Архитектура системы машинного обучения в MetaTrader 5 (Часть 3): Метод разметки сканированием тренда

Введение
Добро пожаловать в третью часть нашей серии статей, посвященной созданию алгоритмов машинного обучения для MetaTrader 5. Мы прошли долгий путь от фундаментальных проблем целостности данных, рассмотренных в Части 1, до революционных методов разметки, представленных в Части 2. Теперь мы готовы приступить к реализации адаптивного метода разметки на основе сканирования тренда.
Финансовые рынки не статичны. То, что работало вчера, может не сработать завтра, и то, что кажется сильным сигналом, на самом деле может оказаться избыточным шумом, созданным пересекающимися наблюдениями. Эта статья напрямую рассматривает эти проблемы, используя мощные техники из исследований Маркоса Лопеса де Прадо. Мы реализуем метод сканирования тренда, который революционизирует наш подход к определению горизонтов прогнозирования. Вместо произвольного выбора прогноза на 5 или 10 дней вперед, сканирование тренда динамически определяет наиболее статистически значимый горизонт для каждой рыночной ситуации. Это похоже на телескоп, который автоматически фокусируется, чтобы получить наилучшее изображение рыночных трендов.
Эта статья напрямую опирается на концепции из Части 2, поэтому, если вы еще не читали ее, мы настоятельно рекомендуем сделать это в первую очередь. К концу этой статьи у вас будет полная, готовая к использованию система разметки, которая адаптируется к рыночным условиям. Это не просто академическая теория — это практический фреймворк, решающий реальные задачи трейдинга.
Метод разметки сканированием тренда
Теория и мотивация
Метод тройных барьеров, который мы исследовали в Части 2, был значительным улучшением по сравнению с разметкой по фиксированному временному горизонту, но он по-прежнему полагался на заранее определенные временные ограничения для наших вертикальных барьеров. Нам нужно было заранее решить, удерживать ли позиции в течение 50 баров, 100 баров или какой-либо другой произвольной длительности. Этот подход предполагает, что оптимальный горизонт прогнозирования является постоянным для всех рыночных условий — предположение, которое, как знает любой, кто торговал на волатильных рынках, в корне ошибочно. Рассмотрим два различных рыночных сценария: трендовый бычий рынок, где импульс сохраняется в течение недель, и неспокойный, боковой рынок, где тренды разворачиваются каждые несколько дней. Использование одного и того же временного горизонта для обоих сценариев — это как носить одну и ту же куртку и летом, и зимой; иногда это может сработать, но редко бывает оптимальным.
Метод сканирования тренда элегантно решает эту проблему, позволяя данным определять оптимальный горизонт прогнозирования для каждого наблюдения. Вместо того чтобы навязывать фиксированные временные рамки, он тестирует множество будущих периодов и выбирает тот, который демонстрирует наиболее сильные статистические свидетельства наличия тренда.
Вот как это работает: для каждой потенциальной точки входа в сделку алгоритм смотрит вперед и вычисляет t-статистики для различных горизонтов прогнозирования (например, 5 баров, 10 баров, 15 баров, вплоть до некоторого максимума). Затем он выбирает горизонт, который дает наиболее статистически значимый результат, по сути задавая вопрос: "В какой будущий момент тренд определен наиболее четко?"
Этот подход имеет несколько ключевых преимуществ перед фиксированными горизонтами:
- Адаптивность к рынку: В волатильные периоды алгоритм может выбирать более короткие горизонты, на которых тренды более выражены. В спокойные, трендовые рынки он может выбирать более длинные горизонты, чтобы захватить устойчивые движения.
- Статистическая строгость: Вместо произвольных отсечек, метки основаны на статистической значимости. Тренд помечается как таковой, только если он соответствует строгим статистическим критериям.
- Снижение шума: Требуя статистической значимости, метод естественным образом отфильтровывает случайные ценовые движения, которые не являются значимыми трендами.
- Динамическая реакция: По мере изменения рыночных условий оптимальный горизонт автоматически корректируется без ручного вмешательства.
Математическая основа проста, но мощна. Для каждого потенциального горизонта h мы вычисляем t-статистику линейного тренда на рассматриваемом участке ряда. T-статистика измеряет, на сколько стандартных отклонений наблюдаемый тренд отклоняется от нуля (отсутствие тренда). Более высокие абсолютные значения указывают на более сильные статистические доказательства наличия тренда.
Алгоритм выбирает горизонт, который максимизирует абсолютное значение t-статистики, но только если оно превышает минимальный порог значимости. Это гарантирует, что мы выбираем не просто "наименее шумный" вариант среди случайных колебаний, а выявляем действительно значимые тренды.
Одним из самых элегантных аспектов сканирования тренда является то, как оно автоматически обрабатывает различные типы рыночного поведения. На трендовых рынках оно обычно выбирает более длинные горизонты, чтобы захватить полное движение. На рынках с возвратом к среднему оно выбирает более короткие горизонты, на которых развороты статистически наиболее очевидны. Во время консолидации оно может не найти статистически значимых трендов ни на одном горизонте, естественным образом генерируя сигналы "удерживать".
Такая адаптивность делает сканирование тренда особенно ценным для стратегий, которым необходимо работать в различных рыночных режимах. Вместо оптимизации под конкретные условия в надежде, что они сохранятся, алгоритм непрерывно смещает аналитический фокус в соответствии с текущей рыночной динамикой.
Реализация
Ниже приведены фрагменты кода, реализующие метод сканирования тренда из книги Маркоса Лопеса де Прадо "Машинное обучение для управляющих активами" (раздел 5.4) .
import numpy as np import pandas as pd import statsmodels.api as sm from multiprocess import mp_pandas_obj # SNIPPET 5.1 T-VALUE OF A LINEAR TREND # --------------------------------------------------- def tValLinR(close): # tValue from a linear trend x = np.ones((close.shape[0], 2)) x[:, 1] = np.arange(close.shape[0]) ols = sm.OLS(close, x).fit() return ols.tvalues[1]
# SNIPPET 5.2 IMPLEMENTATION OF THE TREND-SCANNING METHOD def getBinsFromTrend(close, span, molecule): """ Derive labels from the sign of t-value of linear trend Output includes: - t1: End time for the identified trend - tVal: t-value associated with the estimated trend coefficient - bin: Sign of the trend """ out = pd.DataFrame(index=molecule, columns=["t1", "tVal", "bin"]) hrzns = range(*span) for dt0 in molecule: df0 = pd.Series() iloc0 = close.index.get_loc(dt0) if iloc0 + max(hrzns) > close.shape[0]: continue for hrzn in hrzns: dt1 = close.index[iloc0 + hrzn - 1] df1 = close.loc[dt0:dt1] df0.loc[dt1] = tValLinR(df1.values) dt1 = df0.replace([-np.inf, np.inf, np.nan], 0).abs().idxmax() out.loc[dt0, ["t1", "tVal", "bin"]] = ( df0.index[-1], df0[dt1], np.sign(df0[dt1]), ) # prevent leakage out["t1"] = pd.to_datetime(out["t1"]) out["bin"] = pd.to_numeric(out["bin"], downcast="signed") return out.dropna(subset=["bin"])
def trendScanningLabels(close, span, num_threads=4, verbose=True): out = mp_pandas_obj( getBinsFromTrend, ("molecule", close.index), num_threads, verbose=verbose, close=close, span=span, ) return out.astype({"bin": "int8"})
Несмотря на то, что trendScanningLabels использует механизм многопроцессорной обработки, вызываемый через mp_pandas_obj (см. прилагаемый файл multiprocess.py), исходная реализация слишком медленна для применения в реальной торговле. Моя оптимизированная версия, представленная ниже, использует Numba для компиляции основного цикла в быстрый машинный код, устраняя узкие места производительности Python. Эти улучшения делают функцию примерно в 350 раз быстрее, а также добавляют ключевые обновления функциональности, устраняющие ограничения оригинального кода.
from numba import njit, prange @njit(parallel=True, cache=True) def _window_stats_numba(y, window_length): """ Compute slopes, t-values, and R² for all fixed-length windows. This function is optimized for performance using Numba's JIT compilation. :param y: (np.ndarray) The input data array. :param window_length: (int) The length of the sliding window. :return: (tuple) A tuple containing: - t_values: (np.ndarray) The t-values for each window. - slopes: (np.ndarray) The slopes for each window. - r_squared: (np.ndarray) The R² values for each window. """ n = len(y) num_windows = n - window_length + 1 t_values = np.empty(num_windows) slopes = np.empty(num_windows) r_squared = np.empty(num_windows) t = np.arange(window_length) mean_t = t.mean() Var_t = ((t - mean_t) ** 2).sum() for i in prange(num_windows): window = y[i : i + window_length] mean_y = window.mean() sum_y = window.sum() sum_y2 = (window**2).sum() # Slope estimation S_ty = (window * t).sum() slope = (S_ty - window_length * mean_t * mean_y) / Var_t slopes[i] = slope # SSE calculation beta0 = mean_y - slope * mean_t SSE = sum_y2 - beta0 * sum_y - slope * S_ty # R² calculation SST = sum_y2 - (sum_y**2) / window_length epsilon = 1e-9 r_squared[i] = max(0.0, 1.0 - SSE / (SST + epsilon)) if SST > epsilon else 0.0 # t-value calculation sigma2 = SSE / (window_length - 2 + epsilon) se_slope = np.sqrt(sigma2 / Var_t) t_values[i] = slope / (se_slope + epsilon) return t_values, slopes, r_squared
Представленная ниже функция является основной управляющей-функцией для получения меток сканирования тренда.
from typing import List, Tuple, Union import numpy as np import pandas as pd from loguru import logger def trend_scanning_labels( close: pd.Series, span: Union[List[int], Tuple[int, int]] = (5, 20), volatility_threshold: float = 0.1, lookforward: bool = True, use_log: bool = True, verbose: bool = False, ) -> pd.DataFrame: """ `Trend scanning <https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3257419>`_ is both a classification and regression labeling technique. It fits OLS regressions over multiple rolling windows and selects the one with the highest absolute t-value. The sign of the t-value indicates trend direction, while its magnitude reflects confidence. The method incorporates volatility-based masking to avoid spurious signals in low-volatility regimes. This implementation offers a robust, leakage-proof trend-scanning label generator with: - Expanding, data-adaptive volatility thresholding - Full feature masking (t-value, slope, R²) in low-volatility regimes - Boundary protection to avoid look-ahead leaks - Support for both look-forward and look-backward scan Parameters ---------- close : pd.Series Time-indexed raw price series. Must be unique and sorted (monotonic). span : list[int] or tuple(int, int), default=(5, 20) If list, exact window lengths to scan. If tuple `(min, max)`, uses `range(min, max)` as horizons. volatility_threshold : float, default=0.1 Quantile level (0-1) on the expanding rolling std of log-prices. Windows below this vol threshold are zero-masked. lookforward : bool, default=True If True, labels trend on `[t, t+L-1]`; else on `[t-L+1, t]` by reversing. use_log : bool, default=True Apply log transformation before trend analysis verbose : bool, default=False Print progress for each horizon. Returns ------- pd.DataFrame Indexed by the valid subset of `close.index`. Columns: - t1 : pd.Timestamp End of the event window (lookforward) or start (lookbackward). - window : int Chosen optimal horizon (argmax |t-value|). - slope : float Estimated slope over that window. - t_value : float t-stat for the slope (clipped to ±min(var, 20)). - r_squared : float Goodness-of-fit (zero if below vol threshold). - ret : float Hold-period return over the chosen window. - bin : int8 Sign of `t_value` (-1, 0, +1), zero if |t_value|≈0. Notes ----- 1. Log-transformation stabilizes variance before regression. 2. Uses a precompiled Numba `_window_stats_numba` for the heavy sliding O(N·H) regressions. 3. Boundary slices ensure no forward-looking data leak into features. """ # Input validation and setup close = close.sort_index() if not close.index.is_monotonic_increasing else close.copy() hrzns = list(range(*span)) if isinstance(span, tuple) else span max_hrzn = max(hrzns) if lookforward: valid_indices = close.index[:-max_hrzn].to_list() else: valid_indices = close.index[max_hrzn - 1 :].to_list() if not valid_indices: return pd.DataFrame(columns=["t1", "window", "slope", "t_value", "rsquared", "ret", "bin"]) # Log transformation if use_log: close_processed = close.clip(lower=1e-8).astype(np.float64) y = np.log(close_processed).values else: y = close.values.astype(np.float64) N = len(y) # Compute volatility threshold volatility = pd.Series(y, index=close.index).rolling(max_hrzn, min_periods=1).std().ffill() vol_threshold = volatility.expanding().quantile(volatility_threshold).ffill().values # Precompute all window stats window_stats = np.full((3, N, len(hrzns)), np.nan) for k, hrzn in enumerate(hrzns): if verbose: print(f"Processing horizon {hrzn}", end="\r", flush=True) y_window = y if lookforward else y[::-1] t_vals, slopes, r_sq = _window_stats_numba(y_window, hrzn) if not lookforward: t_vals, slopes, r_sq = t_vals[::-1], slopes[::-1], r_sq[::-1] start_idx = hrzn - 1 else: start_idx = 0 n = len(t_vals) valid_vol = volatility.iloc[start_idx : start_idx + n].values mask = valid_vol > vol_threshold[start_idx : start_idx + n] window_stats[0, start_idx : start_idx + n, k] = np.where(mask, t_vals, 0) window_stats[1, start_idx : start_idx + n, k] = np.where(mask, slopes, 0) window_stats[2, start_idx : start_idx + n, k] = np.where(mask, r_sq, 0) # Integer positions for events event_idx = close.index.get_indexer(valid_indices) # Extract sub-blocks for these events t_block = window_stats[0, event_idx, :] # shape: (E, H) s_block = window_stats[1, event_idx, :] rsq_block = window_stats[2, event_idx, :] # Best horizon per event (argmax of abs t-value) best_j = np.nanargmax(np.abs(t_block), axis=1) # (E,) # Gather optimal metrics opt_tval = t_block[np.arange(len(event_idx)), best_j] opt_slope = s_block[np.arange(len(event_idx)), best_j] opt_rsq = rsq_block[np.arange(len(event_idx)), best_j] opt_hrzn = np.array(hrzns)[best_j] # Compute t1 indices vectorised if lookforward: t1_idx = np.clip(event_idx + opt_hrzn - 1, 0, N - 1) else: t1_idx = np.clip(event_idx - opt_hrzn + 1, 0, N - 1) # Map to timestamps and returns t1_arr = close.index[t1_idx] a, b = (event_idx, t1_idx) if lookforward else (t1_idx, event_idx) rets = close.iloc[b].array / close.iloc[a].array - 1 # Filter labels by t-value tval_abs = np.abs(opt_tval) mask = (tval_abs > 1e-6) bins = np.where(mask, np.sign(opt_tval), 0).astype("int8") # Assemble DataFrame df = pd.DataFrame( { "t1": t1_arr, "window": opt_hrzn, "slope": opt_slope, "t_value": opt_tval, "rsquared": opt_rsq, "ret": rets, "bin": bins, }, index=pd.Index(valid_indices), ) return df
Обратите внимание, что регрессия сканирования тренда y = α + βt + ε предполагает постоянную дисперсию ошибки. Это условие нарушается для сырых цен, но выполняется для логарифмических цен.
Ключевые улучшения по сравнению с исходной реализацией
1. Фильтрация по режиму волатильности
Оригинальный метод сканирования тренда рассматривает все рыночные условия как равнозначные. Наша реализация вводит динамическое пороговое значение на основе волатильности:
# Expanding volatility percentile calculation vol_threshold = volatility.expanding().quantile(volatility_threshold).ffill().values # Zero out statistics during low-volatility periods vol_mask = valid_vol > vol_threshold[start_idx : start_idx + n]
Это предотвращает генерацию алгоритмом ложных сигналов в периоды низкой активности, когда ценовые движения представляют собой преимущественно шум. Использование расширяющихся квантилей позволяет пороговому значению адаптироваться к меняющимся режимам рыночной волатильности.
2. Двойное назначение: Метки и Признаки
Наша реализация может работать в двух режимах:
- lookforward=True: Генерирует метки, сканируя будущие тренды от каждой точки наблюдения
- lookforward=False: Генерирует признаки, сканируя прошлые тренды до каждой точки наблюдения.
# Feature generation example (no data leakage) trend_features = trend_scanning_labels( close_prices, span=(5, 20), lookforward=False, # Look backward for features verbose=True ) # Label generation example trend_labels = trend_scanning_labels( close_prices, span=(5, 20), lookforward=True, # Look forward for labels verbose=True )
Эта двойная функциональность позволяет одной и той же надежной логике обнаружения трендов служить как для разработки признаков, так и для генерации меток в рамках единого фреймворка.
3. Надежная защита границ
В отличие от оригинальной реализации, наша включает строгую защиту границ:
# Remove observations that would require future data iloc0 = slice(0, -max_hrzn) if lookforward else slice(max_hrzn - 1, None) t_series = t_series.iloc[iloc0]
Это гарантирует, что никакая информация из будущего не загрязняет признаки или метки, сохраняя временную целостность, необходимую для надежного бэктестинга и реальной торговли.
Почему эта реализация лучше
- Готова к промышленному применению: Обрабатывает реальные проблемы данных, такие как режимы волатильности и численная нестабильность
- Без утечек данных: Строгие временные границы предотвращают любые искажения, связанные с заглядыванием вперед
- Вычислительно эффективна: JIT-компиляция Numba обеспечивает значительное ускорение
- Гибкость: Единая реализация служит как для генерации признаков, так и для создания меток
- Надежность: Маскирование волатильности и ограничение t-значений улучшают качество сигнала
Эта улучшенная реализация сканирования тренда формирует основу для действительно адаптивных меток машинного обучения, которые реагируют на рыночные условия, сохраняя при этом временную целостность, необходимую для надежных алгоритмических торговых систем. Метки сканирования тренда могут использоваться в регрессионных моделях для прогнозирования величины тренда, где целевой переменной являются t-значения, или в классификационных моделях, где целевой переменной является метка, а t-значения используются в качестве весов наблюдений.
Анализ эффективности метода разметки сканированием тренда
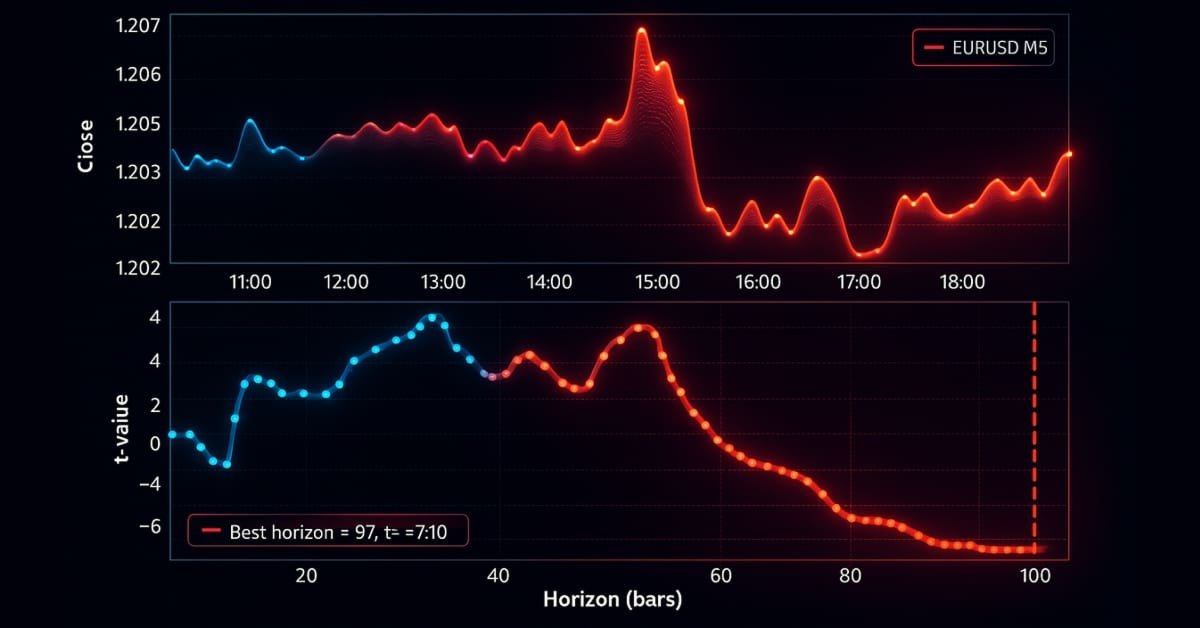
Теперь давайте протестируем сканирование тренда, используя данные EURUSD M5 с 2018-01-01 по 2021-12-31. Мы будем использовать стратегию на основе пересечения скользящих средних MA20 и MA50 в качестве первичной модели и применим мета-разметку к меткам, сгенерированным методами фиксированного горизонта, тройных барьеров и сканирования тренда. События для сделок ((t_events), передаваемые в функции triple_barrier_labels и trend_scanning_labels, определяются моментами пересечения скользящих средних. Для реализации мета-разметки со сканированием тренда я классифицирую сделку как 1, только если направление, предсказанное стратегией пересечения скользящих средних, и метка сканирования тренда совпадают; в противном случае я классифицирую ее как 0. Я обучил случайный лес, используя признаки, которые должны быть предсказательными для трендследящей модели, такие как различные скользящие средние, трендовые индикаторы вроде ADX, а также признаки, полученные при запуске trend_scanning_labels с параметром lookforward=False (см. прилагаемый файл ma_crossover_feature_engine.py). Метки сканирования тренда были сгенерированы путем сканирования окон от 5 до 99, задав диапазон span=(5, 100). Я использовал метод тройных барьеров для установки порога стоп-лосса, но без барьера тейк-профита, чтобы тренды развивались до достижения горизонтального барьера. Ниже приведены соответствующие настройки:
- Целевая волатильность = 20-дневное экспоненциально взвешенное стандартное отклонение доходностей (см. get_daily_vol в прилагаемом файле volatility.py).
- барьер тейк-профита = 0
- барьер стоп-лосса = 2
- горизонтальный барьер = 100
На графиках ниже показана работа сканирования тренда с указанными выше параметрами:
")
")
Отчеты по классификации
Результаты, представленные ниже, показывают precision, recall и F1-меру для обученного классификатора случайного леса при различных порогах волатильности, как без использования весов, так и с использованием t-значений в качестве весов наблюдений.
Метрики классификации сканирования тренда в зависимости от порога волатильности
| 0.0 | 0.05 | 0.1 | 0.2 | 0.3 | ||
|---|---|---|---|---|---|---|
| Класс | ||||||
| -1 | precision | 0.505 | 0.489 | 0.486 | 0.448 | 0.428 |
| -1 | recall | 0.545 | 0.382 | 0.408 | 0.440 | 0.413 |
| -1 | f1-score | 0.524 | 0.429 | 0.444 | 0.444 | 0.420 |
| -1 | support | 1043 | 985 | 909 | 752 | 622 |
| 0 | precision | NaN | 0.176 | 0.297 | 0.525 | 0.658 |
| 0 | recall | NaN | 1.000 | 0.926 | 0.875 | 0.858 |
| 0 | f1-score | NaN | 0.299 | 0.449 | 0.656 | 0.745 |
| 0 | support | NaN | 115 | 256 | 566 | 840 |
| 1 | precision | 0.495 | 0.479 | 0.464 | 0.444 | 0.425 |
| 1 | recall | 0.455 | 0.319 | 0.259 | 0.228 | 0.260 |
| 1 | f1-score | 0.474 | 0.383 | 0.332 | 0.301 | 0.323 |
| 1 | support | 1022 | 965 | 900 | 747 | 603 |
| accuracy | 0.500 | 0.387 | 0.407 | 0.482 | 0.550 |
| 0.0 | 0.05 | 0.1 | 0.2 | 0.3 | ||
|---|---|---|---|---|---|---|
| Класс | ||||||
| -1 | precision | 0.514 | 0.514 | 0.509 | 0.502 | 0.490 |
| -1 | recall | 0.513 | 0.585 | 0.538 | 0.516 | 0.468 |
| -1 | f1-score | 0.513 | 0.548 | 0.523 | 0.509 | 0.479 |
| -1 | support | 1043 | 945 | 865 | 721 | 596 |
| 1 | precision | 0.504 | 0.513 | 0.506 | 0.501 | 0.485 |
| 1 | recall | 0.505 | 0.442 | 0.478 | 0.487 | 0.508 |
| 1 | f1-score | 0.504 | 0.475 | 0.492 | 0.494 | 0.496 |
| 1 | support | 1022 | 935 | 858 | 719 | 589 |
| accuracy | 0.509 | 0.514 | 0.508 | 0.501 | 0.488 |
| Порог | Невзвешенная точность | Взвешенная точность |
|---|---|---|
| 0.0 | 0.500 | 0.509 |
| 0.05 | 0.387 | 0.514 |
| 0.1 | 0.407 | 0.508 |
| 0.2 | 0.482 | 0.501 |
| 0.3 | 0.550 | 0.488 |
| Класс | Метрика | 0.0 | 0.05 | 0.1 | 0.2 | 0.3 |
|---|---|---|---|---|---|---|
| Невзвешенная модель | ||||||
| -1 | f1-score | 0.524 | 0.429 | 0.444 | 0.444 | 0.420 |
| 0 | f1-score | NaN | 0.299 | 0.449 | 0.656 | 0.745 |
| 1 | f1-score | 0.474 | 0.383 | 0.332 | 0.301 | 0.323 |
| Взвешенная модель (t-значения как веса) | ||||||
| -1 | f1-score | 0.513 | 0.548 | 0.523 | 0.509 | 0.479 |
| 0 | f1-score | Неприменимо (бинарная классификация) | ||||
| 1 | f1-score | 0.504 | 0.475 | 0.492 | 0.494 | 0.496 |
Рекомендации: когда использовать взвешенные и невзвешенные модели
Взвешенная модель (t-значения как веса)
- Акцент на статистически более сильных сигналах: Снижает вес слабых меток, отражая силу статистического подтверждения.
- Стабильность вместо пиковых значений: Предпочтение отдается стабильной работе на разных порогах, а не единственной точке с высокой точностью.
- Готовность к производству: Устойчивость и надежность для реальных торговых систем.
- Работа с дисбалансом классов: Снижает доминирование нейтральных или зашумленных классов.
Невзвешенная модель
- Оценка качества сырого сигнала: Базовый уровень эффективности без искажения весами.
- Моделирование нейтральных зон: Сохраняет нейтральный класс (0) там, где это важно для границ принятия решений.
- Исследования и прототипирование: Быстрое экспериментирование до введения статистических ограничений.
- Оптимизация под пиковый порог: Если целевой порог известен и допустима вариативность.
Тестирование на вневыборке
Результаты получены при равномерном распределении объема позиций на сделках по сигналам пересечения MA20 и MA50 для EURUSD M5 за период с 2021-12-31 до 2024-12-31. Мета-метки трендового сканирования сформированы на основе предсказаний случайного леса, обученного на размеченных данных трендового сканирования с порогом волатильности 0.05 и весами, основанными на t-значениях.

Сравнение эффективности: мета-разметка против базовой модели (MA Crossover 20/50)
| Метрика | Фиксированный горизонт | Тройной барьер | Трендовое сканирование |
|---|---|---|---|
| Общая доходность | -12.49% (↓88.4%) | -5.04% (↑34.5%) | 4.53% (↔ 0.0%) |
| Годовая доходность | -4.35% (↓92.4%) | -1.71% (↑35.1%) | 1.49% (↔ 0.0%) |
| Коэффициент Шарпа | -3.72 (↓360%) | -1.66 (↓5.1%) | 2.62 (↑37.3%) |
| Коэффициент Сортино | -5.09 (↓354%) | -3.66 (↓2.2%) | 4.25 (↑88.5%) |
| Коэффициент Калмара | -0.285 (↓22.3%) | -0.138 (↑28.9%) | 0.121 (↔ 0.0%) |
| Макс.просадка | 15.27% (↓57.4%) | 12.38% (↑8.8%) | 12.32% (↔ 0.0%) |
| Доля выигрышей | 49.6% (↔) | 40.3% (↑14.5%) | 21.2% (↑88.5%) |
| Фактор прибыли | 0.96 (↓3.0%) | 0.98 (↔) | 1.04 (↔) |
| Ожидание | -0.0046% (↓332%) | -0.0016% (↓18%) | -0.0762% (↑34%) |
| Критерий Келли | -0.0206 (↓308%) | -0.0068 (↓14%) | -0.3255 (↑34%) |
Ключевые выводы
Результаты тестирования на вневыборочных данных выявили четкие различия между тремя подходами к мета-разметке:
- Фиксированный Горизонт последовательно ухудшал производительность, демонстрируя отрицательную доходность, низкие коэффициенты Шарпа и Сортино, а также более глубокие просадки. Это говорит о том, что жесткие временные рамки удержания позиций плохо подходят для данной стратегии.
- Тройной Барьер показал умеренное улучшение доходности и контроля просадок, но скорректированные по риску метрики (Шарп, Сортино) оставались слабыми. Этот подход обеспечил некоторую стабильность, но не дал решающего преимущества.
- Трендовое Сканирование выделилось наибольшим приростом скорректированной по риску доходности. Коэффициент Шарпа улучшился более чем на 37%, а коэффициент Сортино почти удвоился, при этом просадки остались на прежнем уровне. Это указывает на то, что взвешивание сделок по их статистической значимости обеспечивает более надежную и стабильную производительность.
На практике Фиксированный Горизонт может быть полезен только для сравнительного анализа, Тройной Барьер— для умеренного контроля риска, а Трендовое Сканирование— для промышленного внедрения, где стабильность и скорректированная по риску доходность имеют наибольшее значение.
Расширенные метрики эффективности мета-разметки
| фиксированный_горизонт | тройной_барьер | сканирование_тренда | |
|---|---|---|---|
| Общая доходность | -0.124942 | -0.050359 | 0.045288 |
| Годовая доходность | -0.043504 | -0.017072 | 0.01487 |
| Волатильность | 0.888104 | 0.709836 | 0.521126 |
| Волатильность убытков | 0.649197 | 0.323178 | 0.32075 |
| Коэффициент Шарпа | -3.722773 | -1.66439 | 2.616468 |
| Коэффициент Сортино | -5.092763 | -3.655701 | 4.251009 |
| var_95 | -0.005302 | -0.003206 | -0.002467 |
| cvar_95 | -0.007848 | -0.004445 | -0.003576 |
| Ассиметрия | -0.107052 | 1.311478 | 2.165464 |
| Эксцесс | 3.459559 | 4.599455 | 14.055488 |
| Концентрация прибыли | 0.000775 | 0.000923 | 0.003244 |
| Концентрация убытков | 0.000796 | 0.000342 | 0.000683 |
| Концентрация по времени | 0.004943 | 0.004943 | 0.004943 |
| Макс. просадка | 0.152723 | 0.123841 | 0.123154 |
| Средняя просадка | 0.021861 | 0.016572 | 0.013556 |
| Длительность просадки | 91 дней 05:53:45 | 64 дней 09:48:32 | 51 дней 23:37:23 |
| Индекс язвы | 0.04722 | 0.035056 | 0.029828 |
| Коэффициент Калмара | -0.284854 | -0.137858 | 0.120745 |
| Средняя длительность сделки | 0 дней 06:01:02 | 0 дней 07:39:46 | 0 дней 04:24:31 |
| Частота ставок (сигналов) | 26 | 66 | 33 |
| Ставок в год | 8 | 21 | 10 |
| Кол-во сделок | 2665 | 2665 | 2665 |
| Сделок в год | 888 | 888 | 888 |
| Доля выигрышных сделок | 0.495685 | 0.403002 | 0.212383 |
| Средний выигрыш | 0.002258 | 0.002348 | 0.002342 |
| Средний убыток | -0.002311 | -0.001612 | -0.0016 |
| Лучшая сделка | 0.017643 | 0.017643 | 0.017643 |
| Худшая сделка | -0.01916 | -0.012522 | -0.012522 |
| Фактор прибыли | 0.961558 | 0.983383 | 1.038523 |
| Ожидание | -0.000046 | -0.000016 | -0.000762 |
| Критерий Келли | -0.020585 | -0.00681 | -0.325531 |
| Макс. выигрышей подряд | 6 | 6 | 3 |
| Макс. убытков подряд | 8 | 12 | 3 |
| Доля длинных позиций | 0.5 | 0.484375 | 1.0 |
| Частота фильтрации сигналов | 0.469546 | 0.469546 | 0.469546 |
| Порог уверенности | 0.5 | 0.5 | 0.5 |
Сводка эффективности: стратегии разметки
Трендовое сканирование показывает себя как наиболее надежная стратегия по множеству метрик:
- Доходность: Единственная стратегия с положительной общей (+4.5%) и годовой (+1.5%) доходностью.
- Скорректированная по риску доходность: Наивысшие коэффициенты Шарпа (2.62) и Сортино (4.25), наименьшая волатильность (0.52) и индекс язвы (0.03).
- Устойчивость к просадкам: Кратчайшая длительность просадки (52 дня) и наименьшая средняя просадка (0.0136).
- Хвостовое поведение: Сильный положительный коэффициент асимметрии (2.17) и высокий эксцесс (14.06) указывают на асимметричный потенциал роста.
- Эффективность сделок: Наивысший фактор прибыли (1.04) несмотря на самую низкую долю выигрышей (21.2%).
- Направленность: Полностью смещена в сторону длинных позиций (доля длинных = 1.0), с наивысшей положительной концентрацией (0.0032).
Фиксированный горизонт и Тройной барьер показывают отрицательную доходность и более слабые скорректированные по риску метрики, хотя Тройной Барьер обеспечивает лучший контроль волатильности на падениях и частоту сделок.
Заключение
Методология трендового сканирования доказывает свою ценность при правильной фильтрации, хотя ее влияние зависит от оценки. Не каждый трендовый сигнал стоит использовать в торговле — фокус на периодах высокой уверенности дает гораздо лучшие результаты.
Мы прошли путь от ошибочных временных меток и жестких меток к адаптивной, вероятностной системе, отражающей реальное торговое поведение. Ключевой вывод — методологический: согласуйте свои метки с торговой реальностью. Каждое проектное решение формирует то, чему учится ваша модель — ошибетесь, и сложность не спасет; сделаете правильно, и даже простые модели могут превосходить ожидания.
Будущее машинного обучения в финансах лежит не в более сложных алгоритмах, а в более умной подготовке данных. С этими основами мы готовы исследовать следующий рубеж: веса, выбор модели, кросс-валидацию и live-торговлю. Путешествие продолжается.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/19253
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Извините, но для меня цифры совсем не сходятся:
Общая доходность +4,53%, Шарп 2,62, Макс ДД 12,32%, Коэффициент выигрыша 21,2%, а затем:
Авг. выигрыш = 0,002342 VS Авг. проигрыш = -0,0016 -> Ожидание -0,000762 (-0,076% за сделку) - это примерно так.
В результате PR составляет 0,395, а не 1,038, и при количестве сделок 2665 общий доход составляет -203% (2665 * -0,000762).
Боже мой, вы все еще верите этим статьям о Министерстве обороны?
У меня был серьезный недостаток в способе расчета показателей эффективности, который я заметил только позже. Приношу свои извинения. Жаль, что у авторов нет возможности редактировать свои ошибки.
Не моё дело, чем занимается сервис. Да и переводчик у Вас вместо машинного обучения написал Министерство обороны)))
У меня был серьезный недостаток в способе расчета показателей эффективности, который я заметил только позже. Приношу свои извинения. Жаль, что у авторов нет возможности редактировать свои ошибки.