Adaptive Indikatoren

Einführung
Der Traum eines jeden Traders ist wohl ein Indikator, der sich der aktuellen Marktsituation anpasst, Flach- und Trendsegmente definiert und relevante Preisänderungen berücksichtigt. Konventionelle technische Indikatoren verwenden konstante Verhältnisse bei der Verarbeitung von Eingangssignalen. Diese Verhältnisse hängen in keiner Weise von den Eigenschaften des Eingangssignals und seinen zeitlichen Veränderungen ab.
Adaptive Indikatoren zeichnen sich durch das Vorhandensein einer Rückkopplung zwischen den Werten der Eingangs- und Ausgangssignale aus. Diese Rückkopplung ermöglicht es dem Indikator, sich selbständig auf die optimale Verarbeitung von finanziellen Zeitreihenwerten einzustellen. Einfacher ausgedrückt: Ein adaptiver Indikator ist ein regulärer linearer Indikator, dessen Parameter sich im Laufe der Zeit je nach aktueller Marktsituation verändern können.
Die Anpassungsalgorithmen sind sehr unterschiedlich. Die Wahl eines bestimmten Algorithmus hängt vom Zweck des Indikators ab. Am häufigsten basieren diese Algorithmen jedoch auf verschiedenen Methoden der kleinsten Quadrate. Sehen wir uns einige Beispiele für die Entwicklung eines adaptiven Indikators an.
Erster Versuch
Versuchen wir, einen adaptiven Indikator zu erstellen. Die naheliegendste Möglichkeit, einen Indikator anzupassen, besteht darin, seine letzten Fehler auf die eine oder andere Weise zu berücksichtigen. Schauen wir uns an, wie dies geschehen kann.
Es sei Indicator[i] Indikatorwert des i-ten Balkens. Der Fehler ist dann Error[i] = price[i] - Indicator[i].
Dieser Fehler kann bei den nächsten Balken zur Korrektur der Indikatorwerte verwendet werden. Außerdem können wir Fehler auf unterschiedliche Weise behandeln. Wir können zum Beispiel den Durchschnitt der letzten Fehler nehmen oder eine exponentielle Glättung auf sie anwenden.
Schauen wir uns an, wie dieser Ansatz auf dem Chart aussehen wird. Ich werde die Vorlage aus dem Artikel über technische Indikatoren als Grundlage verwenden. Ich werde jedoch ein paar Änderungen vornehmen. Wir legen zunächst die Anzahl der Fehler fest für
double sum=0; for(int j=0; j<size; j++) sum=sum+coeff[j]*price[i+j];//Calculate the indicator value if(i>0) { double cur_error=price[i]-sum;//Current error if(NumErrors==0) cur_error=(error+cur_error)/2; if(NumErrors==1) error=cur_error/2; if(NumErrors>1) { for(int j=NumErrors-1; j>0; j--) errors[j]=errors[j-1]; errors[0]=cur_error; cur_error=0; for(int j=0; j<NumErrors; j++) cur_error=cur_error+errors[j]; error=cur_error/NumErrors; } } buffer[i]=sum+error;//Indicator value considering the error
So wird unser neuer Indikator im Vergleich zum einfachen gleitenden Durchschnitt (rote Linie) aussehen.
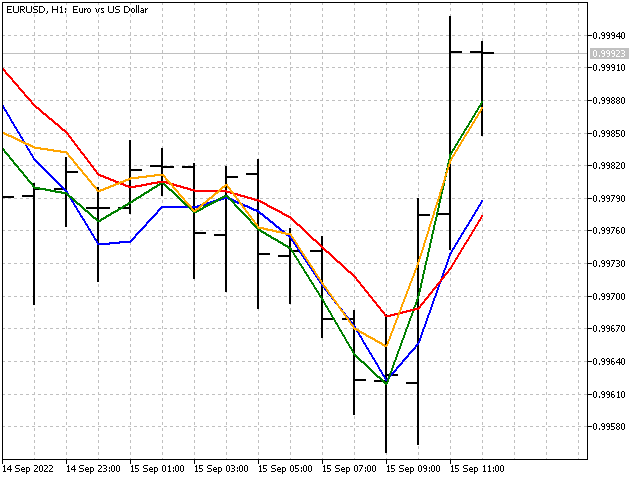
Das Bild sieht schön aus, aber ist unser Indikator auch lernfähig? Leider ist das nicht der Fall. In der Tat haben wir einen gewöhnlichen linearen Indikator, dessen Gewichtskoeffizienten jedoch implizit festgelegt sind.
Nehmen wir einen einfachen gleitenden Durchschnitt mit einer Periodenlänge von 3, der den Mittelwert der letzten drei Fehler darstellt. Berechnen wir zunächst die Fehler:
Error[1] = price[1] - (price[1] + price[2] + price[3])/3
Error[2] = price[2] - (price[2] + price[3] + price[4])/3
Error[3] = price[3] - (price[3] + price[4] + price[5])/3
Dann sieht die Indikatorgleichung wie folgt aus:
Indicator[0] = (price[0] + price[1] + price[2])/3+(Error[1] + Error[2] + Error[3])/3 =>
Indicator[0] = (3*price[0] + 5*price[1] + 4*price[2] + 0*price[3] - 2*price[4] - 1*price[5])/9
Als Ergebnis haben wir einen regulären, linearen Indikator. Daraus ergibt sich eine einfache Schlussfolgerung: Die Fehlerbehandlung allein macht den Indikator nicht lernfähig.
Sonnenaufgang
Pierre-Simon Laplace formulierte einst das Problem, das als „Sunrise Problem“ (Sonnenaufgang-Problem) bekannt geworden ist. Die Essenz dieses Problems lässt sich wie folgt beschreiben: Wenn wir den Sonnenaufgang 1000 Tage lang gesehen haben, wie groß ist dann unsere Zuversicht, dass die Sonne am 1001sten Tag aufgehen wird? Das Problem ist interessant. Betrachten wir das Ganze einmal aus der Perspektive des Handels. Angenommen, Sie haben neun Geschäfte getätigt, von denen sich sechs als gewinnbringend erwiesen haben. Versuchen Sie auf der Grundlage dieser Informationen die Frage zu beantworten: Wie hoch ist die Wahrscheinlichkeit eines profitablen Handels?
In der Regel ist die Wahrscheinlichkeit definiert als das Verhältnis von profitablen Geschäften zu ihrer Gesamtzahl:
![]()
In unserem Beispiel ist die Wahrscheinlichkeit 6/9. Wir gehen aber noch einen Schritt weiter: Wie hoch ist die Gewinnwahrscheinlichkeit für einen zukünftigen Handel? Der Nenner des Bruchs wird bei jedem Ergebnis um eins größer. Beim Zähler sind jedoch zwei Optionen möglich - eine zukünftige Transaktion kann sich entweder als profitabel oder als unprofitabel erweisen. Mit anderen Worten, wir haben zwei Möglichkeiten:
![]()
Nehmen wir den Durchschnitt dieser Werte. In diesem Fall schätzen wir die Gewinnwahrscheinlichkeit wie folgt ein:
![]()
Dies ist etwas weniger als der ursprüngliche Wert von 6/9. Diese Methode wird als Laplace-Glättung bezeichnet. Sie kann für kategoriale Daten verwendet werden, bei denen die Variablen mehrere definierte Werte annehmen können („Erfolg oder Misserfolg“ in unserem Beispiel).
Versuchen wir nun, diese Glättung im Indikator anzuwenden. Zu diesem Zweck werden wir eine kleine Annahme treffen. Wir nehmen an, dass es einen weiteren versteckten Preis im Preisfluss gibt (nennen wir ihn imaginär), der sich ebenfalls auf die Indikatorwerte auswirken wird.
Schauen wir uns an, wie sich die Indikatorgleichung in diesem Fall ändert. So sieht die einfache Gleichung des gleitenden Durchschnitts aus:
![]()
Und so sieht der gleiche Durchschnitt mit einem imaginären Preis aus:
![]()
Auf den ersten Blick sieht alles gut aus. Aber es gibt auch ein paar unangenehme Dinge hier. Erstens wird der imaginäre Preis selbst instabil sein:
![]()
Zweitens: Wenn wir den imaginären Preis auf den nächsten Punkt der Zeitreihe verschieben, wird unser Indikator vereinfacht:
![]()
Diese Vereinfachung hat nicht dazu beigetragen, den Indikator stabil zu machen (das price[1]-Verhältnis ist gleich 1). Dieser Misserfolg kann jedoch als Grundlage für einen anderen Indikator dienen.
Setzen wir zunächst die Periodenlänge iPeriod. Dann finden wir die SL-Werte für alle N mit den Werten von 1 bis iPeriode. Der nächste Schritt ist die Berechnung des Durchschnitts der Summe aller SL-Werte. Als Ergebnis erhalten wir einen Indikator, der einen stabilen Preiswert anzeigt. Dieser Indikator lässt sich wie folgt beschreiben: eine naive Prognose (Vergangenheit=Zukunft) plus einen leicht abgeschwächten linearen Trend.
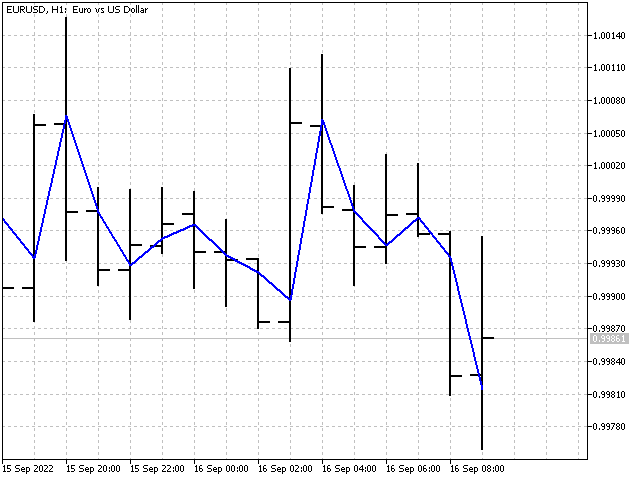
Jetzt haben wir einen Indikator. Die Anpassung ist jedoch noch nicht erfolgt. Ein weiterer Versuch und ein weiteres Fiasko. Machen wir eine kurze Pause einlegen und dann versuchen, doch noch einen adaptiven Indikator zu erstellen. Andernfalls werde ich den Titel des Artikels ändern müssen.
Monduntergang
Ein fiktiver russischer Autor Prutkov sagte einmal sehr weise: „Falls Sie jemals gefragt werden: Was ist nützlicher, die Sonne oder der Mond, antworten Sie: der Mond. Denn die Sonne scheint nur am Tag, wenn es ohnehin hell ist, während der Mond in der Nacht scheint“. Schauen wir uns an, wie dieses Sprichwort auf die Welt des Handels übertragen werden kann.
Bei der Laplace-Glättung haben wir Preiswerte mit denselben Gewichtsverhältnissen verwendet. Aber was passiert, wenn wir den Preisen eine bestimmte Gewichtung geben? Bei den Fensterfunktionen hängen die Gewichtsverhältnisse davon ab, wie weit der jeweilige Messwert vom Gewichtsmittelpunkt des Indikators entfernt ist. Jetzt werden wir es anders machen. Zunächst wählen wir einen bestimmten Preiswert als zentralen Wert. Sie wird das meiste Gewicht haben. Die Gewichtsverhältnisse der übrigen Preise hängen davon ab, wie weit der Preis von diesem Wert entfernt ist - je weiter er davon entfernt ist, desto geringer ist sein Gewicht. Mit anderen Worten, wir werden eine Fensterfunktion nicht im Zeitbereich, sondern im Preisbereich erstellen. Schauen wir uns an, wie ein solcher Algorithmus in der Praxis aussehen würde.
double value=price[i+center],//Price value at the center max=_Point; //Maximum deviation for(int j=0; j<period; j++)//Calculate price deviations from the central one and the max deviation { weight[j]=MathAbs(value-price[i+j]); max=MathMax(max,weight[j]); } double width=(period+1)*max/period,//correct the maximum deviation from the center so that there are no zeros at the ends sum=0, denom=0; for(int j=0; j<period; j++)//calculate weight ratios for each price { if(Smoothing==Linear)//linear smoothing weight[j]=1-weight[j]/width; if(Smoothing==Quadratic)//quadratic smoothing weight[j]=1-MathPow(weight[j]/width,2); if(Smoothing==Exponential)//exponential smoothing weight[j]=MathExp(-weight[j]/width); sum=sum+weight[j]*price[i+j]; denom=denom+weight[j]; } buffer[i]=sum/denom;//indicator value
So sieht unser Indikator auf dem Chart aus.
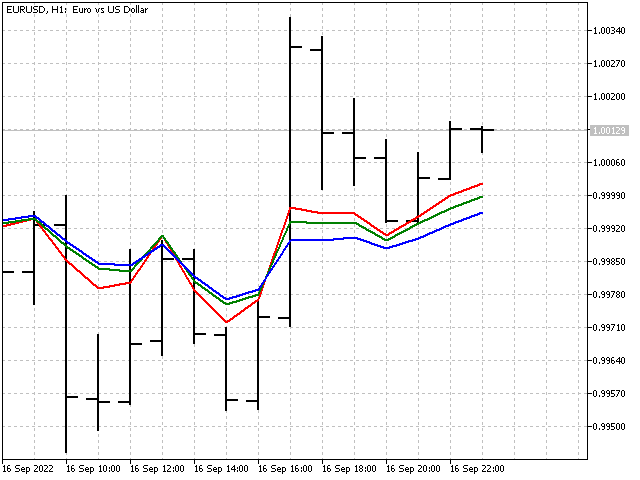
Die Gewichtsverhältnisse der Indikatoren ändern sich. Aber wir können sie nicht als anpassungsfähig bezeichnen. Richtiger wäre es zu sagen, dass sich dieser Indikator an die aktuelle Marktsituation anpasst. Der adaptive Indikator hat zwar nicht funktioniert, aber zumindest haben wir den ersten Schritt getan.
Zweiter Versuch
Nehmen wir eine rechteckige Fensterfunktion als Grundlage. Aber machen wir noch ein paar Änderungen vornehmen - nehmen wir an, dass sich die Verhältnisse am Anfang und am Ende des Fensters ändern können. Die Formel des Indikators sieht dann wie folgt aus:
![]()
wobei N die Periodenlänge des Indikators ist und C1 und C2 adaptive Parameter sind.
Nehmen wir an, dass wir die Werte für diese Verhältnisse bereits kennen. Es erscheint ein neuer Preiswert. Damit einhergehend kann sich der Indikatorfehler ändern.
![]()
Um den Fehler zu verringern, müssen wir jedes Verhältnis um einen bestimmten Faktor R korrigieren:
![]()
Es versteht sich von selbst, dass ich mich darum bemühen werde, dass Änderungen der Kennzahlen den Indikatorfehler auf Null reduzieren. Dies wird jedoch nicht die einzige Bedingung sein. Außerdem sollten die Korrekturen durch R ebenfalls gering sein. Wenn beide Bedingungen erfüllt sind, können wir hoffen, dass die Werte der adaptiven Verhältnisse um einige optimale Werte (wenn überhaupt) schwanken werden.
Wir müssen also eine Lösung für das folgende Problem finden:
![]()
Verwenden wir die Methode der kleinsten Quadrate, um die Korrektur R zu ermitteln. In diesem Fall können die Berechnungen in mehreren Schritten durchgeführt werden. Berechnen wir zunächst den Konvergenzfaktor:
![]()
Dann sind die Korrekturwerte gleich R = price*Error*M.
Dementsprechend lauten die Gleichungen für die Aktualisierung der Parameter wie folgt:
![]()
So wird unser Indikator im Vergleich zum einfachen gleitenden Durchschnitt (rote Linie) aussehen.
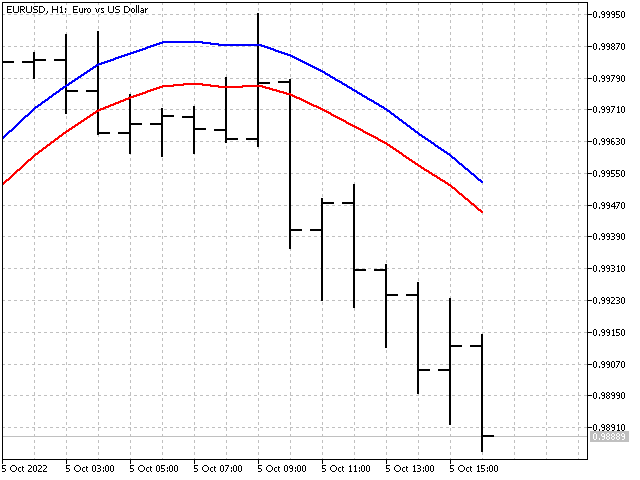
Anpassung
Wir haben es geschafft, mit zwei Verhältnissen zurechtzukommen. Ist es möglich, einen Indikator zu erstellen, bei dem alle seine Parameter adaptiv sind? Ja, das ist sie. Die Berechnungen der Parameter eines solchen Indikators ähneln denen, die im vorherigen Fall betrachtet wurden. Der einzige Unterschied besteht in der Berechnung des Konvergenzfaktors:
![]()
Mit dem Parameter P lässt sich die Änderungsrate der Parameter bei jedem Schritt einstellen. Sein Wert sollte 1 oder höher sein. Bei einem kleinen P erreichen die Indikatorparameter sehr schnell optimale Werte. Allerdings können sich die Veränderungen bei den Indikatorenparameter als zu hoch erweisen. Im Falle eines großen P ändern sich die Indikatorwerte nur langsam. Je größer P, desto glatter wird der Indikator sein. So sehen die Indikatoren zum Beispiel aus, wenn P = 1 und P = 1000.
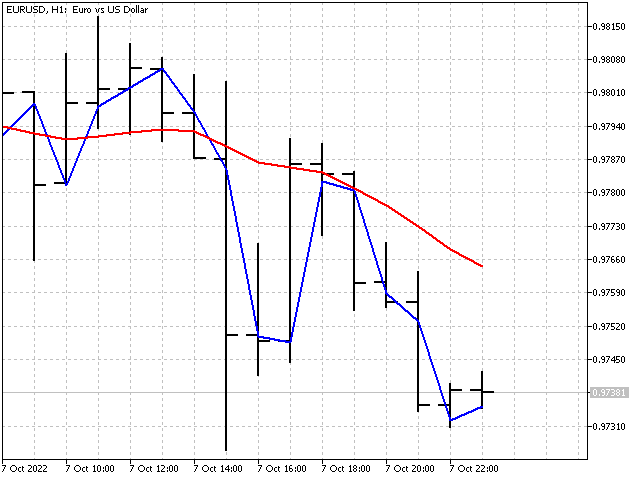
Allgemeine Empfehlung: Stellen Sie den Parameterwert zunächst gleich der Indikatorperiodenlänge ein und ändern Sie ihn dann in die eine oder andere Richtung, bis Sie das gewünschte Ergebnis erhalten.
Ein wichtiges Merkmal der adaptiven Indikatoren ist ihre potenzielle Instabilität. Die Summe der Quotienten eines solchen Indikators ist nicht gleich eins und kann je nach den Eingabedaten variieren. Nehmen wir als Beispiel den exponentiellen Durchschnitt. Die herkömmliche Gleichung sieht wie folgt aus: ![]() .
.
Die adaptive EMA-Gleichung sieht folgendermaßen aus: ![]() .
.
C1 und C2 hängen nicht voneinander ab. Die Parameter werden auf die gleiche Weise aktualisiert wie beim vorherigen Indikator. Der Unterschied besteht darin, dass neben den Preisen auch die früheren Werte des Indikators selbst verwendet werden.
![]()
![]()
Dann sind die aktualisierten Parameter gleich:
![]()
Der adaptive EMA selbst mit verschiedenen P-Werten sieht wie folgt aus.
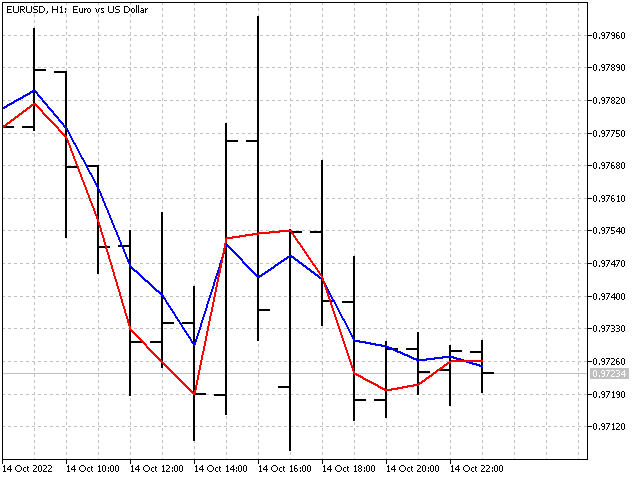
Anpassungsalgorithmen können auch auf Fensterfunktionen angewendet werden. Das Ergebnis wird jedoch nicht so beeindruckend sein, da die Anpassung aufgrund einer Änderung des Normalisierungsverhältnisses erfolgt.
Nehmen wir den LWMA-Indikator mit einer Periodenlänge von 5 als Grundlage. Die Gleichung kann wie folgt geschrieben werden: ![]() .
.
Dabei ist C ein normalisierender Parameter. Im Normalfall ist der Wert dieses Verhältnisses konstant und kann im Voraus berechnet werden. Jetzt werden wir die Möglichkeit zulassen, dass sie sich in die eine oder andere Richtung ändert.
Zunächst müssen wir die gewichtete Summe berechnen: ![]() .
.
In diesem Fall kann der angepasste Wert des normalisierenden Parameters anhand der folgenden Gleichung ermittelt werden:
![]()
Dieser Ansatz kann für Indikatoren mit einem kurzen Zeitraum nützlich sein. Über lange Zeiträume hinweg ist der Einfluss von Anpassung und P fast unsichtbar.
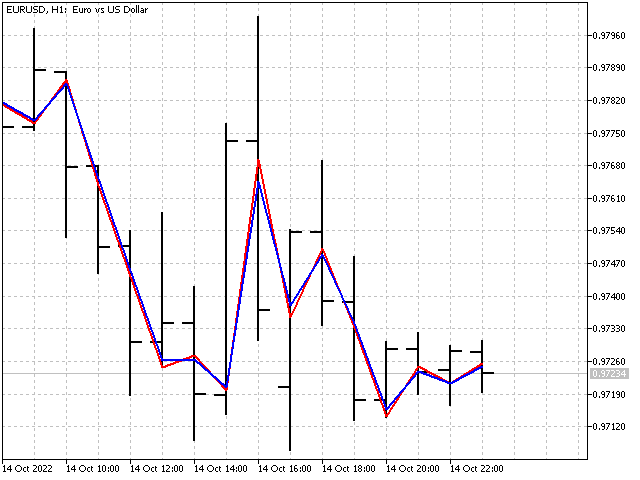
Auf der Grundlage von adaptiven Indikatoren können wir eine Vielzahl von Oszillatoren erstellen. Der adaptive CCI-Indikator sieht zum Beispiel so aus.
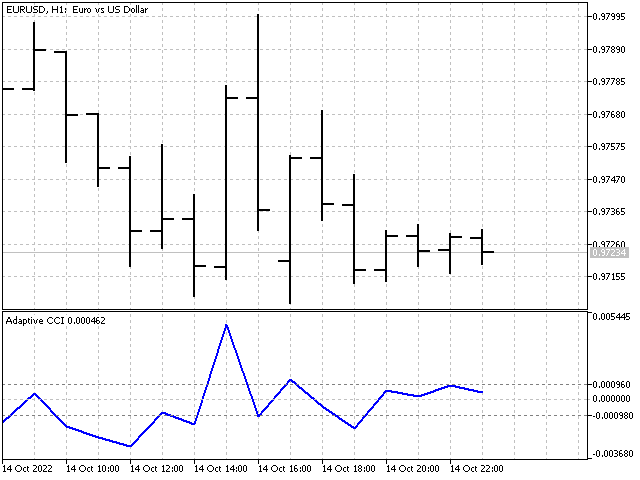
Lineare Vorhersage
Die Entwicklung eines adaptiven Indikators ähnelt in vielerlei Hinsicht der Lösung eines linearen Vorhersageproblems. Wenn wir nämlich die Differenz zwischen dem Indikatorwert und dem zukünftigen Preis (in Bezug auf den Indikator selbst) als Fehler verwenden, dann wird der adaptive Indikator zu einem prädiktiven Indikator.
Nehmen wir zum Beispiel die Eröffnungspreise open. Dann lauten die Indikatorgleichung und der Fehlerwert wie folgt:
![]()
![]()
Alle anderen Berechnungen werden nach Gleichungen durchgeführt, die uns bereits bekannt sind. Das Einzige, was wir zu diesem Indikator hinzufügen werden, ist die Berechnung des durchschnittlichen Prognosefehlers. Als Ergebnis erhalten wir den vorhergesagten Wert des Eröffnungskurses für einen Balken mit einem Index von -1.
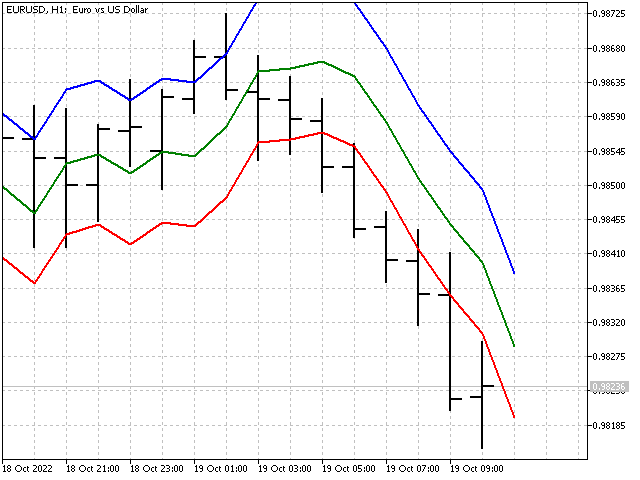
Lineare probabilistische Vorhersage
Die Aufgabe der linearen Vorhersage kann auch in Form der Preisbewegungsgleichung ausgedrückt werden. In der physikalischen Welt sieht alles ganz einfach aus: Wenn die aktuelle Position eines Punktes, seine Geschwindigkeit und seine Beschleunigung bekannt sind, dann ist es nicht schwer, seine Position zum nächsten Zeitpunkt vorherzusagen. Im Falle der Preisbewegung ist alles komplizierter.
Wir kennen den Wert des Preises. In der Sprache der Mathematik sind Geschwindigkeit und Beschleunigung die erste und zweite Ableitung. Wir werden sie durch ein diskretes Analogon ersetzen - geteilte Differenzen der entsprechenden Ordnung. Die Verhältnisse der geteilten Differenzen können der entsprechenden Zeile des Pascalschen Dreiecks entnommen werden. Wir müssen nur abwechselnd die Vorzeichen vor den einzelnen Verhältnissen ändern. Auf diese Weise werden wir erhalten:
1*open[0] -1*open[1] – diskretes Analogon der Geschwindigkeit;
1*offen[0] -2*offen[1] +1*offen[2] – diskretes Analogon der Beschleunigung.
Dann kann die Gleichung der Preisbewegung wie folgt ausgedrückt werden:
open[0] + (open[0] – open[1]) + (open[0] – 2*open[1] + open[2]).
Wir fügen dieser Gleichung adaptive Verhältnisse hinzu und erhalten so das Ergebnis:
open[-1] = open[0] + c1*(open[0] – open[1]) + c2*(open[0] – 2*open[1] + open[2]).
Öffnen wir die Klammern und ordnen wir die Verhältnisse. Dann sieht die Gleichung wie folgt aus:
open[-1] = (1 + с1 + с2)*open[0] + (-c1 – 2*с2)*open[1] + c2*open[2].
Wie Sie sich vielleicht erinnern, sollten die Parameter eines stabilen Indikators im Bereich von -1 bis +1 liegen. Dann müssen wir die folgende Reihe von Ungleichungen lösen:
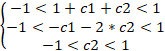
Daraus ergeben sich drei mögliche Optionen:
![]()
![]()
![]()
Jetzt können wir die Parameterwerte wählen und sie im Indikator verwenden.
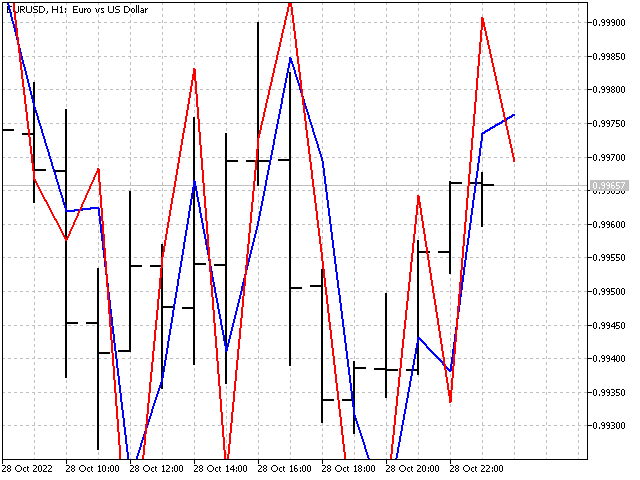
Natürlich bietet die Verwendung von Differenzen höherer Ordnung mehr Möglichkeiten und wirkt sich positiv auf das Aussehen des Indikators aus.
Schlussfolgerung
Die Verwendung von Anpassungsalgorithmen ermöglicht es, recht ungewöhnliche Indikatoren zu erhalten. Ihr Hauptvorteil ist die Selbstanpassung an die aktuelle Marktsituation. Zu den Nachteilen gehört, dass die Zahl der Kontrollparameter zunimmt, deren Auswahl einige Zeit in Anspruch nehmen kann. Andererseits können sich adaptive Indikatoren in einem sehr weiten Bereich verändern, was neue Ansätze für die technische Analyse ermöglichen kann.
Übersetzt aus dem Russischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/ru/articles/11627
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

 Neuronale Netze leicht gemacht (Teil 31): Evolutionäre Algorithmen
Neuronale Netze leicht gemacht (Teil 31): Evolutionäre Algorithmen
 Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 31): Der Zukunft entgegen (IV)
Einen handelnden Expert Advisor von Grund auf neu entwickeln (Teil 31): Der Zukunft entgegen (IV)
- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.
Alexey, ich danke dir!
Ich habe ihn mit großem Vergnügen gelesen, ebenso wie Ihre anderen Artikel hier und im Forum.