
Нейросети в трейдинге: Обучение глубоких спайкинговых моделей (SEW-ResNet)

Введение
Финансовые рынки — это арена, где сталкиваются интересы миллионов участников, а каждое решение оборачивается прибылью или убытком. В таких условиях способность быстро извлекать информацию из сложных потоков данных становится решающим фактором успеха. В последние десятилетия именно искусственные нейронные сети заняли лидирующие позиции в задачах обработки информации, доказав свою эффективность в самых разных областях — от компьютерного зрения до автоматического перевода текстов. Их успех объясняется глубинным обучением: чем больше уровней в архитектуре модели, тем сложнее и многограннее образы, которые она может уловить и описать. В мире трейдинга этот принцип проявляется особенно ярко. Глубокие модели способны различать малейшие закономерности в поведении цены и отделять кратковременный шум от устойчивых трендов.
Однако развитие нейросетевых моделей столкнулось с парадоксом. Увеличение глубины сети, которое должно было приносить исключительно пользу, в определённый момент приводило к неожиданному эффекту. Вместо роста точности мы получали её стагнацию, а порой и деградацию. Ситуация напоминала перегруженный механизм, где новые звенья не упрощают работу, а создают сбои. Решение было найдено в концепции остаточных связей — модель учится не просто извлекать новые признаки, а корректировать уже найденные, добавляя к ним минимальные уточнения. Эта идея воплотилась в архитектуре ResNet, которая стала настоящим прорывом, позволив строить очень глубокие модели без потери качества.
Но параллельно с классическими архитектурами возникло направление, которое всё чаще привлекает внимание исследователей и практиков — спайковые нейронные сети. Их особенность в том, что они ближе к работе мозга. В отличие от привычных нам моделей, в них информация передаётся отдельными импульсами, событиями. Для финансовых рынков такой подход особенно ценен, ведь и здесь доминирует событийная логика: публикация отчёта, заявление регулятора, внезапный всплеск активности — всё это ключевые события, на которые система должна реагировать моментально. Кроме того, спайковые модели обещают большую энергоэффективность и возможность работать на потоках данных в реальном времени.
Однако, несмотря на впечатляющую биологическую правдоподобность и новые перспективы, спайковые модели всё ещё уступали классическим нейронным сетям в ряде практических задач. Особенно это проявлялось на сложных наборах данных, где требовалась высокая точность и глубина анализа. В какой-то момент стало очевидно, что путь к прогрессу лежит через интеграцию идей глубокого обучения в архитектуру спайковых моделей. Так появились первые попытки адаптировать ResNet в спайковом формате. Концепция Spiking ResNet казалась многообещающей — перенести остаточные блоки из классической архитектуры и заменить функции активации на спайковые нейроны. Такой подход давал возможность использовать проверенный временем принцип глубины и остаточных связей в новом, событийном контексте.
Результаты оказались неоднозначными. С одной стороны, модели, конвертированные из классических нейронных сетей, демонстрировали выдающуюся точность и задавали высокий уровень для других решений. С другой — при прямом обучении Spiking ResNet вскрылись проблемы: деградация качества при увеличении глубины, исчезающие и взрывающиеся градиенты, трудности с реализацией корректного тождественного отображения. Всё это делало задачу построения по-настоящему глубоких и устойчивых спайковых моделей нерешённой.
На этом фоне появление фреймворка SEW-ResNet, представленного в работе "Deep Residual Learning in Spiking Neural Networks", стало значительным шагом вперёд. Основная идея заключалась в том, чтобы по-новому взглянуть на механизм остаточного обучения применительно к спайковым архитектурам. Авторы фреймворка предложили Spike-Element-Wise подход, позволяющий естественным образом реализовать тождественное отображение и одновременно избежать ключевых проблем с градиентами. Практическая проверка подтвердила правильность концепции. SEW-ResNet показал не только более высокую точность, но и способность масштабироваться с ростом глубины модели, чего раньше достичь не удавалось. Более того, впервые удалось построить спайковую сеть с глубиной свыше 100 слоёв, которая сохраняла стабильность обучения и превосходила по результатам многие существующие решения.
Если перенести этот разговор в сферу финансов, становится ясно: подобные разработки открывают принципиально новые горизонты. Глубокие модели, обученные на импульсных данных, могут анализировать рыночные события в том виде, в каком они реально происходят. Не как усреднённые ряды чисел, а в виде последовательности дискретных сигналов, каждый из которых имеет значение. Такой взгляд ближе к природе рынка, где цена редко движется плавно и равномерно, а чаще реагирует на всплески ликвидности, новости или настроения участников. Технологии вроде SEW-ResNet обещают научить алгоритмы видеть эти изменения в момент их возникновения.
Таким образом, проблематика построения устойчивых и глубоких спайковых моделей выходит далеко за рамки академического интереса. В финансовой индустрии, где скорость реакции и способность обрабатывать сложные данные определяют конкурентное преимущество, внедрение таких решений может стать ключевым шагом к новым стратегиям и инструментам. Сегодня мы стоим на пороге интеграции идей SEW-ResNet в практические алгоритмические системы. Этот путь мы рассмотрим через призму реализации предложенных подходов средствами MQL5. Что позволит лучше понять саму архитектуру и оценить её прикладной потенциал в реальных условиях рынка.
Алгоритм SEW-ResNet
В основе любого фреймворка спайковых нейронных сетей лежит простая, но фундаментальная идея: базовой вычислительной единицей является спайковый нейрон. Для классических искусственных нейронных сетей такой элемент можно описать как обобщённую сумму произведений, где сигналы проходят по весовым связям и затем преобразуются функцией активации. Однако в спайковой модели всё выглядит куда динамичнее и ближе к биологии. Здесь информация не течёт непрерывным потоком, а передаётся в виде отдельных событий — импульсов, или спайков. Каждый такой импульс подобен электрическому разряду, который в реальном мозге передаётся от нейрона к нейрону.
Чтобы формализовать этот процесс и сделать его пригодным для вычислений, вводится унифицированная модель. Она описывает динамику нейрона во времени, разбивая её на последовательность дискретных шагов. На каждом шаге система решает три ключевые задачи:
- Вычислить новый потенциал мембраны.
- Определить, произошёл ли спайк.
- Сбросить потенциал в случае срабатывания.
Первое уравнение отвечает за эволюцию потенциала.
![]()
Здесь Vt-1 — это мембранный потенциал на предыдущем шаге, а Xt — входной ток, поступивший в данный момент времени. Функция f(•) определяет характер обновления потенциала и меняется в зависимости от выбранного типа нейрона. Фактически это внутренняя физика нейрона, описывающая, как он реагирует на входящий сигнал.
Следующий этап — проверка, превысил ли мембранный потенциал порог.
![]()
Если потенциал достигает порога Vth, нейрон срабатывает и формирует импульс. Функция Гевисайда Θ(•) выступает здесь в роли жёсткого переключателя, который возвращает 1 при превышении порога и 0 в противном случае. Иными словами, либо есть событие, либо его нет.
После этого вступает в силу механизм сброса.
![]()
Если спайк произошёл, потенциал возвращается к фиксированному уровню VReset. Это напоминает процесс разрядки батареи: после выброса энергии система должна вернуться в исходное состояние, чтобы подготовиться к следующему сигналу. Если же импульса не было, потенциал сохраняет текущее значение и продолжает накапливаться.
Всё это создаёт стройную схему, которая позволяет воспроизводить динамику биологических нейронов, но при этом остаётся достаточно простой для вычислений. Более того, гибкость обеспечивается функцией f(•). Для простейшей модели Integrate-and-Fire она имеет вид:
![]()
То есть потенциал просто увеличивается на величину входного тока. В случае же более реалистичной модели Leaky Integrate-and-Fire учитывается утечка накопленного заряда.
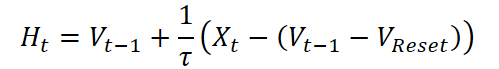
Параметр τ задаёт скорость этой утечки, отражая тот факт, что нейрон не может бесконечно хранить энергию — он постепенно теряет заряд, если импульс так и не был сгенерирован.
Таким образом, в руках исследователя оказывается универсальная конструкция, где базовые процессы (генерация спайка и сброс) одинаковы для всех моделей, а тонкая настройка достигается выбором функции f(•).
Однако на этом пути возникает важная трудность, связанная с обучением. Классическая ступенчатая функция, которая решает, будет ли спайк сгенерирован, не дифференцируема. Это значит, стандартный метод обратного распространения ошибки, на котором держится глубокое обучение, здесь работать не может. На первый взгляд, это серьёзное препятствие. Если нельзя вычислить градиент, то и корректировать веса модели становится невозможно.
Выход был найден в так называемом методе суррогатных градиентов. Его суть заключается в том, что для прямого прохода мы используем реальную ступенчатую функцию, ведь именно она отражает природу спайков. Но когда речь заходит о вычислении производных во время обратного прохода, мы заменяем её гладкой аппроксимацией — функцией σ(•), которая ведёт себя похоже, но при этом имеет удобный аналитический градиент. Такое двойное использование функций позволяет обучать спайковые модели аналогично обычным глубоким нейронным сетям, сохраняя при этом событийную природу вычислений.
Эта комбинация (унифицированная модель нейронов и метод суррогатных градиентов) создаёт надёжный фундамент для построения сложных архитектур. Именно здесь начинается история SEW-ResNet.
Если говорить о глубоких архитектурах, то именно остаточный блок стал тем базисом, на котором вырос ResNet и позволил преодолеть главную болезнь очень глубоких сетей — деградацию качества. Идея казалась простой, но революционной. Если мы не можем обучить все новые слои так, чтобы они в точности повторяли входной сигнал, то давайте оставим для них запасной путь — прямую линию, по которой информация сможет пройти без искажений. В этом и заключалось понятие тождественного отображения. Оно гарантировало, что глубина модели не повредит качеству. В худшем случае новые слои ничего не испортят, а в лучшем — обогатят представление данных.
В классическом ResNet такой блок устроен из двух последовательных свёрточных слоёв, нормализации и функции активации ReLU. Если обозначить вход блока как Xl, а выход — как Yl, то в общем виде формула выглядит так:
![]()
Здесь Fl(•) — это добавление к исходному сигналу. Если оно равно нулю, то результатом будет простое Yl = ReLU(Xl). А поскольку активация после ReLU неотрицательна, то для большинства значений мы фактически получаем тождественное отображение: вход равен выходу. В этом и заключался секрет успеха ResNet.
Попытка перенести эту конструкцию в спайковый мир выглядела вполне естественной. В работах по Spiking ResNet блок устроен так же, только вместо ReLU используется спайковый нейрон.
![]()
Здесь Sl и Ol — это вход и выход блока на шаге времени t, а SN обозначает срабатывание спайкового нейрона.
И вот тут проявляется фундаментальная разница. В классических сетях ReLU работает как плавный фильтр. Пропускает положительные значения без изменений. Поэтому добиться тождественного отображения там просто. Но в случае спайкового нейрона условия куда жёстче. Чтобы обеспечить равенство SN(Slt) = Slt, последний нейрон в блоке должен срабатывать на каждый входной спайк и оставаться молчаливым при его отсутствии. Для простейшей модели IF это ещё можно реализовать — достаточно подобрать порог возбуждения и начальные условия так, чтобы вход 1 всегда вызывал импульс, а вход 0 никогда. Но как только мы берём более сложную модель, например LIF с обучаемой временной константой τ, ситуация усложняется. Потенциал обновляется дробным шагом, зависящим от τ, и подобрать универсальный порог для всех случаев становится практически невозможно.
Таким образом, остаточные блоки Spiking ResNet оказываются ограниченными. Они подходят не для всех моделей нейронов, а значит, уже на базовом уровне нарушается принцип универсальности.
Но и это не единственная проблема. Даже если нам удаётся настроить блоки так, чтобы они реализовывали тождественное отображение, мы сталкиваемся с куда более серьёзной угрозой — исчезающими и взрывающимися градиентами. В глубокой сети передача градиента через последовательность спайковых блоков сводится к произведению множителей, которые связаны с производной ступенчатой функции активации. А поскольку сама эта функция дискретна, для суррогатных аппроксимаций её производная почти всегда либо очень мала (что ведёт к затуханию), либо наоборот даёт нестабильный рост (взрыв). В результате с увеличением числа слоёв сеть становится практически необучаемой. Ошибки не проходят вглубь, веса не корректируются, а градиенты уходят либо в нуль, либо в бесконечность.
Этот эффект и есть пресловутая деградация, только в спайковых моделях он выражен ещё жёстче, чем в классических. И именно из-за этого Spiking ResNet в своём исходном виде так и не смог подтвердить способность глубины давать выигрыш. Более того, зачастую глубокая спайковая модель работала хуже, чем её неглубокий аналог.
Стоит, однако, отметить, что подобные блоки всё же нашли своё место — при преобразовании классических моделей в спайковые. Там задача иная: адаптация уже готовой модели под событийный формат. В этом случае спайковые блоки можно использовать в комбинации с дополнительной нормализацией, и они достаточно успешно воспроизводят частотные характеристики исходных ReLU-активаций.
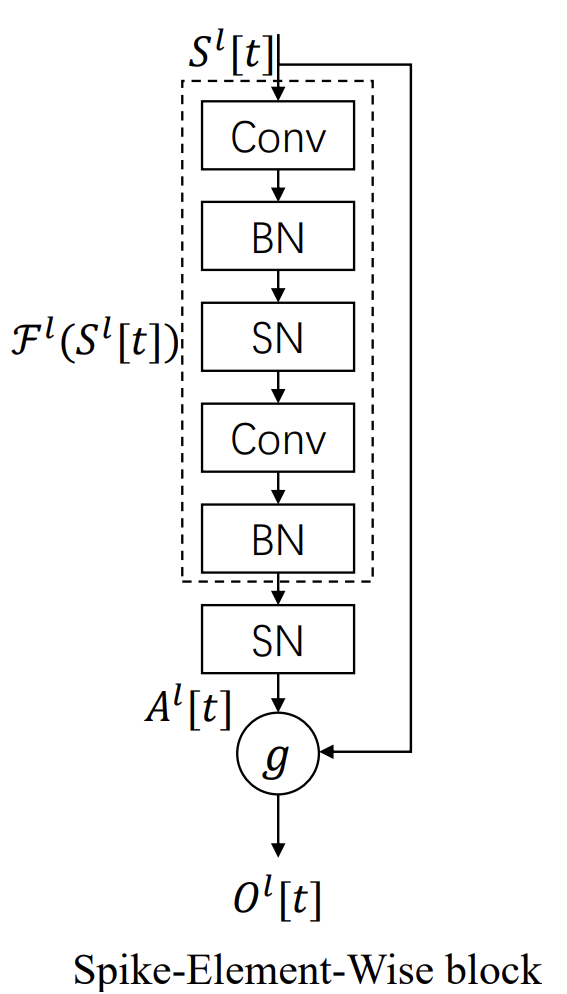
И вот здесь на сцену выходит Spike-Element-Wise блок, который по сути играет ту же роль, что когда-то сыграл классический residual block: он дал SNN возможность расти вглубь, сохраняя стабильность.
Что делает SEW-блок таким особенным? Прежде всего, его простота. Он основан на элементно-покомпонентной операции g, которая комбинирует два потока информации — выход спайковой трансформации и исходный сигнал. Благодаря двоичной природе спайков, такая конструкция работает как идеальный переключатель: при нужных настройках блок становится абсолютно прозрачным, реализуя identity mapping. Это не какая-то тонкая настройка, зависимая от конкретной модели нейрона или параметров мембранной динамики, а универсальный приём, работающий в любой конфигурации. Именно здесь кроется сила SEW — он универсален.
Представим себе длинную цепочку SEW-блоков. В классических ResNet-подобных схемах на определённой глубине мы начинаем терять сигнал — градиенты становятся всё меньше, и сеть перестаёт обучаться. Либо наоборот — в RBA-блоках сигналы растут неконтролируемо, что ведёт к взрывам. В SEW такой сценарий невозможен. Его выход всегда ограничен, градиенты остаются равными единице, и обучение может идти на сотни блоков в глубину. Другими словами, SEW возвращает нам ту же роскошь, которую дал ResNet миру классических нейронных моделей.
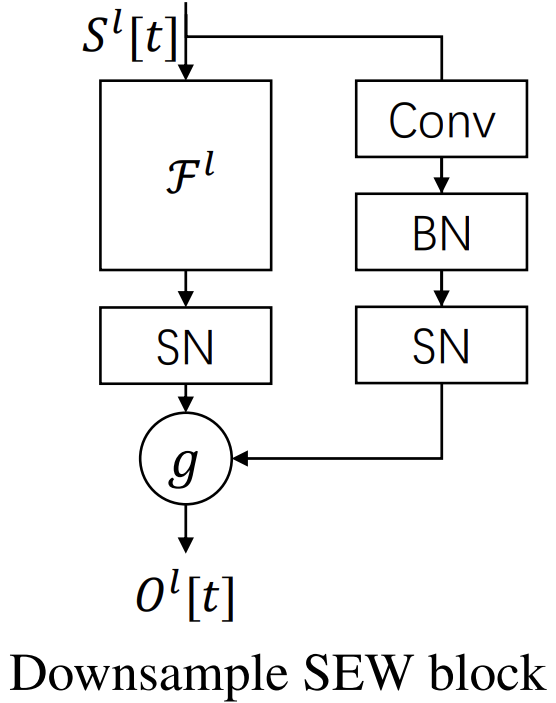
Интересно и то, как решается проблема даунсемплинга. В классических ResNet при изменении размерностей shortcut реализуется через свёртки без активации. В SEW блоке добавляется спайковый нейрон в shortcut, что создаёт более органичную и нейробиологически реалистичную схему. В итоге downsample-блоки изменяют размерность и продолжают работать в спайковом режиме, сохраняя биологическую правдоподобность модели.
Если взглянуть шире, SEW-блок открывает двери к совершенно новому классу приложений. До него SNN-архитектуры были скорее академическим интересом. Слишком сложно было удерживать баланс между глубиной и обучаемостью. С появлением SEW они начинают претендовать на серьёзную конкуренцию с классическими нейросетевым моделям в реальных задачах. А ведь преимущество SNN очевидно: они энергоэффективны, асинхронны, прекрасно ложатся на нейроморфные чипы и дают возможность строить вычисления ближе к реальной динамике мозга.
Переходя от теоретического описания к практическим экспериментам, становится заметна разница между Spiking ResNet и SEW-ResNet. На статических задачах — вроде классификации изображений из набора CIFAR или ImageNet — обе архитектуры показывают близкие результаты, но стоит углубиться, увеличить число слоёв, как Spiking ResNet начинает захлёбываться. Градиенты исчезают, ошибка растёт, и вместо улучшения мы получаем деградацию качества. Это классический сценарий, когда глубина превращается во врага.
SEW-ResNet в таких условиях ведёт себя диаметрально противоположно. Чем глубже модель, тем устойчивее её поведение и тем выше итоговая точность. Это особенно важно, когда речь идёт о задачах, где успех зависит от способности модели видеть далеко вперёд во временном пространстве. В финансовых рынках мы имеем именно такую ситуацию. Редкие и резкие всплески активности, периоды затяжного затишья, смены режимов рынка и длинные временные зависимости, которые необходимо удерживать в памяти.
Для понимания ценности SEW-ResNet в трейдинге, можно провести аналогию с самим рынком. В нём тоже есть сигналы-спайки — неожиданные новости, резкие движения котировок, внезапные всплески ликвидности. Классические нейросетевые модели, работающие с усреднёнными активациями, похожи на трейдера, который видит лишь сглаженный график и упускает резкие импульсы. Spiking-архитектуры, особенно SEW-ResNet, позволяют воспринимать рынок в его естественной, событийной форме, где важен не плавный тренд, а именно момент скачка и его контекст.
В сравнительных тестах на наборах, имитирующих поток событий, SEW-ResNet показал значительное преимущество по точности и по скорости сходимости. Более того, он оказался первым подходом, который позволил тренировать SNN-модели глубже 100 слоёв без катастрофической деградации.
В практическом применении к финансовым данным SEW-ResNet открывает новые горизонты. Он позволяет строить модели, которые способны вылавливать локальные паттерны в котировках и связывать их с длинными историческими зависимостями. Например, модель может уловить короткий всплеск активности в ответ на экономическую новость и одновременно учесть, что подобные всплески в прошлом вели к устойчивому среднесрочному тренду. Это становится возможным именно благодаря глубине, которая теперь не разрушает, а усиливает обучение.
Кроме того, высокая энергоэффективность и событийная природа SNN позволяют рассматривать SEW-ResNet в контексте систем с низкими задержками. В условиях высокочастотной торговли или алгоритмического анализа, где каждая миллисекунда на счету, способность модели быстро обрабатывать спайковые события становится критическим преимуществом.
Авторская визуализация фреймворка представлена ниже.
Реализация средствами MQL5
После того как мы тщательно рассмотрели теоретические основы и архитектурные особенности фреймворка SEW-ResNet, наступает закономерный этап — переход к практической реализации. И здесь важно двигаться от простого к сложному, от фундамента к надстройке. Первым звеном в этой цепочке становится построение базовой функции спайкового нейрона.
На первый взгляд может показаться вполне естественным реализовать процесс генерации спайка в виде отдельной функции. Подобно тому, как в нашей библиотеке реализованы классические функции активации. Однако спайковые нейроны предъявляют принципиально иные требования. В отличие от традиционных активаций, которые моментально вычисляют выходное значение на основе исходного сигнала, спайковый нейрон живёт во времени. Он не просто реагирует на вход, но аккумулирует информацию, накапливает мембранный потенциал, а затем, при достижении порога, генерирует спайк — дискретный импульс, несущий смысловую нагрузку.
Эта временная динамика не может быть сведена к одной лишь статической функции. Для корректного моделирования требуется отдельная память — буферы накопления потенциала, которые по своей сути напоминают скрытые состояния рекуррентных моделей. И именно в этом заключается главный вызов. Использование спайковой активации как простой функции автоматически потребовало бы вмешательства во все ранее созданные объекты слоёв. Фактически, мы бы разрушили архитектурную совместимость библиотеки и потеряли созданную модульность.
Поэтому решение оказалось иным, более зрелым: генерацию спайков мы реализуем в виде отдельного объекта нейронного слоя. Такой шаг на первый взгляд может показаться избыточным, но на деле он является стратегическим. Объект слоя можно встроить в любую существующую архитектуру, не затрагивая работу остальных компонентов. Он становится самостоятельным кирпичиком, который можно комбинировать с другими слоями, наращивая сложность модели.
Но прежде чем мы перейдём непосредственно к коду, стоит ненадолго остановиться на ключевых принципах нашей реализации. В теоретическом описании фреймворка SEW-ResNet авторы заложили базовые идеи — фундамент, открывающий огромное поле для экспериментов, но без конкретных инженерных решений. Именно эти решения и позволяют нам строить реально обучаемые глубокие спайковые модели.
Первый принцип касается накопления потенциала мембраны нейрона. Для этого мы позаимствовали у рекуррентных моделей механизм гейтового обновления состояния. Каждый спайковый нейрон теперь получает собственный гейт, контролирующий, насколько быстро или медленно мембранный потенциал реагирует на поступающие сигналы. И что особенно важно, этот гейт реализован как обучаемый параметр, независимый от исходных данных.
Практический смысл этого подхода легко представить через аналогию с трейдером на рынке. Каждый нейрон учится вырабатывать собственную стратегию реагирования на события. Если сигнал шумный и нестабильный, нейрон ведёт себя консервативно, аккумулирует информацию и реагирует только на действительно значимые изменения. Если же сигнал чистый и предсказуемый, нейрон способен мгновенно сгенерировать спайк, фиксируя важный импульс. В результате каждый элемент становится уникальным, а вся модель получает гибкость, необходимую для работы с разными типами исходных последовательностей.
Такой подход особенно актуален для финансовых рынков, где данные часто представляют собой чередование спокойных периодов и резких всплесков активности. Одни события требуют осторожного реагирования, другие — быстрой и решительной реакции. Возможность настроить каждый нейрон под конкретный характер входного сигнала позволяет модели адаптироваться к этим условиям, сохраняя точность и стабильность обучения.
Кроме того, мы позаимствуем из фреймворка SpikingBrain эффективный механизм адаптивного обучения пороговых значений, реализованный в кернеле FloatToSpike. Этот механизм позволяет нейронам гибко подстраивать свой порог срабатывания под статистику исходных сигналов, что особенно важно при работе с разнородными и шумными данными. Однако в нашей реализации мы внесли небольшое, но принципиально важное изменение, которое усиливает возможности модели.
Теперь при генерации импульса накопленный потенциал нейрона уменьшается на величину порога срабатывания.
__kernel void FloatToSpike(__global float* values, __global const float* levels, __global float* outputs ) { const size_t id = get_global_id(0); float val = IsNaNOrInf(values[id], 0.0f); if(val == 0.0f) outputs[id] = 0.0f; else { const float lev = IsNaNOrInf(levels[id], 0.0f); if(fabs(val) < lev) outputs[id] = 0.0f; else { outputs[id] = (float)sign(val); values[id] = IsNaNOrInf(sign(val)*(fabs(val)-lev), 0.0f); } } }
Мы намеренно отказались от сбрасывания потенциала до фиксированного значения VReset. На первый взгляд это может показаться незначительной деталью, но на практике она открывает совершенно новый уровень гибкости. Такой подход позволяет формировать своеобразную градацию импульсов. Более сильный сигнал оставляет более длительное послесвечение в мембранном потенциале, влияя на последующие события. Иными словами, нейрон теперь способен аккумулировать историю значимых импульсов, создавая эффект временной инерции.
В контексте финансовых рынков это приобретает особую практическую ценность. Рыночные события редко бывают единичными и изолированными. Движение цены одного инструмента часто продолжается серией связанных импульсов, а реакция рынка на новость может растягиваться во времени. Возможность нейрона удерживать часть накопленного потенциала позволяет модели помнить значимые события и адекватно реагировать на их последствия, создавая внутреннюю динамическую память. Такая организация работы нейронов делает SEW-ResNet более чувствительной к истинным рыночным паттернам, одновременно снижая влияние случайного шума.
Таким образом, небольшое, точечное изменение механизма превращает нейрон из простого переключателя спайк/нет спайка в полноценный динамический элемент с градацией отклика. Это сочетание точности, адаптивности и способности аккумулировать информацию во времени является одним из ключевых отличий нашей реализации и создаёт прочный фундамент для построения глубоких, устойчивых и адаптивных моделей.
Предложенное решение реализовано в виде нового объекта CNeuronSpikeActivation, который наследуется от базового класса CNeuronBaseOCL. Этот объект воплощает всю динамику спайкового нейрона, включая накопление мембранного потенциала, адаптивный порог и механизм градации генерации импульсов.
class CNeuronSpikeActivation : CNeuronBaseOCL { protected: CNeuronBaseOCL cHV; CParams cLevels; CParams cGates; //--- virtual bool FloatToSpike(void); virtual bool FloatToSpikeGrad(void); //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronSpikeActivation(void) {}; ~CNeuronSpikeActivation(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint neurons, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual int Type(void) override const { return defNeuronSpikeActivation; } //--- methods for working with files virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; virtual void SetOpenCL(COpenCLMy *obj) override; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; virtual void TrainMode(bool flag) override; virtual bool Clear(void) override; };
Внутри объекта выделены несколько ключевых компонентов:
- cHV отвечает за внутреннюю динамику нейрона, аккумулируя потенциал и учитывая спайковые события;
- cLevels хранит параметры пороговых значений, обеспечивая адаптивное обучение порога;
- cGates реализует механизм гейтового обновления мембранного потенциала, позволяя каждому нейрону индивидуально регулировать скорость реакции на входной сигнал.
Таким образом, каждый нейрон может вырабатывать уникальную стратегию реагирования на шумные или значимые события, что особенно важно для анализа финансовых рядов.
Все внутренние объекты нового класса объявлены статично, что позволило оставить конструктор и деструктор класса пустыми — никаких дополнительных действий при создании или удалении объекта не требуется. Это решение существенно упрощает архитектуру, делает её более предсказуемой и облегчает интеграцию нового нейрона в существующую библиотеку.
Весь процесс инициализации нового нейронного слоя сосредоточен в методе Init, который становится точкой входа для настройки всех компонентов объекта. Здесь задаются ключевые параметры.
bool CNeuronSpikeActivation::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint numNeurons, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, numNeurons, optimization_type, batch)) return false;
Инициализация начинается с базового вызова одноименного метода родительского класса, который настраивает фундаментальные параметры нейрона. После успешного выполнения создаются и инициализируются внутренние компоненты. cHV отвечает за динамику мембранного потенциала. Ему присваивается нулевая активация, и буферы очищаются, чтобы нейрон стартовал в чистом состоянии.
uint index = 0; if(!cHV.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cHV.SetActivationFunction(None); cHV.Clear();
Далее создаётся объект cLevels, отвечающий за адаптивные пороги срабатывания. Для него устанавливается функция активации SoftPlus, которая обеспечивает плавное и устойчивое обновление порогов, а веса инициализируются значением -3.0f, создавая консервативный стартовый порог. Такой порог позволяет нейрону аккумулировать входные сигналы и реагировать только на действительно значимые события, однако при этом мы не закрываем все нейроны с самого начала обучения. Это важно. Нейроны остаются способными к генерации первых спайков даже на старте, что обеспечивает непрерывный поток информации в моделе и позволяет градиентам эффективно распространяться в процессе обучения.
Иными словами, мы избегаем ситуации, когда нейроны полностью пассивны на начальных этапах — они сразу включены в процесс обучения, но действуют осторожно. Такой баланс между консервативной инициализацией и активностью нейронов создаёт оптимальные условия для постепенного обучения модели и стабилизирует начальные этапы тренировки.
index++; if(!cLevels.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cLevels.SetActivationFunction(SoftPlus); CBufferFloat* temp = cLevels.getWeightsParams(); if(!temp || !temp.Fill(-3.0f)) return false;
Следующим шагом инициализируется объект cGates, реализующий механизм гейтового обновления мембранного потенциала. Ему присваивается активация SIGMOID, что позволяет каждому нейрону обучать индивидуальный коэффициент реагирования на новые сигналы. Веса инициализируются нулями, что создаёт нейтральное поведение на старте обучения. При этом после прохождения сигнала через функцию SIGMOID результат оказывается около 0.5 — точка, в которой сигмоида практически линейна. Это имеет ключевое значение. В этой области градиенты сохраняют достаточную величину, что позволяет быстро корректировать параметры гейта в нужном направлении.
Другими словами, на старте обучения нейрон получает сбалансированное состояние — гейт не блокирует и не пропускает сигнал полностью, а оставляет возможность адаптации. Уже на первых шагах тренировки модель способна гибко регулировать скорость накопления мембранного потенциала для каждого нейрона, подстраиваясь под характеристики исходных данных. Это особенно важно для финансовых временных рядов, где сигналы могут быть как спокойными и предсказуемыми, так и резкими и шумными. И правильная динамическая реакция нейронов напрямую влияет на точность прогнозов.
index++; if(!cGates.Init(0, index, OpenCL, Neurons(), optimization, iBatch)) return false; cGates.SetActivationFunction(SIGMOID); temp = cGates.getWeightsParams(); if(!temp || !temp.Fill(0.0f)) return false; //--- return true; }
Таким образом, метод инициализации настраивает нейронный слой и создаёт готовую к работе, гибкую и адаптивную структуру, способную аккумулировать информацию, контролировать порог срабатывания и индивидуально реагировать на входные сигналы.
После завершения инициализации объекта, следующим логическим шагом является построение алгоритма прямого прохода — того, как нейрон обрабатывает исходные данные и генерирует спайки. Этот процесс реализован в методе feedForward, который становится ядром работы нейрона.
bool CNeuronSpikeActivation::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) return false; //--- if(!cHV.SwapOutputs()) return false;
Алгоритм начинается с небольшого блока подготовительной работы. Сначала проверяем корректность полученного указателя на объект предыдущего слоя NeuronOCL. Это гарантирует, что данные для обработки действительно существуют. Далее вызывается метод SwapOutputs для объекта cHV, обеспечивая обновление внутреннего состояния мембранного потенциала. Текущие значения становятся предыдущими, а нейрон готов к обработке нового временного шага. Такой шаг крайне важен для корректной работы накопления потенциала и формирования спайков с учётом истории сигналов.
Если сеть находится в режиме обучения, дополнительно запускается прямой проход для внутренних объектов cLevels и cGates. Первый отвечает за адаптацию порога срабатывания, а второй — за обновление гейта мембранного потенциала. Именно эти компоненты позволяют нейрону гибко регулировать чувствительность к анализируемым данным и эффективно учиться на шумных или изменяющихся сигналах.
if(bTrain) { if(!cLevels.FeedForward()) return false; if(!cGates.FeedForward()) return false; }
Далее происходит поэлементное суммирование входного сигнала и мембранный потенциал с учетом гейтов. Эта операция реализует ключевой принцип спайковых нейронов: входной сигнал аккумулируется с учётом состояния нейрона и его индивидуальной реакции на новизну. Такой подход позволяет модели сохранять динамическую память и гибко реагировать на сложные временные зависимости, что особенно важно для финансовых временных рядов, где каждое изменение может иметь продолжительное влияние на последующие события.
if(!GateElementMult(NeuronOCL.getOutput(), cHV.getPrevOutput(), cGates.getOutput(), cHV.getOutput())) return false; return FloatToSpike(); }
Вызов метода FloatToSpike завершает прямой проход, генерируя спайки на основе текущего состояния мембраны и адаптивного порога. Результатом работы метода feedForward становится выходной сигнал нейрона, готовый к дальнейшей обработке в составе глубокого SEW-ResNet.
Как можно заметить, алгоритм метода прямого прохода имеет линейный и предсказуемый характер. Каждое действие — обновление мембранного потенциала, применение гейта и генерация спайков — выполняется последовательно и прозрачно, без сложных ветвлений или конфликтующих потоков данных. Такой подход имеет важное практическое следствие: распространение градиента ошибки и обучение модели остаются стабильными и не усложняются параллельной обработкой информации, что особенно ценно при работе с глубокой сетью и большим числом нейронов.
Методы обратного прохода, отвечающие за вычисление градиентов и обновление весов, в этой реализации предлагается оставить для самостоятельного изучения. Полный код класса CNeuronSpikeActivation и всех его методов представлен во вложении, что позволяет читателю подробно изучить реализацию и использовать её для построения собственных моделей.
Таким образом, CNeuronSpikeActivation представляет собой универсальный и гибкий инструмент для построения глубоких спайковых моделей на базе SEW-ResNet в MQL5. Его архитектура позволяет экспериментировать с разными схемами накопления потенциала, адаптивного порога и генерации спайков, не нарушая совместимость с уже существующими объектами нейронных слоёв. Именно такой модульный и расширяемый подход обеспечивает возможность строить глубокие, стабильные и адаптивные модели для анализа сложных временных рядов, характерных для финансовых рынков.
Сегодня мы проделали значительную работу, настало время сделать небольшую паузу, чтобы усвоить полученные знания. В следующей статье мы вернёмся к реализации подходов, предложенных авторами фреймворка SEW-ResNet, уже с новыми силами и свежим взглядом, продолжая строить эффективные и адаптивные спайковые модели средствами MQL5.
Заключение
В этой статье мы познакомились с фреймворком SEW-ResNet, основным достоинством которого является возможность прямой реализации остаточного обучения в спайковых моделях. Это позволяет строить глубокие модели без деградации производительности. Использование бинарной природы спайков вместе с поэлементными операциями обеспечивает устойчивость к исчезающим и взрывающимся градиентам.
В практической части мы подробно рассмотрели принципы реализации спайковых нейронов и построения базового алгоритма прямого прохода средствами MQL5. Показано, как использование адаптивного порога, гейтового обновления мембранного потенциала и аккумулирующего механизма потенциала позволяет нейронам эффективно реагировать на последовательные и шумные данные.
В следующей статье мы продолжим расширять функционал SEW-ResNet, чтобы создать полноценную глубокую спайковую модель для анализа и прогнозирования финансовых данных.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования