Машинное обучение и Data Science (Часть 43): Поиск скрытых паттернов в индикаторах с помощью моделей латентных гауссовых смесей LGMM

Содержание
- Введение
- Модель латентных гауссовых смесей (Latent Gaussian mixture model, LGMM)
- Математические основы LGMM
- Обучение LGMM на данных индикаторов
- MQL5-индикатор на основе LGMM
- Как подобрать оптимальное количество компонентов для LGMM
- Сочетание модели латентных гауссовых смесей с классификатором
- Торговый робот на основе LGMM
- Заключение
Введение
Почти все торговые стратегии, которыми мы пользуемся как трейдеры, основаны на выявлении и обнаружении определенных паттернов. Мы анализируем индикаторы в поисках закономерностей и подтверждений, а также рисуем объекты и линии (например, поддержки и сопротивления), чтобы определить текущее состояние рынка.
При этом задача поиска паттернов при анализе финансовых рынков является более простой для человека, чем для программы — автоматизировать этот процесс значительно сложнее из-за природы самих рынков (шумных и хаотичных).
Для решения этой задачи некоторые перешли к использованию искусственного интеллекта (AI) и машинного обучения, например, методов компьютерного зрения, которые обрабатывают изображения и данные аналогично тому, как это делают люди — мы говорили об этом в одной из предыдущих статей..
В данной статье мы рассмотрим вероятностную модель под названием Latent Gaussian Mixture Model (LGMM, латентная гауссовая смесь), способную обнаруживать паттерны. Используя данные индикаторов, мы исследуем эффективность этой модели в задачах выявления скрытых закономерностей и формировании точных прогнозов на финансовых рынках.

Модель латентных гауссовых смесей (Latent Gaussian mixture model, LGMM)
Latent Gaussian Mixture Model — это вероятностная модель, предполагающая, что данные генерируются как смесь нескольких гауссовских распределений, каждое из которых связано со скрытой (латентной) переменной.
Она является расширением модели гауссовых смесей Gaussian Mixture Model (GMM), в которой используются латентные переменные, объясняющие принадлежность каждого наблюдения к определенному кластеру.
Латентные гауссовские модели применяются для анализа данных, в которых процессы, генерирующие наблюдаемые данные, не наблюдаются напрямую и предполагается, что они имеют гауссовское (нормальное) распределение.
Термин latent относится именно к этим ненаблюдаемым переменным — подобно невидимым электрическим сигналам в электрической цепи, которые влияют на поведение системы, но не измеряются напрямую.
На финансовых рынках такие латентные переменные могут представлять скрытые торговые паттерны в данных, которые мы нередко неправильно интерпретируем или вовсе не замечаем.
Проще говоря, основа LGMM включает следующие элементы:
- Латентные (скрытые) переменные
Это ненаблюдаемые переменные, предполагаемо имеющие гауссовское распределение. Они представляют скрытые факторы, влияющие на наблюдаемые данные. - Наблюдения
Фактически собранные данные, которые обычно не имеют гауссовского распределения и могут следовать любой статистической модели, связанной с латентными переменными через известную функцию. - Параметры
Параметры управляют связью между латентными переменными и наблюдениями, включая средние значения и дисперсии соответствующих распределений.
Математические основы LGMM
LGMM представляет собой вероятностную генеративную модель, в основе которой лежит метод кластеризации. Она включает:
Латентные переменные
- они не наблюдаются напрямую;
- они представляют компонент (кластер), из которого была получена конкретная точка данных;
- часто моделируются категориальным (дискретным) распределением, например,
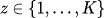
Модель смеси
Распределение вероятностей данных представляется как взвешенная сумма нескольких гауссовских распределений.
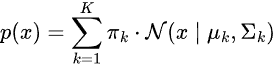
где:
-
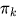 — коэффициент смешивания (априорная вероятность) компонента
— коэффициент смешивания (априорная вероятность) компонента 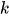 ,
, 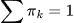
-
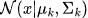 — гауссовское распределение со средним
— гауссовское распределение со средним 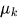 и ковариационной матрицей
и ковариационной матрицей 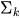
Представление через латентные переменные
Вместо непосредственного моделирования p(x) рассматривается представление:
![]()
где:
Целью модели является оценка латентных переменных и параметров ![]() .
.
Наиболее распространенным методом оценки этих параметров является алгоритм Expectation-Maximization (EM).
Алгоритм Expectation-Maximization (EM) для LGMM
Алгоритм включает два основных шага: прогнозирование Expectation и максимизация Maximization.
Шаг 01 — Expectations
На этом этапе оценивается апостериорная вероятность того, что каждая точка данных принадлежит каждому из гауссовских распределений.
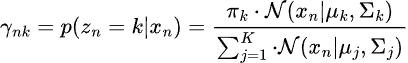
Шаг 02 — Maximization
На этом этапе параметры модели обновляются с использованием вычисленных значений ![]() .
.
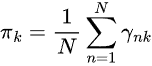
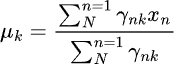
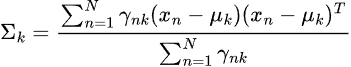
В процессе обучения шаги 01 и 02 повторяются до тех пор, пока модель не достигнет сходимости.
LGMM применяется во многих практических задачах, включая кластеризацию данных с учетом неопределенности (soft clustering), обнаружение аномалий, оценку плотности распределения и задачи распознавания речи.
Обучение LGMM на данных индикаторов
Мы знаем, что в данных индикаторов содержатся паттерны, которые трейдеры используют для принятия обоснованных торговых решений. Попробуем использовать LGMM для поиска таких паттернов.
Сначала соберем данные индикаторов из MetaTrader 5, используем код на MQL5.
- Symbol = XAUUSD.
- Timeframe = DAILY.
Filename: Get XAUUSD Data.mq5
#include <Arrays\ArrayString.mqh> #include <Arrays\ArrayObj.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 input datetime start_date = D'2005.01.01'; input datetime end_date = D'2023.01.01'; input string symbol = "XAUUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; struct indicator_struct { long handle; CArrayString buffer_names; //buffer_names array }; indicator_struct indicators[15]; //Structure for keeping indicator handle alongside its buffer names //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- vector time, open, high, low, close; if (!SymbolSelect(symbol, true)) { printf("%s failed to select symbol %s, Error = %d",__FUNCTION__,symbol,GetLastError()); return; } //--- time.CopyRates(symbol, timeframe, COPY_RATES_TIME, start_date, end_date); open.CopyRates(symbol, timeframe, COPY_RATES_OPEN, start_date, end_date); high.CopyRates(symbol, timeframe, COPY_RATES_HIGH, start_date, end_date); low.CopyRates(symbol, timeframe, COPY_RATES_LOW, start_date, end_date); close.CopyRates(symbol, timeframe, COPY_RATES_CLOSE, start_date, end_date); CDataFrame df; df.insert("Time", time); df.insert("Open", open); df.insert("High", high); df.insert("Low", low); df.insert("Close", close); //--- Oscillators indicators[0].handle = iATR(symbol, timeframe, 14); indicators[0].buffer_names.Add("ATR"); indicators[1].handle = iBearsPower(symbol, timeframe, 13); indicators[1].buffer_names.Add("BearsPower"); indicators[2].handle = iBullsPower(symbol, timeframe, 13); indicators[2].buffer_names.Add("BullsPower"); indicators[3].handle = iChaikin(symbol, timeframe, 3, 10, MODE_EMA, VOLUME_TICK); indicators[3].buffer_names.Add("Chainkin"); indicators[4].handle = iCCI(symbol, timeframe, 14, PRICE_OPEN); indicators[4].buffer_names.Add("CCI"); indicators[5].handle = iDeMarker(symbol, timeframe, 14); indicators[5].buffer_names.Add("Demarker"); indicators[6].handle = iForce(symbol, timeframe, 13, MODE_SMA, VOLUME_TICK); indicators[6].buffer_names.Add("Force"); indicators[7].handle = iMACD(symbol, timeframe, 12, 26, 9, PRICE_OPEN); indicators[7].buffer_names.Add("MACD MAIN_LINE"); indicators[7].buffer_names.Add("MACD SIGNAL_LINE"); indicators[8].handle = iMomentum(symbol, timeframe, 14, PRICE_OPEN); indicators[8].buffer_names.Add("Momentum"); indicators[9].handle = iOsMA(symbol, timeframe, 12, 26, 9, PRICE_OPEN); indicators[9].buffer_names.Add("OsMA"); indicators[10].handle = iRSI(symbol, timeframe, 14, PRICE_OPEN); indicators[10].buffer_names.Add("RSI"); indicators[11].handle = iRVI(symbol, timeframe, 10); indicators[11].buffer_names.Add("RVI MAIN_LINE"); indicators[11].buffer_names.Add("RVI SIGNAL_LINE"); indicators[12].handle = iStochastic(symbol, timeframe, 5, 3,3,MODE_SMA,STO_LOWHIGH); indicators[12].buffer_names.Add("StochasticOscillator MAIN_LINE"); indicators[12].buffer_names.Add("StochasticOscillator SIGNAL_LINE"); indicators[13].handle = iTriX(symbol, timeframe, 14, PRICE_OPEN); indicators[13].buffer_names.Add("TEMA"); indicators[14].handle = iWPR(symbol, timeframe, 14); indicators[14].buffer_names.Add("WPR"); //--- Get buffers for (uint ind=0; ind<indicators.Size(); ind++) //Loop through all the indicators { for (uint buffer_no=0; buffer_no<(uint)indicators[ind].buffer_names.Total(); buffer_no++) //Their buffer names resemble their buffer numbers { string name = indicators[ind].buffer_names.At(buffer_no); //Get the name of the buffer, it is helpful for the DataFrame and CSV file vector buffer = {}; if (!buffer.CopyIndicatorBuffer(indicators[ind].handle, buffer_no, start_date, end_date)) //Copy indicator buffer { printf("func=%s line=%d | Failed to copy %s indicator buffer, Error = %d",__FUNCTION__,__LINE__,name,GetLastError()); continue; } df.insert(name, buffer); //Insert a buffer vector and its name to a dataframe object } } df.to_csv(StringFormat("Oscillators.%s.%s.csv",symbol,EnumToString(timeframe)), true); //Save all the data to a CSV file }
Результаты.
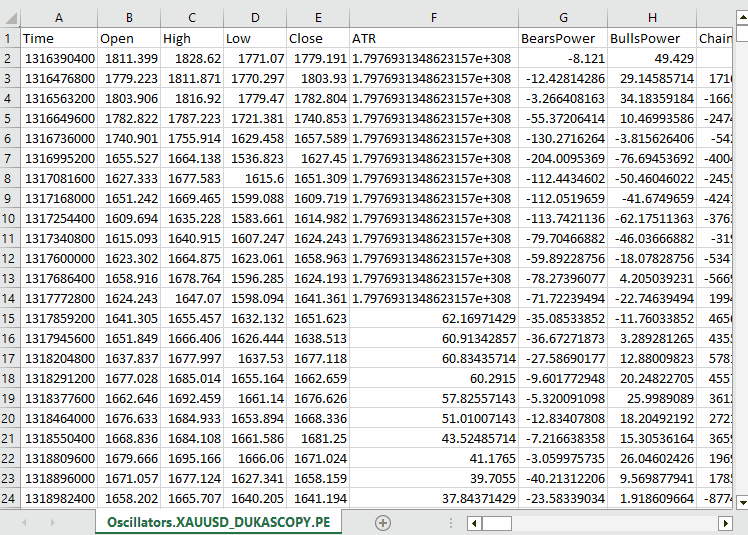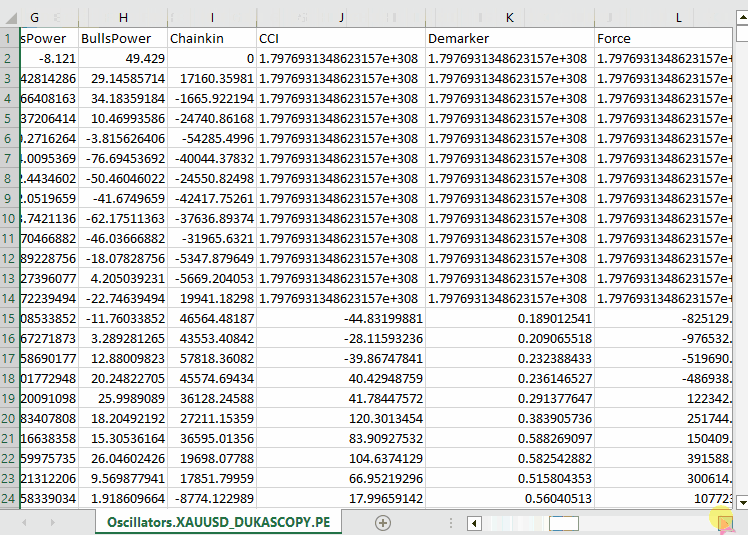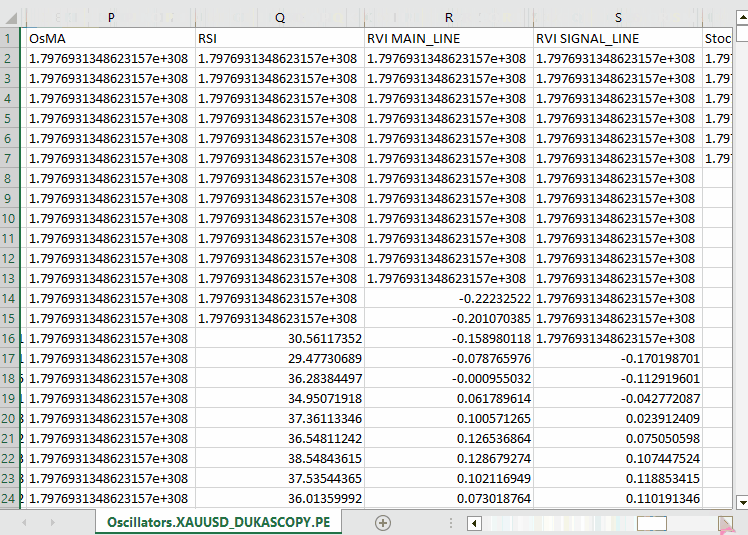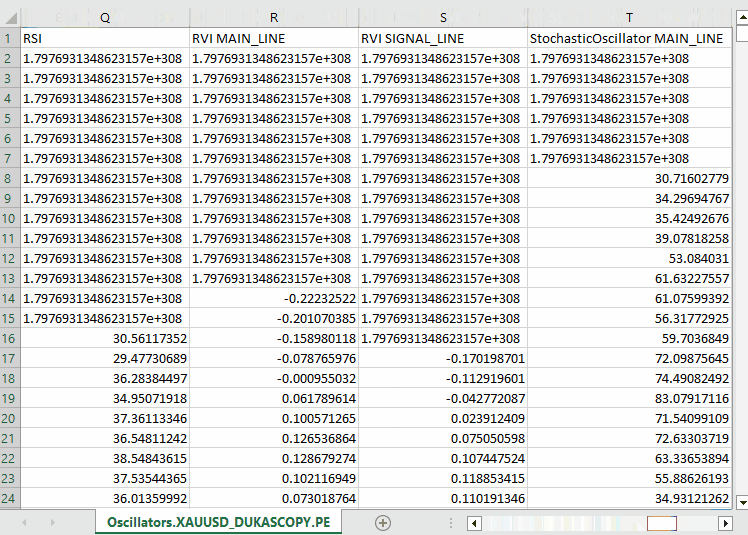
Обратите внимание, что мы собрали практически все встроенные осцилляторы из MQL5. Большинство из них формируют стационарные данные, поскольку обычно имеют фиксированные минимальные и максимальные значения. Например, индикатор RSI принимает значения от 0 до 100.
LGMM способен работать с данными с различными статистическими свойствами, включая нестационарные данные. Все же при использовании стационарных данных модели легче находить значимые структуры и паттерны, поскольку статистические свойства стационарных временных рядов остаются постоянными во времени.
Вы можете использовать любые другие данные.
Помимо данных индикаторов мы также собрали переменные Open, High, Low, Close и Time (OHLCT) для использования в обучении. Эти данные можно использовать для визуализации и для построения целевой переменной в предиктивных моделях машинного обучения, помимо LGMM.
В Python-скрипте (Jupyter Notebook) сначала импортируем зависимости и инициализируем приложения, а затем сразу же загружаем собранные данные.
Filename: main.ipynb
import pandas as pd import numpy as np import MetaTrader5 as mt5 import os from Trade.TerminalInfo import CTerminalInfo import matplotlib.pyplot as plt import seaborn import warnings warnings.filterwarnings("ignore") seaborn.set_style("darkgrid") if not mt5.initialize(): print("Failed to Initialize MetaTrade5, Error = ",mt5.last_error()) mt5.shutdown() terminal = CTerminalInfo() # similarly to CTerminalInfo from MQL5. For getting information about the MetaTrader5 app
Импортируем данные из общей папки, куда мы их сохранили.
common_path = os.path.join(terminal.common_data_path(), "Files") symbol = "XAUUSD" timeframe = "PERIOD_D1" df = pd.read_csv(os.path.join(common_path, f"Oscillators.{symbol}.{timeframe}.csv")) # the same naming pattern as the one used in the MQL5 script # Identify max float value max_float = np.finfo(float).max # Replace all max float (double) values with NaN produced by preliminary indicator calculations df = df.replace(max_float, np.nan) df.dropna(inplace=True) df["Time"] = pd.to_datetime(df["Time"], unit="s") df.head()
Результаты.
Time Open High Low Close ATR BearsPower BullsPower Chainkin CCI ... MACD SIGNAL_LINE Momentum OsMA RSI RVI MAIN_LINE RVI SIGNAL_LINE StochasticOscillator MAIN_LINE StochasticOscillator SIGNAL_LINE TEMA WPR 0 2005-01-03 438.45 438.71 426.72 429.55 5.481429 -12.314215 -0.324215 -1079.046551 -51.013015 ... 0.175727 99.870165 -0.582169 46.666555 -0.082596 0.018515 26.976532 32.920132 -0.000089 -85.144357 1 2005-01-04 429.52 430.18 423.71 427.51 5.450000 -13.677899 -7.207899 -1129.324384 -235.622347 ... -0.000779 98.615544 -1.252741 37.393138 -0.158362 -0.048541 22.158658 27.150101 -0.000190 -82.774252 2 2005-01-05 427.50 428.77 425.10 426.58 5.162143 -10.743913 -7.073913 -1496.644248 -196.837418 ... -0.247283 97.044402 -1.816758 35.666584 -0.227422 -0.119850 17.070979 22.068723 -0.000325 -86.990027 3 2005-01-06 426.31 427.85 420.17 421.37 5.234286 -13.606211 -5.926211 -3349.884147 -164.038728 ... -0.576309 97.480164 -2.194161 34.651526 -0.269634 -0.187300 14.096364 17.775334 -0.000482 -95.312500 4 2005-01-07 421.39 425.48 416.57 419.02 5.605000 -15.098181 -6.188181 -4970.426959 -168.301515 ... -1.015433 95.440750 -2.669414 30.754440 -0.305796 -0.243045 11.442611 14.203318 -0.000670 -91.609589
Подготовим целевую переменную для задачи классификации, чтобы в будущем использовать ее в моделях машинного обучения для создания классификаторов. Отбрасываем неиндикаторные признаки.
lookahead = 1 df["future_close"] = df["Close"].shift(-lookahead) new_df = df.dropna() new_df["Direction"] = np.where(new_df["future_close"]>new_df["Close"], 1, -1) # if a the close value in the next bar(s)=lookahead is above the current close price, thats a long signal otherwise that's a short signal
from sklearn.model_selection import train_test_split X = new_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "future_close", "Direction" ]) y = new_df["Direction"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=42)
Нужно проверить, есть ли у нас нужные данные индикаторов.
X_train.head()
Результаты.
ATR BearsPower BullsPower Chainkin CCI Demarker MACD MAIN_LINE MACD SIGNAL_LINE Momentum OsMA RSI RVI MAIN_LINE RVI SIGNAL_LINE StochasticOscillator MAIN_LINE StochasticOscillator SIGNAL_LINE TEMA WPR 1057 30.139286 34.958195 62.858195 16280.794393 268.371098 251356.076923 -1.759289 -15.645899 107.768519 13.886610 62.077386 0.229591 0.108028 92.301971 83.886543 -0.002663 -8.048595 3806 3.096429 0.724299 3.314299 -1279.189840 69.806094 696.923077 -0.121217 -0.952863 100.299538 0.831645 52.157089 0.096237 0.080054 67.031250 71.466497 -0.000077 -21.325052 38884 5.927143 -8.488258 -3.858258 -2005.866698 -213.672289 -3333.080000 -0.049837 0.496440 99.774916 -0.546277 39.550361 -0.022395 0.035070 28.046540 49.606252 0.000012 -73.130342 10351 2.060714 -0.491108 1.158892 723.246254 40.384615 2508.735385 1.293179 0.953618 100.533084 0.339561 58.791715 0.217352 0.294053 57.239819 69.770534 0.000123 -19.070322 38170 5.632143 -5.682364 -3.262364 -1321.008995 -109.039933 -1673.607692 -0.609996 0.785433 99.712893 -1.395429 41.917705 -0.062258 -0.053202 13.322009 9.490964 0.000035 -77.826942
Наконец, обучим модель LGMM.
from sklearn.mixture import GaussianMixture from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType components = 3 gmm = GaussianMixture(n_components=components, covariance_type="full", random_state=42) gmm.fit(X_train) latent_features_train = gmm.predict_proba(X_train) latent_features_test = gmm.predict_proba(X_test)
Я использую 3 компонента для модели Gaussian Mixture, предполагая, что модель сможет кластеризовать наблюдаемые паттерны индикаторов на 3 кластера. Предположительно, один кластер соответствует бычьему тренду (сигнал на покупку), второй — медвежьему сигналу, третий — консолидации или боковому движению.Однако это лишь предположение.
Как и в случае с другими методами обучения без учителя и кластеризации, интерпретировать полученные компоненты модели довольно сложно. На данный момент можно лишь предположить, что каждый компонент соответствует одному из трех описанных классов.
Вероятно,. вы задаетесь вопросом, почему я называю модель Latent Gaussian Mixture Model (LGMM), хотя фактически использую модель GaussianMixture из библиотеки Scikit-Learn.
Импортированная модель GaussianMixture функционально эквивалентна LGMM, описанной в математическом разделе данной статьи. Теоретически, это одна и та же модель.
Выведем массив latent_features_train.
latent_features_train
Результаты.
array([[9.48947877e-13, 1.08107288e-62, 1.00000000e+00], [9.71935407e-01, 2.80542130e-02, 1.03801388e-05], [5.35722226e-03, 9.94642667e-01, 1.10916653e-07], ..., [7.72441751e-08, 8.80712550e-41, 9.99999923e-01], [9.99975623e-01, 1.07924534e-33, 2.43771745e-05], [1.91968188e-01, 8.08030586e-01, 1.22621110e-06]], shape=(3760, 3))
Модель LGMM сформировала массив из трех элементов в каждой строке предсказаний, где каждый столбец представляет вероятность того, что входные данные принадлежат одному из трех кластеров. Сумма вероятностей по всем трем столбцам в каждой строке равна 1..
Поскольку интерпретировать эти значения в текущем виде достаточно сложно, преобразуем модель в формат ONNX, визуализируем кластеры в MQL5 и посмотрим, какие выводы можно сделать на основе результатов этой вероятностной модели.
Индикатор MQL5 на основе Latent Gaussian Mixture Model (LGMM)
Сначала сохраним LGMM в формате ONNX.
# Define input type (shape should match your training data) initial_type = [("float_input", FloatTensorType([None, X_train.shape[1]]))] # Convert the pipeline to ONNX format onnx_model = convert_sklearn(gmm, initial_types=initial_type) # Save the model to a file with open(os.path.join(common_path, f"LGMM.{symbol}.{timeframe}.onnx"), "wb") as f: f.write(onnx_model.SerializeToString())
Ниже показана архитектура модели при открытии в Netron.
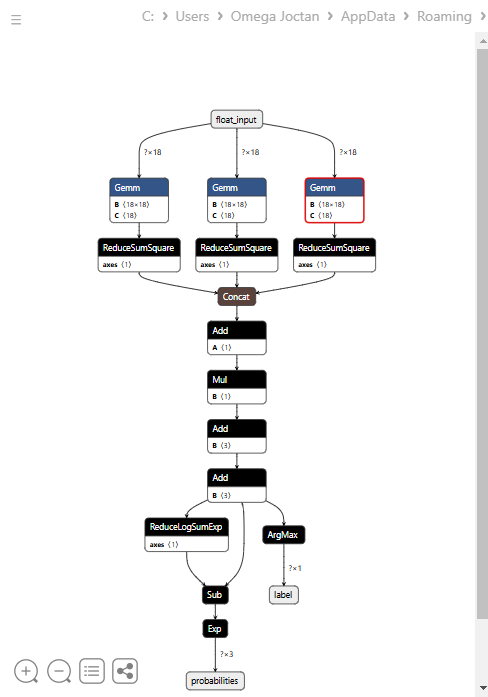
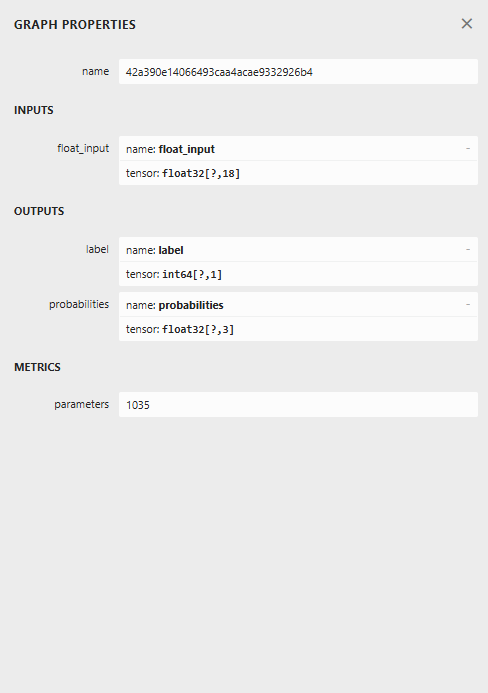
Архитектура модели выглядит необычно: в финальном узле присутствуют два выхода — один для предсказанной метки, а второй для вероятностей. Это необходимо учитывать при реализации кода загрузки модели в MQL5.
Загрузка LGMM в MQL5
Файл: Gaussian Mixture.mqh
Нам потребуется структура выходных данных, которая может принимать несколько массивов значений, чтобы корректно обрабатывать два выходных узла модели, каждый из которых содержит собственный массив результатов.
class CGaussianMixture { protected: bool initialized; long onnx_handle; void PrintTypeInfo(const long num,const string layer,const OnnxTypeInfo& type_info); ulong inputs[]; //Inputs of a model in dimensions [nxn] struct outputs_struct { ulong outputs[]; } model_output_structure[]; //Outputs of the model structure array
Then.
bool CGaussianMixture::OnnxLoad(long &handle) { //--- since not all sizes defined in the input tensor we must set them explicitly //--- first index - batch size, second index - series size, third index - number of series (only Close) OnnxTypeInfo type_info; //Getting onnx information for Reference In case you forgot what the loaded ONNX is all about long input_count=OnnxGetInputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",input_count," input(s)"); for(long i=0; i<input_count; i++) { string input_name=OnnxGetInputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," input name is ",input_name); if(OnnxGetInputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"input",type_info); ArrayCopy(inputs, type_info.tensor.dimensions); } } long output_count=OnnxGetOutputCount(handle); if (MQLInfoInteger(MQL_DEBUG)) Print("model has ",output_count," output(s)"); ArrayResize(model_output_structure, (int)output_count); for(long i=0; i<output_count; i++) { string output_name=OnnxGetOutputName(handle,i); if (MQLInfoInteger(MQL_DEBUG)) Print(i," output name is ",output_name); if(OnnxGetOutputTypeInfo(handle,i,type_info)) { if (MQLInfoInteger(MQL_DEBUG)) PrintTypeInfo(i,"output",type_info); ArrayCopy(model_output_structure[i].outputs, type_info.tensor.dimensions); } //--- Set the output shape replace(model_output_structure); if(!OnnxSetOutputShape(handle, i, model_output_structure[i].outputs)) { if (MQLInfoInteger(MQL_DEBUG)) { printf("Failed to set the Output[%d] shape Err=%d",i,GetLastError()); DebugBreak(); } return false; } } //--- replace(inputs); //--- Setting the input size for (long i=0; i<input_count; i++) if (!OnnxSetInputShape(handle, i, inputs)) //Giving the Onnx handle the input shape { if (MQLInfoInteger(MQL_DEBUG)) printf("Failed to set the input shape Err=%d",GetLastError()); DebugBreak(); return false; } initialized = true; if (MQLInfoInteger(MQL_DEBUG)) Print("ONNX model Initialized"); return true; } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CGaussianMixture::Init(string onnx_filename, uint flags=ONNX_DEFAULT) { onnx_handle = OnnxCreate(onnx_filename, flags); if (onnx_handle == INVALID_HANDLE) return false; return OnnxLoad(onnx_handle); } //+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ bool CGaussianMixture::Init(const uchar &onnx_buff[], ulong flags=ONNX_DEFAULT) { onnx_handle = OnnxCreateFromBuffer(onnx_buff, flags); //creating onnx handle buffer if (onnx_handle == INVALID_HANDLE) return false; return OnnxLoad(onnx_handle); }
Мы создали метод predict из этого класса, который возвращает две переменные: предсказанную метку и вектор вероятностей в структуре.
struct pred_struct { vector proba; long label; };
pred_struct CGaussianMixture::predict(const vector &x) { pred_struct res; if (!this.initialized) { if (MQLInfoInteger(MQL_DEBUG)) printf("%s The model is not initialized yet to make predictions | call Init function first",__FUNCTION__); return res; } //--- vectorf x_float; //Convert inputs from a vector of double values to those float values x_float.Assign(x); vector label = vector::Zeros(model_output_structure[0].outputs[1]); //outputs[1] we get the second shape (columns) from an array vector proba = vector::Zeros(model_output_structure[1].outputs[1]); //outputs[1] we get the second shape (columns) from an array if (!OnnxRun(onnx_handle, ONNX_DATA_TYPE_FLOAT, x_float, label, proba)) //Run the model and get the predicted label and probability { if (MQLInfoInteger(MQL_DEBUG)) printf("Failed to get predictions from Onnx err %d",GetLastError()); DebugBreak(); return res; } //--- res.label = (long)label[label.Size()-1]; //Get the last item available at the label's array res.proba = proba; return res; }
Вызовем функцию predict внутри основной функции индикатора, чтобы получить скрытые признаки.
Файл: LGMM Indicator.mq5
int OnCalculate(const int32_t rates_total, const int32_t prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int32_t &spread[]) { //--- Main calculation loop int lookback = 20; for (int i = prev_calculated; i < rates_total && !IsStopped(); i++) { if (i+1<lookback) //prevent data not found errors during copy buffer continue; int reverse_index = rates_total - 1 - i; //--- Get the indicators data vector x = getX(reverse_index, lookback); if (x.Size()==0) continue; pred_struct res = lgmm.predict(x); vector proba = res.proba; long label = res.label; ProbabilityBuffer[i] = proba.Max(); // Determine color based on histogram value if (label == 0) ColorBuffer[i] = 0; else if (label == 1) ColorBuffer[i] = 1; else ColorBuffer[i] = 2; Comment("bars [",i+1,"/",rates_total,"]"," Proba: ",proba," label: ",label); } //--- return(rates_total); }
Внутри функции getX() нужно собрать все буферы индикаторов точно так же, как мы это делали в скрипте при сборе данных для обучения.
vector getX(uint start=0, uint count=10) { //--- Get buffers CDataFrame df; for (uint ind=0; ind<indicators.Size(); ind++) //Loop through all the indicators { uint buffers_total = indicators[ind].buffer_names.Total(); for (uint buffer_no=0; buffer_no<buffers_total; buffer_no++) //Their buffer names resemble their buffer numbers { string name = indicators[ind].buffer_names.At(buffer_no); //Get the name of the buffer, it is helpful for the DataFrame and CSV file vector buffer = {}; if (!buffer.CopyIndicatorBuffer(indicators[ind].handle, buffer_no, start, count)) //Copy indicator buffer { printf("func=%s line=%d | Failed to copy %s indicator buffer, Error = %d",__FUNCTION__,__LINE__,name,GetLastError()); continue; } df.insert(name, buffer); //Insert a buffer vector and its name to a dataframe object } } return df.iloc(-1); //Return the latest information from the dataframe which is the most recent buffer }
Примечание: все индикаторы инициализированы внутри функции Init сразу после инициализации модели из папки common, куда мы ее сохранили с помощью Python.
#include <Gaussian Mixture.mqh> #include <Arrays\ArrayString.mqh> #include <MALE5\Pandas\pandas.mqh> CGaussianMixture lgmm; input string symbol = "XAUUSD"; input ENUM_TIMEFRAMES timeframe = PERIOD_D1; struct indicator_struct { long handle; CArrayString buffer_names; }; indicator_struct indicators[15]; //--- Indicator buffers double ProbabilityBuffer[]; double ColorBuffer[]; double MaBuffer[]; //+------------------------------------------------------------------+ //| Custom indicator initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- indicator buffers mapping Comment(""); // Setting indicator properties SetIndexBuffer(0, ProbabilityBuffer, INDICATOR_DATA); SetIndexBuffer(1, ColorBuffer, INDICATOR_COLOR_INDEX); // Setting histogram drawing style PlotIndexSetInteger(0, PLOT_DRAW_TYPE, DRAW_COLOR_HISTOGRAM); // Set indicator labels IndicatorSetString(INDICATOR_SHORTNAME, "3-Color Histogram"); IndicatorSetInteger(INDICATOR_DIGITS, _Digits); //--- string filename = StringFormat("LGMM.%s.%s.onnx",symbol, EnumToString(timeframe)); if (!lgmm.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s Failed to initialize the GaussianMixture model (LGMM) in ONNX format file={%s}, Error = %d",__FUNCTION__,filename,GetLastError()); } //--- Oscillators indicators[0].handle = iATR(symbol, timeframe, 14); indicators[0].buffer_names.Add("ATR"); //... //... //... indicators[14].handle = iWPR(symbol, timeframe, 14); indicators[14].buffer_names.Add("WPR"); for (uint i=0; i<indicators.Size(); i++) if (indicators[i].handle==INVALID_HANDLE) { printf("%s Invalid %s handle, Error = %d",__FUNCTION__,indicators[i].buffer_names[0],GetLastError()); return INIT_FAILED; } //--- return(INIT_SUCCEEDED); }
После этого запускаем индикатор на графике XAUUSD с тем же таймфреймом, на котором обучалась модель.
Полученный индикатор по-прежнему трудно интерпретировать, однако один паттерн явно доминирует — компонент, показанный красным цветом. Похоже, что этот паттерн появляется в моменты высокой волатильности рынка — как при восходящем, так и при нисходящем тренде. Назначение остальных компонентов пока не очевидно. Это может быть связано с тем, что выбранное количество компонентов для модели было неоптимальным. Поэтому попробуем определить оптимальное число компонентов.
Поиск оптимального числа компонентов для LGMM
Модель Mixture Model из библиотеки Scikit-Learn предоставляет значения информационных критериев Akaike Information Criterion (AIC) и Bayesian Information Criterion (BIC). Поэтому построим график зависимости этих значений от числа компонентов и попробуем найти точку локтя (elbow point).
Точка локтя на графике — это точка, после которой добавление новых компонентов в модель дает лишь незначительное улучшение качества, то есть кривая начинает выравниваться..
Файл: main.ipynb
lowest_bic = np.inf bic = [] aic = [] n_components_range = range(1, 10) for n_components in n_components_range: gmm = GaussianMixture(n_components=n_components, random_state=42) gmm.fit(X) bic.append(gmm.bic(X_train)) aic.append(gmm.aic(X_train)) if bic[-1] < lowest_bic: best_gmm = gmm lowest_bic = bic[-1] # Plot the BIC and AIC scores plt.figure(figsize=(8, 5)) plt.plot(n_components_range, bic, label='BIC', marker='o') plt.plot(n_components_range, aic, label='AIC', marker='o') plt.xlabel('Number of components') plt.ylabel('Score') plt.title('LGMM selection: AIC vs BIC') plt.legend() plt.grid(True) plt.show()
Результаты.

Кривые AIC и BIC резко снижаются при переходе от 1 к 2 компонентам и продолжают уменьшаться далее, однако скорость улучшения заметно снижается после 5 компонентов для обеих метрик. Это означает, что оптимальным числом компонентов для данной модели является 5.
Вернемся назад, переобучим модель и обновим индикатор.
Файл: main.ipynb
components = 5 # according to the elbow point gmm = GaussianMixture(n_components=components, covariance_type="full", random_state=42) gmm.fit(X_train) latent_features_train = gmm.predict_proba(X_train) latent_features_test = gmm.predict_proba(X_test)
Теперь в модели используется 5 компонентов вместо 3, то есть модель выдает 5 вероятностей, которые мы можем отображать на графике. Соответственно, нужно увеличить количество цветов индикатора до 5 для гистограммы и обработать 5 различных случаев для предсказанных меток.
Файл: LGMM Indicator.mq5
#property indicator_color1 clrDodgerBlue, clrLimeGreen, clrCrimson, clrOrange, clrYellow
Функция OnCalculate
int OnCalculate(const int32_t rates_total, const int32_t prev_calculated, const datetime &time[], const double &open[], const double &high[], const double &low[], const double &close[], const long &tick_volume[], const long &volume[], const int32_t &spread[]) { //--- Main calculation loop int lookback = 20; for (int i = prev_calculated; i < rates_total && !IsStopped(); i++) { if (i+1<lookback) //prevent data not found errors during copy buffer continue; //... //... //... // Determine color based on predicted label if (label == 0) ColorBuffer[i] = 0; else if (label == 1) ColorBuffer[i] = 1; else if (label == 2) ColorBuffer[i] = 2; else if (label == 3) ColorBuffer[i] = 3; else ColorBuffer[i] = 4; Comment("bars [",i+1,"/",rates_total,"]"," Proba: ",proba," label: ",label); }
Новый вид индикатора.
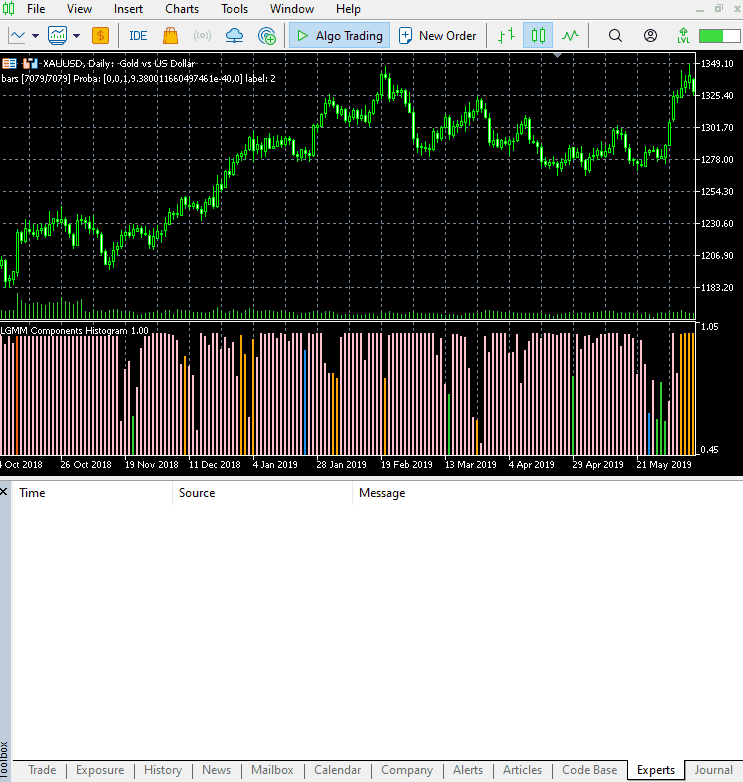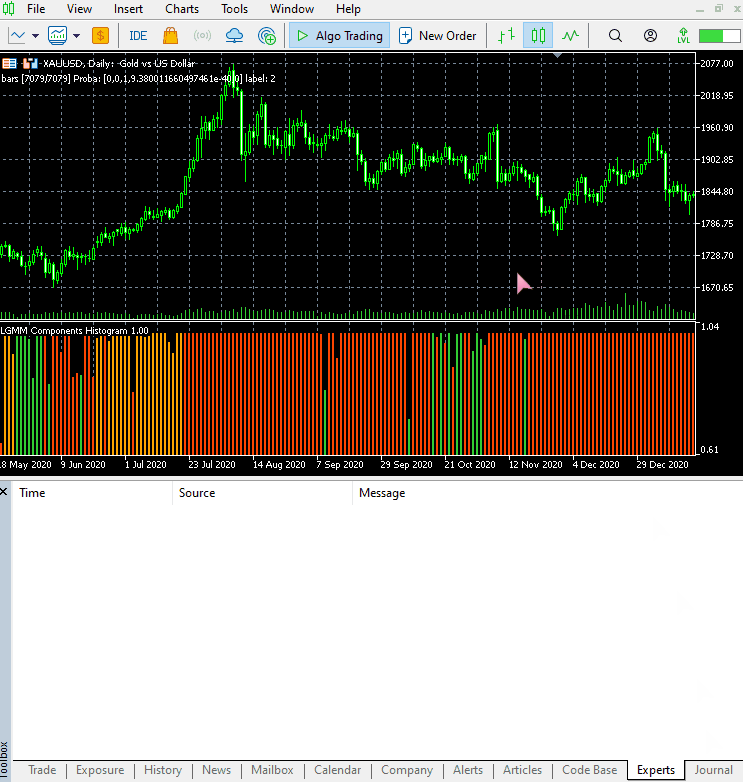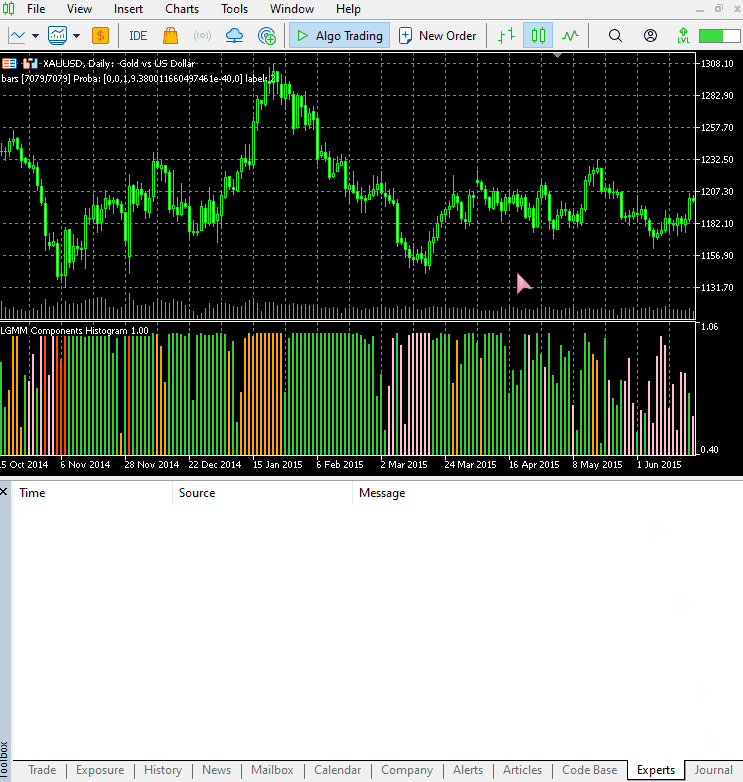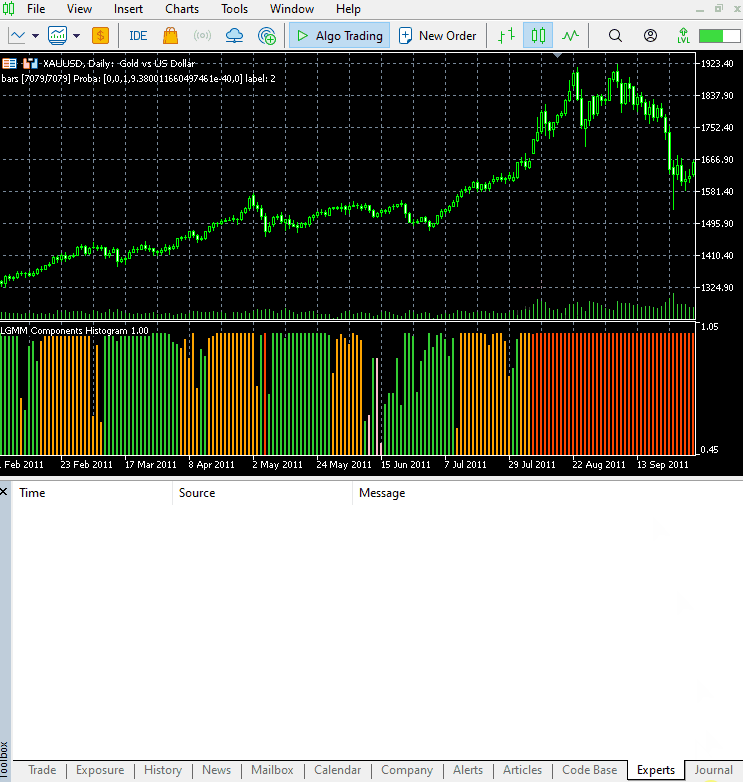
Выглядит отлично, но все еще сложно читать показатели, поскольку мы работаем с простыми осцилляторами, которые показывают зоны перепроданности и перекупленности. Предлагаю вам поэкспериментировать с этим индикатором и поделиться своими мыслями в разделе обсуждения.
Теперь попробуем совместить LGMM с моделью машинного обучения.
Сочетание модели латентных гауссовых смесей с классификатором
Мы увидели, как можно использовать LGMM для получения скрытых признаков, представляющих вероятность принадлежности метки к определенному кластеру, поскольку понять эти признаки довольно сложно. Попробуем использовать их в классификаторе случайного леса (Random Forest) вместе с признаками индикаторов. Надеюсь, что эта модель машинного обучения сможет определить, как скрытые характеристики влияют на торговые сигналы.
Файл: main.ipynb
Ранее мы уже создавали целевую переменную при разделении данных на обучающую и тестовую выборки. Для удобства приведу ее еще раз.
from sklearn.model_selection import train_test_split X = new_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "future_close", "Direction" ]) y = new_df["Direction"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=True, random_state=42)
После обучения модели LGMM мы использовали ее для прогнозирования на обучающих и тестовых данных.
latent_features_train = gmm.predict_proba(X_train) latent_features_test = gmm.predict_proba(X_test)
Поскольку эти данные трудно прочитать, добавим к ним названия признаков, чтобы идентифицировать их.
latent_features_train_df = pd.DataFrame(latent_features_train, columns=[f"LATENT_FEATURE_{i}" for i in range(latent_features_train.shape[1])]) latent_features_test_df = pd.DataFrame(latent_features_test, columns=[f"LATENT_FEATURE_{i}" for i in range(latent_features_test.shape[1])])
latent_features_train_df
Результаты.
| LATENT_FEATURE_0 | LATENT_FEATURE_1 | LATENT_FEATURE_2 | LATENT_FEATURE_3 | LATENT_FEATURE_4 | |
|---|---|---|---|---|---|
| 0 | 0.000000e+00 | 5.368039e-08 | 9.999999e-01 | 1.566000e-57 | 8.541983e-37 |
| 1 | 3.316692e-124 | 8.262106e-01 | 2.931424e-06 | 1.725415e-01 | 1.244990e-03 |
| 2 | 6.572730e-49 | 7.441120e-08 | 3.481699e-08 | 9.461818e-01 | 5.381811e-02 |
| 3 | 0.000000e+00 | 1.165057e-126 | 1.413762e-05 | 4.101964e-16 | 9.999859e-01 |
| 4 | 0.000000e+00 | 4.446778e-289 | 1.000000e+00 | 1.717945e-36 | 4.234123e-21 |
Совместим признаки с основными данными индикаторов.
all_columns = X_train.columns.tolist() + latent_features_train_df.columns.tolist() X_latent_train_arr = np.hstack([X_train, latent_features_train_df]) X_latent_test_arr = np.hstack([X_test, latent_features_test_df]) X_Train_latent = pd.DataFrame(X_latent_train_arr, columns=all_columns) X_Test_latent = pd.DataFrame(X_latent_test_arr, columns=all_columns) X_Train_latent.columns
Результаты.
Index(['ATR', 'BearsPower', 'BullsPower', 'Chainkin', 'CCI', 'Demarker', 'Force', 'MACD MAIN_LINE', 'MACD SIGNAL_LINE', 'Momentum', 'OsMA', 'RSI', 'RVI MAIN_LINE', 'RVI SIGNAL_LINE', 'StochasticOscillator MAIN_LINE', 'StochasticOscillator SIGNAL_LINE', 'TEMA', 'WPR', 'LATENT_FEATURE_0', 'LATENT_FEATURE_1', 'LATENT_FEATURE_2', 'LATENT_FEATURE_3', 'LATENT_FEATURE_4'], dtype='object')
Передадим объединенные данные классификатору случайного леса.
from sklearn.ensemble import RandomForestClassifier from sklearn.utils.class_weight import compute_class_weight classes = np.unique(y_train) weights = compute_class_weight(class_weight='balanced', classes=classes, y=y_train) class_weights_dict = dict(zip(classes, weights)) params = { "n_estimators": 100, "min_samples_split": 2, "max_depth": 10, "max_leaf_nodes": 10, "criterion": "gini", "random_state": 42 } model = RandomForestClassifier(**params, class_weight=class_weights_dict) model.fit(X_Train_latent, y_train)
Оценка модели.
y_train_pred = model.predict(X_Train_latent) print("Train classification report\n", classification_report(y_train, y_train_pred)) y_test_pred = model.predict(X_Test_latent) print("Test classification report\n", classification_report(y_test, y_test_pred))
Результаты.
Train classification report precision recall f1-score support -1 0.60 0.67 0.63 1766 1 0.68 0.61 0.64 1994 accuracy 0.64 3760 macro avg 0.64 0.64 0.64 3760 weighted avg 0.64 0.64 0.64 3760 Test classification report precision recall f1-score support -1 0.45 0.47 0.45 445 1 0.50 0.48 0.49 495 accuracy 0.47 940 macro avg 0.47 0.47 0.47 940 weighted avg 0.47 0.47 0.47 940
Полученная модель демонстрирует плохие результаты на тестовой выборке. Можно многое сделать для ее улучшения, но пока давайте посмотрим на график важности признаков, построенный на основе этой модели.
importances = model.feature_importances_ feature_names = X_Train_latent.columns if hasattr(X_Train_latent, 'columns') else [f'feature_{i}' for i in range(X_Train_latent.shape[1])] # Create DataFrame and sort importance_df = pd.DataFrame({'feature': all_columns, 'importance': importances}) importance_df = importance_df.sort_values('importance', ascending=False) # Plot plt.figure(figsize=(8, 6)) plt.barh(importance_df['feature'], importance_df['importance'], color='red') plt.title('RFC Feature Importance (Gini Importance)') plt.xlabel('Importance Score') plt.gca().invert_yaxis() # Most important on top plt.show()
Результаты.
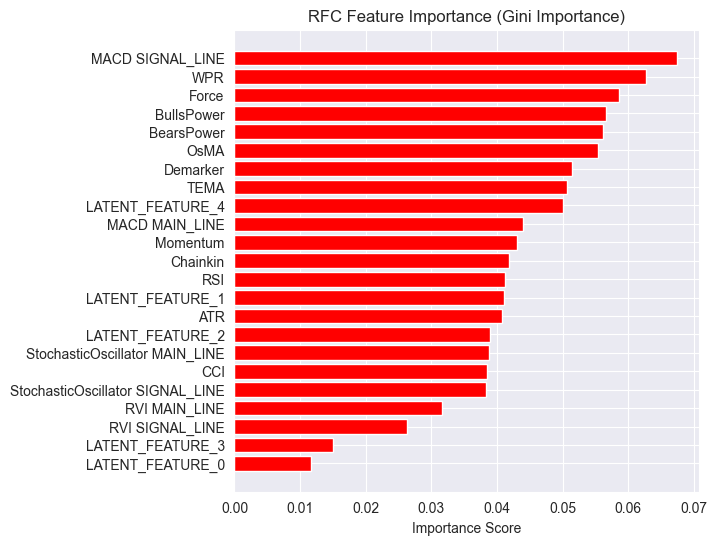
Латентные признаки оказываются важными для модели, что означает, что они содержат определенные паттерны и информацию, которые участвуют в формировании предсказаний.
Причина относительно слабой производительности модели может быть связана с используемой целевой переменной. Значение параметра lookahead = 1 может быть выбрано неправильно.
При использовании индикаторов для принятия торговых решений мы обычно не прогнозируем только один следующий бар. Например, если значение RSI находится ниже порогового значения 30 (зона перепроданности), мы можем предположить, что рынок может перейти к бычьему движению в течение нескольких следующих баров, а не обязательно на следующем баре, как это предполагает текущая схема обучения модели.
Поэтому пересоздадим целевую переменную, используя значение lookahead = 5.
lookahead = 5 df["future_close"] = df["Close"].shift(-lookahead) new_df = df.dropna() new_df["Direction"] = np.where(new_df["future_close"]>new_df["Close"], 1, -1) # if a the close value in the next bar(s)=lookahead is above the current close price, thats a long signal otherwise that's a short signal
Оценка модели как на обучающих, так и на валидационных данных дает другой результат.
Train classification report precision recall f1-score support -1 0.56 0.70 0.62 1706 1 0.69 0.54 0.61 2050 accuracy 0.61 3756 macro avg 0.62 0.62 0.61 3756 weighted avg 0.63 0.61 0.61 3756 Test classification report precision recall f1-score support -1 0.46 0.61 0.52 392 1 0.63 0.48 0.55 548 accuracy 0.54 940 macro avg 0.55 0.55 0.53 940 weighted avg 0.56 0.54 0.54 940
А также другой график важности признаков.
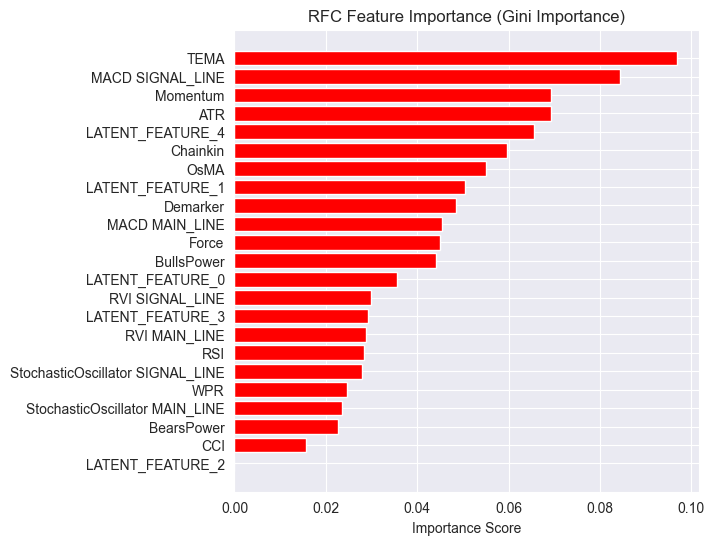
Модель показала общую точность 54%. Это не очень высокий результат, однако достаточно хороший, чтобы подтвердить наблюдения, сделанные на графике важности признаков.
Некоторые латентные признаки, сгенерированные LGMM, вошли в число наиболее значимых предикторов модели.
Признак LATENT_FEATURE_4 оказался пятым по важности для классификатора Random Forest. Остальные латентные признаки, такие как LATENT_FEATURE_0 и LATENT_FEATURE_1, также показали хорошие результаты и превзошли некоторые исходные индикаторы.
В целом большинство признаков, созданных LGMM, содержат паттерны, полезные для модели-классификатора.
Исходя из этой информации, у вас теперь есть отправная точка для понимания индикатора.
Расположение цветов соответствует структуре латентных признаков.
Торговый робот на основе LGMM
В нашем советнике импортируем необходимые библиотеки.
Filename: LGMM BASED EA.mq5
#include <Random Forest.mqh> #include <Arrays\ArrayString.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <Trade\SymbolInfo.mqh> #include <errordescription.mqh> CSymbolInfo m_symbol; CTrade m_trade; CPositionInfo m_position; CRandomForestClassifier rfc;
Проверим, что используем тот же символ и таймфрейм, что и в обучающих данных.
#define MAGICNUMBER 11062025 input string SYMBOL = "XAUUSD"; input ENUM_TIMEFRAMES TIMEFRAME = PERIOD_D1; input uint LOOKAHEAD = 5; input uint SLIPPAGE = 100;
Инициализируем обе модели (LGMM и модель классификатора случайного леса) в функции OnInit.
int OnInit() { if (!MQLInfoInteger(MQL_DEBUG) && !MQLInfoInteger(MQL_TESTER)) { ChartSetSymbolPeriod(0, SYMBOL, TIMEFRAME); if (!SymbolSelect(SYMBOL, true)) { printf("%s failed to select SYMBOL %s, Error = %s",__FUNCTION__,SYMBOL,ErrorDescription(GetLastError())); return INIT_FAILED; } } //--- Loading the Gaussian Mixture model string filename = StringFormat("LGMM.%s.%s.onnx",SYMBOL, EnumToString(TIMEFRAME)); if (!lgmm.Init(filename, ONNX_COMMON_FOLDER)) { printf("%s Failed to initialize the GaussianMixture model (LGMM) in ONNX format file={%s}, Error = %s",__FUNCTION__,filename,ErrorDescription(GetLastError())); } //--- Loading the RFC model filename = StringFormat("rfc.%s.%s.onnx",SYMBOL,EnumToString(TIMEFRAME)); Print(filename); if (!rfc.Init(filename, ONNX_COMMON_FOLDER)) { printf("func=%s line=%d, Failed to Load the RFC in ONNX file={%s}, Error = %s",__FUNCTION__,__LINE__,filename,ErrorDescription(GetLastError())); return INIT_FAILED; } //... //... other lines of code //... }
В функции getX вызываем LGMM для подготовки скрытых признаков, которые можно использовать вместе с данными индикаторов в качестве окончательных входных данных для модели классификатора случайного леса.
vector getX(uint start=0, uint count=10) { //--- Get buffers CDataFrame df; for (uint ind=0; ind<indicators.Size(); ind++) //Loop through all the indicators { uint buffers_total = indicators[ind].buffer_names.Total(); for (uint buffer_no=0; buffer_no<buffers_total; buffer_no++) //Their buffer names resemble their buffer numbers { string name = indicators[ind].buffer_names.At(buffer_no); //Get the name of the buffer, it is helpful for the DataFrame and CSV file vector buffer = {}; if (!buffer.CopyIndicatorBuffer(indicators[ind].handle, buffer_no, start, count)) //Copy indicator buffer { printf("func=%s line=%d | Failed to copy %s indicator buffer, Error = %d",__FUNCTION__,__LINE__,name,GetLastError()); continue; } df.insert(name, buffer); //Insert a buffer vector and its name to a dataframe object } } if ((uint)df.shape()[0]==0) return vector::Zeros(0); //--- predict the latent features vector indicators_data = df.iloc(-1); //index=-1 returns the last row from the dataframe which is the most recent buffer from all indicators //--- Given the indicators let's predict the latent features vector latent_features = lgmm.predict(indicators_data).proba; if (latent_features.Size()==0) return vector::Zeros(0); return hstack(indicators_data, latent_features); //Return indicators data stacked alongside latent features }
Наконец, добавим простую торговую стратегию, основанную на торговых сигналах, генерируемых моделью классификатора случайного леса.
void OnTick() { //--- Close trades after AI predictive horizon is over CloseTradeAfterTime(MAGICNUMBER, PeriodSeconds(TIMEFRAME)*LOOKAHEAD); //--- Refresh tick information if (!m_symbol.RefreshRates()) { printf("func=%s line=%s. Failed to copy rates, Error = %s",__FUNCTION__,ErrorDescription(GetLastError())); return; } //--- vector x = getX(); //Get all the input for the model if (x.Size()==0) return; long signal = rfc.predict(x).cls; //the class predicted by the random forest classifier double proba = rfc.predict(x).proba; //probability of the predictions double volume = m_symbol.LotsMin(); if (!PosExists(POSITION_TYPE_SELL, MAGICNUMBER) && !PosExists(POSITION_TYPE_BUY, MAGICNUMBER)) //no position is open { if (signal == 1) //If a model predicts a bullish signal m_trade.Buy(volume, SYMBOL, m_symbol.Ask()); //Open a buy trade else if (signal == -1) // if a model predicts a bearish signal m_trade.Sell(volume, SYMBOL, m_symbol.Bid()); //open a sell trade } }
Сделки будем зкарывать после того, как пройдет определенное количество баров (LOOKAHEAD) на таймфрейме, на котором обучалась модель. Значение параметра LOOKAHEAD должно совпадать со значением, использованным при создании целевой переменной в обучающем скрипте.
Настройки тестера.
Входные данные.

Результаты тестирования
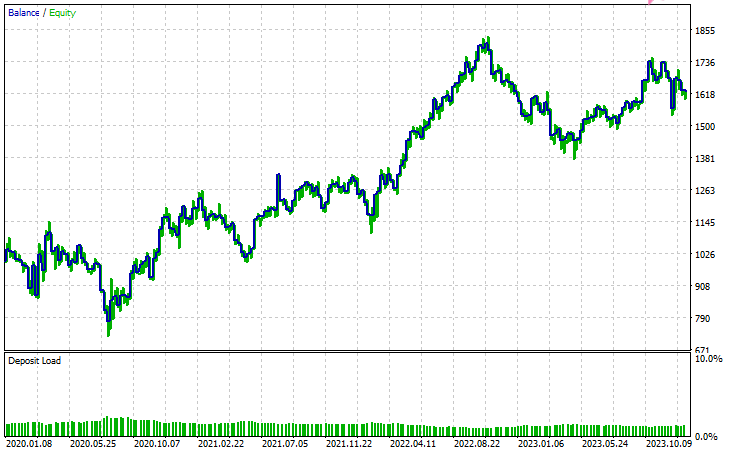
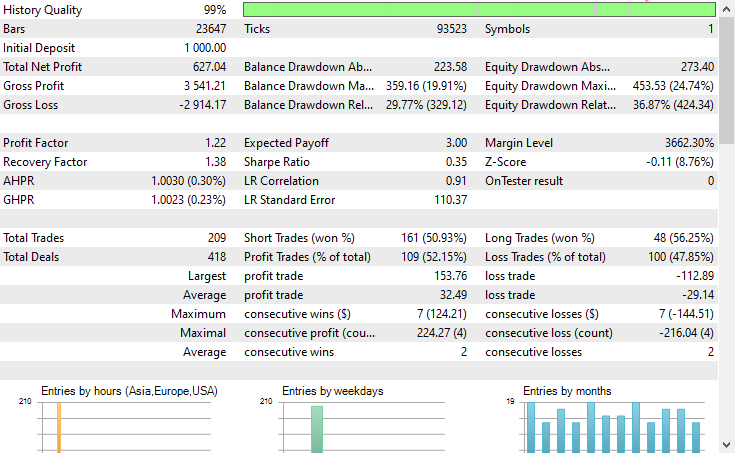
Заключение
Latent Gaussian Mixture Model (LGMM) — это достаточно эффективная техника, позволяющая получать значимые признаки, отражающие скрытые, ненаблюдаемые паттерны, которые часто оказываются полезными для моделей машинного обучения. Однако, как и любые другие модели машинного обучения и методы прогнозирования, она имеет ряд недостатков.
Обзор модели латентных гауссовых смесей (Latent Gaussian mixture model, LGMM)
| Аспект | Описание |
|---|---|
| Что такое LGMM | Метод извлечения скрытых признаков, представляющих собой ненаблюдаемые закономерности в данных. Эти функции могут быть полезны для моделей машинного обучения. |
| Основные преимущества | Выявляет значимые скрытые структуры в данных, которые могут улучшить показатели модели. |
Ограничения LGMM
| Ограничения | Пояснение |
|---|---|
| Предполагается гауссово распределение. | LGMM предполагает, что каждая точка данных подчиняется многомерному нормальному распределению, что редко встречается в финансовых данных, которые, как правило, носят хаотичный и нелинейный характер. |
| Чувствительна к инициализации | Данная модель требует тщательного подбора количества компонентов. Неправильная инициализация или неверный выбор параметров могут значительно снизить ее эффективность. |
| Результаты трудно интерпретировать. | Скрытые характеристики трудно понять или объяснить. Будучи методом обучения без учителя, модель не присваивает метки обнаруженным паттернам, а лишь группирует их. |
| Чувствительна к выбросам | Гауссовы распределения не устойчивы к выбросам. Несколько экстремальных значений могут исказить среднее значение и увеличить дисперсию, что приведет к искажению результатов модели. |
Эта модель наиболее полезна, когда речь идет о сокращении размерности (уменьшении количества признаков до нескольких значимых) и о введении новых признаков для обогащения модели более полезной информацией. Я считаю, что лучше всего использовать ее именно для этого.
Всем удачи!
Оставайтесь с нами и вносите свой вклад в разработку алгоритмов машинного обучения для языка MQL5 в этом GitHub-репозитории.
Таблица вложений
| Имя файла | Описание и назначение |
|---|---|
| Include\errordescription.mqh | Содержит описание всех кодов ошибок, генерируемых MetaTrader 5. |
| Include\Gaussian Mixture.mqh | Библиотека, содержащая класс для инициализации и развертывания модели гауссовой смеси, хранящейся в формате ONNX. |
| Include\pandas.mqh | Содержит класс для хранения и обработки данных, аналогичный классу Pandas, предлагаемому в языке программирования Python. |
| Include\Random Forest.mqh | Библиотека, содержащая класс для инициализации и развертывания классификатора случайного леса, хранящегося в формате ONNX. |
| Indicators\LGMM Indicator.mq5 | Индикатор для отображения скрытых признаков, полученных с помощью модели скрытой гауссовой смеси (LGMM). |
| Scripts\Get XAUUSD Data.mq5 | Скрипт для сбора данных осцилляторов вместе со значениями OHLCT из MetaTrader 5 и сохранения их в CSV-файл. |
| Experts\LGMM BASED EA.mq5 | Советник, который открывает и закрывает сделки на основе прогнозов, предоставляемых классификатором случайного леса, использующим данные, представляющие собой комбинацию скрытых признаков от алгоритма LGMM и осцилляторов. |
| Python Code\main.ipynb | Блокнот Jupyter (скрипт на Python) для анализа данных, обучения моделей машинного обучения и т.д. |
| Python Code\Trade\TerminalInfo.py | Содержит класс, аналогичный CTerminalInfo, предоставляемому в MQL5, для получения информации о выбранном настольном приложении MetaTrader 5. |
| Python\requirements.txt | Содержит все зависимости Python и номера их версий, используемые в этом проекте. |
| Common\Files\* | CSV-файл, содержащий обучающие данные, и несколько файлов моделей ONNX, использованных в этой статье, только для примера. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18497
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования