
Интеграция MQL5 с пакетами обработки данных (Часть 5): Адаптивное обучение и гибкость

Введение
Проблема, с которой сталкиваются многие алгоритмические трейдеры, заключается в отсутствии адаптивности традиционных торговых систем. Мы говорили в предыдущей статье, большинство советников жестко запрограммированы со статическими условиями и порогами, которые зачастую не способны подстроиться под меняющуюся рыночную динамику, колебания волатильности или новые, ранее не встречавшиеся паттерны в реальном времени. В результате такие системы хорошо работают лишь в определенных рыночных условиях, но теряют эффективность при изменении поведения рынка, что приводит к упущенным возможностям, частым ложным сигналам или затяжным просадкам.
Режимы адаптивного обучения и гибкости предлагают решение этой проблемы. Используя Python для построения модели обучения с подкреплением, способной непрерывно обучаться на исторических данных по XAUUSD, мы даем системе возможность корректировать свою стратегию в соответствии с изменяющимися рыночными условиями. Гибкость библиотек Python (таких как PyTorch, Gym, Pandas и др.) позволяет выполнять продвинутую предобработку данных, моделирование среды и оптимизацию моделей. После обучения модель можно экспортировать в формат ONNX, что позволяет развернуть ее в среде MQL5.
Получение исторических данных
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2025, 05, 15, tzinfo=timezone.utc) utc_to = datetime.(2025, 07,08, tzinfo=timezone.utc) # Get bars from XAU H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("XAUUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Save the data to a CSV file filename = "XAU_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Для получения исторических данных мы начинаем с инициализации соединения с терминалом MetaTrader 5 с помощью функции mt5.initialize(), которая обеспечивает взаимодействие между Python и платформой MetaTrader 5. Затем зададим диапазон дат для выборки данных — начальную и конечную дату. Эти даты обрабатываются как объекты datetime в формате UTC, чтобы учитывать часовые пояса. В данном случае скрипт настроен на получение исторических часовых данных по символу XAUUSD за период с 15 мая 2025 года по 8 июля 2025 года с использованием функции mt5.copy_rates_range().
filename = "XAUUSD_H1.csv" rates_frame.to_csv(filename, index=False) print(f"\nData saved to file: {filename}")
Как вы, возможно, уже знаете, я работаю в Linux. Если же у вас Windows, вы можете получить исторические данные с помощью следующего Python-скрипта:
from datetime import datetime import MetaTrader5 as mt5 import pandas as pd import pytz # Display data on the MetaTrader 5 package print("MetaTrader5 package author: ", mt5.__author__) print("MetaTrader5 package version: ", mt5.__version__) # Configure pandas display options pd.set_option('display.max_columns', 500) pd.set_option('display.width', 1500) # Establish connection to MetaTrader 5 terminal if not mt5.initialize(): print("initialize() failed, error code =", mt5.last_error()) quit() # Set time zone to UTC timezone = pytz.timezone("Etc/UTC") # Create 'datetime' objects in UTC time zone to avoid the implementation of a local time zone offset utc_from = datetime(2025, 05, 15, tzinfo=timezone.utc) utc_to = datetime(2025, 07, 08, tzinfo=timezome.utc) # Get bars from XAUUSD H1 (hourly timeframe) within the specified interval rates = mt5.copy_rates_range("XAUUSD", mt5.TIMEFRAME_H1, utc_from, utc_to) # Shut down connection to the MetaTrader 5 terminal mt5.shutdown() # Check if data was retrieved if rates is None or len(rates) == 0: print("No data retrieved. Please check the symbol or date range.") else: # Display each element of obtained data in a new line (for the first 10 entries) print("Display obtained data 'as is'") for rate in rates[:10]: print(rate) # Create DataFrame out of the obtained data rates_frame = pd.DataFrame(rates) # Convert time in seconds into the 'datetime' format rates_frame['time'] = pd.to_datetime(rates_frame['time'], unit='s') # Display data directly print("\nDisplay dataframe with data") print(rates_frame.head(10)
Если по какой-то причине вам не удаётся получить исторические данные программно, их можно загрузить вручную прямо из платформы MetaTrader 5. Для этого запустите терминал, затем в верхнем меню перейдите в меню Сервис > Настройки и перейдите на вкладку Графики. Здесь необходимо указать количество баров, отображаемых на графике. Рекомендуется выбрать опцию без ограничений (unlimited bars), особенно учитывая, что мы работаем с диапазонами дат и не можем точно предсказать, сколько баров будет содержать тот или иной таймфрейм.
Далее, чтобы загрузить сами данные, перейдите в меню Обзор > Символы, после чего откроется окно символов на вкладке Спецификация. Здесь выберите вкладку Бары или Тики в зависимости от того, какие данные вам нужны. Укажите желаемые начальную и конечную даты, затем нажмите кнопку "Запрос". После загрузки данных вы сможете экспортировать их и сохранить в формате .csv для дальнейшего использования.
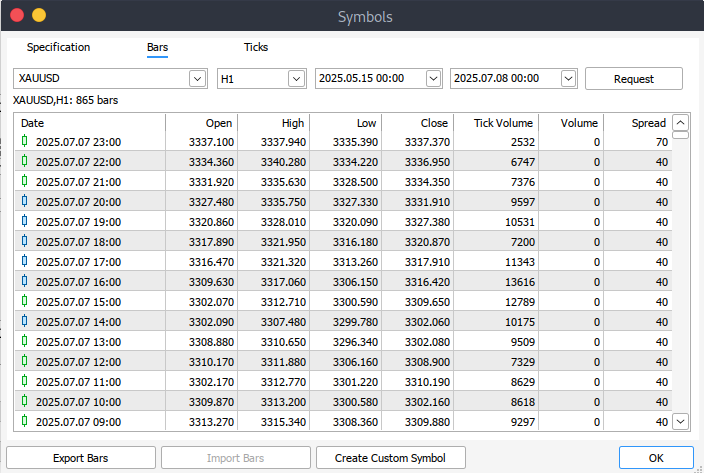
Начало работы
import pandas as pd # Load the uploaded BTC 1H CSV file file_path = '/home/int_j/Documents/Art Draft/Data Science/Adaptive Learning/XAUUSD_H1.csv' xau_data = pd.read_csv(file_path) # Display basic information about the dataset xau_data_info = xau_data.info() xau_data_head = xau_data.head() xau_data_info, xau_data_head
Начнем с анализа набора данных, чтобы понять его структуру. Для этого проверяются типы данных, размерность и полнота с помощью функции info(). Дополнительно выводятся первые строки с помощью head() — они дают общее представление о содержимом и структуре датасета. Этот шаг является стандартной частью разведочного анализа данных (EDA), позволяя убедиться, что данные были корректно загружены, и получить первичное представление об их формате.
# Reload the data with tab-separated values xau_data = pd.read_csv(file_path, delimiter='\t') # Display basic information and the first few rows after parsing xau_data_info = xau_data.info() xau_data_head = xau_data.head() xau_data_info, xau_data_head
В следующем блоке кода происходит повторная загрузка исторических данных XAUUSD из указанного файла, при этом в качестве разделителя используется символ табуляции (\t), а не запятая по умолчанию. Это важно при работе с файлами формата TSV (Tab-Separated Values), чтобы корректно распарсить данные. После загрузки данных в DataFrame xau_data выводится основная информация о наборе данных (типы столбцов, количество ненулевых значений, использование памяти) с помощью info(), а также отображаются первые строки через head() для быстрого просмотра.
import pandas as pd import numpy as np import ta from sklearn.preprocessing import StandardScaler # Split the single column into proper columns if len(xau_data.columns) == 1: # Extract column headers from the first row headers = xau_data.columns[0].split('\t') # Split data into separate columns xau_data = xau_data[xau_data.columns[0]].str.split('\t', expand=True) xau_data.columns = headers # Convert columns to proper data types numeric_cols = ['<OPEN>', '<HIGH>', '<LOW>', '<CLOSE>', '<TICKVOL>', '<VOL>', '<SPREAD>'] xau_data[numeric_cols] = xau_data[numeric_cols].apply(pd.to_numeric, errors='coerce') # Clean and create features xau_data = xau_data.dropna() xau_data['return'] = xau_data['<CLOSE>'].pct_change() # Add technical indicators xau_data['rsi'] = ta.momentum.RSIIndicator(xau_data['<CLOSE>'], window=14).rsi() xau_data['macd'] = ta.trend.MACD(xau_data['<CLOSE>']).macd_diff() xau_data['sma_20'] = ta.trend.SMAIndicator(xau_data['<CLOSE>'], window=20).sma_indicator() xau_data['sma_50'] = ta.trend.SMAIndicator(xau_data['<CLOSE>'], window=50).sma_indicator() xau_data = xau_data.dropna() # Normalize features scaler = StandardScaler() features = ['rsi', 'macd', 'sma_20', 'sma_50', 'return'] xau_data[features] = scaler.fit_transform(xau_data[features])
В этом блоке кода выполняется очистка и форматирование исторического набора данных XAUUSD. Если данные были загружены некорректно в виде одного столбца (что возможно при работе с TSV-файлами), скрипт разбивает этот столбец по символам табуляции, извлекая корректные заголовки и значения. Затем ключевые столбцы, такие как open, high, low, close, volume и spread, явно преобразуются в числовые типы данных, при этом возможные ошибки обрабатываются с помощью параметра errors='coerce'. После этого удаляются все пропущенные значения, и добавляется новый столбец с дневной доходностью, рассчитываемой как процентное изменение цены закрытия.
Следующий этап обогащает датасет техническими индикаторами с использованием библиотеки технического анализа. Рассчитываются такие показатели, как RSI (индекс относительной силы), MACD (схождение/расхождение скользящих средних), а также простые скользящие средние за 20 и 50 периодов на основе цены закрытия. Эти признаки широко используются в алгоритмической торговле, помогая моделям выявлять тренды и импульс. В завершение все выбранные признаки нормализуются с помощью StandardScaler из scikit-learn, приводя их к нулевому среднему и единичной дисперсии — это важный этап перед подачей данных в модели машинного обучения или обучения с подкреплением.
import gym from gym import spaces class TradingEnv(gym.Env): def __init__(self, df, window_size=30, initial_balance=10000): super(TradingEnv, self).__init__() self.df = df.reset_index(drop=True) self.window_size = window_size self.initial_balance = initial_balance self.action_space = spaces.Discrete(3) # 0: hold, 1: buy, 2: sell # Use correct shape (window_size, number of features) self.observation_space = spaces.Box( low=-np.inf, high=np.inf, shape=(self.window_size, len(features)), dtype=np.float32 ) def reset(self): self.current_step = self.window_size self.balance = self.initial_balance self.position = 0 # 1 = long, -1 = short, 0 = neutral self.entry_price = 0 self.trades = [] return self._next_observation() def _next_observation(self): # Use iloc to prevent overshooting shape obs = self.df.iloc[self.current_step - self.window_size : self.current_step] obs = obs[features].values return obs def step(self, action): current_price = self.df.loc[self.current_step, '<CLOSE>'] reward = 0 if action == 1 and self.position == 0: # Buy self.position = 1 self.entry_price = current_price elif action == 2 and self.position == 0: # Sell self.position = -1 self.entry_price = current_price elif action == 0 and self.position != 0: # Close position if self.position == 1: reward = current_price - self.entry_price elif self.position == -1: reward = self.entry_price - current_price self.position = 0 self.current_step += 1 done = self.current_step >= len(self.df) - 1 obs = self._next_observation() return obs, reward, done, {}
Как видно из приведенного кода, определяется пользовательская среда OpenAI Gym под названием TradingEnv, предназначенная для обучения агентов с подкреплением торговым решениям на основе исторических финансовых данных (в нашем случае XAUUSD). Среда моделирует процесс торговли, предоставляя три дискретных действия: удержание позиции (0), покупка (1) и продажа (2). Она инициализируется с фиксированным окном прошлых наблюдений (window_size) и использует признаки из данных для имитации торгового поведения. Пространство наблюдений представляет собой окно исторических значений признаков (например, RSI, MACD), а сама среда отслеживает такие ключевые параметры, как баланс, состояние позиции и цена входа.
Функция reset() подготавливает среду к новому эпизоду, сбрасывая счетчик шагов, баланс, текущую позицию и все открытые сделки. Функция step() реализует логику действий агента. Если агент покупает или продает, находясь вне позиции, открывается сделка. Если же он выбирает удержание при уже открытой позиции, она закрывается, и прибыль или убыток рассчитываются в виде вознаграждения. Эпизод проходит шаг за шагом по датасету до достижения его конца (done=True). Возвращаемые наблюдения представляют собой срезы исторических признаков, которые агент использует для принятия последующих решений.
import torch.nn as nn import torch.nn.functional as F class DuelingDQN(nn.Module): def __init__(self, state_shape, action_dim): super(DuelingDQN, self).__init__() # Calculate flattened dimension flattened_dim = np.prod(state_shape) # Network layers self.fc1 = nn.Linear(flattened_dim, 128) # Value stream self.value_stream = nn.Sequential( nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, 1) ) # Advantage stream self.advantage_stream = nn.Sequential( nn.Linear(128, 128), nn.ReLU(), nn.Linear(128, action_dim) ) def forward(self, state): # Flatten state while keeping batch dimension x = state.view(state.size(0), -1) x = F.relu(self.fc1(x)) value = self.value_stream(x) advantages = self.advantage_stream(x) return value + (advantages - advantages.mean(dim=1, keepdim=True))
Далее определяется архитектура Dueling Deep Q-Network (Dueling DQN) с использованием PyTorch — это вариация стандартной DQN, в которой отдельно оцениваются функция ценности состояния и функция преимущества действия. Класс DuelingDQN наследуется от nn. Module и принимает в качестве параметров форму входного состояния и количество возможных действий (action_dim). Сначала входные данные разворачиваются в вектор и проходят через общий полносвязный слой (fc1). после этого поток разделяется на два: один оценивает ценность состояния, второй — преимущества для каждого действия.
В методе forward() оба потока объединяются по формуле:
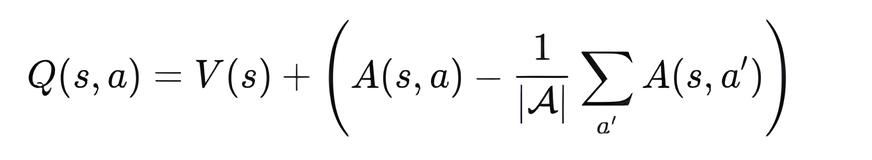
Это позволяет модели различать собственную ценность состояния (V(s)) и относительную выгоду каждого действия (A(s, a)), что повышает стабильность и эффективность обучения в задачах с подкреплением, таких как торговля.
# Training loop parameters env = TradingEnv(xau_data) # Use positional arguments instead of keyword arguments model = DuelingDQN(150, 3) # input_dim=150 (flattened state), action_dim=3 target_model = DuelingDQN(150, 3) # Same dimensions target_model.load_state_dict(model.state_dict())
Результат:
<All keys matched successfully>
Здесь происходит инициализация среды обучения и моделей для агента Dueling DQN. Среда TradingEnv создается на основе подготовленного набора данных xau_data, который предоставляет рыночные признаки для обучения. Создаются две копии модели DuelingDQN: model (основная сеть) и target_model (целевая сеть), обе с входной размерностью 150 и пространством действий из трех вариантов (покупка, продажа, удержание). Целевая сеть инициализируется копированием весов основной модели — это стандартная практика в обучении DQN, позволяющая стабилизировать процесс за счет использования медленно обновляемой целевой сети при вычислении временных разностей.
class ReplayBuffer: def __init__(self, capacity=10000): self.buffer = deque(maxlen=capacity) def push(self, state, action, reward, next_state, done): self.buffer.append((state, action, reward, next_state, done)) def sample(self, batch_size): batch = random.sample(self.buffer, batch_size) state, action, reward, next_state, done = map(np.array, zip(*batch)) return ( torch.tensor(state, dtype=torch.float32), # Shape: [batch, state_dim] torch.tensor(action, dtype=torch.int64), # Should be integer (for indexing) torch.tensor(reward, dtype=torch.float32), torch.tensor(next_state, dtype=torch.float32), torch.tensor(done, dtype=torch.float32) ) def __len__(self): return len(self.buffer)
Класс ReplayBuffer реализует буфер памяти, используемый в обучении с подкреплением для хранения и выборки опыта. Он использует структуру deque с фиксированным максимальным размером (по умолчанию 10 000), что позволяет эффективно хранить кортежи вида (state, action, reward, next_state, done). Метод push() добавляет новый опыт в буфер, автоматически удаляя самый старый при превышении.
Метод sample() случайным образом выбирает пакет примеров и преобразует их в тензоры PyTorch, пригодные для обучения модели, обеспечивая корректные типы данных для каждого элемента (например, int64 для действий и float32 для состояний и наград). Такой буфер способствует более стабильному и менее коррелированному обучению, позволяя агенту обучаться на разнообразном наборе прошлых взаимодействий, а не только на последовательных шагах.
env = TradingEnv(xau_data) obs_shape = env.observation_space.shape n_actions = env.action_space.n # Calculate flattened dimension flattened_dim = np.prod(obs_shape) # 30*5 = 150 model = DuelingDQN(flattened_dim, n_actions) target_model = DuelingDQN(flattened_dim, n_actions) target_model.load_state_dict(model.state_dict()) optimizer = optim.Adam(model.parameters(), lr=0.0005) buffer = ReplayBuffer() gamma = 0.99 epsilon = 1.0 batch_size = 64 target_update_interval = 10 all_rewards = [] all_actions = [] # We'll collect actions for the entire dataset # Training loop for episode in range(200): state = env.reset() total_reward = 0 done = False episode_actions = [] # Store actions for this episode while not done: if random.random() < epsilon: action = env.action_space.sample() else: with torch.no_grad(): # Flatten state and pass to model state_tensor = torch.tensor(state, dtype=torch.float32).flatten().unsqueeze(0) q_values = model(state_tensor) action = q_values.argmax().item() next_state, reward, done, _ = env.step(action) buffer.push(state, action, reward, next_state, done) state = next_state total_reward += reward episode_actions.append(action) # Record action if len(buffer) >= batch_size: s, a, r, s2, d = buffer.sample(batch_size) q_val = model(s).gather(1, a.unsqueeze(1)).squeeze() next_q_val = target_model(s2).max(1)[0] target = r + (1 - d) * gamma * next_q_val loss = nn.MSELoss()(q_val, target) optimizer.zero_grad() loss.backward() optimizer.step() epsilon = max(0.01, epsilon * 0.995) if episode % target_update_interval == 0: target_model.load_state_dict(model.state_dict()) print(f"Episode {episode}, Reward: {total_reward}") # After episode completes all_rewards.append(total_reward) all_actions.extend(episode_actions) # Add episode actions to master list
Результат:

Этот цикл обучения настраивает среду обучения с подкреплением для торговли с использованием архитектуры Dueling Deep Q-Network (Dueling DQN). Сначала инициализируется среда на основе исторических данных XAUUSD, после чего из пространств наблюдений и действий извлекаются ключевые параметры. Создаются модель Dueling DQN и целевая модель, обе с входной размерностью 150 (что соответствует 30 временным шагам × 5 признаков). Также настраиваются оптимизатор (Adam) и буфер воспроизведения (replay buffer), а также задаются гиперпараметры: коэффициент дисконтирования (gamma), уровень исследования (epsilon), размер батча и частота обновления целевой сети.
В ходе каждого эпизода среда сбрасывается, и агент пошагово взаимодействует с ней, выбирая действия по ε-жадной (epsilon-greedy) стратегии. Если случайное число меньше epsilon, выбирается случайное действие; в противном случае модель выбирает действие с максимальным предсказанным значением Q. После выполнения действия агент получает отклик от среды, который сохраняется в буфере воспроизведения. Как только в буфере накапливается достаточное количество данных, из него выбирается пакет опыта для обучения модели. Рассчитываются значения Q и целевые значения, после чего ошибка среднеквадратичного отклонения распространяется обратно (в методе backpropagation) для обновления параметров модели.
Для стабилизации обучения целевая модель периодически обновляется, копируя веса текущей модели. Значение epsilon постепенно уменьшается, снижая долю случайных действий и позволяя агенту все больше опираться на накопленные знания. В процессе обучения фиксируются суммарные награды и действия в каждом эпизоде для оценки производительности. Этот цикл помогает агенту выработать оптимальную торговую стратегию, балансируя между исследованием и использованием уже изученных закономерностей на протяжении 200 эпизодов.
import matplotlib.pyplot as plt # Plotting performance metrics like cumulative reward plt.plot([r for r in range(len(buffer.buffer))], label="Reward Trend") plt.title("Training Rewards") plt.show()
Результат:
Для визуализации результатов обучения мы используем библиотека matplotlib и строим диаграмму динамики вознаграждений на основе данных из буфера воспроизведения. Это позволяет отслеживать, как меняется накопленная награда агента в процессе обучения.
import matplotlib.pyplot as plt plt.figure(figsize=(12, 6)) plt.plot(all_rewards) plt.xlabel("Episode") plt.ylabel("Total Reward") plt.title("Training Performance") plt.grid(True) plt.show()
Результат:
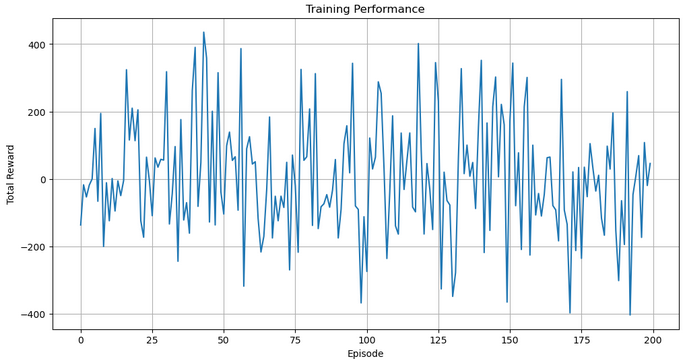
Затем визуализируем эффективность агента по эпизодам — для этого строим диаграмму all_rewards, который показывает суммарную награду за каждый эпизод. Такая диаграмма дает представление о прогрессе обучения и стабильности поведения торгового агента со временем. Для удобства добавлена сетка и подписи осей.
# Run a clean evaluation with the trained model (no exploration) eval_env = TradingEnv(xau_data) state = eval_env.reset() eval_actions = [] # Store actions for this single episode with torch.no_grad(): while True: # Flatten state and predict state_tensor = torch.tensor(state, dtype=torch.float32).flatten().unsqueeze(0) q_values = model(state_tensor) action = q_values.argmax().item() next_state, _, done, _ = eval_env.step(action) eval_actions.append(action) state = next_state if done: break # Now plot using eval_actions close_prices = xau_data['<CLOSE>'].values window_size = eval_env.observation_space.shape[0] # Create action array with same length as price data action_array = np.full(len(close_prices), np.nan) action_array[window_size:window_size + len(eval_actions)] = eval_actions # Create plot plt.figure(figsize=(14, 8)) plt.plot(close_prices, label='XAUUSD Price', alpha=0.7) # Plot buy signals (action=1) buy_mask = (action_array == 1) buy_indices = np.where(buy_mask)[0] plt.scatter(buy_indices, close_prices[buy_mask], color='green', label='Buy', marker='^', s=100) # Plot sell signals (action=2) sell_mask = (action_array == 2) sell_indices = np.where(sell_mask)[0] plt.scatter(sell_indices, close_prices[sell_mask], color='red', label='Sell', marker='v', s=100) plt.legend() plt.title("Trading Actions on XAUUSD (Trained Policy)") plt.xlabel("Time Step") plt.ylabel("Price") plt.grid(True) plt.show()
Результат:
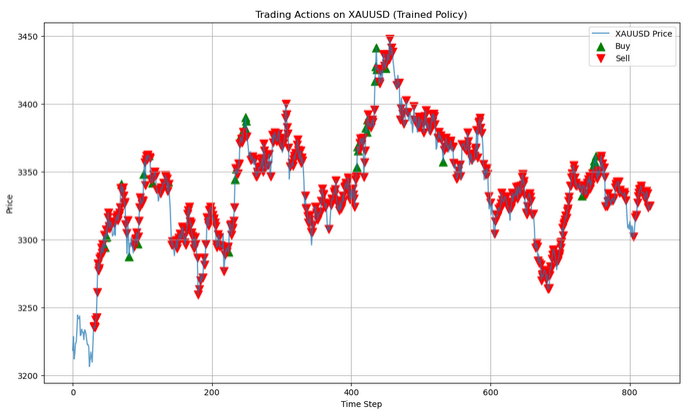
На этапе оценки (evaluation) обученная модель используется для принятия решений в "чистой" среде без исследования (eval_env). Агент наблюдает текущее состояние рынка, выбирает действие с наибольшим значением Q (жадная стратегия) и фиксирует каждое принятое решение. Процесс продолжается до завершения эпизода, позволяя оценить поведение агента без влияния случайности.
dummy_input = torch.randn(1, *obs_shape) torch.onnx.export(model, dummy_input, "dueling_dqn_xauusd.onnx", input_names=["input"], output_names=["output"], dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}}
В завершение экспортируем обученную модель Dueling DQN в формат ONNX с использованием фиктивного входного вектора (dummy input) для обеспечения совместимости с другими платформами. Это позволяет использовать модель вне PyTorch, например, в системах реального времени или непосредственно в среде MQL5.
Собираем все вместе в MQL5
//+------------------------------------------------------------------+ //| ONNX_DQN_Trading_Script.mq5 | //| Copyright 2023, MetaQuotes Ltd. | //| https://www.mql5.com | //+------------------------------------------------------------------+ #property copyright "Copyright 2023, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- input parameters input string ModelPath = "dueling_dqn_xauusd.onnx"; // File in MQL5\Files\ input int WindowSize = 30; // Observation window size input int FeatureCount = 5; // Number of features //--- ONNX model handle long onnxHandle; //--- Normalization parameters (REPLACE WITH YOUR ACTUAL VALUES) const double RSI_MEAN = 55.0, RSI_STD = 15.0; const double MACD_MEAN = 0.05, MACD_STD = 0.5; const double SMA20_MEAN = 1800.0, SMA20_STD = 100.0; const double SMA50_MEAN = 1800.0, SMA50_STD = 100.0; const double RETURN_MEAN = 0.0002, RETURN_STD = 0.01; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- Load ONNX model onnxHandle = OnnxCreate(ModelPath, ONNX_DEFAULT); if(onnxHandle == INVALID_HANDLE) { Print("Error loading model: ", GetLastError()); return; } //--- Prepare input data buffer double inputData[]; ArrayResize(inputData, WindowSize * FeatureCount); //--- Collect and prepare data if(!PrepareInputData(inputData)) { Print("Data preparation failed"); OnnxRelease(onnxHandle); return; } //--- Set input shape (no need to set shape for dynamic axes) //--- Run inference double outputData[3]; if(!RunInference(inputData, outputData)) { Print("Inference failed"); OnnxRelease(onnxHandle); return; } //--- Interpret results InterpretResults(outputData); OnnxRelease(onnxHandle); } //+------------------------------------------------------------------+ //| Prepare input data for the model | //+------------------------------------------------------------------+ bool PrepareInputData(double &inputData[]) { //--- Get closing prices double closes[]; int closeCount = WindowSize + 1; if(CopyClose(_Symbol, _Period, 0, closeCount, closes) != closeCount) { Print("Not enough historical data. Requested: ", closeCount, ", Received: ", ArraySize(closes)); return false; } //--- Calculate returns (percentage changes) double returns[]; ArrayResize(returns, WindowSize); for(int i = 0; i < WindowSize; i++) returns[i] = (closes[i] - closes[i+1]) / closes[i+1]; //--- Calculate technical indicators double rsi[], macd[], sma20[], sma50[]; if(!CalculateIndicators(rsi, macd, sma20, sma50)) return false; //--- Verify indicator array sizes if(ArraySize(rsi) < WindowSize || ArraySize(macd) < WindowSize || ArraySize(sma20) < WindowSize || ArraySize(sma50) < WindowSize) { Print("Indicator data mismatch"); return false; } //--- Normalize features and fill input data int dataIndex = 0; for(int i = WindowSize - 1; i >= 0; i--) { inputData[dataIndex++] = (rsi[i] - RSI_MEAN) / RSI_STD; inputData[dataIndex++] = (macd[i] - MACD_MEAN) / MACD_STD; inputData[dataIndex++] = (sma20[i] - SMA20_MEAN) / SMA20_STD; inputData[dataIndex++] = (sma50[i] - SMA50_MEAN) / SMA50_STD; inputData[dataIndex++] = (returns[i] - RETURN_MEAN) / RETURN_STD; } return true; } //+------------------------------------------------------------------+ //| Calculate technical indicators | //+------------------------------------------------------------------+ bool CalculateIndicators(double &rsi[], double &macd[], double &sma20[], double &sma50[]) { //--- RSI (14 period) int rsiHandle = iRSI(_Symbol, _Period, 14, PRICE_CLOSE); if(rsiHandle == INVALID_HANDLE) return false; if(CopyBuffer(rsiHandle, 0, 0, WindowSize, rsi) != WindowSize) return false; IndicatorRelease(rsiHandle); //--- MACD (12,26,9) int macdHandle = iMACD(_Symbol, _Period, 12, 26, 9, PRICE_CLOSE); if(macdHandle == INVALID_HANDLE) return false; double macdSignal[]; if(CopyBuffer(macdHandle, 0, 0, WindowSize, macd) != WindowSize) return false; if(CopyBuffer(macdHandle, 1, 0, WindowSize, macdSignal) != WindowSize) return false; // Calculate MACD difference (histogram) for(int i = 0; i < WindowSize; i++) macd[i] = macd[i] - macdSignal[i]; IndicatorRelease(macdHandle); //--- SMA20 int sma20Handle = iMA(_Symbol, _Period, 20, 0, MODE_SMA, PRICE_CLOSE); if(sma20Handle == INVALID_HANDLE) return false; if(CopyBuffer(sma20Handle, 0, 0, WindowSize, sma20) != WindowSize) return false; IndicatorRelease(sma20Handle); //--- SMA50 int sma50Handle = iMA(_Symbol, _Period, 50, 0, MODE_SMA, PRICE_CLOSE); if(sma50Handle == INVALID_HANDLE) return false; if(CopyBuffer(sma50Handle, 0, 0, WindowSize, sma50) != WindowSize) return false; IndicatorRelease(sma50Handle); return true; } //+------------------------------------------------------------------+ //| Run model inference | //+------------------------------------------------------------------+ bool RunInference(const double &inputData[], double &outputData[]) { //--- Run model directly without setting shape (for dynamic axes) if(!OnnxRun(onnxHandle, ONNX_DEBUG_LOGS, inputData, outputData)) { Print("Model inference failed: ", GetLastError()); return false; } return true; } //+------------------------------------------------------------------+ //| Interpret model results | //+------------------------------------------------------------------+ void InterpretResults(const double &outputData[]) { //--- Find best action int bestAction = ArrayMaximum(outputData); string actionText = ""; switch(bestAction) { case 0: actionText = "HOLD"; break; case 1: actionText = "BUY"; break; case 2: actionText = "SELL"; break; } //--- Print results Print("Model Output: [HOLD: ", outputData[0], ", BUY: ", outputData[1], ", SELL: ", outputData[2], "]"); Print("Recommended Action: ", actionText); }
MQL5-скрипт ONNX_DQN_Trading_Script.mq5 предназначен для запуска обученной модели Dueling DQN, экспортированной в формате ONNX, для генерации торговых сигналов в MetaTrader 5. Сначала модель ONNX загружается из каталога Files, подготавливаются входные данные на основе фиксированного окна наблюдения. Скрипт собирает цены последние ценовые данные и рассчитывает технические индикаторы RSI, гистограмму MACD, SMA20, SMA50, а также доходности, после чего они нормализуются на основе заранее заданных средних значений и стандартных отклонений. Обработанные признаки преобразуются в одномерный массив, соответствующий формату входных данных модели.
Когда входной вектор подготовлен, скрипт выполняет инференс с помощью OnnxRun, возвращая три значения — прогнозные Q-оценки для действий HOLD, BUY и SELL. Действие с наибольшим значением интерпретируется как рекомендация модели и выводится в терминал. Этап инференса сопровождается проверками на ошибки для повышения надёжности, а используемые ресурсы освобождаются после завершения операций.
Заключение
В итоге была разработана адаптивная и гибкая торговая модель на основе архитектуры Dueling DQN, обученная на исторических данных XAUUSD. Модель обрабатывает скользящее окно технических признаков, включая RSI, гистограмму MACD, SMA20, SMA50 и процентные изменения доходности, нормализованные на основе статистических параметров. Мы визуализировали процесс обучения с накопленными наградами для контроля стабильности После обучения мы экспортировали модель в формат ONNX для интеграции с MetaTrader 5, где специальный скрипт на MQL5 загружает модель, динамически подготавливает входные данные, выполняет инференс и интерпретирует рекомендуемое действие (HOLD, BUY или SELL) на основе максимального выходного значения.
В заключение можно сказать, что данный сквозной (end-to-end) пайплайн предоставляет трейдерам мощную автоматизированную систему поддержки принятия решений, объединяющую глубокое обучение с подкреплением и данные рынка в реальном времени. Гибкость системы позволяет легко адаптировать ее под новые торговые инструменты или наборы индикаторов благодаря изменению входных признаков и повторного обучения. Благодаря внедрению ONNX-инференса непосредственно в MQL5, трейдеры могут использовать интеллектуальные модели прямо в своей торговой платформе, повышая эффективность исполнения стратегий и скорость реакции на изменения рынка без необходимости в стороннем программном обеспечении.
| Название файла | Описание |
|---|---|
| Ada_flex.mq5 | Файл, содержащий скрипт MQL5 для использования моделИ обучения с подкреплением, обученной на Python. |
| Ada_L.ipynb | Файл, содержащий Notebook для обучения модели и ее сохранения |
| XAUUSD_H1.csv | Файл с историческими данными о цене XAUUSD |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18761
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования