
Нейросети в трейдинге: Оценка риска по несогласованности представлений (Окончание)

Введение
Рынок редко становится непредсказуемым мгновенно. Сначала модель теряет способность правильно интерпретировать его состояние. Внешне всё может выглядеть вполне стабильно: котировки продолжают движение, индикаторы подтверждают сигнал, прогнозы формально остаются корректными. Но внутри системы постепенно накапливается расхождение между внутренним представлением модели и реальной структурой данных. Именно в этот момент начинает расти основной риск. Не как единичная ошибка, а как потеря устойчивости всей схемы интерпретации рынка.
Классические методы контроля моделей обычно опираются на одну доминирующую метрику — ошибку прогноза или качество реконструкции данных. На практике этого оказывается недостаточно. Рынок работает в разных режимах, и одна точка контроля неизбежно оставляет слепые зоны. Модель может показывать хороший прогноз и одновременно терять внутреннюю устойчивость. Возможна и обратная ситуация: ошибка возрастает, но структура поведения системы остаётся стабильной. Именно поэтому задача оценки риска оказывается значительно сложнее обычного контроля ошибки.
Фреймворк ReGEN-TAD предлагает более устойчивый подход к этой проблеме. В его основе лежит идея многоконтурной генеративной проверки состояния системы. Вместо одного сигнала контроля используется сразу несколько взаимосвязанных каналов наблюдения. Авторы фреймворка выделяют три ключевых выхода модели: первичный прогноз будущего состояния, уточнённый прогноз и реконструкцию входного окна данных.
Первичный прогноз оценивает способность модели объяснять ближайшую динамику рынка. Затем система анализирует структуру допущенной ошибки и формирует уточнённый прогноз. Такой подход позволяет модели не просто фиксировать отклонение, а учитывать характер самой ошибки. Параллельно выполняется реконструкция входного окна, которая проверяет, насколько текущие данные соответствуют внутренней норме модели. В результате система оценивает состояние рынка сразу с нескольких сторон, а не через единственную метрику качества.
Дальнейшее развитие архитектуры добавляет ещё один важный уровень анализа — контроль согласованности внутренних представлений. Различие между альтернативными интерпретациями рыночного состояния преобразуется в самостоятельный вычисляемый объект и начинает использоваться как источник сигнала риска. Риск рассматривается не как внешняя метка, а как следствие внутреннего состояния модели — прежде всего устойчивости её представлений.
В предыдущих работах мы последовательно переносили эту логику в прикладной торговый контекст. В первой статье была выполнена базовая адаптация ReGEN-TAD и подготовлена единая схема токенизированного представления данных. Во второй работе архитектура получила дальнейшее развитие. Риск был формализован как объект, существующий в том же пространстве представлений, что и исходные признаки. Для этого был введён специализированный блок генерации токена разности, который преобразует несогласованность между двумя внутренними представлениями в отдельный вычисляемый сигнал. На этой основе была построена основная вычислительная магистраль с параллельной обработкой данных через трансформерную и рекуррентную ветви. Это позволило одновременно анализировать глобальный контекст рынка и последовательную динамику временного ряда, сформировало основу дальнейшей системы.
Текущий этап продолжает развитие архитектуры и концентрируется на одном из центральных компонентов генеративного контура ReGEN-TAD — голове прогнозирования/реконструкции. Первичный прогноз, уточнённый прогноз и реконструкция рассматриваются не как три независимые архитектуры, а как режимы работы одного вычислительного модуля. Поэтому в данной работе реализуется универсальный объект головы прогнозирования/реконструкции, способный выполнять все три функции за счёт различной параметризации и конфигурации входных данных.
Такой подход позволяет сохранить целостность архитектуры, уменьшить дублирование вычислительных блоков и одновременно подготовить основу для дальнейшего объединения всех компонентов ReGEN-TAD в единый согласованный вычислительный конвейер оценки состояния рынка.

Модуль "головы прогнозирования"
После формирования компонентов базовой архитектуры ReGEN-TAD следующим логичным шагом становится реализация одного из ключевых компонентов генеративного контура — головы прогнозирования/реконструкции. Именно этот модуль отвечает за построение прогнозов и восстановление входного состояния. Фактически он становится универсальным вычислительным узлом, через который проходят сразу несколько режимов интерпретации данных.
Важно отметить, что в архитектуре ReGEN-TAD первичный прогноз, уточнённый прогноз и реконструкция не рассматриваются как полностью независимые механизмы. Несмотря на различие задач, все три режима используют близкую вычислительную логику: преобразование латентного представления в целевое пространство признаков. Поэтому реализация трёх отдельных архитектур здесь привела бы лишь к дублированию вычислений и усложнению сопровождения модели.
В данной работе строится единый модуль головы прогнозирования/реконструкции, способный работать в нескольких режимах. Конкретная роль определяется конфигурацией входных данных, параметрами запуска и способом интерпретации результата. В одном случае модуль формирует первичный прогноз будущего состояния. В другом — получает дополнительную информацию об ошибке и строит уточнённый прогноз. В режиме реконструкции тот же вычислительный контур восстанавливает структуру исходного входного окна.
Подобная схема делает архитектуру более компактной и согласованной. Все режимы используют единое пространство параметров и одинаковую логику преобразований. Это особенно важно для задач анализа финансовых временных рядов, где различные контуры модели должны интерпретировать рынок в максимально близкой системе представлений. Иначе отдельные компоненты начинают постепенно расходиться в трактовке состояния данных, что со временем снижает устойчивость всей системы.
С инженерной точки зрения такой подход упрощает дальнейшее развитие архитектуры. Изменение внутренней структуры головы автоматически распространяется на все режимы её работы. Это позволяет последовательно улучшать качество прогнозирования, реконструкции и анализа ошибки без необходимости синхронной поддержки нескольких независимых реализаций.
Практическая реализация головы прогнозирования/реконструкции оформлена в виде отдельного нейронного класса CNeuronReGENTADHead, унаследованного от CNeuronRevINDenormOCL. Такое наследование не случайно. Оно сразу задаёт связь с вычислительным контуром обратного преобразования и денормализации, что особенно важно для выхода модели в исходное пространство признаков.
class CNeuronReGENTADHead : public CNeuronRevINDenormOCL { protected: CLayer cFlow; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronReGENTADHead(void) {}; ~CNeuronReGENTADHead(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension_in, uint units_in, uint dimension_out, uint units_out, CNeuronBatchNormOCL* norm, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronReGENTADHead; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; virtual bool SetNorm(CNeuronBatchNormOCL* norm); };
Внутри класса выделен дополнительный модуль cFlow, отвечающий за локальную обработку сигнала перед формированием результата. Именно через него проходит внутренняя логика преобразования, которая позволяет использовать один и тот же класс в разных режимах работы.
Ключевая логика головы прогнозирования/реконструкции закладывается уже на этапе инициализации объекта. Фактически здесь формируется вся внутренняя вычислительная структура модуля.
bool CNeuronReGENTADHead::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint dimension_in, uint units_in, uint dimension_out, uint units_out, CNeuronBatchNormOCL *norm, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronRevINDenormOCL::Init(numOutputs, myIndex, open_cl, dimension_out * units_out, -1, NULL)) ReturnFalse; activation = None; if(!!norm) if(!SetNorm(norm)) ReturnFalse;
Сначала вызывается базовая инициализация родительского класса. На этом этапе голова получает механизм обратного преобразования и денормализации данных. Для финансовых временных рядов это особенно важно. Модель работает не в исходном пространстве цен, а в нормализованном представлении. Поэтому перед формированием результата требуется корректный возврат к реальному масштабу признаков.
Далее отключается функция активации. Это решение выглядит вполне логичным. Голова работает с восстановлением и прогнозированием непрерывных величин, где жёсткие нелинейные ограничения на выходе способны исказить структуру сигнала. В задачах анализа временных рядов подобное ограничение часто приводит к деградации качества реконструкции или к потере мелких изменений динамики.
Затем начинается построение внутреннего вычислительного контура cFlow, который фактически и образует основную архитектуру головы. Сначала поток данных переводится в удобное представление при помощи CNeuronTransposeOCL.
cFlow.Clear(); cFlow.SetOpenCL(OpenCL); //--- uint index = 0; CNeuronTransposeOCL* transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_in, dimension_in, optimization, iBatch) || !cFlow.Add(transp)) DeleteObjAndFalse(transp); transp.SetActivationFunction(None);
Транспонирование здесь играет техническую, но важную роль. Оно позволяет последующим свёрточным блокам работать вдоль нужного измерения данных. Для временных рядов это критично, поскольку модель должна отдельно анализировать структуру признаков и временную динамику.
Далее формируется первая сверточная последовательность.
index++; uint dim_hide = (MathMax(units_in, units_out) + 1) / 2; CNeuronSpikeConvBlock* conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, units_in, units_in, dim_hide, dimension_in, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, dim_hide, dim_hide, units_out, dimension_in, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv);
На этом этапе размерность постепенно преобразуется от units_in к промежуточному скрытому пространству dim_hide, а затем к units_out. Скрытая размерность вычисляется динамически. Такой подход делает архитектуру более гибкой. Промежуточное пространство автоматически адаптируется под размеры входа и выхода, не требуя ручной настройки для каждого режима работы.
После корректировки длины последовательности выполняется ещё одно транспонирование. Затем аналогичная схема повторяется уже для пространства признаков данных.
index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, dimension_in, units_out, optimization, iBatch) || !cFlow.Add(transp)) DeleteObjAndFalse(transp); transp.SetActivationFunction(None); dim_hide = (MathMax(dimension_in, dimension_out) + 1) / 2; index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, dimension_in, dimension_in, dim_hide, units_out, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv); index++; conv = new CNeuronSpikeConvBlock(); if(!conv || !conv.Init(0, index, OpenCL, dim_hide, dim_hide, dimension_out, units_out, 1, optimization, iBatch) || !cFlow.Add(conv)) DeleteObjAndFalse(conv); index++; transp = new CNeuronTransposeOCL(); if(!transp || !transp.Init(0, index, OpenCL, units_out, dimension_out, optimization, iBatch) || !cFlow.Add(transp)) DeleteObjAndFalse(transp); transp.SetActivationFunction(None); //--- return true; }
В результате внутри cFlow строится двухэтапный контур преобразования. Модель адаптирует пространство признаков и временную структуру. Такая схема хорошо согласуется с логикой ReGEN-TAD, где важно одновременно учитывать локальные особенности признаков и последовательную динамику временного ряда.
Механизм прямого прохода построен предельно последовательно и хорошо отражает общую архитектурную идею модуля. Метод feedForward не содержит сложной управляющей логики или разветвлённых сценариев обработки. Вместо этого весь вычислительный поток организован как линейное прохождение сигнала через внутренний контейнер cFlow.
На вход метод получает указатель на предыдущий нейронный слой NeuronOCL. Далее этот объект последовательно передаётся через все элементы внутреннего контура cFlow. Каждый следующий блок получает результат работы предыдущего слоя.
bool CNeuronReGENTADHead::feedForward(CNeuronBaseOCL *NeuronOCL) { CNeuronBaseOCL* prev = NeuronOCL; CNeuronBaseOCL* curr = NULL; for(int i = 0; i < cFlow.Total(); i++) { curr = cFlow[i]; if(!curr || !curr.FeedForward(prev)) ReturnFalse; prev = curr; }
Фактически cFlow здесь выступает как компактный вычислительный конвейер головы прогнозирования. При этом сама голова не знает деталей внутренней реализации отдельных блоков. Она лишь организует последовательное распространение сигнала через заранее собранный вычислительный граф. Такой подход делает архитектуру более гибкой и упрощает дальнейшую модификацию внутренних компонентов.
Отдельно стоит обратить внимание на завершающий этап.
return CNeuronRevINDenormOCL::feedForward(prev);
}
После прохождения через весь внутренний контур результат передаётся в родительский класс. Именно здесь выполняется обратное преобразование и денормализация выходных данных. Это важная часть общей схемы. Внутренние вычисления модели выполняются в нормализованном пространстве признаков, однако итоговый прогноз или реконструкция должны возвращаться в исходный масштаб данных.
Такая организация даёт ещё одно преимущество. Голова прогнозирования остаётся независимой от конкретного режима работы. Независимо от того, используется ли модуль для первичного прогноза, уточнения ошибки или реконструкции входного окна, сам вычислительный контур остаётся неизменным. Меняются только входные данные и интерпретация результата. Это позволяет использовать единый механизм обработки для всех трёх режимов ReGEN-TAD без дублирования архитектуры.
Объект верхнего уровня
Все рассмотренные ранее компоненты — токенизация входных данных, генерация токена разности, параллельные магистрали обработки и генеративные головы — не могут эффективно работать изолированно. Каждый из этих модулей решает только часть общей задачи. Лишь их совместная работа позволяет модели одновременно учитывать глобальный контекст рынка, последовательную динамику временного ряда и устойчивость собственных внутренних представлений.
Именно согласованность этих контуров и формирует полноценную систему оценки риска. Если один модуль фиксирует отклонение, а остальные продолжают интерпретировать рынок как стабильный, система постепенно начинает терять целостность восприятия рыночного состояния. Поэтому задача объекта верхнего уровня заключается не в простом объединении отдельных блоков, а в организации единого вычислительного процесса, внутри которого все компоненты работают в общей системе представлений.
Следующим логичным шагом становится построение объекта верхнего уровня, объединяющего все модули ReGEN-TAD в единый вычислительный конвейер. Именно здесь отдельные архитектурные элементы начинают взаимодействовать как согласованная система анализа рынка, а не как набор независимых вычислительных узлов.
Практическая реализация архитектуры оформлена в виде класса CNeuronReGENTAD, унаследованного от базового объекта CNeuronBaseOCL. Именно этот класс объединяет ранее реализованные компоненты в единую вычислительную систему.
class CNeuronReGENTAD : public CNeuronBaseOCL { protected: CNeuronReGENTADBackbone cBackbone; CLayer cHeads[3]; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL) override; virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL) override; virtual bool calcInputGradients(CNeuronBaseOCL *NeuronOCL) override; public: CNeuronReGENTAD(void) {}; ~CNeuronReGENTAD(void) {}; //--- virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch); //--- virtual bool Save(const int file_handle) override; virtual bool Load(const int file_handle) override; //--- virtual int Type(void) override const { return defNeuronReGENTAD; } virtual void SetOpenCL(COpenCLMy *obj) override; virtual void TrainMode(bool flag) override; virtual void SetActivationFunction(ENUM_ACTIVATION value) override { }; //--- virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau) override; virtual bool Clear(void) override; };
Основу архитектуры формируют два ключевых элемента. Объект cBackbone инкапсулирует основную магистраль обработки данных. Именно здесь выполняется параллельный анализ последовательности через трансформерную и рекуррентную ветви, формируются внутренние представления и вычисляется их согласованность. По сути cBackbone выступает центральным механизмом интерпретации состояния рынка.
Массив cHeads[3] содержит генеративные головы модели. Несмотря на наличие трёх независимых контуров обработки, архитектурно они используют один и тот же универсальный модуль прогнозирования/реконструкции, рассмотренный ранее. Различие между ними определяется режимом работы и конфигурацией входных данных. Один контур используется для построения первичного прогноза, второй — для уточнения ошибки, третий — для реконструкции входного состояния.
Такое разделение хорошо согласуется с исходной логикой ReGEN-TAD. cBackbone отвечает за формирование и анализ представлений, а генеративные головы — за проверку устойчивости этих представлений через прогнозирование и восстановление данных.
Сборка полной архитектуры ReGEN-TAD выполняется внутри метода инициализации. Именно здесь отдельные модули объединяются в единую вычислительную систему и получают общую схему взаимодействия.
bool CNeuronReGENTAD::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint &dimensions[], uint units_s, uint heads, uint stack_size, uint layers, uint embed_size, uint candidates, uint topK, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!cBackbone.Init(0, 0, open_cl, dimensions, units_s, heads, stack_size, layers, embed_size, candidates, topK, optimization_type, batch)) ReturnFalse;
Работа начинается с инициализации главной магистрали интерпретации рыночных данных. cBackbone формирует внутренние представления рынка, выполняет параллельную обработку через трансформерную и рекуррентную ветви и подготавливает embedding-пространство для дальнейшей генеративной обработки.
После этого управления передается родительскому классу.
if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, cBackbone.Neurons() + 3 * embed_size, optimization_type, batch)) ReturnFalse; activation = None;
Обратите внимание, что в данном случае порядок инициализации намеренно отличается от привычной схемы, использованной в ранее созданных объектах. Обычно сначала инициализируется родительский класс, после чего последовательно создаются внутренние модули. Здесь используется обратный подход: первым инициализируется объект cBackbone.
Такое решение связано с практическими особенностями архитектуры ReGEN-TAD. Модуль cBackbone формирует основное пространство внутренних представлений модели, и именно его конфигурация определяет итоговую размерность значительной части вычислительного контура. Предварительная инициализация позволяет сразу получить готовые размеры выходного пространства без дополнительного ручного пересчёта параметров.
После инициализации cBackbone размерность тензора результатов формируется напрямую: к размерности выходного пространства cBackbone добавляются три embedding-вектора отклонений, формируемые генеративными контурами по результатам прогнозирования и реконструкции данных. Такой подход упрощает сборку модели и одновременно снижает вероятность ошибок при согласовании размерностей между внутренними модулями.
Далее начинается подготовка генеративных голов. Каждый элемент массива cHeads представляет отдельный генеративный контур. Однако важно понимать, что все головы строятся вокруг одного универсального механизма прогнозирования/реконструкции. Для первых двух контуров создаётся одинаковая последовательность блоков.
for(uint i = 0; i < cHeads.Size(); i++) { cHeads[i].Clear(); cHeads[i].SetOpenCL(OpenCL); } //--- CNeuronReGENTADHead* head = NULL; CNeuronDifferenceTokenizer* diff = NULL; uint backbone_units = cBackbone.Neurons() / embed_size; uint index = 1; for(int i = 0; i < 2; i++) { head = new CNeuronReGENTADHead(); if(!head || !head.Init(0, index, OpenCL, embed_size, backbone_units, dimensions[0], units_s, cBackbone.GetNorm(), optimization, iBatch) || !cHeads[i].Add(head)) DeleteObjAndFalse(head); index++; diff = new CNeuronDifferenceTokenizer(); if(!diff || !diff.Init(0, index, OpenCL, head.Neurons(), embed_size, optimization, iBatch) || !cHeads[i].Add(diff)) DeleteObjAndFalse(diff); diff.SetActivationFunction(TANH); index++; }
Сначала формируется объект головы. Именно этот модуль выполняет прогнозирование или реконструкцию данных в зависимости от режима работы.
После головы подключается CNeuronDifferenceTokenizer — блок преобразования разницы между представлениями в отдельный embedding-вектор риска. Здесь хорошо видно развитие логики ReGEN-TAD: модель анализирует не только результат прогноза, но и структуру возникающего расхождения.
Для токенизатора используется активация TANH. Это позволяет стабилизировать диапазон значений токена разности и уменьшить влияние резких выбросов в пространстве представлений.
Третий контур строится несколько иначе. Перед головой добавляется дополнительный слой объединения.
CNeuronBaseOCL* neuron = new CNeuronBaseOCL(); if(!neuron || !neuron.Init(0, index, OpenCL, cBackbone.Neurons() + diff.Neurons(), optimization, iBatch) || !cHeads[2].Add(neuron)) DeleteObjAndFalse(neuron); neuron.SetActivationFunction(None);
Третий генеративный контур работает уже не только с представлением cBackbone, но и с ранее сформированным токеном разности. Фактически именно здесь появляется механизм уточняющего прогноза, который учитывает структуру предыдущей ошибки.
После объединения данных снова подключается универсальная голова прогнозирования/реконструкции и токенизатор разности.
index++; head = new CNeuronReGENTADHead(); if(!head || !head.Init(0, index, OpenCL, embed_size, backbone_units + 1, dimensions[0], units_s, cBackbone.GetNorm(), optimization, iBatch) || !cHeads[2].Add(head)) DeleteObjAndFalse(head); index++; diff = new CNeuronDifferenceTokenizer(); if(!diff || !diff.Init(0, index, OpenCL, head.Neurons(), embed_size, optimization, iBatch) || !cHeads[2].Add(diff)) DeleteObjAndFalse(diff); diff.SetActivationFunction(TANH); //--- return true; }
Таким образом архитектура сохраняет единый вычислительный принцип для всех генеративных контуров, но постепенно усложняет входное представление по мере продвижения сигнала через систему.
В результате метод инициализации формирует полный генеративный контур ReGEN-TAD. Модуль cBackbone строит внутреннее представление рынка, генеративные головы проверяют его устойчивость через прогнозирование и реконструкцию, а токенизаторы разности преобразуют возникающие расхождения в отдельные сигналы риска.
Как и в других вычислительных модулях архитектуры, объект верхнего уровня переопределяет методы прямого и обратного прохода. Однако в случае CNeuronReGENTAD эта логика становится существенно более многослойной. Модель уже не ведёт себя как обычная последовательная нейронная сеть. Метод прямого прохода организует взаимодействие нескольких генеративных контуров, каждый из которых анализирует состояние рынка под своим углом.
При этом важно учитывать ключевое ограничение реального торгового процесса. Модель работает в онлайн-режиме на потоковых финансовых данных. В такой постановке невозможно напрямую сравнивать первичный и уточнённый прогноз с фактическим будущим состоянием рынка в момент их генерации.
Это означает, что классическая схема ошибка относительно будущего в текущем шаге для двухшагового прогноза оказывается неприменимой. Мы не можем вычислить корректную разность между прогнозами и ещё не реализованным рыночным состоянием.
Однако у системы остаётся другое, более устойчивое окно наблюдения — предыдущий шаг. На каждой итерации уже известно, каким был прогноз на прошлом состоянии и чем фактически завершился соответствующий временной интервал. Это позволяет перенести логику обучения во времени.
Вместо немедленного сравнения с будущим состоянием модель оценивает качество прогнозов, сформированных на предыдущей итерации. Иными словами, перед обновлением основной магистрали на новых рыночных данных выполняется расчёт ошибки по уже реализованному прогнозу прошлого шага.
Таким образом, порядок операций принципиально смещается. Сначала происходит оценка и корректировка параметров модели на основе запаздывающей ошибки. И только после этого выполняется пересчёт основной магистрали на новом состоянии рынка.
Это критично для устойчивости обучения. Если сначала обновить cBackbone на новых данных, а затем применить градиенты от прошлого прогноза, они будут привязаны к уже изменённому внутреннему представлению. В результате такие градиенты теряют интерпретируемость и перестают корректно отражать причину ошибки.
Поэтому обновление весов в части прогнозирования выполняется до обработки нового входного окна. Модель фактически завершает один цикл обучения на предыдущем состоянии и только затем переходит к следующему шагу анализа рынка. Это обеспечивает временную согласованность градиентов и устойчивость онлайн-обучения в непрерывном потоке данных.
Работа начинается с прохождения сигнала через генеративный контур формирования первичного прогноза.
bool CNeuronReGENTAD::feedForward(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse; //--- Forecast 1 CNeuronBaseOCL* curr = NULL; CNeuronBaseOCL* prev = cBackbone.AsObject(); for(int i = 0; i < cHeads[1].Total(); i++) { curr = cHeads[1][i]; if(!curr || !curr.FeedForward(prev, NeuronOCL.getOutput())) ReturnFalse; prev = curr; }
На этом этапе голова получает одновременно внутреннее представление модели и целевое состояние. Это позволяет учитывать структуру реальных данных уже в момент формирования прогноза и сразу закладывать основу для вычисления отклонения.
После завершения первичного прогноза активируется второй генеративный контур — механизм уточнения. Здесь архитектура начинает работать принципиально иначе. Перед обработкой выполняется объединение двух пространств представлений.
//--- Forecast 2 curr = cHeads[2][0]; if(!curr || !Concat(cBackbone.getOutput(), prev.getOutput(), curr.getOutput(), cBackbone.Neurons(), prev.Neurons(), 1)) ReturnFalse; prev = curr; for(int i = 1; i < cHeads[2].Total(); i++) { curr = cHeads[2][i]; if(!curr || !curr.FeedForward(prev, NeuronOCL.getOutput())) ReturnFalse; prev = curr; }
К исходному представлению cBackbone добавляется эмбеддинг отклонения предыдущего прогноза. Таким образом модель учитывает не только состояние рынка, но и ошибку собственной интерпретации этого состояния. Именно так формируется уточняющий контур ReGEN-TAD.
Далее второй генеративный поток повторно проходит через голову прогнозирования/реконструкции и токенизатор разности. В результате формируется не просто прогноз, а структурированное представление собственной ошибки модели.
Особое значение имеет организация обратного прохода. В режиме обучения система сначала вычисляет ошибку уточнённого прогноза.
//--- Backprop if(bTrain) { //--- Forecast 2 curr = cHeads[2][-2]; float error = 0; if(!curr || !curr.calcOutputGradients(NeuronOCL.getOutput(), error)) ReturnFalse;
После этого градиенты последовательно распространяются через второй генеративный контур.
for(int i = cHeads[2].Total() - 3; i >= 0; i--) { curr = cHeads[2][i]; if(!curr || !curr.CalcHiddenGradients(cHeads[2][i + 1])) ReturnFalse; } for(int i = 1; i < cHeads[2].Total() - 1; i++) { curr = cHeads[2][i]; if(!curr || !curr.UpdateInputWeights(cHeads[2][i - 1])) ReturnFalse; }
Далее выполняется декомпозиция объединённого пространства признаков.
//--- Forecast 1 curr = cHeads[2][0]; prev = cHeads[1][-1]; if(!DeConcat(cBackbone.getPrevOutput(), prev.getGradient(), curr.getGradient(), cBackbone.Neurons(), prev.Neurons(), 1)) ReturnFalse; Deactivation(prev);
Это позволяет корректно разделить вклад ошибки между cBackbone и первичным прогнозом. По сути, система одновременно обучает как сам прогноз, так и механизм его уточнения.
Затем происходит перерасчёт первого генеративного контура. Здесь появляется ключевая особенность архитектуры: ошибка уточняющего прогноза агрегируется с ошибкой первичного прогноза.
curr = cHeads[1][-2]; if(!curr || !curr.CalcHiddenGradients(prev, NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) ReturnFalse; CBufferFloat* temp = curr.getGradient(); if(!curr.SetGradient(curr.getPrevOutput(), false) || !curr.calcOutputGradients(NeuronOCL.getOutput(), error) || !SumAndNormalize(temp, curr.getGradient(), temp, 1, false, 0, 0, 0, 1) || !curr.SetGradient(temp, false)) ReturnFalse;
Такой подход отражает базовую идею ReGEN-TAD — модель оптимизируется не под одну локальную метрику, а под согласованность нескольких взаимосвязанных представлений рынка.
for(int i = cHeads[1].Total() - 3; i >= 0; i--) { curr = cHeads[1][i]; if(!curr || !curr.CalcHiddenGradients(cHeads[1][i + 1], NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) ReturnFalse; }
После завершения генеративных контуров корректировки распространяются на cBackbone.
if(!cBackbone.CalcHiddenGradients(curr) || !SumAndNormalize(cBackbone.getGradient(), cBackbone.getPrevOutput(), cBackbone.getGradient(), 1, false, 0, 0, 0, 1)) ReturnFalse; if(!NeuronOCL.CalcHiddenGradients(cBackbone.AsObject())) ReturnFalse; if(!cBackbone.UpdateInputWeights(NeuronOCL)) ReturnFalse; prev = cBackbone.AsObject(); for(int i = 0; i < cHeads[1].Total(); i++) { curr = cHeads[1][i]; if(!curr || !curr.UpdateInputWeights(prev)) ReturnFalse; prev = curr; } }
На этом этапе внутренние представления модели начинают адаптироваться под согласованную структуру прогнозирования и анализа ошибки. Только после этого выполняется основной проход cBackbone.
//--- Backbone if(!cBackbone.FeedForward(NeuronOCL)) ReturnFalse;
Затем активируется контур реконструкции, который восстанавливает структуру входного окна и формирует дополнительный сигнал согласованности.
//--- Recover prev = cBackbone.AsObject(); for(int i = 0; i < cHeads[0].Total(); i++) { curr = cHeads[0][i]; if(!curr || !curr.FeedForward(prev, NeuronOCL.getOutput())) ReturnFalse; prev = curr; }
На финальном этапе все результаты объединяются в единое выходное пространство.
if(!Concat(cBackbone.getOutput(), cHeads[0][-1].getOutput(), cHeads[1][-1].getOutput(), cHeads[2][-1].getOutput(), Output, cBackbone.Neurons(), cHeads[0][-1].Neurons(), cHeads[1][-1].Neurons(), cHeads[2][-1].Neurons(), 1)) ReturnFalse; //--- return true; }
Итоговый результат включает представление cBackbone и три embedding-вектора отклонений, полученных из реконструкции, первичного прогноза и уточняющего прогноза. Именно эта совокупность становится основой для оценки состояния рынка и вычисления риска.
В методе прямого прохода мы фактически учитывали только часть ошибки, связанную с генеративными головами прогнозирования. Однако полная картина значительно шире. В системе присутствуют ещё реконструкция и общий контур согласованности, которые формируют дополнительный поток градиентов. Поэтому обратный проход в calcInputGradients устроен как поэтапное восстановление вкладов каждой части архитектуры. Сначала выполняется декомпозиция общего градиента на уровне результатов работы модуля.
bool CNeuronReGENTAD::calcInputGradients(CNeuronBaseOCL *NeuronOCL) { if(!NeuronOCL) ReturnFalse; //--- if(!cHeads[0][-1] || !cHeads[1][-1] || !cHeads[2][-1] || !DeConcat(cBackbone.getPrevOutput(), cHeads[0][-1].getGradient(), cHeads[1][-1].getGradient(), cHeads[2][-1].getGradient(), Gradient, cBackbone.Neurons(), cHeads[0][-1].Neurons(), cHeads[1][-1].Neurons(), cHeads[2][-1].Neurons(), 1)) ReturnFalse;
На этом этапе итоговая ошибка распределяется между 4 основными источниками: cBackbone, реконструкцией, первичным прогнозом и уточнённым прогнозом. Это важно, поскольку каждый из этих контуров интерпретирует одно и то же рыночное состояние по-разному, и их вклад в обучение должен быть разделён корректно.
Далее последовательно обрабатывается контур уточнённого прогноза. Градиенты проходят в обратном направлении через всю цепочку слоёв.
//--- Forecast 2 CNeuronBaseOCL* curr = cHeads[2][-1]; Deactivation(curr); for(int i = cHeads[2].Total() - 2; i >= 0; i--) { curr = cHeads[2][i]; if(!curr || !curr.CalcHiddenGradients(cHeads[2][i + 1], NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) ReturnFalse; }
Здесь модель восстанавливает причинно-следственную структуру ошибки уточнения, которая зависит как от текущего состояния, так и от предыдущего прогноза. После этого сигнал возвращается к первичному прогнозу, где ошибка уже комбинируется с результатом уточняющего контура.
//--- Forecast 1 curr = cHeads[2][0]; CNeuronBaseOCL* prev = cHeads[1][-1]; if(!DeConcat(cBackbone.getPrevOutput(), prev.getPrevOutput(), curr.getGradient(), cBackbone.Neurons(), prev.Neurons(), 1) || !SumAndNormalize(prev.getGradient(), prev.getPrevOutput(), prev.getGradient(), 1, false, 0, 0, 0, 1)) ReturnFalse; Deactivation(prev); for(int i = cHeads[1].Total() - 2; i >= 0; i--) { curr = cHeads[1][i]; if(!curr || !curr.CalcHiddenGradients(cHeads[1][i + 1], NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) ReturnFalse; }
Важно отметить момент объединения. Здесь происходит агрегация двух источников информации — ошибки первичного прогноза и уточняющего сигнала. Это отражает принцип ReGEN-TAD: модель обучается не по отдельным метрикам, а по согласованности последовательных интерпретаций одного и того же состояния рынка.
После этого выполняется обратное распространение в контур реконструкции.
//--- Recovery prev = cHeads[0][-1]; Deactivation(prev); curr = cHeads[0][-2]; if(!curr || !curr.CalcHiddenGradients(prev, NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) ReturnFalse; CBufferFloat* temp = curr.getGradient(); float error = 0; if(!curr.SetGradient(curr.getPrevOutput(), false) || !curr.calcOutputGradients(NeuronOCL.getOutput(), error) || !SumAndNormalize(temp, curr.getGradient(), temp, 1, false, 0, 0, 0, 1) || !curr.SetGradient(temp, false)) ReturnFalse; for(int i = cHeads[0].Total() - 3; i >= 0; i--) { curr = cHeads[0][i]; if(!curr || !curr.CalcHiddenGradients(cHeads[0][i + 1], NeuronOCL.getOutput(), NeuronOCL.getGradient(), (ENUM_ACTIVATION)NeuronOCL.Activation())) ReturnFalse; }
Этот блок играет особую роль: он восстанавливает структуру входного окна и тем самым фиксирует, насколько внутреннее представление модели соответствует исходным данным. Ошибка реконструкции затем частично возвращается в общее пространство градиентов.
Отдельного внимания заслуживает локальная корректировка внутри реконструкции. Она позволяет дополнительно стабилизировать обучение, учитывая отклонение восстановленного сигнала от исходного.
После завершения всех генеративных контуров градиенты сходятся в cBackbone.
if(!cBackbone.CalcHiddenGradients(curr) || !SumAndNormalize(cBackbone.getGradient(), cBackbone.getPrevOutput(), cBackbone.getGradient(), 1, false, 0, 0, 0, 1)) ReturnFalse;
Именно здесь происходит финальная агрегация всех потоков ошибки. Объект cBackbone получает суммарный сигнал, отражающий не только точность прогнозов, но и качество реконструкции и согласованность внутренних представлений.
Завершается обратный проход распространением градиента в слой исходных данных.
if(!NeuronOCL.CalcHiddenGradients(cBackbone.AsObject())) ReturnFalse; //--- return true; }
Таким образом, calcInputGradients формирует вторую, недостающую часть обучения — полный цикл согласованной оптимизации всех контуров ReGEN-TAD. Если прямой проход отвечает за формирование и взаимодействие представлений, то обратный проход обеспечивает их согласованную коррекцию с учётом реконструкции, прогнозирования и уточнения ошибки в единой структуре.
В результате CNeuronReGENTAD выступает полноценным координатором всей архитектуры. Фактически именно этот уровень превращает отдельные архитектурные элементы ReGEN-TAD в целостную рабочую систему. Здесь модель начинает анализировать рынок через совокупность взаимосвязанных представлений, каждое из которых проверяет устойчивость остальных.
Тестирование
После сборки вычислительного контура мы переходим к самому чувствительному этапу — обучению и тестированию модели. До этого момента архитектура существовала как система преобразований данных. Теперь она начинает жить в двух режимах: сначала в замкнутом историческом пространстве, затем — в потоке реального рынка.
Первый шаг — офлайн-обучение на архиве котировок EURUSD H1 за 2025 год. Здесь рынок ещё застывший в своей истории: он уже известен, измерен и не меняется во времени. Для модели это наиболее спокойная, но при этом крайне важная среда. Каждый бар проходит через ReGEN-TAD как элемент единой последовательности, где ценовые движения превращаются в токенизированное представление и проходят через весь вычислительный контур.
На этом этапе система не просто подбирает веса под исторические данные. Она выстраивает внутреннюю геометрию переходов между состояниями рынка. Модель начинает различать, как рынок ведёт себя в разных режимах: где он ускоряется, где затухает, где переходит в боковое движение. Формируется своего рода динамическая карта поведения, основанная на повторяемости структурных реакций.
Именно здесь закладываются базовые закономерности: реакция на импульсы, поведение после флетов, изменение контекста при смене рыночного режима. Это попытка зафиксировать логику переходов между состояниями, которая потом будет проверяться уже в условиях неопределённости.
Далее система переходит ко второму этапу — онлайн-обучению в тестере MetaTrader 5. И здесь происходит принципиальный сдвиг. Рынок перестаёт быть архивом и превращается в непрерывный поток данных. Каждый новый бар больше не является частью фиксированной последовательности — он становится текущим состоянием системы, которое необходимо интерпретировать и одновременно использовать для корректировки модели.
В этом режиме каждый проход через архитектуру ReGEN-TAD выполняет двойную функцию. С одной стороны, модель формирует прогноз и анализирует структуру текущего состояния. С другой — немедленно корректирует собственные внутренние представления на основе наблюдаемого отклонения. Последовательность начинает жить как поток: обновляется sequence-логика, адаптируется контекст, перестраиваются сценарные зависимости между состояниями рынка.
Финальный этап — тестирование на данных января–марта 2026 года — выполняет роль стресс-проверки всей архитектуры. Здесь модель сталкивается с новыми рыночными режимами, которые уже не обязаны повторять поведение обучающего периода. Именно в таких условиях проявляется устойчивость всей системы: насколько хорошо она удерживает внутреннюю согласованность, и насколько гибко реагирует на смещение рыночной структуры без разрушения ранее выученных закономерностей.
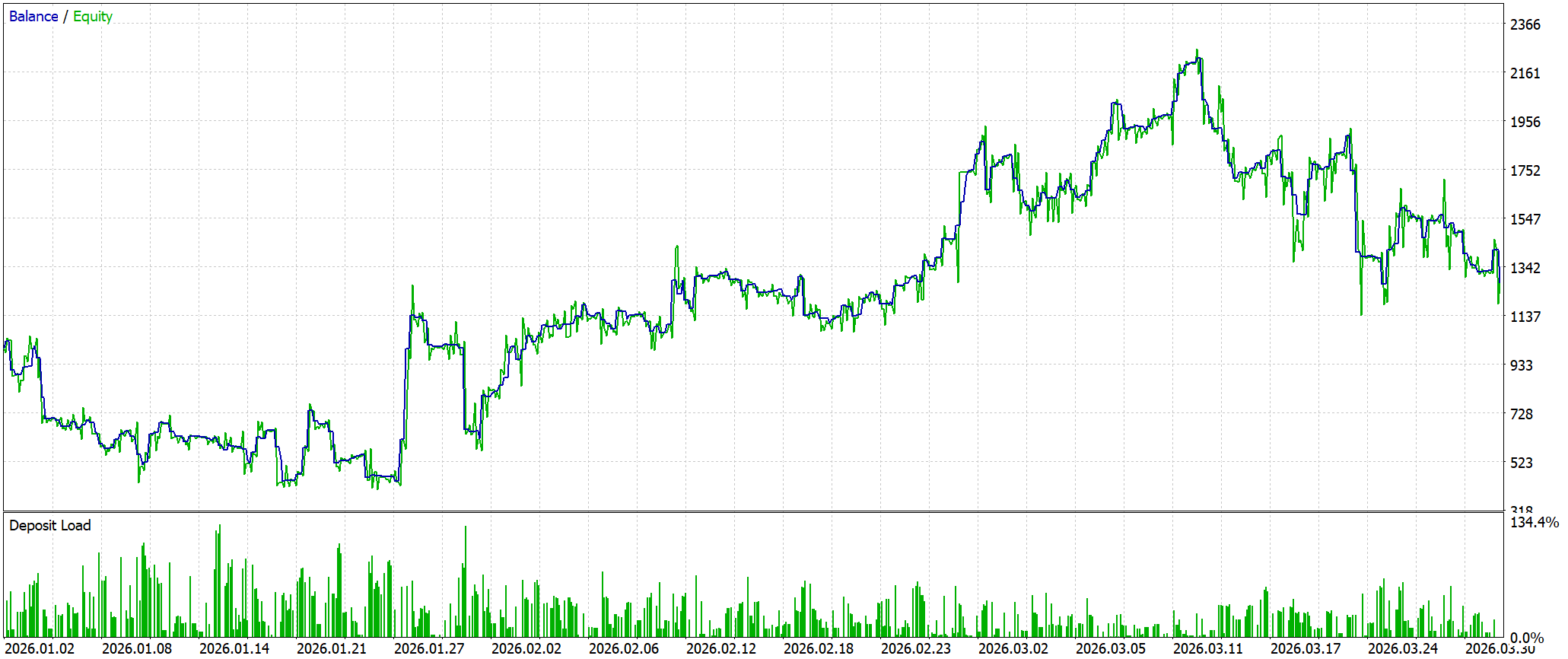
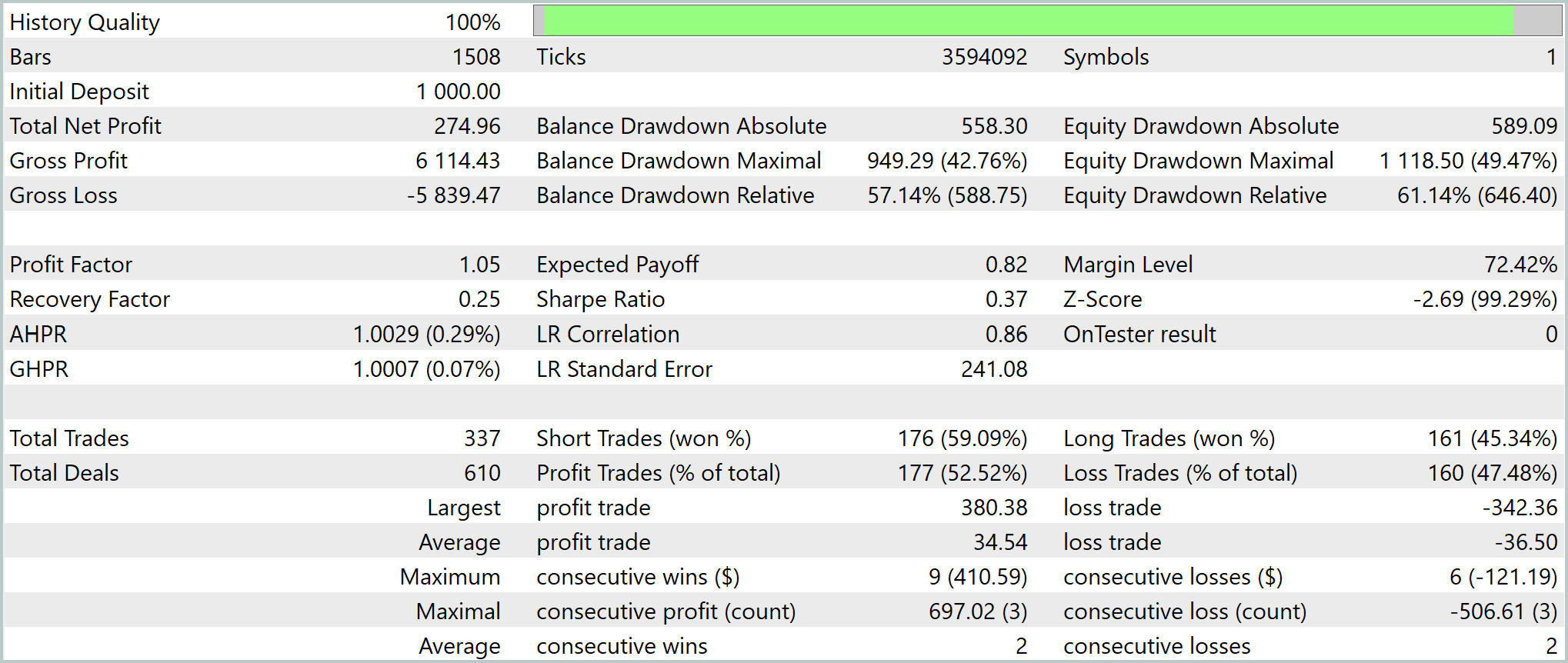
По результатам тестирования модель демонстрирует формирование рабочего, но пока ещё нестабильного торгового преимущества. Она завершает тест с итоговой прибылью +274.96 USD при стартовом депозите 1000.0 USD, что соответствует доходности около 27.5%. Формально результат положительный, но кривая капитала ведёт себя неровно: рост чередуется с просадками, а часть прибыли периодически возвращается рынку.
По качеству торговой логики система остаётся на границе устойчивости. Profit factor 1.05 показывает почти полное равновесие между валовой прибылью (6114.43 USD) и убытком (−5839.47 USD). Средняя прибыльная сделка составляет 34.54 USD, тогда как средний убыток — 36.50 USD. Баланс почти симметричный, но с небольшим смещением в сторону потерь. Именно это и съедает часть преимущества, не давая системе закрепиться в устойчивом положительном ожидании, несмотря на общее количество прибыльных сделок (52.52%).
Риск-профиль остаётся ключевым ограничением системы. Стратегия периодически работает в режиме глубокого капитального стресса. Тем не менее внутри поведения модели уже прослеживается структура: LR correlation 0.86, Z-score −2.69 с вероятностью 99.29% и асимметрия направлений (long win rate 45.34% против 59.09% у short). Это фиксирует важный факт — система формирует устойчивые локальные паттерны, но пока не умеет стабильно масштабировать их в низкорисковый доход. В текущем виде это рабочий прототип ReGEN-TAD с проявленным, но ещё не стабилизированным торговым преимуществом.
Заключение
Мы завершили адаптацию фреймворка ReGEN-TAD к прикладному финансовому контексту и собрали его в виде работающего вычислительного контура, ориентированного на онлайн-обработку рыночных данных. Архитектура прошла путь от теоретически описанной многоконтурной генеративной схемы до инженерной реализации. Ключевые компоненты — прогнозирование, уточнение и реконструкция — объединены в единый поток обработки.
В ходе работы была реализована полная цепочка взаимодействия модулей. Отдельное внимание было уделено корректной организации прямого и обратного прохода в условиях онлайн-обучения. Модель опирается на запаздывающую, но доступную обратную связь.
Результаты тестирования подтверждают, что система уже формирует устойчивую, хотя ещё нестабильную торговую структуру. Модель демонстрирует положительную доходность и статистически значимое отклонение от случайного поведения, но при этом сохраняет высокий уровень риска и выраженные просадки капитала. Это указывает на наличие рабочего преимущества, которое пока не стабилизировано в достаточной степени.
Текущий этап можно считать завершённой инженерной адаптацией ReGEN-TAD: архитектура функционирует как единый механизм анализа рынка, однако дальнейшая работа смещается в сторону повышения устойчивости, снижения риска и повышения согласованности между представлениями, формируемыми генеративными контурами.
Ссылки
- An Interpretable Generative Framework for Anomaly Detection in High-Dimensional Financial Time Series
- Другие статьи серии
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Study.mq5 | Советник | Советник офлайн-обучения моделей |
| 2 | StudyOnline.mq5 | Советник | Советник онлайн-обучения моделей |
| 3 | Test.mq5 | Советник | Советник для тестирования модели |
| 4 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы и архитектуры моделей |
| 5 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 6 | NeuroNet.cl | Библиотека | Библиотека кода OpenCL-программы |
Проект представлен на forge.mql5.io/dng.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования