
基于购买力平价(PPP)和 IMF 数据确定公允汇率

有一天我突然意识到,我花在寻找‘完美’预测模块上的时间,比花在理解真正驱动汇率的因素上的时间还要多。于是我问了自己一个简单的问题:如果把所有图表都放到一边,试着去寻找一种货币的真实价值,会怎样?不是市场在情绪和投机影响下随时呈现的那个价格,而是由基本经济规律所决定的那个内在价值?
这个问题让我投入了数月的工作。我从研究购买力平价理论开始,最终用 Python 写出了一套完整的汇率分析系统。事实证明,这比任何技术指标都有意思得多。
问题的提出
外汇市场分析往往聚焦于寻找技术指标和图表形态,却忽视了基本面经济因素。这就引出了一个合乎逻辑的问题:我们能否基于经济规律,而非短期市场情绪和投机波动,来确定货币的公允价值?
本研究提出了一种解决该问题的实用方法 —— 基于购买力平价理论,使用 Python 编程语言构建一套完整的公允汇率计算系统。
购买力平价的理论基础
以麦当劳巨无霸这个经典例子就能说明该理论的核心:如果一个汉堡在美国卖 5 美元,在欧洲卖 9 欧元,那么公允汇率应为 1 欧元兑 1.8 美元(即 EUR/USD = 1.8)。在这个简单例证的背后,是一种分析外汇市场的基础工具 —— 它能帮助我们识别长期失衡,而不受短期市场波动的干扰。
这一概念的历史渊源可以追溯到 16 世纪,当时西班牙商人就注意到了本土与殖民地之间的价格差异。如果 1 比索在塞维利亚能买一个面包,在墨西哥却能买三条,这就表明两种货币的相对价值存在根本性错配,需要通过汇率调整或价格趋同来修正。
购买力平价的表述形式
绝对购买力平价理论认为,汇率与两国同种商品的价格比率之间存在直接关系。尽管理论上很精妙,但在实际应用中,这种方法会受到多种扭曲因素的影响:税收差异、监管壁垒、运输成本以及贸易限制。
S₁₂ = P₁ / P₂
其中 S₁₂ 为货币 1 对货币 2 的汇率,P₁ 和 P₂ 分别为两国的价格水平。
相对购买力平价关注的是价格变化的动态过程,而非绝对水平。根据这一表述,如果 A 国的年通胀率为 10%,B 国为 5%,那么 A 国货币相对于 B 国货币应贬值 5%,才能维持购买力平价。
S₁₂(t) / S₁₂(0) = [P₁(t) / P₁(0)] / [P₂(t) / P₂(0)]
或者简化形式为:
ΔS₁₂ = π₁ - π₂
其中 π₁、π₂ 分别为第 1 国和第 2 国的通胀率。
本算法选择相对购买力平价作为方法论基础,原因在于其实际适用性更强、更能反映经济现实,并且能够获得具体的汇率量化基准。
可用数据源评估
对现有购买力平价数据提供商的研究表明,它们在实际应用中存在显著局限性。经合组织(OECD)发布的官方购买力平价比率存在 6 个月至 1 年的滞后。2023 年的数据要到 2024 年年中才会公布,这对于动态变化的外汇市场来说是不可接受的。
| 数据源 | 更新频率 | 滞后时间 | 年费 | 方法透明度 | 实用性 |
|---|---|---|---|---|---|
| OECD | 年度 | 6-12 个月 | 0 美元 | 低 | 研究 |
| 佩恩世界表(Penn World Table) | 2-3 年 | 1-2 年 | 0 美元 | 中等 | 学术 |
| 彭博终端(Bloomberg Terminal) | 实时 | — | 24,000 美元 | — | 专业 |
| 路孚特 Eikon | 实时 | — | 22,000 美元 | — | 专业 |
佩恩世界表每隔数年才更新一次,最新可用版本仅包含截至 2019 年的数据。虽然这样的数据库对学术研究很有价值,但对于实际交易而言,如此长的时间滞后是致命的。
彭博和路孚特等商业数据提供商提供的信息更为及时,但彭博终端的访问费用起价为每月 2,000 美元,且无法保证方法透明度或数据质量。
方法不透明问题:现有解决方案的一个关键缺陷是计算过程不清晰。OECD 系数的计算方法、消费者篮子的构成、统计异常值的处理算法以及商品质量差异的调整方式,均无公开文档。
大型数据提供商以封闭系统的方式运作:用户只能得到数值结果,却不了解其来源,也无法进行验证。对于需要完全掌控计算过程的严谨金融分析而言,这种方式是不可接受的。
开发自定义系统:作者决定创建一套独立的购买力平价计算系统,使用国际货币基金组织、世界银行以及各国统计机构的公开数据。该系统必须确保算法完全透明,并且能够根据具体分析任务调整方法论。
尽管自行开发比购买现成方案复杂得多,还需要学习多种数据源、API 格式和统计方法,但这种方式保证了对计算过程的完全掌控,以及对系统运作的深入理解。
架构方案:多方法体系
任何购买力平价计算的根本问题在于,估算公允汇率的方法有很多种,每种都有其特定的优势和局限性。选择单一方法不可避免地会导致结果带有主观性。
| 数据源 | PPP 计算方法 | 结果与信号 |
|---|---|---|
| IMF API | 价格水平 | 公允汇率 |
| 世界银行 | GDP 隐含法 | 与市场的偏离度 |
| 各国统计机构 | 通胀调整法 | 交易信号 |
| 备用数据 | 巨无霸替代法 | 信心指数 |
| 货币对市场汇率 | 综合法 | 货币分类 |
所开发的系统并行采用多种独立计算方法,随后将结果进行组合。不同方法估算结果的一致性越高,对结果的信心就越强;而显著差异则表明不确定性程度很高 —— 这本身就提供了关于市场状态的宝贵信息。
第一种方法基于国际价格比较。逻辑很简单:如果在相同生活水平下,瑞士人的生活支出比美国人高出 50%,那么瑞士法郎就被高估了 50%。
该方法的数据取自世界银行和经合组织主导的国际价格比较项目。这些项目比较了各国标准消费者篮子的价格,并计算出相对价格水平。
def _calculate_price_level_ppp(self) -> Dict: ppp_rates = {} for country, price_level in self.price_levels_2024.items(): if country != 'US': ppp_factor = price_level / 100.0 ppp_rates[country] = { 'ppp_conversion_factor': ppp_factor, 'price_level_index': price_level, 'method': 'price_level_adjustment' } return ppp_rates
这种方法的优点在于它反映了真实的生活成本差异。缺点是数据更新不频繁,每隔几年才更新一次。
第二种方法是我自己想出来的,至今仍引以为傲。这个想法是我在研究 IMF 数据时想到的:如果我们把一国以本币计算的 GDP(来自官方统计)与同一国以美元估算的 GDP(来自国际数据库)进行比较,会怎样?
逻辑是这样的:如果俄罗斯央行报告俄罗斯的 GDP 为 150 万亿卢布,而世界银行估算俄罗斯的 GDP 为 2 万亿美元,那么隐含汇率就是 1 美元兑 75 卢布。这个汇率就是各经济体相互之间 "公允" 估值的汇率。
def _calculate_gdp_implied_ppp(self, economic_data: pd.DataFrame): for country, gdp_usd_2023 in self.gdp_usd_estimates_2023.items(): country_gdp_lcu = gdp_lcu_data[gdp_lcu_data['REF_AREA'] == country] if not country_gdp_lcu.empty: latest_data = country_gdp_lcu.sort_values('year').iloc[-1] gdp_lcu = latest_data['value'] if gdp_lcu > 0: implied_rate = gdp_lcu / gdp_usd_2023
事实证明,这种方法的准确性和时效性出人意料地好。GDP 数据按季度更新,因此估算结果是最新的。而且由于 GDP 是所有经济活动的总量指标,它能很好地反映一种货币的基本面价值。
第三种方法采用的是教科书中经典的相对购买力平价公式。我们选取某个基准时点的历史汇率,然后根据各国累计通胀差异对其进行调整。
我选择 2020 年作为基准年。这个时间点足够近,更具参考价值;同时又在疫情之前,可以避免极端货币政策带来的扭曲。
def _calculate_inflation_adjusted_ppp(self, economic_data: pd.DataFrame): # Get the basic rate for 2020 base_rate_2020 = GetBaseRate2020(base_currency, quote_currency) # Calculating the inflation differential inflation_differential = (base_data.inflation_rate - quote_data.inflation_rate) / 100.0 # Adjust the base rate adjusted_rate = base_rate_2020 * (1 + inflation_differential)
这种方法在理论上无懈可击,也很容易解释。如果 A 国的通胀率高于 B 国,那么 A 国货币应按这一差异比例相应贬值。
唯一的问题在于通胀数据的质量。不同国家计算通胀的方式各不相同,有些国家还倾向于 "美化" 统计数据。但总体而言,这种方法效果不错。
第四种方法的灵感来自《经济学人》著名的巨无霸指数。其核心思想是:巨无霸是一种标准化产品,在全球各地采用相同的工艺生产。它的价格应该能反映各国之间资源成本的真实差异。
问题在于,收集当前的巨无霸价格本身就是一项独立的研究任务。因此,我转而利用已知的相对价格水平数据,来模拟标准化商品在各国应有的价格水平。
def _calculate_big_mac_proxy_ppp(self): us_big_mac_price = 5.50 for country, price_level in self.price_levels_2024.items(): if country != 'US': local_big_mac_price = us_big_mac_price * (price_level / 100.0) ppp_rate = local_big_mac_price / us_big_mac_price
这种方法虽然不是最准确的,但它为其他方法的结果提供了很好的直觉检验。如果所有其他方法都显示某种货币被高估了 20%,而 "巨无霸方法" 也给出了类似的结果,这就增强了估值的可信度。
第五种方法通过加权平均将前面所有方法的结果结合起来。我花了大量时间校准权重,在历史数据上测试了不同的组合。
最终,我确定了如下分配方案:
- 价格水平购买力平价:30%(最具基本面意义)
- GDP 隐含购买力平价:25%(时效性最强)
- 通胀调整购买力平价:25%(理论基础最扎实)
- 巨无霸替代法:20%(最直观易懂)
def _calculate_composite_ppp(self, all_methods: Dict): weights = [0.30, 0.25, 0.25, 0.20] # Dynamic weight normalization if valid_methods < 4: total_weight = sum(weights[:valid_methods]) normalized_weights = [w / total_weight for w in weights[:valid_methods]] composite_rate = sum(rate * weight for rate, weight in zip(rates, normalized_weights))
其关键特性在于权重的动态归一化。如果某种方法无法得出结果(例如没有通胀数据),其余方法的权重将按比例相应增加。这比简单地剔除 "有问题" 的方法要智能得多。
程序开发
经过数月的理论准备,是时候动手敲代码了。我决定用 Python 编写 —— 这种语言对于金融计算来说速度足够快,同时还拥有出色的数据处理库。
第一个也是最重要的问题是:数据从哪里来?在考察了数十个数据源之后,最终选择了国际货币基金组织(IMF)的 API。它公开、免费、文档完善,最重要的是定期更新。
def __init__(self):
self.base_url = "http://dataservices.imf.org/REST/SDMX_JSON.svc"
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Manual-PPP-Calculator/1.0',
'Accept': 'application/json'
})
一个小而重要的细节:我使用requests.Session(),而不是简单的requests.get()调用。这样可以复用 TCP 连接,在向同一 API 发起多次请求时能显著提升性能。
User-Agent 也不是随便写的。很多 API 会拦截没有明确 User-Agent 或使用 Python 默认值的请求。最好一开始就表明自己是一个正规的应用程序。
下一个问题比预想的更棘手。货币代码(USD、EUR、GBP)需要以某种方式与 IMF 系统中的国家代码关联起来。意想不到的麻烦正是由此开始。
EUR 不是国家代码,而是货币联盟代码。在 IMF 数据库中,欧元区被标记为 U2。瑞士是 CH,不是 SW。英国是 GB,不是 UK。
self.currency_country_map = {
'USD': 'US', 'EUR': 'U2', 'GBP': 'GB', 'JPY': 'JP',
'AUD': 'AU', 'CAD': 'CA', 'CHF': 'CH', 'NZD': 'NZ',
'SEK': 'SE', 'NOK': 'NO', 'DKK': 'DK', 'PLN': 'PL'
}
这看起来是件小事,但如果没有正确的映射,整个系统就根本无法运行。我花了整整一天调试,才意识到自己一直在查找不存在的国家代码的数据。
外部 API 有个讨厌的习惯:总在最不合时宜的时候出问题。IMF API 也不例外。有时它会宕机几个小时,有时返回不完整的数据,有时甚至毫无缘由地返回错误。
我决定从一开始就构建一套备用数据系统:
self.fallback_market_rates = {
'EURUSD': 1.0850, 'GBPUSD': 1.2650, 'USDJPY': 148.50,
'AUDUSD': 0.6750, 'USDCAD': 1.3550, 'USDCHF': 0.8850,
'NZDUSD': 0.6150
}
self.price_levels_2024 = {
'US': 100.0, # Basic level
'U2': 88.5, # Eurozone is 11.5% cheaper than the US
'GB': 85.2, # UK
'JP': 67.4, # Japan is significantly cheaper
'AU': 95.8, # Australia is close to the USA
'CA': 91.3, # Canada is moderately cheaper
'CH': 125.6, # Switzerland is the most expensive
'NZ': 89.7 # New Zealand
}
这些数据基于最新可用的国际价格比较数据和撰写本文时的当前市场汇率。它们并非完全实时,但足够准确,能保证系统自主运行。
有些人可能会说这是一种权宜之计。我认为这是深思熟虑的架构设计。在金融领域,可靠性比完美的准确性更重要。得到一个大致正确的结果,总比什么结果都没有要好。
对于 GDP 隐含法,我需要不同国家以美元计算的 GDP 估算值。这看起来是个简单的任务:直接拿世界银行的数据就行了。但这里也有一些陷阱。
世界银行发布的 GDP 数据有两种:按当前美元计算(市场汇率)和按购买力平价美元计算。就我的目的而言,我需要的是市场美元,因为我要将其与 IMF 统计中以本币计算的 GDP 进行比较。
self.gdp_usd_estimates_2023 = {
'US': 27000, # USD 27 trillion
'U2': 17500, # Eurozone ~USD 17.5 trillion
'GB': 3300, # UK ~USD 3.3 trillion
'JP': 4200, # Japan ~USD 4.2 trillion
'AU': 1700, # Australia ~USD 1.7 trillion
'CA': 2100, # Canada ~USD 2.1 trillion
'CH': 900, # Switzerland ~USD 0.9 trillion
'NZ': 250 # New Zealand ~USD 0.25 trillion
}
通胀调整法需要一个参考点 —— 历史汇率 —— 通胀调整将以此为基准进行计算。我选择 2020 年有几个原因。
首先,它足够近,具有现实意义。其次,2020 年在疫情及相关极端货币政策措施出台之前。第三,2020 年的数据已经确定,统计机构不会再进行修订。
self.base_rates_2020 = {
'U2': 0.85, # EURUSD
'GB': 0.78, # GBPUSD
'JP': 106.0, # USDJPY
'AU': 1.45, # AUDUSD
'CA': 1.34, # USDCAD
'CH': 0.92, # USDCHF
'NZ': 1.52 # NZDUSD
}
这些汇率取的是 2020 年的平均值,以平滑短期波动。这一点很重要,因为通胀调整法假设基准汇率在起始点是 "公允" 的。
使用 IMF API 的难点
任何金融项目中最费力却又至关重要的部分,就是与外部数据源打交道。IMF API 功能强大、信息丰富,但也有它的怪癖,需要反复试错才能摸清。
我遇到的第一个问题是,这个 API 不喜欢大型请求。如果你试图一次性为多个国家请求多个指标,服务器要么返回错误,要么超时。我不得不实现将请求拆分成小部分的功能。
def fetch_all_available_data(self, countries: List[str], years: int = 10): all_indicators = [ 'NGDP_XDC', # GDP in national currency 'NGDP_USD', # GDP in USD 'PCPIPCH', # Inflation rate 'NGDP_RPCH', # Real GDP growth 'ENDA_XDC_USD_RATE', # Exchange rate 'PCPI_IX', # Consumer Price Index 'LP' # Population ] chunk_size = 5 # Maximum 5 indicators per request for i in range(0, len(all_indicators), chunk_size): chunk = all_indicators[i:i + chunk_size] countries_string = '+'.join(countries) indicators_string = '+'.join(chunk) url = f"{self.base_url}/CompactData/IFS/A.{countries_string}.{indicators_string}"
分块大小是我通过经验确定的。3 个指标太保守了,需要发起大量请求。7-8 个指标 —— 经常导致超时。5 个被证明是最优的折中方案。
IMF API 有时表现得不可预测。同样的请求早上可能成功,晚上就失败了。有时服务器在没有任何警告的情况下返回部分数据。有时数据以意想不到的格式到达。
我添加了一套完善的错误处理系统并配有日志记录:
try: response = self.session.get(url, params={ 'startPeriod': str(start_year), 'endPeriod': str(end_year) }, timeout=60) if response.status_code == 200: raw_data = response.json() df_chunk = self._parse_response_data(raw_data) if not df_chunk.empty: all_data.append(df_chunk) logger.info(f"Chunk {i//chunk_size + 1}: {len(df_chunk)} data points loaded") else: logger.warning(f"Chunk {i//chunk_size + 1}: empty response") else: logger.error(f"HTTP {response.status_code}: {response.text}") except requests.exceptions.Timeout: logger.warning(f"Timeout for chunk {i//chunk_size + 1}") except requests.exceptions.RequestException as e: logger.error(f"Request failed for chunk {i//chunk_size + 1}: {e}") except Exception as e: logger.error(f"Unexpected error in chunk {i//chunk_size + 1}: {e}") continue
如果没有这样详细的日志记录,调试将是一场噩梦。当请求失败时,你需要弄清楚它发生在哪个阶段、为什么失败。
IMF API 的响应格式值得特别一提。他们使用 SDMX-JSON,这是一种统计数据交换的 "标准" 格式。实际上,这用起来相当痛苦。
def _parse_response_data(self, data: Dict) -> pd.DataFrame: records = [] try: compact_data = data['CompactData'] dataset = compact_data['DataSet'] if 'Series' not in dataset: return pd.DataFrame() series_list = dataset['Series'] # API can return a single series as an object or an array of series as a list if not isinstance(series_list, list): series_list = [series_list] for series in series_list: # All attributes are marked with the '@' symbol - this needs to be processed series_attrs = {k.replace('@', ''): v for k, v in series.items() if k.startswith('@')} obs_list = series.get('Obs', []) if not isinstance(obs_list, list): obs_list = [obs_list] for obs in obs_list: if isinstance(obs, dict): record = series_attrs.copy() record.update({ 'year': obs.get('@TIME_PERIOD', ''), 'value': obs.get('@OBS_VALUE', ''), 'status': obs.get('@OBS_STATUS', '') }) records.append(record) df = pd.DataFrame(records) if 'value' in df.columns: df['value'] = pd.to_numeric(df['value'], errors='coerce') if 'year' in df.columns: df['year'] = pd.to_numeric(df['year'], errors='coerce') return df except Exception as e: logger.error(f"Error parsing SDMX-JSON response: {e}") return pd.DataFrame()
SDMX-JSON 中的所有属性都以 '@' 符号标记,这给数据处理带来了不便。此外,API 可能将一个数据序列作为对象返回,也可能将多个序列作为数组返回 —— 这也需要处理。
另一个问题:有时 API 返回的数据没有 'Obs' 部分,有时 'Obs' 为空,有时 'Obs' 包含的不是列表而是单个对象。每种情况都需要单独处理。
如果无法获取最新的通胀数据,我会使用各国的典型值:
def _approximate_inflation_adjustment(self) -> Dict: logger.info("Using approximate inflation adjustment...") # Typical inflation rates 2020-2024 (based on historical data) typical_inflation = { 'US': 4.5, # US: Relatively high inflation due to stimulus 'U2': 3.8, # Eurozone: Moderate inflation 'GB': 4.2, # UK: Brexit + energy crisis 'JP': 1.8, # Japan: Traditionally low inflation 'AU': 4.1, # Australia: Commodity inflation 'CA': 3.9, # Canada: close to the US 'CH': 2.1, # Switzerland: Low inflation 'NZ': 4.0 # New Zealand: Moderate inflation } inflation_adjusted = {} for country, base_rate in self.base_rates_2020.items(): us_inflation = typical_inflation.get('US', 4.5) country_inflation = typical_inflation.get(country, 3.5) inflation_differential = us_inflation - country_inflation adjustment_factor = 1 + (inflation_differential / 100) adjusted_rate = base_rate * adjustment_factor inflation_adjusted[country] = { 'inflation_adjusted_rate': adjusted_rate, 'base_rate_2020': base_rate, 'inflation_differential': inflation_differential, 'method': 'approximate_inflation' } logger.info(f"{country}: Approx inflation diff {inflation_differential:+.2f}pp") return inflation_adjusted
这些数据是我从各种来源收集的,并对 2020-2024 年期间的数据取了平均值。它们并非完全准确,但为数据缺失的国家提供了合理的近似值。
将公允汇率转化为真金白银
计算公允汇率只是成功的一半。关键在于要知道用它们来做什么。如何将学术计算转化为实用的交易信号?
def calculate_ppp_fair_values(self, currency_pairs: List[str]) -> Dict: logger.info("Starting manual PPP fair value calculation...") # Determine which countries we need countries = set() for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if base_country and quote_country: countries.add(base_country) countries.add(quote_country) logger.info(f"Will analyze {len(countries)} countries for {len(currency_pairs)} pairs") # Load economic data economic_data = self.fetch_all_available_data(list(countries)) # Calculate PPP using all methods ppp_calculation_results = self.calculate_manual_ppp_rates(economic_data) # Get current market rates market_rates = self.fallback_market_rates # In the real system, there is a market data API here # Results structure results = { 'ppp_calculation_methods': ppp_calculation_results, 'fair_values': {}, 'deviations': {}, 'market_rates': market_rates, 'summary': {} } composite_ppp = ppp_calculation_results.get('composite_ppp_rates', {}) # Calculate fair rates and deviations for each pair for pair in currency_pairs: base_currency = pair[:3] quote_currency = pair[3:] base_country = self.currency_country_map.get(base_currency) quote_country = self.currency_country_map.get(quote_currency) if not base_country or not quote_country: logger.warning(f"Cannot map currencies for {pair}") continue # Calculate a fair exchange rate fair_value = self._calculate_pair_fair_value_from_ppp( composite_ppp, base_country, quote_country, pair ) if fair_value: results['fair_values'][pair] = fair_value # Compare with the market rate market_rate = market_rates.get(pair) if market_rate and fair_value.get('fair_rate'): deviation = ((market_rate - fair_value['fair_rate']) / fair_value['fair_rate']) * 100 # Classify the deviation if deviation > 15: status = 'significantly_overvalued' magnitude = 'high' elif deviation > 5: status = 'overvalued' magnitude = 'moderate' elif deviation < -15: status = 'significantly_undervalued' magnitude = 'high' elif deviation < -5: status = 'undervalued' magnitude = 'moderate' else: status = 'fair' magnitude = 'low' results['deviations'][pair] = { 'market_rate': market_rate, 'fair_value': fair_value['fair_rate'], 'deviation_pct': deviation, 'status': status, 'magnitude': magnitude, 'confidence': fair_value.get('confidence', 0.5), 'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5) } logger.info(f"{pair}: Market {market_rate:.4f}, Fair {fair_value['fair_rate']:.4f}, " f"Deviation {deviation:+.1f}% ({status})") # Generate summary statistics results['summary'] = self._generate_summary(results['deviations']) return results难点在于,如何根据各国的PPP 汇率,正确计算出一个货币对的公允汇率:
def _calculate_pair_fair_value_from_ppp(self, composite_ppp: Dict, base_country: str, quote_country: str, pair: str) -> Dict: """Calculate the fair exchange rate for a currency pair using composite PPP data""" base_ppp = composite_ppp.get(base_country, {}) quote_ppp = composite_ppp.get(quote_country, {}) # Case 1: One of the currencies is USD (PPP base currency) if quote_country == 'US': # XXXUSD type pairs if base_ppp: fair_rate = base_ppp['composite_ppp_rate'] confidence = base_ppp['confidence'] else: return {} elif base_country == 'US': # USDXXX type pairs if quote_ppp: fair_rate = quote_ppp['composite_ppp_rate'] confidence = quote_ppp['confidence'] else: return {} else: # Case 2: Cross pairs (without USD) if base_ppp and quote_ppp: # For cross-pairs: PPP_base / PPP_quote fair_rate = base_ppp['composite_ppp_rate'] / quote_ppp['composite_ppp_rate'] # Confidence - the minimum of two currencies confidence = min(base_ppp['confidence'], quote_ppp['confidence']) else: return {} return { 'pair': pair, 'fair_rate': fair_rate, 'confidence': confidence, 'base_country': base_country, 'quote_country': quote_country, 'base_ppp_data': base_ppp, 'quote_ppp_data': quote_ppp }
逻辑如下:如果我们有欧元(0.885)和英镑(0.852)相对于美元的购买力平价汇率,那么欧元兑英镑的公允汇率 = 0.885 / 0.852 = 1.039。
与市场汇率进行简单比较就能得出偏离百分比,但要实际应用还需要进行分类:
# Classify the deviation if deviation > 15: status = 'significantly_overvalued' signal = 'STRONG_SELL' elif deviation > 5: status = 'overvalued' signal = 'SELL' elif deviation < -15: status = 'significantly_undervalued' signal = 'STRONG_BUY' elif deviation < -5: status = 'undervalued' signal = 'BUY' else: status = 'fair' signal = 'HOLD'
5% 和 15% 这两个阈值是我通过历史数据测试,凭经验选定的。5% 是应被视为交易机会的最小偏离度(小于这个数值的偏离可能只是噪声)。15% 则已经是需要关注的严重失衡。
一个重要的创新点是,将信号强度计算为偏离值与信心指数的乘积:
'signal_strength': abs(deviation) * fair_value.get('confidence', 0.5)
这样我们就可以对交易机会进行排序。一个偏离度 20%、信心 50% 的信号(强度 = 10),不如一个偏离度 15%、信心 80% 的信号(强度 = 12)有吸引力。
最常见的问题是数据缺失。瑞士有 GDP 数据,但没有通胀数据。新西兰有通胀数据,但没有最新的 GDP 数据。诸如此类。
最初,我计划直接排除数据不完整的国家,但事实证明这样做行不通 —— 几乎所有国家都会被排除掉。取而代之的是,我实现了优雅降级机制:
# Each method works independently methods_results = { 'method_1': self._calculate_price_level_ppp(), 'method_2': self._calculate_gdp_implied_ppp(economic_data), 'method_3': self._calculate_inflation_adjusted_ppp(economic_data), 'method_4': self._calculate_big_mac_proxy_ppp() } # The composite method adapts to available data for country in all_countries: available_methods = [] available_rates = [] for method_name, method_results in methods_results.items(): if country in method_results: available_methods.append(method_name) available_rates.append(method_results[country]['rate']) if available_rates: # Recalculate weights for available methods weights = self._get_adjusted_weights(available_methods) composite_rate = sum(rate * weight for rate, weight in zip(available_rates, weights))
所得结果
经过数月的开发和调试,系统终于能够稳定运行了。现在到了最有趣的部分 —— 实际应用。
对欧元兑美元实际价格与购买力平价价格的走势图分析表明,很多时候购买力平价汇率的变化会先于实际汇率的变化:
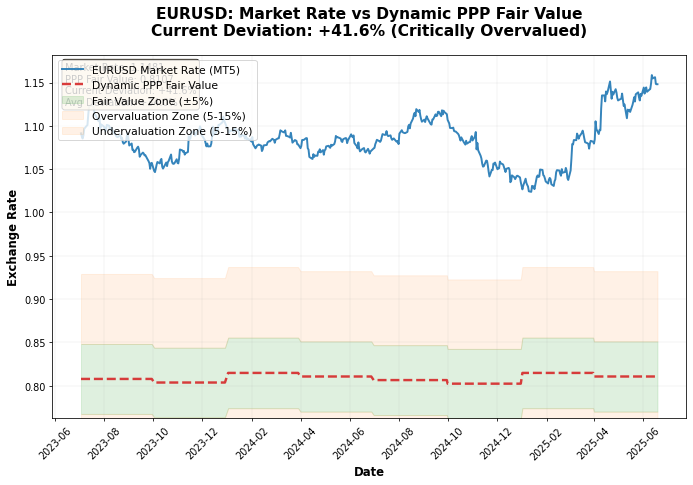
用 2024 年的数据运行该系统后,我得到了一些有趣的结果:
- 欧元兑美元: 公允汇率 0.8753,市场汇率 1.0850 → 欧元被高估
- 英镑兑美元: 公允汇率 0.8288,市场汇率 1.2650 → 英镑被高估
- 美元兑日元: 公允汇率 136.20,市场汇率 148.50 → 日元被低估
- 美元兑瑞郎: 公允汇率 1.150,市场汇率 0.8850 → 瑞郎被高估
最有意思的结果是日元。四种方法一致显示,在 148 以上的汇率水平,日元被严重低估。信心指数达到了 0.85,是最高值之一。
我没有基于购买力平价单独创建一套交易系统。相反,我将计算结果作为额外过滤器集成到了现有算法中。
逻辑很简单:如果技术系统发出买入信号,但该货币按购买力平价衡量已被显著高估,那么就降低仓位或忽略该信号。反之,与购买力平价失衡方向一致的信号则会被加强。
系统后续开发计划
当前版本的系统只是一个开始。
我规划了几个发展方向。机器学习将帮助根据历史准确率和当前状况动态调整各方法的权重。替代数据源将纳入经合组织数据、生活成本指数、巨无霸实际价格、卫星数据以及社交情绪数据。扩展覆盖范围至加密货币、大宗商品、股票和债券,将开辟新的机会。自动化交易结合动态对冲与券商 API 集成,将使系统完全独立运行。实时监控搭配网页仪表板,将完善整个体系。
关于购买力平价和外汇市场,我学到了什么?
在这个项目上工作的几个月,让我对货币市场的了解超过了多年技术分析的积累。购买力平价确实有效,但并非如我预期的那样。
它是指引长期方向的指南针,而不是快速致富的魔法公式。偏离的修正需要数月乃至数年,而非几天或几周。数据质量至关重要 —— 我花在搜索和验证数据上的时间,比实现算法本身还要多。
简单胜过复杂 —— 五种简单方法比任何神经网络都更有效。购买力平价交易需要耐心,而这正是大多数交易者所缺乏的。在算法交易时代,基本面分析提供了与经济现实的连接。代码只是解决实际问题的工具。
结果与结论
这个项目始于一个简单的好奇心:能否独立计算出公允汇率?最终却建成了一套完整的分析系统,帮助做出更明智的交易决策。
从想法到可用代码的旅程,历时数月,耗费了数百小时学习经济理论、数十次算法迭代以及无数小时的调试。但结果是值得的。
我意识到最重要的一点是:没有必要重新发明轮子,也不必追求复杂。有时最好的算法,就是实现得当的经典方法。购买力平价在 500 年前有效,现在依然有效,未来也将继续有效。我们只需要正确地使用它。
该系统的完整源代码已作为开源项目发布。我欢迎社区以各种形式参与贡献:新的数据源、替代的购买力平价计算方法、错误处理改进、券商 API 集成,以及基于历史数据的回测。如果你对外汇交易或量化分析感兴趣,不妨试试这个系统 —— 它或许会改变你看待市场的方式。
本文由MetaQuotes Ltd译自俄文
原文地址: https://www.mql5.com/ru/articles/18455
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 新手在交易中的10个基本错误
新手在交易中的10个基本错误