
Разработка инструментария для анализа Price Action (Часть 34): Построение прогнозных моделей на основе необработанных рыночных данных с помощью усовершенствованного пайплайна загрузки данных

Введение
Анализ Price Action и прогнозирование дальнейшей траектории цены полностью опираются на исторические данные: ключевые уровни поддержки и сопротивления формируются из предыдущих ценовых колебаний, а трейдеров Boom and Crash внезапные всплески нередко застают врасплох – или же они замечают их слишком поздно. Без системного способа собирать, обрабатывать и изучать эти данные каждая сделка превращается в догадку.
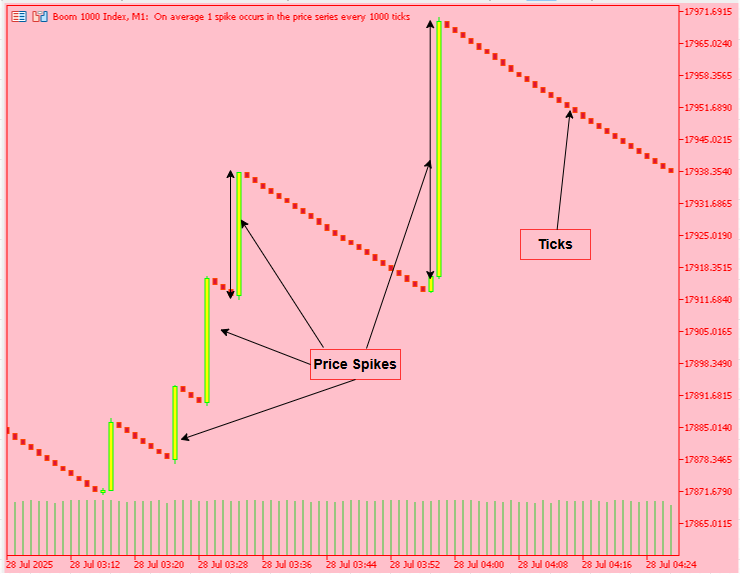
В этой части серии "Разработка инструментария для анализа Price Action" мы представляем сквозную систему, которая преобразует необработанную историю MetaTrader 5 в точные торговые сигналы в реальном времени с помощью машинного обучения. Система состоит из двух согласованно работающих частей:
Загрузка данных в MQL5
- Автоматическое разбиение на порции: легкий скрипт, подключенный к любому графику MetaTrader 5, разбивает историю баров по нескольким символам на JSON-пакеты безопасного размера. Если размер чанка превышает 14 MiB, скрипт динамически делит его пополам, поэтому вы не упретесь в лимит загрузки MetaTrader 5 и вам больше не придется вручную экспортировать CSV.
- Надежная доставка: каждый пакет отправляется методом POST через WebRequest с повторными попытками и подробным логированием. Вы получаете понятную информацию о диапазонах чанков, кодах состояния HTTP и любых ошибках, поэтому в обучающем наборе не возникнет пропусков.
Python-бэкенд машинного обучения
- Единая матрица признаков: поступающая история и логи, сгенерированные советником, объединяются и векторизуются в единую таблицу, где вычисляются величина всплеска, дивергенция MACD, RSI, ATR, наклоны тренда по Калману, полосы индикатора Envelopes и будущие дельты по Prophet.
- Асинхронная компиляция моделей и кэширование: модели Prophet обучаются один раз для каждого символа и кэшируются на час, а классификаторы градиентного бустинга обучаются по запросу, поэтому анализ в реальном времени не задерживается. Глобальная резервная модель обеспечивает покрытие, если данных по отдельному символу недостаточно.
- Полноценные API и CLI: эндпоинты Flask (/upload_history, /upload_spike_csv, /analyze) обрабатывают массовую загрузку истории, циклы сбора в реальном времени и запросы торговых сигналов, а единый CLI охватывает импорт истории, обучение, тесты на исторических данных и диагностику.
Прежде чем модель научится предсказывать всплески Boom and Crash, ей нужна надежная и объемная история. Модуль загрузки истории (History Ingest) – наш основной модуль обработки данных:
- Единообразие независимо от графика: независимо от того, какой инструмент или таймфрейм (M1, H1 и т.д.) вы тестируете, при одинаковых параметрах выбора символа и таймфрейма вы всегда получите один и тот же набор данных – а это ключевое требование для воспроизводимых исследований.
- Соблюдение ограничения по размеру: размер каждого JSON-пакета не превышает 14 MiB, поэтому вы не упираетесь в лимит MetaTrader 5 в 16 MiB и не получаете обрезанные данные.
- Низкая задержка: даже 20 000 баров загружаются менее чем за секунду, поэтому и массовая догрузка истории, и опрос в реальном времени возможны без замедления MetaTrader 5.
- Централизованное логирование и аудит: в логе выводятся индексы чанков, размеры пакетов, сведения об HTTP-ответах и число повторных попыток, поэтому можно точно отследить, какие данные и когда дошли до Python-модуля.
Имея такую основу, наш пайплайн гарантирует богатый и согласованный поток исторических данных, необходимый для обучения моделей, которые обнаруживают ценовые всплески и реагируют на них до того, как они застанут вас врасплох.
Предстоящие разделы:
- Разберем набор инструментов для создания признаков и покажем, как превращать необработанные бары во входные данные для прогнозирования.
- Разберем обучение моделей, стратегии кэширования и настройку производительности.
- Покажем, как вернуть эти модели в MetaTrader 5, чтобы получать оповещения о сигналах на графике и исполнять сделки.
К концу этой серии у вас будет надежный, полностью автоматизированный набор инструментов – от сбора исторических данных до торговых сигналов в реальном времени на основе машинного обучения, – который даст вам преимущество на быстро меняющихся рынках Boom and Crash.
Реализация
Загрузка данных в MQL5
В этом разделе показано, как реализовать загрузку данных в MQL5; ниже приведены пошаговые инструкции по интеграции в ваш проект.
Метаданные скрипта и входные параметры
В верхней части скрипта задаются метаданные, такие как сведения об авторских правах, версия и автор, а затем идут настраиваемые пользователем входные параметры. Сюда входят:
- DaysBack – сколько дней исторических данных нужно получить;
- Timeframe – таймфрейм графика (например, M1);
- StartChunkBars – начальный размер среза данных, который скрипт пытается отправить;
- Timeout_ms – сколько ждать ответа от сервера Python;
- MaxRetry – сколько раз повторять неудачный POST-запрос;
- PauseBetween_ms – длительность паузы между POST-запросами;
- PythonURL – URL локального Python-сервера.
Эти параметры делают скрипт гибким и позволяют адаптировать его к разным задачам и сетевым условиям.
#property strict #property script_show_inputs #property version "1.0" input int DaysBack = 120; // how many days of history to fetch input ENUM_TIMEFRAMES Timeframe = PERIOD_M1; // timeframe for bars input int StartChunkBars = 5000; // initial slice size (bars) input int Timeout_ms = 120000; // WebRequest timeout in ms input int MaxRetry = 3; // retry attempts per chunk input int PauseBetween_ms = 200; // gap between chunk posts input string PythonURL = "http://127.0.0.1:5000/upload_history";
Константы и встроенные вспомогательные функции
Объявленные через #define константы задают максимальный размер JSON (MAX_BYTES) и минимальный размер чанка (MIN_CHUNK). Затем определяются вспомогательные функции L2S (преобразование long в строку) и D2S (преобразование double в строку) для форматирования числовых значений. Функция add() добавляет значение в растущую строку JSON и при необходимости ставит запятую, упрощая дальнейшую сборку JSON в скрипте.
#define MAX_BYTES 14000000 // keep under MT5’s 16 MiB limit #define MIN_CHUNK 1000 // don’t slice smaller than this many bars inline string L2S(long v) { return StringFormat("%I64d", v); } inline string D2S(double v) { return StringFormat("%.5f", v); } void add(string& s, const string v, bool comma) { s += v; if(comma) s += ","; }
Функция построения JSON
Функция BuildJSON() формирует строку JSON из среза массивов исторических данных (время, цена закрытия, цена максимума и цена минимума). Она создает аккуратную структуру JSON, представляющую порцию (чанк) исторических баров в диапазоне от from до to и подходящую для отправки в Python-бэкенд. Этот подход обеспечивает согласованность и компактность данных, а также позволяет сериализовать каждый чанк по отдельности.
string BuildJSON( const string& sym, const long& T[], const double& C[], const double& H[], const double& L[], int from, int to ) { // start JSON with symbol & time array string j = "{\"symbol\":\"" + sym + "\",\"time\":["; for(int i = from; i < to; i++) add(j, L2S(T[i]), i < to - 1); j += "],\"close\":["; // append close prices for(int i = from; i < to; i++) add(j, D2S(C[i]), i < to - 1); // likewise for high j += "],\"high\":["; for(int i = from; i < to; i++) add(j, D2S(H[i]), i < to - 1); // and low j += "],\"low\":["; for(int i = from; i < to; i++) add(j, D2S(L[i]), i < to - 1); j += "]}"; return j; }
Отправка POST с логикой повторных попыток
Функция PostChunk() отвечает за отправку JSON-чанка на сервер Python через WebRequest. Она формирует HTTP-заголовки, преобразует JSON в массив байтов, а при сбоях соединения или HTTP-ошибках повторяет попытку до MaxRetry раз. Каждая попытка пишет в лог информацию о статусе, что упрощает отладку неудачных передач. Если все повторные попытки неудачны, чанк пропускается и процесс прерывается.
bool PostChunk(const string& json, int from, int to) { // convert the JSON string into a UTF‑8 char array char body[]; StringToCharArray(json, body, 0, StringLen(json), CP_UTF8); char reply[]; string hdr = "Content-Type: application/json\r\n", rep_hdr; for(int r = 1; r <= MaxRetry; r++) { int http = WebRequest("POST", PythonURL, hdr, Timeout_ms, body, reply, rep_hdr); if(http != -1 && http < 400) { PrintFormat("Chunk %d-%d HTTP %d %s", from, to, http, CharArrayToString(reply, 0, WHOLE_ARRAY, CP_UTF8)); return true; } // on failure, log and retry PrintFormat("Chunk %d-%d retry %d failed (http=%d err=%d)", from, to, r, http, GetLastError()); Sleep(500); } return false; }
Основная логика в OnStart()
Основная процедура сначала пишет в лог, что загрузчик готов, а затем вычисляет запрашиваемый интервал истории (t1 … t2) на основе текущего времени сервера и параметра DaysBack. С помощью CopyRates() она получает данные OHLC для этого интервала и разбивает результат на отдельные массивы – временные метки, цену закрытия, цену максимума и цену минимума, – чтобы затем эффективно сериализовать данные.
Данные баров передаются порциями. Цикл начинается с заданного пользователем размера StartChunkBars, превращает этот срез в JSON-пакет через BuildJSON() и проверяет, что его размер меньше MAX_BYTES. Если пакет превышает лимит, размер чанка делится пополам, пока пакет не станет допустимым или не будет достигнут порог MIN_CHUNK. Затем подходящий чанк отправляется в Python-бэкенд через PostChunk(), скрипт делает паузу на PauseBetween_ms и переходит к следующему срезу.
int OnStart() { Print("History Ingestor v1.0 ready (timeout=", Timeout_ms, " ms)"); datetime t2 = TimeCurrent(); datetime t1 = t2 - (datetime)DaysBack * 24 * 60 * 60; // 1) Pull bar history from MT5 MqlRates r[]; int total = CopyRates(_Symbol, Timeframe, t1, t2, r); if(total <= 0) { Print("CopyRates error ", GetLastError()); return INIT_FAILED; } ArraySetAsSeries(r, false); // 2) Unpack into simple arrays long T[]; double Cl[], Hi[], Lo[]; ArrayResize(T, total); ArrayResize(Cl, total); ArrayResize(Hi, total); ArrayResize(Lo, total); for(int i = 0; i < total; i++) { T[i] = r[i].time; Cl[i] = r[i].close; Hi[i] = r[i].high; Lo[i] = r[i].low; } // 3) Loop over the data in chunks for(int i = 0; i < total;) { int step = StartChunkBars; bool sent = false; // adaptively shrink chunk until it fits while(step >= MIN_CHUNK) { int to = MathMin(total, i + step); string js = BuildJSON(_Symbol, T, Cl, Hi, Lo, i, to); double size = double(StringLen(js)) / 1e6; PrintFormat("Testing %d–%d size=%.2f MB", i, to, size); if(StringLen(js) < MAX_BYTES) { // post & advance index if(!PostChunk(js, i, to)) return INIT_FAILED; i = to; sent = true; Sleep(PauseBetween_ms); break; } step /= 2; } // abort if even the minimum chunk is too big if(!sent) { Print("Unable to fit minimum chunk – aborting"); return INIT_FAILED; } } Print("Upload finished: ", total, " bars."); return INIT_SUCCEEDED; }
Чтобы настроить History Ingestor в MetaEditor, откройте MetaTrader 5 и нажмите F4, чтобы запустить MetaEditor, затем выберите:
Файл → Новый файл → Скрипт
Дайте скрипту имя, например HistoryIngestor, и завершите мастер. Затем замените сгенерированный шаблон полным кодом (включая директивы #property и функцию OnStart), сохраните файл в папке "Скрипты" и нажмите F7 для компиляции. Убедитесь, что результат компиляции – "0 errors, 0 warnings". Вернитесь в окно "Навигатор" в MetaTrader 5, из раздела "Скрипты" перетащите HistoryIngestor на график и на вкладке "Входные параметры" укажите свои настройки:
DaysBack, Timeframe, размеры чанков, таймауты и PythonURL.
Убедитесь, что домен PythonURL разрешен в разделе:
Сервис → Настройки → Советники
Это нужно для вызовов WebRequest. Кроме того, убедитесь, что на графике загружено достаточно истории, чтобы функция CopyRates могла получить запрошенные бары. После нажатия OK следите за вкладками "Эксперты" и "Журнал": там виден ход загрузки и все сообщения о повторных попытках и ошибках.
Python-бэкенд машинного обучения
Эта система опирается на ряд библиотек Python, включая модели для обнаружения всплесков, но в этой статье основной акцент сделан на загрузке данных; остальные компоненты будут разобраны в следующих частях. Ниже приведен полный список сторонних библиотек и их назначение, а затем – используемые модули стандартной библиотеки:
Сторонние библиотеки
- numpy, pandas: работа с массивами и DataFrame
- pyarrow (или fastparquet): сериализация данных в столбцовом формате
- flask: легковесный Web API
- MetaTrader 5: получение рыночных данных
- ta: индикаторы технического анализа
- scikit-learn, joblib: обучение моделей и их сохранение
- prophet, cmdstanpy: прогнозирование временных рядов
- pykalman: фильтр Калмана
- pytz: поддержка часовых поясов
Их можно установить так:
pip install numpy pandas pyarrow flask MetaTrader5 ta scikit-learn \ joblib prophet cmdstanpy pykalman pytz
При установке prophet автоматически подтягиваются зависимости, такие как tqdm, holidays и lunarcalendar.
Стандартные библиотеки (установка не требуется)
os, sys, logging, warnings, argparse, threading, io, datetime, pathlib, typing, time
| Пакет | Назначение в скрипте | Где используется |
|---|---|---|
| NumPy | Векторизованные вычисления на больших массивах; основа для pandas, TA-lib и scikit-learn. | Все вспомогательные части, связанные с признаками (np.diff, np.std, predict_proba и т.д.). |
| pandas | DataFrame для временных рядов, быстрый ввод-вывод CSV/Parquet, скользящие окна. | Построение DataFrame в /upload_history, удаление дубликатов, создание признаков, обучение моделей, тесты на исторических данных. |
| pyarrow (или fastparquet) | Движок для df.to_parquet() / read_parquet(). Работает гораздо быстрее, чем CSV, занимает меньше места и сохраняет временные метки с точностью до наносекунд. | Дисковое (cDisk) хранилище загруженной истории по каждому символу. |
| flask | Легковесный HTTP-сервер, который предоставляет эндпоинты /upload_history, /upload_spike_csv и /analyze. Преобразует JSON в объекты Python. | Все REST-эндпоинты. |
| MetaTrader 5 | Python-мост к терминалу MetaTrader 5 без графического интерфейса: логин, copy_rates_range, подписка на символ. | Импорт истории, цикл сбора collect_loop, тестер стратегий. |
| ta | Индикаторы технического анализа на чистом Python (MACD, RSI, ATR). | Признаки macd_div, rsi_val, offline_atr. |
| scikit-learn | Ядро машинного обучения (StandardScaler + GradientBoostingClassifier + Pipeline). | Обучение моделей, расчет вероятностей внутри /analyze и тесты на исторических данных. |
| joblib | Быстрая (де)сериализация моделей scikit; реализует посимвольное кэширование моделей. | joblib.dump/load везде, где читаются или записываются модели models/.pkl. |
| cmdstanpy | Stan-бэкенд, который использует Prophet при компиляции. Без него Prophet не сможет обучаться. | Импортируется косвенно через Prophet при выполнении fit(). |
| pykalman | Сглаживание линейным фильтром Калмана; возвращает последний наклон и наклон за 5 баров. | Признак kalman_slope(). |
| pytz | Явное преобразование объектов datetime в UTC, чтобы избежать путаницы между временем брокера и системным временем. | Преобразования в диапазонах истории и тестов на исторических данных. |
| prophet | Низкочастотный прогноз тренда; дает признак delta (оценку будущей цены). | Вспомогательная функция prophet_delta() и кэш асинхронной компиляции. |
Далее разберем часть кода, которая отвечает за сбор и хранение данных, – непосредственно перед этапом обучения модели.
Получение истории MetaTrader 5 через WebRequest
На стороне Python настраивается легковесный Flask API (обычно по адресу http://127.0.0.1:5000/upload_history), который обрабатывает входящие HTTP POST-запросы. Когда скрипт MQL5 отправляет JSON-пакет с историческими данными (имя символа, временные метки, массивы OHLC), этот эндпоинт Flask разбирает и проверяет данные. Это позволяет избежать ручной обработки CSV и гарантирует, что Python-бэкенд сможет автоматически получать данные в реальном времени с любого графика MetaTrader 5 или из скрипта советника через загрузчик.
@app.route('/upload_history', methods=['POST']) def upload_history(): data = request.get_json() df = pd.DataFrame({ 'time': pd.to_datetime(data['time'], unit='s'), 'close': data['close'], 'high': data['high'], 'low': data['low'] }) symbol = data['symbol'] os.makedirs('uploaded_history', exist_ok=True) df.to_parquet(f'uploaded_history/{symbol}.parquet', index=False) return jsonify({"status": "ok", "rows": len(df)})
Хранение и предобработка данных
После получения JSON-пакет преобразуется в pandas DataFrame и при необходимости сохраняется в локальный файл (например, .parquet, .csv или .feather) либо записывается в базу данных временных рядов. Это обеспечивает долговременное хранение данных и позволяет системе при необходимости воспроизводить прошлые рыночные условия. Загруженные данные баров очищаются, избавляются от дубликатов и индексируются по временным меткам, чтобы система вела себя согласованно при повторных загрузках и в разных сессиях. Предобработка также может включать нормализацию часового пояса или фильтрацию нулевых баров.
def load_preprocess(symbol): df = pd.read_parquet(f'uploaded_history/{symbol}.parquet') df.drop_duplicates(subset='time', inplace=True) df.set_index('time', inplace=True) return df
Пайплайн для создания признаков
Исходная история OHLC преобразуется в расширенную матрицу признаков, которая включает как классические технические индикаторы, так и метрики, значимые для машинного обучения. Эти признаки могут включать интенсивность всплеска (пользовательские формулы), значения MACD, RSI, ATR, наклоны по фильтру Калмана и дельты тренда, рассчитанные с помощью Prophet. Эти признаки помогают модели учитывать как краткосрочную волатильность, так и контекст долгосрочного тренда, что критически важно для точного прогнозирования ценовых всплесков и значимых пробоев.
def generate_features(df): df['return'] = df['close'].pct_change() df['volatility'] = df['return'].rolling(10).std() df['range'] = df['high'] - df['low'] df['spike'] = (df['range'] > df['range'].rolling(50).mean() * 2).astype(int) return df.dropna()
Посимвольное кэширование моделей и управление ими
Для каждого загруженного символа Python-система поддерживает отдельную модель машинного обучения. Эти модели либо заново обучаются на загруженных исторических данных, либо обновляются инкрементально. Они сериализуются (через joblib, Pickle или ONNX) и сохраняются в отдельном кэше. Такая архитектура позволяет легко загружать актуальную модель для каждого символа, когда нужно выдать сигнал, обеспечивая и воспроизводимость, и скорость.
def train_model(symbol, df): X = df[['return', 'volatility', 'range']] y = df['spike'] model = RandomForestClassifier(n_estimators=100) model.fit(X, y) os.makedirs('models', exist_ok=True) joblib.dump(model, f'models/{symbol}_model.pkl') return model
Доступ через командную строку и API для обучения и прогнозирования
Python-инструмент предоставляет и утилиты командной строки (например, python train.py --symbol BOOM500), и Flask-эндпоинты в реальном времени (например, /predict) для запуска обучения моделей, тестов на исторических данных и получения актуальных прогнозов. Этот двойной интерфейс поддерживает и пакетные операции, и интеграцию в реальном времени с советниками или панелями управления. Например, после того как модель обучена, советник MQL5 может впоследствии обратиться к эндпоинту /predict и получить сигналы "BUY", "SELL" или "NO ACTION".
@app.route('/predict', methods=['POST']) def predict(): data = request.get_json() features = pd.DataFrame([data['features']]) model = joblib.load(f"models/{data['symbol']}_model.pkl") prediction = model.predict(features)[0] return jsonify({'signal': 'BUY' if prediction == 1 else 'NO ACTION'})
Догрузка истории, переобучение и непрерывное обучение
Система загрузки данных также может работать в непрерывном режиме – отслеживать новые исторические срезы или бары в реальном времени по мере их поступления и периодически запускать переобучение или генерацию сигналов. Это позволяет использовать адаптивные модели, которые остаются актуальными по мере изменения поведения рынка. Это особенно ценно для синтетических инструментов вроде Boom/Crash, у которых со временем могут меняться волатильность и частота всплесков.
def backfill_and_train(symbol): df = load_preprocess(symbol) df = generate_features(df) train_model(symbol, df)
Логирование, мониторинг и отладка
Для прозрачности на стороне Python логируются каждая загрузка, каждый этап создания признаков, каждое событие обучения модели и каждый выданный сигнал. Эти логи при необходимости сохраняются в файлы или внешние дашборды. Это делает пайплайн пригодным для аудита, помогает отслеживать поведение модели и позволяет и разработчикам, и трейдерам понимать, почему были сделаны те или иные прогнозы.
def log_upload(symbol, rows): logging.info(f"{symbol} upload received with {rows} rows.")
Загрузка исторических данных
В этом разделе я покажу, как отработала наша автоматизированная система. После настройки окружения и на стороне MetaTrader 5, и на стороне Python сначала переходим в командной строке в каталог, где находится наш Python-скрипт: ПУТЬ К ВАШЕЙ ПАПКЕC:\Users\hp>cd C:\Users\hp\Pictures\Saved Pictures\Analysis EAЗатем запустите сервер командой: python script_name.py serveВ результате вы должны увидеть, что сервер успешно запустился – в моем случае консоль показала примерно следующее:
* Running on all addresses (0.0.0.0) * Running on http://127.0.0.1:5000
Как только сервер запущен, просто перетащите скрипт на график MetaTrader 5 – загрузка и интеграция данных начнутся сразу.
Логи на вкладке "Эксперты" в MetaTrader 5:
2025.07.28 22:37:58.239 History Ingestor (Crash 1000 Index,M1) HistoryUploader v3.20 (timeout=120000 ms) ready 2025.07.28 22:37:58.365 History Ingestor (Crash 1000 Index,M1) Test 0-5000 size=0.22 MB 2025.07.28 22:38:01.895 History Ingestor (Crash 1000 Index,M1) Chunk 0-5000 HTTP 200 {"rows_written":4990,"status":"ok"} 2025.07.28 22:38:01.895 History Ingestor (Crash 1000 Index,M1) 2025.07.28 22:38:02.185 History Ingestor (Crash 1000 Index,M1) Test 5000-10000 size=0.22 MB 2025.07.28 22:38:07.794 History Ingestor (Crash 1000 Index,M1) Chunk 5000-10000 HTTP 200 {"rows_written":4990,"status":"ok"} 2025.07.28 22:38:07.794 History Ingestor (Crash 1000 Index,M1) 2025.07.28 22:38:08.118 History Ingestor (Crash 1000 Index,M1) Test 10000-15000 size=0.22 MB 2025.07.28 22:38:13.531 History Ingestor (Boom 1000 Index,M1) HistoryUploader v3.20 (timeout=120000 ms) ready 2025.07.28 22:38:13.677 History Ingestor (Boom 1000 Index,M1) Test 0-5000 size=0.24 MB 2025.07.28 22:38:17.710 History Ingestor (Boom 1000 Index,M1) Chunk 0-5000 HTTP 200 {"rows_written":4990,"status":"ok"}
Логи Python в командной строке:
Crash 1000 Index 4990 rows 22:38:01 INFO 127.0.0.1 - - [28/Jul/2025 22:38:01] "POST /upload_history HTTP/1.1" 200 - 22:38:01 DEBUG cmd: where.exe tbb.dll cwd: None 22:38:02 DEBUG Adding TBB (C:\Users\hp\AppData\Local\Programs\Python\Python313\Lib\site-packages\ prophet\stan_model\cmdstan-2.33.1\stan\lib\stan_math\lib\tbb) to PATH 22:38:02 DEBUG input tempfile: C:\Users\hp\AppData\Local\Temp\tmpjw4u6es7\0j91e5cb.json 22:38:02 DEBUG input tempfile: C:\Users\hp\AppData\Local\Temp\tmpjw4u6es7\lzpoq1nb.json 22:38:02 DEBUG idx 0 22:38:02 DEBUG running CmdStan, num_threads: None 22:38:02 DEBUG CmdStan args: ['C:\\Users\\hp\\AppData\\Local\\Programs\\Python\\Python313 \\Lib\\site-packages\\prophet\\stan_model\\prophet_model.bin', 'random', 'seed=46049', 'data', 'file=C:\\Users\\hp\\AppData\\Local\\Temp\\tmpjw4u6es7\\0j91e5cb.json', 'init=C:\\Users\\hp\\ AppData\\Local\\Temp\\tmpjw4u6es7\\lzpoq1nb.json', 'output', 'file=C:\\Users\\hp\\AppData\\ Local\\Temp\\tmpjw4u6es7\\prophet_modelo4ioyzqc\\prophet_model-20250728223802.csv', 'method=optimize', 'algorithm=lbfgs', 'iter=10000'] 22:38:02 - cmdstanpy - INFO - Chain [1] start processing 22:38:02 INFO Chain [1] start processing 22:38:07 DEBUG cmd: where.exe tbb.dll cwd: None Crash 1000 Index 4990 rows 22:38:07 INFO 127.0.0.1 - - [28/Jul/2025 22:38:07] "POST /upload_history HTTP/1.1" 200 - 22:38:07 DEBUG TBB already found in load path 22:38:07 DEBUG input tempfile: C:\Users\hp\AppData\Local\Temp\tmpjw4u6es7\flzd3tj5.json 22:38:08 DEBUG input tempfile: C:\Users\hp\AppData\Local\Temp\tmpjw4u6es7\et_obcyf.json 22:38:08 DEBUG idx 0 22:38:08 DEBUG running CmdStan, num_threads: None 22:38:08 DEBUG CmdStan args: ['C:\\Users\\hp\\AppData\\Local\\Programs\\Python\\Python313 \\Lib\\site-packages\\prophet\\stan_model\\prophet_model.bin', 'random', 'seed=15747', 'data' , 'file=C:\\Users\\hp\\AppData\\Local\\Temp\\tmpjw4u6es7\\flzd3tj5.json', 'init=C:\\Users\\hp \\AppData\\Local\\Temp\\tmpjw4u6es7\\et_obcyf.json', 'output', 'file=C:\\Users\\hp\\AppData\\ Local\\Temp\\tmpjw4u6es7\\prophet_modelgjfhjsn1\\prophet_model-20250728223808.csv', 'method=optimize', 'algorithm=lbfgs', 'iter=10000'] 22:38:08 - cmdstanpy - INFO - Chain [1] start processing 22:38:08 INFO Chain [1] start processing 22:38:10 - cmdstanpy - INFO - Chain [1] done processing 22:38:10 INFO Chain [1] done processing 22:38:10 INFO Prophet compiled for Crash 1000 Index 22:38:15 - cmdstanpy - INFO - Chain [1] done processing 22:38:15 INFO Chain [1] done processing 22:38:15 INFO Prophet compiled for Crash 1000 Index 22:38:17 DEBUG cmd: where.exe tbb.dll cwd: None Boom 1000 Index 4990 rows 22:38:17 INFO 127.0.0.1 - - [28/Jul/2025 22:38:17] "POST /upload_history HTTP/1.1" 200 - 22:38:17 DEBUG TBB already found in load path 22:38:17 DEBUG input tempfile: C:\Users\hp\AppData\Local\Temp\tmpjw4u6es7\9tu4ni1m.json 22:38:17 DEBUG input tempfile: C:\Users\hp\AppData\Local\Temp\tmpjw4u6es7\dbjg87e6.json 22:38:17 DEBUG idx 0 22:38:17 DEBUG running CmdStan, num_threads: None 22:38:17 DEBUG CmdStan args: ['C:\\Users\\hp\\AppData\\Local\\Programs\\Python\\Python313 \\Lib\\site-packages\\prophet\\stan_model\\prophet_model.bin', 'random', 'seed=45546', 'data', 'file=C:\\Users\\hp\\AppData\\Local\\Temp\\tmpjw4u6es7\\9tu4ni1m.json', 'init=C:\\Users\\hp \\AppData\\Local\\Temp\\tmpjw4u6es7\\dbjg87e6.json', 'output', 'file=C:\\Users\\hp\\AppData \\Local\\Temp\\tmpjw4u6es7\\prophet_modele7mw_egb\\prophet_model-20250728223817.csv', 'method=optimize', 'algorithm=lbfgs', 'iter=10000'] 22:38:17 - cmdstanpy - INFO - Chain [1] start processing 22:38:17 INFO Chain [1] start processing Crash 1000 Index 4990 rows 22:38:18 INFO 127.0.0.1 - - [28/Jul/2025 22:38:18] "POST /upload_history HTTP/1.1" 200 - 22:38:23 - cmdstanpy - INFO - Chain [1] done processing 22:38:23 INFO Chain [1] done processing 22:38:24 INFO Prophet compiled for Boom 1000 Index Boom 1000 Index 4990 rows 22:38:27 INFO 127.0.0.1 - - [28/Jul/2025 22:38:27] "POST /upload_history HTTP/1.1" 200 - Crash 1000 Index 4990 rows 22:38:28 INFO 127.0.0.1 - - [28/Jul/2025 22:38:28] "POST /upload_history HTTP/1.1" 200 - Boom 1000 Index 4990 rows 22:38:37 INFO 127.0.0.1 - - [28/Jul/2025 22:38:37] "POST /upload_history HTTP/1.1" 200 - Crash 1000 Index 4990 rows 22:38:38 INFO 127.0.0.1 - - [28/Jul/2025 22:38:38] "POST /upload_history HTTP/1.1" 200 - 22:38:49 DEBUG cmd: where.exe tbb.dll
Логи показывают, что 4 990 строк исторических данных по индексам Crash 1000 и Boom 1000 были успешно загружены и отправлены на Python-сервер (HTTP 200), после чего CmdStan через cmdstanpy запустил цепочки оптимизации для компиляции моделей Prophet по каждому индексу. Это подтверждается сообщениями о запуске и завершении каждой цепочки, а также итоговыми сообщениями "Prophet compiled" для обоих инструментов.
Заключение
Мы успешно собрали исторические ценовые данные в MetaTrader 5, передали их в Python-сервис и сохранили для обучения модели – это видно и во вкладке "Эксперты" MetaTrader 5, и в логах консоли на ПК. Этот надежный конвейер загрузки данных закладывает основу для нашей системы обнаружения всплесков. Затем мы обучим модель обнаружения в Python и интегрируем ее обратно в MetaTrader 5 через советник MQL5, чтобы сигналы в реальном времени можно было генерировать и получать прямо на торговой платформе. Мы успешно собрали исторические ценовые данные в MetaTrader 5, передали их в Python-сервис и сохранили для обучения модели – это видно и во вкладке "Эксперты" MetaTrader 5, и в логах консоли на ПК. Этот надежный конвейер загрузки данных закладывает основу для нашей системы обнаружения всплесков.
Затем мы обучим модель обнаружения в Python и интегрируем ее обратно в MetaTrader 5 через советник MQL5, чтобы сигналы в реальном времени можно было генерировать и получать прямо на торговой платформе.
Если при настройке возникнут трудности, вы можете обратиться ко мне в любое время.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18979
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования