
Нейросети в трейдинге: Обучение глубоких спайкинговых моделей (Интеграция спайков)

Введение
Финансовые рынки во все времена были ареной борьбы противоположностей: порядка и хаоса, рационального расчёта и иррациональных всплесков эмоций. Они напоминают бурное море, где на поверхности видна игра волн — ценовых колебаний, а под водой скрыты сложные течения — фундаментальные факторы, макроэкономические сдвиги и психологические настроения участников. В этом мире каждый трейдер, инвестор или исследователь ищет ключ к пониманию закономерностей. Одни полагаются на интуицию, другие — на строгие формулы, но всё больше внимания в последние десятилетия уделяется искусственному интеллекту и нейросетевым архитектурам.
Классические нейронные сети, построенные для обработки изображений и аудио, казались универсальными инструментами. Но когда мы переносим их в область финансовых временных рядов, особенно на высокочастотных данных, вскрываются фундаментальные противоречия. Рынок — это не плавная кривая функции, а поток событий: сделки, заявки, всплески волатильности, рывки ликвидности. Это серия дискретных ударов метронома, где каждый тик цены можно рассматривать как импульс. Именно поэтому спайковые нейронные сети (SNN, Spiking Neural Networks) в последние годы привлекли внимание исследователей. Они ближе к самой природе рынка, где всё измеряется последовательностью событий во времени.
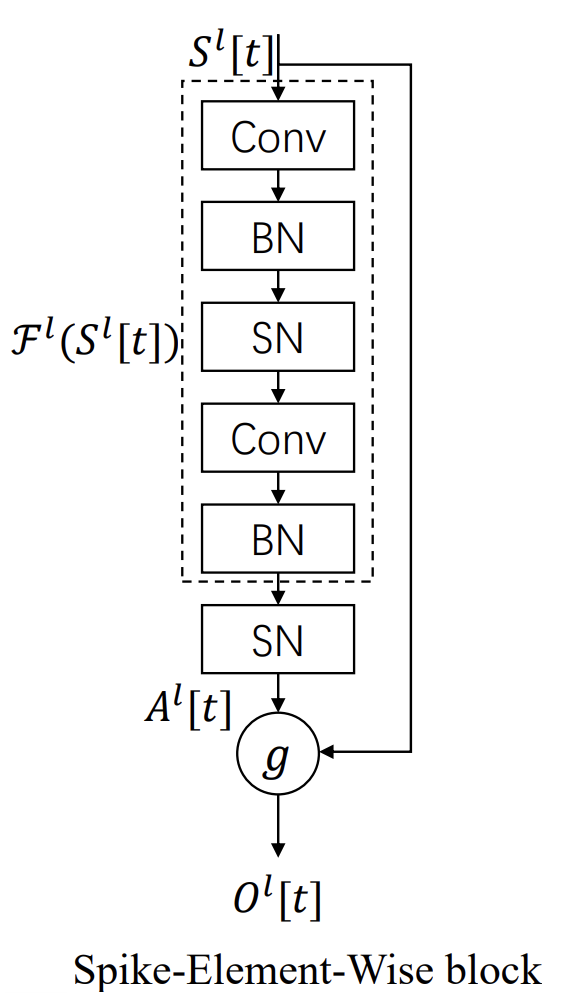
Но переход от классических моделей к спайковым — это не просто техническая деталь, а качественное изменение парадигмы. То, что работает в мире гладких активаций, в спайковом контексте может оказаться бесполезным. Яркий пример — знаменитая архитектура ResNet. В классическом варианте ResNet произвёл революцию в машинном обучении, позволив строить десятки и даже сотни слоёв без потери обучаемости. Секрет заключался в shortcut-связях, которые позволяли сигналу и градиенту проходить через сеть почти без искажений.
И здесь важно подчеркнуть. В обычном ResNet shortcut не является чистым обходом слоя. Он тоже проходит через функцию активации ReLU. Однако, поскольку ReLU положительна и непрерывна, shortcut передаётся почти тождественно, и градиенты свободно циркулируют. Именно это свойство сделало ResNet символом глубины и стабильности.
Совсем иначе обстоит дело в спайковых моделях. Здесь активация — это бинарный импульс. Shortcut, попадая под спайковую функцию активации, теряет идентичность. Бинаризация разрушает саму идею shortcut как прямого канала. В результате, глубина перестаёт работать: градиенты либо затухают, либо становятся нестабильными, и сеть теряет обучаемость. Здесь авторы SEW-ResNet предложили решение, которое можно назвать одновременно простым и гениальным.
Они вынесли shortcut за скобки функции активации. Вместо того чтобы пропускать его через бинарную активацию, они оставили shortcut в стороне и объединили его с результатом остаточной трансформации после активации, задав это объединение через отдельную поэлементную операцию. Таким образом, shortcut вновь обретает свою истинную роль. Он действительно тождественен, и сигнал не теряется в дискретной динамике.
Это изменение выглядит минимальным, но его последствия огромны. Теперь глубокие спайковые модели вновь становятся обучаемыми. А значит, можно строить модели с десятками слоёв и ожидать, что они будут работать так же устойчиво, как и их предшественники в мире классических сетей.
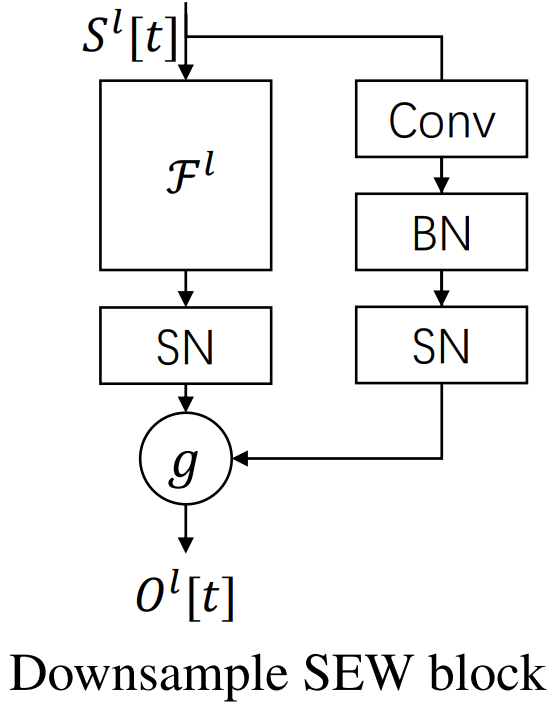
Кроме того, авторы SEW-ResNet расширили идею shortcut. В классическом ResNet операция объединения была жёстко задана — простое сложение. В SEW-ResNet появляется пространство для выбора: сложение, логическое AND, его инверсия и другие функции g(•,•). Это открывает новую главу в проектировании архитектур. Shortcut можно подстраивать под конкретную задачу.
В финансовом контексте это особенно ценно. Представим валютный рынок. Короткие импульсы, вызванные новостями, накладываются на долгосрочные тренды, формируемые политикой центральных банков. Для акций характерны сезонные колебания и влияние квартальной отчётности, а для криптовалют — внезапные всплески активности сообществ и технологические апдейты. Одной архитектуры для всех процессов мало — нужна гибкость. SEW-ResNet её даёт. Можно выбрать такой shortcut, который лучше слышит особенности конкретного актива.
Для трейдера и исследователя это означает новое качество анализа. Если классические методы позволяют уловить лишь среднюю температуру рынка, то SEW-ResNet открывает возможность одновременно чувствовать быстрые рыночные тики и долгосрочные движения. Shortcut становится чем-то вроде надёжного канала памяти, который не даёт модели забывать о том, что происходило раньше, и при этом позволяет ей воспринимать новые события.
SEW-ResNet можно рассматривать как важный шаг в эволюции спайковых моделей. Это принципиальное восстановление ключевого механизма глубины в условиях бинарной динамики.
Авторская визуализация фреймворка представлена ниже.
В практической части предыдущей статьи мы сосредоточились на фундаментальных элементах спайкового нейрона, адаптированного к финансовым временным рядам. Особое внимание было уделено двум ключевым механизмам:
- обучаемым порогам активации;
- гейтам накопления мембранного потенциала.
Обучаемый порог активации позволит нейрону гибко регулировать чувствительность к входным импульсам. В рыночной терминологии это напоминает адаптацию к волатильности. Нейрон учится различать шумовые колебания цены и действительно значимые события. Благодаря этому, даже при сильной динамике рынка модель сохраняет способность реагировать только на существенные сигналы, избегая переизбытка ложных спайков.
Гейты накопления мембранного потенциала обеспечивают контроль за интеграцией анализируемых событий. Вместо простого суммирования входящих спайков, нейрон управляет аккумулированием потенциала и когда он приводит к генерации спайка. Эта особенность позволит модели выстраивать временную память — фиксировать последовательности значимых событий и принимать решение о спайке только тогда, когда накопленный сигнал превышал порог, адаптированный под текущий рыночный контекст.
Эти механизмы были реализованы на уровне базового спайкового нейрона, создавая платформу для построения более сложных архитектур.
Оптимизация OpenCL-программы
Сегодня мы продолжаем начатую работу. Но прежде чем двигаться дальше в реализации подходов, предложенных авторами фреймворка SEW-ResNet, сделаем небольшое отступление и обратим внимание на ещё одну важную особенность спайковых моделей — молчание нейрона до появления события. Это свойство позволяет значительно снизить вычислительные затраты, поскольку нейрон ожидает сигнала и не тратит ресурсы на обработку пустых входов. В реализованных нами ранее алгоритмах нулевой вход не приносит экономии ресурсов. Операция умножения на ноль выполнялась каждый раз, хотя результат заранее известен.
В классических нейросетевых моделях такое поведение вполне оправдано. Нулевой вход — редкость, исключение из правил, и введение дополнительного контроля часто только усложняет и замедляет вычисления. Но спайковые модели работают иначе. Здесь большинство входов в каждый момент времени оказываются нулевыми, поскольку значимыми являются лишь отдельные события — короткие импульсы на фоне тишины. Поэтому добавление точки контроля, позволяющей пропускать операции с нулями, становится естественным и оправданным решением.
Если провести параллель с финансовыми рынками, молчание нейрона напоминает «тишину» на графике между всплесками торговой активности. В периоды, когда рынок спокоен, каждый тик цены мало информативен — и анализировать каждый из них было бы пустой тратой ресурсов. Спайковый нейрон ведёт себя аналогично. Он остаётся неактивным, пока не поступит сигнал, несущий значимую информацию. Как только появляется событие (резкий всплеск объёма, пробой уровня или новостной импульс) — нейрон мгновенно реагирует. Такой подход экономит вычислительные ресурсы и повышает устойчивость сети к шуму, фильтруя малозначимые изменения, которые не несут ценности.
Однако, с целью сохранения универсальности компонентов нашей библиотеки, мы не стали создавать новые объекты, а решили добавить точки контроля в существующие алгоритмы. Начнём с прямого прохода полносвязного слоя, где были внесены наиболее значимые изменения в кернел OpenCL-программы.
Во-первых, была добавлена проверка нулевых значений анализируемых данных. Во-вторых, мы отказались от классического цикла по всем исходным данным в рамках одного потока. Вместо этого вычисления распределяются между потоками рабочей группы, а результаты суммируются после завершения работы всех потоков. Такой подход значительно повышает эффективность и позволяет использовать параллельные возможности GPU.
__kernel void FeedForward(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, const int inputs, const int activation ) { const int i = get_global_id(0); const int total_out = get_global_size(0); const int loc = get_local_id(1); const int total_loc = get_local_size(1);
Алгоритм кернела начинается с определения глобального идентификатора текущего потока. Каждому нейрону в слое соответствует отдельная рабочая группа потоков, объединенных по первому измерению пространства задач. Это позволяет вычислять выходы всех нейронов параллельно.
Затем определяем локальный идентификатор потока в рабочей группе и общее количество потоков в группе. Это важно для распределения вычислений по нескольким потокам, чтобы ускорить обработку больших объемов анализируемых данных.
Локальный массив Temp используется для хранения промежуточных сумм внутри рабочей группы. Он обеспечивает координацию между потоками, когда каждый поток считает свою часть произведений входов и весов.
__local float Temp[LOCAL_ARRAY_SIZE];
Далее создаются локальные переменные для накопления суммы (sum) и временного хранения значения входа (inp). Переменная shift определяет смещение в матрице весов для текущего нейрона. Поскольку веса хранятся в плоском массиве, смещение позволяет корректно обращаться к элементам, соответствующим конкретному нейрону.
float sum = 0; float inp; int shift = RCtoFlat(i, 0, total_out, (inputs + 1), 1);
После завершения подготовительной работы, мы создаем основной цикл вычисления суммы входов, умноженных на веса. Здесь мы оставляем цикл, как страховочный вариант для обработки больших тензоров исходных данных, превышающих допустимый размер рабочей группы. Каждому потоку достаётся свой набор входов, что позволяет распределить работу.
for(int k = loc; k < inputs; k += total_loc) { inp = IsNaNOrInf(matrix_i[k], 0.0f); if(inp == 0.0f) continue;
В теле цикла мы сначала извлекаем значение из буфера исходных данных. Каждая итерация берёт очередной входной сигнал. Если получаем нулевое значение, мы немедленно переходим к следующей итерации, не выполняя дальнейших операций. Такой подход позволяет пропускать дорогостоящие обращение к глобальной памяти для чтения весов и саму операцию умножения. Контроль нулевых значений превращает цикл в интеллектуальный фильтр, который концентрируется только на значимых событиях, экономя вычислительные ресурсы и ускоряя анализ рыночных данных.
При получении значимого сигнала, аккумулируем произведения входов и весов.
sum += IsNaNOrInf(inp * matrix_w[shift + k], 0.0f); } if(loc == 0) sum += IsNaNOrInf(matrix_w[shift + inputs], 0.0f);
После завершения всех итераций цикла только один поток рабочей группы добавляет смещение. А затем выполняем суммирование всех частичных результатов потоков внутри рабочей группы с использованием локального массива Temp. Это обеспечивает корректное объединение результатов распараллеленных вычислений.
sum = LocalSum(sum, 1, Temp); //--- if(loc == 0) matrix_o[i] = fActivation(sum, activation); }
Наконец, к полученной сумме применяется выбранная функция активации.
Такой подход сохраняет универсальность слоя и позволяет в дальнейшем интегрировать его в более сложные классические и спайковые модели, не изменяя архитектуру сети. Одновременно мы получаем экономию ресурсов и ускорение работы при анализе спайков, где множество входов на каждом шаге могут быть нулевыми, отражая периоды тишины на рынке.
Стоит обратить внимание, что добавление рабочих групп вносит изменения в пространство задач выполнения кернела. Соответственно, для корректной работы объекта требуется внести точечные правки в метод постановки кернела в очередь выполнения.
bool CNeuronBaseOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(OpenCL) == POINTER_INVALID || CheckPointer(NeuronOCL) == POINTER_INVALID) return false; uint global_work_offset[2] = { 0, 0 }; uint global_work_size[2] = { Output.Total(), (uint)MathMin((NeuronOCL.Neurons() + 3) / 4, OpenCL.GetMaxLocalSize(1)) }; uint local_work_size[2] = { 1, global_work_size[1] }; //--- const int kernel = def_k_FeedForward; setBuffer(kernel, def_k_ff_matrix_w, NeuronOCL.getWeightsIndex()) setBuffer(kernel, def_k_ff_matrix_i, NeuronOCL.getOutputIndex()) setBuffer(kernel, def_k_ff_matrix_o, Output.GetIndex()) setArgument(kernel, def_k_ff_inputs, NeuronOCL.Neurons()) setArgument(kernel, def_k_ff_activation, (int)activation) //--- kernelExecuteLoc(kernel, global_work_offset, global_work_size, local_work_size) //--- return true; }
Аналогичную точку контроля нулевых значений мы добавляем и в кернел прямого прохода сверточного слоя. Однако в данном случае мы не используем рабочие группы. Это связано с тем, что ядра свертки предполагаются относительно небольшими, и распределение вычислений между потоками в данном случае не даёт значительного ускорения.
Тем не менее проверка нулевых входов остаётся критически важной. Она позволяет пропускать лишние операции умножения и обращения к глобальной памяти даже в сверточных слоях, экономя ресурсы при обработке больших объёмов финансовых временных рядов.
__kernel void FeedForwardConv(__global const float *matrix_w, __global const float *matrix_i, __global float *matrix_o, const int inputs, const int step, const int window_in, const int window_out, const int activation ) { const size_t i = get_global_id(0); const int out = get_global_id(1); const size_t v = get_global_id(2); const size_t outputs = get_global_size(0); //--- const int shift_out = window_out * i; const int shift_in = step * i; //--- const int shift_var_in = v * inputs; const int shift_var_out = v * window_out * outputs; const int shift_var_w = v * window_out * (window_in + 1); //--- float sum = 0; float inp; //--- int shift = (window_in + 1) * out; int stop = (window_in <= (inputs - shift_in) ? window_in : (inputs - shift_in)); for(int k = 0; k < stop; k ++) { inp = IsNaNOrInf(matrix_i[shift_var_in + shift_in + k], 0.0f); if(inp == 0.0f) continue; sum += IsNaNOrInf(inp * matrix_w[shift_var_w + shift + k], 0.0f); } sum += IsNaNOrInf(matrix_w[shift_var_w + shift + window_in], 0.0f); //--- matrix_o[shift_var_out + out + shift_out] = fActivation(sum, activation);; }
Таким образом, точка контроля нулевых входов становится универсальным инструментом оптимизации, применимым как к полносвязным, так и к сверточным слоям, сохраняя эффективность и точность работы модели.
Модуль Spike ResNeXt Bottleneck
После выполнения оптимизации существующих алгоритмов мы возвращаемся к реализации подходов, предложенных авторами фреймворка SEW-ResNet. Однако мы сделаем небольшое отступление от авторской работы и внедрим предложенные решения в архитектуру ResNeXt.
Выбор ResNeXt обусловлен её особенностями. Она сочетает в себе преимущества ResNet (остаточные блоки и shortcut-связи) с идеей разветвлённых блоков, которые позволяют параллельно обрабатывать несколько независимых путей. Такая архитектура даёт дополнительную гибкость и улучшает способность сети к извлечению признаков.
Внедрение SEW-блоков в ResNeXt открывает новые возможности для работы с финансовыми временными рядами. Множество параллельных путей модели теперь может обрабатывать различные аспекты анализируемых данных. Одни — фиксируют краткосрочные импульсы и всплески волатильности; другие — улавливают долгосрочные тренды; Shortcut, выведенный за пределы спайковой активации, сохраняет целостность сигнала, а обучаемые пороги и гейты накопления потенциала мембраны обеспечивают адаптацию к конкретным рыночным условиям.
Таким образом, мы получаем гибридную архитектуру, сочетающую идеи SEW-ResNet и ResNeXt, способную глубоко и эффективно анализировать финансовые временные ряды, сокращая избыточные вычисления и повышая устойчивость к шуму.
Начинаем работу с создания модуля Bottleneck в рамках класса CNeuronSpikeResNeXtBottleneck, который наследует функциональность базового спайкового нейрона с активацией CNeuronSpikeActivation. Этот объект становится фундаментальным строительным блоком для интеграции SEW-блоков в архитектуру ResNeXt.
class CNeuronSpikeResNeXtBottleneck : public CNeuronSpikeActivation { protected: CLayer cBottleneck; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeResNeXtBottleneck(void) {}; ~CNeuronSpikeResNeXtBottleneck(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, uint group_size, uint groups, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeResNeXtBottleneck; } //--- methods for working with files virtual bool Save(int const file_handle) override; virtual bool Load(int const file_handle) override; //--- virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Внутри класса определён объект cBottleneck — динамический массив, который заполняется указателями на компоненты архитектуры основного пути обработки данных.
Особое внимание следует обратить на динамичность архитектуры. Она не фиксирована, а полностью зависит от набора параметров, заданных пользователем при инициализации. Поэтому мы отказались от жёсткого перечня внутренних компонентов и используем динамический массив, формируемый на лету в процессе инициализации.
Сам процесс инициализации выполняется в методе Init. Именно здесь создаётся и наполняется массив cBottleneck, блок за блоком формируя основной путь обработки сигналов и обеспечивая гибкость архитектуры объекта.
bool CNeuronSpikeResNeXtBottleneck::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, uint group_size, uint groups, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeActivation::Init(numOutputs, myIndex, open_cl, chanels_out * units_out, optimization_type, batch)) return false;
Процесс начинается с инициализации базового спайкового нейрона через вызов одноименного метода родительского класса, что задаёт общие параметры слоя, количество выходов и режим оптимизации. После этого создаются локальные указатели на различные типы компонентов.
CNeuronConvOCL *conv = NULL; CNeuronMultiWindowsConvOCL *mwconv = NULL; CNeuronBatchNormOCL *norm = NULL; CNeuronSpikeActivation *spike = NULL; CNeuronTransposeOCL* transp = NULL;
После завершения подготовительной работы, переходим к непосредственной инициализации внутренних компонентов. Сначала формируется блок проекции исходных данных, где сигнал проецируется во внутреннее представление нейрона. Создаётся и инициализируется свёрточный слой с заданными параметрами каналов, групп и размера анализируемой последовательности.
cBottleneck.Clear(); cBottleneck.SetOpenCL(OpenCL); //--- Projection in uint index = 0; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, chanels_in, chanels_in, group_size * groups, units_in, 1, optimization, iBatch) || !cBottleneck.Add(conv)) { DeleteObj(conv) return false; } conv.SetActivationFunction(SoftPlus);
Затем добавляется BatchNorm для нормализации результатов и спайковая активация, которая позволяет нейрону реагировать только на значимые события, игнорируя шумовые нули.
index++; norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cBottleneck.Add(norm)) { DeleteObj(norm) return false; } norm.SetActivationFunction(None); index++; spike = new CNeuronSpikeActivation(); if(!spike || !spike.Init(0, index, OpenCL, norm.Neurons(), optimization, iBatch) || !cBottleneck.Add(spike)) { DeleteObj(spike) return false; }
Далее формируется блок Feature Extraction. Здесь создаются многоканальные свёрточные нейроны, предназначенные для выполнения операций групповой свертки, как это предложено авторами архитектуры ResNeXt. К результатам свёртки последовательно применяются функции активации SoftPlus, нормализация батчей и спайковая активация.
//--- Feature Extraction index++; uint windows[]; if(ArrayResize(windows, groups) < (int)groups) return false; ArrayFill(windows, 0, groups, group_size); mwconv = CNeuronMultiWindowsConvOCL(); if(!mwconv || !mwconv.Init(0, index, OpenCL, windows, group_size, groups, units_in, optimization, iBatch) || !cBottleneck.Add(mwconv)) { DeleteObj(mwconv) return false; } mwconv.SetActivationFunction(SoftPlus); index++; norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, mwconv.Neurons(), iBatch, optimization) || !cBottleneck.Add(norm)) { DeleteObj(norm) return false; } norm.SetActivationFunction(None); index++; spike = new CNeuronSpikeActivation(); if(!spike || !spike.Init(0, index, OpenCL, norm.Neurons(), optimization, iBatch) || !cBottleneck.Add(spike)) { DeleteObj(spike) return false; }
Этот блок выполняет ключевую задачу. Он извлекает признаки из анализируемого сигнала, формируя устойчивые и информативные паттерны, которые затем передаются как по разветвлённым путям ResNeXt. Таким образом, Feature Extraction обеспечивает способность фокусироваться на значимых событиях и адаптироваться к различным паттернам, встречающимся в финансовых временных рядах.
Следующий этап — проекция результатов. Сигнал агрегируется, проходя через свёрточный слой и BatchNorm.
//--- Projection out index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, group_size * groups, group_size * groups, chanels_out, units_in, 1, optimization, iBatch) || !cBottleneck.Add(conv)) { DeleteObj(conv) return false; } conv.SetActivationFunction(SoftPlus); index++; norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cBottleneck.Add(norm)) { DeleteObj(norm) return false; } norm.SetActivationFunction(None);
Здесь следует обратить внимание на гибкость архитектуры объекта. Предусмотрена возможность изменять на выходе как размерность признаков, так и длину последовательности.
Если длина последовательности остаётся неизменной, процесс инициализации объекта на этом завершается. Финальная активация данных в этом случае будет выполняться средствами родительского класса, обеспечивая согласованность с остальными компонентами сети.
if(units_in == units_out) return true;
Однако, если требуется изменить длину последовательности, необходимо добавить ещё несколько объектов, которые обеспечат правильное преобразование формы тензоров. Прежде всего добавляем спайковую активацию, которая подготовит полученные на предыдущем шаге значения.
index++; spike = new CNeuronSpikeActivation(); if(!spike || !spike.Init(0, index, OpenCL, norm.Neurons(), optimization, iBatch) || !cBottleneck.Add(spike)) { DeleteObj(spike) return false; }
А затем следует блок проекции длины последовательности. Вначале данные транспонируются из временного ряда в последовательность признаков.
//--- Projection units index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_in, chanels_out, optimization, iBatch) || !cBottleneck.Add(transp)) { DeleteObj(transp) return false; }
Сверточный блок изменяет размерность унитарных последовательностей признаков до заданного размера.
index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, units_in, units_in, units_out, chanels_out, 1, optimization, iBatch) || !cBottleneck.Add(conv)) { DeleteObj(conv) return false; } conv.SetActivationFunction(SoftPlus);
Полученные значения нормализуются, и выполняется обратное транспонирование, возвращая тензор в представление мультимодальной временной последовательности, но уже скорректированной по длине.
index++; norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cBottleneck.Add(norm)) { DeleteObj(norm) return false; } norm.SetActivationFunction(None); index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, chanels_out, units_out, optimization, iBatch) || !cBottleneck.Add(transp)) { DeleteObj(transp) return false; } //--- return true; }
Каждый компонент добавляется в динамический массив cBottleneck, и при любой ошибке инициализации объект безопасно удаляется через DeleteObj, предотвращая утечки памяти.
В результате мы получаем универсальный и гибкий модуль, способный обрабатывать финансовые временные ряды, фильтровать шум, учитывать редкие события и работать с различными конфигурациями модели. А динамическая архитектура позволяет адаптировать нейрон под конкретные задачи, сохраняя эффективность и точность анализа.
В процессе инициализации объекта мы получили сложную и структурированную архитектуру объекта, включающую множество компонентов: свёрточные нейроны, многоканальные свёртки, нормализацию и спайковую активацию. Однако использование динамического массива указателей на внутренние компоненты позволяет скрыть всю эту сложность при реализации алгоритмов прямого и обратного прохода.
Несмотря на многогранность проводимого анализа, поток данных остаётся линейным. Сигнал проходит последовательно через все внутренние блоки. Это означает, что для прямого прохода достаточно просто в цикле перебрать все компоненты массива cBottleneck, последовательно передавая сигнал от одного блока к другому.
Метод feedForward реализует алгоритм прямого прохода. В начале работы метода создаются две переменные:
- prev, указывающая на источник входного сигнала,
- current, которая будет последовательно принимать ссылки на каждый блок массива.
Изначально prev ссылается на объект исходных данных, полученный в параметрах метода.
bool CNeuronSpikeResNeXtBottleneck::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL *prev = NeuronOCL; CNeuronBaseOCL *current = NULL;
Далее начинается перебор всех компонентов динамического массива в цикле. На каждой итерации current получает ссылку на соответствующий блок — будь то свёрточный нейрон, BatchNorm, многоканальная свёртка или спайковая активация.
for(int i = 0; i < cBottleneck.Total(); i++) { current = cBottleneck[i]; if(!current || !current. Feedforward(prev)) return false; prev = current; }
Каждый компонент последовательно обрабатывает сигнал, полученный от предыдущего блока, выполняет внутренние вычисления и возвращает результат. Если какой-либо блок отсутствует, или возникла ошибка при обработке, метод немедленно завершает выполнение, возвращая false. После успешной обработки текущего блока указатель prev обновляется и начинает ссылаться на него, обеспечивая передачу сигнала следующему компоненту в массиве.
По завершении цикла вызывается одноименный метод родительского класса, который выполняет финальную активацию данных. Именно здесь формируются спайки с учётом обучаемых порогов и накопления потенциала мембраны, что позволяет нейрону реагировать только на значимые события.
return CNeuronSpikeActivation::feedforward(prev);
}
Таким образом, даже при сложной и структурированной архитектуре объекта поток данных остаётся линейным и управляемым. Использование динамического массива скрывает внутреннюю сложность, упрощает реализацию алгоритма и позволяет легко добавлять новые компоненты или изменять архитектуру без переписывания прямого прохода.
После подробного рассмотрения метода feedForward, который обеспечивает последовательную и линейную передачу сигнала через все внутренние компоненты объекта, естественным продолжением становится организация обратного распределения ошибки. В спайковых моделях, как и в классических нейросетях, корректное распределение градиентов критически важно. Оно позволяет модели адаптироваться к редким событиям и фильтровать шум, что особенно актуально для финансовых временных рядов. В этом контексте метод calcInputGradients выполняет ту же роль, что и прямой проход, но с обратной логикой движения сигнала.
bool CNeuronSpikeResNeXtBottleneck::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false;
Метод начинает работу с проверки корректности указателя на объект исходных данных, чтобы избежать обработки пустых данных, которая могла бы привести к ошибкам или некорректным обновлениям весов.
Далее определяется блок, с которого начнется обратная передача сигнала ошибки. Если динамический массив cBottleneck содержит элементы, то старт осуществляется с последнего блока, поскольку именно он является конечной точкой прямого прохода. В противном случае сигнал ошибки сразу направляется к исходному нейрону.
CNeuronBaseOCL *current = (cBottleneck.Total() > 0 ? cBottleneck[-1] : NeuronOCL); if(!CNeuronSpikeActivation::calcInputGradients(current)) return false;
Этот шаг критичен: он гарантирует, что обратное распространение начинается с корректной точки, что особенно важно при сложных архитектурах с множеством внутренних преобразований.
Вызывается одноименный метод родительского класса, который формирует начальные градиенты на уровне выхода. Этот вызов учитывает накопленный потенциал мембраны и обучаемые пороги активации, позволяя спайковому нейрону правильно реагировать на значимые события и игнорировать нулевые или шумовые импульсы.
Далее начинается цикл, проходящий по всем элементам массива в обратном порядке. На каждой итерации сигнал ошибки передается от текущего блока к предыдущему с путем вызова метода CalcHiddenGradients, который вычисляет градиенты для скрытых компонентов.
for(int i = cBottleneck.Total() - 1; i >= 0; i--) { current = (i > 0 ? cBottleneck[i - 1] : NeuronOCL); if(!current || !current.CalcHiddenGradients(cBottleneck[i])) return false; } //--- result return true; }
Таким образом, каждая внутренняя часть архитектуры корректно получает сигнал ошибки и может обновлять свои параметры. Если какой-либо блок отсутствует, или вычисление не удалось, метод немедленно завершает выполнение, возвращая false.
Важно отметить, что несмотря на сложность и многослойность архитектуры, поток ошибки остаётся линейным и управляемым. Использование динамического массива позволяет скрыть внутреннюю сложность и обеспечивает гибкость. Можно легко модифицировать или расширять модель, добавлять новые компоненты без изменения алгоритма обратного прохода.
Для анализа финансовых временных рядов это особенно важно, поскольку сигналы могут содержать шум, редкие события и сложные паттерны. Корректное распределение градиентов гарантирует, что модель будет обучаться эффективно, точно отражать динамику рынков и надежно прогнозировать будущие изменения.
В итоге, метод calcInputGradients становится логическим зеркалом прямого прохода, обеспечивая обратную связь и точное управление параметрами всех компонентов объекта. Он демонстрирует, как динамическая архитектура и последовательная передача сигнала могут работать вместе, скрывая сложность и позволяя модели адаптироваться к самой разнообразной и непредсказуемой информации, которую несут финансовые временные ряды.
Модуль остаточных связей
Следующим этапом нашей работы становится построение модуля остаточных связей. В ходе анализа данных размерность тензора может изменяться, и для корректного выполнения последующих операций крайне важно согласовать размеры выходных тензоров двух параллельных информационных потоков. Без этой синхронизации невозможно правильно суммировать или объединять результаты основного и дополнительного путей модели, что нарушило бы целостность информации и повлияло бы на точность прогнозов.
Модуль остаточных связей выполняет роль мостика, обеспечивая согласование размерностей и позволяя корректно передавать сигнал по всей архитектуре. Для реализации нового объекта мы, несмотря на кажущуюся необычность, используем ранее созданный CNeuronSpikeResNeXtBottleneck в качестве родителя. Его способность работать с динамической архитектурой оказывается как нельзя кстати. Весь функционал переносится на новый объект, а внутренняя структура формируется простым наполнением динамического массива новой конфигурацией.
class CNeuronSpikeResNeXtResidual : public CNeuronSpikeResNeXtBottleneck { public: CNeuronSpikeResNeXtResidual(void) {}; ~CNeuronSpikeResNeXtResidual(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeResNeXtResidual; } };
Следовательно, для создания полностью функционирующего объекта остаточных связей нам достаточно переопределить метод инициализации.
bool CNeuronSpikeResNeXtResidual::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint chanels_in, uint chanels_out, uint units_in, uint units_out, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronSpikeActivation::Init(numOutputs, myIndex, open_cl, chanels_out * units_out, optimization_type, batch)) return false;
Метод Init строит внутреннюю архитектуру исключительно через динамический массив, наполняя его компонентами, которые согласуют размеры тензоров на выходе параллельных потоков. Сначала вызывается инициализация общего родительского класса CNeuronSpikeActivation, чтобы подготовить объект к работе.
После этого динамический массив cBottleneck, унаследованный от родительского класса, очищается и получает ссылку на объект OpenCL для выполнения вычислений. Все последующие компоненты будут добавляться именно в этот массив, формируя линейный, но динамически настраиваемый путь обработки данных.
Если количество каналов на входе и выходе различается, создаётся свёрточный слой для проекции каналов, которому сразу назначается функция активации SoftPlus.
CNeuronConvOCL *conv = NULL; CNeuronBatchNormOCL *norm = NULL; CNeuronSpikeActivation *spike = NULL; CNeuronTransposeOCL* transp = NULL; //--- cBottleneck.Clear(); cBottleneck.SetOpenCL(OpenCL); //--- Projection Chanels uint index = 0; if(chanels_in != chanels_out) { conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, chanels_in, chanels_in, chanels_out, units_in, 1, optimization, iBatch) || !cBottleneck.Add(conv)) { DeleteObj(conv) return false; } conv.SetActivationFunction(SoftPlus); index++; }
Далее, при необходимости изменения длины последовательности, добавляются компоненты для проекции соответствующего измерения. Но сначала, в случае необходимости, мы добавляем нормализацию и спайковую активацию для проекции размерности признаков.
//--- Projection Units if(units_in != units_out) { if(chanels_in != chanels_out) { norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, conv.Neurons(), iBatch, optimization) || !cBottleneck.Add(norm)) { DeleteObj(norm) return false; } norm.SetActivationFunction(None); index++; spike = new CNeuronSpikeActivation(); if(!spike || !spike.Init(0, index, OpenCL, norm.Neurons(), optimization, iBatch) || !cBottleneck.Add(spike)) { DeleteObj(spike) return false; } index++; }
Затем мы осуществляем транспонирование представления данных и добавляем свёрточный слой с активацией SoftPlus, задача которого скорректировать размерность временной последовательности.
transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_in, chanels_out, optimization, iBatch) || !cBottleneck.Add(transp)) { DeleteObj(transp) return false; } index++; conv = new CNeuronConvOCL(); if(!conv || !conv.Init(0, index, OpenCL, units_in, units_in, units_out, chanels_out, 1, optimization, iBatch) || !cBottleneck.Add(conv)) { DeleteObj(conv) return false; } conv.SetActivationFunction(SoftPlus); index++; norm.SetActivationFunction(None); index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, chanels_out, units_out, optimization, iBatch) || !cBottleneck.Add(transp)) { DeleteObj(transp) return false; } index++; }
После чего выполняем обратную транспозицию данных.
Такой подход позволяет согласовать размерности тензоров и обеспечить корректную передачу сигнала по всей структуре.
В завершение инициализации добавляется слой BatchNorm, который стабилизирует сигналы на выходе, подготавливая их для последующей спайковой активации средствами общего родительского класса.
norm = new CNeuronBatchNormOCL(); if(!norm || !norm.Init(0, index, OpenCL, Neurons(), iBatch, optimization) || !cBottleneck.Add(norm)) { DeleteObj(norm) return false; } //--- return true; }
Таким образом, метод Init превращает сложный набор операций по согласованию размерностей и интеграции остаточных связей в прозрачный и управляемый процесс. Динамическая структура создавать модели с различными параметрами, сохраняя линейный поток сигнала и обеспечивая корректное формирование признаков даже в самых сложных финансовых временных рядах.
Сегодня мы проделали серьёзную работу и значительно продвинулись в реализации фреймворка. Настало время сделать небольшую паузу, дать мыслям улечься и позволить всем концепциям устаканиться. Полный код всех описанных объектов вы найдёте во вложении. А мы вернёмся к работе с новыми силами в следующей статье, чтобы продолжить углублённое исследование возможностей SEW-ResNet и внедрение его подходов в финансовые модели.
Заключение
В ходе статьи мы подробно рассмотрели реализацию ключевых компонентов фреймворка SEW-ResNet средствами MQL5. Мы разобрали прямой и обратный проход Bottleneck, внедрили точки контроля нулевых значений, оптимизировали вычислительные алгоритмы и построили модуль остаточных связей, способный согласовывать размерности тензоров в сложной динамической архитектуре. Использование динамических массивов позволило скрыть внутреннюю сложность и обеспечить гибкость при работе с потоками данных различной структуры.
Реализованные решения демонстрируют, как современные спайковые подходы могут быть интегрированы в финансовые модели, обеспечивая точное и эффективное выделение признаков, фильтрацию редких событий и согласованное обучение на исторических данных.
Полный код всех описанных объектов представлен во вложении, что позволяет воспроизвести и расширить предложенные методы. Мы сделали важный шаг в направлении практического применения SEW-ResNet к анализу финансовых временных рядов и подготовили почву для дальнейших экспериментов. В следующей статье мы продолжим исследование, внедряя новые возможности фреймворка и углубляя понимание его потенциала для трейдинга.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования