
Преодоление ограничений машинного обучения (Часть 9): Обучение признаков на основе корреляции в задачах самообучения на финансовых данных

Существует множество препятствий, существенно затрудняющих любому участнику нашего сообщества безопасное развертывание торговых приложений, основанных на машинном обучении. В этой серии статей мы стремимся привлечь внимание читателя к источникам ошибок, которые труднее увидеть и которые не рассматриваются в стандартной литературе по машинному обучению. Среди них одним из наиболее важных является скрытый сбой, который возникает при нарушении основополагающих допущений модели.
Все статистические модели делают определенные допущения относительно имеющихся у вас данных и процесса, сгенерировавшего эти данные. Чем меньше допущений делает модель, тем более гибкой — или “мощной” — она становится, поскольку модели с меньшим количеством допущений могут обучаться многим сложным взаимосвязям. На этом этапе некоторые читатели могут задуматься: “Если модели становятся более эффективными, если в них делается меньше допущений, то почему бы не создать модель, которая вообще не делает каких-либо допущений?” К сожалению, невозможно создать статистическую модель, которая не делала бы совсем никаких допущений относительно имеющихся у вас данных. Одним из наиболее важных допущений, необходимых для построения модели машинного обучения, является допущение о том, что существует взаимосвязь между имеющимися у вас входными признаками и интересующим вас целевым значением.
Эти допущения лежат в основе нашей способности (или неспособности) прибыльно прогнозировать выбранный финансовый рынок. Когда эти допущения нарушаются, ничего видимого не происходит. Никакого предупреждения нет. Эта скрытая точка отказа — это то, с чем современные статистические модели просто сталкиваются на каком-то этапе, часто без обнаружения таких отказов.
В научных текстах часто приводятся статистические тесты для определения того, выполняются ли допущения модели. Важно понимать, насколько хорошо допущения вашей модели соответствуют характеру поставленной задачи, поскольку это позволяет определить, подходит ли выбранная модель для поставленной задачи, которую мы хотим ей поручить. Однако эти стандартные статистические тесты создают дополнительные существенные трудности сверх уже сложной задачи. Вкратце, стандартные академические решения не только сложны в исполнении и тщательной интерпретации, но и подвержены риску получения ложных результатов, что означает, что они могут ошибочно признать пригодной модель, которая на деле некорректна. Это подвергает практиков неконтролируемым рискам.
Таким образом, в данной статье предлагается более практичное решение, гарантирующее, что допущения вашей модели о реальном мире не будут нарушены. Мы сосредоточимся на одном допущении, присущем всем статистическим моделям — от простых линейных моделей до современных глубоких нейронных сетей. Все они допускают, что выбранное вами целевое значение является функцией имеющихся у вас наблюдений. Мы показываем, что более высоких уровней эффективности можно достичь, рассматривая данный набор наблюдений как исходный материал, из которого мы генерируем новые потенциальные целевые значения, которые могут легче поддаваться обучению. Эта парадигма также известна как самоконтролируемое обучение.
Эти новые целевые значения, порожденные из входных данных, по определению являются функциями самих наблюдений. Это может показаться ненужным, но на самом деле это устраняет одну из самых больших слепых зон наших статистических моделей, помогая нам создавать более стабильные и надежные торговые приложения с численным управлением. Давайте приступим!
Получение наших данных из терминала MetaTrader 5
В этом обсуждении мы намерены использовать наши входные параметры, а именно источники ценовых данных о ценах открытия, максимума, минимума и закрытия (OHLC), в качестве исходных компонентов для новых обучающих сигналов, которым может обучаться наша статистическая модель. Поэтому для обеспечения воспроизводимости лучше всего, чтобы мы выполняли все манипуляции с данными в MQL5. В машинном обучении предполагается, что целевая переменная — будущая цена - является функцией наблюдений, OHLC. Это противоречит стандартной портфельной теории, поскольку мы знаем, что будущая доходность зависит от ожиданий инвесторов, а не от исторических цен. Исходя из этой мотивации, давайте вычислим новые воображаемые точки, которые лежат между наблюдаемыми уровнями цен. Чтобы сделать это в MQL5, мы применяем простую арифметику для вычисления воображаемой средней точки, которая находится между каждой парой источников OHLC. //+------------------------------------------------------------------+ //| Fetch Data Mid Points | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- File name string file_name = Symbol() + " Mid Points.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle, //--- Time "Time", //--- OHLC "Open", "High", "Low", "Close", //--- OHLC Mid Points "O-H M", "O-L M", "O-C M", "H-L M", "H-C M", "L-C M" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i), iClose(_Symbol,PERIOD_CURRENT,i), //--- OHLC Mid Points (iOpen(_Symbol,PERIOD_CURRENT,i) + iHigh(_Symbol,PERIOD_CURRENT,i))/2, (iOpen(_Symbol,PERIOD_CURRENT,i) + iLow(_Symbol,PERIOD_CURRENT,i))/2, (iOpen(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2, (iHigh(_Symbol,PERIOD_CURRENT,i) + iLow(_Symbol,PERIOD_CURRENT,i))/2, (iHigh(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2, (iLow(_Symbol,PERIOD_CURRENT,i) + iClose(_Symbol,PERIOD_CURRENT,i))/2 ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Анализ наших рыночных данных на Python
Давайте начнем с импорта наших стандартных библиотек Python.
#Load our libraries import pandas as pd import numpy as np import seaborn as sns import matplotlib.pyplot as plt
Затем считываем CSV-файл, созданный с помощью нашего скрипта MQL5.
#Read in the data
data = pd.read_csv('./EURUSD Mid Points.csv')
data 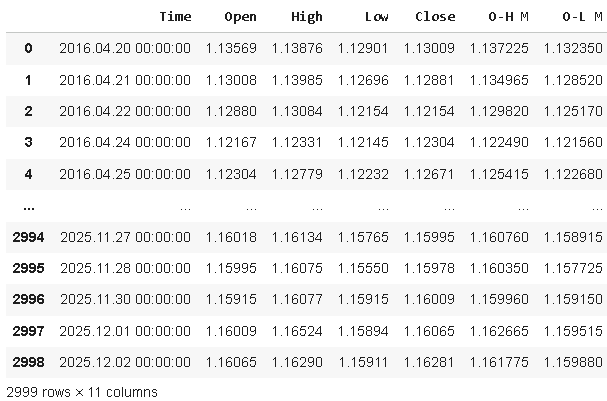
Рисунок 1: Визуализация наших рыночных данных в соответствии с нашими расчетами в нашем скрипте на MQL5
Мы вычислили средние значения в нашем скрипте на MQL5, используя своё понимание арифметики. Однако нам следует провести ряд тестов для проверки корректности, чтобы убедиться, что мы реализовали именно то, что задумали. Как видно на рисунке 2 ниже, мы отобразили исторические максимальные и минимальные значения обменного курса EURUSD, полученные от нашего брокера. Кроме того, мы можем наблюдать, что пунктирная воображаемая средняя точка, которую мы рассчитали в MQL5, находится между максимумом и минимумом, как мы и ожидали.
#Examine correctness plt.plot(data.loc[0:10,'High'],color='red') plt.plot(data.loc[0:10,'H-L M'],color='black',linestyle=':') plt.plot(data.loc[0:10,'Low'],color='blue') plt.grid() plt.legend(['High','H-L Mid','Low']) plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Hisotircal Time Stamp') plt.title('The High-Low Mid Point of EURUSD Exchange Rates')
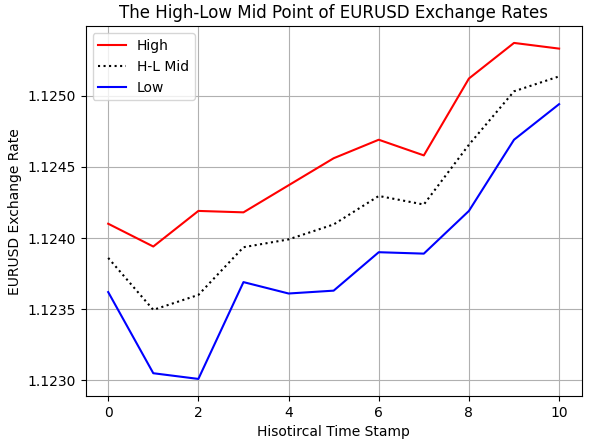
Рисунок 2: Визуализация средней точки между максимумом и минимумом цены EURUSD
Средняя точка между ценами открытия и закрытия также была рассчитана правильно, как видно на следующем рисунке.
#Examine correctness plt.plot(data.loc[70:90,'Open'],color='red') plt.plot(data.loc[70:90,'O-C M'],color='black',linestyle=':') plt.plot(data.loc[70:90,'Close'],color='blue') plt.grid() plt.legend(['Open','O-C Mid','Close']) plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Hisotircal Time Stamp') plt.title('The Open-Close Mid Point of EURUSD Exchange Rates')
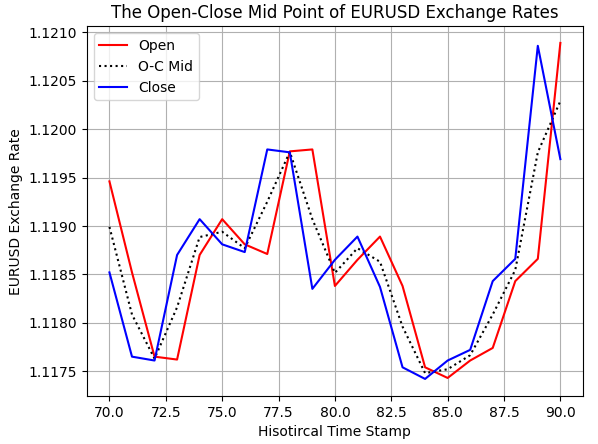
Рисунок 3: Визуализация средней точки между ценой открытия и закрытия.
Теперь определим, насколько далеко в будущее мы хотим заглянуть в нашем прогнозе.
#Forecast horizon HORIZON = 2
Обычно в стандартной академической литературе по статистическому обучению именно на этом этапе ожидается, что читатель разделит свои вводные признаки и целевое значение. Однако именно в этом заключается главное отличие решения, которое данная статья стремится донести до читателя. Вместо того чтобы работать с фиксированным целевым значением, мы будем создавать как можно больше целевых объектов на основе имеющихся наблюдений.
#Candidate targets candidate_y = data.iloc[:,4:11].columns candidate_x = data.iloc[:,1:5].columns
Для этого упражнения мы сохранили классическое целевое значение будущей цены, а также использовали другие замещающие целевые показатели, которые, по нашему мнению, могут быть проще для изучения, чем классическое целевое значение.
candidate_y
Index(['Close', 'O-H M', 'O-L M', 'O-C M', 'H-L M', 'H-C M', 'L-C M'], dtype='object')
Создадим столбцы в исходном наборе данных для хранения будущего значения каждого потенциального целевого значения.
data['Label 1'] = 0 data['Label 2'] = 0 data['Label 3'] = 0 data['Label 4'] = 0 data['Label 5'] = 0 data['Label 6'] = 0 data['Label 7'] = 0
Наконец, создадим дополнительные столбцы, которые будут служить бинарными целевыми значениями для каждого целевого значения, которое мы хотим оценить.
data['Target 1'] = 0 data['Target 2'] = 0 data['Target 3'] = 0 data['Target 4'] = 0 data['Target 5'] = 0 data['Target 6'] = 0 data['Target 7'] = 0
Теперь нам нужно разметить набор данных, а затем заполнить целевое значение. Этот простой цикл будет итеративно заполнять столбцы нулей, которые мы определили ранее, будущим значением целевого значения и его соответствующим двоичным представлением.
#Label the dataset for i in np.arange(7): #Add labels to the data label = 'Label ' + str(i+1) data[label] = data[candidate_y[i]].shift(-HORIZON) #Define the labels as binary targets target = 'Target ' + str(i+1) data[target] = 0 #Add the target data.loc[data[label] > data[candidate_y[i]],target] = 1 #Drop the last missing forecast horizon period data = data.iloc[:-HORIZON,:] data
Теперь давайте загрузим библиотеки статистического обучения, которые нам нужны, чтобы определить, какому целевому значению нашей модели легче обучиться, учитывая имеющиеся наблюдения.
from sklearn.model_selection import TimeSeriesSplit,cross_val_score from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
Чтобы наши сравнения были точными, мы будем использовать одну и ту же модель для каждого целевого значения.
def get_model(): return(LinearDiscriminantAnalysis())
Теперь определим наш объект кросс-валидации временных рядов. Это гарантирует, что мы не будем выполнять случайную перетасовку при кросс-валидации нашей модели.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Подготовим массив данных, чтобы отслеживать нашу точность по каждому целевому значению.
scores = []
Проведем кросс-валидацию эффективности работы той же модели при тех же входных признаках, но изменим только целевое значение, которое модель пытается изучить, на основе имеющихся наблюдений.
#Classical Target scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-7],cv=tscv,scoring='accuracy'))) #Modern Targets scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-6],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-5],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-4],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-3],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-2],cv=tscv,scoring='accuracy'))) scores.append(np.mean(cross_val_score(get_model(),data.loc[:,candidate_x],data.iloc[:,-1],cv=tscv,scoring='accuracy')))
Теперь читатель может ясно видеть практическую ценность предложенного нами решения. Создавая собственные целевые значения на основе наблюдений, с которых вы начинали, можно добиться таких уровней качества, которых нельзя достичь, если ограничиваться классической целевой переменной — будущей ценой.
scores
[np.float64(0.503006012024048),
np.float64(0.7082164328657314),
np.float64(0.6941883767535071),
np.float64(0.6328657314629258),
np.float64(0.6501002004008015),
np.float64(0.5739478957915832),
np.float64(0.5739478957915831)]
При визуализации результатов предложенного нами решения, достигнутые нами улучшения становятся очевидными. Нашей модели оказалось проще освоить все остальные целевые значения, созданные на основе наблюдений, чем она смогла, пытаясь обучиться самой цене. Похоже, что преимущества с лихвой компенсируют дополнительные усилия, затраченные на их приобретение.
sns.barplot(scores,color='black') plt.xticks([0,1,2,3,4,5,6],candidate_y) plt.axhline(scores[0],linestyle=':',color='red') plt.ylabel('Accuracy out of 100%') plt.xlabel('Selected Target') plt.title('EURUSD Forecasting Accuracy is a Function of The Target')
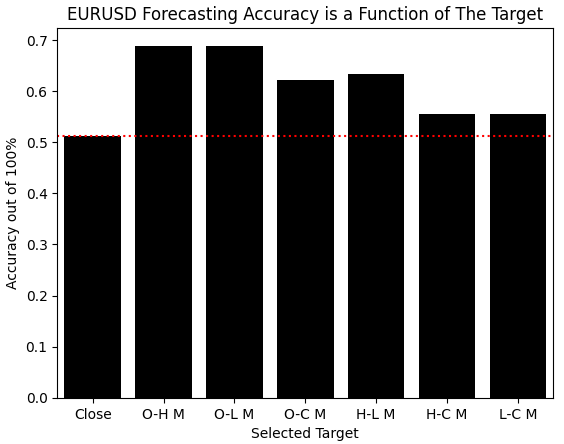
Рисунок 4: Изменения, реализованные в результате изменения наших целевых значений, являются значительными и заслуживают дальнейшего изучения
Являясь алгоритмическими трейдерами, ориентирующимися на числовые данные, мы можем быстро многое узнать о нашем наборе данных, тщательно интерпретируя значимые числа, полученные из этого набора данных. В этом случае нам следует проявлять осторожность в отношении взлома целевой функции. Следовательно, мы должны определить наивысший показатель, который могла бы получить любая модель, всегда прогнозируя наиболее распространенную метку для каждого целевого значения.
Поскольку каждое целевое значение равно либо 1, либо 0, вычисление среднего значения каждого целевого значения фактически позволяет нам определить, какое целевое значение встречается чаще всего и какова доля его доминирования. Если оба целевых значения совпадают, то среднее значение этого целевого значения должно быть равно 0,5. Отклонения менее 0,5 указывают на большее количество нулей, а обратное — на большее количество единиц. Среднее значение может быть равно 1 только в том случае, если все целевые значения равны 1, и аналогично, чтобы получить среднее значение, равное 0, все значения должны быть равны 0.
Таким образом, мы видим, что наши потенциальные целевые значения ведут себя хорошо, и ни одно из них не отклонилось слишком далеко от 0,5, чтобы разумно объяснить улучшения по сравнению с классической моделью.
data.iloc[:,-7:].mean() | Целевое значение | Среднее значение |
|---|---|
| Целевое значение 1 | 0.502836 |
| Целевое значение 2 | 0.507174 |
| Целевое значение 3 | 0.487154 |
| Целевое значение 4 | 0.494161 |
| Целевое значение 5 | 0.500167 |
| Целевое значение 6 | 0.474808 |
| Целевое значение 7 | 0.522856 |
Теперь, когда мы определили целевые значения, которые легче предсказать, чем первоначальные уровни цен, давайте узнаем, как наше новое целевое значение связано с классическим целевым значением. Это критически важный этап. Начинаем с импорта простой линейной модели
from sklearn.linear_model import LinearRegression
Статистические инструменты можно использовать либо для вывода, либо для получения интерпретируемых инсайтов. Обычно мы используем наши инструменты для выводов или просто для прогнозирования. Сегодня мы сосредоточимся на использовании этих моделей для получения информации, а не для предсказательного моделирования.
explanation = LinearRegression()
Обучение линейной модели на двух целевых значениях может на первый взгляд показаться необоснованным. Однако это совершенно разумная практика.
explanation.fit(data[['Label 1']],data['Label 2'])
Коэффициенты, изученные нашей линейной моделью, сразу же показывают, движутся ли два наши целевые значения вместе или в противоположных направлениях. Наша линейная модель оценила коэффициенты почти равными 1, что означает, что сгенерированное нами новое целевое значение почти идеально соответствует классическому целевому значению. И, следовательно, прогнозирование нового целевого значения так же хорошо, как и прогнозирование классического целевого значения, с тем преимуществом, что обучение нового целевого значения, которое мы сформулировали, обходится дешевле.
explanation.coef_
array([0.99533718])
В качестве альтернативы читатель мог бы также просто рассчитать корреляционную матрицу сгенерированных нами потенциальных целевых значений, чтобы получить тот же результат.
data.iloc[:,-14:-7].corr()
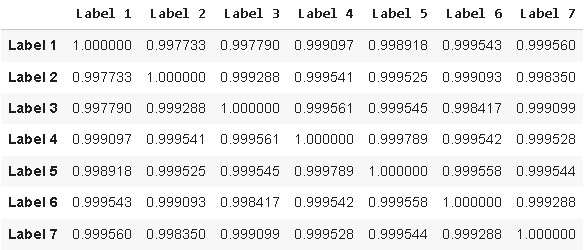
Рисунок 5: Визуализация корреляции между потенциальными целевыми значениями, которые мы разработали, и классическим целевым значением
Наконец, мы также можем доказать это самим себе визуально, построив график классического целевого значения, которое у нас есть, по сравнению с новым целевым значением, которое мы хотим смоделировать. Это действие показывает нам то, что мы подтвердили выводами, полученными с помощью нашей линейной модели и корреляционной матрицы: два наших целевых значения следуют друг за другом с явной и определенной близостью.
plt.plot(data.iloc[0:200,-14],color='black') plt.plot(data.iloc[0:200,-13],linestyle=':',color='red') plt.grid() plt.ylabel('EURUSD Exchange Rate') plt.xlabel('Historical Time') plt.title('Visualizing Our Classical & Candidate Target') plt.legend(['Classical Target','Candidate Target'])
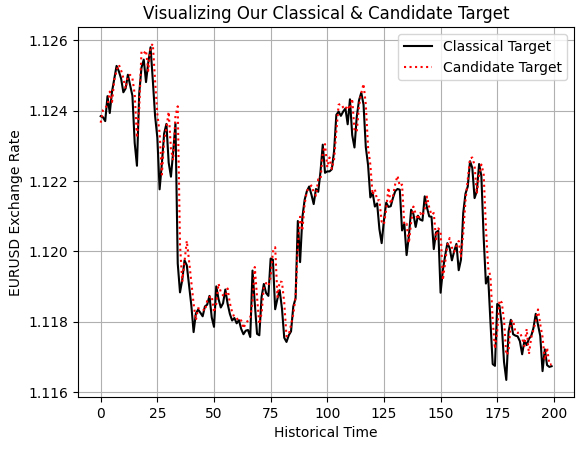
Рисунок 6: Визуализация взаимосвязи между нашим разработанным целевым значением-кандидатом и классическим целевым значением
Теперь, когда мы определили, какое целевое значение мы обучаем лучше всего, мы будем использовать все исходные данные, которые собрали на данный момент, чтобы помочь нам смоделировать целевое значение, в достижении которого мы преуспели.
X = ['Open','High','Low','Close','O-H M','O-C M', 'H-L M', 'H-C M', 'L-C M'] y = ['Target 2']
К моему удивлению, наши уровни эффективности нисколько не изменились, несмотря на дополнительные входные признаки, которые мы внедрили в нашу модель.
np.mean(cross_val_score(get_model(),data.loc[:,X],data.iloc[:,-6],cv=tscv,scoring='accuracy'))
np.float64(0.7082164328657314)
Вспомним показатель, который получили, используя обычные ценовые данные OHLC.
scores[1] np.float64(0.7082164328657314)
Прежде чем мы сможем сделать вывод о том, что реализовали наилучшую из возможных статистических моделей, мы должны быть уверены в том, что не сможем улучшить свои результаты, создав более подробное описание поведения рынка для нашей модели. Таким образом, мы рассчитаем рост отдельных источников ценовых данных и, кроме того, мы также рассчитаем рост по различным источникам ценовых данных. Все эти признаки будут объединены с первоначальным пакетом признаков, с которых мы начинали, что даст нам всестороннее и подробное представление об обменных курсах на паре EURUSD.
#Feature Engineering initial_features = data.loc[:,X] #Growth in individual Price Levels new_features = initial_features new_features['Delta Open'] = data['Open'].shift(HORIZON) - data['Open'] new_features['Delta High'] = data['High'].shift(HORIZON) - data['High'] new_features['Delta Low'] = data['Low'].shift(HORIZON) - data['Low'] new_features['Delta Close'] = data['Close'].shift(HORIZON) - data['Close'] #Growth across all Price levels new_features['Growth O-H'] = data['Open'].shift(HORIZON) - data['High'].shift(HORIZON) new_features['Growth O-L'] = data['Open'].shift(HORIZON) - data['Low'].shift(HORIZON) new_features['Growth O-C'] = data['Open'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features['Growth H-L'] = data['High'].shift(HORIZON) - data['Low'].shift(HORIZON) new_features['Growth H-C'] = data['High'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features['Growth L-C'] = data['Low'].shift(HORIZON) - data['Close'].shift(HORIZON) new_features = new_features.iloc[HORIZON:,:] new_features.reset_index(drop=True,inplace=True) data = data.loc[HORIZON:,:] data.reset_index(inplace=True,drop=True) new_features
Возможно, наша интуиция подсказала нам, что такой подход гарантированно приведет к улучшениям; однако в этой серии статей мы стремимся дать данным говорить самим за себя. Похоже, что все наши усилия по совершенствованию этих новых признаков были напрасны, потому что нам по-прежнему не удается превзойти аналогичную модель, которая была ограничена обработкой гораздо меньшего объема данных.
np.mean(cross_val_score(get_model(),new_features,data.iloc[:,-6],cv=tscv,scoring='accuracy'))
np.float64(0.688118007375461)
Для читателей, нуждающихся в обновлении, это тот показатель, который мы пытаемся побить. Построение признаков - это необходимый шаг для обеспечения того, чтобы мы использовали наилучшую возможную модель для имеющихся у нас данных. Это не гарантирует улучшения ваших результатов. Как уже должны знать все постоянные читатели, при оптимизации нет никаких гарантий.
scores[1] np.float64(0.6889680605037813)
На данном этапе мы исчерпали возможности разработки функций на основании прямого преобразования исходных источников ценовых данных. Поскольку эти дополнительные описательные признаки не привели к улучшениям, наш следующий вопрос заключается в том, лучше ли выражена информация, содержащаяся в наборе данных, в другой системе координат.
Некоторые взаимосвязи могут быть трудными для обучения в настройках высокой размерности, и поэтому возможно ли, чтобы наша модель могла лучше изучить эти взаимосвязи в более значимом представлении исходного набора данных с низкой размерностью? На этот вопрос отвечает семейство статистических алгоритмов, известных как методы обучения многообразию. В данном обсуждении мы выберем в качестве выбора алгоритма обучения многообразию Метод независимых компонент (Independent Component Analysis, ICA).
ICA - это мощное расширение популярного Метода главных компонент (Principal Component Analysis, PCA). Среди многих отличий PCA можно быстро вычислить, поскольку он основан на решениях замкнутой формы, выраженных в линейной алгебре. Однако ICA лучше рассматривать как задачу оптимизации, которая не имеет замкнутого решения, а скорее должна решаться итеративно.
ICA был популяризирован сообществом по обработке сигналов, где было обнаружено, что он способен выделять и разделять сигналы, которые могли создавать помехи друг другу. ICA эффективно способен преобразовать любую заданную матрицу данных в максимально независимые и негауссовы векторы, которые, как считается, являются первоначальными источниками сигнала, генерирующего наблюдения. Читатели, желающие получить более глубокое представление об ICA, могут найти доступно написанную исследовательскую статью на эту тему, ссылка на которую приведена здесь.
#Manifold Learning from sklearn.decomposition import FastICA from sklearn.model_selection import RandomizedSearchCV
Как правило, обучение на многомерных наборах данных может быть сложной задачей. Методы обучения многообразию, такие как FastICA, основаны на убеждении, что, хотя данные записаны в многомерном пространстве, большинство измерений являются лишь окружающим пространством, и реальный процесс, который нас интересует, может определяться лишь несколькими важными измерениями. Таким образом, мы будем итеративно использовать алгоритм FastICA для представления исходных рыночных данных, состоящих из 20 столбцов, используя столбцы от 1 до 18, и каждый раз будем фиксировать результаты.
#Keep track of our performance manifold = [] #Search for a manifold where the objective is easier to learn res = [] for i in np.arange(new_features.shape[1]-2): enc = FastICA(n_components=i+1) new_manifold = pd.DataFrame(enc.fit_transform(new_features)) res.append(np.mean(cross_val_score(get_model(),new_manifold,data.iloc[:,-6],cv=tscv,scoring='accuracy'))) #Remember the score we are trying to outperform res.append(scores[1])
Как видно, наши лучшие результаты получены на последнем графике баров, показывающем, что модель, использующая только данные OHLC, все равно превзошла бы нас даже после применения FastICA. Таким образом, на данный момент мы можем быть уверены, что у нас есть оптимальная модель, просто используя рыночные данные OHLC, и теперь мы можем с уверенностью экспортировать модель в формат ONNX.
sns.barplot(res,color='black') plt.axhline(np.max(res),color='red',linestyle=':') plt.scatter(np.argmax(res),np.max(res),color='red')
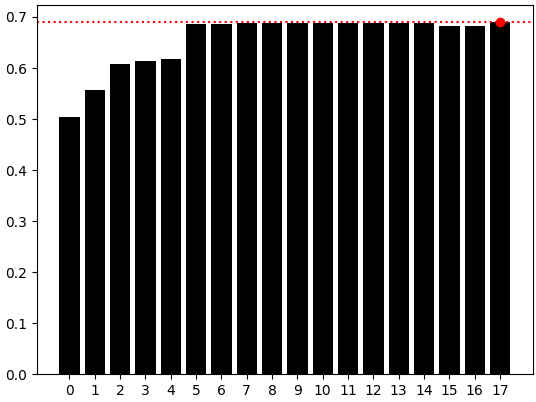
Рисунок 7: Простая модель с использованием 4 столбцов (OHLC) по-прежнему оставалась нашей самой эффективной моделью
Экспортирование в ONNX
Теперь мы готовы экспортировать нашу статистическую модель в формат Open Neural Network Exchange, также известный как ONNX. ONNX позволяет эффективно и оперативно делиться нашей моделью машинного обучения и выражать нашу модель независимо от платформы. Следовательно, загружаем необходимые библиотеки.
import onnx from skl2onnx.common.data_types import FloatTensorType from skl2onnx import convert_sklearn
Определяем форму входных данных для модели. Модель использует четыре основных источника ценовых данных, и эти типы входных данных относятся к типу float, который мы задаем, используя тип паттерна float.
initial_types = [('float_input',FloatTensorType([1,4]))]
Мы также задаем форму выходных данных модели: модель имеет один выходной параметр — целевое значение.
final_types = [('float_output',FloatTensorType([1,1]))]
После этого нам необходимо обеспечить разделение входных признаков. Мы не хотим обучать нашу модель на том же временном периоде, который планируем использовать для тестирования на истории в MetaTrader 5. Поэтому мы исключаем последние пять лет из нашего набора данных и оставляем оставшуюся часть в качестве обучающего набора.
train = data.iloc[:(-365*5),:] test = data.iloc[(-365*5):,:]
Случайные леса (Random forests) — это мощные и гибкие статистические модели, способные обучаться нелинейным эффектам в данных. Поэтому в данном обсуждении мы используем модель случайного леса, хотя читатель может использовать любую другую модель по своему выбору.
В этом примере мы используем индикатор ATR для установки стоп-лоссов в соответствии с волатильностью рынка. Все остальное будет обработано в первую очередь нашей моделью.
from sklearn.ensemble import RandomForestRegressor
Затем обучаем модель на наших обучающих данных.
model = RandomForestRegressor() model.fit(data.loc[:,['Open','High','Low','Close']],data.loc[:,'Label 2'])
Далее мы приступаем к преобразованию модели в ее прототип ONNX. Этот прототип представляет собой промежуточный файл перед сохранением нашей модели ONNX на диск.
onnx_proto = convert_sklearn(model,initial_types=initial_types,final_types=final_types,target_opset=12) Теперь мы можем сохранить файл ONNX.
onnx.save(onnx_proto,'EURUSD MidPoint RFR.onnx')
Тестирование наших допущений
Теперь мы готовы приступить к разработке приложения. Начнём с загрузки файла ONNX, который мы только что записали на диск.
//+------------------------------------------------------------------+ //| EURUSD MidPoint.mq5 | //| Copyright 2025, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD MidPoint RFR.onnx" as const uchar onnx_proto[];
Затем определяем необходимые нам технические индикаторы.
//+------------------------------------------------------------------+ //| Technical Indicators | //+------------------------------------------------------------------+ int atr_handler; double atr_reading[];
Нам также потребуется несколько глобальных переменных для отслеживания текущих цен bid и ask, а также несколько важных функций для нашей модели, таких как обработчик и входные и выходные данные модели.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ double ask,bid; vectorf model_inputs,model_outputs; long model;
Затем мы загружаем библиотеку сделок, которая поможет нам управлять входами и выходами из позиций.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> CTrade Trade;
При первой загрузке нашего приложения мы загружаем соответствующие технические индикаторы и начинаем инициализацию нашей модели из созданного ранее экспорта ONNX. Мы устанавливаем входную и выходную формы и, наконец, прежде чем передавать управление обратно вызывающему экземпляру проверяем, является ли модель допустимой.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Setup our indicators atr_handler = iATR("EURUSD",PERIOD_D1,14); //--- Setup the ONNX model model = OnnxCreateFromBuffer(onnx_proto,ONNX_DATA_TYPE_FLOAT); //--- Define the model parameter shape ulong input_shape[] = {1,4}; ulong output_shape[] = {1, 1 }; OnnxSetInputShape(model,0,input_shape); OnnxSetOutputShape(model,0,output_shape); model_inputs = vectorf::Zeros(4); model_outputs = vectorf::Zeros( 1 ); if(model != INVALID_HANDLE) { return(INIT_SUCCEEDED); } //--- return(INIT_FAILED); }
Когда наше приложение больше не используется, мы освобождаем ресурсы, которые были предназначены для технического индикатора и модели ONNX.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up memory we are no longer using when the application is off IndicatorRelease(atr_handler); OnnxRelease(model); }
Всякий раз при получении новых ценовых уровней мы обновляем нашу текущую запись time, и если сформировалась новая дневная свеча, мы извлекаем свежие копии текущих ценовых уровней, а затем пересчитываем нашу воображаемую среднюю точку в соответствии с текущими ценами. Затем передаем модели ONNX ее четыре входных признака и получаем прогноз. Если наша модель ожидает, что средняя точка в будущем будет больше, чем сейчас, мы открываем длинные позиции; в противном случае мы открываем короткие позиции.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- When price levels change datetime current_time = iTime("EURUSD",PERIOD_D1,0); static datetime time_stamp; //--- Update the time if(current_time != time_stamp) { time_stamp = current_time; //--- Fetch indicator current readings CopyBuffer(atr_handler,0,0,1,atr_reading); double open = iOpen("EURUSD",PERIOD_D1,0); double close = iClose("EURUSD",PERIOD_D1,0); double high = iHigh("EURUSD",PERIOD_D1,0); double low = iLow("EURUSD",PERIOD_D1,0); double o_h_mid = ((open + high)/2); model_inputs[0] = (float) open; model_inputs[1] = (float) high; model_inputs[2] = (float) low; model_inputs[3] = (float) close; ask = SymbolInfoDouble("EURUSD",SYMBOL_ASK); bid = SymbolInfoDouble("EURUSD",SYMBOL_BID); //--- If we have no open positions if(PositionsTotal() == 0) { if(!(OnnxRun(model,ONNX_DATA_TYPE_FLOAT,model_inputs,model_outputs))) { Comment("Failed to obtain a forecast from our model: ",GetLastError()); } else { Comment("Forecast: ",model_outputs); //--- Trading rules if((model_outputs[1] > o_h_mid)) { //--- Buy signal Trade.Buy(0.01,"EURUSD",ask,ask-(atr_reading[0] * 2),ask+(atr_reading[0] * 2),""); } else if((model_outputs[1] < o_h_mid)) { //--- Sell signal Trade.Sell(0.01,"EURUSD",bid,bid+(atr_reading[0] * 2),bid-(atr_reading[0] * 2),""); } } } } } //+------------------------------------------------------------------+
Теперь мы готовы начать пятилетнее тестирование на исторических данных нашей модели с февраля 2020 года до момента написания статьи в 2025 году.

Рисунок 8: Выбор дней тестирования на истории для теста за 5 лет для проверки наших новых допущений
Устанавливаем параметры случайной задержки, чтобы получить реалистичную имитацию сетевых задержек и других задержек, возникающих при реальной торговле.

Рисунок 9: Убедитесь, что вы выбрали настройки случайной задержки для надежной имитации реальных рыночных условий
По завершении теста мы сможем наблюдать кривую эквити, полученную с помощью подхода, предложенного в этой статье. Как мы видим, несмотря на то, что модель максимально проста, она создает доминирующий восходящий тренд на кривой эквити в течение пяти лет торговли. Она использует все сигналы, что поразительно для такой простой модели, и показывает, что в самоконтролируемом обучении есть свои достоинства.

Рисунок 10: Новая кривая эквити, полученная в результате наших новых допущений
Кроме того, когда мы изучаем подробную статистику работы модели, мы видим хороший profit factor и приемлемое ожидаемое значение прибыли на сделку. Получение значений, превышающих единицу, указывает на то, что модель приносила прибыль в течение пяти лет. Однако вызывает разочарование тот факт, что сделки модели снова смещены в сторону длинных позиций: за пять лет в рамках модели было открыто почти в три раза больше длинных позиций, чем коротких. Это указывает на то, что все еще есть слабые места и «слепые зоны», которые мы еще не охватили. Хотя модель случайного леса должна быть способна к изучению сильных нелинейных взаимосвязей, интересно отметить, что в модели все еще присутствует смещение.

Рисунок 11: Подробная статистика эффективности нашей новой статистической стратегии
Заключение
В заключение, в этой статье было продемонстрировано, как статистические сигналы более высокого порядка могут быть реализованы в режиме самостоятельного контроля и применены в алгоритмической торговой настройке. Опираясь исключительно на данные, полученные от нашего брокера, мы можем генерировать новые сигналы, которые наши статистические модели смогут изучать более надежно. Даже простая модель, построенная на основе парадигмы самоконтроля, кажется достаточно надежной, чтобы ее можно было оставить без контроля на пять лет и она, тем не менее, эффективно работала. Кроме того, в статье показано, как искать дополнительные исходные данные, которые читатель может использовать для повышения точности, и не предполагать, что большее количество данных автоматически улучшает результаты, а вместо этого эмпирически проверить, действительно ли помогает большее количество данных. Как мы видели в этой статье, даже самое необходимое может быть использовано в качестве мощных торговых сигналов.
Наконец, как мы подробно обсуждали во вступительной статье этой серии статей, показатели эффективности, которые мы используем для критики статистических моделей, не обязательно соответствуют нашим целям как сообщества алгоритмических трейдеров. Таким образом, читатель должен обратить внимание на то, что статистическая точность модели, составляющая 68%, в нашем обсуждении воплотилась только до 52% прибыльности.
| Название файла | Описание файла |
|---|---|
| Self Supervised Learning: Generating Targets From OHLC Data.ipynb | Jupyter Notebook, который мы использовали для проведения статистического анализа наших исторических рыночных данных по паре EURUSD. |
| EURUSD MidPoint.mq5 | Торговое приложение, которое мы создали, чтобы принимать торговые сигналы на основе изученных им сигналов с самоконтролем. |
| Fetch Data Mid Points.mq5 | Скрипт на MQL5, который мы использовали для извлечения и манипулирования нашими историческими рыночными данными по паре EURUSD. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/20514
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования