
从基础到中级:数组(一)

概述
此处提供的内容仅用于教育目的。在任何情况下,除了学习和掌握所提出的概念外,都不应出于任何目的使用此应用程序。
在上一篇文章从基础到中级:数组和字符串(三 )中,我使用根据目前所展示的知识水平定制的代码,解释并演示了标准库如何将二进制值转换为十进制、八进制和十六进制表示形式。我还介绍了它如何生成二进制字符串表示,使我们更容易可视化结果。
除了这个基本概念,我还演示了如何根据秘密短语定义密码长度。幸运的是,生成的密码包含重复的字符序列。考虑到这不是预期目标,这是一个了不起的结果。事实上,这只是一次幸运的意外。然而,它提供了一个很好的机会来解释与数组和字符串相关的其他几个概念和要点。
一些读者可能希望我深入研究标准库中每个函数或过程的工作原理。但这不是我的意图。我的实际目标是揭示每个决定背后的概念。你可以根据需要解决的问题的性质做出自己的选择。虽然我们还处于相当基本的水平,但我们已经有了一些现实世界的编程可能性。这使我们能够开始应用稍微更先进的概念。
这不仅简化了编码过程,而且使您,亲爱的读者,能够更轻松地阅读更复杂的代码。没必要担心会发生什么。我将逐步介绍更改,以便您熟悉它们并舒适地阅读我的代码。我倾向于以可能让初学者感到困惑的方式最小化或压缩表达式,我想让你适应这种风格。
也就是说,让我们从回顾上一篇文章开始。换句话说,让我们学习许多可能的方法之一,以避免用于从秘密短语生成密码的因子分解过程产生的结果。
众多解决方案之一
非常好,今天,我们将从使代码更加优雅开始。原始代码如下所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", PassWord(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string PassWord(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[], 16. pos, 17. i = 0; 18. 19. ArrayResize(psw, SizePsw); 20. ArrayInitialize(psw, 0); 21. for (int c = 0; szArg[c]; c++) 22. { 23. pos = (uchar)(szArg[c] % StringLen(szCodePhrase)); 24. psw[i++] += (uchar)szCodePhrase[pos]; 25. i = (i == SizePsw ? 0 : i); 26. } 27. 28. for (uchar c = 0; c < SizePsw; c++) 29. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 30. 31. return CharArrayToString(psw); 32. } 33. //+------------------------------------------------------------------+
代码 01
在我看来,这段代码有点不够优雅。这是因为第 16 行和第 17 行声明的变量仅在第 21 行的循环中使用。如果出于任何原因,我们以后需要一个同名或不同类型的变量,我们就必须付出额外的工作来调整代码。正如我们在前面的文章中看到的,可以在 FOR 循环中直接声明变量。
亲爱的读者,请密切注意。当声明多个仅用于 FOR 循环的变量时,它们必须属于同一类型。在 FOR 循环的第一个表达式中声明和初始化不同类型的变量是不可能的。所以,我们需要在这里做一个小决定。第 16 行和第 17 行声明的变量 “pos” 和 “i” 为 uchar 类型,而 FOR 循环内声明的变量 “c” 为 int 类型。我们可以将 “pos” 和 “i” 更改为 int,或者将 “c” 更改为 uchar。在我看来,短语超过 255 个字符是没有意义的。因此,我们可以采取中间立场,将所有三个变量定义为 ushort 类型,因为它们仅用作索引变量。根据这个解释,我们将代码 01 修改为代码 02。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[psw[c] % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+
代码 02
尽管代码 02 可能表现出明显的复杂性,但它仍然执行与代码 01 相同的任务。不过,我想提请您注意第 20 行。请注意,在 for 循环的第一个表达式中,我们现在声明了将在循环中独占使用的所有变量。仔细查看 FOR 语句的第三个表达式。在这种情况下,如果不使用三元运算符,就不可能以这种方式调整变量 “i” 的值。然而,值得注意的是,这种调整只是确保索引保持在数组的边界内,因为实际增量是在第 23 行执行的。
尽管发生了这种修改,但输出仍然完全相同。也就是说,当您运行代码时,您会在终端上看到类似于下图所示的内容。
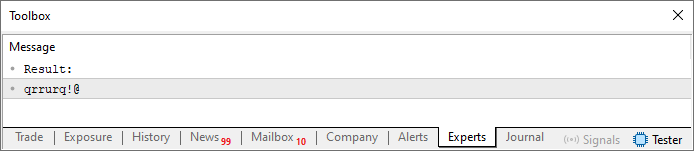
图 01
现在,我们来想一想。输出字符串中符号的重复发生是因为在第 27 行,我们引用了 szCodePhrase 字符串中的相同位置。换句话说,通过减少值以保持在第 13 行定义的字符串长度内,我们最终会重复指向同一位置。但是(这是一个重要的时刻),如果我们将当前位置与前一个位置相加,我们可以生成一个与上一个完全不同的新索引。由于第 13 行的字符串不包含重复字符,因此输出字符串(即我们的密码)也不会有重复字符。
这里有一件重要的事情要记住:这种技术并不总是有效的。这是因为第 13 行定义的字符串中的字符数可能并不理想。在另一种情况下,这些值可能会陷入一个完美的循环。这是因为我们基本上是在处理第 13 行声明的字符或符号的循环,其中第一个字符(右括号)链接到最后一个字符,即数字 9。它就像一条蛇咬自己的尾巴。
许多非程序员不理解这个概念。但在处理代码时,这样的事情总是以这样或那样的形式出现。
好了,现在我已经解释了我们要做什么,让我们来看看代码。如下图所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. void OnStart(void) 05. { 06. const string sz_Secret_Phrase = "Um pequeno jabuti xereta viu dez cegonhas felizes"; 07. 08. Print("Result:\n", Password(sz_Secret_Phrase, 8)); 09. } 10. //+------------------------------------------------------------------+ 11. string Password(const string szArg, const uchar SizePsw) 12. { 13. const string szCodePhrase = ")0The!1quick@2brown#3fox$4jumps%5over^6the&7lazy*8dog(9"; 14. 15. uchar psw[]; 16. 17. ArrayResize(psw, SizePsw); 18. ArrayInitialize(psw, 0); 19. 20. for (ushort c = 0, pos, i = 0; szArg[c]; c++, i = (i == SizePsw ? 0 : i)) 21. { 22. pos = (ushort)(szArg[c] % StringLen(szCodePhrase)); 23. psw[i++] += (uchar)szCodePhrase[pos]; 24. } 25. 26. for (uchar c = 0; c < SizePsw; c++) 27. psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 0) + psw[c]) % StringLen(szCodePhrase)]); 28. 29. return CharArrayToString(psw); 30. } 31. //+------------------------------------------------------------------+s
代码 03
这种方法非常有趣。请注意,我几乎没有更改代码中的任何内容。只有第 27 行是新的。我做了一些与 for 循环的第三个表达式非常相似的事情,你可以在第 20 行看到。但在深入探讨之前,让我们先看看结果。就在下面可以看到。
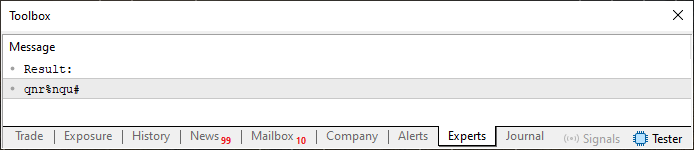
图 02
你会发现我们之前的重复字符已经不复存在了。然而,通过更改代码 03 中的一行,可以进一步改进。如前几篇文章所述,第 27 行使用的三元运算符的功能类似于 IF 语句。因此,计算的第一个值不会进行任何调整。然而,所有后续值都会根据前一次迭代中使用的索引进行调整。请密切注意:用于此调整的数组值不是第 20 行循环中计算的值。它是从第 13 行定义的字符串中获得的。因此,要确定其确切值,您需要查阅 ASCII 表,并将该值添加到第 20 行循环中计算的值中。这可能看起来有点令人困惑,但一旦你停下来想一想,其实很简单。
现在,我想提请你注意三元运算符中使用的零值。这就是第一个索引保持不变的原因。但是,如果我们用另一个值替换那个零呢?假设我们修改第 27 行,如下所示。
psw[c] = (uchar)(szCodePhrase[((c ? psw[c - 1] : 5) + psw[c]) % StringLen(szCodePhrase)]);
结果会大不相同,如下图所示。
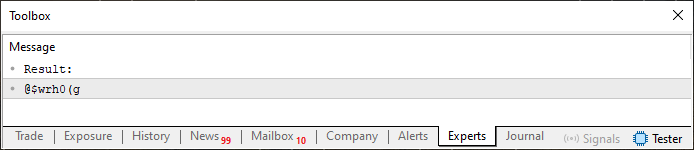
图 03
很有趣,不是吗?只需一个简单的更改,我们就可以生成许多人认为的强密码。我们用基本的计算和两个容易记住的短语完成了这项工作。请记住,我们使用我仍然认为是初学者的编程知识水平完成了所有这些工作。对于刚刚起步的人来说,这还不错。所以,亲爱的读者,请尽情探索和尝试新的可能性。我在这里展示的只是一个简单、基本的例子,一个有经验的程序员可以在几分钟内实现。
太好了,这是使用数组演示中最简单的部分。然而,我们还没有完全完成。在我们进一步探讨更高级和更复杂的主题之前,我们需要介绍一些关于数组的额外细节。那么让我们转到一个新的主题。
数据类型及其与数组的关系
本节的主题正是编程中最复杂、最令人困惑、最难掌握的主题之一。亲爱的读者,也许,而且很可能,你还没有理解这个话题到底有多复杂。有些人认为自己是优秀的程序员,但不知道事情是如何相互关联的。因此,他们声称某些任务是不可能的,或者比实际更困难。
当你逐渐吸收这个话题时,你会开始理解许多其他概念,乍一看,这些概念可能看似无关,但在更深层次上,它们都是从根本上联系在一起的。
让我们首先思考一下计算机内存。无论处理器是 8 位、16 位、32 位、64 位,还是 48 位等不常见的处理器,都没有关系,那不重要。同样,无论我们处理的是二进制、八进制、十六进制还是其他任何数字系统,都无关紧要,这也没什么区别。真正重要的是如何设置或构建数据结构。例如:谁决定一个字节必须有 8 位?为什么是 8?难道不能是 10 位或 12 位吗?
也许这种思路现在没有多大意义。这是因为很难将几十年的经验提炼成初学者可以理解的东西。如果不过早地深入探讨某些概念,讨论这样的话题可能会非常困难。然而,基于我们在之前的文章中已经介绍过的内容,我们可以在这里玩得开心一些。让我们使用一个数据类型的数组和一个完全不同类型的变量。但有一个小规则:数组中使用的数据类型不能与变量的数据类型相同。即便如此,只要我们遵循一些简单的规则,我们就可以让它们相互交流,甚至持有相同的值。
听起来很复杂,好像需要更多的编程知识,对吗?让我们试试看。为了让事情变得更加愉快,我们将带回上一篇文章中的函数 —— 我们用来将二进制值转换为其他格式的函数。
听起来是个不错的计划。由于我们将广泛使用这种实现来解释几个概念,让我们将该函数放入头文件中。这就引出了下面显示的代码。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. string ValueToString(ulong arg, char format) 05. { 06. const string szChars = "0123456789ABCDEF"; 07. string sz0 = ""; 08. 09. while (arg) 10. switch (format) 11. { 12. case 0: 13. sz0 = StringFormat("%c%s", szChars[(uchar)(arg % 10)], sz0); 14. arg /= 10; 15. break; 16. case 1: 17. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x7)], sz0); 18. arg >>= 3; 19. break; 20. case 2: 21. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0xF)], sz0); 22. arg >>= 4; 23. break; 24. case 3: 25. sz0 = StringFormat("%c%s", szChars[(uchar)(arg & 0x1)], sz0); 26. arg >>= 1; 27. break; 28. default: 29. return "Format not implemented."; 30. } 31. 32. return sz0; 33. } 34. //+------------------------------------------------------------------+
代码 04
现在,一个重要的细节:由于代码 04 是一个头文件,将被包含并仅用于教程脚本,因此它将被放置在脚本目录内的文件夹中。正如我之前解释的那样,这对这里创建的任何东西都有具体的影响,我不会重复这个解释。让我们继续吧。好的,亲爱的读者,请注意这一点:我们要转换的所有值都应被视为无符号值,至少在我们纠正代码 04 中显示的函数中的这个小细节之前。
完成之后,我们就可以测试一切是否正常运行。为此,我们将使用一个简单的脚本:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. ushort value = 0xCADA; 09. 10. PrintFormat("Translation via standard library.\n" + 11. "Decimal: %I64u\n" + 12. "Octal : %I64o\n" + 13. "Hex : %I64X", 14. value, value, value 15. ); 16. PrintFormat("Translation personal.\n" + 17. "Decimal: %s\n" + 18. "Octal : %s\n" + 19. "Hex : %s\n" + 20. "Binary : %s", 21. ValueToString(value, 0), 22. ValueToString(value, 1), 23. ValueToString(value, 2), 24. ValueToString(value, 3) 25. ); 26. } 27. //+------------------------------------------------------------------+
代码 05
执行此脚本后,输出将如下图所示:
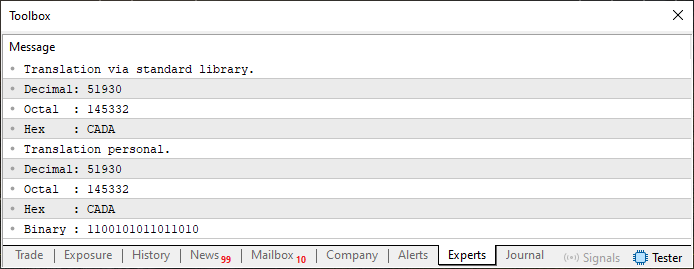
图 04
它显然有效。有了这些,我们就可以开始尝试不同数据类型的数组和变量了。这将帮助你开始掌握一种非常奇怪的行为,这种行为只发生在某些编程语言中。首先,我们将对代码 05 进行一些修改。这个版本将作为我们的起点,我称之为“ POINT ZERO ”(0 点)。如下所示:
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA}; 09. ushort value = 0; 10. 11. value = (array[0] << 8) | (array[1]); 12. 13. PrintFormat("Translation personal.\n" + 14. "Decimal: %s\n" + 15. "Octal : %s\n" + 16. "Hex : %s\n" + 17. "Binary : %s", 18. ValueToString(value, 0), 19. ValueToString(value, 1), 20. ValueToString(value, 2), 21. ValueToString(value, 3) 22. ); 23. } 24. //+------------------------------------------------------------------+
代码 06
现在,我请求你,亲爱的读者,放下任何分心或可能转移你注意力的事情。我需要你完全专注于我们从这一点开始要探索的内容。因为我要解释的是许多初学者程序员感到非常困惑的事情。并非所有程序员,尤其是那些使用特定语言(如 MQL5)的程序员。
在我们深入解释之前,让我们先看看运行代码 06 的结果。您可以在下面看到它:
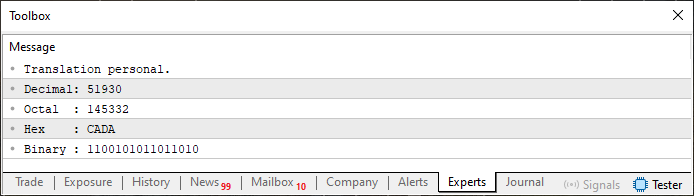
图 05
您在代码 06 中看到的内容为广泛的概念奠定了基础。如果你能真正理解这段代码,你就能轻松理解接下来的所有相关主题。这是因为许多这些主题在某种程度上源于这段代码的功能。
乍一看,您可能没有意识到这段看似简单的代码实际上有多复杂,或者仅仅因为这种实现是可能的,就可以完成什么。所以让我们慢慢来。对于那些已经有一定经验的人来说,接下来的内容都不是新鲜事。但对于那些仍在学习的人来说,这里的解释似乎令人困惑。
好吧,也许我有点想得太多了。让我们稍微回顾一下,再问一下:仅根据目前所解释的内容,您还不明白代码 06 的哪一部分?最有可能的是第 8 行和第 11 行。实际上,对于刚刚起步的人来说,这些话似乎没有多大意义。在本文的前几节中,我们确实看到了类似的情况。查看代码 03,特别是第 15、20、23 和 27 行。
然而,在代码 06 中,情况略有不同 —— 虽然不是完全不同,但足以引起混乱。也许这是因为我在正确解释数组之前使用了数组,犯了一个错误。对此,我深表歉意。特别是如果您现在感觉有点迷茫,就像看到图 05 中的输出时的情况一样,这是运行代码 06 的结果。
所以,让我们退一步,以正确的方式做事。让我们从代码 06 的第 11 行开始。我们所拥有的相当于以下代码行,如下所示:
value = (0xCA << 8) | (0xDA);
乍一看,这似乎有点复杂。尽管我们已经讨论了位移运算符的工作原理。让我们借助视觉辅助工具,这将使事情变得更容易理解。
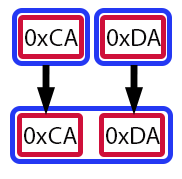
图 06
在这个图中,每个红色矩形代表一个字节,或者更确切地说,一个 uchar 类型的值。蓝色矩形代表变量。箭头指示值在整个过程中如何移动和变换。换句话说,图 06 显示了变量 value 的值在第 11 行是如何形成的。让我看看我是否理解正确:你是说,即使值的类型是 ushort,我们也可以将 uchar 类型的值插入其中?这样做,我们就能构建一个全新的值吗?确实如此,亲爱的读者。但它并没有就此止步。让我们慢慢来,这样才能完全理解这个概念。
如您所知,第 8 行中定义的内存区域是一个恒定区域。但还有更多。由于我们正在初始化此内存块中的值,您可以将其视为一种 ROM 卡带,类似于老式视频游戏机中使用的老式游戏卡带。

图 07
谈论在 RAM 内创建 ROM 可能听起来很奇怪,但是是的,这基本上就是第 8 行正在做的事情。
但请稍等一下,我们在第 8 行创建的 ROM 的大小是多少?这取决于不同情况,亲爱的读者。不,我并不是想回避这个问题。我完全是诚实的。幸运的是,标准库中有一个函数可以让我们确定分配块的大小。请记住,数组是一个字符串,但字符串是一种特殊的数组,正如我们之前讨论的那样。与前面示例中使用的数组(我们从简单短语生成密码)不同,代码 06 中的数组是一个纯数组。也就是说,它不是字符串,但它意味着表示任何类型的值。然而,由于我们将其声明为 uchar 数组,我们限制了可以在其中存储的值的范围。这就是事情变得有趣的地方:我们可以使用更大的类型来解释存储在数组中的值。
为此,我们需要一种能够保存数组中所有位的数据类型。这正是图 06 想要展示的。蓝色部分代表组成数组的位的集合,被视为一个单元。为了使这个概念更加清晰,让我们在第 08 行添加更多信息,看看会发生什么。但为了保持简单,我们需要调整代码,如下所示。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. } 25. //+------------------------------------------------------------------+
代码 07
是的,我知道。我们在代码 07 中所做的事情可能看起来完全是疯狂的。但是看一下我们执行此代码时得到的结果。请看下面。
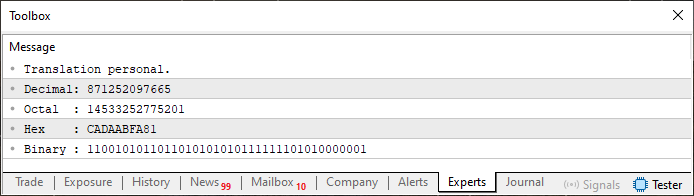
图 08
现在你可能会说这完全是疯了。但正如你所看到的,亲爱的读者,它奏效了。换句话说,我们在一个数组中组合了二进制值、十六进制值和十进制值。最后,我们构建了一个类似 ROM 的小型存储块,其中包含某种信息。但最疯狂的是 —— 你在这里看到的只是巨大冰山的一角。
在我们深入探讨之前,让我们花点时间了解一下这里实际发生了什么,以及在使用这种设置时需要考虑哪些限制和预防措施。
您可能已经注意到,在第 8 行,我只是添加了更多数据。我们最多可以在那里放置多少数据?答案是:无限量,或至少是系统允许的数量。在实践中,可以包含的数据量完全取决于机器的内存容量。然而,虽然我们可以在第 8 行的数组中放入几乎无限的值,但这并不适用于 “value” 变量。这就是硬限制发挥作用的地方。在这个例子中,亲爱的读者,我想给你尽可能多的自由去进行实验。因此,我使用了MQL5目前支持的最大位容量 —— 64 位, 即 8 个字节。这是否意味着我们只能在值变量中存储 8 个字节?不完全是。它的真正含义是:一旦达到 64 位,任何新数据都将覆盖旧值。这创建了一个数据流模型,我们稍后将更详细地探讨。
重要的是要理解该变量最多可容纳 64 位。但这并不一定意味着 8 个值。对于那些没有阅读前面的文章或练习其中解释的内容就直接进入这篇文章的人来说,这正是事情开始变得棘手的地方。
现在,在我们深入研究第 11 行的循环并探究第 12 行发生的情况之前,让我们修改代码 07 中的一个小细节。这一修改将使数组大小的概念及其内部的信息量更加清晰。下面的代码行显示了这个小修改。
const ushort array[] = {0xCADA, B'1010101111111010', 0x81}; 现在,查看上面修改后的行,您会注意到我们的数组不再有 5 个元素 —— 它只有 3 个。值得注意的是,尽管我们改变了元素的数量,但我们仍然使用几乎相同数量的内存。不同之处在于,现在我们浪费了 8 位内存。这是因为,与我们在代码 07 中看到的每个字节都被充分利用不同,在这个新结构中,数组中的最后一个值仅使用了可用的 16 位中的 8 位。这似乎是一个可以接受的浪费水平。稍后我们将进一步讨论这个问题。现在,请记住:您使用的数据类型会影响内存使用情况。在某些情况下,它还会影响代码的行为。
然而,还有一种更糟糕的情况:当你使用下面所示的行时。
const int array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 我知道许多开发人员并不担心为每个变量使用最合适的数据类型。但即使在代码 07 中使用该行似乎存在(在我们当前的情况下,实际上不存在)任何问题,您也不再浪费每个元素 8 位。现在数组中每个元素浪费了 16 位。如果有 5 个元素,那就浪费了 80 位或 10 个字节,这超过了我们在文章开始时构建的密码的宽度。
同样,这种内存浪费量可能看起来微不足道,特别是考虑到当今的机器通常配备 32 GB 或更多的 RAM。即使在我们当前的示例中存在这种浪费,代码的行为也不会改变。这要归功于第 11 行和第 12 行的逻辑,我们现在将对其进行分解。
在这里,我们告诉代码,对于数组中的每个元素,我们希望存储在 value 中的值向左移动 8 位,为新元素腾出空间。这就是第 12 行发生的情况。但这行专门针对变量 “c” 指示的数组中的某个元素。我们如何知道数组中有多少个元素?看一下第 11 行。for 循环条件中的第二个表达式提供了该信息。我们在这里所做的是调用 MQL5 中的标准库函数。
此函数相当于使用 ArraySize() 。这就是我们确定数组中存在多少个元素的方法,而不管每个元素实际使用多少位。
要试验这种行为,只需修改代码,使其看起来像下面显示的版本。
01. //+------------------------------------------------------------------+ 02. #property copyright "Daniel Jose" 03. //+------------------------------------------------------------------+ 04. #include "Tutorial\File 01.mqh" 05. //+------------------------------------------------------------------+ 06. void OnStart(void) 07. { 08. const uchar array[] = {0xCA, 0xDA, B'10101011', 250, 0x81}; 09. ulong value = 0; 10. 11. for (uchar c = 0; c < array.Size(); c++) 12. value = (value << 8) | (array[c]); 13. 14. PrintFormat("Translation personal.\n" + 15. "Decimal: %s\n" + 16. "Octal : %s\n" + 17. "Hex : %s\n" + 18. "Binary : %s", 19. ValueToString(value, 0), 20. ValueToString(value, 1), 21. ValueToString(value, 2), 22. ValueToString(value, 3) 23. ); 24. Print("Number of elements in the array: ", ArraySize(array)); 25. } 26. //+------------------------------------------------------------------+
代码 08
当我们运行代码 08 时,我们将能够看到数组中存在的元素数量,如下图中突出显示的区域所示。
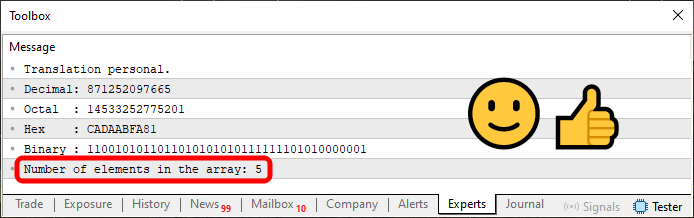
图片 09
最后的探讨
好吧,亲爱的读者,这篇文章已经包含了丰富的材料供你学习和吸收。因此,我会给你一些时间来复习和练习我们到目前为止所涵盖的所有内容。试着真正理解与使用数组相关的这些基本概念。尽管本文中使用的数组属于 ROM 类型,即其内容无法修改,但尽力理解这里所解释的内容仍然至关重要。我知道这些材料可能很难同时消化,但我鼓励你付出努力,专注于追求更深入的理解。
掌握本文和前几篇文章中的概念将极大地支持你作为程序员的成长。随着材料变得越来越复杂,您将面临越来越大的挑战。但不要因困难而气馁 —— 勇敢地接受它。一定要练习,并参考附件,以帮助您理解文章中没有完全演示但顺便提到的主题。一些示例包括讨论过的代码修改,但未显示其输出。了解这些变化如何影响记忆非常重要。因此,请尽情探索附件。
本文由MetaQuotes Ltd译自葡萄牙语
原文地址: https://www.mql5.com/pt/articles/15462
注意: MetaQuotes Ltd.将保留所有关于这些材料的权利。全部或部分复制或者转载这些材料将被禁止。
本文由网站的一位用户撰写,反映了他们的个人观点。MetaQuotes Ltd 不对所提供信息的准确性负责,也不对因使用所述解决方案、策略或建议而产生的任何后果负责。

 利用CatBoost机器学习模型作为趋势跟踪策略的过滤器
利用CatBoost机器学习模型作为趋势跟踪策略的过滤器