionalität der Daten zu reduzieren und spezifische Merkmale zu extrahieren.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; prev_count = descr.count = prev_count - 1; descr.window = 2; descr.step = 1; descr.window_out = 4; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronProofOCL; prev_count = descr.count = prev_count; descr.window = 4; descr.step = 4; if(!scheduler.Add(descr)) { delete descr; return false; }
Dann gibt es drei vollständig verbundene Schichten mit allmählich abnehmender Größe. Bitte beachten Sie, dass die Größe der letzten Schicht das Zweifache der Anzahl der zu trainierenden Fertigkeiten beträgt. Dies ist ein charakteristisches Merkmal eines variablen Auto-Encoders. Im Gegensatz zum klassischen Auto-Encoder wird beim Variations-Auto-Encoder jedes Merkmal durch 2 Parameter dargestellt: den Mittelwert und die Streuung der Verteilung.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.activation = LReLU; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NSkills; descr.activation = None; descr.optimization = ADAM; if(!scheduler.Add(descr)) { delete descr; return false; }
Der Trick mit der Reparametrisierung wird in der nächsten Schicht ausgeführt, die speziell für die Implementierung eines Variations-Autocodierers geschaffen wurde. Auch hier werden die Parameter aus einer bestimmten Verteilung entnommen. Die Größe dieser Schicht entspricht der Anzahl der zu trainierenden Fertigkeiten.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NSkills; if(!scheduler.Add(descr)) { delete descr; return false; }
Der Decoder ist in Form von 3 vollständig verbundenen Schichten implementiert. Die letzte davon ohne Aktivierungsfunktion, da es schwierig ist, eine Aktivierungsfunktion für nicht normalisierte Daten zu definieren.
//--- layer 10 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 128; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 11 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = LReLU; if(!scheduler.Add(descr)) { delete descr; return false; } //--- layer 12 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.optimization = ADAM; descr.activation = None; if(!scheduler.Add(descr)) { delete descr; return false; }
Bitte beachten Sie, dass wir, wie bei der vorherigen Methode, die ursprünglichen Daten nicht vollständig wiederherstellen können. Schließlich sind die Auswirkungen der Maßnahmen des Agenten auf den Marktpreis des Instruments vernachlässigbar. Im Gegenteil, der Stand des Gleichgewichts hängt direkt von der Strategie des Agenten ab. Daher wird am Ausgang des Auto-Encoders nur die Beschreibung des Kontostandes wiederhergestellt.
Nach dem Scheduler erstellen wir eine Beschreibung der Agentenarchitektur. Wie oben erwähnt, wird die Quelldatenschicht des Agenten auf die Anzahl der zu trainierenden Fertigkeiten reduziert.
//--- Actor actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; prev_count = descr.count = NSkills; descr.window = 0; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Die Verwendung eines anderen verborgenen Modells ermöglicht es uns, den Datenvorverarbeitungsblock zu eliminieren. So gibt es unmittelbar nach der Quelldatenschicht einen Entscheidungsblock von 3 vollständig verbundenen Schichten.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.optimization = ADAM; descr.activation = TANH; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 256; descr.activation = LReLU; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Am Ausgang des Modells verwenden wir einen Block einer vollständig parametrisierten Quantilsfunktion, mit der wir die Verteilung der Belohnungen genauer untersuchen können.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronFQF; descr.count = NActions; descr.window_out = 32; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- return true; }
Wie zuvor haben wir die Funktion zur Beschreibung der Modellarchitektur in die Include-Datei „\EDL\Trajectory.mqh“ aufgenommen. Dadurch können wir in allen Phasen der EDL-Methode eine einzige Modellarchitektur verwenden.
Nach der Erstellung der Modellarchitektur gehen wir über zur Arbeit an den EAs, um die untersuchte Methode zu implementieren. Zunächst erstellen wir den EA der ersten - Forschung. Diese Funktion wird im EA „EDL\Research.mq5“ ausgeführt. Um es gleich vorweg zu nehmen: Der Algorithmus dieses EAs kopiert fast vollständig die gleichnamigen EAs aus früheren Artikeln. Es gibt aber auch Unterschiede aufgrund der Architektur der Modelle. Insbesondere in früheren Implementierungen verwendete der Algorithmus dieses EA nur das Agentenmodell, dessen Input mit Anfangsdaten und einer zufällig generierten Skill-ID versorgt wurde. In dieser Implementierung stellen wir historische Daten für die Eingabe in den Planer bereit. Nach dem direkten Durchlauf extrahieren wir den verborgenen Zustand, den wir dem Agenten als Eingabe vorlegen, um eine Entscheidung über die Aktion zu treffen. Der vollständige Code des EA und alle seine Funktionen sind im Anhang zu finden.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- if(!IsNewBar()) return; //--- ........ ........ //--- if(!Scheduler.feedForward(GetPointer(State1), 1, false)) return; if(!Scheduler.GetLayerOutput(LatentLayer, Result)) return; //--- if(!Actor.feedForward(Result, 1, false)) return; int act = Actor.getSample(); //--- ........ ........ //--- }
Der zweite Schritt der EDL-Methode besteht darin, Fertigkeiten zu ermitteln. Wie im theoretischen Teil erwähnt, werden wir in diesem Stadium einen Variations-Autocodierer trainieren. Diese Funktionalität wird in dem EA „StudyModel.mq5“ ausgeführt. Der EA wurde auf der Grundlage der Modell-Trainings-EAs aus früheren Artikeln erstellt. Die einzigen Änderungen betrafen den Methodenalgorithmus.
In der Funktion OnInit wird nur ein Scheduler-Modell initialisiert. Die wichtigsten Änderungen wurden jedoch an der Trainingsfunktion des Train-Modells vorgenommen. Wie zuvor deklarieren wir interne Variablen am Anfang der Funktion.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { int total_tr = ArraySize(Buffer); uint ticks = GetTickCount(); vector<float> account, reward; int bar, action;
Dann wird ein Trainingszyklus mit der in den externen EA-Parametern angegebenen Anzahl von Iterationen durchgeführt.
//--- for(int iter = 0; (iter < Iterations && !IsStopped()); iter ++) { int tr = (int)(((double)MathRand() / 32767.0) * (total_tr - 1)); int i = (int)((MathRand() * MathRand() / MathPow(32767, 2)) * (Buffer[tr].Total - 2));
Im Hauptteil der Schleife wählen wir nach dem Zufallsprinzip einen Durchlauf und dann einen der Zustände des ausgewählten Durchlaufs aus der Trainingsmenge aus. Die Beschreibungsdaten des ausgewählten Zustands werden in den Quelldatenpuffer für den Vorwärtsdurchlauf unseres Modells übertragen. Diese Iterationen unterscheiden sich nicht von denen, die wir zuvor durchgeführt haben. Wie Sie sich vielleicht erinnern, geben wir Informationen über den Kontostand in relativen Begriffen an.
State.AssignArray(Buffer[tr].States[i].state); float PrevBalance = Buffer[tr].States[MathMax(i - 1, 0)].account[0]; float PrevEquity = Buffer[tr].States[MathMax(i - 1, 0)].account[1]; State.Add((Buffer[tr].States[i].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i].account[1] / PrevBalance); State.Add((Buffer[tr].States[i].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i].account[2] / PrevBalance); State.Add(Buffer[tr].States[i].account[4] / PrevBalance); State.Add(Buffer[tr].States[i].account[5]); State.Add(Buffer[tr].States[i].account[6]); State.Add(Buffer[tr].States[i].account[7] / PrevBalance); State.Add(Buffer[tr].States[i].account[8] / PrevBalance);
Als Nächstes werden wir den Gewinn pro Lot aus der Preisveränderung in Höhe der nächsten Kerze ermitteln und Saldo und Eigenkapital in lokalen Variablen für spätere Berechnungen speichern.
//--- bar = (HistoryBars - 1) * BarDescr; double cl_op = Buffer[tr].States[i + 1].state[bar]; double prof_1l = SymbolInfoDouble(_Symbol, SYMBOL_TRADE_TICK_VALUE_PROFIT) * cl_op / SymbolInfoDouble(_Symbol, SYMBOL_POINT); PrevBalance = Buffer[tr].States[i].account[0]; PrevEquity = Buffer[tr].States[i].account[1];
Nach Abschluss der vorbereitenden Arbeiten führen wir einen Vorwärtsdurchlauf unseres Modells durch.
if(IsStopped()) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Nach der erfolgreichen Durchführung des Vorwärtsdurchlaufs müssen wir einen Rückwärtsdurchlauf unseres Modells organisieren. Hier müssen wir die Zielwerte für unser Modell vorbereiten. Der Logik des Trainings von Auto-Encodern folgend, müssten wir den Quelldatenpuffer als Zielwerte verwenden. Wir haben jedoch Änderungen an der Architektur und der Schulungslogik vorgenommen. Erstens erzeugen wir bei der Ausgabe keinen vollständigen Satz von Attributen der Quelldaten, sondern nur Parameter zur Beschreibung des Zustands des Kontos.
Zweitens haben wir einen kleinen Schritt nach vorn gemacht. Wir möchten das Modell trainieren, um eine Vorhersage für den späteren Kontostand zu treffen. Wir werden jedoch nicht für alle möglichen Aktionen des Agenten einen Kontostand erzeugen. In der Phase des Modelltrainings können wir die nächste Kerze in der Trainingsstichprobe bestimmen und die für uns vorteilhafteste Maßnahme ergreifen. Auf diese Weise bilden wir den gewünschten Prognosezustand des Kontos und verwenden ihn als Zielwerte für den Rückwärtsdurchlauf des Modells.
if(prof_1l > 5 ) action = (prof_1l < 10 || Buffer[tr].States[i].account[6] > 0 ? 2 : 0); else { if(prof_1l < -5) action = (prof_1l > -10 || Buffer[tr].States[i].account[5] > 0 ? 2 : 1); else action = 3; } account = GetNewState(Buffer[tr].States[i].account, action, prof_1l); Result.Clear(); Result.Add((account[0] - PrevBalance) / PrevBalance); Result.Add(account[1] / PrevBalance); Result.Add((account[1] - PrevEquity) / PrevEquity); Result.Add(account[2] / PrevBalance); Result.Add(account[4] / PrevBalance); Result.Add(account[5]); Result.Add(account[6]); Result.Add(account[7] / PrevBalance); Result.Add(account[8] / PrevBalance);
Bitte beachten Sie, dass wir bei der Definition der gewünschten Aktion Einschränkungen einführen:
- einen Mindestgewinn, um einen Handel zu eröffnen,
- eine minimale Bewegung, um den Handel zu schließen (wir warten auf kleine Schwankungen),
- das Schließen aller gegenläufigen Handelsgeschäfte, bevor wir eine neue Position eröffnen.
Wir wollen also ein Vorhersagemodell mit dem gewünschten Verhalten erstellen.
Wir übertragen den erzeugten Prognosezustand des Kontos auf die Ebene der relativen Einheiten und geben ihn in den Datenpuffer ein. Danach führen wir einen umgekehrten Durchlauf unseres Modells durch.
if(!Scheduler.backProp(Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Scheduler", iter * 100.0 / (double)(Iterations), Scheduler.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Wie zuvor zeigen wir am Ende der Schleifeniterationen eine Informationsmeldung an, damit der Nutzer den Modellbildungsprozess visuell überwachen kann.
Nach Abschluss aller Iterationen des Modelltrainingszyklus löschen wir den Kommentarblock im Chart und leiten den Prozess der Beendigung des EA ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Scheduler", Scheduler.getRecentAverageError()); ExpertRemove(); //--- }
Der vollständige Code für das Scheduler-Variations-Autocodierer-Training EA befindet sich im Anhang.
Nachdem wir die Abhängigkeiten zwischen Umweltzuständen und Fertigkeiten bestimmt haben, müssen wir unseren Agenten mit den notwendigen Fertigkeiten ausstatten. Wir arrangieren die Funktionalität in dem EA „EDL\StudyActor.mq5“. In diesem EA verwenden wir 2 Modelle (Planer und Agent). Wir werden jedoch nur einen Agenten ausbilden. Daher laden wir 2 Modelle in der EA-Initialisierungsmethode vor. Eine kritische Beendigung des Programms führt jedoch nur dazu, dass der Scheduler, der bereits trainiert sein sollte, nicht mehr geladen werden kann.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- ResetLastError(); if(!LoadTotalBase()) { PrintFormat("Error of load study data: %d", GetLastError()); return INIT_FAILED; } //--- load models float temp; if(!Scheduler.Load(FileName + "Sch.nnw", temp, temp, temp, dtStudied, true)) { PrintFormat("Error of load scheduler model: %d", GetLastError()); return INIT_FAILED; }
Wenn beim Laden des Agentenmodells ein Fehler auftritt, wird ein neues Modell erstellt.
if(!Actor.Load(FileName + "Act.nnw", dtStudied, true)) { CArrayObj *actor = new CArrayObj(); CArrayObj *scheduler = new CArrayObj(); if(!CreateDescriptions(actor, scheduler)) { delete actor; delete scheduler; return INIT_FAILED; } if(!Actor.Create(actor)) { delete actor; delete scheduler; return INIT_FAILED; } delete actor; delete scheduler; //--- }
Nach dem Laden oder Erstellen eines neuen Modells überprüfen wir, ob die Größen der neuronalen Schichten der Quelldaten und die Ergebnisse der Funktionalität entsprechen.
//--- Actor.getResults(Result); if(Result.Total() != NActions) { PrintFormat("The scope of the actor does not match the actions count (%d <> %d)", NActions, Result.Total()); return INIT_FAILED; } Actor.SetOpenCL(Scheduler.GetOpenCL()); Actor.SetUpdateTarget(MathMax(Iterations / 100, 10000)); //--- Scheduler.getResults(Result); if(Result.Total() != AccountDescr) { PrintFormat("The scope of the scheduler does not match the account description (%d <> %d)", AccountDescr, Result.Total()); return INIT_FAILED; } //--- Actor.GetLayerOutput(0, Result); int inputs = Result.Total(); if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("Error of load latent layer %d", LatentLayer); return INIT_FAILED; } if(inputs != Result.Total()) { PrintFormat("Size of latent layer does not match input size of Actor (%d <> %d)", Result.Total(), inputs); return INIT_FAILED; }
Nach erfolgreichem Laden und Initialisieren der Modelle und nach dem Passieren aller Kontrollen initialisieren wir das Ereignis für den Start des Modelltrainings und schließen den Betrieb der EA-Initialisierungsfunktion ab.
//--- if(!EventChartCustom(ChartID(), 1, 0, 0, "Init")) { PrintFormat("Error of create study event: %d", GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
Der Prozess der Agentenschulung ist nach der Train-Methode organisiert. Der erste Teil der Methode beinhaltet die Auswahl eines Durchlaufs, der Zustand und die Organisation des direkten Durchlaufs des Schedulers ist oben beschrieben und wurde ohne Änderungen in diesen EA übernommen. Daher werden wir diesen Block überspringen und sofort mit der Organisation der direkten Passage unseres Agenten fortfahren. Hier ist alles ganz einfach. Wir extrahieren nur den latenten Zustand des Auto-Encoders und leiten die empfangenen Daten an den Eingang unseres Agenten weiter. Vergessen wir nicht, die Ausführung von Vorgängen zu kontrollieren.
//+------------------------------------------------------------------+ //| Train function | //+------------------------------------------------------------------+ void Train(void) { ........ ........ //--- if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } //--- if(!Actor.feedForward(Result, 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Nachdem wir die Operationen des Vorwärtsdurchlaufs erfolgreich abgeschlossen haben, müssen wir den Rückwärtsdurchlauf durch unser Agentenmodell organisieren. Wie bereits im theoretischen Block erwähnt, wird das Agententraining mit Hilfe von Verstärkungsmethoden durchgeführt. Wir müssen die Bildung von Belohnungen für Handlungen organisieren, die während des direkten Durchlaufs entstehen. Bei der EDL-Methode wird der Agent auf der Grundlage der vom Diskriminator generierten Belohnungen trainiert. In diesem Fall übernimmt der Auto-Encoder-Decoder die Rolle des Schedulers. Wir haben jedoch eine leichte Abweichung von dem von den Autoren vorgeschlagenen Prinzip der Belohnungsbildung vorgenommen. Dies steht im Allgemeinen nicht im Widerspruch zur Methodenideologie.
Wie oben erwähnt, haben wir beim Training des Auto-Encoders den gewünschten berechneten Zustand unseres Kontos unter Berücksichtigung der eingeführten Einschränkungen verwendet. Nun werden wir das Verhalten des Agenten belohnen, das uns dem gewünschten Ergebnis so nahe wie möglich bringt. Als Maß für den Abstand zwischen dem gewünschten und dem prognostizierten Zustand unseres Saldos verwenden wir die euklidische Metrik des Abstands zwischen zwei Vektoren. Wir multiplizieren den resultierenden Abstand mit „-1“ als Belohnung, sodass die Aktion, die uns dem gewünschten Zustand so nahe wie möglich bringt, die maximale Belohnung erhält.
Dieser Ansatz ermöglicht es uns, einen Zyklus zu arrangieren und Belohnungen für alle möglichen Aktionen des Agenten auszufüllen, und nicht nur für eine einzelne Aktion. Dies erhöht im Allgemeinen die Stabilität und Leistung des Modelltrainings.
Scheduler.getResults(SchedulerResult); ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); reward[0] = reward[0] / PrevBalance - 1.0f; reward[3] = reward[2] / PrevBalance; reward[2] = reward[1] / PrevEquity - 1.0f; reward[1] /= PrevBalance; reward[4] /= PrevBalance; reward[7] /= PrevBalance; reward[8] /= PrevBalance; reward=MathPow(SchedulerResult - reward, 2.0); ActorResult[action] = -reward.Sum(); }
Nachdem wir den Zyklus der Aufzählung aller möglichen Aktionen des Agenten abgeschlossen haben, erhalten wir einen Vektor der Abstände zwischen den berechneten Zuständen nach jeder möglichen Aktion des Agenten und dem von unserem Auto-Encoder vorhergesagten gewünschten Zustand. Wie Sie sich vielleicht erinnern, haben wir die Entfernungen mit umgekehrtem Vorzeichen geschrieben. Daher ist unser maximaler Abstand maximal negativ oder einfach das Minimum. Wenn wir diesen Mindestwert von jedem Element des Vektors abziehen, wird die Belohnung für die Aktion, die uns weiter vom gewünschten Ergebnis entfernt, auf Null gesetzt. Alle anderen Belohnungen werden ohne Änderung ihrer Struktur in den Bereich der positiven Werte übertragen.
ActorResult = ActorResult - ActorResult.Min();
In diesem Fall verwenden wir SoftMax bewusst nicht. Denn durch den Übergang in den Bereich der Wahrscheinlichkeiten wird nur die Struktur erhalten und der Einfluss der großen Entfernung vom gewünschten Ergebnis neutralisiert. Dieser Einfluss ist für die Entwicklung einer Gesamtstrategie von großer Bedeutung.
Außerdem ist zu bedenken, dass die vorhergesagten Zustände des Auto-Encoders nicht vollständig mit der realen Stochastizität der Umgebung übereinstimmen. Daher ist es wichtig, die Vorhersagequalität eines Auto-Encoders zu bewerten. Die Qualität eines Agenten-Trainings hängt letztlich von der Übereinstimmung zwischen den vom Auto-Encoder vorhergesagten Zuständen und den tatsächlichen Umweltzuständen ab, mit denen der Agent interagiert.
Ich möchte Sie auch daran erinnern, dass der Agent bei der Entwicklung Ihrer Strategie nicht nur die aktuelle Belohnung berücksichtigt, sondern die gesamte Wahrscheinlichkeit, vor Ende der Episode eine Belohnung zu erhalten. In diesem Fall verwenden wir das Zielmodell (Target Net), um die Kosten für den nächsten Zustand zu bestimmen. Diese Funktionalität ist bereits im vollständig parametrisierten Quantilsfunktionsmodell implementiert. Für das normale Funktionieren des Systems müssen wir jedoch den nächsten Zustand des Systems an die Umkehrmethode übergeben.
In diesem Fall müssen wir zunächst einen Vorwärtsdurchlauf des Auto-Encoders durchführen und dabei den nächsten Systemzustand aus dem Erfahrungswiedergabepuffer verwenden.
State.AssignArray(Buffer[tr].States[i+1].state); State.Add((Buffer[tr].States[i+1].account[0] - PrevBalance) / PrevBalance); State.Add(Buffer[tr].States[i+1].account[1] / PrevBalance); State.Add((Buffer[tr].States[i+1].account[1] - PrevEquity) / PrevEquity); State.Add(Buffer[tr].States[i+1].account[2] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[4] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[5]); State.Add(Buffer[tr].States[i+1].account[6]); State.Add(Buffer[tr].States[i+1].account[7] / PrevBalance); State.Add(Buffer[tr].States[i+1].account[8] / PrevBalance); //--- if(!Scheduler.feedForward(GetPointer(State), 1, false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Dann können wir eine komprimierte Darstellung des nächsten Zustands des Systems aus dem latenten Zustand des Auto-Encoders extrahieren. Dann führen wir einen Rückwärtsdurchlauf unseres Agenten durch.
if(!Scheduler.GetLayerOutput(LatentLayer, Result)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; } State.AssignArray(Result); Result.AssignArray(ActorResult); if(!Actor.backProp(Result,DiscountFactor,GetPointer(State),1,false)) { PrintFormat("%s -> %d", __FUNCTION__, __LINE__); ExpertRemove(); break; }
Anschließend informieren wir den Nutzer über den Fortschritt des Agententrainings und gehen zur nächsten Iteration des Zyklus über.
if(GetTickCount() - ticks > 500) { string str = StringFormat("%-15s %5.2f%% -> Error %15.8f\n", "Actor", iter * 100.0 / (double)(Iterations), Actor.getRecentAverageError()); Comment(str); ticks = GetTickCount(); } }
Nach Abschluss der Agentenschulung löschen wir das Kommentarfeld und leiten die Abschaltung des EA ein.
Comment(""); //--- PrintFormat("%s -> %d -> %-15s %10.7f", __FUNCTION__, __LINE__, "Actor", Actor.getRecentAverageError()); ExpertRemove(); //--- }
Der vollständige Code des EAs befindet sich im Anhang.
3. Test
Wir haben die Effizienz des Ansatzes anhand historischer Daten für die ersten 4 Monate des Jahres 2023 auf EURUSD getestet. Wie immer haben wir den H1-Zeitrahmen verwendet. Die Indikatoren wurden mit Standardparametern verwendet. Zunächst haben wir eine Datenbank mit Beispielen von 50 Pässen zusammengestellt, unter denen sich sowohl rentable als auch unrentable Pässe befanden. Bisher haben wir uns bemüht, nur rentable Durchläufe zu verwenden. Auf diese Weise wollten wir Fertigkeiten vermitteln, mit denen sich Gewinne erzielen lassen. In diesem Fall haben wir der Beispieldatenbank mehrere unrentable Durchläufe hinzugefügt, um dem Modell unrentable Zustände zu demonstrieren. Schließlich nehmen wir im realen Handel das Risiko von Drawdowns in Kauf. Aber wir möchten eine Strategie haben, um mit minimalen Verlusten aus ihnen herauszukommen.
Dann haben wir die Modelle trainiert - zuerst den Auto-Encoder, dann den Agenten.
Das trainierte Modell wurde im Strategietester mit historischen Daten für Mai 2023 getestet. Diese Daten waren nicht im Trainingssatz enthalten und ermöglichen es uns, die Leistung der Modelle an neuen Daten zu testen.
Die ersten Ergebnisse waren schlechter als unsere Erwartungen. Zu den positiven Ergebnissen gehört eine ziemlich gleichmäßige Verteilung der in der Teststichprobe verwendeten Fertigkeiten. An dieser Stelle enden die positiven Ergebnisse unseres Tests. Nach mehreren Iterationen des Trainings des Auto-Encoders und des Agenten waren wir immer noch nicht in der Lage, ein Modell zu erhalten, das in der Lage war, aus der Trainingsmenge Gewinne zu erzielen. Offensichtlich war das Problem, dass der Auto-Encoder nicht in der Lage war, Zustände mit ausreichender Genauigkeit vorherzusagen. Infolgedessen ist die Saldenkurve weit vom gewünschten Ergebnis entfernt.
Um unsere Annahme zu testen, wurde ein alternativer EA „EDL\StudyActor2.mq5“ für das Agententraining erstellt. Der einzige Unterschied zwischen der alternativen Option und der zuvor betrachteten ist der Algorithmus zur Erzeugung der Belohnung. Wir nutzten den Zyklus auch zur Vorhersage von Änderungen im Kontostatus. Diesmal haben wir den Indikator für die Veränderung des relativen Saldos als Belohnung verwendet.
ActorResult = vector<float>::Zeros(NActions); for(action = 0; action < NActions; action++) { reward = GetNewState(Buffer[tr].States[i].account, action, prof_1l); ActorResult[action] = reward[0]/PrevBalance-1.0f; }
Der Agent, der mit der modifizierten Belohnungsfunktion trainiert wurde, zeigte während des gesamten Testzeitraums einen relativ gleichmäßigen Anstieg der Rentabilität.


Der Agent wurde mit einem modifizierten Ansatz zur Belohnungsgenerierung trainiert, ohne den Auto-Encoder neu zu trainieren und die Architektur des Agenten selbst zu verändern. Das Training der beiden Agenten wurde vollständig unter vergleichbaren Bedingungen durchgeführt. Erst eine Überarbeitung der Ansätze zur Belohnungsbildung ermöglichte es, die Effizienz des Modells zu erhöhen. Dies bestätigt einmal mehr die Bedeutung der richtigen Wahl der Belohnungsfunktion, die bei den Methoden des Verstärkungstrainings die Schlüsselrolle spielt.

Schlussfolgerung
In diesem Artikel haben wir eine weitere Methode zum Training von Fertigkeiten vorgestellt: Erkunden, Entdecken und Lernen (EDL). Der Algorithmus ermöglicht es dem Agenten, die Umgebung zu erkunden und neue Fertigkeiten zu entdecken, ohne die Bedingungen oder die erforderlichen Fertigkeiten vorher zu kennen. Ermöglicht wird dies durch den Einsatz eines Variations-Autocodierers, der Abhängigkeiten zwischen Umweltzuständen und den geforderten Fertigkeiten ermittelt.
In der ersten Phase der Methode wird eine Umweltstudie durchgeführt. Es wird eine Trainingsstichprobe von Zuständen mit maximaler Abdeckung verschiedener Zustände gebildet, die verschiedenen Verhaltensweisen entsprechen. Danach werden die Abhängigkeiten zwischen Zuständen und Fertigkeiten mit Hilfe des Variations-Autocodierers gesucht. Der latente Zustand des Auto-Encoders dient als komprimierte Repräsentation von Zuständen und als eine Art Identifikator der erforderlichen Fertigkeit. Der Modell-Decoder und -Encoder bilden Abhängigkeitsfunktionen zwischen Zuständen und Fertigkeiten.
Der Agent wird in diesem Rahmen trainiert, indem er versucht, den vom Auto-Encoder vorhergesagten Zustand zu erreichen. Den prädiktiven Zuständen, die der Auto-Encoder liefert, fehlt die Stochastizität der realen Umgebung, was die Stabilität und Geschwindigkeit des Agententrainings erhöht. Gleichzeitig ist dies ein Engpass des Ansatzes, da die Leistung des Modells stark von der Qualität der Zustandsvorhersage durch den Auto-Encoder abhängt. Dies wurde bei dem Test demonstriert.
Heutzutage sind die Finanzmärkte ein recht komplexes und stochastisches Umfeld, das sich nur schwer vorhersagen lässt. Investitionen in sie sind nach wie vor sehr riskant. Positive Handelsergebnisse lassen sich nur durch die strikte Einhaltung einer maßvollen und ausgewogenen Strategie erzielen.
Liste der Referenzen
Programme, die im diesem Artikel verwendet werden
| # | Name | Typ | Beschreibung |
|---|---|---|---|
| 1 | Research.mq5 | Expert Advisor | Beispielsammlung EA |
| 2 | StudyModel.mq5 | Expert Advisor | Training des Auto-Encoder-Modells EA |
| 3 | StudyActor.mq5 | Expert Advisor | Agentenausbildung EA |
| 4 | StudyActor2.mq5 | Expert Advisor | Alternatives Agententraining EA (geänderte Belohnungsfunktion) |
| 5 | Test.mq5 | Expert Advisor | Test-EA des Modells |
| 6 | Trajectory.mqh | Klassenbibliothek | Struktur der Systemzustandsbeschreibung |
| 7 | FQF.mqh | Klassenbibliothek | Klassenbibliothek zur Organisation der Arbeit eines vollständig parametrisierten Modells |
| 8 | NeuroNet.mqh | Klassenbibliothek | Eine Bibliothek von Klassen zur Erstellung eines neuronalen Netzes |
| 9 | NeuroNet.cl | Code Base | OpenCL-Programmcode-Bibliothek |
| 10 | VAE.mqh | Klassenbibliothek | Klassenbibliothek für latente Schichten des Variations-Autokodierers |
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/12783
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Gibt es Meldungen im Protokoll des Testagenten? In einigen Phasen der Initialisierungsunterbrechung zeigt der EA Meldungen an.
Ich habe alle Testerprotokolle gelöscht und die Research-Optimierung für die ersten 4 Monate des Jahres 2023 auf EURUSD H1 ausgeführt.
Ich habe es mit echten Ticks ausgeführt:
Ergebnis: 4 Samples insgesamt, 2 im Plus und 2 im Minus:
Vielleicht mache ich etwas falsch, optimiere die falschen Parameter oder es stimmt etwas mit meinem Terminal nicht? Das ist mir nicht klar... Ich versuche, Ihre Ergebnisse wie im Artikel zu wiederholen...
Die Fehler beginnen ganz am Anfang.
Das Set und das Ergebnis der Optimierung sowie die Logs der Agenten und des Testers sind im Research.zip-Archiv angehängt.
Ich habe alle Testerprotokolle gelöscht und die Research-Optimierung für die ersten 4 Monate des Jahres 2023 auf EURUSD H1 durchgeführt.
Ich lief es auf echte Ticks:
Ergebnis: 4 Stichproben insgesamt, 2 im Plus und 2 im Minus:
Vielleicht mache ich etwas falsch, optimiere die falschen Parameter oder es stimmt etwas mit meinem Terminal nicht? Es ist mir nicht klar... Ich versuche, Ihre Ergebnisse wie im Artikel zu wiederholen...
Die Fehler beginnen ganz am Anfang.
Das Set und das Optimierungsergebnis sowie die Agenten- und Testerprotokolle sind im Archiv Research.zip angehängt
1. Ich habe die vollständige Optimierung angegeben, nicht die schnelle Optimierung. Dies ermöglicht eine vollständige Aufzählung der gegebenen Parameter. Dementsprechend wird es mehr Durchläufe geben.
2. Die Tatsache, dass es beim Start von Research profitable und unprofitable Durchläufe gibt, ist normal. Beim ersten Durchlauf wird das neuronale Netz mit zufälligen Parametern initialisiert. Die Anpassung des Modells wird während des Trainings durchgeführt.
Das Problem ist, dass Sie "tester.ex5" ausführen, um die Qualität der trainierten Modelle zu prüfen, die Sie noch nicht haben. Zuerst müssen Sie Research.mq5ausführen , um eine Datenbank mit Beispielen zu erstellen. Dann StudyModel.mq5, mit dem der Autoencoder trainiert wird. Der Schauspieler wird in StudyActor.mq5 oder StudyActor2.mq5 trainiert (unterschiedliche Belohnungsfunktion). Und erst dann wird tester.ex5 funktionieren. Beachten Sie, dass Sie in den Parametern des letzteren das Akteursmodell Act oder Act2 angeben müssen. Dies hängt vom Expert Advisor ab, mit dem Sie Actor studieren.
Dmitry guten Tag!
Können Sie mir sagen, wie man verstehen kann, dass der Trainingsfortschritt überhaupt stattfindet? Sind die Prozentsätze der Fehler beim Reinforcement Learning von Bedeutung oder schauen sie auf das tatsächliche Handelsergebnis des Netzwerks?
Wie viele Zyklen haben Siestudiert (StudyModel.mq5 -> StudyActor2.mq5 ), bis Sie ein angemessenes Ergebnis erhielten?
Sie haben in Ihrem Artikel angegeben, dass Sie zunächst eine Basis von 50 Durchläufen gesammelt haben. Haben Sie im Laufe des Trainings weitere Sammlungen durchgeführt, die ursprüngliche Basis ergänzt oder gelöscht und neu erstellt?
Verwenden Sie immer 100.000 Iterationen in jedem Durchgang oder ändern Sie die Anzahl von Durchgang zu Durchgang? Wovon hängt sie ab?
Ich habe dem Netzwerk 3 Tage lang eine Lektion erteilt, ich habe vielleicht 40-50 Zyklen gemacht. Das Ergebnis ist wie auf dem Screenshot zu sehen. Manchmal gibt es nur eine gerade Linie (öffnet oder schließt keine Geschäfte). Manchmal werden viele Geschäfte eröffnet und nicht geschlossen. Nur das Eigenkapital ändert sich. Ich habe verschiedene Beispiele ausprobiert. Ich habe versucht, 50 Beispiele zu erstellen und dann Schleifen zu bilden. Ich habe versucht, 96 Beispiele zu erstellen und alle 10 Zyklen weitere 96 Beispiele hinzuzufügen, und so weiter bis zu 500. Das Ergebnis ist das gleiche. Wie kann ich es unterrichten? Was mache ich falsch?
Guten Tag Dimitri!
Können Sie mir sagen, wie man den Fortschritt des Trainings überhaupt verstehen kann? Spielen die Fehlerprozente beim Reinforcement Learning eine Rolle oder schauen sie auf das tatsächliche Handelsergebnis des Netzwerks?
Wie viele Zyklen haben Siestudiert (StudyModel.mq5 -> StudyActor2.mq5 ), bis Sie ein angemessenes Ergebnis erhielten?
Sie haben in Ihrem Artikel angegeben, dass Sie zunächst eine Basis von 50 Durchläufen gesammelt haben. Haben Sie im Laufe des Trainings weitere Sammlungen durchgeführt, die ursprüngliche Basis ergänzt oder gelöscht und neu erstellt?
Verwenden Sie immer 100.000 Iterationen in jedem Durchgang oder ändern Sie die Anzahl von Durchgang zu Durchgang? Wovon hängt sie ab?
Ich habe dem Netzwerk 3 Tage lang eine Lektion erteilt, ich habe vielleicht 40-50 Zyklen gemacht. Das Ergebnis ist wie auf dem Screenshot zu sehen. Manchmal gibt es nur eine gerade Linie (öffnet oder schließt keine Geschäfte). Manchmal werden viele Geschäfte eröffnet und nicht geschlossen. Nur das Eigenkapital ändert sich. Ich habe verschiedene Beispiele ausprobiert. Ich habe versucht, 50 Beispiele zu erstellen und dann Schleifen zu bilden. Ich habe versucht, 96 Beispiele zu erstellen und alle 10 Zyklen weitere 96 Beispiele hinzuzufügen, und so weiter bis zu 500. Das Ergebnis ist das gleiche. Wie kann ich es unterrichten? Was mache ich falsch?
Es ist dasselbe...
Ich habe ein paar Tage damit verbracht, aber das Ergebnis ist das gleiche.
Wie man es lehrt, ist unklar ...
Ich habe es nicht geschafft, das Ergebnis wie in dem Artikel zu bekommen....