
Преодоление ограничений машинного обучения (Часть 8): Непараметрический выбор стратегии

В своем предыдущем обсуждении, посвященном автоматическому выбору стратегии мы рассмотрели два подхода к определению торговых стратегий из списка стратегий-кандидатов. Первым был метод "белого ящика", использующий матричную факторизацию - простой, прозрачный и интуитивно понятный. Сегодня мы сосредоточимся на повышении эффективности второго подхода: более сложного решения "черного ящика".
Проблема определения прибыльных стратегий остается значимой. Данная статья посвящена улучшению конфигурации и настройки моделей "черного ящика". Ранее мы разработали статистическую модель, которая научилась предсказывать ожидаемую прибыль от каждой стратегии, направляя нас к потенциально прибыльным стратегиям. Хотя это вполне оправданная цель, более простой альтернативой было бы определить стратегию, которой наша модель "черного ящика" может научиться наиболее эффективно, - выбрать цель, на которой она работает “наилучшим образом”. Но это создает серьезный вызов.
Сравнение эффективности работы модели по различным целям регрессии является непростой задачей. В отличие от задач классификации, где такие метрики, как accuracy и precision (точность по положительному классу), упрощают сравнение, регрессия имеет дело с реальными целями, такими как будущая доходность, а общие показатели, такие как квадратный корень из среднего квадратичной ошибки (RMSE), могут вводить в заблуждение. Проблема заключается в том, что общепринятая Евклидова метрика дисперсии чувствительна к масштабу. А это означает, что такие индикаторы, как стохастик и значения скользящих средних, напрямую не сопоставимы. В дополнение к этой проблеме классическое обучение под наблюдением дает здесь мало помогает.
Именно здесь взаимная информация (MI) становится ценной. MI обладает свойствами, которые делают её подходящей для сравнения целевых признаков регрессии - она непараметрическая, не содержит единиц измерения и привязана к нулю, что дает нам значимую опорную точку. Если коротко, при выборе между несколькими целями для моделирования мы рекомендуем выбрать ту, которая максимизирует MI.
MI измеряет зависимость между двумя переменными. В нашем контексте нам нужны прогнозы модели, которые были бы чувствительны к реальным изменениям целевых показателей. В первой статье этой серии мы показали, что RMSE может быть искажен моделями, предсказывающими среднюю доходность. Читатели, которые еще не читали наше предыдущее обсуждение о взломе целевой функции, могут найти полезную ссылку, прикрепленную здесь. Вкратце, MI более надежна и менее уязвима для подобных манипуляций, что делает ее гораздо более надежным решением для определения наиболее информативного целевого признака регрессии при наличии множества целевых признаков регрессии на выбор.
Получение нужных нам данных
Постоянные читатели узнают этот скрипт — это тот же самый, который мы использовали в первой версии этого обсуждения. Мы включили его сюда для удобства новых читателей. Скрипт извлекает рыночные данные OHLC вместе со скользящими средними, RSI и стохастическими индикаторами. //+------------------------------------------------------------------+ //| ProjectName | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- Define our moving average indicator #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average we have #define RSI_PERIOD 15 //--- RSI Period #define STOCH_K 5 //--- Stochastich K Period #define STOCH_D 3 //--- Stochastich D Period #define STOCH_SLOWING 3 //--- Stochastic slowing #define STOCH_MODE MODE_EMA //--- Stochastic mode #define STOCH_PRICE STO_LOWHIGH //--- Stochastic price feeds #define HORIZON 5 //--- Forecast horizon //--- Our handlers for our indicators int ma_handle,ma_o_handle,ma_h_handle,ma_l_handle,rsi_handle,stoch_handle; //--- Data structures to store the readings from our indicators double ma_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],rsi_reading[],sto_reading_main[],sto_reading_signal[]; //--- File name string file_name = Symbol() + " Market Data As Series Indicators.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size + (HORIZON * 2); //---Setup our technical indicators ma_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); rsi_handle = iRSI(_Symbol,PERIOD_CURRENT,RSI_PERIOD,PRICE_CLOSE); stoch_handle = iStochastic(_Symbol,PERIOD_CURRENT,STOCH_K,STOCH_D,STOCH_SLOWING,STOCH_MODE,STOCH_PRICE); //---Set the values as series CopyBuffer(ma_handle,0,0,fetch,ma_reading); ArraySetAsSeries(ma_reading,true); CopyBuffer(ma_o_handle,0,0,fetch,ma_o_reading); ArraySetAsSeries(ma_o_reading,true); CopyBuffer(ma_h_handle,0,0,fetch,ma_h_reading); ArraySetAsSeries(ma_h_reading,true); CopyBuffer(ma_l_handle,0,0,fetch,ma_l_reading); ArraySetAsSeries(ma_l_reading,true); CopyBuffer(rsi_handle,0,0,fetch,rsi_reading); ArraySetAsSeries(rsi_reading,true); CopyBuffer(stoch_handle,0,0,fetch,sto_reading_main); ArraySetAsSeries(sto_reading_main,true); CopyBuffer(stoch_handle,0,0,fetch,sto_reading_signal); ArraySetAsSeries(sto_reading_signal,true); //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle, //--- Time "Time", //--- OHLC "Open", "High", "Low", "Close", //--- MA OHLC "MA O", "MA H", "MA L", "MA C", //--- RSI "RSI", //--- Stochastic Oscilator "Stoch Main", "Stoch Signal" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- MA OHLC ma_o_reading[i], ma_h_reading[i], ma_l_reading[i], ma_reading[i], //--- RSI rsi_reading[i], //--- Stochastic Oscilator sto_reading_main[i], sto_reading_signal[i] ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+ //+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef HORIZON #undef MA_PERIOD #undef MA_TYPE //+------------------------------------------------------------------+
Начинаем на Python
Как только данные получены, начинаем свой анализ на Python. Начинаем с импорта стандартных библиотек Python, используемых для чтения наших данных.#Import the standard libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns
Далее определим, насколько далеко в будущее мы хотим заглянуть в нашем прогнозе.
HORIZON = 10
Теперь давайте ознакомимся с данными.
data = pd.read_csv("../EURUSD Market Data As Series Indicators.csv")
Добавляем метки к набору данных. Как упоминалось в связанном обсуждении о взломе целевой функции, обозначение ваших данных как изменение переменной может привести к проблемам, поскольку лучшим прогнозом часто становится среднее изменение в обучающем наборе. Однако, как читатели увидят позже в этой статье, мы обнаружили, что изучение изменений в индикаторе Stochastic Main по-прежнему возможно и выгодно, несмотря на трудности, вызванные дифференцированием целевого показателя.
data['Price Target'] = data['Close'].shift(-HORIZON) - data['Close'] data['MA C Target'] = data['MA C'].shift(-HORIZON) - data['MA C'] data['Stoch Target'] = data['Stoch Main'].shift(-HORIZON) - data['Stoch Main'] data['RSI Target'] = data['RSI'].shift(-HORIZON) - data['RSI']
Чтобы задать эталонные метки, мы также размечаем целевые переменные в формате бинарной классификации. Сначала мы инициализируем все метки значением 0.
data['Price Target 2'] = 0 data['MA C Target 2'] = 0 data['Stoch Target 2'] = 0 data['RSI Target 2'] = 0
Затем присваиваем метку 1, если фактическое значение целевой переменной выросло.
data.loc[data['Close'].shift(-HORIZON) > data['Close'],'Price Target 2'] = 1 data.loc[data['MA C'].shift(-HORIZON) > data['MA C'],'MA C Target 2'] = 1 data.loc[data['Stoch Main'].shift(-HORIZON) > data['Stoch Main'],'Stoch Target 2'] = 1 data.loc[data['RSI'].shift(-HORIZON) > data['RSI'],'RSI Target 2'] = 1
Далее удаляем все временные периоды, которые перекрываются с запланированным периодом тестирования на исторических данных. Для этого обсуждения мы отбросим исторические данные за последние три года и сохраним их для оценки модели.
#Drop the last 3 years of historical data data = data.iloc[:-(365*3),:] test = data.iloc[-(365*3):,:]
Separate the inputs and outputs.
X = data.iloc[:,1:12] y = data.iloc[:,12:-4] y_classif = data.iloc[:,-4:] X_test = test.iloc[:,1:12] y_test = test.iloc[:,12:-4] y_classif_test = test.iloc[:,-4:]
Загружаем зависимости для машинного обучения.
import onnx from sklearn.linear_model import Ridge from sklearn.ensemble import AdaBoostClassifier from sklearn.neural_network import MLPRegressor from skl2onnx.convert import convert_sklearn from skl2onnx.common.data_types import FloatTensorType from sklearn.model_selection import RandomizedSearchCV,TimeSeriesSplit,cross_val_score from sklearn.metrics import root_mean_squared_error from sklearn.feature_selection import mutual_info_regression
Как и в большинстве наших обсуждений, посвященных тщательному моделированию, мы используем кросс-валидацию временных рядов для получения надежных результатов.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Определяем метод, возвращающий новый экземпляр идентичной модели.
def get_model(): return(Ridge(alpha=1e-3))
Обучаем модель для каждого доступного целевого значения.
#Control model model_a = get_model() #Close Moving Average model model_b = get_model() #Stoch model model_c = get_model() #RSI model model_d = get_model() model_a.fit(X,y.iloc[:,0]) model_b.fit(X,y.iloc[:,1]) model_c.fit(X,y.iloc[:,2]) model_d.fit(X,y.iloc[:,3])
Теперь давайте запишем прогнозы каждой модели на тестовом наборе, но не будем обучать модель с помощью тестовых данных!
preds_a = model_a.predict(X_test) preds_b = model_b.predict(X_test) preds_c = model_c.predict(X_test) preds_d = model_d.predict(X_test)
Начинаем с изучения эффективности модели, которая пыталась напрямую предсказать изменения цен. Для постоянных читателей то, что следует ниже, должно быть знакомо. По оси x отложены предсказанные моделью значения, а по оси y - частота этих предсказаний. Три пунктирные линии на графике представляют среднее целевое значение (центральная линия) и наиболее предельные значения, наблюдаемые в обучающем наборе (внешние линии). Красная линия показывает частоту реальных доходов в тестовом наборе, в то время как черная линия показывает предсказания модели. Как мы видим, модель группирует свои прогнозы вокруг среднего целевого значения, которому она обучилась в обучающем наборе, не в состоянии охватить весь спектр реальных рыночных движений.
Обратите внимание, что показатель MI приводится вместе со значением RMSE. В заголовке графика Ядерной оценки плотности (Kernel Density Estimate, KDE) показан только показатель MI. Ценовая модель достигла значения MI в 0,04233. Напомним, что показатели MI, близкие к 0, нежелательны — они указывают на то, что прогнозы модели не зависят от реальных рыночных обменных курсов.
score_1 = mutual_info_regression(y_test.iloc[:,[0]],preds_a) score_1_rmse = root_mean_squared_error(y_test.iloc[:,[0]],preds_a) s = 'Forecasting Price Directly Mutual Information: ' + str(score_1[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,0],color='red') sns.kdeplot(preds_a,color='black') plt.axvline(y.iloc[:,0].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,0].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,0].min(),color='black',linestyle=':') plt.legend(['Actual Exchange Rate','Forecasted Exchange Rate']) plt.grid()
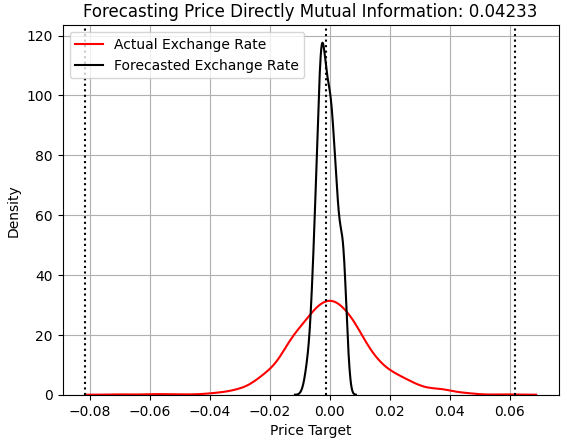
Рисунок 1: Визуализация прогнозов нашей модели в сравнении с реальными обменными курсами, наблюдаемыми вне выборки при прогнозировании цены
На диаграмме рассеяния проблема становится еще яснее. Прогнозы модели (выделены черным цветом) находятся посередине реальных обменных курсов (выделены красным цветом). Это вопрос взлома целевой функции, о котором мы говорили ранее. Традиционные “лучшие практики” благоприятствовали бы RMSE и, таким образом, поощряли бы использование этой модели в реальной торговле. Но, как мы увидим, MI быстро схватывает эту проблему и обеспечивает более надежный показатель оценки эффективности.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,0],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_a,color='black') plt.legend(['Actual Exchange Rate','Forecasted Exchange Rate']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Exchange Rate') plt.title(s) plt.grid()

Рисунок 2: Наша первая модель демонстрирует «привязывание» к среднему значению, что нежелательно
Давайте теперь рассмотрим работу статистической модели, которая учится ожидать изменений в индикаторе Close Moving Average. На всех наших графиках используется один и тот же стиль представления, поэтому мы можем быстро заметить, что эта модель по—прежнему не отражает разброс целевой переменной, хотя ее показатель MI увеличился более чем на 100%, с 0,04 до 0,1. Однако из графика KDE на рис. 3 не видно, почему показатель MI улучшился.
score_2 = mutual_info_regression(y_test.iloc[:,[1]],preds_b) score_2_rmse = root_mean_squared_error(y_test.iloc[:,[1]],preds_b) s = 'Forecasting Moving Average Directly Mutual Information: ' + str(score_2[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,1],color='red') sns.kdeplot(preds_b,color='black') plt.axvline(y.iloc[:,1].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,1].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,1].min(),color='black',linestyle=':') plt.legend(['Actual Moving Average','Forecasted Moving Average']) plt.grid()
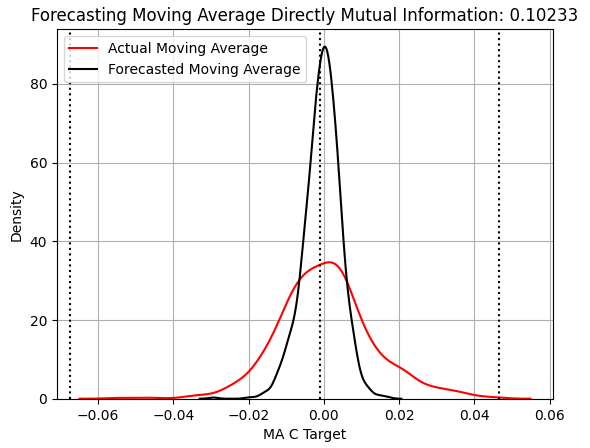
Рисунок 3: Визуализация нашей возможности прогнозировать изменения в индикаторе Close Moving Average
Улучшение становится очевидным, когда мы рассматриваем диаграмму рассеяния прогнозов модели, полученных вне выборки. То, что когда-то было тонкой черной линией, обозначающей наблюдаемые обменные курсы, теперь превратилось в более размытое распределение, демонстрирующее повышенную чувствительность к изменениям на рынке EURUSD. Эта модель по-прежнему неприемлема, но это шаг в правильном направлении.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,1],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_b,color='black') plt.legend(['Actual Moving Average','Forecasted Moving Average']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Moving Average') plt.title(s) plt.grid()
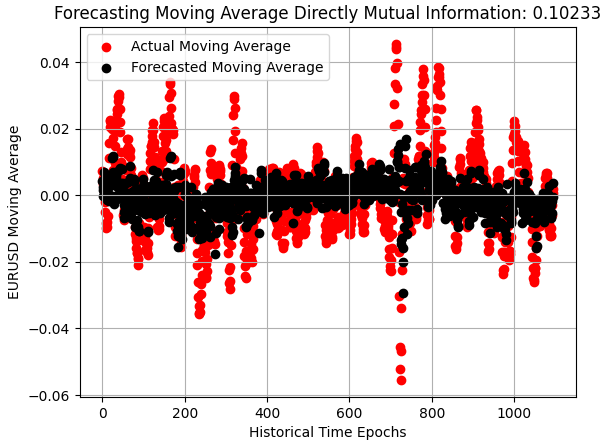
Рисунок 4: Наша модель существенно улучшилась и начинает учитывать волатильность рынка
При оценке модели, прогнозирующей индикатор Stochastic, мы видим существенные улучшения. Даже до рассмотрения резкого увеличения MI, мы видим, что наконец-то создали модель, которая не «привязывается» к среднему значению. Эта модель - единственная из рассмотренных нами, которая в разумных пределах напоминает распределение результатов тестовых наблюдений и лучше отражает масштаб рынка, чем предыдущие модели.
score_3 = mutual_info_regression(y_test.iloc[:,[2]],preds_c) score_3_rmse = root_mean_squared_error(y_test.iloc[:,[2]],preds_c) s = 'Forecasting EURUSD Stochastic Directly MI: ' + str(score_3[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,2],color='red') sns.kdeplot(preds_c,color='black') plt.axvline(y.iloc[:,2].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,2].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,2].min(),color='black',linestyle=':') plt.legend(['Actual Stochastic','Forecasted Stochastic']) plt.grid()
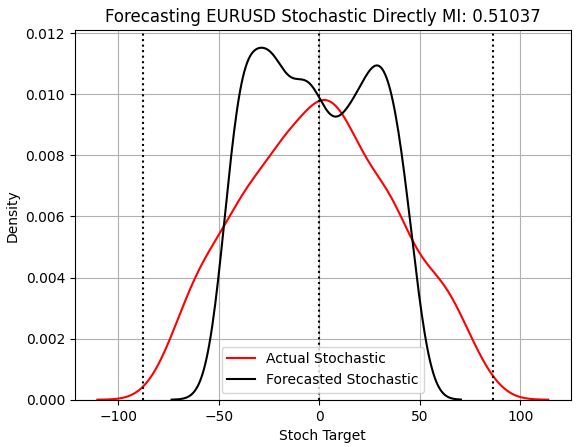
Рисунок 5: Наша модель наконец-то дает результаты, симметричные истинным наблюдениям, которые мы не учитывали при обучении
Кроме того, когда мы изучаем диаграмму рассеяния результатов, становится ясна причина резкого скачка MI. Стохастическая модель впечатляюще работает вне выборки и почти полностью отражает истинную волатильность рынка. Сравнивая эту диаграмму рассеяния с рисунком 1, становится очевидным, почему MI является хорошим кандидатом для автоматического выбора целевых показателей регрессии.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,2],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_c,color='black') plt.ylabel('Growth in The Stochastic Main Indicator') plt.xlabel('Historical Time Epochs') plt.title(s) plt.grid()

Рисунок 6: Визуализация нашей возможности отражать изменения в индикаторе Стохастический осциллятор (Stochastic Oscilator)
Далее мы рассмотрим прогнозирование RSI и связанных с ним изменений. К сожалению, как показано ниже, RSI так же сложно прогнозировать, как и индикаторы скользящей средней, и это приводит к снижению показателя MI до того уровня, на котором он был ранее. Модель также не отражает истинный разброс рынка, хотя изменения RSI в тестовом наборе естественным образом группируются вокруг 0. Однако модель переоценивает эту пропорцию, что потенциально может привести к неоптимальной эффективности.
score_4 = mutual_info_regression(y_test.iloc[:,[3]],preds_d) score_4_rmse = root_mean_squared_error(y_test.iloc[:,[3]],preds_d) s = 'Forecasting EURUSD RSI Directly MI: ' + str(score_4[0])[:7] plt.title(s) sns.kdeplot(y_test.iloc[:,3],color='red') sns.kdeplot(preds_d,color='black') plt.axvline(y.iloc[:,3].mean(),color='black',linestyle=':') plt.axvline(y.iloc[:,3].max(),color='black',linestyle=':') plt.axvline(y.iloc[:,3].min(),color='black',linestyle=':') plt.grid() plt.legend(['Actual RSI','Forecasted RSI'])
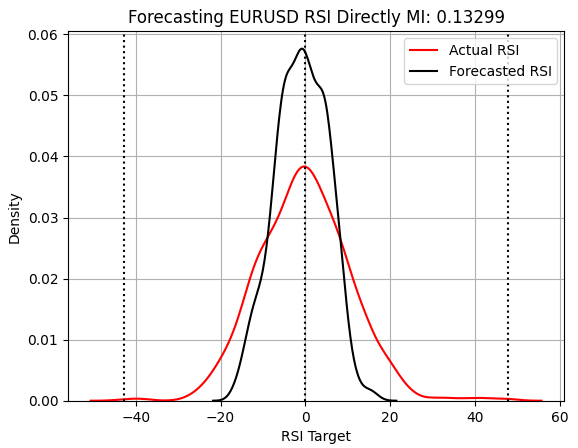
Рисунок 7: Наша стратегия RSI, по-видимому, переоценивает количество прогнозов, сгруппированных вокруг 0
Наконец, когда мы изучаем диаграмму рассеяния прогноза RSI, мы видим, что, хотя эта модель лучше, чем модель, «привязанная» к среднему значению, с которой мы начинали, - она не просто проходит по центру наблюдений — она все еще не отражает динамику рынка так же хорошо, как модель стохастического осциллятора.
plt.scatter(x=np.arange(y_test.shape[0]),y=y_test.iloc[:,3],color='red') plt.scatter(x=np.arange(y_test.shape[0]),y=preds_d,color='black') plt.legend(['Actual RSI','Forecasted RSI']) plt.xlabel('Historical Time Epochs') plt.ylabel('EURUSD Moving Average') plt.title('Visualizing Our Ability To Forecast Change in EURUSD Moving Average') plt.grid()
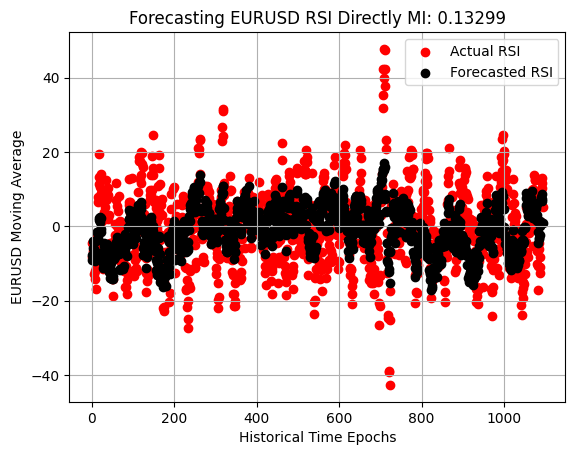
Рисунок 8: Наша стратегия показала лучшие результаты в обучении ожиданию изменений в RSI, чем непосредственно изменений в цене
Из всего, что мы видели, должно быть ясно, что модель, обучающаяся предсказывать изменения в стохастическом осцилляторе, работает лучше всего, даже вне выборки. Мы могли бы распознавать это визуально по диаграммам рассеяния. Теперь, после построения столбчатой диаграммы показателей MI для каждой цели, мы видим явного победителя. Однако читателю следует отметить, что мы подошли к сути проблемы, рассматриваемой в этой статье. Мы нанесли на график показатели MI для каждой модели, но также записали их показатели RMSE. Что происходит, когда мы вместо этого строим график RMSE?
mi_scores = [score_1,score_2,score_3,score_4] rmse_scores = [score_1_rmse,score_2_rmse,score_3_rmse,score_4_rmse] sns.barplot(mi_scores,color='black') plt.ylabel('Mutual Information Score') plt.xlabel('Target') plt.title('Mutual Information Score') plt.xticks([0,1,2,3],['Price','Moving Average','Stochastic','RSI'])
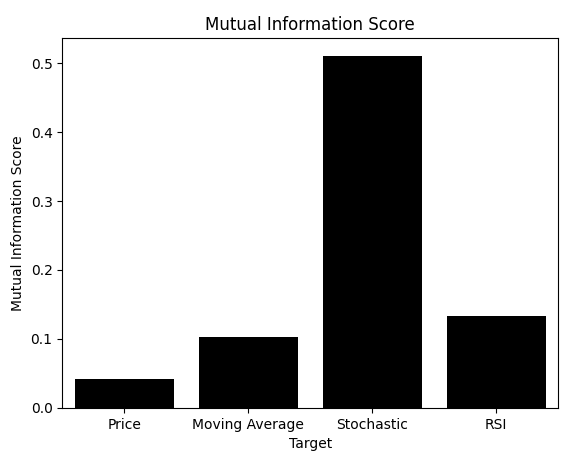
Рисунок 9: Взаимная информация корректно определяет подходящее целевое значение для моделирования, поскольку она не зависит от масштаба данных
Как показано, RMSE — показатель, на который полагаются многие практикующие специалисты, — рассказывает совершенно иную историю. Помните, что RMSE и MI интерпретируются по-разному. При использовании MI нам нужны модели, которые максимизируют показатель. С помощью RMSE мы хотим минимизировать показатель. К сожалению, RMSE привел бы нас к выбору модели Цены (Price) или скользящей средней (Moving Average), даже если бы мы визуально подтвердили, что они были неоптимальными.
Учитывая всю информацию, которую вы прочитали до сих пор, доверились бы вы RMSE или MI? Теперь некоторые читатели, возможно, ясно видят проблему. Но для тех, кто все еще не уверен, мы предлагаем еще один тест, который выявит слабость RMSE.
sns.barplot(rmse_scores,color='black') plt.xticks([0,1,2,3],['Price','Moving Average','Stochastic','RSI']) plt.title('RMSE Score ') plt.ylabel('Root Mean Squared Error') plt.xlabel('Target')
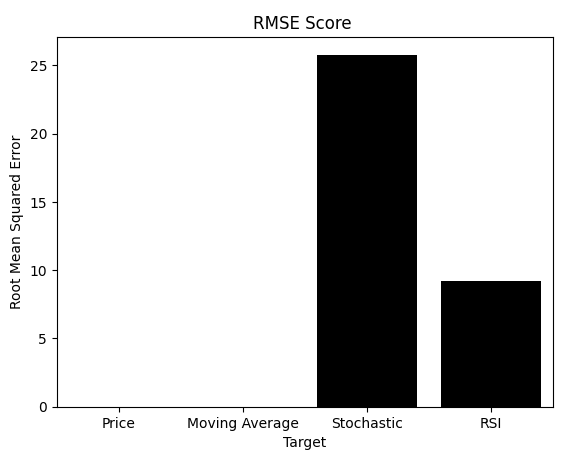
Рисунок 10: RMSE может неверно навести нас на мысль, что модель, изучающая стохастический осциллятор, работает плохо
Мы снова переопределяем метод для создания новой модели классификатора и сравниваем ее точность при классификации бинарных изменений в каждом целевом объекте. Как и прежде, мы создаем четыре идентичные копии одной и той же модели и измеряем точность кросс-валидации на обучающем наборе. Мы также отслеживали точность, которую могла бы получить каждая модель, просто предсказывая основной класс в своем обучающем наборе — еще одна форма взлома целевой функции, на которую стоит обратить внимание. Когда мы строим графики этих результатов, становится очевидной истина: стохастическая модель показывает наилучшие результаты, как это ясно показала ранее модель MI. Красная линия на графике показывает наивысшую точность, которую могла достичь любая модель с помощью взлома целевой функции, подтверждая, что эффективность работы стохастической модели действительно значима.
def get_model(): return(AdaBoostClassifier()) #Control model model_a = get_model() #Close Moving Average model model_b = get_model() #Stoch model model_c = get_model() #RSI model model_d = get_model() score = [] score.append(np.mean(cross_val_score(model_a,X,y_classif.iloc[:,0],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_b,X,y_classif.iloc[:,1],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_c,X,y_classif.iloc[:,2],cv=tscv,scoring='accuracy',n_jobs=-1))) score.append(np.mean(cross_val_score(model_d,X,y_classif.iloc[:,3],cv=tscv,scoring='accuracy',n_jobs=-1))) h1 = y_classif.loc[y_classif['Price Target 2'] == 1].shape[0] / y_classif.shape[0] h2 = y_classif.loc[y_classif['MA C Target 2'] == 1].shape[0] / y_classif.shape[0] h3 = y_classif.loc[y_classif['Stoch Target 2'] == 1].shape[0] / y_classif.shape[0] h4 = y_classif.loc[y_classif['RSI Target 2'] == 1].shape[0] / y_classif.shape[0] reward_hacking = [h1,h2,h3,h4] sns.barplot(score,color='black') plt.xticks([0,1,2,3],['Price','MA','Stochastic','RSI']) plt.ylabel('Accuracy Score 100%') plt.xlabel('Potential Target') plt.axhline(np.max(reward_hacking),color='red',linestyle=':') plt.title('Our Accuracy Changes Depending On The Target')
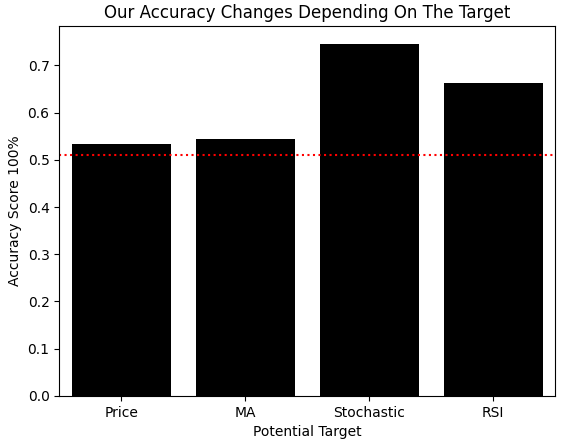
Рисунок 11: Даже если установить нашу проблему, как задачу классификации, мы придем к тому же выводу
Теперь, когда мы определили стратегию, которую наша модель "черного ящика" лучше всего усваивает, можно вывести торговые правила непосредственно из данных. Например, если прогнозируется рост стохастического осциллятора, следует ли нам открывать длинную или короткую позицию? Один из способов ответить на этот вопрос — изучить среднюю доходность по всем экземплярам, когда стохастический осциллятор имел значение 1. В нашем случае это среднее значение составило 0,0052, что говорит о том, что разумно открывать длинные позиции, когда ожидается рост осциллятора.
data.loc[data['Stoch Target 2']==1,'Price Target'].mean()
0.005242425488180883
Конечно, ни одна стратегия не идеальна — были экземпляры, когда цена падала, несмотря на положительную метку.
data.loc[data['Stoch Target 2']==1,'Price Target'].min()
-0.06370000000000009
Однако ценность этого упражнения заключается в том, что оно позволяет читателю оценить, соответствует ли стратегия его профилю рисков, используя данные, а не интуицию. Подсчитав, как часто цена и стохастический осциллятор двигались вместе, мы обнаружили, что в 71% случаев они совпадали. Этот априорный принцип еще больше укрепляет нашу уверенность в данной стратегии.
print('Price And The Stochastic Rise Together: ',((data.loc[(data['Stoch Target 2']==1 ) & (data['Price Target 2']==1),:].shape[0] / data.loc[data['Price Target 2'] == 1].shape[0])) * 100,'% of the time')
Price и Stochastic растут вместе: 70.94972067039106 % от времени
Если даже простые модели могут распознать, что стохастический осциллятор легче обучается, то более гибкая модель, такая как глубокая нейронная сеть, при правильной настройке должна еще лучше отражать эту взаимосвязь. Мы исследуем это, выполнив рандомизированный поиск по гиперпараметрам нейронной сети. Сначала перечислим все возможные входные значения для оценки.
dist = {
'max_iter':[10,50,100,500,1000,5000,10000,50000,100000],
'activation':['tanh','relu','identity','logistic'],
'alpha':[10e0,10e-1,10e-2,10e-3,10e-4,10-5,10e-6],
'solver':['lbfgs','adam','sgd'],
'learning_rate':['constant','invscaling','adaptive'],
'hidden_layer_sizes':[(11,1),(11,22,33,44,33,22,11,5),(11,4,40,20,2),(11,11),(11,11,11),(11,11,11,11),(11,22,33,44),(11,22,55,22,11),(11,100,11),(11,5,2,5,11),(11,3,9,18,9,3)]
} Затем определяем фиксированные константы, которые останутся неизменными в процессе обучения.
#Define the model model = MLPRegressor(shuffle=False,early_stopping=False,random_state=0,verbose=True) #Initialize the randomized search object rscv = RandomizedSearchCV(model,dist,random_state=0,n_iter=40,scoring='neg_mean_squared_error',cv=tscv,n_jobs=-1,refit=True) #Perform the search res = rscv.fit(X,y_classif['Stoch Target 2']) res.best_estimator_
После выбора наилучшей модели с помощью случайного поиска мы готовы экспортировать ее в формат ONNX (Open Neural Network Exchange). ONNX — это широко используемый открытый стандарт, который делает модели переносимыми и независимыми от фреймворков. Начинаем с определения ожидаемых моделью форм входных и выходных данных.
initial_types = [('float_input',FloatTensorType([1,X.shape[1]]))] final_types = [('float_output',FloatTensorType([1,1]))]
Далее преобразуем модель ONNX в ее прототипную форму, которая служит промежуточным представлением перед сохранением её на диск с помощью функции сохранения ONNX.
onnx_proto = convert_sklearn(model=res.best_estimator_,initial_types=initial_types,final_types=final_types,target_opset=12) onnx.save(onnx_proto,'Unsupervised Strategy Selection Stochastic MLP.onnx')
Создание нашего приложения на MQL5
Теперь, когда модель у нас готова, можем приступить к созданию своего торгового приложения. Начинаем с загрузки модели ONNX и указания системных констант для обеспечения согласованных расчетов индикаторов при извлечении данных и выборе стратегии.//+------------------------------------------------------------------+
//| Automatic Strategy Selection.mq5 |
//| Gamuchirai Ndawana |
//| https://www.mql5.com/ru/users/gamuchiraindawa |
//+------------------------------------------------------------------+
#property copyright "Gamuchirai Ndawana"
#property link "https://www.mql5.com/ru/users/gamuchiraindawa"
#property version "1.00"
//+------------------------------------------------------------------+
//| System resources |
//+------------------------------------------------------------------+
#resource "\\Files\\Unsupervised Strategy Selection Stochastic MLP.onnx" as const uchar onnx_buffer[]; Далее определяем системные константы, чтобы гарантировать, что расчет наших технических индикаторов будет согласован как со скриптом получения данных, так и с расчетами индикаторов из нашего предыдущего обсуждения автоматического выбора стратегии.
//+------------------------------------------------------------------+ //| System definiyions | //+------------------------------------------------------------------+ #define MA_PERIOD 5 //--- Moving Average Period #define MA_TYPE MODE_SMA //--- Type of moving average #define RSI_PERIOD 15 //--- RSI Period #define STOCH_K 5 //--- Stochastich K Period #define STOCH_D 3 //--- Stochastich D Period #define STOCH_SLOWING 3 //--- Stochastic slowing #define STOCH_MODE MODE_EMA //--- Stochastic mode #define STOCH_PRICE STO_LOWHIGH //--- Stochastic price feeds #define TOTAL_STRATEGIES 4 //--- Total strategies we have to choose from #define ONNX_INPUTS 11 //--- Total inputs needed by our ONNX model #define ONNX_OUTPUTS 1 //--- Total outputs needed by our ONNX modelНам также понадобится торговая библиотека, чтобы помочь нам управлять рыночным риском и позициями.
//+------------------------------------------------------------------+
//| System libraries |
//+------------------------------------------------------------------+
#include <Trade\Trade.mqh>
CTrade Trade; Для отслеживания времени, показаний индикаторов и прогнозов нашей модели потребуется несколько глобальных переменных.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ int ma_c_handle,ma_o_handle,ma_h_handle,ma_l_handle,rsi_handle,stoch_handle,atr_handle; double ma_c_reading[],ma_o_reading[],ma_h_reading[],ma_l_reading[],rsi_reading[],sto_reading_main[],sto_reading_signal[],atr_reading[]; long onnx_model; vectorf onnx_features,onnx_targets; MqlDateTime ts,tc; MqlTick current_tick;
Теперь мы можем инициализировать нашу ONNX-модель, создав ее из буфера ONNX с помощью метода OnnxCreateFromBuffer. Затем мы определяем и тестируем входные и выходные параметры и проводим окончательную проверку, чтобы убедиться в надежности модели. Если все тесты проходят успешно, мы инициализируем отслеживание времени и необходимые технические индикаторы.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the model's inputs and outputs onnx_features = vectorf::Zeros(ONNX_INPUTS); onnx_targets = vectorf::Zeros(ONNX_OUTPUTS); //--- Create the ONNX model onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DATA_TYPE_FLOAT); //--- Define the I/O shape ulong input_shape[] = {1,ONNX_INPUTS}; ulong output_shape[] = {ONNX_OUTPUTS,1}; if(!OnnxSetInputShape(onnx_model,0,input_shape)) { Print("Failed to define ONNX input shape"); return(INIT_FAILED); } if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { Print("Failed to define ONNX output shape"); return(INIT_FAILED); } //--- Check if the model is valid if(onnx_model == INVALID_HANDLE) { Print("Failed to create our ONNX model from buffer"); return(INIT_FAILED); } //--- Setup the time TimeLocal(tc); TimeLocal(ts); //---Setup our technical indicators ma_c_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_CLOSE); ma_o_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_OPEN); ma_h_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_HIGH); ma_l_handle = iMA(_Symbol,PERIOD_CURRENT,MA_PERIOD,0,MA_TYPE,PRICE_LOW); atr_handle = iATR(_Symbol,PERIOD_CURRENT,14); rsi_handle = iRSI(_Symbol,PERIOD_CURRENT,RSI_PERIOD,PRICE_CLOSE); stoch_handle = iStochastic(_Symbol,PERIOD_CURRENT,STOCH_K,STOCH_D,STOCH_SLOWING,STOCH_MODE,STOCH_PRICE); //--- return(INIT_SUCCEEDED); }
Если приложение больше не используется, мы освободим ресурсы, выделенные для модели ONNX и технических индикаторов.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(onnx_model); IndicatorRelease(ma_c_handle); IndicatorRelease(ma_o_handle); IndicatorRelease(ma_h_handle); IndicatorRelease(ma_l_handle); IndicatorRelease(rsi_handle); IndicatorRelease(stoch_handle); IndicatorRelease(atr_handle); }
При получении новых ценовых уровней мы сначала проверим, сформировалась ли новая дневная свеча, а затем обновим время и показания всех технических индикаторов. Затем каждый входной параметр модели преобразуется в число с плавающей запятой для обеспечения совместимости с моделью ONNX перед генерацией прогноза. Прогноз сравнивается с нашими условиями выхода на рынок для определения надлежащей позиции.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- TimeLocal(ts); if(ts.day != tc.day) { //--- Update the time TimeLocal(tc); //--- Update Our indicator readings CopyBuffer(ma_c_handle,0,0,1,ma_c_reading); CopyBuffer(ma_o_handle,0,0,1,ma_o_reading); CopyBuffer(ma_h_handle,0,0,1,ma_h_reading); CopyBuffer(ma_l_handle,0,0,1,ma_l_reading); CopyBuffer(rsi_handle,0,0,1,rsi_reading); CopyBuffer(stoch_handle,0,0,1,sto_reading_main); CopyBuffer(stoch_handle,0,0,1,sto_reading_signal); CopyBuffer(atr_handle,0,0,1,atr_reading); //--- Set our model inputs onnx_features[0] = (float) iOpen(Symbol(),PERIOD_CURRENT,0); onnx_features[1] = (float) iHigh(Symbol(),PERIOD_CURRENT,0); onnx_features[2] = (float) iLow(Symbol(),PERIOD_CURRENT,0); onnx_features[3] = (float) iClose(Symbol(),PERIOD_CURRENT,0); onnx_features[4] = (float) ma_o_reading[0]; onnx_features[5] = (float) ma_h_reading[0]; onnx_features[6] = (float) ma_l_reading[0]; onnx_features[7] = (float) ma_c_reading[0]; onnx_features[8] = (float) rsi_reading[0]; onnx_features[9] = (float) sto_reading_main[0]; onnx_features[10] = (float) sto_reading_signal[0]; //--- Copy Market Data double close = iClose(Symbol(),PERIOD_CURRENT,0); SymbolInfoTick(Symbol(),current_tick); //--- Place a position if(PositionsTotal() ==0) { if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_features,onnx_targets)) { Comment("Onnx Model Prediction: \n",onnx_targets); //--- Store our result if(LongConditions()) Buy(); else if(ShortConditions()) Sell(); } else { Print("No trading oppurtunities expected."); } } } } //+------------------------------------------------------------------+
Наши условия выхода на рынок определяются в собственных выделенных методах. Если прогноз ONNX превысит 0,5, ожидается рост уровня стохастического осциллятора. Если осциллятор находится выше 50 и продолжает расти, мы открываем длинную позицию. Либо, если осциллятор находится ниже классического уровня 30, мы также открываем длинные позиции. Наконец, если мы наблюдаем свечу бычьего поглощения, это наше последнее условие для открытия длинной позиции. Обратное остается справедливым для коротких позиций.
//+------------------------------------------------------------------+ //| The market conditions we require to open short positions | //+------------------------------------------------------------------+ bool ShortConditions(void) { return(((onnx_targets[0] < 0.5) && (sto_reading_main[0]<50)) || (sto_reading_main[0]<80) || (iHigh(Symbol(),PERIOD_CURRENT,1) > iHigh(Symbol(),PERIOD_CURRENT,2) && iLow(Symbol(),PERIOD_CURRENT,1) > iLow(Symbol(),PERIOD_CURRENT,2) && iOpen(Symbol(),PERIOD_CURRENT,1)<iOpen(Symbol(),PERIOD_CURRENT,2))); } //+------------------------------------------------------------------+ //| The market conditions we require to open long positions | //+------------------------------------------------------------------+ bool LongConditions(void) { return(((onnx_targets[0] > 0.5) && (sto_reading_main[0]>50)) || (sto_reading_main[0]>30) || (iHigh(Symbol(),PERIOD_CURRENT,1) > iHigh(Symbol(),PERIOD_CURRENT,2) && iLow(Symbol(),PERIOD_CURRENT,1) > iLow(Symbol(),PERIOD_CURRENT,2) && iOpen(Symbol(),PERIOD_CURRENT,1)>iOpen(Symbol(),PERIOD_CURRENT,2))); }
При размещении позиций, как длинных, так и коротких, мы будем использовать одинаковый размер лота для каждого входа и устанавливать равномерно расположенные уровни тейк-профита и стоп-лосса.
//+------------------------------------------------------------------+ //| Enter a long position | //+------------------------------------------------------------------+ void Buy(void) { Trade.Buy(0.01,Symbol(),current_tick.ask,current_tick.ask-(1.5*atr_reading[0]),current_tick.ask+(1.5*atr_reading[0])); } //+------------------------------------------------------------------+ //| Enter a short position | //+------------------------------------------------------------------+ void Sell(void) { Trade.Sell(0.01,Symbol(),current_tick.bid,current_tick.bid+(1.5*atr_reading[0]),current_tick.bid-(1.5*atr_reading[0])); } //+------------------------------------------------------------------+
В завершение снимаем определения всех системных констант.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef MA_PERIOD #undef MA_TYPE #undef RSI_PERIOD #undef STOCH_K #undef STOCH_D #undef STOCH_SLOWING #undef STOCH_MODE #undef STOCH_PRICE #undef TOTAL_STRATEGIES #undef ONNX_INPUTS #undef ONNX_OUTPUTS //+------------------------------------------------------------------+
Завершив настройку нашего приложения, мы теперь выберем период тестирования на истории, составляющий 3 года, который мы не учитывали для обучения нашей модели ранее в ходе обсуждения. Бэктест охватит период с января 2022 года до периода значительно позже января 2025 года.
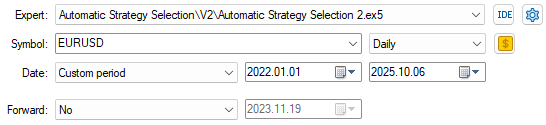
Рисунок 12: Выбор окна тестирования на истории для оценки нашей стратегии
Использование моделирования на основе реальных тиков с произвольными настройками задержки обеспечивает надежную имитацию реальных рыночных условий.
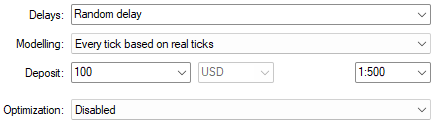
Рисунок 13: Выберем правильные условия для тестирования на истории, чтобы обучиться реалистичным ожиданиям
Кривая эквити, построенная с помощью нашего пересмотренного решения "черного ящика", показывает сильный восходящий тренд, демонстрирующий эффективность стратегии. Мы также наблюдаем периоды, когда стратегия испытывала сложности, но нас обнадеживает тот факт, что после каждого спада она с устойчивостью восстанавливалась.
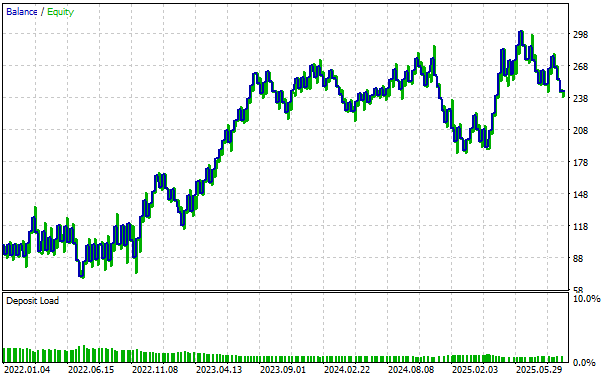
Рисунок 14: Визуализация кривой эквити, которую мы получили, следуя нашей тщательно пересмотренной торговой стратегии, дает нам уверенность в внесенных нами изменениях
Наконец, при анализе подробной статистики нашей стратегии, мы наблюдаем значительное улучшение по сравнению с нашей первой попыткой смоделировать все возможные стратегии. Наша стратегия была прибыльной, с сильным восстановлением и коэффициентом прибыли.
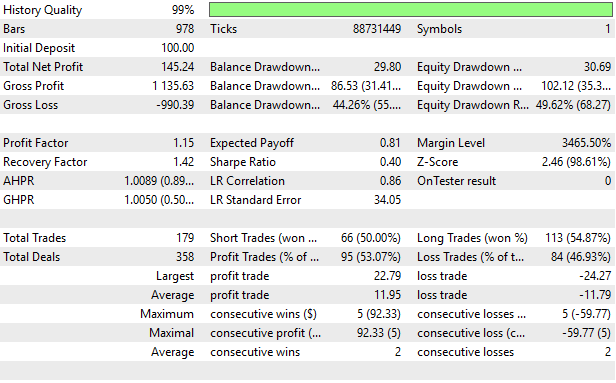
Рисунок 15: Визуализация подробных результатов, полученных с помощью улучшенного решения "черного ящика"
Заключение
Мы подошли к концу обсуждения. В этой статье читателю представлена подробная демонстрация способов настройки любого решения "черного ящика" для автоматического определения эффективных стратегий. В предыдущем обсуждении мы попытались смоделировать все возможные стратегии, а затем использовать сигналы только от той стратегии, которая, как ожидается, будет наиболее прибыльной, генерируя прибыль в размере 38,58 долларов во время проведения бэктеста. В этом обсуждении мы предложили, как можно использовать взаимную информацию для быстрого определения наилучшей стратегии для обучения нашего статистического оценщика, повысив уровень прибыли до 145,24 долларов за тот же период тестирования на истории. При этом все остальные переменные, такие как размер позиции и торговый объем, остаются неизменными.
Предложенное нами сегодня решение улучшило наш коэффициент Шарпа с 0,13 изначально до 0,4. Эта статья научила читателя, как тщательно настроить ваше решение "черного ящика", используя рассмотренные численные методы, и, самое главное, как избежать "слепых зон" традиционных "лучших практик", таких как чрезмерное полагание на RMSE для кросс-валидации регрессионных моделей и его тенденция поощрять «привязывание» к среднему значению в моделях.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/20317
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования