
Нейросети — это просто (Часть 31): Эволюционные алгоритмы

Содержание
- Введение
- 1. Основные принципы построения алгоритма
- 2. Реализация средствами MQL5
- 3. Тестирование
- Заключение
- Ссылки
- Программы, используемые в статье
Введение
Продолжаем изучение безградиентных методов оптимизации моделей. Основным преимуществом методов оптимизации данного класса является возможность оптимизации моделей, которые невозможно оптимизировать с помощью градиентных методов. Это задачи, когда не представляется возможным определить производную функции модели или её вычисление усложнено какими-либо факторами. В предыдущей статье мы познакомились с генетическим алгоритмом оптимизации. Напомню, идея генетического алгоритма заимствована из знаний естественных наук. Каждый весовой коэффициент модели представляется отдельным геном в генокоде модели. В процессе оптимизации оценивается некая популяция моделей, инициализированных случайным образом. Популяция имеет конечный "срок жизни". И по окончании эпохи отбираются "лучшие" представители популяции, которые дадут "потомство" для следующей эпохи. Пара "родителей" для каждого индивидуума (модели в новой популяции) выбирается случайным образом. И "гены родителей" наследуются также случайным образом.
1. Основные принципы построения алгоритма
Как можно заметить, в рассмотренном ранее генетическом алгоритме оптимизации очень много случайности. Да, мы целенаправленно отбираем лучших представителей из каждой популяции. Но при этом, большая часть популяции отсеивается. То есть, при полном прогоне всей популяции на каждой эпохе мы выполняем большое количество "пустой" работы. Кроме того, развитие нашей популяции моделей от эпохи к эпохе в нужном нам направлении во многом зависит от фактора случайности. И ничто не гарантирует нам направленного движения к цели.
Если же мы вспомним метод градиентного спуска, то тогда на каждой итерации мы целенаправленно двигались в сторону антиградиента. Тем самым минимизировали ошибку модели. И обучение модели двигается в требуемом направлении. Конечно, для применения метода градиентного спуска нам нужно аналитическим способом определить производную функции на каждой итерации.
А что делать, если у нас нет такой возможности? Можем ли мы как-то совместить оба подхода?
Давайте вначале вспомним геометрическое значение производной функции. Производная функции характеризует скорость изменения значения функции в данной точке. И определяется как предел отношение изменения значения функции к изменению её аргумента при стремлении изменения аргумента к "0". Конечно, если такой предел существует.
Это значит, что помимо аналитической производной мы можем найти некое её приближение экспериментальным путем. Для определения производной функции по аргументу x экспериментальным путем, нам необходимо немного изменить значение параметра x при прочих равных условиях и вычислить значение функции. Отношение изменения значения функции к изменению аргумента даст нам приближенное значение производной.
Так как наши модели являются нелинейными, то в целях получения более качественного определения производной экспериментальным путём рекомендуется для каждого аргумента осуществлять 2 следующие операции. В первом случае прибавлять некое значение, а во-втором — отнимать то же значение. Среднее значение двух операций даст более точное приближение значения производной нашей функции по анализируемому аргументу в данной точке.
Надо сказать, что подобный подход часто используется и при оценке корректности вывода аналитической производной модели. На эксплуатации этого свойства строятся и эволюционные алгоритмы. Основная идея эволюционных стратегий оптимизации состоит в использовании градиентов, полученных экспериментальным путем, для определения направления оптимизации параметров модели.
Но, как легко заметить, основная проблема в использовании экспериментальных градиентов в необходимости осуществления большого количества операций. Только для определения влияния одного параметра на результат модели нам необходимо совершить 3 прямых прохода модели с одними исходными данными. Соответственно, рост числа параметров модели сопровождается 3-х кратным увеличением числа итераций.
Нас это не устраивает. И с этим надо что-то делать.
К примеру, мы можем изменить не один параметр, а, скажем, два. Но в таком случае, как определить влияние каждого из них? И как изменять выбранные параметры? Синхронно или нет? А если влияние выбранных параметров на результат неодинаковое? И их изменение необходимо осуществлять с различной интенсивностью?
Конечно, мы можем абстрагироваться от всех этих вопросов и сказать, что нам неважны процессы, происходящие внутри модели. Нам необходимо получить модель, удовлетворяющую нашим требованиям. Возможно, она будет неоптимальная. В конце концов, понятие оптимальности — это максимально возможное удовлетворение всех предъявленных требований.
В таком случае мы можем смотреть на модель и совокупность её параметров как некое единое целое. Мы можем воспользоваться неким алгоритмом и поменять сразу все параметры модели. Алгоритм изменения параметров может быть любым. В том числе и случайным распределением.
Оценку влияния изменений мы будем осуществлять единственно доступным способом — проверка работы модели на обучающей выборке. Если новый набор параметров смог улучшить предыдущий результат, то мы его принимаем. Если же результат хуже предыдущего, отвергаем и возвращаемся к предыдущему набору параметров. И повторяем цикл для новых и новых параметров.
Не напоминает генетический алгоритм? А где же оценка экспериментального градиента, о котором говорили выше?
Давайте приблизимся ещё больше к генетическому алгоритму. Точно также мы возьмем целую популяцию моделей, эффективность которых будет проверяться на некоей конечной обучающей выборке. Только в данном случае мы будем использовать для всех значений близкие по значению параметры в отличие от генетического алгоритма, в котором каждая модель представляла собой некую индивидуальность, созданную случайным образом. На самом деле, мы возьмём одну модель и добавим к её параметрам некий случайный шум. Именно использование случайного шума позволит нам получить популяцию, в которой не будет ни одной одинаковой модели. Но небольшая величина шума позволит нам получить результаты работы всех моделей в одном подпространстве с небольшим отклонением. А значит, результаты моделей будут сопоставимы.
![]()
где w' - параметры модели в популяции;
w - параметры исходной модели;
ɛ - случайный шум.
Оценивать эффективность работы каждой модели из популяции мы можем с помощью функции потерь или системы вознаграждений. Выбор за вами и во многом зависит от постановки решаемой задачи. При этом учитываем политику оптимизации. Мы минимизируем функцию потерь и максимизируем суммарное вознаграждение. В практической части данной статьи мы будем максимизировать суммарное вознаграждение, аналогично решению задачи обучения с подкреплением.
После проверки работы новой популяции на обучающей выборке нам предстоит определить каким образом оптимизировать параметры исходной модели. Тут можно погрузиться в математику операций и постараться вывести неким образом влияние каждого параметра на результат. При этом мы воспользуемся рядом допущений. Но мы же выше договорились рассматривать модель как единое целое. А значит, весь набор шума, добавленный в каждой отдельной модели популяции, можно оценить полученным суммарным вознаграждением в ходе проверки эффективности модели на обучающей выборке. Поэтому к параметрам исходной модели мы прибавим средневзвешенное значение шума соответствующего параметра от всех моделей популяции. А взвешивать значения шума мы будем на суммарное вознаграждение. Ну и конечно, мы умножим полученное средневзвешенное значение на коэффициент обучения модели. Формула обновления параметров модели представлена ниже. Как можно заметить, представленная формула уж очень напоминает формулу обновления весов при использовании градиентного спуска.
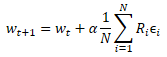
Именно такой эволюционный алгоритм оптимизации моделей был предложен командой OpenAI в сентябре 2017 года в статье "Evolution Strategies as a Scalable Alternative to Reinforcement Learning". В статье предложенный алгоритм рассматривается в качестве альтернативы изученным нами ранее методами Q-learning и Policy Gradient. Предложенный алгоритм показывает свою жизнеспособность и продуктивность. Демонстрирует устойчивость к частоте действий и отсрочки вознаграждений. Кроме того, предложенный авторами метод масштабирования алгоритма позволяет практически с линейной зависимостью увеличивать скорость решения задачи за счет привлечения дополнительных вычислительных ресурсов. Так, при использовании более тысячи параллельных вычислительных машин им удалось всего за 10 минут решить 3-х мерную задачу ходьбы гуманоида. Но проблему масштабирования мы не будем рассматривать в нашей статье.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов алгоритма мы переходим к практической части нашей статьи, в которой мы рассмотрим реализацию предложенного алгоритма средствами MQL5. Сразу скажу, что мы будем реализовывать не 100% оригинальный алгоритм. Мы внесли некоторые изменения с полным сохранением идеи алгоритма. В частности, авторами было предложено использовать жадный алгоритм для выбора действия. Мы же оставили вероятностный алгоритм выбора действия. Кроме того, мы добавили параметры мутации, по аналогии с генетическим алгоритмом. В оригинальном алгоритме мутация не использовалась.
Для реализации алгоритма мы создадим новый класс нейронной сети CNetEvolution наследником класса модели генетического алгоритма. Наследоваться мы будем непублично. Поэтому нам нужно будет переопределить все используемые методы. На первый взгляд, публичное наследование могло бы нас избавить от переопределения некоторых методов, которые мы будем просто переадресовывать на методы родительского класса. Но непубличное наследование перекроет доступ к неиспользуемым методам. Наиболее это полезно при перегрузе методов. Тогда пользователь не увидит перегруженные методы родительских классов, что избавит от ненужной путаницы.
class CNetEvolution : protected CNetGenetic { protected: virtual bool GetWeights(uint layer) override; public: CNetEvolution() {}; ~CNetEvolution() {}; //--- virtual bool Create(CArrayObj *Description, uint population_size) override; virtual bool SetPopulationSize(uint size) override; virtual bool feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) override; virtual bool Rewards(CArrayFloat *rewards) override; virtual bool NextGeneration(float mutation, float &average, float &mamximum); virtual bool Load(string file_name, uint population_size, bool common = true) override; virtual bool Save(string file_name, bool common = true); //--- virtual bool GetLayerOutput(uint layer, CBufferFloat *&result) override; virtual void getResults(CBufferFloat *&resultVals); };
В теле нового класса мы не объявляем новых экземпляров класса. Более того, мы не объявляем ни одной внутренней переменной. Нам будет достаточно использовать объекты и переменные родительских классов. Поэтому и конструктор, и деструктор класса остаются пустыми.
Здесь надо обратить внимание, что мы не создаём объектов для хранения весов исходной модели до добавления шума. И в этом тоже есть отступление от оригинального алгоритма. Но мы ещё вернемся к этому вопросу в процессе реализации.
Следующим рассмотрим метод создания популяции моделей Create. В параметрах метод получает динамический массив описания одной модели и размер популяции, аналогично методу родительского класса. Основной функционал мы будем выполнять с использованием метода родительского класса. Для этого нам достаточно лишь вызвать его и передать полученные параметры.
Напомню, что в методе класса генетического алгоритма CNetGenetic::Create мы создавали популяцию моделей с одной архитектурой и случайными весовыми коэффициентами. Сейчас же нам необходимо создать аналогичную популяцию. Только параметры наших моделей должны быть близки. Чтобы сделать их таковыми мы вызовем метод NextGeneration, который рассмотрим чуть позже.
Результат выполнения операций мы проверяем на каждом шаге. И при завершении работы метода вернем логический результат выполнения операций.
bool CNetEvolution::Create(CArrayObj *Description, uint population_size) { if(!CNetGenetic::Create(Description, population_size)) return false; float average, maximum; return NextGeneration(0,average, maximum); }
Выше был упомянут метод NextGeneration. Не будем откладывать на потом то, что можно сделать сразу и посмотрим на его алгоритм. Функционал данного метода аналогичен функционалу одноименного метода родительского класса. Но, как уже было сказано выше, есть определенная специфика, связанная с требованиями алгоритма.
В параметрах метод получает вероятность мутации и 2 переменные, куда мы запишем значение среднего и максимального вознаграждения.
В теле метода мы сразу сохраняем необходимые значения вознаграждений и ограничиваем максимальное значение мутации. Ограничение максимального значения мутации вызвано стремлением получить обученную модель. Ведь при завышенном значении мутации мы на каждой итерации будем генерировать случайные параметры модели вне зависимости от полученных результатов. Как следствие, наша популяция постоянно будет состоять из случайных необученных моделей.
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { maximum = v_Rewards.Max(); average = v_Rewards.Mean(); mutation = MathMin(mutation, MaxMutation);
Далее мы немного поработаем с подготовкой базы для обновления весовых коэффициентов модели. Как было сказано в теоретической части данной статьи, мерой для взвешивания размера шума при обновлении параметров является суммарное вознаграждение отдельной модели на обучающей выборке. Но в зависимости от используемой политики вознаграждения, суммарная награда может быть как положительной, так и отрицательной. И с большой долей вероятности мы получим ситуацию, когда суммарные награды всех членов популяции имеют одинаковый знак. Все положительные или все отрицательные.
При этом не все шумовые дополнения к параметрам модели несут положительное или отрицательное влияние. В таком случае положительное влияние одних компонентов будет гаситься отрицательным влияние других. И в лучшем случае это замедлит наше продвижение в нужном направлении. А в худшем случае, поведет обучение модели в обратном направлении. Для минимизации влияния этого эффекта в вектор вероятностей v_Probability мы запишем разницу суммарного вознаграждения конкретной модели и среднего суммарного вознаграждения всей популяции.
Здесь мы выходим из того, что добавляемый шум принадлежит нормальному распределению. А значит, суммарное вознаграждение исходной модели находится примерно в средине общего распределения суммарных вознаграждений популяции. И после вычисления разницы, модели с уровнем суммарного вознаграждения ниже среднего получат отрицательную вероятность. И чем меньше суммарное вознаграждение модели, тем более отрицательной будет её вероятность. Аналогично, модели с максимальным суммарным вознаграждением получат и максимальную положительную вероятность. Что нам это дает с практической точки зрения? Если добавленный шум оказал положительное влияние, то умножив его на положительную вероятность получим смещение весового коэффициента в том же направлении. А значит, направляем обучение модели в требуемую сторону. Если же добавленный шум оказал отрицательное влияние, то умножив его на отрицательную вероятность мы изменяем направление смещения весового коэффициента с полученного отрицательного на ожидаемое положительное. И, опять же, направляем обучение нашей модели в сторону максимизации суммарного вознаграждения.
Далее, согласно оригинальному алгоритму, параметры модели корректируются на средневзвешенное значение шума. Поэтому и мы нормализуем вектор полученных вероятностей таким образом, чтобы сумма абсолютных значений всех его элементов была равна "1".
v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum;
После определения коэффициентов обновления модели, которые мы записали в вектор v_Probability, переходим к циклу перебора слоёв модели. Именно в теле этого цикла мы и будем формировать параметры моделей новой популяции.
В теле цикла мы сначала получаем указатель на динамический массив объектов текущего слоя. И сразу проверим действительность полученного указателя на объект. Также проверим размер динамического массива. Он должен соответствовать заданному размеру популяции. При недостаточном размере популяции вызовем метод создания дополнительных моделей CreatePopulation. Напомню, здесь мы используем метод родительского класса без изменений.
for(int l = 1; l < layers.Total(); l++) { CLayer *layer = layers.At(l); if(!layer) return false; if(layer.Total() < (int)i_PopulationSize) if(!CreatePopulation()) return false;
После чего мы вызовем метод GetWeights, который в матрицах m_Weights и m_WeightsConv нам создаст обновленные параметры текущего слоя модели. Непосредственно алгоритм метода будет рассмотрен позже.
if(!GetWeights(l)) return false;
Теперь, когда мы получили обновленные параметры нашей модели мы можем приступить к заполнению популяции. С этой целью мы создаём вложенный цикл с числом итераций равным размеру популяции.
В теле цикла мы получаем указатель на объект текущего нейрона анализируемого нейронного слоя. Сразу проверяем действительность полученного указателя. И тут же получаем указатель на объект матрицы весов.
for(uint i = 0; i < i_PopulationSize; i++) { CNeuronBaseOCL* neuron = layer.At(i); if(!neuron) return false; CBufferFloat* weights = neuron.getWeights();
Если полученный указатель матрицы весов действительный, то мы начинаем работу с ней. Тут мы создаём ещё один вложенный цикл, который будет перебирать элементы матрицы весов.
В теле цикла мы первым делом проверяем вероятность использования мутации и, при необходимости, генерируем случайное число. Если сгенерированное случайное число будет меньше вероятности мутации, то в текущий элемент матрицы запишем случайный весовой коэффициент. И перейдем к следующей итерации цикла. Примерно такой подход мы использовали и в генетическом алгоритме.
if(!!weights) { for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error of update weights"); return false; } continue; } }
Если же текущий весовой коэффициент подлежит обновлению, то мы сначала проверяем его текущее значение. При необходимости, невалидное число заменим случайным весовым коэффициентом.
if(!MathIsValidNumber(m_Weights[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_Weights.Cols()))) { Print("Error of update weights"); return false; } continue; }
И в завершении итерации вложенного цикла добавим шум к текущему весовому коэффициенту.
if(!weights.Update(w, m_Weights[0, w] + GenerateWeight((uint)m_Weights.Cols()))) { Print("Error of update weights"); return false; } } weights.BufferWrite(); }
После добавления шума ко всем элементам матрицы весов текущего элемента популяции, перенесем обновленные параметры в память контекста OpenCL.
При необходимости повторим вышеописанные итерации для матрицы весов свёрточного слоя.
if(neuron.Type() != defNeuronConvOCL) continue; CNeuronConvOCL* temp = neuron; weights = temp.GetWeightsConv(); for(int w = 0; w < weights.Total(); w++) { if(mutation > 0) { int err_code; float random = (float)Math::MathRandomNormal(0.5, 0.5, err_code); if(mutation > random) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error of update weights"); return false; } continue; } }
if(!MathIsValidNumber(m_WeightsConv[0, w])) { if(!weights.Update(w, GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error of update weights"); return false; } continue; }
if(!weights.Update(w, m_WeightsConv[0, w] + GenerateWeight((uint)m_WeightsConv.Cols()))) { Print("Error of update weights"); return false; } } weights.BufferWrite(); } }
Итерации повторяются для всех элементов последовательности.
В заключении метода обнулим вектор накопления суммарного вознаграждения и завершим работу метода.
v_Rewards.Fill(0); //--- return true; }
Следуя цепочке вызовов методов, далее мы рассмотрим метод GetWeights, который мы вызывали из предыдущего метода. Назначение данного метода — обновление параметров оптимизируемой модели. Напомню, что используемый нами родительский класс генетического алгоритма CNetGenetic имел одноименный метод для выгрузки параметров одного нейронного слоя всех моделей популяций. Позже мы использовали полученную матрицу для создания новой популяции. Здесь мы придерживаемся той же логики, только меняется немного содержание в соответствии с эксплуатируемым алгоритмом оптимизации.
В параметрах метод получает порядковый номер нейронного слоя, матрицу параметров которого необходимо создать. В теле метода мы проверяем наличие сформированного вектора вероятностей использование представителей популяции в обновлении параметров модели. И вызываем одноименный метод родительского класса. При этом не забываем контролировать процесс выполнения операций.
bool CNetEvolution::GetWeights(uint layer) { if(v_Probability.Sum() == 0) return false; if(!CNetGenetic::GetWeights(layer)) return false;
После завершения операций метода родительского класса мы ожидаем, что матрицы m_Weights и m_WeightsConv будут содержать весовые коэффициенты анализируемого нейронного слоя всех моделей популяции.
Обратите внимание, что матрицы содержат весовые коэффициенты. А нам для обновления параметров модели необходимы значения добавленного шума и параметры исходной модели.
Поступаем аналогично корректировке вознаграждения. Мы знаем, что шум имеет нормальное распределение. А каждый параметр моделей популяции является суммой соответствующего параметра исходной модели и шума. Делаем допущение, что параметры исходной модели находятся в середине распределения соответствующих параметров моделей популяции. А значит мы можем воспользоваться вектором средних значений соответствующих параметров популяции.
if(m_Weights.Cols() > 0) { vectorf mean = m_Weights.Mean(0);
Таким образом, отняв вектор средних значений от матрицы параметров моделей популяции, мы можем получить требуемую матрицу добавленного шума.
matrixf temp = matrixf::Zeros(1, m_Weights.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_Weights.Rows(), 1)).MatMul(temp); m_Weights = m_Weights - temp;
Использование одинакового подхода для определения добавленного шума и вероятностей его использования в обновлении весовых коэффициентов модели даёт нам сопоставимые значения. И далее мы можем воспользоваться вышеуказанной формулой обновления параметров модели. После чего нам остается лишь перенести полученные значения в соответствующую матрицу.
mean = mean + m_Weights.Transpose().MatMul(v_Probability) * lr; if(!m_Weights.Resize(1, m_Weights.Cols())) return false; if(!m_Weights.Row(mean, 0)) return false; }
При необходимости повторим операции и для второй матрицы.
if(m_WeightsConv.Cols() > 0) { vectorf mean = m_WeightsConv.Mean(0); matrixf temp = matrixf::Zeros(1, m_WeightsConv.Cols()); if(!temp.Row(mean, 0)) return false; temp = (matrixf::Ones(m_WeightsConv.Rows(), 1)).MatMul(temp); m_WeightsConv = m_WeightsConv - temp; mean = mean + m_WeightsConv.Transpose().MatMul(v_Probability) * lr; if(!m_WeightsConv.Resize(1, m_WeightsConv.Cols())) return false; if(!m_WeightsConv.Row(mean, 0)) return false; } //--- return true; }
С полным кодом всех методов и классов можно ознакомиться во вложении.
Выше рассмотрен алгоритм методов, в которые были внесены изменения для организации эволюционного алгоритма. Для полной функциональности класса нам ещё нужно переопределить методы для переадресации потока на соответствующие методы родительского класса. Напомню, что это вынужденная мера при непубличном наследовании.
bool CNetEvolution::SetPopulationSize(uint size) { return CNetGenetic::SetPopulationSize(size); }
bool CNetEvolution::feedForward(CArrayFloat *inputVals, int window = 1, bool tem = true) { return CNetGenetic::feedForward(inputVals, window, tem); }
bool CNetEvolution::Rewards(CArrayFloat *rewards) { if(!CNetGenetic::Rewards(rewards)) return false; //--- v_Probability = v_Rewards - v_Rewards.Mean(); v_Probability = v_Probability / MathAbs(v_Probability).Sum(); //--- return true; }
bool CNetEvolution::GetLayerOutput(uint layer, CBufferFloat *&result) { return CNet::GetLayerOutput(layer, result); }
void CNetEvolution::getResults(CBufferFloat *&resultVals)
{
CNetGenetic::getResults(resultVals);
}
Для завершения работы над классом нам остаётся лишь переопределить методы работы с файлами. Прежде всего нам нужно определиться с методом сохранения модели. Как вы уже заметили, выше мы не сохраняли отдельно модель с обновленными параметрами. Мы лишь обновляли параметры, чтобы построить новую популяцию. Но для сохранения обученной модели нам нужно выбрать лишь одну. И тут вполне логично сохранить модель с лучшим результатом. Среди методов родительского класса у нас уже есть таковой. На него мы и перенаправим поток операций.
