
Преодоление ограничений машинного обучения (Часть 6): Эффективная кросс-валидация исторической памяти рынка

В своем предыдущем обсуждении по теме кросс-валидации мы рассмотрели классический подход и то, как он применяется к данным временных рядов для оптимизации моделей и уменьшения их переобучения. Для удобства ссылка на это обсуждение находится здесь. Мы также предположили, что можем добиться более высоких результатов, чем предполагает традиционная интерпретация. В этой статье мы исследуем «слепые зоны» традиционной кросс-валидации и показываем, как их можно улучшить с помощью методов проверки, специфичных для конкретной предметной области.
Чтобы быстрее донести свою мысль, рассмотрим мысленный эксперимент. Представьте, что вы могли бы совершить путешествие во времени на 400 лет в будущее. По прибытии вы оказываетесь в комнате, заполненной одной газетой за каждый пропущенный вами день — целая гора газет, охватывающих столетия мировых событий, которые вы пропустили. Рядом с этой горой работает терминал MetaTrader 5. Прежде чем начать торговать, сначала необходимо узнать о мире из этих газет.
В каком порядке вы бы их читали? Вам необходимо читать все доступные газеты, или сможете ли вы по-прежнему действовать успешно, усваивая только самую свежую информацию? Насколько далеко в прошлое следует заглядывать в информацию, прежде чем она уже будет учтена в цене и перестанет быть полезной?
На подобные вопросы лучше всего отвечать с помощью кросс-валидации. Однако классические формы кросс-валидации по своей сути предполагают, что вся информация, содержащаяся в прошлом, является необходимой. Мы хотим ввести новую форму кросс-валидации, которая позволит выяснить, верно ли это предположение.
Прежде чем мы перейти к результатам, полученным с помощью нашего терминала MetaTrader 5, давайте сначала порассуждаем на эту тему, чтобы дать читателю четкое представление о мотивации. Вообще говоря, начинать с самой старой газеты в комнате, а затем читать дальше было бы бесполезно.
Рисунок 1: Всегда ли для нас лучше всего ознакомиться со всеми имеющимися у нас историческими данными, описывающими рынок?
Умный трейдер предпочел бы начать с самой свежей информации и двигаться в обратном направлении, поскольку более старая информация быстро теряет актуальность на финансовых рынках. Это подчеркивает тонкую истину, уникальную для финансовой сферы: информация устаревает.
Рисунок 2: Или, возможно, нам лучше исходить из предположения, что финансовые рынки придают большее значение самой последней доступной информации?
В естественных науках информация не подвержена устареванию. Заметки Ньютона о гравитации спустя столетия по-прежнему дают те же результаты. Однако на финансовых рынках стратегии, которые работали в 1950-х годах, сегодня могут оказаться неэффективными. Рыночные условия меняются и некогда ценная информация часто уже учтена в цене или устаревает.
Это приводит нас к важному вопросу: всегда ли использование большего количества исторических данных улучшает прогностическую эффективность наших статистических моделей? Наши результаты свидетельствуют об обратном. Перегрузка модели данными из далекого прошлого может снизить ее точность. Как и в проведенном нами мысленном эксперименте, нет необходимости читать все когда-либо изданные газеты — только те, которые актуальны и сегодня.
Профессиональные трейдеры не начинают свой анализ с первой зафиксированной свечи на каждом рынке, где они торгуют. Однако в машинном обучении мы ожидаем от наших моделей именно этого, слепо полагая, что чем больше, тем лучше. В данной дискуссии оспаривается это предположение и рассматривается вопрос о том, обладают ли финансовые рынки эффективной исторической памятью — пределом, за которым старая информация перестает иметь значение.
Наша цель — изучить взаимосвязь между объемом исторических данных, используемых для обучения, и нашими результатами вне выборки. Мы сосредоточиваемся на том, может ли меньший, более свежий набор данных соответствовать или даже превосходить модель, обученную на всем наборе данных. Для исследования этого вопроса мы использовали данные о рынке примерно за восемь лет и разделили их пополам. Обучающий набор постепенно расширялся на сегменты—10%, 20%, 30%, и так далее, постепенно добавляя более старые данные. Каждому разделу была назначена одна модель. Затем мы измерили погрешность каждой модели по фиксированному тестовому набору продолжительностью примерно 4 года.
Результаты были очевидны: наименьшая ошибка вне выборки произошла в модели, которая обучена с использованием только 80% доступных обучающих данных, а не всех из них. Добавление более старых данных после этого момента только ухудшило точность. Это демонстрирует, что модели могут лучше обучаться при меньшем объеме данных, особенно если более ранние наблюдения больше не отражают текущие рыночные реалии.
Объем данных, используемых для обучения модели, призван служить показателем затрат, связанных с созданием модели. Вообще говоря, чем больше данных мы используем для обучения модели, тем дороже становится ее получение. Таким образом, эти результаты имеют важное значение для практиков на всех уровнях. Понимание их помогает снизить вычислительные затраты, затраты на облачную инфраструктуру, сократить циклы разработки и повысить эффективность модели.
Приступаем к нашему анализу на Python
Теперь мы приступим к анализу данных, экспортируемых из MetaTrader 5, используя стандартные библиотеки Python, на которые мы обычно полагаемся.
#Import the standard python libraries import numpy as np import pandas as pd import seaborn as sns import MetaTrader5 as mt5 import matplotlib.pyplot as plt
Теперь давайте войдем в терминал MetaTrader 5.
#Log in to our MT5 Terminal if(mt5.initialize()): #User feedback print("Logged In") else: print("Failed To Log In")
Logged In
Прежде чем получить исторические данные по инструменту, сначала необходимо выбрать инструмент из обзора рынка.
#Fetch Data on the EURUSD Symbol #First select the EURUSD symbol from the Market Watch if(mt5.symbol_select("EURUSD")): #Found the symbol print("Found the EURUSD Symbol")
Found the EURUSD Symbol
Теперь можно получить котировки от нашего брокера.
#Fetch the historical EURUSD data we need data = pd.DataFrame(mt5.copy_rates_from_pos("EURUSD",mt5.TIMEFRAME_D1,0,3000)) data
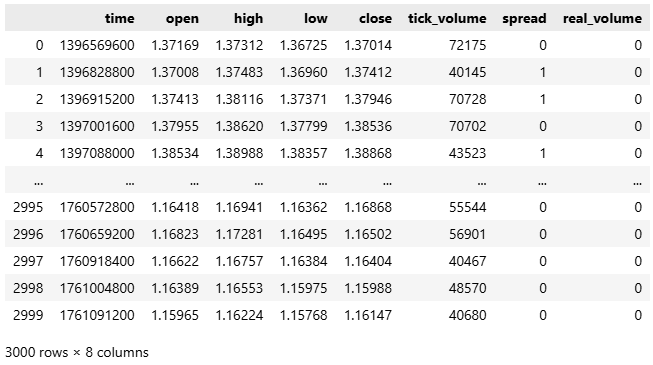
Рисунок 1: Приступаем к нашему анализу исторических рыночных данных по паре EURUSD.
Данные по соглашению поступают к нам в unix-времени, поскольку большинство брокеров используют linux-серверы. Поэтому мы переведем время из секунд в удобочитаемый формат год-месяц-дата.
#Convert the time from seconds to human readable data['time'] = pd.to_datetime(data['time'],unit='s') #Make sure the correct changes were made data
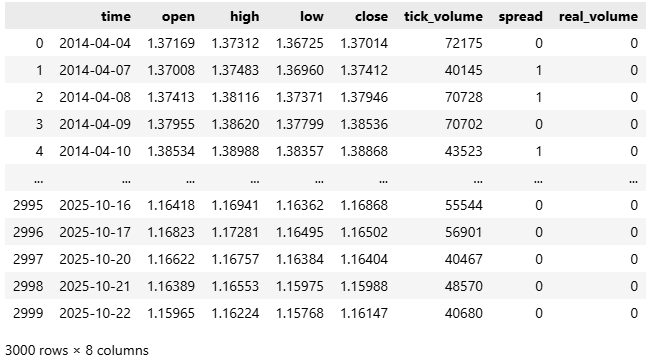
Рисунок 2: Конвертирование нашего представления времени из секунд в удобочитаемый формат.
Теперь сосредоточимся на четырех столбцах, отображающих цены открытия, максимума, минимума и закрытия.
#Select the OHLC columns data = data.iloc[:,:-3] data
Рисунок 3: Сократим объем данных, чтобы можно было сосредоточить наш анализ на четырех основных уровнях цен.
Затем начинаем с создания классической модели прогнозирования временных рядов, в которой прогнозы делаются на шаг вперед.
#Define the classical horizon HORIZON = 1
Следуя этой настройке, помечаем наши данные.
#Label the data data['Target'] = data['True Close'].shift(HORIZON)
Удалим все пропущенные строки, так как пропущенные значения могут привести к ошибкам при обучении моделей из scikit-learn.
#Drop missing rows data.dropna(inplace=True)
Далее импортируем необходимые библиотеки машинного обучения.
#Import cross validation tools from sklearn.linear_model import Ridge,LinearRegression from sklearn.metrics import root_mean_squared_error from sklearn.neural_network import MLPRegressor
Давайте разделим наш набор данных на две равные части — одну для обучения, а другую для тестирования.
#The big picture of what we want to test train , test = data.iloc[:data.shape[0]//2,:] , data.iloc[data.shape[0]//2:,:]
Затем разделяем входные признаки и выходные целевые показатели.
#Define inputs and target X = data.columns[1:-1] y = data.columns[-1]
Чтобы сохранить модульность нашего рабочего процесса, определяем функцию под названием get_model(), возвращающую регрессор случайного леса (Random Forest Regressor). Случайные леса - это мощные модели, способные улавливать сложные нелинейные взаимодействия между переменными, которые могут быть упущены в более простых моделях.
#Fetch a new copy of the model def get_model(): return(RandomForestRegressor(random_state=0,n_jobs=-1))
Определившись с нашей моделью, мы переходим к основному разделу программы. Здесь мы создаем список для записи показателей эффективности модели и указываем общее количество итераций, которые хотим выполнить. Пользователи могут свободно экспериментировать с этим параметром — большее количество итераций позволяет получить более подробную информацию.
На каждой итерации цикла мы обучаем модель на все большей доле обучающих данных. Используя функцию arange в NumPy, мы создаем дроби в диапазоне от 0,1 до 1,0 с шагом 0,1. Для каждой дроби мы обучаем модель, используя только самую свежую часть доступных обучающих данных, и оцениваем ее на фиксированном тестовом наборе. Этот процесс повторяется до тех пор, пока модель не будет обучена на всем обучающем разделе.
После завершения всех итераций мы строим график эффективности модели на обучающей доле. Красным маркером на графике отмечена наименьшая ошибка теста, наблюдаемая на отметке 80%. Это означает, что модель достигла наилучших показателей вне выборки при обучении только на 80% доступных данных.
Важно отметить, что эта процедура отличается от классической кросс-валидации k-fold. В нашей настройке обучающий и тестовый наборы данных не содержат пересекающихся наблюдений. Обучающий набор просто расширяется за счет включения более старых данных, в то время как тестовый набор остается неизменным. Наблюдение минимального уровня эффективности перед достижением 100% свидетельствует о том, что самые старые данные не обладали дополнительной прогностической ценностью.
В заключение, наш эксперимент демонстрирует, что меньшая по размеру и более дешевая модель, обученная на ограниченном, более свежем наборе данных, может превзойти модель, обученную на всем историческом наборе данных.
#Store our performance error = [] #Define the total number of iterations we wish to perform ITERATIONS = 10 #Let us perform the line search for i in np.arange(ITERATIONS): #Training fraction fraction =((i+1)/10) #Partition the data to select the most recent information partition_index = train.shape[0] - int(train.shape[0]*fraction) train_X_partition = train.loc[partition_index:,X] train_y_partition = train.loc[partition_index:,y] #Fit a model model = get_model() #Fit the model model.fit(train_X_partition,train_y_partition) #Cross validate the model out of sample score = root_mean_squared_error(test.loc[:,y],model.predict(test.loc[:,X])) #Append the error levels error.append(score) #Plot the results plt.title('Improvements Made By Historical Data') plt.plot(error,color='black') plt.grid() plt.ylabel('Out of Sample RMSE') plt.xlabel('Progressivley Fitting On All Historical Data') plt.scatter(np.argmin(error),np.min(error),color='red')
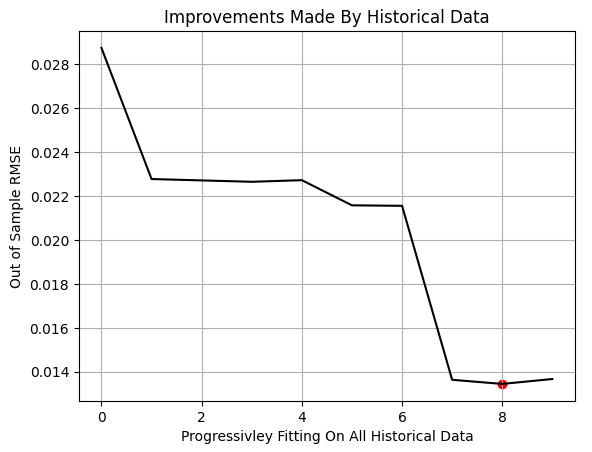
Рисунок 4: Результаты, полученные с помощью нашего терминала MetaTrader 5, показывают, что простое добавление большего количества исторических данных не всегда улучшает результаты.
Теперь мы определяем оптимальный индекс раздела, рассчитанный на основе нашего перебора по сетке.
#Let us select the partition of interest partition_index = train.shape[0] - int(train.shape[0]*(0.8))
Наша методология показывает, что первые 300 наблюдений — данные примерно за один год — содержащиеся в обучающем наборе, были бесполезны для прогнозирования.
train.loc[partition_index:,:]
Рисунок 5: Мы приблизительно оценили представленный выше набор обучающих данных как наиболее актуальный для текущего рынка.
Поэтому мы сравним результаты двух моделей:
- Классическая модель: обучена на всех доступных данных и делает прогноз на один шаг вперед.
- Современный вариант: обучена только на оптимальной части всех доступных исторических данных и предназначена для прогнозирования на несколько шагов вперед.
Для начала определим базовый уровень эффективности, следуя классической настройке. Для этого инициализируем новую модель.
#Prepare the baseline model
model = LinearRegression() Обучим модель на всем наборе данных в соответствии с классической настройкой.
#Fit the baseline model on all the data
model.fit(train.loc[:,X],train.loc[:,y]) Далее готовимся экспортировать модель в формат ONNX (Open Neural Network Exchange). ONNX обеспечивает независимый от фреймворка способ представления и развертывания моделей машинного обучения, позволяя им работать на различных платформах независимо от среды обучения.
#Prepare to export to ONNX import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
После загрузки необходимых зависимостей мы определяем входные и выходные параметры нашей модели.
#Define ONNX model input and output dimensions initial_types = [("FLOAT INPUT",FloatTensorType([1,4]))] final_types = [("FLOAT OUTPUT",FloatTensorType([1,1]))]
Преобразуем модель sklearn в прототипный формат ONNX, используя функцию convert_sklearn.
#Convert the model to its ONNX prototype onnx_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
После преобразования сохраняем модель ONNX на диск с помощью функции onnx.save().
#Save the ONNX model onnx.save(onnx_proto,"EURUSD Baseline LR.onnx")
Начинаем на MQL5
На данном этапе мы готовы установить базовый показатель эффективности. Первым шагом является определение системных констант, которые останутся неизменными на протяжении обоих тестов, гарантируя, что любые различия в результатах возникают исключительно вследствие выбора модели.//+------------------------------------------------------------------+ //| Information Decay.mq5 | //| Gamuchirai Ndawana | //| https://www.mql5.com/ru/users/gamuchiraindawa | //+------------------------------------------------------------------+ #property copyright "Gamuchirai Ndawana" #property link "https://www.mql5.com/ru/users/gamuchiraindawa" #property version "1.00" //+------------------------------------------------------------------+ //| System definitions | //+------------------------------------------------------------------+ #define SYMBOL "EURUSD" #define SYSTEM_TIMEFRAME PERIOD_D1 #define SYSTEM_DATA COPY_RATES_OHLC #define TOTAL_MODEL_INPUTS 4 #define TOTAL_MODEL_OUTPUTS 1 #define ATR_PERIOD 14 #define PADDING 2
Загрузим модель ONNX. Напомним, что эта базовая модель обучена на всех исторических данных и настроена на прогнозирование на один шаг вперед.
//+------------------------------------------------------------------+ //| System resources we need | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD Baseline LR.onnx" as const uchar onnx_buffer[];
Далее загружаем необходимые библиотеки — как для исполнения сделок, так и нашу пользовательскую вспомогательную библиотеку, которая извлекает важную торговую информацию, такую как минимальный размер лота и текущие цены bid и ask.
//+------------------------------------------------------------------+ //| Libraries | //+------------------------------------------------------------------+ #include <Trade\Trade.mqh> #include <VolatilityDoctor\Trade\TradeInfo.mqh> CTrade Trade; TradeInfo *TradeHelper;
Также определяем набор глобальных переменных, которые будут использоваться во всем приложении.
//+------------------------------------------------------------------+ //| Global variables | //+------------------------------------------------------------------+ long onnx_model; vectorf onnx_inputs,onnx_output; MqlDateTime current_time,time_stamp; int atr_handler; double atr[];
После завершения настройки мы переходим к этапу инициализации приложения. Здесь мы создаём экземпляр модели ONNX из буфера, определённого в заголовке программы. Выполняем проверку на наличие ошибок, подтверждая, что хэндл модели является действительным. Если обнаружен недействительный хэндл, отображается сообщение об ошибке, и инициализация прерывается. В противном случае переходим к определению входные и выходные показателей модели. Любые обнаруженные здесь ошибки аналогично сообщаются пользователю. Если инициализация прошла успешно, мы устанавливаем начальные значения ключевых глобальных переменных, таких как текущее время, создаем новые экземпляры классов и инициализируем технический индикатор, от которого зависит наше приложение.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Create the ONNX model from its buffer onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DATA_TYPE_FLOAT); //--- Check for errors if(onnx_model == INVALID_HANDLE) { //--- User feedback Print("An error occured loading the ONNX model:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Setup the ONNX handler input shape else { //--- Define the I/O shapes ulong input_shape[] = {1,4}; ulong output_shape[] = {1,1}; //--- Attempt to set input shape if(!OnnxSetInputShape(onnx_model,0,input_shape)) { //--- User feedback Print("Failed to specify the correct ONNX model input shape:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Attempt to set output shape if(!OnnxSetOutputShape(onnx_model,0,output_shape)) { //--- User feedback Print("Failed to specify the correct ONNX model output shape:\n",GetLastError()); //--- Abort return(INIT_FAILED); } //--- Mark the current time TimeLocal(current_time); TimeLocal(time_stamp); //--- Setup the trade helper TradeHelper = new TradeInfo(SYMBOL,SYSTEM_TIMEFRAME); //--- Setup our technical indicators atr_handler = iATR(Symbol(),SYSTEM_TIMEFRAME,ATR_PERIOD); //--- Success return(INIT_SUCCEEDED); } }
Когда приложение больше не используется, мы обеспечиваем надлежащую очистку ресурсов, освобождая память, выделенную для модели ONNX, технического индикатора и других динамических объектов, созданных во время выполнения.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- OnnxRelease(onnx_model); IndicatorRelease(atr_handler); delete(TradeHelper); }
Основная логика приложения сосредоточена в функции OnTick(). Каждый раз, когда появляется новая рыночная цена, мы обновляем текущее время с помощью функции TimeLocal(), возвращающей местное время компьютера, на котором запущен терминал MetaTrader 5. Затем сравниваем currenttime.dayofyear и timestamp.dayofyear.
Поскольку Timestamp обновлялась в последний раз во время инициализации, это условие выполнится только после смены дня. Когда это условие выполняется, мы обновляем временную метку до текущего времени, обновляем буферы технических индикаторов и подготавливаем входные и выходные векторы для модели ONNX.
Затем запрашиваем у модели новый прогноз, используя команду OnnxRun(). Эта функция принимает экземпляр модели ONNX, параметры флагов для специальных атрибутов модели, а также подготовленные входные и выходные векторы.
После получения прогноза отображаем обратную связь пользователю. Если условий открытых сделок не существует, мы выполняем действия, основанные на выходных данных модели. Однако, если модель не дает прогноза, мы уведомляем пользователя о возникновении ошибки.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check for updated candles TimeLocal(current_time); //--- Periodic one day test if(current_time.day_of_year != time_stamp.day_of_year) { //--- Update the time stamp TimeLocal(time_stamp); //--- Update technical indicators CopyBuffer(atr_handler,0,0,1,atr); //--- Prepare a prediction from our model onnx_inputs = vectorf::Zeros(TOTAL_MODEL_INPUTS); onnx_inputs[0] = (float) iOpen(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[1] = (float) iHigh(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[2] = (float) iLow(Symbol(),SYSTEM_TIMEFRAME,0); onnx_inputs[3] = (float) iClose(Symbol(),SYSTEM_TIMEFRAME,0); //--- Also prepare the outputs onnx_output = vectorf::Zeros(TOTAL_MODEL_OUTPUTS); //--- Fetch a prediction from our model if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_inputs,onnx_output)) { //--- Give user feedback Comment("Trading Day: ",time_stamp.year," ",time_stamp.mon," ",time_stamp.day_of_week,"\nForecast: ",onnx_output[0]); //--- Check if we have an open position if(PositionsTotal() == 0) { //--- Long condition if(onnx_output[0] > iClose(SYMBOL,SYSTEM_TIMEFRAME,0)) Trade.Buy(TradeHelper.MinVolume(),SYMBOL,TradeHelper.GetAsk(),TradeHelper.GetBid()-(atr[0]*PADDING),TradeHelper.GetBid()+(atr[0]*PADDING),""); //--- Short condition if(onnx_output[0] < iClose(SYMBOL,SYSTEM_TIMEFRAME,0)) Trade.Sell(TradeHelper.MinVolume(),SYMBOL,TradeHelper.GetBid(),TradeHelper.GetAsk()+(atr[0]*PADDING),TradeHelper.GetAsk()-(atr[0]*PADDING),""); } //--- Manage our open position else { //--- This control branch remains empty for now } } //--- Something went wrong else { Comment("Failed to obtain a prediction from our model. ",GetLastError()); } } } //+------------------------------------------------------------------+
Наконец, отменим определение всех системных констант, созданных нами ранее.
//+------------------------------------------------------------------+ //| Undefine system constants | //+------------------------------------------------------------------+ #undef SYMBOL #undef SYSTEM_DATA #undef SYSTEM_TIMEFRAME #undef ATR_PERIOD #undef PADDING #undef TOTAL_MODEL_INPUTS #undef TOTAL_MODEL_OUTPUTS
Определив наше приложение, мы теперь готовы приступить к тестированию. Мы проводим свою оценку в течение пятилетнего периода тестирования на исторических данных, указанного ранее. Мы начинаем с выбора базовой версии приложения, которое мы только что создали, и определения соответствующих дат обучения.

Рисунок 6: Даты, которые мы выбрали для нашего периода тестирования на исторических данных, выходят за рамки периода обучения, указанного на рисунке 3.
Далее мы указываем условия эмуляции, при которых будет выполняться тестирование на истории. Напомним, что мы используем каждый тик, основанный на реальных тиках, чтобы зафиксировать реалистичную эволюцию рыночных условий. Параметр задержки настроен на случайную задержку; это позволяет нам надежно имитировать непредсказуемую природу реальных торговых условий.

Рисунок 7: Выбранные нами условия тестирования на истории предназначены для имитации неопределенности реальных рыночных условий.
Анализируя базовые показатели эффективности, мы видим, что первоначальная версия нашего приложения принесла общую прибыль в размере 90 долларов за пятилетний период тестирования на истории. Хотя этот результат не совсем плох, он далек от впечатляющего. При более внимательном рассмотрении обнаруживается тревожная особенность в структуре сделок: приложение вообще не совершало длинных сделок на протяжении всего тестирования на истории. Все заключенные сделки были исключительно короткими позициями. Такое поведение не было ни ожидаемым, ни запланированным во время разработки, и не существует четкого объяснения, почему модель вела себя именно так. Кроме того, точность стратегии составляла примерно 50%, что едва превышает вероятность. Еще более тревожным было то, что ожидаемая отдача была отрицательной, что указывало на то, что приложение, скорее всего, потеряет деньги в долгосрочной перспективе.
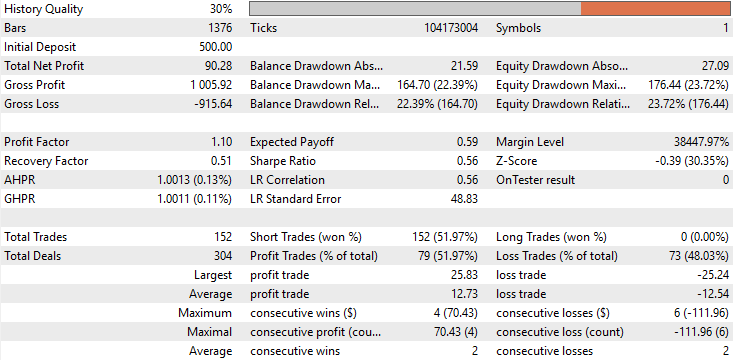
Рисунок 8: Подробный статистический анализ результатов, полученных в результате проведенного нами бэктеста.
Изучая кривую эквити, мы видим выраженную волатильность и нестабильность на протяжении всего периода тестирования. По мере приближения к ноябрю 2022 года баланс счета перестает расти и вступает в длительную фазу консолидации, которая сохраняется в течение почти трех лет в рамках периода тестирования на истории. В целом, базовая модель не способствует значимому увеличению счета и не дает уверенности в его долгосрочной жизнеспособности.
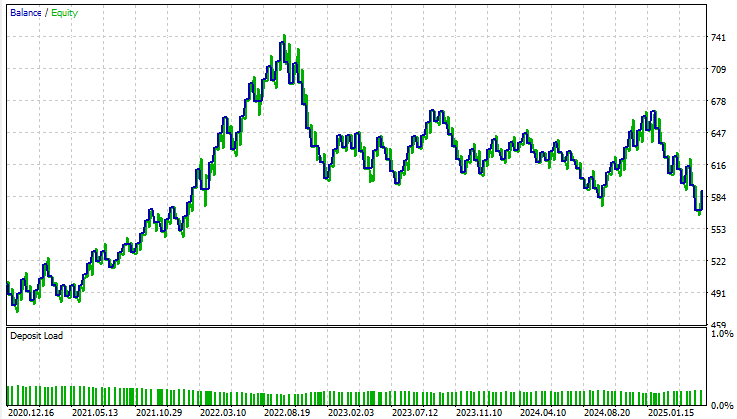
Рисунок 9: Визуализация кривой эквити, которую мы получили, следуя традиционным рекомендациям по созданию статистической модели.
Изменение нашей ONNX-модели
Теперь, когда мы установили базовые показатели эффективности, полученные при классической настройке, давайте выйдем за традиционные рамки и изменим нашу модель ONNX, чтобы лучше отразить то, как на самом деле работают профессиональные трейдеры. Первое крупное изменение отличается от традиционной философии дизайна. Вместо того чтобы разрабатывать модели, которые заглядывают только на шаг вперед, мы теперь разрабатываем нашу модель с расчетом на десять шагов в будущее. Трейдеры, принимающие решения вручную, не торгуют от свечи к свече; они действуют, основываясь на более широкой картине ожидаемого движения рынка. Поэтому наша модель должна отражать ту же самую дальновидную интуицию. HORIZON = 10 Далее мы определяем оптимальный раздел данных, рассчитанный с использованием методов кросс-валидации.
#Let us select the partition of interest partition_index = train.shape[0] - int(train.shape[0]*(0.8)) train.loc[partition_index:,:]
Затем мы загружаем новую модель, идентичную по архитектуре базовой модели.
#Prepare the improved baseline model
model = LinearRegression() Обучаем новую модель исключительно на этом оптимальном разделе данных.
#Fit the improved baseline model
model.fit(train.loc[partition_index:,X],train.loc[partition_index:,y]) После обучения мы преобразуем эту улучшенную модель в ее прототип ONNX. Но следует помнить, что обе модели имеют одинаковую сложность.
#Convert the model to its ONNX prototype onnx_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
Наконец, сохраняем модель ONNX в файл.
#Save the ONNX model onnx.save(onnx_proto,"EURUSD Improved Baseline LR.onnx")
Улучшение наших первоначальных результатов
Пользователь должен иметь в виду, что единственным компонентом, требующим модификации, является ссылка на файловый ресурс ONNX, расположенная в заголовке приложения. Остальная часть системы остается неизменной и будет работать точно так же, как и раньше. //+------------------------------------------------------------------+ //| System resources we need | //+------------------------------------------------------------------+ #resource "\\Files\\EURUSD Improved Baseline LR.onnx" as const uchar onnx_buffer[];
Затем мы выбираем эту улучшенную версию приложения для тестирования в течение того же пятилетнего периода, что и базовая модель. Важно отметить, что все условия тестирования на исторических данных, включая случайную задержку и выполнение на основе тиков, идентичны показанным на рисунке 7 для обеспечения сопоставимости.
Рисунок 10: Выбираем нашу новую и улучшенную версию приложения, чтобы сравнить реализованные нами улучшения.
При анализе подробной статистики результатов разница между этими двумя приложениями становится сразу очевидной. Общая чистая прибыль от усовершенствованной модели увеличилась более чем в три раза, примерно с 90 до 330 долларов. Теперь мы можем наблюдать, что первоначальный перекос в распределении сделок полностью исправлен. В базовой версии нашего приложения все сделки были исключительно короткими позициями — непреднамеренный дисбаланс в поведении модели. В отличие от этого, улучшенная версия теперь открывает как длинные, так и короткие позиции сбалансированным образом, что отражает более естественный процесс принятия решений профессиональным трейдером.
Кроме того, наблюдается значительное улучшение точности, которая выросла с примерно 52% до почти 60%. Это обнадеживающее развитие событий, свидетельствующее о том, что внутренняя логика принятия решений в модели стала более последовательной и точной.
Однако, что меня больше всего удивило в этом анализе, так это то, что общее количество сделок осталось одинаковым в обеих моделях. В ходе бэктеста каждая версия исполнила ровно 152 сделки. Несмотря на это, усовершенствованная модель позволила более чем втрое увеличить общую чистую прибыль, продемонстрировав явный рост эффективности. Иными словами, при том же количестве сделок улучшенная модель показала существенно более высокую доходность. Более того, как коэффициент Шарпа, так и ожидаемая прибыль значительно выросли — это еще одно доказательство того, что модель более разумно распределяет капитал и выбирает время для совершения сделок.
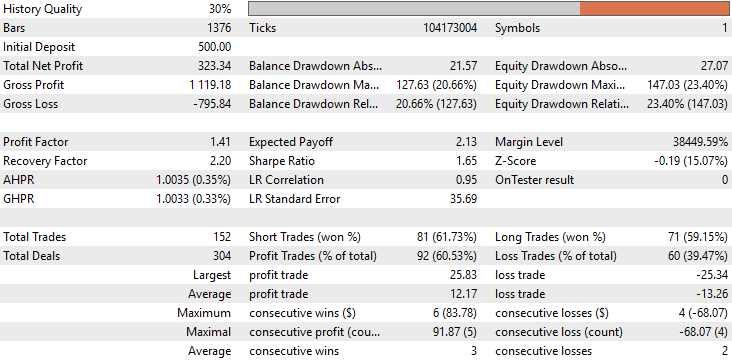
Рисунок 11: Подробный анализ полученных нами результатов показывает, что внесенные нами изменения были уместными.
При изучении кривой эквити, полученной в улучшенной версии, разница бросается в глаза. Длительный период консолидации, который досаждал первоначальному приложению и длился почти три года, полностью исчез. Новая модель демонстрирует устойчивый и стабильный рост, что свидетельствует об эффективном устранении любых структурных ограничений или «слепых зон», существовавших в предыдущей версии. Этот результат одновременно обнадеживает и подтверждает, что внесенные нами улучшения оказали значимое влияние.
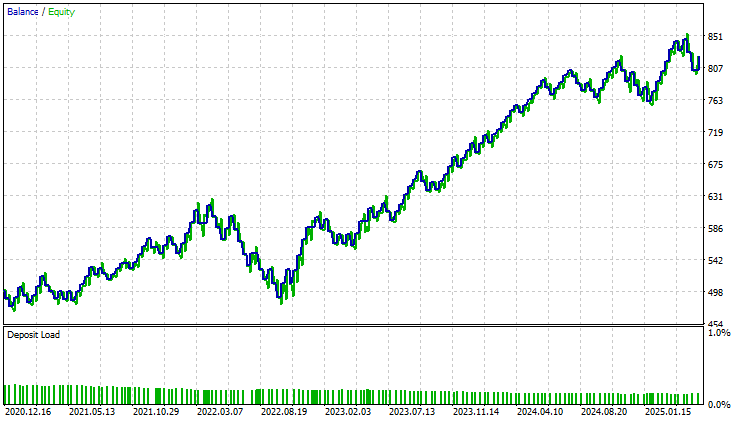
Рисунок 12: Улучшенная кривая эквити, которую мы получили, демонстрирует, что внесенные нами изменения обеспечили стабильность нашей системы в течение 5-летнего периода тестирования.
Заключение
После прочтения этой статьи читатель должен получить практические знания об истинной природе статистического обучения в алгоритмической торговле. Один из ключевых выводов заключается в том, что слепое следование традиционным статистическим принципам не всегда приносит пользу нам как алгоритмическим трейдерам. Мы не можем просто позаимствовать эвристику “больших данных” и ожидать, что она будет работать без изменений в нашей области, где актуальность данных сильно зависит от настоящего момента.
В этой статье также приведены практические рекомендации по сохранению капитала, который в противном случае мог бы быть использован не по назначению при приобретении чрезмерно сложных или неэффективных моделей. Представленная здесь информация может напрямую обеспечить реальную экономию средств, причем не только на капитальных затратах, но и на вычислительных ресурсах, времени разработки и затратах на инфраструктуру, связанных с внедрением передовых систем машинного обучения.
Наконец, теперь читатель должен иметь более четкое представление о «слепых зонах», присущих классическим парадигмам кросс-валидации. Мы часто упускаем из виду, действительно ли все данные, которые мы включаем, способствуют достижению нашей цели. Представленный здесь анализ раскрывает новую форму переобучения, о которой классическое статистическое обучение дает мало рекомендаций. Он показывает, что попытка обучить модель на основе всех доступных данных сама по себе может быть непризнанным источником неэффективности. Взятые вместе, эти уроки позволяют нам создавать более эффективные и прибыльные модели машинного обучения для алгоритмической торговли.
| Название файла | Описание файла |
|---|---|
| Information Decay Baseline.mq5 | Базовое торговое приложение, созданное с использованием классических парадигм машинного обучения. |
| Information Decay Improved Baseline.mq5 | Улучшенное приложение, разработанное с использованием эффективной кросс-валидации исторической памяти рынка (EMCV) - метода, привязанного к предметной области, представленного в этой работе. |
| Limitations of Cross Validation 1.ipynb | Jupyter Notebook использовался для анализа рыночных данных и создания наших моделей ONNX. |
| EURUSD Baseline LR.onnx | Классическая модель ONNX, созданная в соответствии с классическими лучшими практиками. |
| EURUSD Improved Baseline LR.onnx | Усовершенствованная модель ONNX, которая превзошла классический базовый уровень благодаря использованию новых передовых методов, связанных с предметной областью, описанных в настоящей работе. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/20010
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования