
Die Grenzen des maschinellen Lernens überwinden (Teil 5): Ein kurzer Überblick über die Kreuzvalidierung von Zeitreihen

In unserer entsprechenden Artikelserie haben wir zahlreiche Taktiken für den Umgang mit Problemen, die durch das Marktverhalten entstehen, behandelt. In dieser Serie konzentrieren wir uns jedoch auf Probleme, die durch die Algorithmen des maschinellen Lernens verursacht werden, die wir in unseren Strategien einsetzen wollen. Viele dieser Probleme ergeben sich aus der Architektur des Modells, den bei der Modellauswahl verwendeten Algorithmen, den Verlustfunktionen, die wir zur Leistungsmessung definieren, und vielen anderen Themen derselben Art.
All die beweglichen Teile, die zusammen ein Modell des maschinellen Lernens bilden, können ungewollt Hindernisse in unserem Streben nach Anwendung des maschinellen Lernens auf den algorithmischen Handel schaffen, die eine sorgfältige diagnostische Bewertung erfordern. Deshalb ist es wichtig, dass jeder von uns diese Einschränkungen versteht und als Gemeinschaft neue Lösungen entwickelt und neue Standards für sich selbst definiert.
Modelle des maschinellen Lernens, die im algorithmischen Handel eingesetzt werden, stehen vor besonderen Herausforderungen, die oft durch die Art und Weise verursacht werden, wie wir sie validieren und testen. Ein entscheidender Schritt ist die Kreuzvalidierung von Zeitreihen – eine Methode zur Bewertung der Modellleistung anhand ungesehener, chronologisch geordneter Daten.
Anders als bei der Standard-Kreuzvalidierung können die Zeitreihendaten nicht gemischt werden, da dadurch Informationen aus der Zukunft in die Vergangenheit gelangen würden. Dadurch wird das Resampling komplexer und führt zu einzigartigen Kompromissen zwischen Verzerrung, Varianz und Robustheit.
In diesem Artikel stellen wir die Kreuzvalidierung für Zeitreihen vor, erläutern ihre Rolle bei der Vermeidung von Überanpassungen und zeigen, wie sie dazu beitragen kann, selbst bei begrenzten Daten zuverlässige Modelle zu trainieren. Anhand eines kleinen Zweijahresdatensatzes zeigen wir, wie eine geeignete Kreuzvalidierung die Leistung eines tiefen neuronalen Netzes im Vergleich zu einem einfachen linearen Modell verbessert.
Unser Ziel ist es, sowohl den Wert als auch die Grenzen gängiger Zeitreihen-Kreuzvalidierungsmethoden aufzuzeigen und damit die Grundlage für eine tiefergehende Diskussion im nächsten Teil der Reihe zu schaffen.
Daten in MQL5 abrufen
Für diese Diskussion beginnen wir mit dem Abrufen historischer Daten aus dem MetaTrader 5-Terminal mithilfe eines MQL5-Skripts, das wir von Hand geschrieben haben. Das Skript beginnt mit dem Speichern des Namens der Datei, die ausgegeben werden soll.
Als Nächstes speichern wir die Menge der abzurufenden Daten als Eingabeparameter, den der Nutzer an das Skript übergeben kann. Stellen Sie sicher, dass Sie die Eigenschaft #property script_show_inputs in der Kopfzeile Ihres Skripts festlegen, um sicherzustellen, dass der Endnutzer die Anzahl der abzurufenden Takte angeben kann.
Nachdem wir alle notwendigen Informationen gesammelt haben, beginnen wir mit dem Schreiben der Datei. Mit der Funktion FileOpen erstellen wir einen neuen File-Handler. Diese Funktion akzeptiert Parameter, die den verwendeten Dateityp, die auszuführenden Operationen und das Trennzeichen oder die Abstandskonvention für die Datei definieren.
Daher übergeben wir der FileOpen-Methode den zu Beginn des Skripts generierten Dateinamen, die entsprechenden Datei-Operationsmodi und -typen sowie das Komma als Begrenzungszeichen unserer Wahl.
Danach initialisieren wir eine for-Schleife, die von der Gesamtzahl der abzurufenden Takte bis zum Anfang läuft. In der ersten Iteration schreiben wir die Spaltennamen auf, die wir in unserer CSV-Datei speichern wollen. Bei jeder nachfolgenden Iteration werden die relevanten Marktdaten für den jeweiligen Zeitpunkt abgerufen, wobei wir uns schrittweise von der Vergangenheit zur Gegenwart bewegen.
Dadurch wird sichergestellt, dass unsere CSV-Datei so strukturiert ist, dass die ältesten Daten am Anfang und die jüngsten Daten am Ende stehen.
//+------------------------------------------------------------------+ //| Fetch_Data | //| Copyright 2020, CompanyName | //| http://www.companyname.net | //+------------------------------------------------------------------+ #property copyright "Copyright 2024, MetaQuotes Ltd." #property link "https://www.mql5.com" #property version "1.00" #property script_show_inputs //--- File name string file_name = Symbol() + " Detailed Market Data As Series.csv"; //--- Amount of data requested input int size = 3000; //+------------------------------------------------------------------+ //| Our script execution | //+------------------------------------------------------------------+ void OnStart() { int fetch = size; //---Write to file int file_handle=FileOpen(file_name,FILE_WRITE|FILE_ANSI|FILE_CSV,","); for(int i=size;i>=1;i--) { if(i == size) { FileWrite(file_handle,"Time", //--- OHLC "True Open", "True High", "True Low", "True Close" ); } else { FileWrite(file_handle, iTime(_Symbol,PERIOD_CURRENT,i), //--- OHLC iClose(_Symbol,PERIOD_CURRENT,i), iOpen(_Symbol,PERIOD_CURRENT,i), iHigh(_Symbol,PERIOD_CURRENT,i), iLow(_Symbol,PERIOD_CURRENT,i) ); } } //--- Close the file FileClose(file_handle); } //+------------------------------------------------------------------+
Analysieren unserer Daten in Python
Nachdem wir unsere CSV-Datei erfolgreich geschrieben haben, importieren wir im nächsten Schritt unsere Pandas-, NumPy- und Matplotlib-Bibliotheken, um mit unserer Analyse zu beginnen.
#Import basic libraries import pandas as pd import numpy as np import matplotlib.pyplot as plt
Beim Lesen der mit dem MQL5-Skript erstellten Daten ist zu beachten, dass der Leser im nachstehenden Beispielcode den Pfad durch seinen eigenen Systempfad ersetzen sollte.
#Read in the data data = pd.read_csv("/ENTER/YOUR/PATH/HERE/EURUSD Detailed Market Data As Series.csv")
In unserem Beispiel wollen wir zeigen, dass die Kreuzvalidierung zur Anpassung komplexer Modelle auch bei begrenzten Datensätzen verwendet werden kann. Daher werden wir die Daten der letzten zwei Jahre auswählen und alles andere weglassen.
data = data.iloc[(365*2):,:] data.reset_index(drop=True,inplace=True)
Von dort aus müssen wir festlegen, wie weit wir in die Zukunft vorausschauen wollen.
#Define a forecast horizon HORIZON = 1
Der nächste Schritt besteht darin, die Inputs vorzubereiten, mit denen wir arbeiten wollen – die differenzierten Inputs. Wir erstellen diese, indem wir die aktuelle Eingabe von ihrem vorherigen Wert subtrahieren. Wir fügen dem Datensatz auch die Bezeichnung hinzu. Danach werden alle fehlenden Werte gestrichen.
#Let us start by following classical rules data['True Close Diff'] = data['True Close'] - data['True Close'].shift(HORIZON) data['True Open Diff'] = data['True Open'] - data['True Open'].shift(HORIZON) data['True High Diff'] = data['True High'] - data['True High'].shift(HORIZON) data['True Low Diff'] = data['True Low'] - data['True Low'].shift(HORIZON) #Add the target data['Target'] = data['True Close'] - data['True Close'].shift(-HORIZON) data.dropna(inplace=True) data.reset_index(inplace=True,drop=True)
Lassen Sie uns die Daten visualisieren.
#Let's visualize the data
plt.plot(data['True Close'],color='black')
plt.grid()
plt.title('EURUSD Data From 2023 - 2024')
plt.xlabel('Time')
plt.ylabel('EURUSD Exchange Rate') 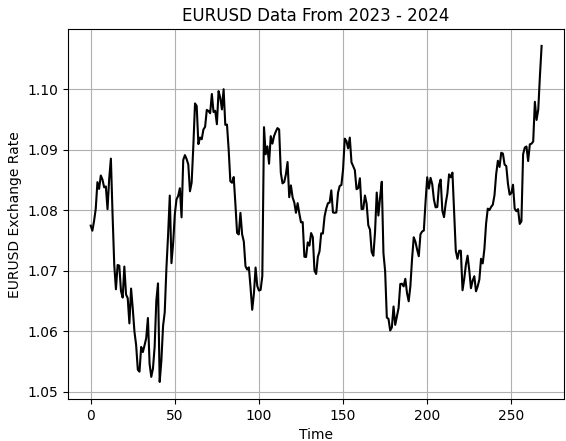
Abbildung 1: Visualisierung unserer kleinen Stichprobe von historischen EURUSD-Wechselkursen
Als Nächstes teilen wir unseren Datensatz in zwei Hälften: die erste Hälfte für das Training und die zweite für die Tests.
#Partition the data train , test = data.iloc[:data.shape[0]//2,:] , data.iloc[data.shape[0]//2:,:]
Wir speichern die Eingaben und Ziele getrennt.
#Differenced inputs X = train.iloc[:,5:-4].columns y = 'Target'
Wir laden nun unsere Bibliotheken für maschinelles Lernen und Bewertungsmetriken, um die Modelle zu bewerten.
#Load a machine learning library from sklearn.neural_network import MLPRegressor from sklearn.linear_model import LinearRegression,Ridge from sklearn.metrics import root_mean_squared_error
Wie bereits in der Einleitung zu diesem Artikel erwähnt, definieren wir zunächst ein Kontroll-Setup, indem wir unser lineares Modell erstellen.
#Start the model model = Ridge(alpha=1e-7)
Passen wir das Modell an.
model.fit(train.loc[:,X],train.loc[:,y])
Schließlich speichern wir die Vorhersagen, die das Modell auf der Testmenge gemacht hat, ohne das Modell auf diese Menge anzupassen. Erinnern Sie sich daran, dass es wichtig ist, das Modell nicht an den Testsatz anzupassen, da wir diesen Teil der Daten später zur Bewertung unseres Modells während des Backtests in MetaTrader 5 verwenden werden.
test['Predictions'] = model.predict(test.loc[:,X])
Lassen Sie uns nun allgemein bewerten, wie solide unser Modell ist. Wir beginnen damit, die Vorhersagen unseres Modells auf den Daten außerhalb der Stichprobe darzustellen und sie mit den tatsächlich realisierten Preisniveaus zu vergleichen. Wie wir sehen können, scheint das Modell, wenn wir die Leistung unseres Modells aufzeichnen, ein vernünftiges Verständnis für das zukünftige Verhalten der Preisniveaus zu haben. Die Vorhersagen erscheinen kohärent und stimmen gut mit der tatsächlichen Flugbahn des Ziels überein. Manchmal können wir jedoch auch feststellen, dass das Modell die Schwankungen der Preisdaten nicht so gut erfasst, wie wir es uns wünschen.
plt.plot(test.loc[:,'Target'],color='black') plt.plot(test.loc[:,'Predictions'],color='red',linestyle=':') plt.legend(['Target','Predictions']) plt.title('Visualizing Model Accuracy Out of Sample') plt.xlabel('Time') plt.ylabel('EURUSD Exchange Rate') plt.grid()
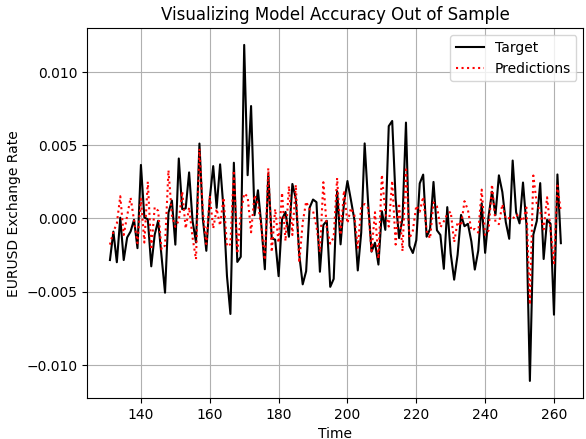
Abbildung 2: Visualisierung der Genauigkeit außerhalb der Stichprobe, die unser einfaches lineares Modell erreichen könnte
Außerdem sind die Korrelationsniveaus, die sich aus unserem linearen Modell und dem realen Ziel ergeben, eher gering. Das Modell ergibt eine Korrelation von 0,58, was relativ schlecht ist.
test.loc[:,['Target','Predictions']].corr().iloc[0,1]
0.5826364163824712
Umstellung auf ONNX
ONNX, die Abkürzung für Open Neural Network Exchange, ist ein Open-Source-Protokoll, mit dem wir Modelle für maschinelles Lernen in verschiedenen Frameworks erstellen und einsetzen können. Es ist sprachunabhängig, d. h. wir können ein Modell in einer Sprache trainieren, die die ONNX-API unterstützt, und es für die Bereitstellung in eine andere Sprache exportieren, solange beide ONNX unterstützen. So kann dasselbe Modell in vielen Systemen verwendet werden.
All dies ist dank der weit verbreiteten Nutzung der ONNX-API möglich. Wir beginnen also mit dem Import der ONNX-Bibliothek, zusammen mit einer Konvertierungsbibliothek, die scikit-learn-Modelle in ihre ONNX-Darstellung umwandelt. Dieses Diagramm kann leicht in die ursprüngliche Implementierung zurückverwandelt werden.
import onnx from skl2onnx import convert_sklearn from skl2onnx.common.data_types import FloatTensorType
Sobald die ONNX-Bibliothek importiert ist, definieren wir die Eingabe- und Ausgabeformen, die das Modell akzeptiert und zurückgibt.
initial_types = [("FLOAT INPUT",FloatTensorType([1,4]))] final_types = [("FLOAT OUTPUT",FloatTensorType([1,1]))]
Anschließend wandeln wir jedes unserer trainierten Modelle in seine ONNX-Prototypen um.
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12) model2_proto = convert_sklearn(model2,initial_types=initial_types,target_opset=12)
Als Nächstes speichern wir diese Prototypen als .onnx-Dateien mit der ONNX-Speichermethode.
onnx.save(model_proto,"EURUSD LR D1 DIFFERENCED.onnx") onnx.save(model2_proto,"EURUSD LR 2 D1 RAW.onnx")
Definition unseres Benchmark-Leistungsniveaus
Wir beginnen mit dem Laden des zuvor erstellten ONNX-Puffers.
//-- Load the onnx buffer #resource "\\Files\\EURUSD LR D1 DIFFERENCED.onnx" as const uchar onnx_buffer[];
Dann definieren wir globale Variablen, die sich auf das ONNX-Modell beziehen, einschließlich Vorhersagespeicher und Modellhandler.
//--- Global variables long onnx_model; vector onnx_inputs,onnx_output;
Danach laden wir die Handelsbibliothek, die uns hilft, Positionen und Risikoniveaus zu verwalten.
//--- Libraries #include <Trade\Trade.mqh> CTrade Trade;
Wenn das Modell zum ersten Mal initialisiert wird, bereiten wir es mit der Methode OnnxCreateFromBuffer() vor. Diese Methode benötigt zwei Parameter:
- Der aus der Datei erstellte ONNX-Puffer.
-
Die Initialisierungsargumente – wie z.B. die Angabe des ONNX-Datentyps als Float, da Float-Eingänge und -Ausgänge stabil sind und in ONNX häufig verwendet werden.
Anschließend werden die Eingabe- und Ausgabeformen des Modells so eingestellt, dass sie mit den zuvor in Python definierten Formen übereinstimmen.
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Prepare the ONNX model onnx_model = OnnxCreateFromBuffer(onnx_buffer,ONNX_DEFAULT); //--- Set the input shape of the model ulong model_input[] = {1,4}; OnnxSetInputShape(onnx_model,0,model_input); ulong model_output[] = {1,1}; OnnxSetOutputShape(onnx_model,0,model_output); //--- return(INIT_SUCCEEDED); }
Wenn die Anwendung geschlossen wird, geben wir die dem ONNX-Modell zugewiesenen Ressourcen frei, was in MQL5 eine gute Praxis ist.
//+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- Free up dedicated ONNX resources OnnxRelease(onnx_model); }
Jedes Mal, wenn wir neue Preise erhalten, prüfen wir zunächst, ob es keine offenen Positionen gibt. Wenn das der Fall ist, bereiten wir uns darauf vor, eine Vorhersage vom ONNX-Modell zu erhalten, um zu entscheiden, welche Position wir einnehmen sollen.
Dazu wird die Größe des Eingabevektors an die erwartete Form angepasst – in diesem Fall an die Größe vier. Jede Eingabe wird verarbeitet und in den Typ float umgewandelt. Wir holen auch Marktdaten wie Geld- und Briefkurse ein. Eine Variable namens Padding bestimmt, wie breit der Stop-Loss sein wird.
Als Nächstes bereiten wir einen Vektor vor, um die Vorhersage des Modells zu speichern – dieser sollte die Länge eins haben. Wir verwenden dann den Befehl onnx.run(), um eine Prognose zu erstellen, sie auf dem Terminal auszudrucken und sie mit dem aktuellen Marktpreis zu vergleichen, um ein Handelssignal zu erzeugen.
Dies ist die klassische Art und Weise, wie maschinelle Lernmodelle in Handelssystemen eingesetzt werden. Wenn eine Position bereits offen ist, warten wir einfach, bis sie entweder den Stop-Loss oder den Take-Profit erreicht. Dies hilft uns zu beurteilen, wie genau und konsistent die
//+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- Check if we have no open positions if(PositionsTotal() ==0) { //--- Prepare the model inputs onnx_inputs.Resize(4); onnx_inputs[0] = (float) iClose(Symbol(),PERIOD_D1,0) - iClose(Symbol(),PERIOD_D1,1); onnx_inputs[1] = (float) iOpen(Symbol(),PERIOD_D1,0) - iOpen(Symbol(),PERIOD_D1,1); onnx_inputs[2] = (float) iHigh(Symbol(),PERIOD_D1,0) - iHigh(Symbol(),PERIOD_D1,1); onnx_inputs[3] = (float) iLow(Symbol(),PERIOD_D1,0) - iLow(Symbol(),PERIOD_D1,1); //--- Market data double ask = SymbolInfoDouble(Symbol(),SYMBOL_ASK); double bid = SymbolInfoDouble(Symbol(),SYMBOL_BID); double padding = 5e-3; //--- Store the model's prediction onnx_output.Resize(1); if(OnnxRun(onnx_model,ONNX_DATA_TYPE_FLOAT,onnx_inputs,onnx_output)) { Print("Model forecast: ",onnx_output[0]); //--- Buy setup if(onnx_output[0] > iClose(Symbol(),PERIOD_D1,0)) Trade.Buy(0.01,Symbol(),ask,ask-padding,ask+padding,""); //--- Sell setup else if(onnx_output[0] < iClose(Symbol(),PERIOD_D1,0)) Trade.Sell(0.01,Symbol(),bid,bid+padding,bid-padding,""); } } //--- Otherwise, if we do have open positions else if(PositionsTotal()>0) { //--- Then Print("Position Open"); } } //+------------------------------------------------------------------+
Wir beginnen wie üblich mit der Hervorhebung der Daten, die wir für unseren Backtest reserviert haben. Erinnern Sie sich daran, dass wir in Python unseren Datensatz in zwei Hälften geteilt haben und unser Modell nicht auf den Testsatz angepasst haben. Dies sind die gleichen Daten, die wir für unsere MetaTrader 5 Praxis ausgewählt haben. Dies gibt uns einen gesunden Maßstab, um zu versuchen, unser tiefes neuronales Netzwerk zu übertreffen.

Abbildung 3: Auswahl der Daten, die wir für unseren Kontroll-Backtest benötigen
Wir werden auch zufällige Verzögerungseinstellungen wählen, um sicherzustellen, dass unsere Backtest-Bedingungen den realen Handelsbedingungen entsprechen.
Abbildung 4: Auswahl von Backtest-Bedingungen, die die erwarteten Einsatzbedingungen nachbilden
Bei der Analyse der von der Handelsstrategie erzeugten Kapitalkurve ist zu erkennen, dass die ursprüngliche Strategie in der ersten Hälfte des Backtest-Zeitraums zwar langsam anlief, sich aber am Ende als profitabel erwies.
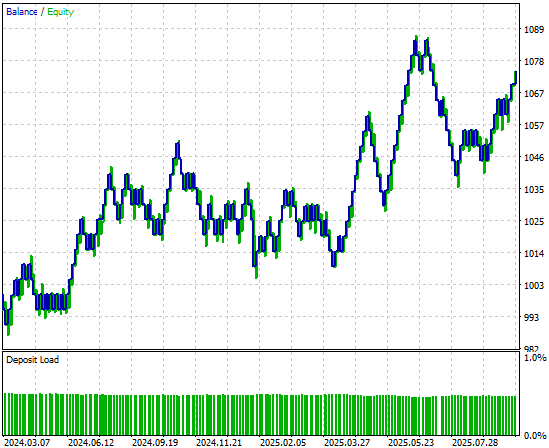
Abbildung 5: Die durch unser einfaches lineares Modell erzeugte Equity-Kurve erscheint vielversprechend, aber wir können immer noch ein höheres Leistungsniveau erreichen
Wenn wir uns die detaillierten Leistungsstatistiken ansehen, sehen wir, dass es noch Raum für Verbesserungen gibt. Zum Beispiel schneiden Verkäufe des Modells besonders schlecht ab – die Genauigkeit liegt bei knapp fünfzig Prozent und ist damit nur wenig besser als der Zufall. Interessant ist jedoch auch, dass das Modell bei Käufen gut fundiert erscheint.
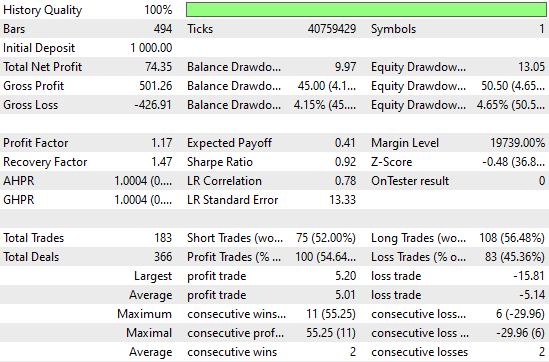
Abbildung 6: Visualisierung der detaillierten Statistiken, die wir durch die Auswertung unseres einfachen Ridge-Modells auf Daten außerhalb der Stichprobe erhalten haben
Die Verbesserung unserer ersten Ergebnisse
Lassen Sie uns nun versuchen, diese ersten Ergebnisse zu verbessern. Wir beginnen mit dem Import der entsprechenden Resampling-Methoden aus der scikit-learn-Bibliothek: RandomizedSearchCV und TimeSeriesSplit. Diese beiden können zusammen für das Resampling von Zeitreihen verwendet werden.
from sklearn.model_selection import RandomizedSearchCV,TimeSeriesSplit
Als Nächstes erstellen wir ein TimeSeriesSplit-Objekt mit fünf Foldings und setzen den Abstand zwischen den einzelnen Foldings gleich dem Prognosehorizont.
tscv = TimeSeriesSplit(n_splits=5,gap=HORIZON) Anschließend erstellen wir ein neuronales Netzwerk mit Grundeinstellungen, die bei allen Iterationen unserer Kreuzvalidierungstests gleich bleiben.
nn = MLPRegressor(random_state=0,shuffle=False,early_stopping=False,max_iter=1000)
Wir erstellen auch ein Wörterbuch mit Parametern für unser tiefes neuronales Netz. Jeder dieser Parameter wird ausprobiert und verglichen, um das beste Modell zu ermitteln.
distributions = dict(activation=['identity','logistic','tanh','relu'], alpha=[100,10,1,1e-1,1e-2,1e-3,1e-4,1e-5,1e-6,1e-7], hidden_layer_sizes=[(4,40,20,10,2),(4,100,200,500,100,4),(4,20,40,20,4,2),(4,10,50,10,4),(4,4,4,4)], solver=['adam','sgd','lbfgs'], learning_rate = ['constant','invscaling','adaptive'] )
Dann verwenden wir das randomisierte Suchverfahren, das eine kontrollierte Anzahl von Iterationen aus allen möglichen Parameterkombinationen durchführt. Es durchsucht nicht den gesamten Eingaberaum erschöpfend, sondern ermöglicht es uns, durch die Einstellung des Parameters n_iter zu kontrollieren, wie streng die Suche ist.
rscv = RandomizedSearchCV(nn,distributions,random_state=0,n_iter=50,n_jobs=-1,scoring='neg_mean_squared_error',cv=tscv)
Um die Kreuzvalidierung durchzuführen, rufen wir einfach die Methode fit() für das zuvor erstellte RandomizedSearchCV-Objekt auf und speichern die Ergebnisse in einer Variablen, die nach unserem Suchverfahren für das neuronale Netz benannt ist.
nn_search = rscv.fit(train.loc[:,X],train.loc[:,y])
Nach Abschluss der Suche werden die besten, durch Kreuzvalidierung gefundenen Parameter abgerufen.
nn_search.best_params_
{'solver': 'lbfgs',
'learning_rate': 'adaptive',
'hidden_layer_sizes': (4, 40, 20, 10, 2),
'alpha': 0.0001,
'activation': 'identity'}
Wir initialisieren dann ein neues Modell mit diesen Parametern und passen es an die Trainingsmenge an.
model = MLPRegressor(random_state=0,shuffle=False,early_stopping=False,max_iter=1000,solver='lbfgs',learning_rate='adaptive',hidden_layer_sizes=(4, 40, 20, 10, 2),alpha=0.0001,activation='identity') model.fit(train.loc[:,X],train.loc[:,y])
Schließlich wandeln wir das Modell in seinen ONNX-Prototyp um.
model_proto = convert_sklearn(model,initial_types=initial_types,target_opset=12)
Schließlich speichern wir die ONNX-Datei des neuronalen Netzes auf unserem Laufwerk, damit wir die vorgenommenen Verbesserungen testen können.
onnx.save(model_proto,'EURUSD NN D1.onnx')
Die Umsetzung unserer Verbesserungen
Die meisten Teile unserer früheren Anwendung bleiben unverändert, sodass wir uns jetzt auf die wenigen Codezeilen konzentrieren können, die wir aktualisieren müssen, um unser verbessertes Modell widerzuspiegeln. Die einzige Zeile, die geändert werden muss, ist der Ressourcenpfad in unserer Header-Datei – er muss aktualisiert werden, damit er auf das neue neuronale Netzwerkmodell verweist, das wir gerade erstellt haben.
//-- Load the onnx buffer #resource "\\Files\\EURUSD NN D1.onnx" as const uchar onnx_buffer[];
Sobald dies abgeschlossen ist, können wir beobachten, wie sich unsere neue Anwendung im gleichen Backtestzeitraum verhält. Um einen fairen Vergleich zu gewährleisten, werden wir die gleichen Daten wie bisher auswählen.
Abbildung 7: Auswahl unserer neuen und verbesserten Anwendung des tiefen neuronalen Netzes für den Handel im gleichen Testzeitraum
Wenn wir die detaillierten Leistungsstatistiken analysieren, können wir bereits bemerkenswerte Veränderungen feststellen. Der Gesamtnettogewinn ist mit der Anzahl der vom System registrierten Handelssignale erheblich gestiegen. Das bedeutet, dass das neuronale Netzwerk die Rentabilität erhöht hat und gleichzeitig mehr Geschäfte platziert als die Vorgängerversion – bei gleichbleibender Genauigkeit. Dies sind recht beeindruckende Verbesserungen, die zu beobachten sind.
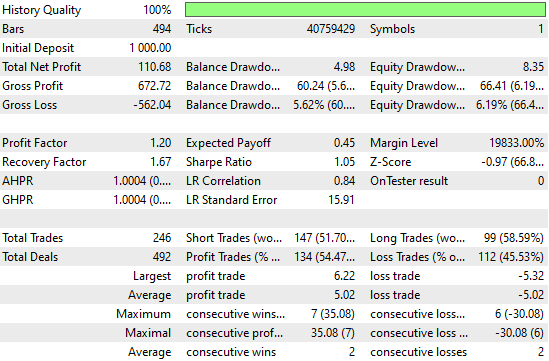
Abbildung 8: Unser Leistungsniveau hat sich gegenüber dem von uns festgelegten Kontrollmaßstab erheblich verbessert
Wenn wir schließlich die von der neuen Version der Anwendung erzeugte Kapitalkurve betrachten, können wir deutlich sehen, dass die Konsolidierungsphase, die zuvor das Wachstum in unserem ursprünglichen Backtest stagnieren ließ, nun durch einen starken, explosiven Aufwärtstrend ersetzt wurde, der von unserem neuronalen Netz erzeugt wurde. Damit verfügen wir über eine zuverlässigere und robustere Quelle für Handelssignale in der Zukunft.
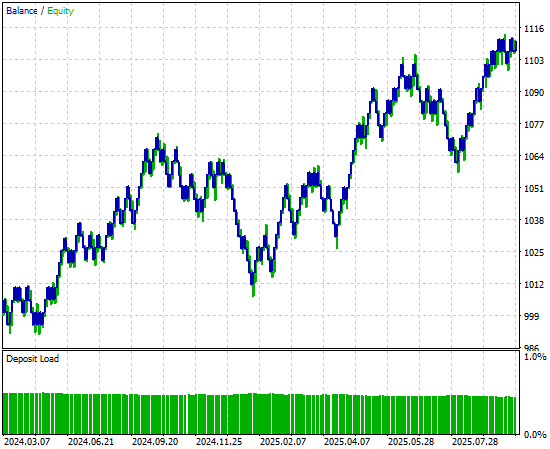
Abbildung 9: Visualisierung der durch unsere Strategie erzeugten Kapitalkurve, die wir durch Kreuzvalidierung der Zeitreihen verbessert haben
Schlussfolgerung
Dieser Artikel hat dem Leser einen Überblick über die Stärken von Zeitreihen-Kreuzvalidierungsverfahren gegeben, wenn diese sinnvoll eingesetzt werden. Der Leser erfährt, dass die Kreuzvalidierung von Zeitreihen dazu beitragen kann, das Risiko der Überanpassung zu verringern, bessere Modellparameter zu finden und zu optimieren, die bestmögliche Methode aus einem Pool von Modellkandidaten zu ermitteln und den Testfehler eines Modells anhand von Daten zu schätzen, die es noch nicht gesehen hat.
Wie wir in diesem Artikel wiederholt haben, ist diese Liste von Anwendungsfällen keineswegs erschöpfend. Es wäre unmöglich, alle Vorteile aufzuzählen, die die Kreuzvalidierung von Zeitreihen für unsere Modellierungspipeline bietet.
Da wir nun aber an diesem Punkt unserer Diskussion angelangt sind, sollte der Leser gut darauf vorbereitet sein, tiefergehende Fragen zu stellen. Können die hier gezeigten Leistungsniveaus durch strengere Formen der Zeitreihen-Kreuzvalidierung als die hier vorgestellte einfache K-Fold-Methode noch verbessert werden? Das sind Fragen, die es auf jeden Fall wert sind, weiter untersucht zu werden.
In den folgenden Diskussionen werden wir alternative Kreuzvalidierungsmethoden, wie die „Walk-Forward Time Series Cross-Validation“, betrachten und sie dem Ansatz „K-Fold“ gegenüberstellen. Durch diesen Vergleich werden wir lernen, zu begründen, warum eine Methode besser geeignet sein könnte als eine andere. Um zu verstehen, wann das der Fall sein könnte, müssen Sie zunächst eine klare Vorstellung davon haben, was eine gute Kreuzvalidierung für Sie leisten kann.
| Dateiname | Beschreibung der Datei |
|---|---|
| Fetch_Data.mq5 | Das nutzerdefinierte MQL5-Skript, das wir geschrieben haben, um unsere historischen Daten aus dem MetaTrader 5-Terminal abzurufen. |
| The_Limitations_of_AI_Model_Selection.ipynb | Das Jupyter-Notebook, das wir geschrieben haben, um die Marktdaten zu analysieren, die wir vom MetaTrader 5 Terminal erhalten haben. |
| EURUSD_LR_D1_DIFFERENCED.onnx | Das ONNX-Modell mit linearer Regression, das wir als Benchmark-Modell erstellt haben. |
| EURUSD_NN_D1.onnx | Das Modell des tiefen neuronalen Netzwerks ONNX, das wir erstellt haben, um den Benchmark zu übertreffen. |
| EURUSD_Daily_EA.mq5 | Die durch ein tiefes neuronales Netzwerk erweiterte Handelsanwendung haben wir mithilfe von Zeitreihen-Kreuzvalidierung optimiert. |
| EURUSD_Daily_EA_3.mq5 | Die Benchmark-Anwendung für den Handel sollte besser abschneiden, obwohl die Datenmenge begrenzt war. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/19775
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.