
Архитектура системы машинного обучения в MetaTrader 5 (Часть 2): Маркировка финансовых данных для машинного обучения

Оглавление
- Введение
- Обзор методов маркировки (разметки)
- Реализация: метод маркировки "Тройной барьер" (Triple-Barrier)
- Мета-маркировка на практике: стратегия на основе полос Боллинджера
- Заключение
Введение
Представьте себе: вы тренируетесь, чтобы стать снайпером элитного уровня. Что вы выберете — стрелять по идеальным кругам на бумажной мишени или тренироваться на мишенях в форме человеческого силуэта, имитирующих реальные боевые сценарии? Очевидно, что вам нужны мишени, отражающие реальность, с которой вы столкнетесь.
Тот же принцип применим и к машинному обучению в финансах. Большинство академических исследований используют так называемую "маркировку с фиксированным временным горизонтом" — аналог стрельбы по тем самым идеальным кругам. Этот подход задает простой вопрос: "Будет ли цена выше или ниже ровно через X дней?". Но в чем проблема: реальных трейдеров интересует не только то, где цена окажется в итоге. Их волнует сам путь — когда сработает стоп-лосс, когда следует зафиксировать прибыль и как цена движется на этом пути.
И снова добро пожаловать в нашу серию "MetaTrader 5 и Машинное Обучение: Практическое Руководство". В Части 1 мы разобрались с критической "ловушкой временных меток", которая незаметно разрушает большинство торговых алгоритмов. Теперь мы беремся за не менее важную задачу: как создавать метки (разметку), которые действительно отражают то, как вы торгуете в реальном мире.
Взгляните на это так: если вы создаете модель для прогнозирования сердечного приступа у человека, вы не будете смотреть только на то, жив он или умер ровно через 365 дней. Вы захотите знать о предупредительных признаках, ранних вмешательствах и последовательности событий, значимых для принятия медицинских решений. На финансовых рынках дела обстоят точно так же.
Эта статья предполагает, что вы уже умеете работать с Python и имеете базовое представление о концепциях машинного обучения. Мы глубоко погрузимся в практический код и реальные примеры применения, которые вы сможете использовать немедленно.
Краткое содержание Части 1: Утечка данных и исправление временных меток
В первой части серии мы рассмотрели критическую, но часто упускаемую из виду проблему, которая может незаметно подорвать работу моделей машинного обучения на финансовых рынках: "ловушку временных меток" и проблемы утечки данных, присущие структуре данных по умолчанию в MetaTrader 5. Мы заложили важнейший фундамент, занявшись целостностью данных и подчеркнув необходимость построения чистых, объективных баров из сырых тиковых данных. Эта основа является обязательным условием для разработки надежных моделей машинного обучения в финансах. Если вы еще не ознакомились с Частью 1, мы настоятельно рекомендуем сделать это перед продолжением.
Заложенный там фундамент обеспечивает:
- Целостность данных: Все временные метки отражают момент фактической доступности информации.
- Статистическую корректность: Бары, построенные на основе активности, обеспечивают лучшие статистические свойства для моделей машинного обучения.
- Соответствие реальности: Построение баров соответствует реальному потоку рыночной информации.
Устранив эти фундаментальные проблемы качества данных, мы теперь располагаем чистыми, объективными наборами данных, готовыми к следующему критическому этапу в нашем конвейере машинного обучения — методам маркировки (разметки), которые действительно отражают рыночную динамику.
Обзор методов маркировки (разметки)
Большинство моделей машинного обучения в финансах терпят неудачу по удивительно прозаической причине — не из-за плохих алгоритмов или недостаточной вычислительной мощности, а из-за ужасной разметки. Когда я начинал создавать торговые модели, я месяцами оптимизировал признаки и экспериментировал с различными архитектурами нейросетей, только чтобы обнаружить, что моя схема разметки была фундаментально ошибочной. По сути, я учил свою модель попадать в яблочко, когда на самом деле мне нужно было, чтобы она попадала в движущуюся мишень в условиях урагана.
Финансовые рынки неумолимо зашумлены. Каждый тик содержит некую смесь подлинной информации и случайного хаоса, и наша задача — извлечь сигнал, признавая при этом, что большинство ценовых движений — это просто участники рынка, меняющие свое мнение, или алгоритмы, реагирующие на микросекундные колебания. Хорошая разметка не просто говорит нам, что произошло — она помогает нам понять, что важно для принятия реальных торговых решений.
Самый простой подход, с которого большинство и начинает, — это маркировка с фиксированным временным горизонтом. Вы выбираете период, скажем, пять дней, и спрашиваете, будет ли цена выше или ниже в конце этого периода. Если акции Apple закрываются в понедельник на уровне $150, а к пятнице достигают $155, понедельник помечается как сигнал к покупке. Это чисто, интуитивно понятно и в корне неверно для того, как работает реальная торговля. Когда в последний раз вы покупали акцию, думая: "Я вернусь и проверю ровно через пять дней, что бы ни случилось"? Если акции во вторник упадут на 20%, вы не будете ждать до пятницы, чтобы переоценить ситуацию. Если они подскочат на 15% в среду, вы, возможно, немедленно зафиксируете прибыль.
Это подводит нас к методу тройных барьеров, который изменил подход серьезных практиков к финансовому ML. Вместо произвольных временных горизонтов вы устанавливаете три барьера вокруг каждой потенциальной сделки, точно так же, как это делает профессиональный трейдер. Есть ваша цель по прибыли — возможно, на 5% выше цены входа. Есть ваш стоп-лосс — скажем, на 3% ниже цены покупки. И есть временной лимит, потому что вы не хотите держать убыточные позиции вечно. Ваша метка зависит от того, какой барьер будет достигнут первым. Внезапно ваша модель учится не абстрактным движениям цены; она учится тому, достигнут ли конкретные торговые установки целей по прибыли раньше, чем сработают стоп-лоссы.
Красота этого подхода в том, что он отражает реальную торговую психологию. Реальных трейдеров не волнует, вырастут ли в итоге акции, если сначала они упадут достаточно, чтобы сработали их правила управления рисками. Путь так же важен, как и пункт назначения, и метод тройных барьеров естественным образом учитывает эту зависимость от пути. Вы даже можете сделать барьеры динамическими — более широкие стопы в периоды волатильности, более узкие, когда рынки спокойны.
Для рынков, где длина трендов сильно варьируется, методы сканирования тренда предлагают элегантное решение. Вместо навязывания фиксированных временных рамок эти алгоритмы тестируют множество будущих периодов и определяют наиболее статистически значимый тренд. Возможно, 5-дневный тренд слабый, 10-дневный — сильный, а 15-дневный — умеренный. Метод выбирает самый сильный сигнал и присваивает метку соответственно. Это похоже на то, как если бы алгоритм сам определял оптимальный горизонт прогнозирования для каждого состояния рынка.
Затем существует мета-маркировка, которая решает совершенно иную проблему. Вместо прогнозирования направления рынка она спрашивает: "Когда мне следует доверять моим другим прогнозам?". Представьте, что у вас уже есть торговая стратегия, генерирующая сигналы на покупку и продажу. Мета-маркировка строит вторую модель, которая оценивает, будет ли каждый сигнал, вероятно, прибыльным. Ваша основная стратегия может говорить "покупай", но мета-модель учитывает дополнительные факторы — недавнюю эффективность, рыночную волатильность, время с момента последнего крупного события в новостях — и выдает оценку уверенности. Высокая уверенность означает, что вы открываете позицию с большим объемом. Низкая уверенность означает, что вы пропускаете сделку или входите с малым объемом.
Этот подход признает важнейший факт: знание того, когда вы, вероятно, будете правы, часто ценнее, чем попытки быть правым чаще. Это разница между тем, чтобы быть хорошим прогнозистом, и тем, чтобы быть прибыльным трейдером. Многие стратегии терпят неудачу не потому, что их прогнозы направления плохи, а потому, что они ставят одинаковую сумму на сигналы с высокой и низкой уверенностью.
Каждый метод маркировки учит вашу модель разным вещам: Методы с фиксированным горизонтом фокусируются на чистом направлении цены. Метод тройных барьеров включает управление рисками и зависимость от пути. Сканирование тренда адаптируется к меняющимся рыночным условиям. Мета-маркировка оптимизирует уверенность и управление размером позиции. Выбранный вами метод фундаментально формирует то, чему учится ваша модель и как она ведет себя в реальной торговле.
Ключевые соображения при работе с финансовыми данными
- Избегайте ошибки ретроспективного взгляда (hindsight bias): Убедитесь, что ваши метки основаны только на информации, доступной на момент принятия решения. Например, при маркировке точки данных за "сегодня" вы можете использовать только информацию с "сегодня" или раньше для определения признаков и информацию из "будущего" (относительно "сегодня") для определения метки.
- Балансируйте классы: Если вы делаете разметку для классов "покупка", "продажа" и "удержание", вы можете обнаружить, что сигналы "удержание" (или небольшие движения) встречаются гораздо чаще. Сильно несбалансированные классы могут затруднить обучение модели для миноритарных классов. Существуют методы для решения этой проблемы (например, сверхдискретизация, недодискретизация или использование соответствующих метрик оценки).
- Волатильность — ключевой фактор: На финансовых рынках волатильность меняется. Движение цены в 2% может быть огромным на спокойном рынке, но незначительным в период волатильности. Подумайте об использовании порогов, скорректированных на волатильность, для ваших меток (как в методе тройных барьеров).
- Стационарность: Финансовые временные ряды часто нестационарны (их статистические свойства, такие как среднее значение и дисперсия, меняются со временем). Хотя сама по себе маркировка напрямую не делает данные стационарными, выбор метода маркировки (например, маркировка доходностей, которые часто более стационарны, чем цены) и последующая разработка признаков имеют решающее значение.
- Итерируйте и улучшайте: Ваш первый подход к маркировке может оказаться не лучшим. Будьте готовы экспериментировать с различными методами, горизонтами и пороговыми значениями, чтобы увидеть, что лучше всего работает для ваших конкретных целей и анализируемых активов.
Реализация: метод маркировки "Тройной барьер" (Triple-Barrier)
Установка динамических барьеров
Как утверждалось в предыдущем разделе, на практике мы хотим устанавливать лимиты для взятия прибыли и стоп-лосса, которые являются функцией рисков, связанных со сделкой. В противном случае, учитывая текущую волатильность, мы иногда будем целиться слишком высоко (𝜏 ≫ 𝜎ti,0), а иногда слишком низко (𝜏 ≪ 𝜎ti,0).
Приведенный ниже код рассчитывает дневную волатильность во внутридневных точках оценки, применяя экспоненциально взвешенное скользящее стандартное отклонение с определенным периодом ретроспективного анализа (lookback). Эта волатильность будет использоваться для установки барьеров взятия прибыли и стоп-лосса.
def get_daily_vol(close, lookback=100): """ Advances in Financial Machine Learning, Snippet 3.1, page 44. Daily Volatility Estimates Computes the daily volatility at intraday estimation points. Otherwise, sometimes we will be aiming too high (tao ≫ sigma_t_i,0), and sometimes too low (tao ≪ sigma_t_i,0), considering the prevailing volatility. Snippet 3.1 computes the daily volatility at intraday estimation points, applying a span of lookback days to an exponentially weighted moving standard deviation. Note: This function is used to compute dynamic thresholds for profit taking and stop loss limits. :param close: (pd.Series) Closing prices :param lookback: (int) Lookback period to compute volatility :return: (pd.Series) Daily volatility value """ # Find previous valid trading day for each date prev_idx = close.index.searchsorted(close.index - pd.Timedelta(days=1)) prev_idx = prev_idx[prev_idx > 0] # Drop indices before the start # Align current and previous closes curr_idx = close.index[close.shape[0] - prev_idx.shape[0] :] prev_close = close.iloc[prev_idx - 1].values # Previous day's close ret = close.loc[curr_idx] / prev_close - 1 vol = ret.ewm(span=lookback).std() return vol
Установка вертикальных барьеров (временных ограничений)
Для установки вертикальных барьеров мы используем следующую функцию. При использовании баров, построенных на основе активности (activity-driven bars), более осмысленно устанавливать барьеры, основываясь на количестве баров до истечения срока, а не на фиксированном временном периоде, поскольку в пределах временного горизонта может наблюдаться экстремальная изменчивость.
# Snippet 3.4 page 49, Adding a Vertical Barrier def add_vertical_barrier(t_events, close, num_bars=0, **time_delta_kwargs): """ Advances in Financial Machine Learning, Enhanced Implementation. Adding a Vertical Barrier For each event in t_events, finds the timestamp of the next price bar at or immediately after: - A fixed number of bars (for activity-based sampling), OR - A time delta (for time-based sampling) This function creates a series of vertical barrier timestamps aligned with the original events index. Out-of-bound barriers are marked with NaT for downstream handling. :param t_events: (pd.Series) Series of event timestamps (e.g., from symmetric CUSUM filter) :param close: (pd.Series) Close price series with DateTimeIndex :param num_bars: (int) Number of bars for vertical barrier (activity-based mode). Takes precedence over time delta parameters when > 0. :param time_delta_kwargs: Time components for time-based barrier (mutually exclusive with num_bars): :param days: (int) Number of days :param hours: (int) Number of hours :param minutes: (int) Number of minutes :param seconds: (int) Number of seconds :return: (pd.Series) Vertical barrier timestamps with same index as t_events. Out-of-bound events return pd.NaT. Example: # Activity-bar mode (tick/volume/dollar bars) vertical_barriers = add_vertical_barrier(t_events, close, num_bars=10) # Time-based mode vertical_barriers = add_vertical_barrier(t_events, close, days=1, hours=3) """ # Validate inputs if num_bars and time_delta_kwargs: raise ValueError("Use either num_bars OR time deltas, not both") # BAR-BASED VERTICAL BARRIERS if num_bars > 0: indices = close.index.get_indexer(t_events, method="nearest") t1 = [] for i in indices: if i == -1: # Event not found t1.append(pd.NaT) else: end_loc = i + num_bars t1.append(close.index[end_loc] if end_loc < len(close) else pd.NaT) return pd.Series(t1, index=t_events) # TIME-BASED VERTICAL BARRIERS td = pd.Timedelta(**time_delta_kwargs) if time_delta_kwargs else pd.Timedelta(0) barrier_times = t_events + td # Find next index positions t1_indices = np.searchsorted(close.index, barrier_times, side="left") t1 = [] for idx in t1_indices: if idx < len(close): t1.append(close.index[idx]) else: t1.append(pd.NaT) # Mark out-of-bound for downstream return pd.Series(t1, index=t_events)
Применение метода тройных барьеров
Метод тройных барьеров по своей сути зависит от пути (path-dependent), что означает, что мы не можем просто посмотреть на финальную цену, чтобы определить нашу метку. Вместо этого нам нужно отслеживать весь путь цены с момента входа в позицию до момента выхода, независимо от того, вызвано ли это достижением цели по прибыли, стоп-лосса или истечением временного лимита.
Когда мы применяем метод тройных барьеров, мы, по сути, спрашиваем: "Начиная с момента времени ti,0, что произойдет первым по мере движения вперед во времени?" Процесс продолжается до тех пор, пока мы не достигнем ti,1, которое представляет собой момент первого касания какого-либо барьера. Это может быть наша цель по прибыли, наш стоп-лосс или наш максимальный период удержания (вертикальный барьер, установленный на ti,0 + h). Доходность, которую мы используем для маркировки, рассчитывается от точки входа ti,0 до этого момента первого касания ti,1.
Функция apply_pt_sl_on_t1() реализует эту логику и требует для правильной работы нескольких входных данных. Во-первых, ей нужен ряд цен закрытия, чтобы можно было отслеживать фактическую траекторию цены. Датафрейм events содержит необходимую информацию для каждой потенциальной сделки: колонка t1 указывает, когда каждая сделка должна истечь (вертикальный барьер), а колонка trgt определяет, насколько широкими должны быть наши горизонтальные барьеры.
Параметр pt_sl особенно важен. Это список из двух элементов, который управляет шириной барьеров. Первый элемент (pt_sl[0]) устанавливает, сколько кратных целевой ширине (значению trgt) использовать для барьера взятия прибыли,в то время как второй элемент (pt_sl[1]) делает то же самое для барьера стоп-лосса. Если любое из значений равно нулю, соответствующий барьер отключается. Эта гибкость позволяет создавать асимметричные соотношения риска и прибыли. Например, вы можете установить жесткий стоп-лосс, но позволить прибыли расти дальше.
Функция систематически обрабатывает эти барьеры, отслеживая движения цены бар за баром до тех пор, пока один из барьеров не будет пробит, что дает нам точную информацию о времени и доходности, необходимую для точной маркировки.
# Snippet 3.2, page 45, Triple Barrier Labeling Method def apply_pt_sl_on_t1(close, events, pt_sl, molecule): """ Advances in Financial Machine Learning, Snippet 3.2, page 45. Triple Barrier Labeling Method This function applies the triple-barrier labeling method. It works on a set of datetime index values (molecule). This allows the program to parallelize the processing. Mainly it returns a DataFrame of timestamps regarding the time when the first barriers were reached. :param close: (pd.Series) Close prices :param events: (pd.Series) Indices that signify "events" (see cusum_filter function for more details) :param pt_sl: (np.array) Element 0, indicates the profit taking level; Element 1 is stop loss level :param molecule: (an array) A set of datetime index values for processing :return: (pd.DataFrame) Timestamps of when first barrier was touched """ # Apply stop loss/profit taking, if it takes place before t1 (end of event) events = events.loc[molecule].copy() out = events[["t1"]].copy(deep=True) profit_taking_multiple = pt_sl[0] stop_loss_multiple = pt_sl[1] # Profit taking active if profit_taking_multiple > 0: profit_taking = np.log(1 + profit_taking_multiple * events["trgt"]) else: profit_taking = pd.Series(index=events.index) # NaNs # Stop loss active if stop_loss_multiple > 0: stop_loss = np.log(1 - stop_loss_multiple * events["trgt"]) else: stop_loss = pd.Series(index=events.index) # NaNs # Use dictionary to collect barrier hit times barrier_dict = {"sl": {}, "pt": {}} # Get events for loc, vertical_barrier in events["t1"].fillna(close.index[-1]).items(): closing_prices = close[loc:vertical_barrier] # Path prices for a given trade cum_returns = np.log(closing_prices / close[loc]) * events.at[loc, "side"] # Path returns barrier_dict["sl"][loc] = cum_returns[ cum_returns < stop_loss[loc] ].index.min() # Earliest stop loss date barrier_dict["pt"][loc] = cum_returns[ cum_returns > profit_taking[loc] ].index.min() # Earliest profit taking date # Convert dictionary to DataFrame and join to `out` barrier_df = pd.DataFrame(barrier_dict) out = out.join(barrier_df) # Join on index (loc) return out
Метод тройных барьеров предлагает восемь возможных конфигураций, в зависимости от того, какие барьеры вы активируете. Думайте о каждом варианте как о комбинации [прибыль, стоп-лосс, время], где 1 означает активен, а 0 — отключен.
- Большинство практических торговых стратегий используют одну из трех конфигураций:
- [1,1,1] - Полная настройка: Активны все три барьера. Вы стремитесь к прибыли, управляя как риском падения, так и периодом удержания позиции. Это отражает то, как на самом деле работают большинство профессиональных трейдеров.
- [0,1,1] - Дать прибыли расти: Нет цели по прибыли, но вы выйдете через X периодов, если только не сработает стоп-лосс. Идеально подходит для моментум-стратегий, где вы хотите следовать за трендом.
- [1,1,0] - Без временного давления: Активны цель по прибыли и стоп-лосс, но нет временного лимита. Вы будете держать позицию, пока не будет достигнут один из ценовых барьеров, сколько бы времени это ни заняло.
- Три технически возможные, но менее реалистичные конфигурации:
- [0,0,1] - Фиксированный горизонт: Только выход по времени. По сути, это маркировка с фиксированным временным горизонтом, хотя это может работать с барами, построенными на основе активности.
- [1,0,1] - Игнорирование убытков: Держать до получения прибыли или истечения времени, независимо от промежуточных убытков. Опасно для управления рисками.
- [1,0,0] - Держать вечно: Нет стоп-лосса или временного лимита. Держать убыточные позиции, пока они в конце концов не станут прибыльными — рецепт разрушения портфеля.
- Две по сути бесполезные конфигурации:
- [0,1,0] - Ожидание неудачи: Держать позиции, пока они не достигнут стоп-лосса. Зачем входить в сделки, ожидая только убытков?
- [0,0,0] - Нет выхода: Все барьеры отключены. Позиции никогда не закрываются, и метки не генерируются.
Ниже представлены две возможные конфигурации метода тройных барьеров.
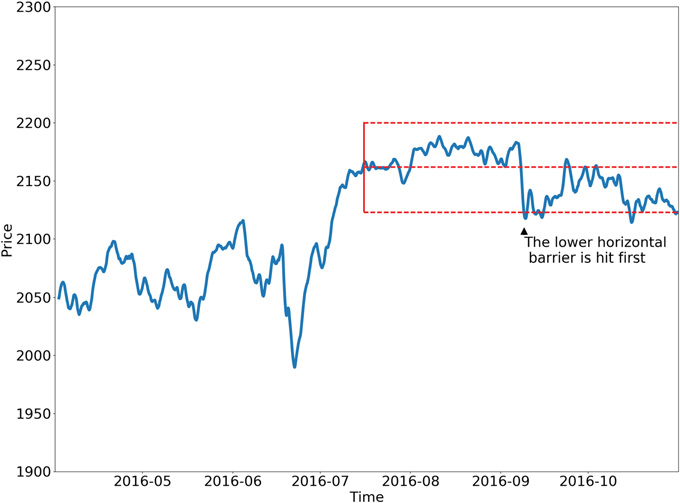
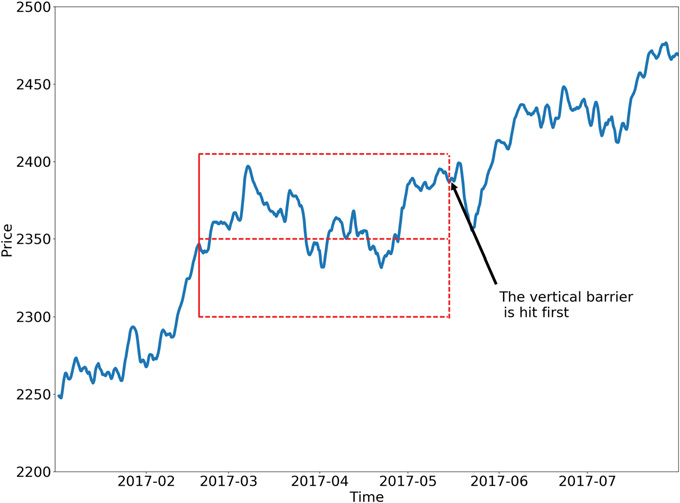
Обучение направлению и размеру (позиции)
Функции в этом разделе используют метод тройных барьеров либо для обучения направлению {1, 0, -1}, когда side_prediction=None в get_events(), либо для обучения размеру на основе данных мета-маркировки, когда направление известно. Обучение направлению сделки подразумевает, что либо горизонтальные барьеры отсутствуют, либо они симметричны. Это связано с тем, что на данном этапе мы не можем дифференцировать барьеры взятия прибыли и остановки убытков. Как только направление становится известно, мы можем оптимизировать барьеры, чтобы найти комбинацию, которая приводит к наиболее эффективной модели. Мы получаем даты первого касания барьера, запуская get_events().
# Snippet 3.3 -> 3.6 page 50, Getting the Time of the First Touch, with Meta Labels def get_events(close, t_events, pt_sl, target, min_ret, num_threads, vertical_barrier_times=False, side_prediction=None, verbose=True): """ Advances in Financial Machine Learning, Snippet 3.6 page 50. Getting the Time of the First Touch, with Meta Labels This function is orchestrator to meta-label the data, in conjunction with the Triple Barrier Method. :param close: (pd.Series) Close prices :param t_events: (pd.Series) of t_events. These are timestamps that will seed every triple barrier. These are the timestamps selected by the sampling procedures discussed in Chapter 2, Section 2.5. E.g.: CUSUM Filter :param pt_sl: (list) Element 0, indicates the profit taking level; Element 1 is stop loss level. A non-negative float that sets the width of the two barriers. A 0 value means that the respective horizontal barrier (profit taking and/or stop loss) will be disabled. :param target: (pd.Series) of values that are used (in conjunction with pt_sl) to determine the width of the barrier. In this program this is daily volatility series. :param min_ret: (float) The minimum target return required for running a triple barrier search. :param num_threads: (int) The number of threads concurrently used by the function. :param vertical_barrier_times: (pd.Series) A pandas series with the timestamps of the vertical barriers. We pass a False when we want to disable vertical barriers. :param side_prediction: (pd.Series) Side of the bet (long/short) as decided by the primary model :param verbose: (bool) Flag to report progress on asynch jobs :return: (pd.DataFrame) Events -events.index is event's starttime -events['t1'] is event's endtime -events['trgt'] is event's target -events['side'] (optional) implies the algo's position side -events['pt'] is profit taking multiple -events['sl'] is stop loss multiple """ # 1) Get target target = target.reindex(t_events) target = target[target > min_ret] # min_ret # 2) Get vertical barrier (max holding period) if vertical_barrier_times is False: vertical_barrier_times = pd.Series(pd.NaT, index=t_events, dtype=t_events.dtype) # 3) Form events object, apply stop loss on vertical barrier if side_prediction is None: side_ = pd.Series(1.0, index=target.index) pt_sl_ = [pt_sl[0], pt_sl[0]] else: side_ = side_prediction.reindex(target.index) # Subset side_prediction on target index. pt_sl_ = pt_sl[:2] # Create a new df with [v_barrier, target, side] and drop rows that are NA in target events = pd.concat({'t1': vertical_barrier_times, 'trgt': target, 'side': side_}, axis=1) events = events.dropna(subset=['trgt']) # Apply Triple Barrier first_touch_dates = mp_pandas_obj(func=apply_pt_sl_on_t1, pd_obj=('molecule', events.index), num_threads=num_threads, close=close, events=events, pt_sl=pt_sl_, verbose=verbose) for ind in events.index: events.at[ind, 't1'] = first_touch_dates.loc[ind, :].dropna().min() if side_prediction is None: events = events.drop('side', axis=1) # Add profit taking and stop loss multiples for vertical barrier calculations events['pt'] = pt_sl[0] events['sl'] = pt_sl[1] return events
Мы используем get_bins() для возврата датафрейма events, в котором:
- events.index— время начала события
- events['t1']— время окончания события
- events['trgt'] — целевой уровень события
- events['side'] (по желанию) — подразумевает направление позиции стратегии
- Случай 1: Если "side" отсутствует в events → bin∈ {-1, 1} (маркировка на основе движения цены)
- Случай 2: Если "side" присутствует → bin ∈ {0, 1} (маркировка на основе прибыли/убытка — мета-маркировка)
# Snippet 3.4 -> 3.7, page 51, Labeling for Side & Size with Meta Labels def get_bins(triple_barrier_events, close, vertical_barrier_zero=False, pt_sl=[1, 1]): """ Advances in Financial Machine Learning, Snippet 3.7, page 51. Labeling for Side & Size with Meta Labels Compute event's outcome (including side information, if provided). events is a DataFrame where: Now the possible values for labels in out['bin'] are {0,1}, as opposed to whether to take the bet or pass, a purely binary prediction. When the predicted label the previous feasible values {−1,0,1}. The ML algorithm will be trained to decide is 1, we can use the probability of this secondary prediction to derive the size of the bet, where the side (sign) of the position has been set by the primary model. :param triple_barrier_events: (pd.DataFrame) Events DataFrame with the following structure: - **index**: pd.DatetimeIndex of event start times - **t1**: (pd.Series) Event end times - **trgt**: (pd.Series) Target returns - **side**: (pd.Series, optional) Algo's position side Labeling behavior depends on the presence of 'side': - Case 1: If 'side' not in events → `bin ∈ {-1, 1}` (label by price action) - Case 2: If 'side' is present → `bin ∈ {0, 1}` (label by PnL — meta-labeling) :param close: (pd.Series) Close prices :param vertical_barrier_zero: (bool) If True, set bin to 0 for events that touch vertical barrier, else bin is the sign of the return. :param pt_sl: (list) Take-profit and stop-loss multiples :return: (pd.DataFrame) Meta-labeled events :returns index: Event start times :returns t1: Event end times :returns trgt: Target returns :returns side: Optional. Algo's position side :returns ret: Returns of the event :returns bin: Labels for the event, where 1 is a positive return, -1 is a negative return, and 0 is a vertical barrier hit """ # 1. Align prices with their respective events events = triple_barrier_events.dropna(subset=["t1"]) all_dates = events.index.union(other=events["t1"].array).drop_duplicates() prices = close.reindex(all_dates, method="bfill") # 2. Create out DataFrame out_df = events[["t1"]].copy() out_df["ret"] = np.log(prices.loc[events["t1"].array].array / prices.loc[events.index]) out_df["trgt"] = events["trgt"] # Meta labeling: Events that were correct will have pos returns if "side" in events: out_df["ret"] *= events["side"] # meta-labeling if vertical_barrier_zero: # Label 0 when vertical barrier reached out_df["bin"] = barrier_touched( out_df["ret"].values, out_df["trgt"].values, np.array(pt_sl, dtype=float), ) else: # Label is the sign of the return out_df["bin"] = np.where(out_df["ret"] > 0, 1, -1).astype("int8") # Meta labeling: label incorrect events with a 0 if "side" in events: out_df.loc[out_df["ret"] <= 0, "bin"] = 0 # Add the side to the output. This is useful for when a meta label model must be fit if "side" in triple_barrier_events.columns: out_df["side"] = triple_barrier_events["side"].astype("int8") out_df["ret"] = np.exp(out_df["ret"]) - 1 # Convert log returns to simple returns return out_df
NOTE: mp_pandas_obj() использованная выше, — это вспомогательная функция, которая обеспечивает параллельную обработку при работе с объектами pandas (так как pandas по умолчанию выполняет вычисления только на одном ядре процессора). Файл multiprocess.py содержит эту функцию, а также другие вспомогательные инструменты для многопроцессорной обработки.
Чтобы установить метку в ноль при касании вертикального барьера, мы вызываем barrier_touched() inget_bins().
# Snippet 3.9, page 55, Question 3.3 def barrier_touched(ret, target, pt_sl): """ Advances in Financial Machine Learning, Snippet 3.9, page 55, Question 3.3. Adjust the getBins function (Snippet 3.7) to return a 0 whenever the vertical barrier is the one touched first. Top horizontal barrier: 1 Bottom horizontal barrier: -1 Vertical barrier: 0 :param ret: (np.array) Log-returns :param target: (np.array) Volatility target :param pt_sl: (ArrayLike) Take-profit and stop-loss multiples :return: (np.array) Labels """ N = ret.shape[0] # Number of events store = np.empty(N, dtype=np.int8) # Store labels in an array profit_taking_multiple = pt_sl[0] stop_loss_multiple = pt_sl[1] # Iterate through the DataFrame and check if the vertical barrier was reached for i in range(N): pt_level_reached = ret[i] > np.log(1 + profit_taking_multiple * target[i]) sl_level_reached = ret[i] < np.log(1 - stop_loss_multiple * target[i]) if ret[i] > 0.0 and pt_level_reached: # Top barrier reached store[i] = 1 elif ret[i] < 0.0 and sl_level_reached: # Bottom barrier reached store[i] = -1 else: # Vertical barrier reached store[i] = 0 return store
Когда маркировать как ноль, а когда как знак доходности
Маркировка события, не затронувшего барьеры, как нуля имеет смысл, когда вы хотите, чтобы ваша модель фокусировалась строго на четких исходах с управляемым риском.В то время как использование знака доходности на горизонте учитывает все направленные движения, даже если ваши рисковые пороги не были достигнуты.
Маркируйте как ноль, если:
- Вы строите трехклассовый классификатор (вверх, вниз, нейтрально) и хотите, чтобы "нейтрально" означало "отсутствие решительного движения" в рамках ваших риск-лимитов.
- Вы предпочитаете отфильтровывать неоднозначные сигналы — небольшие движения, которые так и не коснулись ни одного из барьеров, — из обучающего процесса.
- Вы хотите измерять успех события исключительно по достижению заданных порогов прибыли или убытка, игнорируя все остальные случаи.
Маркируйте как знак доходности, если:
- Вам нужно, чтобы каждый пример содержал бинарное направление (вверх/вниз) для двухклассовой задачи, и вы хотите избежать чрезмерного количества нейтральных меток.
- Вы моделируете моментум или доходность за временной горизонт, а не исходы, строго контролируемые риском.
- Вы считаете, что движение цены — каким бы малым оно ни было — является информативным и должно влиять на ваш оценщик (модель).
Помимо этого выбора, учитывайте, как он влияет на баланс классов и зашумленность меток. Если вы видите слишком много нулей, вы можете применить недоотбор (undersampling) нейтральных примеров или поднять ваши горизонтальные барьеры. А если ваши метки "знака доходности" слишком зашумлены, вы можете применить минимальный порог доходности перед присвоением меток +1/−1.
Событийная Выборка (Сэмплирование на Основе Событий)
Трейдеры не просто принимают случайные решения о том, когда покупать или продавать ценные бумаги. Вместо этого они ждут наступления определенных событий на рынке, прежде чем совершать действия. Эти "триггерные события" могут включать:
- Публикацию важных экономических данных (например, данных по занятости или отчетов об инфляции)
- Моменты, когда рыночные цены внезапно становятся крайне нестабильными
- Ситуации, когда ценовая разница между связанными инструментами значительно отклоняется от своей обычной нормы
Когда происходит одно из таких событий, это рассматривается как сигнал о том, что на рынке может происходить нечто важное. Затем мы можем позволить нашим алгоритмам машинного обучения (МО) выяснить, существует ли в этих обстоятельствах точная прогностическая функция.
Ключевая идея заключается в том, что можно ли в этих условиях построить точную прогнозную модель рыночных движений именно тогда, когда эти события происходят. Если алгоритм показывает, что конкретный тип события не приводит к точным прогнозам, то нам нужно либо изменить определение того, что считается значимым событием, либо повторить попытку, используя другие характеристики (признаки) в качестве входных данных для модели.
CUSUM-фильтр
Мощным методом для событийной выборки является CUSUM-фильтр — метод контроля качества, используемый для обнаружения сдвигов в среднем значении измеряемой величины. В финансах мы можем адаптировать этот фильтр для отбора точек данных всякий раз, когда происходит значительное отклонение рыночной переменной, например цены. CUSUM-фильтр работает путем накопления отклонений от ожидаемого значения и генерации события выборки, когда это накопление превышает определенный порог.
Симметричный CUSUM-фильтр определяется следующим образом:
-
S⁺ = max(0, S⁺ + ΔP)
-
S⁻ = min(0, S⁻ + ΔP)
Где ΔP — это изменение цены. Событие генерируется, когда либо S⁺ превышает положительный порог h, либо S опускается ниже отрицательного порога -h. Когда событие генерируется, соответствующий накопитель (аккумулятор) сбрасывается. Этот метод позволяет избежать множественных срабатываний, когда цена колеблется около порога, — недостатка, распространенного в таких популярных рыночных индикаторах, как полосы Боллинджера. Используя CUSUM-фильтр, мы можем создать матрицу признаков X, которая дискретизируется в моменты значительной рыночной активности, предоставляя более релевантные данные для наших моделей машинного обучения.
# Snippet 2.4, page 39, The Symmetric CUSUM Filter. def cusum_filter(raw_time_series, threshold, time_stamps=True): """ Advances in Financial Machine Learning, Snippet 2.4, page 39. The Symmetric Dynamic/Fixed CUSUM Filter. The CUSUM filter is a quality-control method, designed to detect a shift in the mean value of a measured quantity away from a target value. The filter is set up to identify a sequence of upside or downside divergences from any reset level zero. We sample a bar t if and only if S_t >= threshold, at which point S_t is reset to 0. One practical aspect that makes CUSUM filters appealing is that multiple events are not triggered by raw_time_series hovering around a threshold level, which is a flaw suffered by popular market signals such as Bollinger Bands. It will require a full run of length threshold for raw_time_series to trigger an event. Once we have obtained this subset of event-driven bars, we will let the ML algorithm determine whether the occurrence of such events constitutes actionable intelligence. Below is an implementation of the Symmetric CUSUM filter. Note: As per the book this filter is applied to closing prices but we extended it to also work on other time series such as volatility. :param raw_time_series: (pd.Series) Close prices (or other time series, e.g. volatility). :param threshold: (float or pd.Series) When the abs(change) is larger than the threshold, the function captures it as an event, can be dynamic if threshold is pd.Series :param time_stamps: (bool) Default is to return a DateTimeIndex, change to false to have it return a list. :return: (datetime index vector) Vector of datetimes when the events occurred. This is used later to sample. """ t_events = [] s_pos = 0 s_neg = 0 # log returns raw_time_series = pd.DataFrame(raw_time_series) # Convert to DataFrame raw_time_series.columns = ['price'] raw_time_series['log_ret'] = raw_time_series.price.apply(np.log).diff() if isinstance(threshold, (float, int)): raw_time_series['threshold'] = threshold elif isinstance(threshold, pd.Series): raw_time_series.loc[threshold.index, 'threshold'] = threshold else: raise ValueError('threshold is neither float nor pd.Series!') raw_time_series = raw_time_series.iloc[1:] # Drop first na values # Get event time stamps for the entire series for tup in raw_time_series.itertuples(): thresh = tup.threshold pos = float(s_pos + tup.log_ret) neg = float(s_neg + tup.log_ret) s_pos = max(0.0, pos) s_neg = min(0.0, neg) if s_neg < -thresh: s_neg = 0 t_events.append(tup.Index) elif s_pos > thresh: s_pos = 0 t_events.append(tup.Index) # Return DatetimeIndex or list if time_stamps: event_timestamps = pd.DatetimeIndex(t_events) return event_timestamps return t_events
Давайте проанализируем, как работает средне-возвратная (mean-reverting) стратегия на основе полос Боллинджера при использовании нефильтрованных сигналов входа по сравнению с сигналами, отфильтрованными с помощью CUSUM-фильтра. Для обучения и валидации мы будем использовать 5-минутные тайм-бары по паре EURUSD за период с 2018-01-01 по 2021-12-31, а для вневыборочного тестирования — данные с 2022-01-01 по 2024-12-31.
Для целей данной демонстрации мы намеренно используем чувствительную конфигурацию полос Боллинджера (период 20, 1.5 стандартных отклонения) чтобы сгенерировать большой объем торговых сигналов для оценки мета-моделью. Хотя такая конфигурация была бы слишком зашумленной для самостоятельной стратегии, она создает идеальные условия для стресс-тестирования нашего пайплайна маркировки и фильтрации.
Для обеспечения согласованности и совместимости между всеми стратегиями я предпочитаю структурировать их, используя объектно-ориентированный дизайн Python — в частности, через общий интерфейс или базовый класс. Такой подход позволяет каждой стратегии предоставлять одни и те же основные функции (например, генерацию сигналов, фильтрацию событий), что упрощает их сравнение, расширение и интеграцию в более широкие рабочие процессы. Использование TA-Lib и Pandas TA для генерации часто используемых сигналов является полезным, поскольку эти библиотеки реализуют отраслевые стандартные формулы, построены на высокооптимизированном бэкенде на C, что делает их в 2–4 раза быстрее эквивалентных реализаций на чистом Python. Кроме того, они гарантируют стандартизированный вывод и согласованную обработку краевых случаев, что упрощает последующие задачи, такие как маркировка, фильтрация или визуализация. Эта библиотека иногда может быть сложна в установке, поэтому я рекомендую следовать инструкциям в этой статье.
import pandas as pd from typing import Tuple, Union import logging from abc import ABC, abstractmethod from typing import Dict, Tuple, Union import numpy as np import pandas as pd import talib from loguru import logger class BaseStrategy(ABC): """Abstract base class for trading strategies""" @abstractmethod def generate_signals(self, data: pd.DataFrame) -> pd.Series: """Generate trading signals (1 for long, -1 for short, 0 for no position)""" pass @abstractmethod def get_strategy_name(self) -> str: """Return strategy name""" pass @abstractmethod def get_objective(self) -> str: """Return strategy objective""" pass class BollingerMeanReversionStrategy(BaseStrategy): """Bollinger Bands mean reversion strategy""" def __init__(self, window: int = 20, num_std: float = 2.0, objective: str = "mean_reversion"): self.window = window self.num_std = num_std self.objective = objective def generate_signals(self, data: pd.DataFrame) -> pd.Series: """Generate mean-reversion signals using Bollinger Bands""" close = data["close"] # Calculate Bollinger Bands upper_band, _, lower_band = talib.BBANDS( close, timeperiod=self.window, nbdevup=self.num_std, nbdevdn=self.num_std ) # Generate signals signals = pd.Series(0, index=data.index, dtype="int8", name="side") signals[(close >= upper_band)] = -1 # Sell signal (mean reversion) signals[(close <= lower_band)] = 1 # Buy signal (mean reversion) return signals def get_strategy_name(self) -> str: return f"Bollinger_w{self.window}_std{self.num_std}" def get_objective(self) -> str: return self.objective def get_entries( strategy: 'BaseStrategy', data: pd.DataFrame, filter_events: bool = False, filter_threshold: Union[float, pd.Series] = None, on_crossover: bool = True, ) -> Tuple[pd.Series, pd.DatetimeIndex]: """Get timestamps and position information for entry events. This function processes signals from a given `BaseStrategy` to identify trade entry points. It can apply a CUSUM filter to isolate significant events or, by default, detect entries at signal crossover points. Args: strategy (BaseStrategy): The trading strategy object that generates the primary signals. data (pd.DataFrame): A pandas DataFrame containing the input data, expected to have a 'close' column if `filter_events` is True. filter_events (bool, optional): If True, a CUSUM filter is applied to the signals to identify significant events. Defaults to False. filter_threshold (Union[float, pd.Series], optional): The threshold for the CUSUM filter. Must be a float or a pandas Series. Defaults to None. on_crossover (bool, optional): If True, only events where the signal changes from the previous period are considered entry points. Defaults to True. Raises: ValueError: If `filter_events` is True and `filter_threshold` is not a `float` or `pd.Series`. Returns: Tuple[pd.Series, pd.DatetimeIndex]: A tuple containing: side (pd.Series): A Series with the same index as the input data, where each value represents the trading position (-1 for short, 1 for long, 0 for no position). t_events (pd.DatetimeIndex): A DatetimeIndex of the timestamps for each detected entry event. """ primary_signals = strategy.generate_signals(data) signal_mask = primary_signals != 0 # Vectorized CUSUM filter application if filter_events: try: close = data.close except AttributeError as e: logger.error(f"Dataframe must have a 'close' column: {e}") raise e if not isinstance(filter_threshold, (pd.Series, float)): raise ValueError("filter_threshold must be a Series or a float") elif isinstance(filter_threshold, pd.Series): filter_threshold = filter_threshold.copy().dropna() close = close.reindex(filter_threshold.index) # Assuming cusum_filter is a function that takes a Series and a threshold filtered_events = cusum_filter(close, filter_threshold) signal_mask &= primary_signals.index.isin(filtered_events) else: # Vectorized signal change detection if on_crossover: signal_mask &= primary_signals != primary_signals.shift() t_events = primary_signals.index[signal_mask] side = pd.Series(index=data.index, name="side") side.loc[t_events] = primary_signals.loc[t_events] side = side.ffill().fillna(0).astype("int8") if filter_events: s = " generated by CUSUM filter" elif on_crossover: s = " generated by crossover" else: s = "" logger.info(f"Generated {len(t_events):,} trade events{s}.") return side, t_events
Разработка признаков для мета-маркировки (Meta-Labeling)
Чтобы уловить нюансированную динамику финансовых временных рядов, мы сконструировали богатый набор признаков, сочетающий статистическую строгость с предметными знаниями в области финансов. Этот набор включает в себя скорректированные на волатильность индикаторы моментума, структуры автокорреляции и моменты высших порядков доходности (асимметрию и эксцесс), наряду с метриками на основе полос Боллинджера и нормированными разностями скользящих средних. Технические сигналы, такие как RSI, MACD, ADX и ATR, были извлечены с использованием библиотек TA-Lib и pandas-ta, что обеспечивает согласованность и воспроизводимость результатов. Включая как краткосрочные, так и долгосрочные признаки — от лаговых доходностей и оценок волатильности Янга-Чжана до трендследящих индикаторов — модель получает возможность обнаруживать тонкие изменения в рыночном поведении и адаптироваться к меняющимся условиям торговли. Код можно найти в приложенном файле features.py.
Чтобы проиллюстрировать эффективность CUSUM-фильтра, я обучил модель случайного леса (Random Forest), используя нефильтрованные и отфильтрованные сигналы на наших 5-минутных данных по EURUSD. Мои горизонтальные барьеры были установлены с использованием экспоненциально взвешенной дневной волатильности за 100 дней в качестве целевого показателя, при этом барьер взятия прибыли (take-profit) был установлен на 1, а барьер стоп-лосса (stop-loss) — на 2. Мой вертикальный барьер (максимальное время удержания позиции) был установлен на 50 баров.
target = get_daily_vol(close, lookback=100)
cusum_filter_threshold = target.mean()
Влияние фильтрации данных
Прежде чем погрузиться в сравнение моделей, давайте кратко разберем ключевые метрики, представленные в каждой таблице классификации:- Точность (Precision): Процент правильных положительных прогнозов от общего количества выданных положительных сигналов. Высокая точность означает малое количество ложных срабатываний.
- Полнота (Recall): Процент фактически положительных случаев, которые были правильно идентифицированы. Высокая полнота означает, что пропущено мало событий.
- F1-мера:Точность (Accuracy) может быть неадекватной метрикой для оценки в задачах мета-маркировки (meta-labeling). Предположим, что после применения мета-маркировки отрицательных случаев (метка '0') стало намного больше, чем положительных (метка '1'). В таком сценарии классификатор, который предсказывает каждый случай как отрицательный, достигнет высокой точности (Accuracy), хотя полнота (Recall) будет равна 0, а точность (Precision) будет не определена. F1-мера исправляет этот недостаток, оценивая классификатор через (равновзвешенное) среднее гармоническое точности и полноты.
- Поддержка (Support): Количество экземпляров для каждого класса в валидационном наборе.
- Точность (Accuracy): Общая доля правильных прогнозов по всем классам.
Для подробного разбора этих метрик смотрите статью "Как интерпретировать отчет по классификации в sklearn".
Прежде чем мы сравним какие-либо показатели, обратите внимание на то, как CUSUM-фильтр сокращает объем выборки на 76.1%.
| Нефильтрованные сигналы | Фильтрованные сигналы | Сокращение, % |
|---|---|---|
| 32828 | 7825 | 76.1 |
ТАБЛИЦА 0: Количество сигналов - Фильтрованные против нефильтрованных
CUSUM-фильтр направлен на отсеивание "шума", который неразрывно связан с динамикой класса 0 (нейтральные события). Идеальный результат — это улучшение F1-меры для класса 1 (лучшее выявление значимых событий) при сохранении F1-меры для класса 0 (отсутствие ложных сигналов). Наша фильтрованная первичная модель показывает идеальный результат, однако фильтрованная мета-модель (meta-model) демонстрирует снижение F1-меры для класса 0 на 5.8%. Чтобы смягчить этот эффект, можно настраивать гиперпараметры модели или изменить набор признаков.
| Метрика | Нефильтрованная | Фильтрованная | Δ |
|---|---|---|---|
| Полнота (Recall) (1) | 1.00 | 1.00 | 0% |
| Точность (Precision) (1) | 0.33 | 0.38 | +15.2% |
| F1 (1) | 0.49 | 0.55 | +11.0% |
| Метрика | Нефильтрованная | Фильтрованная | Δ |
|---|---|---|---|
| F1 (0) | 0.69 | 0.65 | -5.8% |
| F1 (1) | 0.57 | 0.60 | +5.3% |
| Точность | 0.64 | 0.63 | -1.6% |
Таблица 4: Сравнение фильтрованных и нефильтрованных мета-моделей (Meta-Models)
Компромисс между сокращением данных и производительностью модели можно рассчитать следующим образом:
- сохранение производительности = фильтрованная производительность / нефильтрованная производительность * 100
- чистая выгода = сохранение производительности - сокращение данных
Если мы получаем положительную чистую выгоду, то фильтр эффективен и должен использоваться.
| Модель | Сокращение данных | Сохранение производительности | Чистая выгода |
|---|---|---|---|
| Первичная | 76.1% | 112.2% | +36.1% |
| Мета-модель (Мета) | 76.1% | 98.5% | +22.4% |
Таблица 5: Анализ компромисса
Основные выводы из сравнения нефильтрованных и фильтрованных сигналов:
- CUSUM-фильтр успешно отбросил 76,1% событий как шум.
- Фильтрация повысила точность как в первичной модели, так и в мета-модели.
- Фильтрация лишь незначительно ухудшила общую производительность мета-модели, несмотря на сокращение данных на 76%. Наблюдался прирост F1-меры для класса 1 на 5,3% и падение для класса 0 на 5,6%. И несмотря на падение F1 для класса 0, мы все равно получили чистую выгоду от использования CUSUM-фильтра.
Мета-маркировка на практике: стратегия на основе полос Боллинджера
Отчеты о классификации и кривые ROC ниже подчеркивают ключевой вывод: мета-маркировка наиболее эффективна в сочетании с реалистичными схемами маркировки, учитывающими риск.
;")
Рисунок 1: Отчет о классификациибазовой моделис фиксированным временным горизонтом

Рисунок 2: Отчет о классификациимета-моделис фиксированным временным горизонтом

Рисунок 3: Отчет о классификациибазовой модели с методом тройного барьера

Рисунок 4: Отчет о классификациимета-моделис методом тройного барьера
ROC-кривые

Рисунок 5: ROC кривые:сравнение мета-моделей с фиксированным горизонтом иметодом тройного барьера
Интерпретация результатов: расшифровка производительности модели
Разительный контраст в полученных результатах подтверждает основную гипотезу: именно разметка данных определяет успех. Отчет о классификации модели с фиксированным временным горизонтом показывает ее фундаментальную неспособность к обучению; неумение модели выделять сигналы на уровне выше случайного графически подтверждается ее ROC-кривой, которая практически лежит на диагонали — верный признак бесполезного классификатора. Напротив, отчет по методу тройного барьера демонстрирует, что модель успешно выявила прогностические закономерности. Этот факт подчеркивается выраженным изгибом ее ROC-кривой в направлении верхнего левого угла, что указывает на значимый компромисс между долями истинно и ложно положительных результатов. Значение AUC-ROC, значительно превышающее 0,5, доказывает ощутимую предсказательную силу этой модели.
Что еще важнее, показатели точности (precision) напрямую переводятся в реалии трейдинга: более высокая точность для класса '1' означает, что большая доля наших спрогнозированных прибыльных сделок (мета-меток), вероятно, окажется верной. Это, в свою очередь, повышает потенциальную доходность стратегии и создает конкретную статистическую основу для определения размера позиции, основанного на уверенности модели.
Экономическая значимость: результаты на вневыборочных данных
Хотя модель с тройным барьером продемонстрировала статистически значимое улучшение AUC, ее истинная ценность раскрывается в смоделированной кривой капитала. Рисунок 7 показывает, что стратегия, использующая наш новый метод разметки, достигла доходности -0,03% с максимальной просадкой 36,9%, значительно превзойдя эталонную стратегию с фиксированным горизонтом, которая показала доходность -0,71% при максимальной просадке 76%.

Рисунок 6: Кривая капиталадля стратегии с фиксированным горизонтом

Рисунок 7: Кривая доходности для стратегии с методом тройного барьера
В таблице ниже представлены все показатели эффективности для каждого метода разметки:
| Метрика (Metrics) | Фиксированный временной горизонт (Fixed-Time Horizon) | Тройной барьер (Triple-Barrier) |
|---|---|---|
| Общая доходность (total_return) | -0.709771 | -0.028839 |
| Годовая доходность (annualized_return) | -0.338102 | -0.009714 |
| Волатильность (volatility) | 0.483111 | 0.37613 |
| нисходящая волатильность (downside volatility) | 0.336945 | 0.231413 |
| Коэффициент Шарпа (sharpe_ratio) | -4.778646 | -0.021566 |
| Коэффициент Сортино (sortino_ratio) | -6.851611 | -0.035053 |
| var_95 | -0.002864 | -0.00215 |
| cvar_95 | -0.004164 | -0.002992 |
| Коэффициент асимметрии (skewness) | -0.014451 | 0.034745 |
| Эксцесс (kurtosis) | 3.857222 | 2.507046 |
| Максимальная просадка (max_drawdown) | 0.761708 | 0.368585 |
| Средняя просадка (avg_drawdown) | 0.08375 | 0.039945 |
| Длительность просадки (drawdown_duration) | 84 дня 01:18:50 | 32 дня 03:17:12 |
| Индекс язвы (Ulcer Index) | 0.217503 | 0.098507 |
| Коэффициент Калмара (calmar_ratio) | -0.443874 | -0.026354 |
| Частота ставок (bet_frequency) | 3901 | 3969 |
| Количество ставок в год (bets_per_year) | 1300.040115 | 1322.701671 |
| Количество сделок (num_trades) | 37691 | 27426 |
| Количество сделок в год (Количество сделок в год) | 12560.83363 | 9139.93853 |
| Доля выигрышей (Win Rate) | 0.497546 | 0.504339 |
| Средний выигрыш (avg_win) | 0.001266 | 0.001081 |
| Средний проигрыш (avg_loss) | -0.001322 | -0.001105 |
| Лучшая сделка (best_trade) | 0.014599 | 0.01451 |
| Худшая сделка (worst_trade) | -0.013828 | -0.010548 |
| Фактор прибыли (Profit Factor) | 0.952754 | 0.999799 |
| Ожидаемая доходность (Expectancy) | -0.000034 | -0.000002 |
| Критерий Келли (kelly_criterion) | -0.027194 | -0.002226 |
| Количество выигрышей подряд (consecutive_wins) | 77 | 92 |
| Количество проигрышей подряд (consecutive_losses) | 66 | 90 |
| Средняя длительность сделки (avg_trade_duration) | 0 дней 00:39:18 | 0 дней 06:22:15 |
Таблица 6: Показатели эффективности на вневыборочных данных
Заключение
В этой второй части серии статей "Практическое руководство по машинному обучению для MetaTrader 5" мы исследовали, как выбор метода разметки влияет на поведение и надежность финансовых моделей. Отказавшись от фиксированных временных горизонтов и приняв на вооружение методы, зависящие от траектории цены, такие как метод тройного барьера, мы показали, как можно закодировать учет рисков и реалистичную динамику сделок непосредственно в процесс обучения.
Мета-маркировка (Meta-labeling) стала стратегическим дополнением, которое отсеивает сигналы с низкой уверенностью и повышает точность, особенно в сочетании с надежными схемами разметки. Отчеты о классификации и ROC-кривые демонстрируют, как этот многослойный подход улучшает качество сигналов даже при агрессивной фильтрации.
Но наше путешествие далеко от завершения.
В следующей статье мы реализуем метод сканирования тренда (trend-scanning method), который позволит моделям динамически выбирать свой горизонт прогнозирования на основе статистически значимых движений цены. Это открывает новый уровень адаптивности на волатильных рынках.
Мы также решим проблему одновременности (concurrency) в финансовых данных, когда множество сигналов перекрываются во времени. Для этого мы введем веса выборок (sample weights), отражающие уникальность и значимость каждого наблюдения. Это гарантирует, что наши модели будут учиться на действительно независимых сигналах, а не на избыточном шуме.
Наконец, мы рассмотрим, как использовать вероятности, генерируемые мета-маркировкой, для более интеллектуального определения размера позиций. Вместо бинарного исполнения сигналов мы будем использовать вероятностную уверенность для масштабирования объема позиций, согласовывая убежденность модели с распределением капитала.
В совокупности эти усовершенствования приблизят нас к созданию производственного конвейера машинного обучения для финансовых рынков — такого, который является не только технически обоснованным, но и стратегически согласованным с реальным торговым поведением.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18864
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Я что-то не понимаю:
Если вы обучаете модели не на сырых тиковых данных, а на построенных барах (время, тик и т.д.), нужно ли строить бары во время живой торговли?
Я чего-то не понимаю:
Если вы обучаете модели не на сырых тиковых данных, а на построенных барах (время, тик и т.д.), нужно ли строить бары во время реальной торговли?