直推和主动机器学习中的梯度提升
介绍
半监督学习或直推学习使用未标记的数据,使模型能够更好地理解一般的数据结构。这和我们的思考方法很相似。只要记住一些图像,人脑就能够把这些图像的知识概括地外推到新的物体上,而不必关注无关紧要的细节。这样可以减少过度拟合,并获得更好的泛化效果。
直推是由支持向量机(SVM)的共同发明者弗拉基米尔·瓦普尼克(Vladimir Vapnik)提出的。他认为,直推比归纳法更可取,因为归纳法需要先解决更一般的问题(推断函数),然后再解决更具体的问题(计算新案例的输出)。
"在解决感兴趣的问题时,不要把解决更一般的问题作为中间步骤。试着得到你真正需要的答案,而不是更笼统的答案。"
瓦普尼克的这一假设与伯特兰·罗素(Bertrand Russell)早些时候的观察结果相似:
"我们将得出这样一个结论:苏格拉底是凡人,如果我们把我们的论证纯粹归纳起来,而不是用“人人都是凡人”的方式,然后用演绎的方式,那么苏格拉底就更接近于确定性".
从长远来看,无监督学习(使用未标记的数据)将变得更加重要。无监督学习通常是人和动物的典型特征:他们通过观察发现世界的结构,而不是通过识别每个物体的名称。
因此,半监督学习结合了这两个过程:监督学习发生在少量的标记数据上,然后模型将其知识外推到一个大的未标记区域。
使用未标记数据意味着与底层数据分布有某种联系。必须至少满足以下假设之一:
- 连续性假设。彼此接近的点更有可能共享一个标签。在有监督学习中也假设了这一点,并且产生了一种偏好,即分离类的几何简单边界。在半监督学习的情况下,平滑性假设在低密度区域中产生偏好,在低密度区域中,很少有点彼此接近,但在不同的类中。
- 集群假设。数据往往会形成离散的簇,同一簇中的点更有可能共享一个标签(尽管共享一个标签的数据可以分布在多个簇中)。这是光滑性假设的一个特例,导致使用聚类算法进行学习。
- 流形假设。数据大致位于比输入空间低得多的维数的流形上。在这种情况下,使用标记和未标记的数据学习流形可以避免维数灾难。然后利用流形上定义的距离和密度继续学习。
有关半监督学习的更多详细信息,请查看链接。
半监督学习的主要方法是伪标记,其实现如下:
- 一些邻近度量(例如,欧几里德距离)用于基于标记的数据区域(伪标签)标记其余的数据,
- 训练标签与伪标签和符号相结合。
- 模型在整个数据集上进行训练。
研究人员认为,将标记数据与未标记数据结合使用可以显著提高模型的精度。我在上一篇文章中使用了类似的想法,其中我使用了对标记数据分布的概率密度的估计,并从这个分布中采样。但是新数据的分布可能不同,因此半监督学习可以提供一些好处,本文的实验将说明这一点。
主动学习是半监督学习的某种逻辑延续,它是一个迭代的过程,以这样一种方式标记新数据,从而使分隔类的边界处于最佳位置。
主动学习的主要假设是,学习算法可以选择要学习的数据。与传统方法相比,该方法的训练数据显著减少。这里的传统方法指的是使用标记数据的传统监督学习,这种训练可以称为被动训练。该模型只需对标记数据进行训练,数据越多越好。被动学习中最耗时的问题之一是数据收集和标记。在许多情况下,收集额外数据或适当标记可能会受到限制。
主动学习有三种最流行的场景,其中学习模型将从未标记区域请求新的类实例标签:
- 成员查询综合. 在这种情况下,模型从某个分布中生成一个实例,该分布对所有示例都是公共的。这可能是一个带有附加噪声的类实例,也可能只是所讨论空间中的一个似是而非的点。这个新点被送到先知(oracle)那里培训,Oracle 是估值函数的传统名称,用于评估模型的给定功能实例的值。
- 基于流的采样. 根据这个场景,每次检查一个未标记的数据点,然后 Oracle 根据某种信息标准选择是要查询这个点的类标签还是拒绝它。
- 基于池的采样. 在这个场景中,有大量未标记的示例,就像前面的例子一样,实例是根据信息量从池中选择的,从池中选择信息量最大的实例。这是活跃的学习爱好者中最流行的情景。将对所有未标记的实例进行排序,然后选择信息量最大的实例。
每个场景都可以基于特定的查询策略。如上所述,主动学习和被动学习的主要区别在于基于过去的查询和模型响应从未标记区域查询实例的能力。因此,所有查询都需要某种程度的信息性。
最流行的查询策略如下:
- 不确定度抽样(最小置信度)。根据这个策略,我们选择模型最不确定的实例。例如,将标签分配给某个类的概率低于某个边界。
- 边际抽样. 第一种策略的缺点是它只决定属于一个标签的概率,而忽略属于其他标签的概率。边际抽样策略选择两个最可能的标签之间的最小概率差。
- 熵采样. 对每个实例应用熵公式,查询出最大值的实例。
与半监督学习类似,主动学习过程包括几个步骤:
- 该模型是在标记数据上训练的。
- 同样的模型用于标记未标记的数据以预测概率(伪标记)。
- 选择新实例查询策略。
- 根据信息量从数据池中选取N个实例加入训练样本。
- 重复此循环,直到达到某个停止标准。停止标准可以是迭代次数或学习误差的估计,也可以是其他外部准则。
主动学习
让我们直接进入主动学习,用我们的数据测试它的有效性。
Python语言中有几个用于主动学习的库,其中最流行的是:
- modAL 是一个非常简单易学的包,它是流行的机器学习库 sciket learn 的一种包装(它们完全兼容)。该软件包提供了最流行的主动学习方法。
- Libact使用多臂老虎机(multi-armed bandit)策略来动态选择最佳查询。
- Alipy 是一种来自包提供商的实验室,包含了大量的查询策略。
我选择了 modAL 库,因为它更直观,更适合于了解主动学习理念。它在设计模型和使用标准块或创建自己的模型时提供了更大的自由度。
让我们使用以下方案来考虑上述过程,不需要进一步解释:
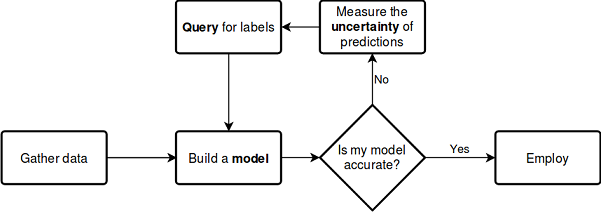
参见文档
关于这个库的最大优点是你可以使用任何 sciket-learn 分类器。以下示例演示如何使用随机森林作为学习模型:
from modAL.models import ActiveLearner from modAL.uncertainty import entropy_sampling from sklearn.ensemble import RandomForestClassifier learner = ActiveLearner( estimator=RandomForestClassifier(), query_strategy=entropy_sampling, X_training=X_training, y_training=y_training )
这里的随机森林充当学习模型和评估器,允许根据查询策略(例如,基于熵,如本例中所示)从未标记数据中选择新样本。接下来,将由少量标记数据组成的数据集传递给模型,这是用于初步培训的。
modAL 库支持查询策略的简单组合,并允许从中生成复合加权策略:
from modAL.utils.combination import make_linear_combination, make_product from modAL.uncertainty import classifier_uncertainty, classifier_margin # creating new utility measures by linear combination and product # linear_combination will return 1.0*classifier_uncertainty + 1.0*classifier_margin linear_combination = make_linear_combination( classifier_uncertainty, classifier_margin, weights=[1.0, 1.0] ) # product will return (classifier_uncertainty**0.5)*(classifier_margin**0.1) product = make_product( classifier_uncertainty, classifier_margin, exponents=[0.5, 0.1] )
生成查询后,将使用 multi_argmax 或 weighted_randm 选择器从未标记的数据区域中选择符合查询条件的实例:
from modAL.utils.selection import multi_argmax # defining the custom query strategy, which uses the linear combination of # classifier uncertainty and classifier margin def custom_query_strategy(classifier, X, n_instances=1): utility = linear_combination(classifier, X) query_idx = multi_argmax(utility, n_instances=n_instances) return query_idx, X[query_idx] custom_query_learner = ActiveLearner( estimator=GaussianProcessClassifier(1.0 * RBF(1.0)), query_strategy=custom_query_strategy, X_training=X_training, y_training=y_training )
查询策略
有三种主要的查询策略,所有的策略都是基于分类的不确定性,这就是为什么它们被称为不确定性度量。让我们看看它们是如何工作的。
在一个简单的情况下,分类不确定性被评估为U(x)=1−P(x^ | x),其中x是要预测的情况,而x^是最可能的预测。例如,如果有三个类别和三个样本项,则相应的不确定度可计算如下:
[[0.1 , 0.85, 0.05], [0.6 , 0.3 , 0.1 ], [0.39, 0.61, 0.0 ]] 1 - proba.max(axis=1) [0.15, 0.4 , 0.39]
因此,第二个例子将被选为最不确定的例子。
分类裕度是第一个和第二个最可能查询的概率之差。根据以下公式确定差异:M(x)=P(x1^ | x)−P(x2^ | x),其中x1^和x2^是第一和第二最可能的类别。
这种查询策略选择两个最有可能的类的概率之间的间隔最小的实例,因为解的间隔越小,不确定性就越大。
>>> import numpy as np >>> proba = np.array([[0.1 , 0.85, 0.05], ... [0.6 , 0.3 , 0.1 ], ... [0.39, 0.61, 0.0 ]]) >>> >>> proba array([[0.1 , 0.85, 0.05], [0.6 , 0.3 , 0.1 ], [0.39, 0.61, 0. ]]) >>> part = np.partition(-proba, 1, axis=1) >>> part array([[-0.85, -0.1 , -0.05], [-0.6 , -0.3 , -0.1 ], [-0.61, -0.39, -0. ]]) >>> part[:, 0] array([-0.85, -0.6 , -0.61]) >>> part[:, 1] array([-0.1 , -0.3 , -0.39]) >>> margin = - part[:, 0] + part[:, 1] >>> margin array([0.75, 0.3 , 0.22])
在这种情况下,将选择第三个样本(数组的第三行),因为该实例的概率余量最小。
分类熵使用信息熵公式计算:H(x)=-∑kpklog(pk),其中pk是样本属于第k类的概率。分布越接近均匀,熵越高。在我们的例子中,第二个例子得到了最大熵。
[0.51818621, 0.89794572, 0.66874809]
看起来并不难,这个描述似乎足以理解三种主要的查询策略。有关更多详细信息,请学习软件包文档,因为我只提供基本要点。
批量查询策略
一次查询一个元素并重新训练模型并不总是有效的。一个更有效的解决方案是一次从未标记的数据中标记和选择多个实例,对此有许多查询。其中最流行的是基于相似函数(如余弦距离)的排序集抽样(Ranked Set Sampling)。此方法估计在x(未标记实例)附近对特征空间的探索程度。评估后,具有最高等级的实例被添加到训练集中,并从未标记的数据池中移除。然后重新计算等级并再次添加最佳实例,直到实例数达到指定的大小(批量大小)。
信息密度查询
上面描述的简单查询策略不评估数据结构,这可能导致次优查询。为了改进采样,您可以使用信息密度度量来帮助正确选择未标记数据的元素。它使用余弦或欧氏距离。信息密度越高,所选实例与其他实例的相似性就越高。
分类委员会查询
这种查询类型消除了简单查询类型的一些缺点。例如,由于特定分类器的特性,元素的选择往往是有偏差的。可能缺少一些重要的采样元素。通过同时存储多个假设并选择存在分歧的查询,可以消除这种影响。因此,分类器委员会根据自己的样本副本学习每个分类器,然后对结果进行加权。其他类型的分类器委员会学习包括打包(bagging)和引导(bootstrapping)。
这个简短的描述几乎完全涵盖了库的功能。有关详细信息,请参阅文档。
主动学习
我选择了批量查询策略,以及分类器委员会查询,并进行了一系列的实验。批量查询策略在新数据上没有表现出良好的性能,但是,通过将它生成的数据集提交给GMM,我开始得到有趣的结果。
考虑一个实现批量主动学习函数的示例:
def active_learner(data, labeled_size, unlabeled_size, batch_size, max_depth): X_raw = data[data.columns[1:-1]].to_numpy() y_raw = data[data.columns[-1]].to_numpy() # Isolate our examples for our labeled dataset. training_indices = np.random.randint(low=0, high=X_raw.shape[0] + 1, size=labeled_size) X_train = X_raw[training_indices] y_train = y_raw[training_indices] # fit the model on all data cl = AdaBoostClassifier(DecisionTreeClassifier(max_depth=max_depth), n_estimators=50, learning_rate = 0.01) cl.fit(X_raw, y_raw) print('Score for the passive learning: ', cl.score(X_raw, y_raw), ' with train size: ', data.shape[0]) # Isolate the non-training examples we'll be querying. X_pool = np.delete(X_raw, training_indices, axis=0) y_pool = np.delete(y_raw, training_indices, axis=0) # Pre-set our batch sampling to retrieve 3 samples at a time. preset_batch = partial(uncertainty_batch_sampling, n_instances=batch_size) # Specify our core estimator along with its active learning model. cl = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3), n_estimators=50, learning_rate = 0.03) learner = ActiveLearner(estimator=cl, query_strategy=preset_batch, X_training=X_train, y_training=y_train)
以下是函数的输入:带标签的数据集、带标签的实例数、未标记的实例数、批次标签查询的批次大小和最大树深度。
从标记的数据集中随机选择指定数量的标记实例进行模型预训练。数据集的其余部分形成一个池,从中查询实例。我使用 AdaBoost 作为基本分类器,它类似于 CatBoost。然后,对模型进行迭代训练:
# Allow our model to query our unlabeled dataset for the most # informative points according to our query strategy (uncertainty sampling). N_QUERIES = unlabeled_size // batch_size for index in range(N_QUERIES): query_index, query_instance = learner.query(X_pool) # Teach our ActiveLearner model the record it has requested. X, y = X_pool[query_index], y_pool[query_index] learner.teach(X=X, y=y) # Remove the queried instance from the unlabeled pool. X_pool, y_pool = np.delete( X_pool, query_index, axis=0), np.delete(y_pool, query_index) # Calculate and report our model's accuracy. model_accuracy = learner.score(X_raw, y_raw) print('Accuracy after query {n}: {acc:0.4f}'.format( n=index + 1, acc=model_accuracy)) # Save our model's performance for plotting. performance_history.append(model_accuracy) print('Score for the active learning with train size: ', learner.X_training.shape)
由于这种半监督学习的结果是任何事情都可能发生的,因此结果可以是任意的。但是,在对学习者设置进行了一些操作之后,我得到了与上一篇文章相当的结果。
理想情况下,主动学习者对少量标记数据的分类精度应超过对所有数据进行标记的类似分类器的精度。
>>> learned = active_learner(pr, 1000, 1000, 50) Score for the passive learning: 0.5991245668429692 with train size: 5483 Accuracy after query 1: 0.5710 Accuracy after query 2: 0.5836 Accuracy after query 3: 0.5749 Accuracy after query 4: 0.5847 Accuracy after query 5: 0.5829 Accuracy after query 6: 0.5823 Accuracy after query 7: 0.5650 Accuracy after query 8: 0.5667 Accuracy after query 9: 0.5854 Accuracy after query 10: 0.5836 Accuracy after query 11: 0.5807 Accuracy after query 12: 0.5907 Accuracy after query 13: 0.5944 Accuracy after query 14: 0.5865 Accuracy after query 15: 0.5949 Accuracy after query 16: 0.5873 Accuracy after query 17: 0.5833 Accuracy after query 18: 0.5862 Accuracy after query 19: 0.5902 Accuracy after query 20: 0.6002 Score for the active learning with train size: (2000, 8)
根据该报告,在所有标记数据上训练的分类器的准确率低于只训练了2000个实例的主动学习者,这可能很好。
现在,可以将这个样本发送到GMM模型,然后训练 CatBoost 分类器。
# prepare data for CatBoost
catboost_df = pd.DataFrame(learned.X_training)
catboost_df['labels'] = learned.y_training
# perform GMM clusterization over dataset
X = catboost_df.copy()
gmm = mixture.GaussianMixture(
n_components=75, max_iter=500, covariance_type='full', n_init=1).fit(X)
# sample new dataset
generated = gmm.sample(10000)
# make labels
gen = pd.DataFrame(generated[0])
gen.rename(columns={gen.columns[-1]: "labels"}, inplace=True)
gen.loc[gen['labels'] >= 0.5, 'labels'] = 1
gen.loc[gen['labels'] < 0.5, 'labels'] = 0
X = gen[gen.columns[:-1]]
y = gen[gen.columns[-1]]
pr = pd.DataFrame(X)
pr['labels'] = y
# fit CatBoost model and test it
model = fit_model(pr)
test_model(model, TEST_START, END_DATE)
这个过程可以重复几次,因为在数据处理的每个阶段都有不确定性因素,不允许建立明确的模型。在所有迭代之后(训练期为1年,然后是5年的测试期),测试器获得了以下图表:
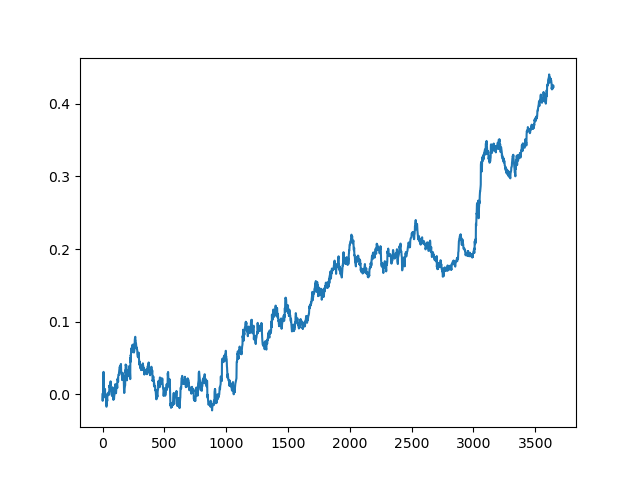
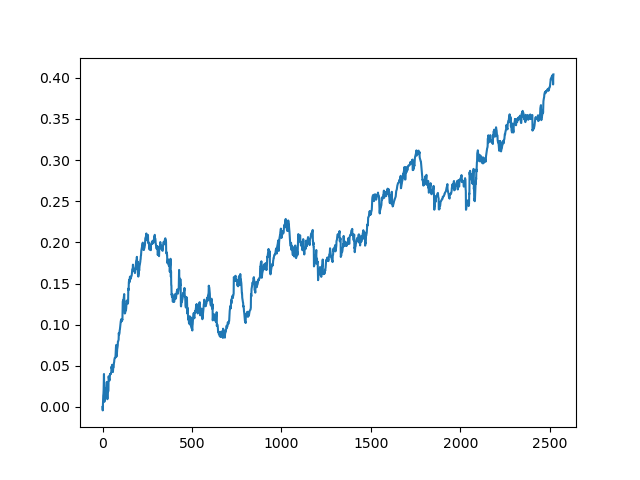
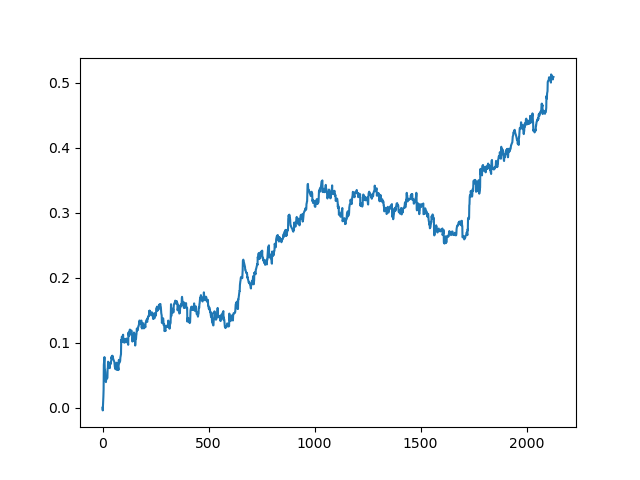
当然,这些结果并不是基准,它们只表明可以获得有利可图的(基于新数据的)模型。
现在让我们在分类器委员会上实现学习功能,看看会发生什么:
def active_learner_committee(data, learners_number, labeled_size, unlabeled_size, batch_size): X_pool = data[data.columns[1:-1]].to_numpy() y_pool = data[data.columns[-1]].to_numpy() cl = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3), n_estimators=50, learning_rate = 0.05) cl.fit(X_pool, y_pool) print('Score for the passive learning: ', cl.score( X_pool, y_pool), ' with train size: ', data.shape[0]) # initializing Committee members learner_list = list() # Pre-set our batch sampling to retrieve 3 samples at a time. preset_batch = partial(uncertainty_batch_sampling, n_instances=batch_size) for member_idx in range(learners_number): # initial training data train_idx = np.random.choice(range(X_pool.shape[0]), size=labeled_size, replace=False) X_train = X_pool[train_idx] y_train = y_pool[train_idx] # creating a reduced copy of the data with the known instances removed X_pool = np.delete(X_pool, train_idx, axis=0) y_pool = np.delete(y_pool, train_idx) # initializing learner learner = ActiveLearner( estimator=AdaBoostClassifier(DecisionTreeClassifier(max_depth=2), n_estimators=50, learning_rate = 0.05), query_strategy=preset_batch, X_training=X_train, y_training=y_train ) learner_list.append(learner) # assembling the committee committee = Committee(learner_list=learner_list) unqueried_score = committee.score(X_pool, y_pool) performance_history = [unqueried_score] N_QUERIES = unlabeled_size // batch_size for idx in range(N_QUERIES): query_idx, query_instance = committee.query(X_pool) committee.teach( X=X_pool[query_idx].reshape(1, -1), y=y_pool[query_idx].reshape(1, ) ) model_accuracy = committee.score(X_pool, y_pool) performance_history.append(model_accuracy) print('Accuracy after query {n}: {acc:0.4f}'.format( n=idx + 1, acc=model_accuracy)) # remove queried instance from pool X_pool = np.delete(X_pool, query_idx, axis=0) y_pool = np.delete(y_pool, query_idx) return committee
同样,我选择了批处理查询策略,以消除每次添加一个元素时重新训练模型的需要。剩下的部分,我已经创建了一个由任意数量的 AdaBoost 分类器组成的委员会(我认为添加超过5个分类器是没有意义的,但是您可以进行实验)。
以下是由五个模型组成的委员会的训练分数,这些模型的设置与前面的方法相同:
>>> committee = active_learner_committee(pr, 5, 1000, 1000, 50) Score for the passive learning: 0.6533842794759825 with train size: 5496 Accuracy after query 1: 0.5927 Accuracy after query 2: 0.5818 Accuracy after query 3: 0.5668 Accuracy after query 4: 0.5862 Accuracy after query 5: 0.5874 Accuracy after query 6: 0.5906 Accuracy after query 7: 0.5918 Accuracy after query 8: 0.5910 Accuracy after query 9: 0.5820 Accuracy after query 10: 0.5934 Accuracy after query 11: 0.5864 Accuracy after query 12: 0.5753 Accuracy after query 13: 0.5868 Accuracy after query 14: 0.5921 Accuracy after query 15: 0.5809 Accuracy after query 16: 0.5842 Accuracy after query 17: 0.5833 Accuracy after query 18: 0.5783 Accuracy after query 19: 0.5732 Accuracy after query 20: 0.5828
主动学习者委员会的成绩不如被动学习者委员会好,猜测原因是不可能的。也许这只是一个随机的结果。然后,我使用相同的原理多次运行生成的数据集,得到以下随机结果:
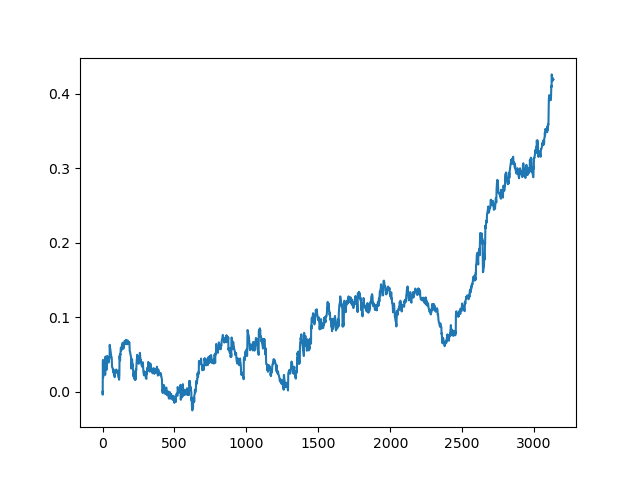
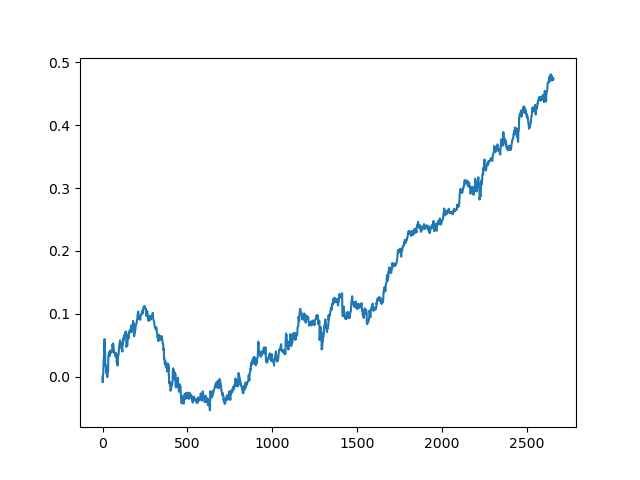
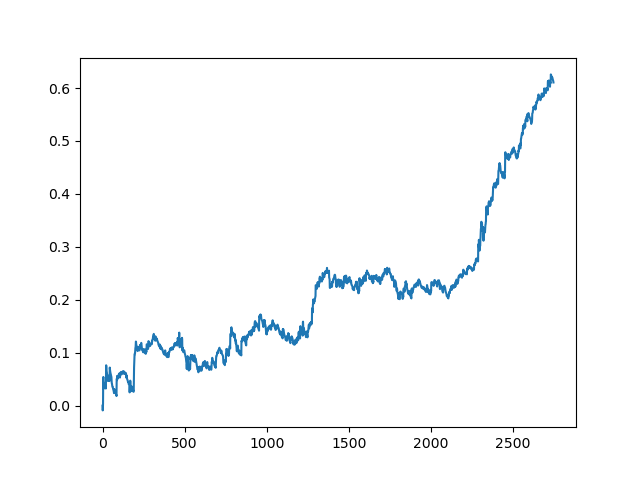
结论
在本文中,我们探讨了主动学习。印象还不清楚。一方面,从一小部分实例中学习总是很有诱惑力的,而且这些模型对于一些分类问题非常有效。然而,这离人工智能还很遥远。这种模型在垃圾数据中找不到稳定的模式,需要对特征和标签进行更彻底的准备,包括基于专家标签的数据准备。我没有看到模型质量有任何显著提高。同时,培训模型所需的劳动强度和时间也有所增加,这是一个不利因素。我喜欢主动学习的哲学和对人类思维特点的运用。附件提供了所有讨论过的函数。您可以进一步探索这些模型,并尝试以其他原创方式应用它们。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/8743
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。
 利用 CatBoost 算法寻找外汇市场的季节性模式
利用 CatBoost 算法寻找外汇市场的季节性模式
 神经网络变得轻松(第九部分):操作归档
神经网络变得轻松(第九部分):操作归档
 开发自适应算法 (第二部分): 提高效率
开发自适应算法 (第二部分): 提高效率
是的,但其他例子都没有标记
那么前 1000 个和额外 1000 个的分区是否适用?
那么,前 1000 次和增加的 1000 次的加价是否适用?
在一个小的标注数据集上进行训练,然后标注一个新的大数据集,从中选择置信度最低的点,添加,训练。如此循环往复
未标记数据和已标记数据的大小没有任何规定,正确指标的选择也是如此。因此,这里有一种实验方法--随心所欲)。
实际上,这与从估计分布中抽取示例非常相似,就像关于 GMM 的文章中的情况一样,所以我决定试试看。不过,第一种方法更有趣。
你好,马克西姆、
模型的学习是只在训练时进行一次,还是在实时交易时也在学习?
我的意思是,如果模型进行了任何亏损交易,它是否会在进行实时交易时自我学习?是 "主动机器学习"还是我理解错了?
谢谢
你好,马克西姆、
感谢你提供的英文版本。我有 3 个关于代码具体部分的问题,如果你能具体回答这些问题,我将不胜感激,因为我是一个初级程序员,仍然很难理解解释中的所有内容。
1.请问您从哪里以及如何获得以下数字,这些数字只适用于 "EURUSD "货币对还是所有货币对?
2.我想知道您是从哪里以及如何获得以下数字的,这些数字是否只适用于 "EURUSD "货币对还是所有货币对?
3.您能否准确地告诉我,我需要编辑代码的哪些部分才能使其适用于其他货币对?
我已经尝试了其他货币对,但我不确定是我做错了什么,还是其他货币对的结果不好,而欧元兑美元货币对的 结果很好。如果您能再发布一个其他货币对的示例,让我更好地了解如何实施才能使其适用于其他货币对,我将不胜感激。