
Преодоление ограничений машинного обучения (Часть 5): Краткий обзор кросс-валидации временных рядов

В другой серии наших статей мы рассмотрели многочисленные тактические приемы решения проблем, возникающих в результате поведения рынка. Однако в этой серии мы сосредоточимся на проблемах, связанных с алгоритмами машинного обучения, которые мы хотим использовать в своих стратегиях. Многие из этих проблем возникают из-за архитектуры модели, алгоритмов, используемых при выборе модели, функций потерь, которые мы задаем для оценки качества модели, и многих других вопросов такого же характера.
Все компоненты, из которых состоит модель машинного обучения, могут непреднамеренно создавать препятствия в нашем стремлении применить машинное обучение к алгоритмической торговле, требуя тщательной диагностической оценки. Поэтому для каждого из нас важно понимать эти ограничения и, как сообщество, разрабатывать новые решения и определять новые стандарты для себя.
Модели машинного обучения, используемые в алгоритмической торговле, сталкиваются с уникальными вызовами, часто обусловленными тем, как мы их проверяем и тестируем. Одним из важнейших этапов является кросс-валидация временных рядов - метод оценки эффективности модели на основе ранее не наблюдавшихся хронологически упорядоченных данных.
В отличие от стандартной кросс-валидации, данные временных рядов нельзя перемешать, поскольку это приведет к утечке будущей информации в прошлое. Это усложняет процедуры выборки и приводит к уникальным компромиссам между смещением, дисперсией и надежностью.
В этой статье мы расскажем о кросс-валидации временных рядов, объясним ее роль в предотвращении переобучения и покажем, как она может помочь в обучении надежных моделей даже на ограниченных данных. Используя небольшой набор данных за два года, мы демонстрируем, как надлежащая кросс-валидация улучшила результаты глубокой нейронной сети по сравнению с простой линейной моделью.
Наша цель - подчеркнуть как ценность, так и ограничения общих методов кросс-валидации временных рядов, заложив основу для более глубокого обсуждения в следующей части серии.
Получение данных в MQL5
В этом обсуждении мы начнем с извлечения исторических данных из терминала MetaTrader 5 с помощью скрипта на MQL5, который мы реализовали вручную. Скрипт запускается с сохранения имени файла, который будет записан.
Далее мы сохраняем объем данных, подлежащих извлечению, в качестве входного параметра, который пользователь может передать скрипту. Обязательно задайте свойство #property script_show_inputs в заголовке своего скрипта, чтобы конечный пользователь мог указать количество извлекаемых баров.
После сбора всей необходимой информации мы приступаем к процессу записи файла. С помощью функции FileOpen, мы создаем новый обработчик файлов. Эта функция принимает параметры, которые определяют тип используемого файла, операции, выполняемые с ним, а также соглашение о разделителях или пробелах для файла.
Поэтому мы передаем методу FileOpen имя файла, сгенерированное в начале скрипта, соответствующие режимы и типы работы с файлами, а также запятую в качестве разделителя по нашему выбору.
После этого мы инициализируем цикл for, который выполняется от общего количества извлекаемых баров вплоть до начала. На первой итерации мы записываем имена столбцов, которые хотим сохранить в своем CSV-файле. Для каждой последующей итерации мы извлекаем релевантные рыночные данные, соответствующие данному моменту времени, постепенно продвигаясь от прошлого к настоящему.
Это гарантирует, что наш CSV-файл структурирован так, что самые старые даты располагаются вверху, а самые свежие - в конце.
//+------------------------------------------------------------------+ //| Fetch_Data | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- File name string file_name = Symbol() + " Detailed Market Data As Series.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size; //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Анализ наших данных на Python
После успешного создания нашего CSV-файла следующим шагом будет импорт наших библиотек Pandas, NumPy и Matplotlib, чтобы приступить к анализу.
#Import basic libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt
При чтении данных, созданных с помощью скрипта на MQL5, обратите внимание, что в приведенном ниже примере кода читатель должен заменить путь на свой системный путь.
#Read in the data data = pd.read_csv("/ENTER/YOUR/PATH/HERE/EURUSD Detailed Market Data As Series.csv")
В нашем примере мы хотим продемонстрировать, что кросс-валидация может быть использована для обучения сложных моделей даже на ограниченных наборах данных. Поэтому мы выберем данные за последние два года и отбросим все остальное.
data = data.iloc[(365*2):,:] data.reset_index(drop=True,inplace=True)
Исходя из этого, мы должны определить, насколько далеко в будущем мы хотим сделать прогноз.
#Define a forecast horizon HORIZON = 1
Следующим шагом является подготовка входных признаков, с которыми мы хотим работать, — разностных входных признаков. Мы создаем их путем вычитания текущего входного значения из его предыдущего значения. Мы также добавляем метку к набору данных. После этого отбрасываем все пропущенные значения.
#Let us start by following classical rules data['True Close Diff'] = data['True Close'] - data['True Close'].shift(HORIZON) data['True Open Diff'] = data['True Open'] - data['True Open'].shift(HORIZON) data['True High Diff'] = data['True High'] - data['True High'].shift(HORIZON) data['True Low Diff'] = data['True Low'] - data['True Low'].shift(HORIZON) #Add the target data['Target'] = data['True Close'] - data['True Close'].shift(-HORIZON) data.dropna(inplace=True) data.reset_index(inplace=True,drop=True)
Визуализируем данные.
#Let's visualize the data
plt.plot(data['True Close'],color='black')
plt.grid()
plt.title('EURUSD Data From 2023 - 2024')
plt.xlabel('Time')
plt.ylabel('EURUSD Exchange Rate') 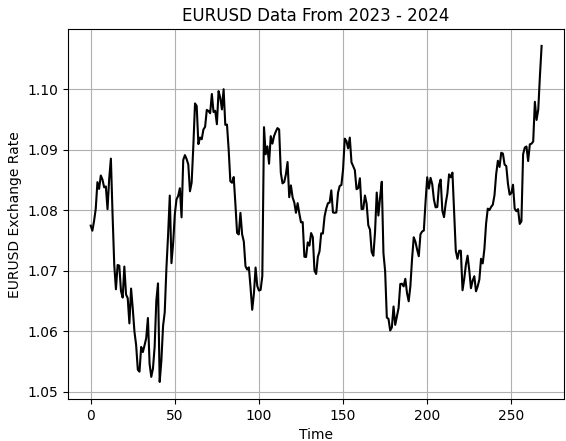
Рисунок 1: Визуализация небольшой выборки исторических обменных курсов на паре EURUSD
Затем разделяем наш набор данных на две половины: первую половину для обучения, а вторую - для тестирования.
#Partition the data train , test = data.iloc[:data.shape[0]//2,:] , data.iloc[data.shape[0]//2:,:]
Храните входные признаки и целевые значения отдельно.
#Differenced inputs X = train.iloc[:,5:-4].columns y = 'Target'
Теперь загружаем свои библиотеки машинного обучения и показатели оценки для оценивания моделей.
#Load a machine learning library from sklearn.neural_network import MLPRegressor from sklearn.linear_model import LinearRegression,Ridge from sklearn.metrics import root_mean_squared_error
Как говорилось ранее во введении к этой статье, сначала определяем контрольную настройку, создавая нашу линейную модель.
#Start the model model = Ridge(alpha=1e-7)
Обучим модель.
model.fit(train.loc[:,X],train.loc[:,y])
Наконец, сохраняем прогнозы, сделанные моделью на тестовом наборе, без обучения модели на этом наборе. Напомним, что важно не обучать модель на тестовом наборе данных, поскольку мы будем использовать эту часть данных позже для оценки нашей модели во время тестирования на исторических данных в MetaTrader 5.
test['Predictions'] = model.predict(test.loc[:,X])
Теперь давайте в целом оценим, насколько надежна наша модель. Начнем с построения прогнозов, сделанных нашей моделью на основе данных вне выборки и сравнения их с фактическими реализованными уровнями цен. Как мы видим, при построении графика работы нашей модели, она, по-видимому, разумно отражает будущее поведение цен. Сделанные ей прогнозы кажутся последовательными и хорошо согласуются с реальным графиком, по которому движется фактическое целевое значение. Однако иногда мы также можем заметить, что модель не отражает колебания ценовых данных так эффективно, как нам хотелось бы.
plt.plot(test.loc[:,'Target'],color='black') plt.plot(test.loc[:,'Predictions'],color='red',linestyle=':') plt.legend(['Target','Predictions']) plt.title('Visualizing Model Accuracy Out of Sample') plt.xlabel('Time') plt.ylabel('EURUSD Exchange Rate') plt.grid()
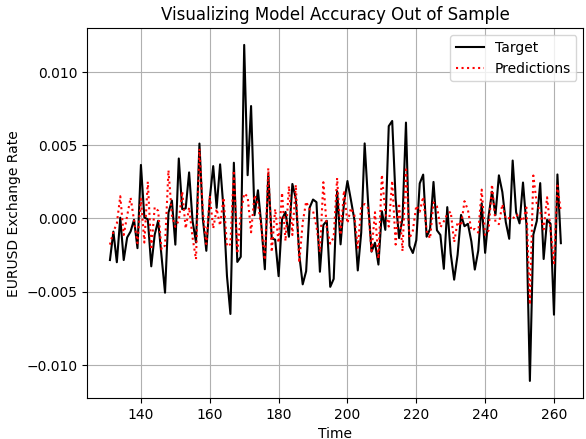
Рисунок 2: Визуализация точности вне выборки, которую может достичь наша простая линейная модель
Кроме того, уровни корреляции, полученные с помощью нашей линейной модели и реальным целевым значением, довольно низкие. Модель показывает коэффициент корреляции 0,58, что является относительно низким показателем.
test.loc[:,['Target','Predictions']].corr().iloc[0,1]
0.5826364163824712
Конвертирование в формат ONNX
ONNX (Open Neural Network Exchange) - это протокол с открытым исходным кодом, позволяющий создавать и развертывать модели машинного обучения в различных средах. Он не зависит от языка программирования, то есть мы можем обучить модель на одном языке, поддерживающем API ONNX, и экспортировать её на другой для развертывания, при условии, что оба языка поддерживают ONNX. Это позволяет использовать одну и ту же модель во многих системах.
Всё это стало возможным благодаря широкому распространению API ONNX. Итак, начнем с импорта библиотеки ONNX, а также библиотеки преобразования, которая преобразует модели scikit-learn в их ONNX-представление. ONNX-представление — это просто описывающий модель математический вычислительный график. Этот график может быть легко преобразован обратно в исходную реализацию.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
После импорта библиотеки ONNX мы определяем входные и выходные параметры, которые модель принимает и возвращает.
initial_types = [("FLOAT INPUT",FloatTensorType([1,4]))] final_types = [("FLOAT OUTPUT",FloatTensorType([1,1]))]
Затем преобразуем каждую из наших обученных моделей в их прототипы в ONNX.
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) model2_proto = convert_sklearn(model2,initial_types=initial_types,target_opset=12)
Далее сохраняем эти прототипы в виде файлов .onnx, используя метод сохранения ONNX.
onnx.save(model_proto,"EURUSD LR D1 DIFFERENCED.onnx") onnx.save(model2_proto,"EURUSD LR 2 D1 RAW.onnx")
Определение нашего базового уровня результатов
Начнём с загрузки созданного ранее буфера ONNX.
//-- Load the onnx buffer #resource "\\Files\\EURUSD LR D1 DIFFERENCED.onnx" as const uchar onnx_buffer[];
Затем определяем связанные с моделью ONNX глобальные переменные, включая хранилище прогнозов и обработчики модели.
//--- Global variables long onnx_model; vector onnx_inputs,onnx_output;
После этого загружаем библиотеку Trade, которая помогает управлять позициями и уровнями риска.
//--- Libraries #include <Trade\Trade.mqh> CTrade Trade;
При первой инициализации модели мы подготавливаем её с помощью метода OnnxCreateFromBuffer(). Этот метод принимает два параметра:
- Буфер ONNX, созданный из файла.
-
Аргументы инициализации — например, указание типа данных ONNX как float, поскольку входные и выходные данные типа float стабильны и широко используются в ONNX.
Затем задаем формы входных и выходных данных модели в соответствии с определенными ранее в Python.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the ONNX model onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Set the input shape of the model ulong model_input[] = {1,4}; OnnxSetInputShape(onnx_model,0,model_input); ulong model_output[] = {1,1}; OnnxSetOutputShape(onnx_model,0,model_output); //--- return(INIT_SUCCEEDED); }
При закрытии приложения мы освобождаем ресурсы, выделенные для модели ONNX, что является стандартной практикой в MQL5.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up dedicated ONNX resources OnnxRelease(onnx_model); }
Каждый раз при получении новых цен сначала проверяем, нет ли открытых позиций. Если это так, готовимся получить прогноз от модели ONNX, чтобы решить, какую позицию принять.
Для этого мы изменяем размер входного вектора в соответствии с ожидаемым параметром — в данном случае, размером четыре. Каждый входной параметр обрабатывается и преобразуется в тип float. Мы также получаем рыночные данные, такие как цены bid и ask. Переменная, называемая padding, определяет ширину нашего стоп-лосса.
Далее подготавливаем вектор для хранения предсказания модели — он должен иметь длину один. Затем используем команду OnnxRun() для получения прогноза, выводим его в терминал и сравниваем с фактической рыночной ценой, чтобы сгенерировать торговый сигнал.
Это классический способ использования моделей машинного обучения в торговых системах. Если позиция уже открыта, мы просто ждем, пока она достигнет либо стоп-лосса, либо тейк-профита. Это помогает нам оценить точность и согласованность.
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check if we have no open positions if(PositionsTotal() ==0) { //--- Prepare the model inputs onnx_inputs.Resize(4); onnx_inputs[0] = (float) iClose(Symbol(),PERIOD_D1,0) - iClose(Symbol(),PERIOD_D1,1); onnx_inputs[1] = (float) iOpen(Symbol(),PERIOD_D1,0) - iOpen(Symbol(),PERIOD_D1,1); onnx_inputs[2] = (float) iHigh(Symbol(),PERIOD_D1,0) - iHigh(Symbol(),PERIOD_D1,1); onnx_inputs[3] = (float) iLow(Symbol(),PERIOD_D1,0) - iLow(Symbol(),PERIOD_D1,1); //--- Market data double ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); double bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); double padding = 5e-3; //--- Store the model's prediction onnx_output.Resize(1); if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_inputs,onnx_output)) { Print("Model forecast: ",onnx_output[0]); //--- Buy setup if(onnx_output[0] > iClose(Symbol(),PERIOD_D1,0)) Trade.Buy(0.01,Symbol(),ask,ask-padding,ask+padding,""); //--- Sell setup else if(onnx_output[0] < iClose(Symbol(),PERIOD_D1,0)) Trade.Sell(0.01,Symbol(),bid,bid+padding,bid-padding,""); } } //--- Otherwise, if we do have open positions else if(PositionsTotal()>0) { //--- Then Print("Position Open"); } } //+------------------------------------------------------------------+
Начнём, как обычно, с выделения дат, которые мы зарезервировали для бэктеста. Напомним, что в Python мы разделили наш набор данных пополам и не обучали модель на тестовом наборе. Это те же даты, которые мы выбрали для тестирования в MetaTrader 5. Это дает нам надежный ориентир для попытки превзойти результаты, используя нашу глубокую нейронную сеть.

Рисунок 3: Выбор дат, необходимых для проведения контрольного бэктеста
Мы также выберем случайные значения задержки, чтобы гарантировать, что условия нашего бэкеста соответствуют реальным условиям торговли.
Рисунок 4: Выбираем условия тестирования, имитирующие ожидаемые условия развертывания
Анализируя кривую эквити, построенную на основе торговой стратегии, мы видим, что, хотя в первой половине периода тестирования на исторических данных стратегия показала медленный старт, в итоге она оказалась прибыльной.
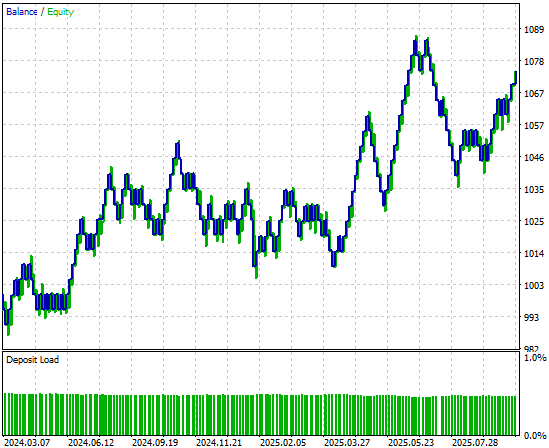
Рисунок 5: Кривая эквити, построенная на основе нашей простой линейной модели, выглядит многообещающе, но, тем не менее, мы можем достичь более высоких показателей результатов
Если взглянуть на подробную статистику производительности, то станет ясно, что есть еще куда стремиться. Например, короткие позиции показывают особенно плохие результаты — точность составляет около пятидесяти процентов, что лишь немного лучше случайного совпадения. Однако интересно отметить, что модель, по-видимому, хорошо работает с длинными позициями.
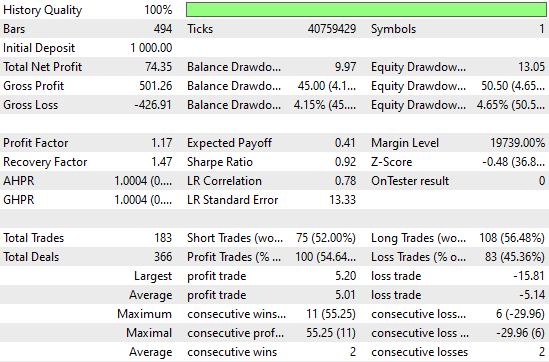
Рисунок 6: Визуализация подробной статистики, полученной в результате оценки нашей простой ридж-модели на данных вне выборки
Улучшение наших первоначальных результатов
Теперь давайте попробуем улучшить эти первоначальные результаты. Начнём с импорта соответствующих методов повторной выборки из библиотеки scikit-learn: RandomizedSearchCV и TimeSeriesSplit. Эти два метода можно использовать вместе для повторной выборки временных рядов.
from sklearn.model_selection import RandomizedSearchCV,TimeSeriesSplit
Далее создаём объект TimeSeriesSplit с пятью фолдами и устанавливаем промежуток между каждой сверткой равным горизонту прогнозирования.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Затем мы создаём нейронную сеть с базовыми настройками, которые будут оставаться последовательными на протяжении всех циклов наших тестов кросс-валидации.
nn = MLPRegressor(random_state=0,shuffle=False,early_stopping=False,max_iter=1000)
Мы также создаём словарь параметров для своей глубокой нейронной сети. Каждый из этих параметров будет проверен и сравнен с целью выявления наилучшей модели.
distributions = dict(activation=['identity','logistic','tanh','relu'], alpha=[100,10,1,1e-1,1e-2,1e-3,1e-4,1e-5,1e-6,1e-7], hidden_layer_sizes=[(4,40,20,10,2),(4,100,200,500,100,4),(4,20,40,20,4,2),(4,10,50,10,4),(4,4,4,4)], solver=['adam','sgd','lbfgs'], learning_rate = ['constant','invscaling','adaptive'] )
Затем мы используем процедуру рандомизированного поиска, которая выполняет контролируемое количество итераций из всех возможных комбинаций параметров. Она не выполняет исчерпывающий поиск по всему входному пространству, а позволяет нам контролировать строгость поиска путем настройки параметра n_iter.
rscv = RandomizedSearchCV(nn,distributions,random_state=0,n_iter=50,n_jobs=-1,scoring='neg_mean_squared_error',cv=tscv)
Для выполнения кросс-валидации мы просто вызываем метод fit() для объекта RandomizedSearchCV, созданного ранее, и сохраняем результаты в переменной, названной в честь процедуры поиска нашей нейронной сети.
nn_search = rscv.fit(train.loc[:,X],train.loc[:,y])
После завершения поиска мы получаем наилучшие параметры, найденные с помощью кросс-валидации.
nn_search.best_params_
{'solver': 'lbfgs',
'learning_rate': 'adaptive',
'hidden_layer_sizes': (4, 40, 20, 10, 2),
'alpha': 0.0001,
'activation': 'identity'}
Затем инициализируем новую модель с этими параметрами и обучаем её на обучающем наборе данных.
model = MLPRegressor(random_state=0,shuffle=False,early_stopping=False,max_iter=1000,solver='lbfgs',learning_rate='adaptive',hidden_layer_sizes=(4, 40, 20, 10, 2),alpha=0.0001,activation='identity') model.fit(train.loc[:,X],train.loc[:,y])
Наконец, мы преобразуем модель в её прототип для ONNX.
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
В конце концов, мы сохраняем файл ONNX нейронной сети на нашем диске, чтобы протестировать внесенные нами улучшения.
onnx.save(model_proto,'EURUSD NN D1.onnx')
Реализуем улучшения
Большинство частей нашего предыдущего приложения остались прежними, так что теперь мы можем сосредоточиться на нескольких строках кода, которые нам нужно обновить, чтобы отразить нашу улучшенную модель. Единственная строка, которую нужно изменить, — это путь к ресурсу в нашем заголовочном файле - он должен быть обновлен, чтобы указывать на новую модель нейронной сети, которую мы только что создали.
//-- Load the onnx buffer #resource "\\Files\\EURUSD NN D1.onnx" as const uchar onnx_buffer[];
Как только это будет сделано, мы сможем понаблюдать за работой нашего нового приложения в течение того же периода тестирования на исторических данных. Мы выберем те же даты, что и раньше, чтобы обеспечить достоверное сравнение.
Рисунок 7: Выбор нашего нового и улучшенного приложения на основе глубоких нейронных сетей для торговли в течение того же периода тестирования
При анализе подробной статистики результатов уже можно заметить существенные изменения. Общая чистая прибыль существенно выросла, как и количество торговых сигналов, зарегистрированных системой. Это означает, что нейронная сеть повысила прибыльность, разместив при этом больше сделок, чем предыдущая версия, — при сопоставимых показателях точности. Эти улучшения выглядят весьма впечатляюще
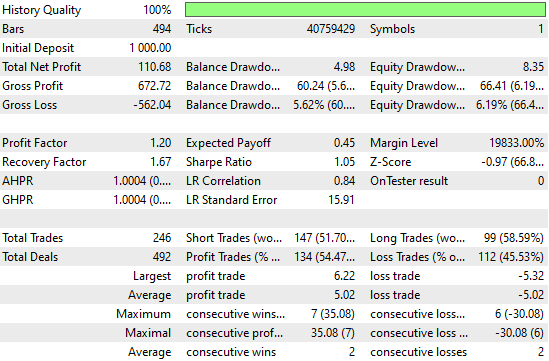
Рисунок 8: Уровни показателей результатов значительно улучшились по сравнению с установленным нами контрольным эталоном
Наконец, взглянув на кривую эквити, построенную на основе новой версии приложения, четко видно, что период консолидации, который ранее замедлял рост в нашем первоначальном бэктесте, теперь сменился сильным, взрывным восходящим трендом, созданным нашей нейронной сетью. Это обеспечит нам более надежный и стабильный источник торговых сигналов, направленных в будущее.
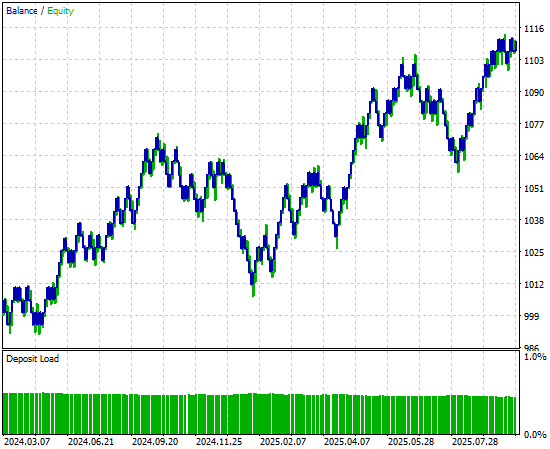
Рисунок 9: Визуализация кривой эквити, полученной в результате применения нашей стратегии, улучшенной с помощью кросс-валидации временных рядов
Заключение
В данной статье представлен обзор преимуществ методов кросс-валидации временных рядов при их осмысленном применении. Читатель уходит, зная, что кросс-валидация временных рядов может быть использована для снижения риска переобучения, настройки и поиска лучших параметров модели, определения наилучшего возможного метода из множества моделей-кандидатов и оценки ошибки тестирования модели на данных, которые она еще не видела.
Как мы уже повторяли на протяжении всей этой статьи, этот список вариантов использования ни в коем случае не является исчерпывающим. Было бы невозможно охватить все преимущества, которые кросс-валидация временных рядов несёт для нашего процесса моделирования.
Однако теперь, когда мы подошли к этому моменту в нашем обсуждении, читатель должен быть хорошо подготовлен к более глубоким вопросам. Можно ли, тем не менее, повысить показатели результатов, продемонстрированных нами здесь сегодня, используя более строгие формы кросс-валидации временных рядов, чем простой метод K-Fold, представленный здесь? Эти вопросы, безусловно, заслуживают дальнейшего изучения.
В следующих обсуждениях мы рассмотрим альтернативные методы кросс-валидации, такие как кросс-валидация временных рядов Walk-Forward, и сравним их с подходом K-Fold. Благодаря этому сравнению мы узнаем, как обосновать, почему один метод может быть более подходящим, чем другой. И чтобы вы понимали, когда это может быть применимо, сначала необходимо иметь четкое представление о том, какую пользу может принести вам кросс-валидация.
| Название файла | Описание файла |
|---|---|
| Fetch_Data.mq5 | Пользовательский скрипт на MQL5, который мы создали для извлечения исторических данных из терминала MetaTrader 5. |
| The_Limitations_of_AI_Model_Selection.ipynb | Созданный нами Jupyter Notebook для анализа рыночных данных, полученных из терминала MetaTrader 5. |
| EURUSD_LR_D1_DIFFERENCED.onnx | Модель линейной регрессии ONNX, которую мы создали в качестве нашей базовой модели. |
| EURUSD_NN_D1.onnx | Модель глубокой нейронной сети ONNX, которую мы создали, чтобы превзойти этот эталон. |
| EURUSD_Daily_EA.mq5 | Приложение для торговли, улучшенное с помощью глубокой нейронной сети, которое мы оптимизировали с использованием кросс-валидации временных рядов. |
| EURUSD_Daily_EA_3.mq5 | Базовое торговое приложение, которое мы намеревались превзойти, несмотря на ограниченный набор данных. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/19775
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования