
博弈论方法在交易算法中的应用

在决策速度至关重要且市场充满高度不确定性的情况下,需要采用不同的方法来创建交易系统。
AdaptiveQ Enhanced 是一款基于深度强化学习(DQN)方法、博弈论和因果分析开发的交易 EA。EA 通过模拟 531,441 种独特状态来分析市场,同时考虑了七大主要货币对之间的相互关系。该算法的关键要素是纳什均衡,用于在交易品种相互影响的条件下选择最优策略。
该系统的新版本实现了一系列扩展操作:除了标准的购买和销售操作外,还增加了逐步建仓和选择性平掉盈利仓位的功能。这使系统在不同市场情景下具备更强的适应能力和操作灵活性。本文探讨了这些方法在 MQL5 中的实际实现,并展示了自适应学习、博弈论和人工智能的结合如何助您构建更准确、更可持续的交易策略。
理论基础:从强化学习到纳什均衡
深度强化学习(DQN)
在深入探讨代码的技术细节之前,让我们先打下理论基础。我们的系统基于深度 Q 学习(深度 Q 网络 (DQN)),它是强化学习算法的现代版本,已被证明不仅在游戏中有效,而且在解决复杂的金融问题方面也有效。
在经典强化学习中,智能体(在我们的案例中是一个交易系统)通过执行特定动作(开仓/平仓)与环境(市场)进行交互。对于每个动作,智能体都会获得一个奖励,并转移到新的状态。智能体的目标是在一段时间内最大化累积奖励。
从数学上讲,这可以用 Q 函数来表示,该函数评估在 s 状态下执行 a 动作的预期效用:
Q(s, a) = r + γ max Q(s', a')
其中 r 是即时奖励,γ 是贴现因子(我们对未来奖励的重视程度),s' 是新状态,a' 是新状态下的可能行动。
博弈论与纳什均衡
传统交易系统孤立地考虑每个交易品种。我们的方法截然不同:我们运用博弈论来解释货币对之间的相互关系。
纳什均衡是指这样一种状态:任何玩家都无法通过单方面改变策略来提高自己的得分。在我们的系统背景下,这意味着我们会为每个货币对找到最优策略,同时考虑其他货币对的策略。
在代码中,这是通过 DetermineActionNash() 函数实现的,该函数现在可以处理扩展后的六个可能的动作。每项操作不仅基于特定货币对的数据进行评估,还会考虑与其他交易品种的相关性:
void DetermineActionNash(int symbolIdx) { double actionScores[TOTAL_ACTIONS]; // Get basic estimates of actions from Q-matrix for(int action = 0; action < TOTAL_ACTIONS; action++) { actionScores[action] = qMatrix[tradeStates[symbolIdx].currentStateIdx][action][symbolIdx]; } // Correction based on correlation with other symbols (Nash) for(int otherIdx = 0; otherIdx < TOTAL_SYMBOLS; otherIdx++) { if(otherIdx != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherIdx]; for(int action = 0; action < TOTAL_ACTIONS; action++) { double otherScore = qMatrix[tradeStates[otherIdx].currentStateIdx][action][otherIdx]; // Take correlation into account only if there is significant relationship if(MathAbs(corr) > 0.3) { actionScores[action] += corr * otherScore * 0.05; } } } }
注意微调 — 只有当相关性的绝对值超过 0.3 时,才会将其纳入考虑。这使您能够过滤掉“杂音”,专注于货币对之间真正重要的关系。
多维行动空间中的因果推理
在更新后的 AdaptiveQ Enhanced 版本中,我们的系统获得了更多可执行的操作:
- 建一个买入仓位
- 建一个卖出仓位
- 增加现有买入仓位的交易量
- 增加现有卖出仓位的交易量
- 只平掉盈利的买入仓位
- 只平掉盈利的卖出仓位
这极大地丰富了系统的战略潜力。现在,它不仅能够开仓和平仓,还能在趋势朝着正确方向发展时增加交易量,并有选择性地锁定利润,在预期市场反转时让亏损仓位保持敞口。
只平掉盈利的仓位尤其有趣。它使系统能够在锁定利润的同时,避免过早兑现亏损头寸,从而显著改善整体收益表现:
void ClosePositionsByTypeIfProfitable(string symbol, ENUM_POSITION_TYPE posType) { CTrade trade; CPositionInfo pos; for(int i = PositionsTotal() - 1; i >= 0; i--) { if(pos.SelectByIndex(i)) { if(pos.Symbol() == symbol && pos.PositionType() == posType) { double profit = pos.Profit(); // Close only if position is in profit if(profit > 0) { trade.PositionClose(pos.Ticket()); } } } } }
技术实现:AdaptiveQ Enhanced 解析
庞大的状态空间和多层次分析
我们系统的一个关键特点是其庞大的状态空间(531,441 个独特的状态)。这提供了对市场状况的详细分析,并使系统能够适应各种场景。
在更新版本中,每个状态都变得更具信息量。现在,系统不仅在当前时间周期内分析市场,还会同时分析三个不同时间周期内的市场情况:M15、H1 和 H4。这种多时间框架方法使 AdaptiveQ Enhanced 能够全面了解市场动态 — 从短期波动到中期趋势。
在每个时间周期中,系统都会跟踪一系列参数:
- 价格与20个移动平均线(从10日均线到200日均线)之间的差异
- 价格相对于关键移动平均线水平的二进制标志
- RSI 和随机震荡技术指标的值
- 价格变动的动量
所有这些数据都被转换成一个唯一的状态索引,然后使用该索引来访问 Q 矩阵:
int ConvertToStateIndex(MarketState &state) { double range = state.price_high - state.price_low; if(range == 0) range = 0.0001; // Basic components from prices int o_idx = (int)((state.price_open - state.price_low) / range * 9); int c_idx = (int)((state.price_close - state.price_low) / range * 9); int m_idx = (int)((state.momentum + 0.001) / 0.002 * 9); // Basic index from main components int stateIdx = o_idx * 81 + c_idx * 9 + m_idx; // Add components from difference with MA for current timeframe int ma_idx = 0; for(int i = 0; i < 10; i++) { int diff_idx = (int)((state.ma_diff[i] + 0.01) / 0.02 * 9); diff_idx = MathMin(MathMax(diff_idx, 0), 8); ma_idx += diff_idx * (int)MathPow(9, i % 3); } // Add components from indicators for each timeframe ulong tf_state = 0; for(int tfIdx = 0; tfIdx < TOTAL_TIMEFRAMES; tfIdx++) { // RSI: 0-100 -> 0-9 int rsi_idx = (int)(state.tf_rsi[tfIdx] / 10); rsi_idx = MathMin(MathMax(rsi_idx, 0), 9); tf_state = tf_state * 10 + rsi_idx; // Stochastic %K: 0-100 -> 0-9 int stoch_k_idx = (int)(state.tf_stoch_k[tfIdx] / 10); stoch_k_idx = MathMin(MathMax(stoch_k_idx, 0), 9); tf_state = tf_state * 10 + stoch_k_idx; // Binary flags for MA: selecting key MAs (10, 50, 100, 200) int ma_flags = 0; ma_flags |= state.tf_ma_above[tfIdx][0] << 0; // MA10 ma_flags |= state.tf_ma_above[tfIdx][4] << 1; // MA50 ma_flags |= state.tf_ma_above[tfIdx][9] << 2; // MA100 ma_flags |= state.tf_ma_above[tfIdx][19] << 3; // MA200 tf_state = tf_state * 16 + ma_flags; } // Hash base index and indicators together ulong hash = stateIdx + ma_idx + (ulong)tf_state; // Reduce to range TOTAL_STATES through hash return (int)(hash % TOTAL_STATES); }
仔细看看这个功能。这里的关键在于:多维市场参数空间被映射为唯一的状态标识符。这就好像我们创建了一个多维市场地图,其中每个点都对应着价格和指标的特定组合,然后使用哈希函数将其压缩成一个一维索引。
缓存和性能优化
考虑到系统的计算复杂性,我们特别关注了优化问题。新版本中不仅增加了对价格和相关性的缓存,还增加了对所有所用指标值的缓存:
// Cache for prices and correlations (performance optimization) double bidCache[TOTAL_SYMBOLS], askCache[TOTAL_SYMBOLS]; double correlationMatrix[TOTAL_SYMBOLS][TOTAL_SYMBOLS]; double pointCache[TOTAL_SYMBOLS]; // Cache for Point // Cache for indicators double maCache[TOTAL_SYMBOLS][10]; double maTFCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; int maAboveCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES][20]; double rsiCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochKCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; double stochDCache[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];此外,系统现在会在调用之间保存指标句柄,从而避免重复创建它们:
// Indicator handles to avoid multiple creation int rsiHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES]; int stochHandles[TOTAL_SYMBOLS][TOTAL_TIMEFRAMES];为了节省计算资源,增加了一种定期更新指标的机制:
// Time of last update of indicators datetime lastMAUpdate = 0; datetime lastIndicatorsUpdate = 0; int indicatorUpdateInterval = 60; // Update indicators every minute void UpdateIndicatorsCache() { datetime currentTime = TimeCurrent(); if(currentTime - lastIndicatorsUpdate < indicatorUpdateInterval) return; // ... indicator update code ... lastIndicatorsUpdate = currentTime; }
这项技术或许看似微不足道,但实际上它能显著提升性能,这对于一个同时处理三种时间周期下七种货币对的系统来说至关重要。
具有机会成本机制的自适应学习
我们系统的核心是自适应学习引擎,如今它已变得更加先进。与经典 Q 学习不同,AdaptiveQ Enhanced 采用了“机会成本”的概念,使系统能够从错误中更快地学习。
当系统做出决策时,它不仅会评估所选动作的实际奖励,还会对其他替代动作的潜在结果进行建模。如果事实证明另一项行动能带来更多利润,系统会更大胆地调整其策略:// Check whether an action resulted in a loss and whether it was possible to make a reward with an alternative action bool wasLoss = reward < 0; bool couldProfit = tradeStates[symbolIdx].alternativeReward > 0 && tradeStates[symbolIdx].opportunityCost < 0; // Apply adaptive learning rate for cases of opportunity cost if(wasLoss && couldProfit) { // Increase learning rate to quickly adapt to incorrect decisions double adaptiveLearningRate = MathMin(learningRate * adaptiveMultiplier, 0.9); // Additionally, reduce the Q-value in proportion to the opportunity cost newQ -= adaptiveLearningRate * MathAbs(tradeStates[symbolIdx].opportunityCost) * opportunityCostWeight; }
这与经验丰富的交易者的做法相似,他们不仅从错误中吸取教训,还会分析错失的机会,并在发现另一种解决方案明显更优时,更积极地调整自己的策略。借助 adaptiveMultiplier 参数,用户可以配置系统从错失的机会中学习的强度。
学习的另一个创新方面是货币对之间的因果效应:
// Update Q-values for other symbols based on correlation (causal learning) for(int otherSymbol = 0; otherSymbol < TOTAL_SYMBOLS; otherSymbol++) { if(otherSymbol != symbolIdx) { double corr = correlationMatrix[symbolIdx][otherSymbol]; // Apply update only if correlation is significant if(MathAbs(corr) > 0.2) { qMatrix[tradeStates[symbolIdx].previousStateIdx][tradeStates[symbolIdx].previousAction][otherSymbol] += learningRate * reward * corr * 0.1; } } }
当系统在一种货币对上积累经验后,它可以将这些经验迁移到其他相关交易品种上,但需视它们之间的相关程度而定。这会产生一种“交叉学习”效应,显著加快系统适应市场条件的过程。
AdaptiveQ Enhanced 的实际应用
高级定制和风险管理功能
AdaptiveQ Enhanced 提供了一系列令人印象深刻的参数,可根据交易者的个人偏好对系统进行微调:
input OPERATION_MODE OperationMode = MODE_LEARN_AND_TRADE; // System operating mode input CLOSE_STRATEGY CloseStrategy = STRATEGY_CLOSE_ALL; // Close strategy input POSITION_MODE PositionMode = MODE_MULTI; // Position mode input double TradeVolume = 0.01; // Base volume of trade input double AddVolumePercent = 50.0; // Percentage of base volume to add to position input int TakeProfit = 2500; // Take Profit (points) input int StopLoss = 1500; // Stop Loss (points) input double LearningRate = 0.1; // Learning rate input double DiscountFactor = 0.9; // Discount factor input double AdaptiveMultiplier = 1.5; // Adaptive learning rate multiplier input double OpportunityCostWeight = 0.2; // Opportunity cost weight input int MaxPositionsPerSymbol = 5; // Maximum number of positions per symbol
该系统可在三种仓位模式下运行:MODE_SINGLE 允许您为每个交易品种只有一个仓位,MODE_MULTI 允许您打开 MaxPositionsPerSymbol 个单向仓位,MODE_OPPOSITE 允许您同时拥有相反方向的仓位。
AddVolumePercent 参数值得特别关注。它决定在执行 ACTION_ADD_BUY 和 ACTION_ADD_SELL 操作时,现有仓位将增加多少交易量。这使得在系统朝着成功趋势的方向增加交易量时,能够实施建仓策略。
智能仓位管理
AdaptiveQ Enhanced 中最有趣的创新之一是能够选择性地仅平掉盈利头寸。这样一来,系统既可以锁定利润,又能让亏损的仓位有机会恢复:
case ACTION_CLOSE_PROFITABLE_BUYS: if(tradeStates[symbolIdx].buyPositions > 0) { // Close only profitable BUY positions ClosePositionsByTypeIfProfitable(symbol, POSITION_TYPE_BUY); tradeStates[symbolIdx].actionSuccessful = true; } break;
结合开立多个仓位的特性,这会产生有趣的动态效应:随着趋势的发展,系统可以逐步建立仓位,然后在出现反转的初步迹象时部分锁定利润,为行情的潜在延续保留一些仓位。
定期保存和加载已训练的模型
我们系统的亮点仍然是保存和加载已训练的 Q 矩阵的功能。在新版本中,得益于定期自动保存功能,这一机制变得更加可靠:
void CheckAndSaveQMatrix() { if(IsNewBar() && OperationMode == MODE_LEARN_AND_TRADE) { Print("Periodic saving of Q-matrix..."); SaveQMatrix(); } }
系统会检查是否有新柱出现,并定期保存累积的知识。这可以防止在意外关机时丢失训练数据。
整个系统的运作方式如下:
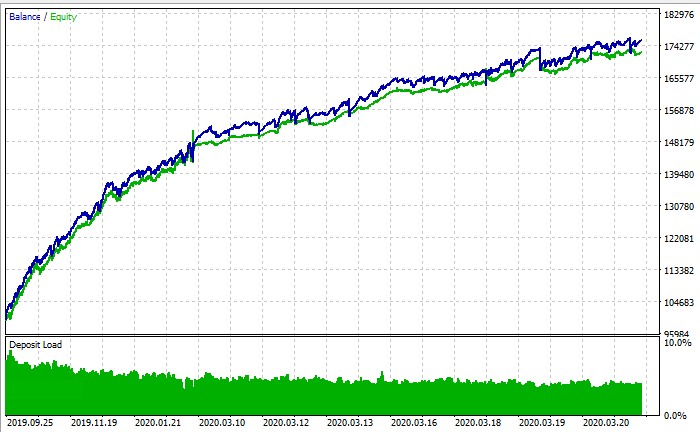
结论:算法交易的新视野
AdaptiveQ Enhanced 交易 EA 不仅仅是另一种算法交易工具,而是一种从根本上分析和预测金融市场的新方法。通过将深度强化学习、博弈论和因果推理与更丰富的交易操作手段和多时间框架分析相结合,我们构建了一个能够捕捉不同货币对之间复杂关系并做出最优交易决策的系统。
适应性学习率机制(受机会成本约束)被证明特别有效。当系统做出错误决策,而采取另一种行动本可带来利润时,它会根据自适应乘数(默认为1.5倍)提高学习率。这是一种“高强度学习” — 系统从错误中学习的速度比从成功中学习的速度更快,这也符合人类的心理特征。
算法交易的未来恰恰在于能够随着市场变化而学习和进化的自适应系统领域。AdaptiveQ Enhanced 不仅仅是一个实验,而是一个实用的工具,它为研发开辟了新的视野。本文提供的代码可供实验和进一步改进。我邀请 MQL5 社区参与这一概念的开发,并基于人工智能和博弈论创造出更先进的交易系统。
金融世界正变得日益复杂且相互关联。只有能够感知这种复杂性并适应其变化的系统,才能在未来的市场中成功竞争。AdaptiveQ Enhanced 是朝着这个方向迈出的一步,是迈向更智能、更具适应性、最终更盈利的算法交易的一步。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/17546
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

您好,我对您的项目非常感兴趣,但我是这方面的新手。我不知道如何在策略测试器中 运行智能交易系统。据我所知,不可能通过测试器进行完全配置和训练?还是我做错了什么?请提供操作系统
我在荷兰哪里有亲戚?
我怎么会有亲戚在荷兰?
啊哈哈哈哈,不在荷兰))))VPN 是这样的东西)))))
PS:策略测试器的底线到底能不能运行训练?根据平衡图表截图,它是一个策略测试器,但无论我做什么,我都无法在其中接近 +。
作者介绍了 "AdaptiveQ Enhanced",这是一款多符号外汇 EA,声称结合了 DQN、纳什均衡、因果分析、七种主要货币对、六种操作和531,441 种 状态。操作集包括买入、卖出、买入加仓、卖出加仓以及仅关闭盈利的买入或卖出。
我的主要问题是:这篇文章使用花哨的标签多于实际内容。文章中的 "纳什均衡 "并不是一个实际的均衡解;它只是在 |corr| > 0.3 时,将一个符号的 Q 值与其他符号的 Q 值按滚动相关性加权相加。这不是任何严肃意义上的博弈论。因果 "语言也存在同样的问题:当 |corr| > 0.2 时,跨符号更新实际上是基于奖励乘以相关性。相关性不是因果性。
状态设计看起来也很不稳定。文章称,它从价格、MA 差值、RSI、随机指标和 MA 标志中构建了丰富的多时间框架状态,然后对多维信息进行散列,并用散列 % TOTAL_STATES 对其进行还原。因此,不同的市场情况可以归结为同一个桶。称其为 "531,441 种独特状态 "听起来比实际情况更令人印象深刻。
仓位逻辑是最丑陋的部分。EA 可以在多仓位或相反仓位模式下运行,为现有仓位增加交易量,每个符号 最多允许5 个仓位,并且只选择性地关闭盈利仓位,而让亏损仓位 "恢复"。在我看来,这不是明智的库存管理;这是一条通往丑陋暴露的装扮之路。
优点:工程方面比一般的 MQL5 更认真。缓存指标句柄、定期更新和保存/加载 Q 矩阵都是实用的实施细节。
因此,在我看来,这是一次有趣的尝试,但交易设计较弱。围绕 "人工智能/游戏理论/因果推理 "的品牌宣传太多,却没有足够的证据证明它具有真正的优势。我不会直接建立在这一逻辑之上。