
Машинное обучение и Data Science (Часть 42): Прогнозирование временных рядов на форексе с ARIMA и Python

Содержание
- Что такое прогнозирование временных рядов?
- Введение в модели ARIMA
- Основные компоненты модели ARIMA
- Модель ARIMA на Python
- Построение модели ARIMA для EURUSD
- Прогнозирование вне выборки с использованием модели ARIMA
- Графики остатков модели ARIMA
- Модель SARIMA
- Заключение
Что такое прогнозирование временных рядов?
Прогнозирование временных рядов — это процесс использования прошлых данных для прогнозирования будущих значений в последовательности точек данных. Эта последовательность обычно упорядочена по времени, отсюда и название временной ряд.
Основные переменные во временных рядах
В данных может быть сколько угодно переменных признаков, но все данные для анализа временных рядов или прогнозирования должны содержать вот эти две переменные:
- Время
Это независимая переменная, представляющая конкретные моменты времени, когда наблюдались точки данных. - Целевая переменная
Это значение, которое вы пытаетесь предсказать на основе прошлых наблюдений и, возможно, других факторов. (Например, дневная цена закрытия акций, почасовая температура, поминутный трафик веб-сайта).
Целью прогнозирования временных рядов является использование исторических закономерностей и тенденций в данных для составления обоснованных прогнозов относительно будущих значений.
Ранее мы рассматривали прогнозирование временных рядов с помощью стандартных моделей. В этой статье мы обсудим прогнозирование с использованием модели, специально разработанной для задач временных рядов — ARIMA.
Прогнозирование временных рядов можно разделить на два типа:
- Прогнозирование одномерных временных рядов
Проблема прогнозирования, где используется один предиктор для предсказания его будущих значений. Например, использование текущих цен закрытия акции для предсказания будущих цен закрытия.
Это именно тот тип прогнозирования, который поддерживают модели ARIMA. - Прогнозирование многомерных временных рядов
Проблема прогнозирования, где для предсказания целевой переменной используются несколько предикторов.
Аналогично примеру, который мы рассматривали в более ранней статье.
Введение в модели ARIMA
ARIMA расшифровывается как Autoregressive Integrated Moving Average = авторегрессия с интегрированной скользящей средней.
Она относится к классу моделей, которые описывают временной ряд на основе его прошлых значений, т.е. сдвигов и ошибок прогнозирования по таким сдвигам.
Эта модель позволяет прогнозировать будущие значения. Любой несезонный временной ряд, который демонстрирует закономерности и не является случайным шумом, можно моделировать с помощью ARIMA.
Иными словами, ARIMA — это алгоритм прогнозирования, основанный на предположении, что информация из прошлых значений временного ряда сама по себе может использоваться для предсказания будущих значений.
Модели ARIMA задаются тремя параметрами порядка: (p, d, q),
где:
- p — порядок авторегрессии (AR)
- q — количество дифференцирований для приведения ряда к стационарному виду
- d — порядок скользящей средней (MA)
Значение параметров p, d и q в модели ARIMA
Значение p
p — это порядок авторегрессии (AR). Он указывает количество лагов Y, используемых в качестве предикторов (насколько далеко в прошлое делается анализ для предсказания).
Значение d
AR в ARIMA — это линейная регрессия, использующая собственные лаги ряда в качестве предикторов. Линейные модели работают лучше всего, когда предикторы независимы друг от друга. Чтобы достичь этого, ряд должен быть стационарным.
Наиболее распространенный способ сделать ряд стационарным — дифференцирование, т.е. вычитание предыдущего значения из текущего. В сложных рядах может потребоваться несколько дифференцирований.
Значение d — это минимальное количество дифференцирований, необходимое для приведения ряда к стационарному виду. Если ряд уже стационарен, d = 0.
Значение q
q — порядок скользящей средней (MA). Он указывает количество ошибок прогнозирования на лагах, включаемых в модель ARIMA.
Ключевые компоненты модели ARIMA
Чтобы понять ARIMA, давайте разберем, из чего эта модель состоит. После того как мы разберем компоненты, станет проще понять, как в целом работает этот метод прогнозирования временных рядов.
Название ARIMA можно разделить на три части (AR, I, MA). Рассмотрим каждую часть.
Авторегрессионная часть AR(p)
В рамках авторегрессионной модели компонент авторегрессии (AR) строит тренд на основе прошлых значений ряда. Поясню, что "авторегрессионная модель" работает как регрессионная модель, в которой в качестве регрессоров используются лаги временного ряда.
Эта часть рассчитывается по следующей формуле:
![]()
где:
-
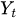 — текущее значение ряда
— текущее значение ряда -
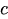 — константа
— константа -
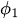 до
до 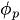 — параметры авторегрессии (коэффициенты), указывающие на то, какой вклад в текущее значение вносит каждый лаг
— параметры авторегрессии (коэффициенты), указывающие на то, какой вклад в текущее значение вносит каждый лаг -
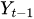 до
до 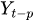 — прошлые лаги ряда
— прошлые лаги ряда -
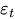 — ошибка на момент t
— ошибка на момент t
Интегрированная часть I(d)
Интегрированная часть включает в себя дифференцирование временного ряда для обеспечения стационарности. Это означает, что среднее значение и дисперсия должны оставаться постоянными в течение определенного периода времени.
По сути, мы вычитаем одно наблюдение из другого, чтобы исключить тренды и сезонность. Выполняя дифференцирование, мы получаем стационарность. Этот шаг позволяет модели фокусироваться на закономерностях, а не на шуме.
Часть MA(q) - скользящая средняя
Компонент скользящей средней анализирует связь текущего наблюдения с ошибками прошлых прогнозов. Такой анализ позволяет делать полезные выводы о возможных тенденциях в данных.
Остатки можно рассматривать как один из видов таких ошибок, и концепция модели скользящей средней оценивает или учитывает их влияние на текущее наблюдение. Это особенно полезно для отслеживания и выявления краткосрочных изменений в данных или случайных шоков. В компоненте MA временного ряда можно получить ценную информацию о поведении, что, в свою очередь, позволяет выполнять прогнозирование с большей точностью.
![]()
где:
-
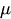 — константа
— константа -
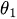 — параметр скользящей средней
— параметр скользящей средней -
 — предыдущая ошибка
— предыдущая ошибка -
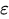 — текущая ошибка
— текущая ошибка
Модель ARIMA в Python
Таким образом, модель ARIMA представляет собой комбинацию трех частей, описанных выше: AR, I и MA. Соответственно, ее уравнение принимает следующий вид.
![]()
Основная сложность при использовании моделей ARIMA заключается в подборе правильных параметров p, d и q. Поскольку именно эти значения определяют работу модели, важно понять, как их правильно определить.
Определение порядка авторегрессии (p)
Необходимое количество AR-компонентов можно определить, анализируя график частичной автокорреляции (PACF).
Частичная автокорреляция — это корреляция между временным рядом и его лагами после исключения влияния промежуточных лагов. Таким образом, PACF отражает чистую корреляцию между лагом и самим рядом. Это позволяет определить, необходимо ли включать данный лаг в AR-компонент модели.
Начнем с установки всех зависимостей через командную строку (CMD). Файл requirements.txt прикреплен в конце этой статьи.
pip install -r requirements.txt
Импорт.
# Importing required libraries import pandas as pd import numpy as np import MetaTrader5 as mt5 # Use auto_arima to automatically select best ARIMA parameters import seaborn as sns import matplotlib.pyplot as plt import warnings import os # Suppress warning messages for cleaner output warnings.filterwarnings("ignore") # Set seaborn plot style for better visualization sns.set_style("darkgrid")
Получение данных из MetaTrader 5.
# Getting (EUR/USD OHLC data) from MetaTrader5 mt5_exe_file = r"c:\Users\Omega Joctan\AppData\Roaming\Pepperstone MetaTrader 5\terminal64.exe" # Change this to your MetaTrader5 path if not mt5.initialize(mt5_exe_file): print("Failed to initialize Metatrader5, error = ",mt5.last_error) exit() # select a symbol into the market watch symbol = "EURUSD" timeframe = mt5.TIMEFRAME_D1 if not mt5.symbol_select(symbol, True): print(f"Failed to select {symbol}, error = {mt5.last_error}") mt5.shutdown() exit() rates = mt5.copy_rates_from_pos(symbol, timeframe, 1, 1000) # Get 1000 bars historically df = pd.DataFrame(rates) print(df.head(5)) print(df.shape)
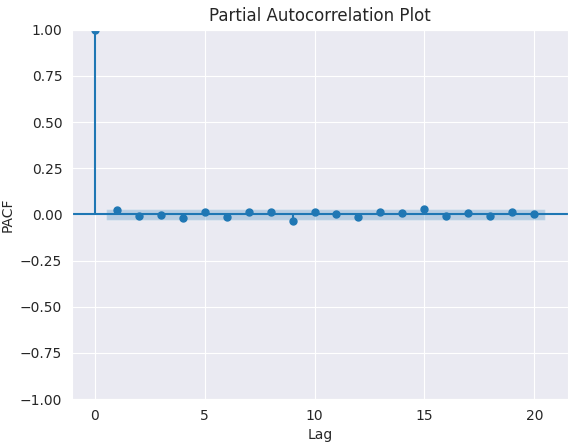
График PACF.
from statsmodels.graphics.tsaplots import plot_pacf import matplotlib.pyplot as plt plt.figure(figsize=(6,4)) plot_pacf(series.diff().dropna(), lags=5) plt.title("Partial Autocorrelation Plot") plt.xlabel('Lag') # X-axis label plt.ylabel('PACF') # Y-axis label plt.savefig("pacf plot.png") plt.show()
Результаты.
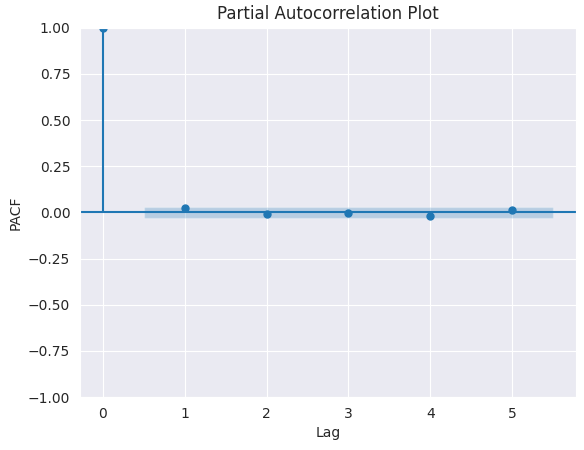
Чтобы определить подходящее значение p, необходимо найти такой лаг, после которого график PACF резко обрывается (значения падают почти до нуля и остаются статистически незначимыми). Этот лаг и будет являться подходящим кандидатом для значения p.
На графике выше правильное значение p = 0 (все лаги после 0 являются незначимыми).
Определение порядка дифференцирования (d) в модели ARIMA
Как мы видели ранее, цель дифференцирования временного ряда — сделать его стационарным, поскольку модель ARIMA предполагает стационарность. Однако важно не допустить недостаточного или чрезмерного дифференцирования ряда.
Правильный порядок дифференцирования — это минимальное количество дифференцирований, необходимое для получения почти стационарного ряда, который колеблется вокруг определенного среднего значения, а график функции автокорреляции (ACF) достаточно быстро стремится к нулю.
Если автокорреляции остаются положительными для большого количества лагов (10 и более), то ряду требуется дополнительное дифференцирование. Если автокорреляция на лаге 1 слишком отрицательная, это, вероятно, означает, что ряд пере-дифференцирован.
Если трудно выбрать между двумя порядками дифференцирования, следует выбрать тот, при котором стандартное отклонение дифференцированного ряда минимально.
Используя цены закрытия EURUSD, определим правильный порядок дифференцирования.
Сначала необходимо проверить, является ли данный ряд стационарным (в нашем случае — цены закрытия), используя тест Дики — Фуллера с расширением (Augmented Dickey-Fuller, ADF) из пакета statsmodels в Python. Проверка стационарности важна, поскольку порядок дифференцирования требуется определять только для нестационарных рядов.
Нулевая гипотеза (Ho) теста ADF заключается в том, что временной ряд не является стационарным. Поэтому, если значение p меньше уровня значимости (< 0,05), мы отклоняем нулевую гипотезу и делаем вывод, что временной ряд стационарен.
Соответственно, в нашем случае, если p > 0,05, мы продолжаем поиск подходящего порядка дифференцирования.
Даже до проведения теста ADF можно заметить, что цены закрытия EURUSD не являются стационарными, просто взглянув на линейный график.
plt.figure(figsize=(7,5)) sns.lineplot(df, x=df.index, y="Close") plt.savefig("close prices.png")
Результаты.
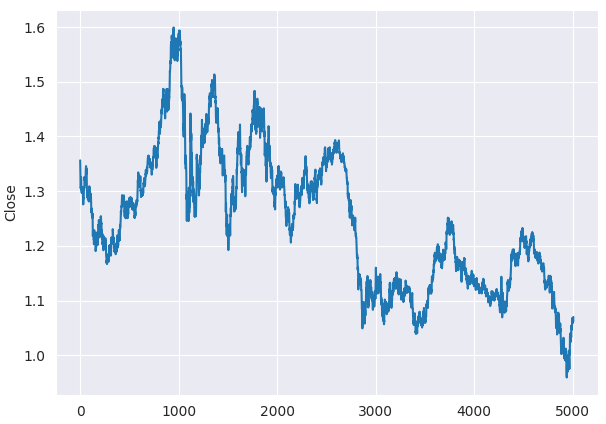
Проверка стационарности.
from statsmodels.tsa.stattools import adfuller series = df["Close"] result = adfuller(series) print(f'p-value: {result[1]}')
Результаты.
p-value: 0.3707268514544181
Как видите, значение p значительно превышает уровень значимости (0,05). Продифференцируем ряд один раз, затем дважды и посмотрим, каким будет график автокорреляции.
# Original Series fig, axes = plt.subplots(3, 2, sharex=True, figsize=(9, 9)) axes[0, 0].plot(series); axes[0, 0].set_title('Original Series') plot_acf(series, ax=axes[0, 1]) # 1st Differencing axes[1, 0].plot(series.diff().dropna()); axes[1, 0].set_title('1st Order Differencing') plot_acf(series.diff().dropna(), ax=axes[1, 1]) # 2nd Differencing axes[2, 0].plot(series.diff().diff()); axes[2, 0].set_title('2nd Order Differencing') plot_acf(series.diff().diff().dropna(), ax=axes[2, 1]) plt.savefig("acf plots.png") plt.show()
Результаты.
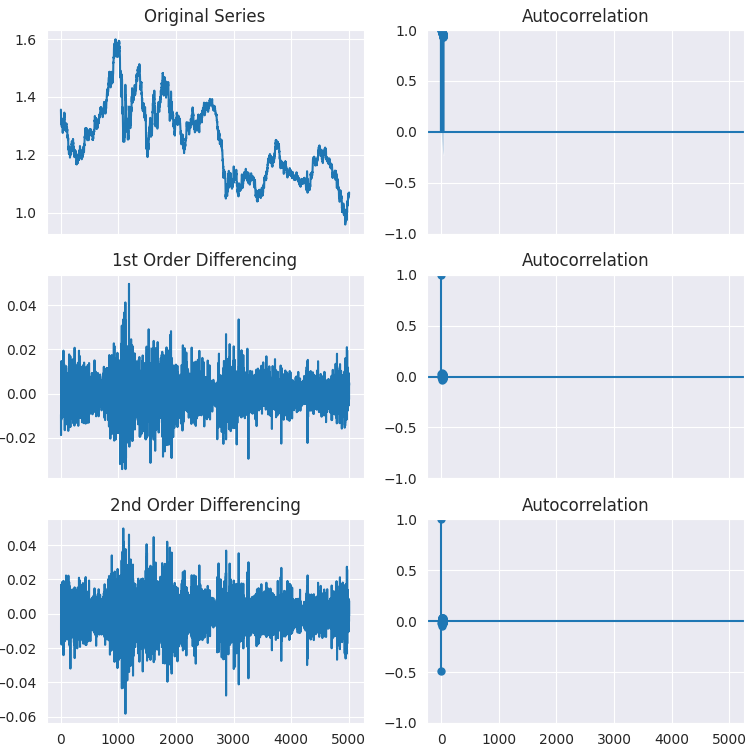
Как видно из графиков, дифференцирование первого порядка справляется со своей задачей, поскольку при дифференцировании второго порядка не наблюдается существенной разницы в результатах стационарности. Это можно еще раз подтвердить с помощью теста ADF.
result = adfuller(series.diff().dropna()) print(f'p-value d=1: {result[1]}') result = adfuller(series.diff().diff().dropna()) print(f'p-value d=2: {result[1]}')
Результаты.
p-value d=1: 0.0 p-value d=2: 0.0
Определение порядка для MA (q)
Аналогично тому, как для определения количества AR-компонентов мы анализировали график PACF, для определения количества MA-компонентов используется график ACF. Напомню, что компонент MA фактически представляет собой ошибки прогнозирования прошлых лагов.
График ACF показывает, сколько MA-компонентов необходимо для устранения автокорреляции в стационаризированном временном ряде.
plt.figure(figsize=(7,5)) plot_pacf(series.diff().dropna(), lags=20) plt.title("Partial Autocorrelation Plot") plt.xlabel('Lag') # X-axis label plt.ylabel('PACF') # Y-axis label plt.savefig("pacf plot finding q.png") plt.show()
Результаты.
Наилучшее значение q = 0.
Методы, описанные выше для определения параметров p, d и q, являются достаточно грубыми и выполняются вручную. Однако этот процесс можно автоматизировать и определить параметры без лишних усилий, используя из библиотеки pmdarima вспомогательную функцию auto_arima.
from pmdarima.arima import auto_arima model = auto_arima(series, seasonal=False, trace=True) print(model.summary())
Результаты.
Performing stepwise search to minimize aic ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=-35532.282, Time=3.21 sec ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=-35537.068, Time=0.49 sec ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=-35537.492, Time=0.59 sec ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=-35537.511, Time=0.74 sec ARIMA(0,1,0)(0,0,0)[0] : AIC=-35538.731, Time=0.25 sec ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=-35535.683, Time=1.22 sec Best model: ARIMA(0,1,0)(0,0,0)[0] Total fit time: 6.521 seconds
Таким образом, мы получили те же самые параметры, что и при ручном анализе.
Построение модели ARIMA для EURUSD
Теперь, когда значения p, d и q определены, у нас есть всt необходимое для обучения модели ARIMA.
from statsmodels.tsa.arima.model import ARIMA arima_model = ARIMA(series, order=(0,1,0)) arima_model = arima_model.fit() print(arima_model.summary())
Результаты.
SARIMAX Results ============================================================================== Dep. Variable: Close No. Observations: 4007 Model: ARIMA(0, 1, 0) Log Likelihood 13987.647 Date: Mon, 26 May 2025 AIC -27973.293 Time: 16:59:38 BIC -27966.998 Sample: 0 HQIC -27971.062 - 4007 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 5.427e-05 7.78e-07 69.768 0.000 5.27e-05 5.58e-05 =================================================================================== Ljung-Box (L1) (Q): 1.47 Jarque-Bera (JB): 1370.86 Prob(Q): 0.22 Prob(JB): 0.00 Heteroskedasticity (H): 0.49 Skew: 0.09 Prob(H) (two-sided): 0.00 Kurtosis: 5.86 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
Далее обучим модель на имеющихся данных и используем ее для прогнозирования вне выборки (out-of-sample), аналогично тому, как это делается в классических моделях машинного обучения.
Начнем с разделения данных на обучающую и тестовую выборки.
series = df["Close"] train_size = int(len(series) * 0.8) train, test = series[:train_size], series[train_size:]
Обучение модели на обучающих данных.
from statsmodels.tsa.arima.model import ARIMA arima_model = ARIMA(train, order=(0,1,0)) arima_model = arima_model.fit() print(arima_model.summary())
Построение прогнозов на основе обучающих данных.
predicted = arima_model.predict(start=1, end=len(train))
Визуализация результата.
plt.figure(figsize=(7,4)) plt.plot(train.index, train, label='Actual') plt.plot(train.index, predicted, label='Forecasted mean', linestyle='--') plt.title('Actual vs Forecast') plt.legend() plt.show()
Результаты.
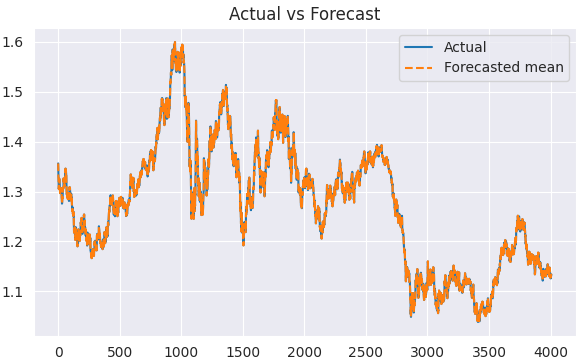
Теперь, когда у нас есть фактические значения и их прогнозы, мы можем оценить модель с помощью какой-нибудь выбранной метрики оценки или функции потерь.
Однако перед этим рассмотрим, как использовать модель ARIMA для прогнозирования вне обучающей выборки (out-of-sample).
Прогнозирование вне выборки с использованием ARIMA
В отличие от классических алгоритмов машинного обучения, традиционные модели прогнозирования временных рядов используют иной подход при работе с данными, которые ранее не встречались модели.
В классических фреймворках машинного обучения и библиотеках Python метод predict, вызываемый с массивом данных, выполняет прогноз — то есть оценивает следующее (будущее) значение. Однако функция predict, реализованная в модуле ARIMA, выполняет несколько иную задачу.
В моделях ARIMA данный метод не обязательно используется для прогнозирования будущего. Он удобен главным образом для получения предсказаний на основе данных внутри выборки (in-sample), то есть данных, которые уже присутствуют в модели — другими словами, обучающих данных.
Чтобы лучше понять это, рассмотрим различие между двумя английскими терминами - prediction и forecasting.
Prediction (предсказание) — это оценка неизвестных значений (как будущих, так и прошлых) с использованием модели. Forecasting (прогнозирование) — это предсказание будущих значений во временном ряде на основе временных закономерностей и зависимостей.
Предсказание (prediction) можно использовать для таких задач, как определение направления рынка или оценка следующей цены закрытия. В то время как прогнозирование (forecast) применяется для определения будущих цен на основе текущих значений временного ряда.
В модели ARIMA метод predict обычно используется для получения прогнозов по тем значениям прошлого, на которых модель уже была обучена. Именно поэтому в нем указываются начальный и конечный индексы. Также можно задать количество шагов в прошлом, для которых требуется выполнить прогноз (например, для оценки модели).
predicted = arima_model.predict(start=1, end=len(train))
print(arima_model.predict(steps=10))
Для прогнозирования будущих значений необходимо использовать метод forecast().
Как мы уже говорили, традиционные модели временных рядов, такие как ARIMA, опираются на предыдущие значения для прогнозирования следующих значений — это видно из ее формулы.
Это означает, что модель необходимо постоянно обновлять новыми данными, чтобы она оставалась актуальной. Например, чтобы модель ARIMA смогла спрогнозировать цену закрытия EURUSD на завтра, ей необходимо передать сегодняшнюю цену закрытия. То же самое относится и к последующим дням.
Этот подход существенно отличается от того, как работают классические модели машинного обучения.
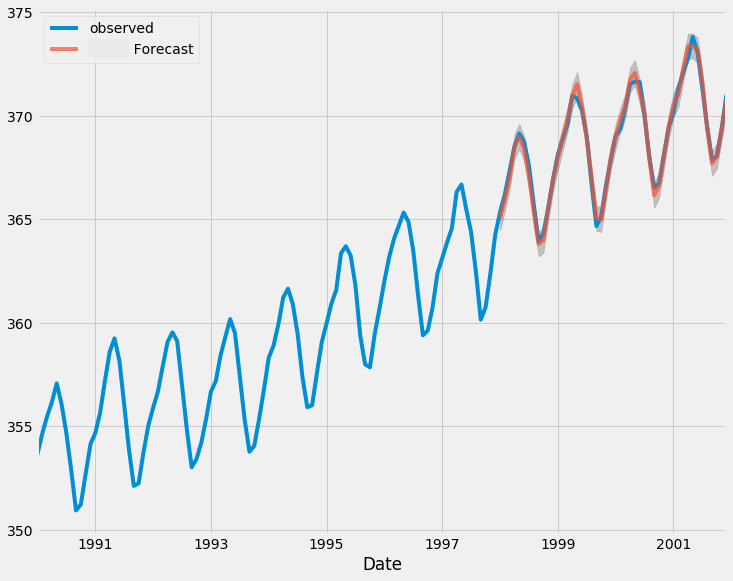
Теперь выполним прогнозирование на данных вне выборки.
# Fit initial model model = ARIMA(train, order=(0, 1, 0)) results = model.fit() # Initialize forecasts forecasts = [results.forecast(steps=1).iloc[0]] # First forecast # Update with test data iteratively for i in range(len(test)): # Append new observation without refitting results = results.append(test.iloc[i:i+1], refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) forecasts = forecasts[:-1] # remove the last element which is the predicted next value # Compare forecasts vs actual test data plt.plot(test.index, test, label="Actual") plt.plot(test.index, forecasts, label="Forecast", linestyle="--") plt.legend()
Метод append добавляет новые (текущие) данные в модель. В данном случае текущая цена закрытия EURUSD используется для прогнозирования следующей цены закрытия.
Если refit=False гарантирует, модель не будет переобучаться заново. Это достаточно эффективный метод обновления модели ARIMA.
Теперь создадим функцию с несколькими метриками оценки, которые можно использовать для анализа работы модели ARIMA.
import sklearn.metrics as metric from statsmodels.tsa.stattools import acf from scipy.stats import pearsonr def forecast_accuracy(forecast, actual): # Convert to numpy arrays if they aren't already forecast = np.asarray(forecast) actual = np.asarray(actual) metrics = { 'mape': metric.mean_absolute_percentage_error(actual, forecast), 'me': np.mean(forecast - actual), # Mean Error 'mae': metric.mean_absolute_error(actual, forecast), 'mpe': np.mean((forecast - actual) / actual), # Mean Percentage Error 'rmse': metric.mean_squared_error(actual, forecast, squared=False), 'corr': pearsonr(forecast, actual)[0], # Pearson correlation 'minmax': 1 - np.mean(np.minimum(forecast, actual) / np.maximum(forecast, actual)), 'acf1': acf(forecast - actual, nlags=1)[1], # ACF of residuals at lag 1 "r2_score": metric.r2_score(forecast, actual) } return metrics
forecast_accuracy(forecasts, test)
Результаты.
{'mape': 0.0034114761554881936,
'me': 6.360279441117738e-05,
'mae': 0.0037872155688622737,
'mpe': 6.825424905960248e-05,
'rmse': 0.005018824533752777,
'corr': 0.99656297100796,
'minmax': 0.0034008221524469695,
'acf1': 0.04637470541528736,
'r2_score': 0.9931220697334551} Значение MAPE = 0.003 показывает, что точность модели составляет примерно 99.996%, и приблизительно такой же результат можно увидеть для метрики r2_score.
Ниже представлен график, сравнивающий фактические и прогнозируемые значения на тестовой выборке.
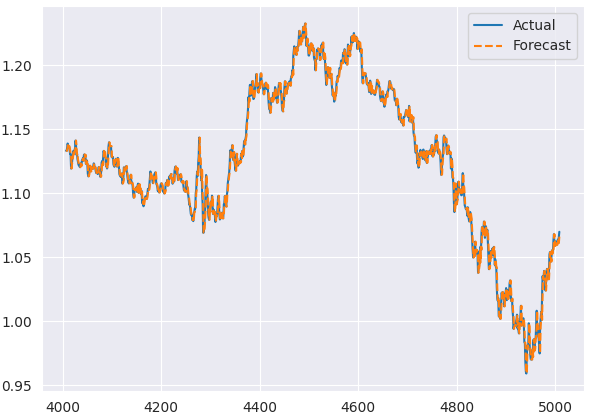
Графики остатков модели ARIMA
В модели ARIMA предусмотрены методы для визуализации остатков. Так мы сможем лучше понять поведение модели.
results.plot_diagnostics(figsize=(8,8)) plt.show()
Результаты.
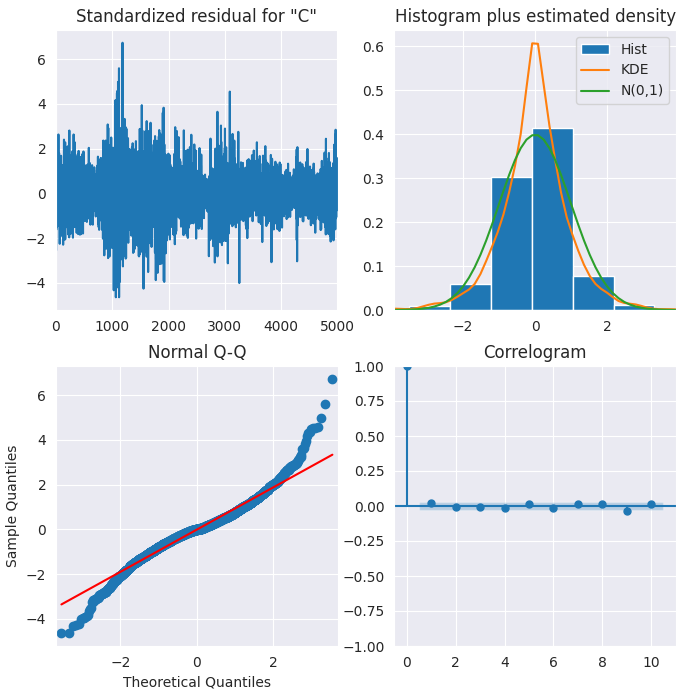
Стандартизированные остатки
Остатки колеблются вокруг среднего значения, равного нулю, и имеют равномерную дисперсию.
Гистограмма
График плотности показывает распределение, близкое к нормальному, со средним значением, слегка смещенным вправо.
Теоретические квантили
Большинство точек располагается практически точно вдоль красной линии. Любые значительные отклонения указывали бы на асимметричность распределения.
Коррелограмма
Коррелограмма (или график ACF) показывает, что остаточные ошибки не являются автокоррелированными. Если бы на графике ACF наблюдалась автокорреляция, это означало бы, что в остатках присутствует определенный паттерн, который не объясняется моделью. В таком случае необходимо добавить дополнительные X-переменные (предикторы) в модель.
В целом модель выглядит достаточно хорошо обученной на данных.
Модель SARIMA
У базовой модели ARIMA есть один недостаток. Она не поддерживает сезонность.
Сезонность — это повторяющиеся закономерности в финансовых данных, возникающие через фиксированные интервалы времени, например: час, день, неделя, месяц, квартал и год.
Часто можно наблюдать, что финансовые инструменты демонстрируют повторяющиеся модели поведения. Например, акции розничных компаний часто растут в четвертом квартале (сезон праздничных покупок), акции энергетических компаний могут следовать сезонным погодным циклам, на рынке Forex часто наблюдается повышенная волатильность во время определенных торговых сессий и т.д.
Если временной ряд содержит наблюдаемую или четко выраженную сезонность, следует использовать Seasonal ARIMA (SARIMA), поскольку эта модель использует сезонное дифференцирование.
Компоненты модели SARIMAX(p, d, q)x(P, D, Q, S)
- Авторегрессия (АР)
Как уже было сказано, авторегрессия использует прошлые значения временного ряда для прогнозирования текущих значений. - Скользящая средняя (MA)
Компонент скользящей средней моделирует прошлые ошибки прогнозирования. - Интегрированная часть I
Интегрирование используется для приведения временного ряда к стационарному виду. - Сезонная составляющая (S)
Сезонный компонент отражает изменения, повторяющиеся через регулярные интервалы времени.
Сезонное дифференцирование похоже на обычное дифференцирование. Разница заключается в том, что вместо вычитания соседних значений мы вычитаем значение из предыдущего сезона.
Перед использованием модели SARIMAX необходимо определить подходящие параметры с помощью функции auto_arima.
from pmdarima.arima import auto_arima # Auto-fit SARIMA (automatically detects P, D, Q, S) auto_model = auto_arima( series, seasonal=True, # Enable seasonality m=5, # Weeky cycle (5 days) for daily data trace=True, # Show search progress stepwise=True, # Faster optimization suppress_warnings=True, error_action="ignore" ) print(auto_model.summary())
Результаты.
Performing stepwise search to minimize aic ARIMA(2,1,2)(1,0,1)[5] intercept : AIC=-35529.092, Time=3.81 sec ARIMA(0,1,0)(0,0,0)[5] intercept : AIC=-35537.068, Time=0.29 sec ARIMA(1,1,0)(1,0,0)[5] intercept : AIC=-35536.573, Time=0.97 sec ARIMA(0,1,1)(0,0,1)[5] intercept : AIC=-35536.570, Time=4.38 sec ARIMA(0,1,0)(0,0,0)[5] : AIC=-35538.731, Time=0.21 sec ARIMA(0,1,0)(1,0,0)[5] intercept : AIC=-35536.048, Time=0.67 sec ARIMA(0,1,0)(0,0,1)[5] intercept : AIC=-35536.024, Time=0.87 sec ARIMA(0,1,0)(1,0,1)[5] intercept : AIC=-35534.248, Time=0.92 sec ARIMA(1,1,0)(0,0,0)[5] intercept : AIC=-35537.492, Time=0.37 sec ARIMA(0,1,1)(0,0,0)[5] intercept : AIC=-35537.511, Time=0.55 sec ARIMA(1,1,1)(0,0,0)[5] intercept : AIC=-35535.683, Time=0.57 sec Best model: ARIMA(0,1,0)(0,0,0)[5] Total fit time: 13.656 seconds SARIMAX Results ============================================================================== Dep. Variable: y No. Observations: 5009 Model: SARIMAX(0, 1, 0) Log Likelihood 17770.365 Date: Tue, 27 May 2025 AIC -35538.731 Time: 11:16:40 BIC -35532.212 Sample: 0 HQIC -35536.446 - 5009 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 4.846e-05 6.06e-07 80.005 0.000 4.73e-05 4.96e-05 =================================================================================== Ljung-Box (L1) (Q): 2.42 Jarque-Bera (JB): 2028.68 Prob(Q): 0.12 Prob(JB): 0.00 Heteroskedasticity (H): 0.34 Skew: 0.08 Prob(H) (two-sided): 0.00 Kurtosis: 6.11 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
Хотя auto_arima возвращает уже готовую модель SARIMAX, и повторная подгонка модели вручную не является обязательной, ручная настройка SARIMAX дает больше контроля над результатами, поэтому выполним ее еще раз.
from statsmodels.tsa.statespace.sarimax import SARIMAX model = SARIMAX( train, order=auto_model.order, # Non-seasonal (p,d,q) seasonal_order=auto_model.order+(5,), # Seasonal (P,D,Q,S) enforce_stationarity=False ) results = model.fit() print(results.summary())
Результаты.
SARIMAX Results ========================================================================================= Dep. Variable: Close No. Observations: 4007 Model: SARIMAX(0, 1, 0)x(0, 1, 0, 5) Log Likelihood 12613.829 Date: Tue, 27 May 2025 AIC -25225.658 Time: 11:16:41 BIC -25219.364 Sample: 0 HQIC -25223.427 - 4007 Covariance Type: opg ============================================================================== coef std err z P>|z| [0.025 0.975] ------------------------------------------------------------------------------ sigma2 0.0001 1.68e-06 63.423 0.000 0.000 0.000 =================================================================================== Ljung-Box (L1) (Q): 3.42 Jarque-Bera (JB): 676.61 Prob(Q): 0.06 Prob(JB): 0.00 Heteroskedasticity (H): 0.48 Skew: -0.01 Prob(H) (two-sided): 0.00 Kurtosis: 5.01 =================================================================================== Warnings: [1] Covariance matrix calculated using the outer product of gradients (complex-step).
Поскольку порядок, возвращаемый auto_model, относится к ARIMA(p, d, q) (даже при включенной сезонности), при объявлении модели SARIMAX необходимо добавить значение 5 в кортеж параметров, чтобы модель стала (p,d,q,s).
Перед визуализацией и анализом фактических и прогнозируемых значений необходимо удалить первые элементы массива, равные размеру сезонного окна. Значения до этого момента являются неполными.
predicted = results.predict(start=1, end=len(train)) clean_train = train[5:] clean_predicted = predicted[5:] plt.figure(figsize=(7,4)) plt.plot(clean_train.index[5:], clean_train[5:], label='Actual') plt.plot(clean_train.index[5:], clean_predicted[5:], label='Forecasted mean', linestyle='--') plt.title('Actual vs Forecast') plt.legend() plt.savefig("sarimax train actual&forecast plot.png") plt.show()
Результаты.
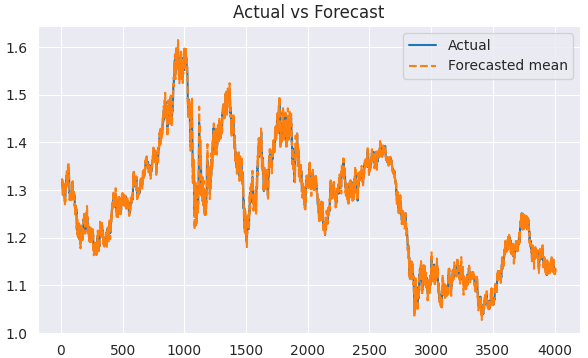
Мы можем оценить эту модель так же, как оценивали ARIMA.
# Initialize forecasts forecasts = [results.forecast(steps=1).iloc[0]] # First forecast # Update with test data iteratively for i in range(len(test)): # Append new observation without refitting results = results.append(test.iloc[i:i+1], refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) clean_test = test[5:] forecasts = forecasts[5:-1] # remove the last element which is the predicted next value and the first 5 items
forecast_accuracy(forecasts, clean_test)
Результаты.
{'mape': 0.004900183060803821,
'me': -6.94082142749275e-06,
'mae': 0.005432456867698095,
'mpe': -7.226495372320155e-06,
'rmse': 0.007127465498996785,
'corr': 0.9931778828074744,
'minmax': 0.004880027322298863,
'acf1': 0.10724254539104018,
'r2_score': 0.9864021833085908} Согласно метрике r2_score, точность модели составляет 98.6%, что является хорошим результатом.
В завершение можно использовать модель ARIMA для выполнения прогнозов в реальном времени, используя данные, полученные из MetaTrader 5.
Сначала необходимо импортировать библиотеку schedule, которая позволит запускать прогнозирование раз в день, поскольку модель была обучена на дневном таймфрейме.
import schedule # Make realtime predictions based on the recent data from MetaTrader5 def predict_close(): rates = mt5.copy_rates_from_pos(symbol, timeframe, 0, 1) if not rates: print(f"Failed to get recent OHLC values, error = {mt5.last_error}") time.sleep(60) rates_df = pd.DataFrame(rates) global results # Get the variable globally, outside the function global forecasts # Append new observation to the model without refitting new_obs_value = rates_df["close"].iloc[-1] new_obs_index = results.data.endog.shape[0] # continue integer index new_obs = pd.Series([new_obs_value], index=[new_obs_index]) # Its very important to continue making predictions where we ended on the training data results = results.append(new_obs, refit=False) # Forecast next step forecasts.append(results.forecast(steps=1).iloc[0]) print(f"Current Close Price: {new_obs_value} Forecasted next day Close Price: {forecasts[-1]}")
Расписание прогнозов.
schedule.every(1).days.do(predict_close) # call the predict function after a given time while True: schedule.run_pending() time.sleep(60) mt5.shutdown()
Результаты.
Current Close Price: 1.1374900000000001 Forecasted next day Close Price: 1.1337899981049262 Current Close Price: 1.1372200000000001 Forecasted next day Close Price: 1.1447100065656721
Используя прогнозируемые цены закрытия, можно расширить систему до полноценной торговой стратегии и выполнять торговые операции через MetaTrader5-Python.
Заключительные мысли
И ARIMA, и SARIMA являются достаточно эффективными традиционными моделями временных рядов, которые используются во многих областях и индустриях. Однако важно понимать их ограничения и недостатки.
- Модели предполагают, что данные являются стационарными (после дифференцирования).
Однако на практике мы не всегда работаем со стационарными данными и часто хотим использовать их в исходном виде. Дифференцирование может исказить естественную структуру и тренды, которые мы пытаемся анализировать. - Предположение линейности
ARIMA по сути является линейной моделью. Она предполагает, что будущие значения линейно зависят от прошлых лагов и ошибок. Это предположение часто не выполняется на финансовых и валютных рынках, где поведение данных может быть значительно более сложным и нелинейным. - Одномерность моделей
Обе модели используют только один признак. Однако финансовые рынки крайне сложны, и для их анализа обычно требуется учитывать множество факторов. Эти модели рассматривают рынок лишь с одной точки зрения, что может приводить к упущению важных сигналов.
Хотя в модель SARIMAX можно добавлять экзогенные переменные, этого зачастую оказывается недостаточно.
Несмотря на эти ограничения, при правильном выборе параметров, типа задачи и используемых данных простая модель ARIMA может превосходить более сложные модели, такие как RNN, при прогнозировании временных рядов.
Всем удачи!
Источники и ссылки
- https://www.geeksforgeeks.org/python-arima-model-for-time-series-forecasting/
- https://www.machinelearningplus.com/time-series/arima-model-time-series-forecasting-python/
- https://datascientest.com/en/sarimax-model-what-is-it-how-can-it-be-applied-to-time-series
- https://www.kaggle.com/code/prashant111/arima-model-for-time-series-forecasting
Таблица вложений
| Имя файла | Описание и назначение |
|---|---|
| forex_ts_forecasting_using_arima.py | Python-скрипт, содержащий все представленные здесь примеры на языке Python. |
| requirements.txt | Текстовый файл, содержащий зависимости Python и номера их версий. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18247
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Потрясающее содержание.
Именно то, что я искал.
Наверное, не буду использовать это в торговле, но очень интересно.
Впервые услышал об ARIMA в книге Перри Дж Кауфмана "Торговые системы и методы".
У кого-нибудь был успех в торговле с ARIMA?