
数据科学与机器学习(第四十二部分):使用Python中的ARIMA模型进行外汇时间序列预测 —— 您需要了解的一切

内容
- 什么是时间序列预测
- ARIMA模型简介
- ARIMA模型的核心组成部分
- 基于Python的ARIMA模型
- 基于欧元兑美元(EURUSD)构建ARIMA模型
- 基于ARIMA进行样本外预测
- ARIMA模型的残差图
- SARIMA模型
- 结论
什么是时间序列预测?
时间序列预测,是利用历史数据预测按时间排序的数据点未来取值的过程。这类数据通常按时间顺序排列,因此被称为时间序列。
时间序列数据的核心变量
尽管数据中可以包含任意多的特征变量,但任何用于时间序列分析或预测的数据,都必须包含以下两个变量:
- 时间
作为自变量,表示各个数据点被观测到的具体时间。 - 目标变量
即您希望基于历史观测值(以及可能的其他因素)预测的数值。(例如:每日股票收盘价、每小时气温、每分钟网站访问量)。
时间序列预测的目标,是挖掘数据中的历史规律与趋势,从而对未来数值做出可靠预测。
我们之前已经讨论过使用常规AI模型进行时间序列预测。在本文中,我们将改用专为时间序列问题设计的模型 —— ARIMA来进行时间序列预测。
可以将时间序列预测分为两类:
- 单变量时间序列预测
这类预测仅用一个变量来预测其自身的未来值。例如,用股票当前收盘价预测未来收盘价。
这正是ARIMA模型所能实现的预测类型。 - 多变量时间序列预测
ARIMA模型简介
ARIMA的全称是自回归积分移动平均模型。
它属于一类基于历史数据建模的方法,即利用时间序列的滞后项与滞后预测误差来解释当前序列。
其公式可直接用于预测未来数值。任何“非季节性”、存在规律模式、且不是纯随机白噪声的时间序列,都可以用ARIMA建模。
因此,简单来说,ARIMA是一种仅依靠时间序列的历史值就能预测未来值的预测算法。
ARIMA模型由三个阶数参数定义:(p, d, q),
其中:
- p 为AR项的阶数
- q为MA项的阶数
- d为使时间序列达到平稳所需的差分阶数
ARIMA模型中p、d、q的含义
p的含义
p是自回归(AR)项的阶数。它表示将多少期滞后的Y值用作预测变量。
d的含义
ARIMA中的自回归意味着这是一个线性回归模型,并使用自身的滞后值作为预测因子。众所周知,线性回归模型在预测变量互不相关、彼此独立时效果最优,因此我们需要让时间序列平稳。
使序列平稳最常用的方法是差分法,即用当前值减去前一期的值。有时,根据序列的复杂程度,可能需要进行多次差分。
因此,d表示使序列平稳所需的最少差分次数。如果时间序列本身已经平稳,则d = 0。
q的含义
q是移动平均(MA)项的阶数。它表示将多少期滞后的预测误差纳入ARIMA模型中。
ARIMA模型的核心组成部分
要理解ARIMA,我们需要拆解它的基本结构。将各组成部分拆分后,就能更轻松地理解这种时序预测方法的整体工作原理。
ARIMA的名称可以拆分为三个部分:AR、I、MA,具体如下。
自回归部分AR(p)
自回归(AR)组件基于历史数值构建趋势。简单来说,自回归模型类似于线性回归模型,但它使用时间序列自身过去的滞后值作为预测因子。
此部分通过以下公式计算:
![]()
其中:
-
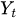 表示时间序列在t时刻的当前取值。
表示时间序列在t时刻的当前取值。 -
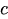 是常数项。
是常数项。 -
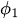 φ₁至φₚ为自回归参数(系数),用于表示各滞后项对当前值的影响程度。
φ₁至φₚ为自回归参数(系数),用于表示各滞后项对当前值的影响程度。 -
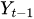 y_(t-1)至 y_(t-p)为时间序列的各期滞后历史值。
y_(t-1)至 y_(t-p)为时间序列的各期滞后历史值。 -
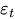 为t时刻的误差项。
为t时刻的误差项。
积分部分I(d)
积分(I)部分涉及对时间序列进行差分处理,同时需保证时间序列的平稳性,即序列的均值和方差在一段时间内保持恒定。
简单来说,就是将一个观测值减去另一个观测值,以消除趋势与季节性的影响。通过差分操作,我们可以使序列变得平稳。这一步至关重要,因为它能让模型拟合数据本身,而非拟合噪声。
移动平均部分MA(q)
移动平均(MA)组件关注观测值与滞后预测误差之间的关系。通过分析当前观测值与历史误差之间的关联,我们可以提取出数据中潜在趋势的有效信息。
我们可以将滞后预测误差视为误差项,移动平均模型会估算这些误差对最新观测值的影响并将其纳入模型。这一方法尤其适用于捕捉数据中的短期波动与随机冲击。在时间序列的MA部分中,我们能获取序列行为的关键信息,从而实现更精准的预测。
![]()
其中:
-
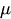 是常数值。
是常数值。 -
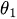 是MA参数。
是MA参数。 -
 是上一期的误差项。
是上一期的误差项。 -
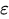 是当前的误差项。
是当前的误差项。
基于Python的ARIMA模型
因此,ARIMA模型就是上述AR、I、MA三个部分的简单组合。其公式如下:
![]()
在ARIMA模型中,关键难点在于确定合适的参数(p、d、q取值)。因为这些参数决定了模型的运行效果,让我们来学习如何确定这些参数。
确定AR项的阶数(p)
我们可以通过观察偏自相关函数(PACF)图来确定所需的AR项数量。
偏自相关是指剔除中间滞后项的影响后,序列与它的滞后项之间的相关关系。因此,PACF反映的是某一滞后项与序列之间的纯相关度。通过这种方式,我们就能判断该滞后项是否需要纳入AR项中。
首先在命令提示符(CMD)中安装所有依赖库。本文末尾附有requirements.txt文件。
pip install -r requirements.txt
导入:
# Importing required libraries import pandas as pd import numpy as np import MetaTrader5 as mt5 # Use auto_arima to automatically select best ARIMA parameters import seaborn as sns import matplotlib.pyplot as plt import warnings import os # Suppress warning messages for cleaner output warnings.filterwarnings("ignore") # Set seaborn plot style for better visualization sns.set_style("darkgrid")
从MetaTrader5中获取数据。
# Getting (EUR/USD OHLC data) from MetaTrader5 mt5_exe_file = r"c:\Users\Omega Joctan\AppData\Roaming\Pepperstone MetaTrader 5\terminal64.exe" # Change this to your MetaTrader5 path if not mt5.initialize(mt5_exe_file): print("Failed to initialize Metatrader5, error = ",mt5.last_error) exit() # select a symbol into the market watch symbol = "EURUSD" timeframe = mt5.TIMEFRAME_D1 if not mt5.symbol_select(symbol, True): print(f"Failed to select {symbol}, error = {mt5.last_error}") mt5.shutdown() exit() rates = mt5.copy_rates_from_pos(symbol, timeframe, 1, 1000) # Get 1000 bars historically df = pd.DataFrame(rates) print(df.head(5)) print(df.shape)
PACF图。
from statsmodels.graphics.tsaplots import plot_pacf import matplotlib.pyplot as plt plt.figure(figsize=(6,4)) plot_pacf(series.diff().dropna(), lags=5) plt.title("Partial Autocorrelation Plot") plt.xlabel('Lag') # X-axis label plt.ylabel('PACF') # Y-axis label plt.savefig("pacf plot.png") plt.show()
输出:
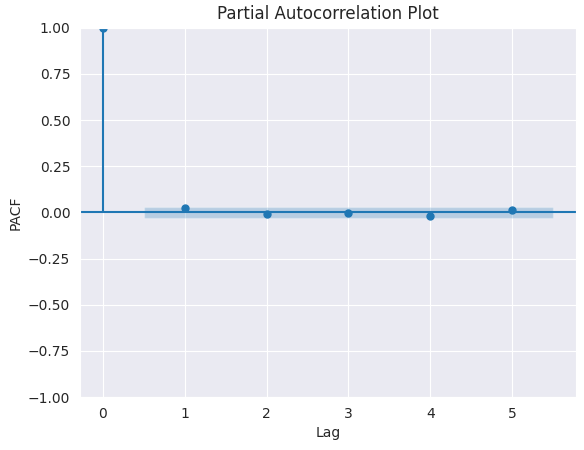
要确定合适的p值,我们需要在图中寻找PACF截断对应的滞后阶数(即相关系数降至接近0且不再显著)。该滞后阶数即为p的合理取值。
由上图可见,合适的p值为0(0阶之后的所有滞后项均不显著)。
确定ARIMA模型中的差分阶数(d)
如前所述,对时间序列进行差分的目的是使其平稳,因为ARIMA模型假设序列是平稳的。但需要注意的是,应避免对时间序列差分不足或过度差分。
合适的差分阶数,是使序列达到近似平稳所需的最小差分次数。平稳序列会围绕一个固定均值波动,并且自相关函数(ACF)图会快速衰减至零附近。
如果序列在很多滞后阶数(10阶及以上)上自相关系数均为正值,说明序列需要进一步差分。反之,如果滞后1阶的自相关系数负值过大,则说明序列很可能已经过度差分。
当难以在两个差分阶数之间做选择时,我们应选择使差分后序列标准差更小的那个阶数。
让我们以欧元兑美元(EURUSD)的收盘价为例,确定合适的差分阶数。
首先,我们需要借助Python中statsmodels库提供的增广迪基 - 富勒检验(ADF检验),检查给定序列(本例中为收盘价)是否平稳。我们要检验平稳性,因为只有非平稳序列才需要计算差分阶数。
ADF检验的原假设(H₀)为时间序列是非平稳的。因此,如果检验的p值小于显著性水平(0.05),我们就拒绝原假设,并推断该时间序列确实是平稳的。
所以,在本例中,如果p值大于0.05,我们就需要继续计算合适的差分阶数。
甚至在进行ADF检验之前,我们仅通过观察折线图,就能判断欧元兑美元的收盘价是非平稳的。
plt.figure(figsize=(7,5)) sns.lineplot(df, x=df.index, y="Close") plt.savefig("close prices.png")
输出:
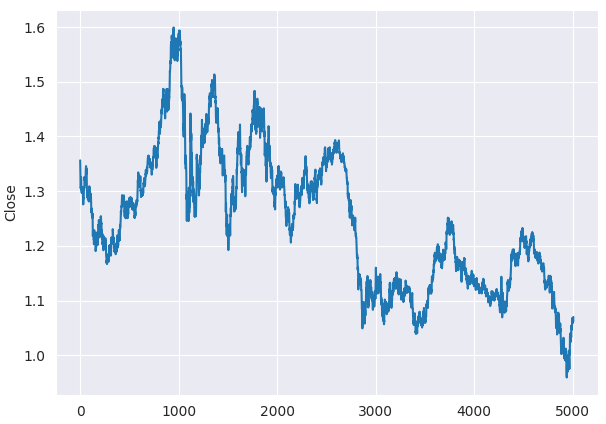
检验平稳性。
from statsmodels.tsa.stattools import adfuller series = df["Close"] result = adfuller(series) print(f'p-value: {result[1]}')
输出:
p-value: 0.3707268514544181
由此可见,p值远大于显著性水平(0.05)。让我们对序列做一次差分,再做二次差分,然后观察自相关图的变化。
# Original Series fig, axes = plt.subplots(3, 2, sharex=True, figsize=(9, 9)) axes[0, 0].plot(series); axes[0, 0].set_title('Original Series') plot_acf(series, ax=axes[0, 1]) # 1st Differencing axes[1, 0].plot(series.diff().dropna()); axes[1, 0].set_title('1st Order Differencing') plot_acf(series.diff().dropna(), ax=axes[1, 1]) # 2nd Differencing axes[2, 0].plot(series.diff().diff()); axes[2, 0].set_title('2nd Order Differencing') plot_acf(series.diff().diff().dropna(), ax=axes[2, 1]) plt.savefig("acf plots.png") plt.show()
输出:
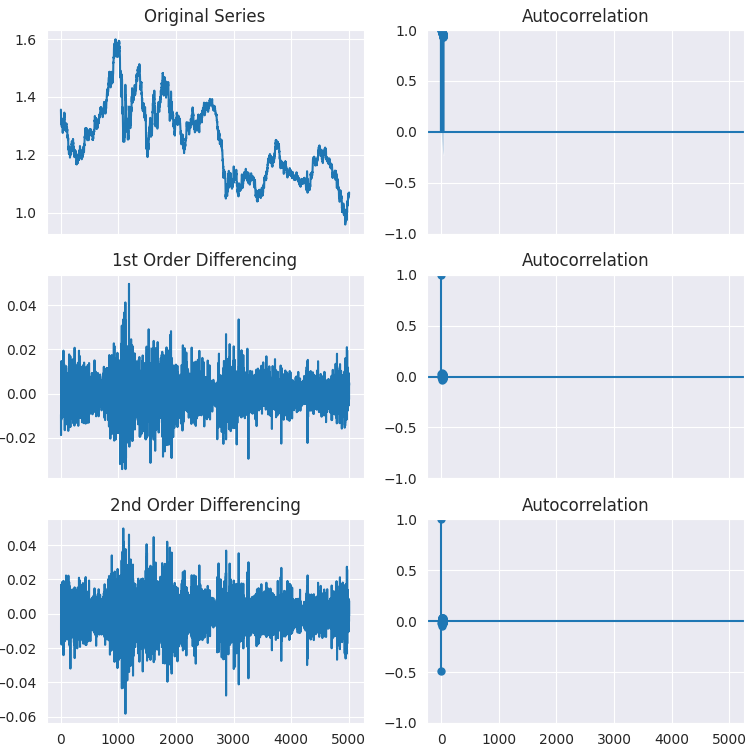
由图可见,一阶差分已经达到了平稳效果,二阶差分后的平稳性并没有显著提升。这一点可以再次通过ADF检验进行验证。
result = adfuller(series.diff().dropna()) print(f'p-value d=1: {result[1]}') result = adfuller(series.diff().diff().dropna()) print(f'p-value d=2: {result[1]}')
输出:
p-value d=1: 0.0 p-value d=2: 0.0
确定MA项的阶数(q)
正如通过查看PACF图来确定AR项的数量一样,我们将借助ACF图以判断MA项的数量。重申一下,严格来说,MA项指的是滞后预测的误差值。
ACF图告诉我们,需要多少个MA项才能消除平稳序列中残留的自相关性。
plt.figure(figsize=(7,5)) plot_pacf(series.diff().dropna(), lags=20) plt.title("Partial Autocorrelation Plot") plt.xlabel('Lag') # X-axis label plt.ylabel('PACF') # Y-axis label plt.savefig("pacf plot finding q.png") plt.show()
输出:
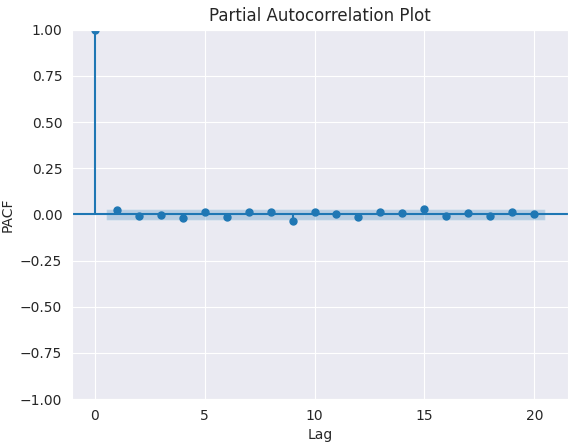
q的最佳值是0。
上述讨论的确定p、d、q值的方法比较原始且需要手动操作。现在,我们可以借助pmdarima库中名为 auto_arima的工具函数,自动完成这一过程,轻松获得这些参数。
from pmdarima.arima import auto_arima model = auto_arima(series, seasonal=False, trace=True) print(model.summary())
输出:
Performing stepwise search to minimize aic ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=-35532.282, Time=3.21 sec ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=-35537.068, Time=0.49 sec ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=-35537.492, Time=0.59 sec ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=-35537.511, Time=0.74 sec ARIMA(0,1,0)(0,0,0)[0] : AIC=-35538.731, Time=0.25 sec ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=-35535.683, Time=1.22 sec Best model: ARIMA(0,1,0)(0,0,0)[0] Total fit time: 6.521 seconds
这样一来,我们得到了与手动分析完全一致的参数。
基于欧元兑美元构建ARIMA模型
既然已经确定了p、d、q的取值,我们就具备了拟合(训练)ARIMA模型所需的全部条件。
from statsmodels.tsa.arima.model import ARIMA arima_model = ARIMA(series, order=(0,1,0)) arima_model = arima_model.fit() print(arima_model.summary())
输出:
SARIMAX Results ============================================================================== Dep. Variable: Close No. Observations: 4007 Model: ARIMA(0, 1, 0) Log Likelihood 13987.647 Date: Mon, 26 May 2025 AIC -27973.293 Time: 16:59:38 BIC -27966.998 Sample: 0 HQIC -27971.062 - 4007 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 5.427e-05 7.78e-07 69.768 0.000 5.27e-05 5.58e-05 =================================================================================== Ljung-Box (L1) (Q): 1.47 Jarque-Bera (JB): 1370.86 Prob(Q): 0.22 Prob(JB): 0.00 Heteroskedasticity (H): 0.49 Skew: 0.09 Prob(H) (two-sided): 0.00 Kurtosis: 5.86 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
现在,我们用部分数据训练该模型,并利用它对样本外数据进行预测,这与使用传统机器学习模型的思路是一样的。
首先,将数据划分为训练集与测试集。
series = df["Close"] train_size = int(len(series) * 0.8) train, test = series[:train_size], series[train_size:]
将模型拟合到训练数据上。
from statsmodels.tsa.arima.model import ARIMA arima_model = ARIMA(train, order=(0,1,0)) arima_model = arima_model.fit() print(arima_model.summary())
对训练数据进行预测。
predicted = arima_model.predict(start=1, end=len(train))
可视化输出结果。
plt.figure(figsize=(7,4)) plt.plot(train.index, train, label='Actual') plt.plot(train.index, predicted, label='Forecasted mean', linestyle='--') plt.title('Actual vs Forecast') plt.legend() plt.show()
输出:
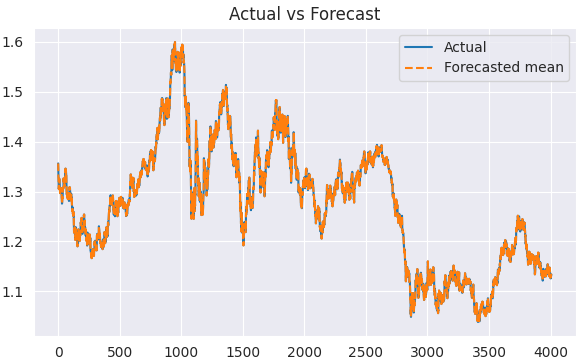
现在,我们有了真实值和对应的预测值,就可以选用任意评估方法或损失函数来评估模型效果。
但在此之前,让我们先学习如何用此ARIMA模型对样本外数据进行预测。
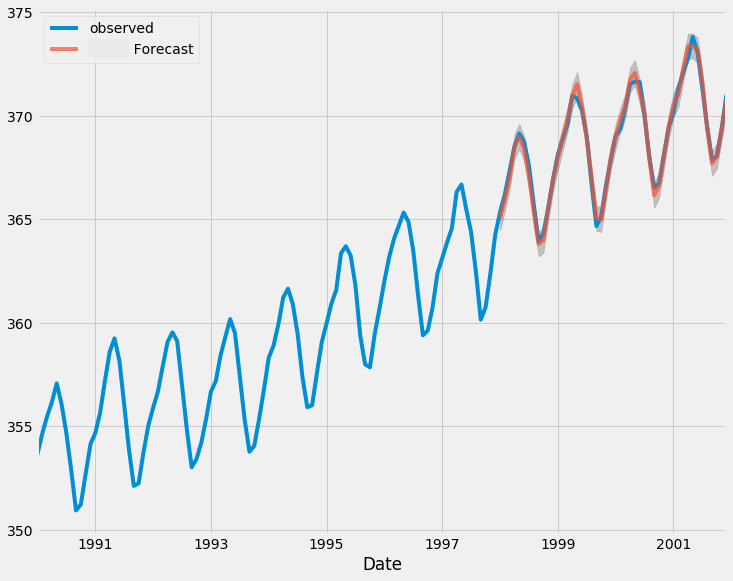
基于ARIMA进行样本外预测
与传统机器学习算法不同,这类经典时间序列预测模型在处理未见过的新数据时,采用的是完全不同的方法。
在常规机器学习框架和Python库中,调用predict方法并传入一组数据,模型就会预测/估计未来值;但ARIMA模块提供的predict函数功能却截然不同。
在ARIMA模型中,该方法并不直接预测未来值,而是仅适用于对样本内数据(即模型已见过的训练集数据)做出预测。
为了理解这一点,我们先区分一下预测和未来预测的差别。
预测泛指用模型估计未知值(可以是未来值或其他缺失值),而未来预测专指利用时间模式和时序依赖关系,预测时间序列未来的值。
预测可用于判断市场方向、估计下一期收盘价等任务;而未来预测专指利用时间模式和时序依赖关系,预测时间序列未来的值。
在ARIMA模型中,predict方法通常用于对模型已经学习过的历史数据做拟合预测,这也是它需要传入起始索引和结束索引的原因。它同样可以指定您想要回测(评估)的历史步长数。
predicted = arima_model.predict(start=1, end=len(train))
print(arima_model.predict(steps=10))
要预测未来值,我们必须使用名为forecast()的方法。
如前所述,ARIMA这类传统时间序列模型依赖前序数据来预测下一时刻的值,这一点由图03中的公式可见。
这就意味着我们需要不断用新数据更新模型,才能保证预测有效。例如,要用ARIMA预测欧元兑美元明日的收盘价,就必须向模型输入今日的收盘价;明日预测后天价格时也是同理。
这与传统机器学习的做法有很大区别。
现在,让我们开始对样本外数据进行预测。
# Fit initial model model = ARIMA(train, order=(0, 1, 0)) results = model.fit() # Initialize forecasts forecasts = [results.forecast(steps=1).iloc[0]] # First forecast # Update with test data iteratively for i in range(len(test)): # Append new observation without refitting results = results.append(test.iloc[i:i+1], refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) forecasts = forecasts[:-1] # remove the last element which is the predicted next value # Compare forecasts vs actual test data plt.plot(test.index, test, label="Actual") plt.plot(test.index, forecasts, label="Forecast", linestyle="--") plt.legend()
append方法会将新的(当前)数据并入模型中。在本例中,使用欧元兑美元的当前收盘价来预测下一期收盘价。
将refit设置为False,确保模型不会重新训练。这是更新ARIMA模型的高效方式。
让我们编写一个包含若干评估指标的函数,用于评估ARIMA模型的表现。
import sklearn.metrics as metric from statsmodels.tsa.stattools import acf from scipy.stats import pearsonr def forecast_accuracy(forecast, actual): # Convert to numpy arrays if they aren't already forecast = np.asarray(forecast) actual = np.asarray(actual) metrics = { 'mape': metric.mean_absolute_percentage_error(actual, forecast), 'me': np.mean(forecast - actual), # Mean Error 'mae': metric.mean_absolute_error(actual, forecast), 'mpe': np.mean((forecast - actual) / actual), # Mean Percentage Error 'rmse': metric.mean_squared_error(actual, forecast, squared=False), 'corr': pearsonr(forecast, actual)[0], # Pearson correlation 'minmax': 1 - np.mean(np.minimum(forecast, actual) / np.maximum(forecast, actual)), 'acf1': acf(forecast - actual, nlags=1)[1], # ACF of residuals at lag 1 "r2_score": metric.r2_score(forecast, actual) } return metrics
forecast_accuracy(forecasts, test)
输出:
{'mape': 0.0034114761554881936,
'me': 6.360279441117738e-05,
'mae': 0.0037872155688622737,
'mpe': 6.825424905960248e-05,
'rmse': 0.005018824533752777,
'corr': 0.99656297100796,
'minmax': 0.0034008221524469695,
'acf1': 0.04637470541528736,
'r2_score': 0.9931220697334551} MAPE值为0.003,表明模型准确率约为99.996%,这一结果与R²决定系数基本一致。
测试集上真实值与预测值的对比图如下:
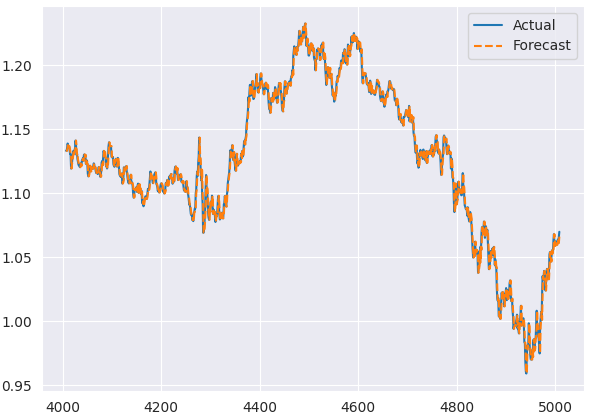
ARIMA模型的残差图
ARIMA提供了残差的可视化方法,便于更直观地理解模型效果。
results.plot_diagnostics(figsize=(8,8)) plt.show()
输出:
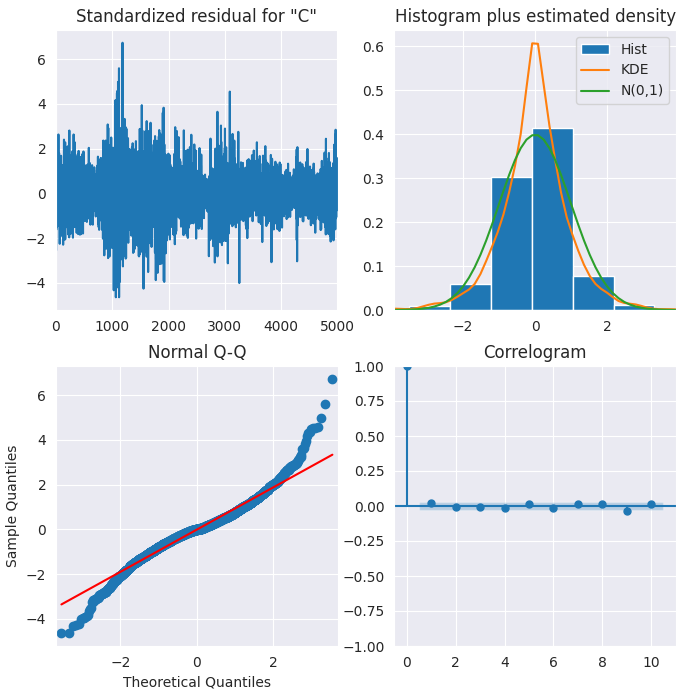
标准化残差
残差看起来围绕均值0上下波动,且方差基本均匀。
直方图
密度分布图显示残差近似服从正态分布,均值略微向右偏移。
理论分位数图
绝大多数点都与红色参考直线高度重合。如果出现明显偏离,则说明分布存在偏斜。
自相关图
自相关图(ACF图)表明残差序列不存在自相关性。如果ACF图显示残差仍存在某种模式,说明模型未能完全解释这些信息,需要引入更多自变量(预测因子)。
总体来看,该模型的拟合效果良好。
SARIMA模型
普通 ARIMA 模型的一个局限在于,它无法显式建模季节性。
季节性是指金融数据中按固定周期重复出现的规律,比如按小时、日、周、月、季度和年度循环的模式。
我们经常会看到交易品种呈现出某些重复性规律。例如,零售类股票通常在第四季度(假日购物季)上涨,部分能源股会随季节性天气变化波动;而在外汇品种中,某些交易时段内市场波动率会明显升高,等等。
如果时间序列数据存在明显或可确定的季节性,那么我们就应该选用季节性ARIMA 模型(简称SARIMA),因为它引入了季节性差分。
SARIMAX(p, d, q)x(P, D, Q, S) 模型组成
- 自回归项(AR)
如前所述,自回归通过时间序列的历史值来预测当前值。 - 移动平均项(MA)
移动平均项用于对历史预测误差进行建模。 - 差分阶数(I)
差分操作始终存在,目的是让时间序列变为平稳序列。 - 季节性项(S)
季节性项用于捕捉按固定周期重复出现的波动变化。
季节性差分与普通差分类似,但区别在于:普通差分是用当期值减去前一期值,而季节性差分是用当期值减去上一个季节周期对应的值。
在调用SARIMAX模型之前,我们先用auto_arima确定其最优参数。
from pmdarima.arima import auto_arima # Auto-fit SARIMA (automatically detects P, D, Q, S) auto_model = auto_arima( series, seasonal=True, # Enable seasonality m=5, # Weeky cycle (5 days) for daily data trace=True, # Show search progress stepwise=True, # Faster optimization suppress_warnings=True, error_action="ignore" ) print(auto_model.summary())
输出:
Performing stepwise search to minimize aic ARIMA(2,1,2)(1,0,1)[5] intercept : AIC=-35529.092, Time=3.81 sec ARIMA(0,1,0)(0,0,0)[5] intercept : AIC=-35537.068, Time=0.29 sec ARIMA(1,1,0)(1,0,0)[5] intercept : AIC=-35536.573, Time=0.97 sec ARIMA(0,1,1)(0,0,1)[5] intercept : AIC=-35536.570, Time=4.38 sec ARIMA(0,1,0)(0,0,0)[5] : AIC=-35538.731, Time=0.21 sec ARIMA(0,1,0)(1,0,0)[5] intercept : AIC=-35536.048, Time=0.67 sec ARIMA(0,1,0)(0,0,1)[5] intercept : AIC=-35536.024, Time=0.87 sec ARIMA(0,1,0)(1,0,1)[5] intercept : AIC=-35534.248, Time=0.92 sec ARIMA(1,1,0)(0,0,0)[5] intercept : AIC=-35537.492, Time=0.37 sec ARIMA(0,1,1)(0,0,0)[5] intercept : AIC=-35537.511, Time=0.55 sec ARIMA(1,1,1)(0,0,0)[5] intercept : AIC=-35535.683, Time=0.57 sec Best model: ARIMA(0,1,0)(0,0,0)[5] Total fit time: 13.656 seconds SARIMAX Results ============================================================================== Dep. Variable: y No. Observations: 5009 Model: SARIMAX(0, 1, 0) Log Likelihood 17770.365 Date: Tue, 27 May 2025 AIC -35538.731 Time: 11:16:40 BIC -35532.212 Sample: 0 HQIC -35536.446 - 5009 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 4.846e-05 6.06e-07 80.005 0.000 4.73e-05 4.96e-05 =================================================================================== Ljung-Box (L1) (Q): 2.42 Jarque-Bera (JB): 2028.68 Prob(Q): 0.12 Prob(JB): 0.00 Heteroskedasticity (H): 0.34 Skew: 0.08 Prob(H) (two-sided): 0.00 Kurtosis: 6.11 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
虽然auto_arima会直接返回一个SARIMAX模型,无需再手动重新拟合,但手动再次拟合SARIMAX模型能够对结果拥有更多控制权,因此,我们还要再执行一次拟合。
from statsmodels.tsa.statespace.sarimax import SARIMAX model = SARIMAX( train, order=auto_model.order, # Non-seasonal (p,d,q) seasonal_order=auto_model.order+(5,), # Seasonal (P,D,Q,S) enforce_stationarity=False ) results = model.fit() print(results.summary())
输出:
SARIMAX Results ========================================================================================= Dep. Variable: Close No. Observations: 4007 Model: SARIMAX(0, 1, 0)x(0, 1, 0, 5) Log Likelihood 12613.829 Date: Tue, 27 May 2025 AIC -25225.658 Time: 11:16:41 BIC -25219.364 Sample: 0 HQIC -25223.427 - 4007 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 0.0001 1.68e-06 63.423 0.000 0.000 0.000 =================================================================================== Ljung-Box (L1) (Q): 3.42 Jarque-Bera (JB): 676.61 Prob(Q): 0.06 Prob(JB): 0.00 Heteroskedasticity (H): 0.48 Skew: -0.01 Prob(H) (two-sided): 0.00 Kurtosis: 5.01 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
尽管已经将季节性参数设置为true,但auto_model返回的阶数仍然仅适用于ARIMA(p,d,q)。在定义SARIMAX模型时,我们必须在元组末尾追加数值5,确保阶数格式为(p,d,q,s)。
在对真实值和预测值进行可视化展示与分析之前,我们需要剔除数组中前若干个数据,剔除数量等于季节性周期长度,因为这部分数据对应的信息不完整。
predicted = results.predict(start=1, end=len(train)) clean_train = train[5:] clean_predicted = predicted[5:] plt.figure(figsize=(7,4)) plt.plot(clean_train.index[5:], clean_train[5:], label='Actual') plt.plot(clean_train.index[5:], clean_predicted[5:], label='Forecasted mean', linestyle='--') plt.title('Actual vs Forecast') plt.legend() plt.savefig("sarimax train actual&forecast plot.png") plt.show()
输出:
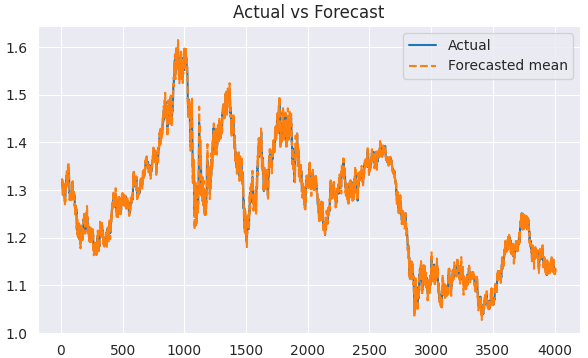
我们可以使用与评估ARIMA模型完全相同的方法来评估该SARIMA模型。
# Initialize forecasts forecasts = [results.forecast(steps=1).iloc[0]] # First forecast # Update with test data iteratively for i in range(len(test)): # Append new observation without refitting results = results.append(test.iloc[i:i+1], refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) clean_test = test[5:] forecasts = forecasts[5:-1] # remove the last element which is the predicted next value and the first 5 items
forecast_accuracy(forecasts, clean_test)
输出:
{'mape': 0.004900183060803821,
'me': -6.94082142749275e-06,
'mae': 0.005432456867698095,
'mpe': -7.226495372320155e-06,
'rmse': 0.007127465498996785,
'corr': 0.9931778828074744,
'minmax': 0.004880027322298863,
'acf1': 0.10724254539104018,
'r2_score': 0.9864021833085908} 从R²指标来看,模型拟合表现较好,约为 0.986。这是一个相当不错的结果。
最后,我们可以使用ARIMA模型,根据从MetaTrader5中获取的数据进行实时预测。
首先,我们需要导入schedule库,以实现每日定时预测 ,因为该模型是基于日周期数据训练的。
import schedule # Make realtime predictions based on the recent data from MetaTrader5 def predict_close(): rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 1) if not rates: print(f"Failed to get recent OHLC values, error = {mt5.last_error}") time.sleep(60) rates_df = pd.DataFrame(rates) global results # Get the variable globally, outside the function global forecasts # Append new observation to the model without refitting new_obs_value = rates_df["close"].iloc[-1] new_obs_index = results.data.endog.shape[0] # continue integer index new_obs = pd.Series([new_obs_value], index=[new_obs_index]) # Its very important to continue making predictions where we ended on the training data results = results.append(new_obs, refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) print(f"Current Close Price: {new_obs_value} Forecasted next day Close Price: {forecasts[-1]}")
通过schedule按日定时执行预测任务。
schedule.every(1).days.do(predict_close) # call the predict function after a given time while True: schedule.run_pending() time.sleep(60) mt5.shutdown()
输出:
Current Close Price: 1.1374900000000001 Forecasted next day Close Price: 1.1337899981049262 Current Close Price: 1.1372200000000001 Forecasted next day Close Price: 1.1447100065656721
根据这些预测的收盘价,您可以将其扩展为一套交易策略,并通过MetaTrader5-Python接口执行实际交易操作。
总结
ARIMA和SARIMA都是表现不错的传统时间序列模型,已被广泛应用于多个领域和行业。但您必须了解它们的局限与缺点,其中包括:
- 它们要求序列平稳(差分后)
但在实际应用中,我们并非总能拿到平稳的数据,且常常希望直接使用原始数据。对数据做差分处理,可能会破坏我们关注的原有数据结构与趋势。 - 线性假设
ARIMA本质上是线性模型,它假设未来值与历史滞后项、历史误差之间呈线性关系。这在金融和外汇市场的走势中并不成立,因为复杂的非线性形态才是常态,这意味着这类模型在某些场景下效果会很差。 - 单变量模型
这两种模型一次只能使用单一特征。众所周知,金融市场非常复杂,需要多个特征和多角度才能全面分析市场。这类模型只能从单一维度观察市场,会让我们遗漏其他有价值的信息。
即便可以在SARIMAX模型中加入外生变量,但通常也远远不够。
尽管存在这些局限,但在参数合适、问题类型匹配、数据信息充分的前提下,简单的ARIMA 模型在时间序列预测上,甚至可以优于RNN这类复杂模型。
谨此结束。
来源与参考文献
- https://www.geeksforgeeks.org/python-arima-model-for-time-series-forecasting/
- https://www.machinelearningplus.com/time-series/arima-model-time-series-forecasting-python/
- https://datascientest.com/en/sarimax-model-what-is-it-how-can-it-be-applied-to-time-series
- https://www.kaggle.com/code/prashant111/arima-model-for-time-series-forecasting
附件表
| 文件名 | 说明/用法 |
|---|---|
| forex_ts_forecasting_using_arima.py | 包含本文探讨的所有案例的完整Python脚本 |
| requirements.txt | 包含Python依赖项及其版本号的文本文件 |
本文由MetaQuotes Ltd译自英文
原文地址: https://www.mql5.com/en/articles/18247
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

令人惊叹的内容。
正是我想要的。
可能不会在交易中使用它,但非常有趣。
第一次听说 ARIMA 是在 Perry J Kaufman 的《交易系统与方法》一书中。
有人使用 ARIMA 成功交易过吗?