bool CNetEvolution::Save(string file_name, bool common = true) { return CNetGenetic::SaveModel(file_name, -1, common); }
С сохранением модели вопрос решили. Переходим к методу загрузки предварительно обученной модели. Ситуация схожая, но есть нюанс. В процессе обучения мы сохраняем не всю популяцию, а только одну модель с наилучшими результатами. Соответственно, после загрузки такой модели нам нужно создать популяцию заданного размера. В методе загрузки родительского класса мы предусмотрели такую возможность. Но там создается популяция моделей с абсолютно случайными параметрами. Нам же необходимо создать популяцию вокруг одной модели с добавлением шума. Поэтому мы сначала вызываем метод загрузки данных модели родительского класса, который создаст функционал и популяцию необходимого размера. А затем обнулим вектор суммарных вознаграждений и вызовем ранее рассмотренный метод NextGeneration, в котором будет создана новая популяция с необходимыми характеристиками.
bool CNetEvolution::Load(string file_name, uint population_size, bool common = true) { if(!CNetGenetic::Load(file_name, population_size, common)) return false; v_Rewards.Fill(0); float average, maximum; if(!NextGeneration(0, average, maximum)) return false; //--- return true; }
Наверное, здесь надо обратить внимание на один момент, который не был уточнен ранее. Как наш метод генерации новой популяции отделит загруженную модель от заполненных случайными весовыми коэффициентами? На самом деле, данная задача решается довольно просто. В методе родительского класса загруженная модель помещается в популяцию с индексом "0". И к ней добавляются модели со случайными параметрами. Мы же для определения вероятности использования добавленного шума используем вектор суммарного вознаграждения моделей. А мы его предусмотрительно обнулили, перед вызовом метода создания новой популяции. Следовательно, в теле метода NextGeneration при определении вероятностей мы также получим вектор нулевых значений. И сумма значений вектора равна "0". В таком случае мы определяем 100% вероятность использования только модели с индексом "0" (загруженной из файла) для формирования базы параметров моделей новой популяции. При этом вероятность использования параметров случайных моделей равна "0". Таким образом, новая популяции будет построена вокруг загруженной из файла модели.
bool CNetEvolution::NextGeneration(float mutation, float &average, float &maximum) { ............. ............. ............. v_Probability = v_Rewards - v_Rewards.Mean(); float Sum = MathAbs(v_Probability).Sum(); if(Sum == 0) v_Probability[0] = 1; else v_Probability = v_Probability / Sum; ............. ............. ............. }
Мы с вами рассмотрели алгоритм всех методов нового класса CNetEvolution и можем перейти к обучения модели, которое мы проведем в следующем разделе данной статьи.
3. Тестирование
Для обучения модели был создан эксперт "Evolution.mq5" на базе эксперта из предыдущей статьи. Все параметры и настройки советника остались без изменения. В принципе, достаточно изменить класс объекта в советнике обучения модели генетическим алгоритмом и можно обучать новые модели эволюционным алгоритмом.
Я же остановлюсь немного на процедуре создания новой модели. Напомню, что после создания инструмента для Transfer-Learning в статьях [7] и [8] я отказался от указания архитектуры модели в коде советника. Это позволяет проводить эксперименты с различными моделями без необходимости внесения изменений в код советника.
Для создания новой модели мы запускаем ранее созданный инструмент "NetCreator". Мы не используем левую часть инструмента и не загружаем никаких предварительно обученных моделей, так как мы создаем полностью новую модель.
Мы знаем, что в процессе обучения на вход модели мы подаем 12 параметров описания каждой свечи. При этом планируем анализировать исторические данные на глубину 20 свечей. Соответственно, размер слоя исходных данных будет составлять 240 нейронов (12 * 20). В качестве слоя исходных данных мы используем полносвязный нейронный слой без использования функции активации. Вносим параметры первого слоя в центральной части нашего инструмента и нажимаем кнопку "ADD LAYER". Результат данной операции — появление описания первого нейронного слоя в правом блоке нашего инструмента.

Далее идет процесс создания архитектуры нашей модели. Например, мы хотим, чтобы наша модель анализировала паттерны из 3-х смежных свечей. Для этого мы добавляем сверточный слой с размером анализируемого окна 36 нейронов (12 * 3). Шаг смешения анализируемого окна устанавливаем в 12 нейронов, что соответствует количеству элементов описания одной свечи. Чтобы дать модели больше свободы действий мы создадим 12 фильтров для анализа паттернов. В качестве функции активации я использовал гиперболический тангенс, что позволяет логически разделить бычьи и медвежьи паттерны. И при этом выход нейронного слоя будет нормализован в пределах области значений функции активации.

Напомню, что созданный нами сверточный слой возвращает сначала последовательность всех элементов одного фильтра, а потом другого. Что можно сравнить с матрицей, в которой каждая строка соответствует отдельному фильтру. А элементы строки представляют результат работы фильтра на всей последовательности исходных данных.
Далее проанализируем результаты работы фильтров выше созданного сверточного слоя. Построим каскад из 3 сверточных слоёв, каждый из которых будет анализировать результаты предшествующего сверточного слоя. Все 3 слоя будут иметь одинаковые характеристики. Они будут анализировать 2 соседних нейрона с шагом в 1 нейрон. Для анализа будут использоваться 2 фильтра в каждом слое.

Как можно заметить, вследствие использования малого шага окна анализируемых данных и нескольких фильтров размер вектора результатов растет от слоя к слою. Обычно, для понижения размерности используются подвыборочные слои. С их помощью либо усредняется значение на выходе фильтров, либо берется максимальное значение. В данном случае я не стал их использовать с надеждой сохранить максимум полезной информации.
Сверточные слои выполняют своеобразную подготовку исходных данных, выделяя в них некоторые паттерны. И чем больше сверточных слоёв, тем более сложные паттерны способна выделить модель. Однако, не следует увлекаться чрезмерно глубокими моделями, так как это усложняет процесс обучения. Да, рассматриваемые безградиентные методы оптимизации моделей не подвержены проблемам взрывающегося и затухающего градиента. Но действительно ли для решения ваших задач нужны глубокие сети. Поэкспериментируйте с различными вариантами и определите влияние увеличения модели на финальный результат. Вы заметите, что на определенном этапе добавление новых слоёв не изменит результат. Но потребует дополнительные затраты ресурсов на оптимизацию модели.
Результаты сверточных нейронных слоёв мы обработаем полносвязным перцептроном из 3-х слоёв по 500 нейронов в каждом. В них я также использовал гиперболический тангенс в качестве функции активации. Вам же предлагаю попробовать работу различных функций активации и сравнить результат.

На выходе нашей модели мы хотим получить вероятностное распределение из 3-х действий: покупка, продажа, выжидание. Для этого мы создадим ещё один полносвязный слой из 3-х нейронов. Но на это раз без использования функции активации.

И переведем полученный результат в область вероятностей с помощью слоя SoftMax.

На этом можно считать завершенной работу по созданию новой модели. Нам остаётся лишь сохранить её с названием файла, к которому будет обращаться наш советник. Функционал сохранения модели запускается нажатием клавиши "SAVE MODEL".

Обучение новой модели, как и ранее, осуществлялось на исторических данных за 2 последних года инструмента EURUSD таймфрейм H1. Процесс обучения модели уже не раз описан в статьях данной серии. И я не буду на нем останавливаться.
Интересно, что в процессе оптимизации модели график динамики суммарной ошибки показал скачкообразную динамику.

После оптимизации мы осуществили тестирование модели в тестере стратегий. Для тестирования модели "Evolution-test.mq5", который является точной копией советника из нескольких предыдущих статьей. Изменения коснулись лишь имени файла загружаемо модели. С полным кодом советника можно ознакомиться во вложении.
Тестирование проводилось за период в последние 2 недели, невходящие в обучающие выборку. Т.е. тестирование проводилось в условиях максимально приближенных к реальным. Результаты тестирования показали жизнеспособность предложенного подхода. На представленном ниже графике можно заметить динамику на увеличение баланса. В целом за период тестирования было совершено 107 трейдов. Из них почти 55% прибыльных. Да, соотношение прибыльных сделок к убыточным близко к 1:1. Но средняя прибыльная сделка на 43% превышает среднюю убыточную сделку. Что в целом дало профит-фактор в размере 1.69. А фактор восстановления достиг 3.39.


Заключение
В данной статье мы познакомились с ещё одним методом безградиентной оптимизации — эволюционный алгоритм. Нами был создан класс реализации данного алгоритма. Результативность рассмотренного алгоритма подтверждается проведенными оптимизацией модели и тестированием результатов оптимизации в тестере стратегий. Результаты тестирования показали возможность получения прибыли советником. Однако стоит обратить внимание, что тестирование проводилось на коротком временном интервале. Это не даёт гарантии на получение прибыли в долгосрочной перспективе.
Построенные в статье модель и советник предназначены только для демонстрации технологии. Перед использованием их на реальных счетах требуются дополнительные настройки и оптимизации.
Ссылки
- Нейросети — это просто (Часть 26): Обучение с подкреплением
- Нейросети — это просто (Часть 27): Глубокое Q-обучение (DQN)
- Нейросети — это просто (Часть 28): Policy gradient алгоритм
- Нейросети — это просто (Часть 29): Алгоритм актер-критик с преимуществом (Advantage actor-critic)
- Natural Evolution Strategies
- Evolution Strategies as a Scalable Alternative to Reinforcement Learning
- Нейросети — это просто (Часть 23): Создаём инструмент для Transfer Learning
- Нейросети — это просто (Часть 24): Совершенствуем инструмент для Transfer Learning
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Evolution.mq5 | Советник | Советник для оптимизации модели |
| 2 | NetEvolution.mqh | Библиотека класса | Библиотека для организации эволюционного алгоритма |
| 3 | Evolution-test.mq5 | Советник | Советник для тестирования модели в тестере стратегий |
| 4 | NeuroNet.mqh | Библиотека классов | Библиотека для организации моделей нейронных сетей |
| 5 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL для организации моделей нейронных сетей |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

 Разработка торговой системы на основе индекса силы медведей Bears Power
Разработка торговой системы на основе индекса силы медведей Bears Power
 Машинное обучение и Data Science — Нейросети (Часть 01): Разбираем нейронные сети с прямой связью
Машинное обучение и Data Science — Нейросети (Часть 01): Разбираем нейронные сети с прямой связью
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Прежде всего, позвольте поблагодарить Дмитрия за эту познавательную серию.
Кто-нибудь может помочь мне разобраться в этой ошибке
10:40:19.206 Core 1 2019.01.01 00:00:00 USDJPY#_PERIOD_H1_Evolution.nnw
10:40:19.206 Core 1 тестер остановлен, потому что OnInit возвращает ненулевой код 1
10:40:19.207 Core 1 отключен
10:40:19.207 Core 1 соединение закрыто
Уважаемый Дмитрий ,
позвольте поблагодарить Вас за Вашу работу, она очень ценна!
Я хотел бы попросить у кого-нибудь помощи. Когда я пытаюсь провести бэктест советника Evolution-test-mq5, то получаю уже упомянутую выше ошибку: тестер остановлен, так как OnInit возвращает ненулевой код 1.
Я переместил файл .nnw в каталог агента (C:\Users\...\MetaQuotes\Tester\D0E8209G77C3CF47AD8BA550E52FF078\Agent-127.0.0.1-3000\MQL5\Files), но это не помогло.
Часть кода, возвращающая ошибку, показана на картинке ниже (как и в комментарии выше).
Может ли кто-нибудь дать мне совет, пожалуйста?
Спасибо
Я переместил файл .nnw в каталог агента (C:\Users\...\MetaQuotes\Tester\D0E8209G77C3CF47AD8BA550E52FF078\Agent-127.0.0.1-3000\MQL5\Files), но это не помогло.
Часть кода, возвращающая ошибку, показана на рисунке ниже (как и в комментарии выше).
Может ли кто-нибудь дать мне совет, пожалуйста?
Спасибо
Привет,
Вы должны переместить файл .nnw в каталог ".\Common\Files".
Здравствуйте Дмитрий,
спасибо за быстрый ответ. Я переместил файлы в эту папку, но, к сожалению, советник так и не запустился. Вместо этого я получил ошибку:
2023.02.22 18:17:24.577 2018.02.01 00:00:00 OpenCL kernel create failed. Код ошибки=5107
2023.02.22 18:17:24.577 2018.02.01 00:00:00 Ошибка создания ядра: 5107
2023.02.22 18:17:24.608 Тестеростановлен, так как OnInit возвращает ненулевой код 1
Попробовал, ставил от 5 до 10, и единицу пробовал. Та же ошибка:
2022.10.22 01:42:08.768 Evolution (EURUSD,H1) Error of execution kernel SoftMax FeedForward: 5109
Кое-что заметил, может из-за этого: при сохранении модели слева в окне появляются надписи: "Error of load model, Select file, error id: 5004". Может это как-то влияет.
Ещё: созданный файл должен весить 16 мегабайт?! Непривычно видеть такие размеры в mql.
UPD
Попробовал на ноутбуке, тоже не хочет обучать:
2022.10.22 13:07:36.028 Evolution (EURUSD,H1) EURUSD_PERIOD_H1_Evolution.nnw
2022.10.22 13:07:36.028 Evolution (EURUSD,H1) OpenCL: GPU device 'Intel(R) UHD Graphics' selected
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 9 undeleted objects left
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 1 object of type CLayer left
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 1 object of type CNeuronBaseOCL left
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 7 objects of type CBufferFloat left
2022.10.22 13:07:37.567 Evolution (EURUSD,H1) 2688 bytes of leaked memory
В журнале:
2022.10.22 13:07:34.716 Experts expert Evolution (EURUSD,H1) loaded successfully
2022.10.22 13:07:37.568 Experts initializing of Evolution (EURUSD,H1) failed with code 1
2022.10.22 13:07:37.580 Experts expert Evolution (EURUSD,H1) removed