
От сигнала к сделке через цепочку агентов: LangChain-архитектура поверх MQL5

Введение
Интеграция LLM с MetaTrader обычно сводится к простому сценарию: советник спрашивает модель "BUY/SELL" и выполняет ответ. Такое решение терпит фиаско при первых нестандартных условиях — расширенный спред, релиз важной статистики через 10 минут, уже открытые позиции или просадка выше допустимого лимита.
Требования практического алготрейдера здесь конкретны: работать на таймфреймах M15–H1 с учётом задержки вызовов LLM (цепочка может занимать 30–90 с), учитывать новости в ближайшие 10 минут, не допускать больше 3 открытых позиций и риск на сделку ≈1%, а также хранить историю решений и их исходов.
Решение — разделить "мышление" и "исполнение", пропускать решение через три независимых фильтра (Signal → News → Risk), фиксировать каждое решение в SQLite с decision_id и замыкать петлю через команду RESULT. Такое требование определяет архитектуру и критерии верификации, а не остаётся абстракцией.
Общая схема
Система состоит из трёх слоёв, которые общаются через локальный WebSocket на порту 8977. WebSocket выбран вместо HTTP осознанно: полнодуплексный протокол позволяет серверу без блокировок обслуживать несколько экземпляров советника параллельно. Кроме того, WebSocket-соединение остаётся установленным между вызовами — не нужно тратить время на рукопожатие при каждом тике.
- Нижний слой — MQL5-советник. Занимается только сбором рыночных данных и исполнением команд. Никакой логики принятия решений. Чистый ввод-вывод.
- Средний слой — Python-сервер с LangChain, где живут агенты. Здесь происходит всё мышление: технический анализ, новостная фильтрация, управление риском, работа с памятью.
- Верхний слой — языковая модель (используется Grok через langchain-xai , но архитектура позволяет подставить любого провайдера).
MT5 → ANALYZE:SYM:TF:csv|{account} → Signal Agent → News Agent → Risk Agent → {signal, decision_id} → MT5
↕ ↕
SQLite память agent_stats
MT5 → RESULT:SYM:decision_id:pnl → обновить исход в БД
MT5 → MEM_STATUS:SYM:TF → статистика Поток данных строго однонаправленный: вниз по цепочке идут данные и контекст, обратно — только финальная команда плюс decision_id , по которому сервер потом запишет результат сделки. Если на любом этапе агент говорит "нет" — цепочка обрывается и советник получает "signal": "hold". Fail-safe по умолчанию.
Требования к системе → как их закрывает архитектура| Требование | Реализация |
|---|---|
| Таймфрейм M15–H1, задержка 30–90 с | On‑bar режим, таймаут 90 с, WebSocket без handshake |
| Учёт новостей за 10 минут | Отдельный агент новостей, проверка по времени и символу |
| Не больше 3 открытых позиций, риск 1% на сделку | Агент риска: читает account_json , жёсткие правила в промпте |
| Память о решениях и их исходах | SQLite + команда RESULT, статистика возвращается в agent_stats |
| Разделение мышления и исполнения | MQL5 только I/O, Python‑сервер принимает решения |
| Возможность менять логику без перекомпиляции советника | Протокол команд (ANALYZE, RESULT, MEM_STATUS, STATUS, STOP) |
Советник на стороне MQL5
Советник работает по событию нового бара, а не на каждом тике. Это сделано осознанно. LLM-вызов занимает 30–60 секунд на полную цепочку из трёх агентов. Гнать три агента на каждом тике бессмысленно; решение принимается раз в бар.
//+------------------------------------------------------------------+ //| OnTick | //+------------------------------------------------------------------+ void OnTick() { // Проверяем закрытые позиции для отправки RESULT if(InpSendResults) CheckClosedPosition(); // Новый бар? datetime barTime = iTime(_Symbol, PERIOD_CURRENT, 0); if(barTime == g_lastBar) return; g_lastBar = barTime; g_barCount++; if(g_barCount % InpAnalysisBars != 0) return; // Собираем цены закрытия double prices[]; ArraySetAsSeries(prices, true); int copied = CopyClose(_Symbol, PERIOD_CURRENT, 0, InpPriceBars, prices); if(copied < 20) { PrintFormat("Мало баров: %d", copied); return; } // CSV цен (от старых к новым) string csv = ""; for(int i = copied - 1; i >= 0; i--) { csv += DoubleToString(prices[i], _Digits); if(i > 0) csv += ","; } // Команда ANALYZE с опциональными данными счёта string cmd = "ANALYZE:" + _Symbol + ":" + InpTimeframe + ":" + csv; // Добавляем данные счёта через "|" для Risk Agent if(InpSendAccount) { string acc = StringFormat( "|{\"balance\":%.2f,\"equity\":%.2f," "\"free_margin\":%.2f,\"open_positions\":%d}", AccountInfoDouble(ACCOUNT_BALANCE), AccountInfoDouble(ACCOUNT_EQUITY), AccountInfoDouble(ACCOUNT_MARGIN_FREE), Count_OpenPositions() ); cmd += acc; } PrintFormat("▶ ANALYZE (%d баров, TF=%s, LangChain)...", copied, InpTimeframe); string response = SendCommand(cmd); if(StringLen(response) == 0) { Print("⚠ Нет ответа от сервера (цепочка агентов может занять до 60с)"); return; } ParseAnalyzeResponse(response); if(g_barCount % InpStatusBars == 0) RequestMemStatus(); if(InpShowComment) UpdateComment(barTime); ExecuteSignal(); }
Протокол команд прост:
| Команда | Формат | Описание |
|---|---|---|
| ANALYZE | ANALYZE:SYM:TF:csv|{account_json} | Запрос сигнала от цепочки |
| RESULT | RESULT:SYM:decision_id:pnl | Сообщить исход закрытой сделки |
| MEM_STATUS | MEM_STATUS:SYM:TF | Запросить статистику памяти |
| STATUS | STATUS | Короткий пинг — проверка связи после подключения |
| STOP | STOP | Отключиться от сервера |
Советник не знает ничего об агентах — он просто отправляет данные, ждёт JSON-ответ и исполняет инструкции. Это важно: разделение обязанностей позволяет менять логику агентов без перекомпиляции советника.
Один важный инженерный нюанс: команды делятся на быстрые и долгие. ANALYZE — это полная цепочка из трёх LLM-вызовов, которая может занять до 90 секунд. Все остальные команды возвращаются за доли секунды. Использовать один и тот же таймаут для всех — плохая идея: либо быстрые команды придётся ждать бессмысленно долго, либо ANALYZE будет обрываться. Поэтому в советнике две функции:
string SendCommand(string cmd) { return WsSend(cmd) ? WsReceive(InpReceiveMs) : ""; } string SendQuickCmd(string cmd) { return WsSend(cmd) ? WsReceive(InpQuickReceiveMs) : ""; }
таймаут … InpReceiveMs = 90000 (90 секунд) — для ANALYZE. InpQuickReceiveMs = 5000 (5 секунд) — для RESULT, MEM_STATUS, STATUS, STOP.
Особого внимания заслуживает цикл обратной связи: в советнике используется массив gtrackTicket[MAXTRACKED], потому что за один тик может закрыться несколько позиций (например, при одновременном срабатывании SL). После закрытия каждой из них советник вычисляет реальный PnL (включая своп и комиссию) и отправляет его на сервер командой RESULT:
//+------------------------------------------------------------------+ //| Отправка RESULT на сервер | //+------------------------------------------------------------------+ void SendResultForClosed(ulong ticket, int decId, string sym) { if(ticket == 0 || decId < 0) return; double profit = GetDealProfitByPosition(ticket); if(profit == EMPTY_VALUE) { Sleep(200); profit = GetDealProfitByPosition(ticket); } if(profit == EMPTY_VALUE) return; double contract = SymbolInfoDouble(sym, SYMBOL_TRADE_CONTRACT_SIZE); double pnlPts = (contract > 0 && InpLotSize > 0 && g_pipValue > 0) ? profit / (InpLotSize * contract * g_pipValue) : profit; string cmd = StringFormat("RESULT:%s:%d:%.5f", sym, decId, pnlPts); string resp = SendCommand(cmd); if(StringLen(resp) > 0) { string outcome = (profit > 0) ? "WIN" : "LOSS"; PrintFormat("RESULT → decision_id=%d %s pnl=%.2f (%.1f pts)", decId, outcome, profit, pnlPts); } }
Именно этот механизм даёт системе память о результатах, а не только о намерениях.
Технические индикаторы на стороне Python
Сервер сам считает полный набор индикаторов из полученного CSV цен — не перекладывает эту задачу на LLM. Это принципиально важно для производительности: модель получает уже готовые числа, а не массив из 60 свечей с просьбой "посчитай RSI".
def calc_indicators(prices: List[float]) -> dict: arr = np.array(prices, dtype=float) # EMA(20), EMA(50), RSI(14), ATR(14), ATR(20), # Bollinger Bands(20), Stochastic(14), z-score(20), # MA5/MA20/MA50, тренд, выравнивание цены относительно MA20 # ... return { "current": ..., "rsi": ..., "ema20": ..., "ema50": ..., "atr": ..., "bb_lo": ..., "bb_hi": ..., "stoch": ..., "zscore": ..., "trend": "up|down|mixed", "ma_align": "above|below|mixed", "volatility": "high|normal|low" }
Агент сигналов получает в промпт уже готовый словарь с двадцатью числами. Ему остаётся интерпретировать, а не вычислять.
Агентная цепочка: три промпта
Все три промпта написаны на английском — это намеренно. LLM в целом показывают более предсказуемые и структурированные ответы на английском, особенно когда речь идёт о строгом JSON-выводе.
Агент сигналов знает о собственной истории. Его системный промпт содержит agent_stats (агрегированную статистику) и memory_context (конкретные прецеденты). Это создаёт поведенческие паттерны: если win-rate ниже 40%, агент автоматически снижает уверенность; если три последних сделки были убыточными — дополнительный штраф к confidence.
SIGNAL_PROMPT = ChatPromptTemplate.from_messages([ ("system", """You are a disciplined quantitative trading agent with persistent memory. === YOUR SELF-KNOWLEDGE === {agent_stats} === HISTORICAL CONTEXT (from your SQLite memory) === {memory_context} === BEHAVIORAL RULES === 1. If your win-rate on this instrument is below 40% — be extra conservative. 2. If the last 3 decisions were all losses — reduce confidence by 0.1. 3. If historical context shows repeated failures on one signal type — downgrade it. 4. If volatility is HIGH — prefer hold unless confidence > 0.75. 5. Never ignore your own track record. Adapt. Return ONLY valid JSON: { "signal": "buy" | "sell" | "hold", "confidence": <0.0–1.0>, "ema20": <number>, "ema50": <number>, "rsi14": <number>, "trend": "up" | "down" | "flat", "comment": "<one sentence in Russian>" }"""), ("human", "{market_data}") ])
Агент новостей — второй фильтр в цепочке. Он оценивает текущее UTC-время и инструмент: не выходит ли ключевая статистика (NFP, CPI, решение ЦБ), нет ли геополитических событий. При news_risk = "HIGH" цепочка немедленно прерывается и возвращается hold — агент риска даже не вызывается.
Агент риска — последний рубеж. Он получает сигнал с уровнем уверенности и реальные данные счёта (баланс, equity, свободная маржа, количество открытых позиций). Жёсткие правила зашиты в системный промпт: риск на сделку не более 1% от баланса, максимум 3 открытых позиции, минимальный стоп 15 пипсов, соотношение TP/SL не хуже 1:1.5. Объём рассчитывается по формуле:
volume = (balance * 0.01) / (sl_pips * 10)
Агент риска возвращает не цены стопов, а пипсы — sl_pips и tp_pips . Советник сам пересчитывает их в ценовые уровни исходя из текущего bid/ask и point.
Оркестратор: последовательная цепочка
Flask endpoint из статьи заменён прямым WebSocket-сервером — это снимает накладные расходы HTTP и позволяет обслуживать несколько советников параллельно в разных потоках. Логика оркестрации при этом та же: строго последовательная цепочка с тремя точками выхода.
def analyze_with_langchain_memory(symbol, prices, timeframe, account): # 1. Считаем индикаторы Python-кодом ind = calc_indicators(prices) # 2. Загружаем контекст из SQLite agent_stats = memory.get_stats(symbol, timeframe) memory_context = memory.get_context(symbol, timeframe, ind["rsi"]) # 3. Signal Agent sig_raw = signal_chain.invoke({ "market_data": market_data, "agent_stats": agent_stats, "memory_context": memory_context, }) signal = parse_llm(sig_raw.content) if signal["confidence"] < 0.0001 or signal["signal"] == "hold": memory.write_decision(..., signal="hold", ...) return {"signal": "hold", "decision_id": decision_id} # 4. News Agent news_raw = news_chain.invoke({"symbol": symbol, "utc_time": utc_now}) news = parse_llm(news_raw.content) if news["news_risk"] == "HIGH": memory.write_decision(..., signal="hold", news_risk="HIGH", ...) return {"signal": "hold", "comment": f"news_risk_HIGH: {news['reason']}"} # 5. Risk Agent risk_raw = risk_chain.invoke({ "signal_data": json.dumps(signal), "account_data": json.dumps(account), "agent_stats": agent_stats, }) risk = parse_llm(risk_raw.content) if not risk["approved"]: memory.write_decision(..., signal="hold", ...) return {"signal": "hold", "comment": f"risk_rejected: {risk['reason']}"} # 6. Записываем решение в SQLite и возвращаем команду decision_id = memory.write_decision( symbol=symbol, timeframe=timeframe, signal=signal["signal"], confidence=signal["confidence"], ... ) return { "signal": signal["signal"], "confidence": signal["confidence"], "decision_id": decision_id, "volume": risk["volume"], "sl_pips": risk["sl_pips"], "tp_pips": risk["tp_pips"], "news_risk": news["news_risk"], "chain_log": " | ".join(chain_log), }
Обратите внимание: каждое решение — в том числе hold — записывается в базу. Это позволяет анализировать не только сделки, но и пропущенные входы.
Парсинг ответов LLM
LLM иногда оборачивают JSON в markdown-блоки или добавляют thinking-теги (reasoning-модели). Сервер обрабатывает оба случая:
def parse_llm(raw: str) -> dict: text = raw.strip() # Убираем ```json ... ``` if text.startswith("```"): lines = text.splitlines() text = "\n".join(lines[1:-1] if lines[-1].strip() == "```" else lines[1:]) # Убираем <think>...</think> для reasoning-моделей if "<think>" in text and "</think>" in text: text = text[text.find("</think>") + 8:].strip() # Извлекаем JSON start = text.find("{") end = text.rfind("}") + 1 if start >= 0 and end > start: return json.loads(text[start:end]) raise ValueError(f"No JSON found in: {text[:100]}")
Исполнение в советнике
После получения ответа советник применяет собственный порог уверенности ( InpMinConf = 0.55 ) как дополнительный фильтр. Если сервер вернул buy или sell , но confidence ниже порога — советник самостоятельно переходит в hold , не открывая позицию.
SL и TP берутся из ответа Risk Agent в пипсах и пересчитываются в цены:
void ExecuteSignal() { if(g_conf < InpMinConf) { PrintFormat("HOLD — conf=%.2f ниже минимума %.2f", g_conf, InpMinConf); return; } if(g_signal == "buy") { if(PositionExistsByType(POSITION_TYPE_BUY)) return; CloseByType(POSITION_TYPE_SELL); double ask = SymbolInfoDouble(_Symbol, SYMBOL_ASK); double point = SymbolInfoDouble(_Symbol, SYMBOL_POINT); // Приоритет: SL/TP от Risk Agent, иначе входные параметры double vol = InpLotSize; int sl_pts = InpSL_Points; int tp_pts = InpTP_Points; // Если сервер вернул объём и пипсы — используем их // (они уже нормализованы Risk Agent) double sl = (sl_pts > 0) ? ask - sl_pts * point : 0; double tp = (tp_pts > 0) ? ask + tp_pts * point : 0; if(OpenOrder(ORDER_TYPE_BUY, vol, ask, sl, tp)) { g_totalBuys++; g_totalTrades++; g_posTicket = LastOpenTicket(); g_posDecisionId = g_decisionId; g_posSym = _Symbol; g_resultSent = false; PrintFormat("✓ BUY %.2f | SL=%.5f TP=%.5f | decision_id=%d", vol, sl, tp, g_decisionId); } } else if(g_signal == "sell") { if(PositionExistsByType(POSITION_TYPE_SELL)) return; CloseByType(POSITION_TYPE_BUY); double bid = SymbolInfoDouble(_Symbol, SYMBOL_BID); double point = SymbolInfoDouble(_Symbol, SYMBOL_POINT); double vol = InpLotSize; int sl_pts = InpSL_Points; int tp_pts = InpTP_Points; double sl = (sl_pts > 0) ? bid + sl_pts * point : 0; double tp = (tp_pts > 0) ? bid - tp_pts * point : 0; if(OpenOrder(ORDER_TYPE_SELL, vol, bid, sl, tp)) { g_totalSells++; g_totalTrades++; g_posTicket = LastOpenTicket(); g_posDecisionId = g_decisionId; g_posSym = _Symbol; g_resultSent = false; PrintFormat("✓ SELL %.2f | SL=%.5f TP=%.5f | decision_id=%d", vol, sl, tp, g_decisionId); } } else { Print("HOLD — сигнал от цепочки агентов"); } }
После закрытия позиции советник автоматически вычисляет реальный PnL из истории сделок (включая своп и комиссию) и отправляет его командой RESULT . Именно так замыкается петля обратной связи: агент получает информацию о том, чем закончилось каждое его решение, и это ложится в SQLite-память для следующих вызовов.
Комментарий на графике
Советник выводит на график полную картину состояния системы:
╔ LANGCHAIN MEMORY AGENT v1.0 ╗ Время: 2025.01.15 14:00 Баров: 42 Позиции: 1 Сделок: 7 Equity: 10234.56 ───────────────────────── Сигнал: buy conf=0.78 decision_id: 23 Chain: signal=buy conf=0.78 [8.2s] | news=LOW [3.1s] | risk=OK vol=0.01 [6.5s] Comment: Восходящий тренд подтверждён EMA-кроссом ───────────────────────── Память: 18 зап. | WR=61% | +2.34 pts Best: buy BUY: 5 SELL: 2
Поле chain_log показывает результат каждого агента и время его ответа — это встроенный мониторинг производительности цепочки в реальном времени.
Производительность и задержки
Честный разговор: полная цепочка из трёх LLM-вызовов занимает 30–60 секунд в зависимости от нагрузки на API. Именно поэтому таймаут в советнике выставлен в InpReceiveMs = 90000 (90 секунд). Для скальпинга это неприемлемо. Для внутридневной торговли на M15–H1 — абсолютно нормально: решение принимается раз в бар, а за это время API успевает ответить трижды.
Если нужна скорость, детерминированные вычисления (EMA, RSI, ATR, уровни) выполняются на стороне Python — без участия LLM. К языковой модели агент обращается только за финальным суждением по готовым числам. Дальнейшая оптимизация — запускать Signal Agent и News Agent параллельно через asyncio.gather, так как они независимы: один анализирует цену, другой — новости. Это сокращает суммарное время примерно вдвое. Агент риска при этом запускается после — он зависит от результатов обоих.
Бэктест системы
Тестирование проводилось на EURUSD, таймфрейм M15, период с 1 марта по 14 апреля 2026 года. Начальный депозит — 10 000 USD, фиксированный лот 0.01, стоп-лосс 700 пунктов, тейк-профит 150 пунктов. Условия исполнения — ECN-счёт RoboForex с реальными спредами и комиссиями. InpMinConf = 0.01 намеренно занижен, чтобы максимально охватить входы. В боевой конфигурации порог имеет смысл поднять до 0.55–0.65.
Ключевые метрики
| Показатель | Значение |
|---|---|
| Чистая прибыль | 32.47 USD |
| Всего сделок | 99 |
| Процент прибыльных | 85.86% (85 из 99) |
| Profit Factor | 1.35 |
| Recovery Factor | 1.66 |
| Sharpe Ratio | 2.77 |
| Максимальная просадка по эквити | 19.52 USD (0.19%) |
| Z-Score | 1.46 (85.57%) |
| LR Correlation | 0.65 |
| Средняя прибыльная сделка | 1.48 USD |
| Средняя убыточная сделка | -6.61 USD |
| Максимум последовательных убытков | 1 |
Распределение win/loss асимметрично и это — ожидаемое поведение системы с соотношением TP/SL 150/700. Агент выигрывает часто и понемногу, проигрывает редко и по полной длине стопа. Именно поэтому profit factor 1.35 при win-rate 85.86% — не противоречие, а прямое следствие выбранной конфигурации рисков.
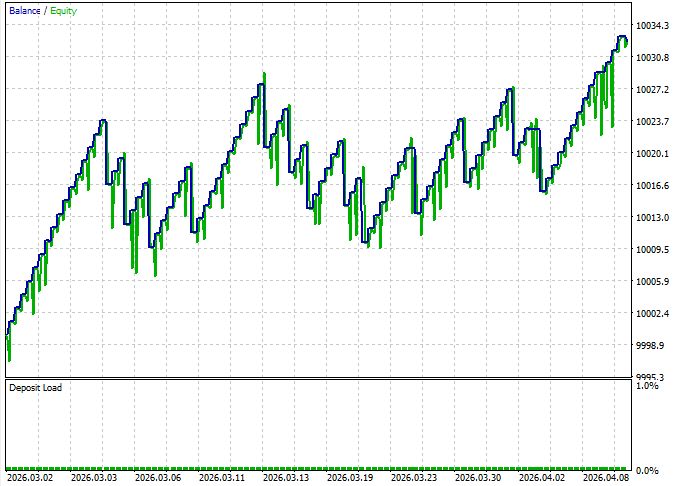
Sharpe Ratio 2.77 и Recovery Factor 1.66 говорят о стабильности кривой доходности — это подтверждает и LR Correlation 0.65 (линейный рост с умеренным разбросом). Z-Score 1.46 при 85.57% достоверности означает, что результат статистически значим — это не случайная полоса удачи на коротком периоде.
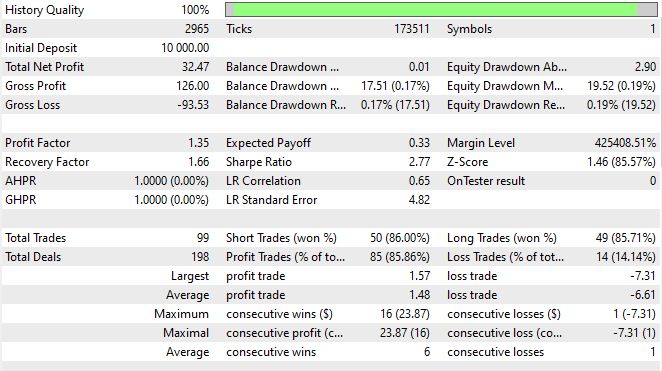
Показательна также дисциплина входов: максимум последовательных убытков равен одному. Это прямое свидетельство работы петли обратной связи — после проигрыша агент корректирует уверенность на основании свежей записи в agent_stats , и следующее решение принимается уже с учётом неудачи. Длинные убыточные серии, характерные для детерминированных советников, здесь гасятся на уровне рассуждения.
Баланс long/short практически идеален — 49 длинных сделок против 50 коротких, с сопоставимым win-rate (85.71% и 86.00%). Это подтверждает, что цепочка не имеет структурного смещения в одну сторону, которое часто проявляется у систем на фиксированных правилах.
Запуск
Скачайте Python 3.10 или новее с сайта python.org. При установке обязательно поставьте галочку "Add python.exe to PATH" — без неё дальнейшие команды не заработают.
pip install langchain langchain-xai langchain-core python-dotenv numpy
Создайте папку C:\langchain_trader и положите в неё файл langchain_memory_server.py .
Откройте командную строку и перейдите в папку проекта:
cd C:\langchain_trader python -m venv venv venv\Scripts\activate
В начале строки должно появиться (venv) — это значит окружение активно.
Если PowerShell ругается на политику выполнения, один раз выполните следующую команду и перезапустите окно:
Запуск:
Set-ExecutionPolicy -Scope CurrentUser -ExecutionPolicy RemoteSigned
С активным (venv) выполните:
pip install langchain langchain-xai langchain-core python-dotenv numpy
Зайдите на console.x.ai, зарегистрируйтесь, в разделе API Keys нажмите Create API Key и скопируйте ключ (начинается на xai- ).
В папке проекта выполните через командную строку:
echo XAI_API_KEY=xai-ваш_ключ_сюда > .env
Именно через командную строку — Блокнот добавляет расширение .txt , и файл не сработает.
Далее вам остается лишь запуск сервера:
python langchain_memory_server.py
Окно должно вывести баннер со строкой LangChain Memory Agent started on 127.0.0.1:8977 . Это окно держите открытым — пока оно работает, сервер принимает подключения.
Настройка MetaTrader 5
Откройте Сервис → Настройки → Советники и включите:
- галочку "Разрешить автоматическую торговлю"
- галочку "Разрешить WebRequest для следующих URL"
- в список URL добавьте http://127.0.0.1:8977
Установка советника в MetaTrader 5
Откройте Файл → Открыть каталог данных, зайдите в папку MQL5\Experts и скопируйте туда файл LangChain_MemoryEA.mq5 .
Вернитесь в MetaTrader 5. В окне Навигатор нажмите правой кнопкой по разделу Советники → Обновить.
Компиляция советника
Двойной клик по LangChain_MemoryEA в Навигаторе откроет MetaEditor. Нажмите F7. Внизу должно появиться 0 error(s), 0 warning(s) .
Если редактор ругается на winhttp.mqh — нужен билд MT5 не ниже 2875. Обновите терминал через Справка → Проверка обновлений.
Запуск советника на графике
Откройте график нужного инструмента на таймфрейме H1, перетащите на него советника из Навигатора. Во вкладке Зависимости поставьте галочку "Разрешить торговлю" и нажмите OK.
Кнопка алготорговли после нажатия станет зелёной, а в логе вкладки Эксперты — запись [OK] WebSocket → 127.0.0.1:8977. Первый сигнал придёт на закрытии ближайшего бара (для H1 — в круглый час).
Итог
Мы разобрали воспроизводимую архитектуру: три слоя (MetaTrader 5 — локальный Python/LangChain — LLM), транспорт WebSocket и ограниченный набор команд (ANALYZE, RESULT, MEM_STATUS, STATUS, STOP).
Практические артефакты: последовательная цепочка агентов Signal→News→Risk, вычисление индикаторов в Python (детерминированно), персистентная память в SQLite и обратная связь RESULT, дающая agent_stats.
Минимально рабочая конфигурация — один символ/TF, on-bar режим, таймаут ANALYZE ≈90 с, быстрые команды ≈5 с, порог уверенности 0.55, правила риска: 1% баланса на сделку, max 3 позиции, min SL 15 пипсов.
Проверить систему просто:
- ANALYZE возвращает JSON с decision_id
- MEM_STATUS отдаёт агрегаты памяти
- В терминале виден chain_log с таймингами и параметрами риска
- После закрытия MetaTrader 5 отправляет RESULT, и память обновляется
Механизм улучшения — не магия LLM, а петля обратной связи + жёсткие детерминированные ограничители: память уменьшает повторение ошибок, риск-агент предотвращает эксцессы. Система остаётся инструментом — требует настройки порогов и мониторинга, но даёт воспроизводимый путь от требования к рабочему контуру.
Полный исходный код советника и Python‑сервера доступен в прикреплённых файлах.
| Название файла | Назначение файла |
|---|---|
| langchain_memory_server.py | Сервер системы |
| LangChain_MemoryEA.mq5 | Советник системы |
| winhttp.mqh | Библиотека связи терминала с сервером через сокеты, была описана в статье |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования