
Машинное обучение и Data Science (Часть 45): Прогнозирование временных рядов на форексе с моделью PROPHET от Facebook

Содержание
- Что представляет собой модель Prophet
- Особенности модели Prophet
- Реализация модели Prophet в Python
- Добавление праздников в модель Prophet
- Торговый робот для MetaTrader 5 на основе модели Prophet
- Заключение
Что представляет собой модель Prophet
Модель Prophet — это инструмент с открытым исходным кодом для прогнозирования временных рядов, разработанный компанией Meta (ранее Facebook). Он предназначен для получения точных и удобных в использовании прогнозов для бизнес- и аналитических задач, особенно на временных рядах с выраженной сезонностью и трендами.
Данная модель была представлена Facebook (S. J. Taylor и Benjamin Letham, 2018) и изначально предназначалась для прогнозирования ежедневных данных с недельной и годовой сезонностью, а также с учетом праздничных эффектов. Позднее она была расширена для работы с другими типами сезонных данных. Наилучшие результаты достигаются на временных рядах с выраженной сезонностью и достаточным количеством исторических данных.
Основные термины:
- Trend (тренд) — показывает тенденцию данных к росту или снижению на протяжении длительного периода и отфильтровывает сезонные колебания.
- Seasonality (сезонность) — это колебания, происходящие в течение короткого периода и недостаточно выраженные, чтобы считаться трендом.

В этой статье мы разберем и реализуем данную модель на данных Forex и посмотрим, как она может помочь в понимании рыночных данных. Но сначала подробно рассмотрим саму модель.
Особенности модели Prophet
Модель Prophet можно рассматривать как нелинейную регрессионную модель, задаваемую формулой:
![]()
Рисунок 01
где:
-
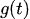 — кусочно-линейный тренд (или компонент роста)
— кусочно-линейный тренд (или компонент роста) -
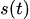 — различные сезонные компоненты
— различные сезонные компоненты -
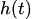 — учитывает эффекты праздников, а
— учитывает эффекты праздников, а 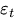 — случайная ошибка белого шума.
— случайная ошибка белого шума.
1. Компонент тренда
Компонент тренда ![]() допускает наличие точек изменения (changepoints), которые автоматически определяются, если не заданы вручную. Эти точки представляют моменты времени, в которых тренд может измениться (например, резкий рост или падение).
допускает наличие точек изменения (changepoints), которые автоматически определяются, если не заданы вручную. Эти точки представляют моменты времени, в которых тренд может измениться (например, резкий рост или падение).
Также можно использовать логистическую модель роста вместо линейной, что вводит параметр емкости (cap) для моделирования эффектов насыщения. Это полезно, когда рост замедляется после достижения определенного естественного предела.
2. Сезонность
В модели Prophet сезонность ![]() моделируется с использованием рядов Фурье.
моделируется с использованием рядов Фурье.
По умолчанию:
- Порядок 10 используется для годовой сезонности
- Порядок 3 используется для недельной сезонности
Эти члены Фурье помогают модели улавливать повторяющиеся сезонные эффекты.
3. Эффекты праздников
Эффекты праздников ![]() включаются в модель в виде фиктивных переменных (one-hot encoding), что позволяет корректировать прогнозы вблизи особых дат, которые исторически вызывали отклонения в поведении данных. Например, экономические новости или государственные праздники.
включаются в модель в виде фиктивных переменных (one-hot encoding), что позволяет корректировать прогнозы вблизи особых дат, которые исторически вызывали отклонения в поведении данных. Например, экономические новости или государственные праздники.
Вся модель оценивается в рамках байесовского подхода, что позволяет автоматически определять точки изменения и другие параметры модели.
Хотя базовая аддитивная декомпозиционная модель выглядит простой, вычисления внутри формулы являются весьма сложными с математической точки зрения. Если вы не понимаете, что делаете, модель может давать неверные прогнозы.
Prophet предоставляет два подхода к моделированию.
- Кусочно-линейная модель роста (по умолчанию)
- Логистическая модель
01. Кусочно-линейная модель
Эта модель используется в Prophet по умолчанию. Она предполагает, что тренд данных следует линейной траектории, но может изменяться в определенные моменты времени (точки изменения). Эта модель подходит для данных с устойчивым ростом или снижением, возможно с резкими сдвигами.
Данный подход описывается формулой на Рисунке 01.
02. Логистическая модель
Эта модель подходит для данных с насыщаемым ростом, то есть когда сначала наблюдается быстрый рост, а затем он замедляется по мере приближения к максимальной емкости или пределу. Такое поведение часто встречается в реальных системах с естественными или бизнес-ограничениями (например, рост числа пользователей на насыщенном рынке).
Логистическая модель включает параметр емкости, определяющий верхний предел.
Данный подход описывается следующей формулой:
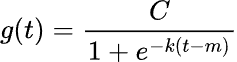
Изображение 02
где:
![]() — предельная емкость,
— предельная емкость, ![]() — скорость роста, а
— скорость роста, а ![]() — параметр смещения.
— параметр смещения.
Реализация модели Prophet в Python
Используя данные EURUSD с часового графика, попробуем определить тренд, сезонность и спрогнозировать будущие значения с помощью данной модели.
Первое, что необходимо сделать — установить все зависимости из файла requirements.txt, приложенного в конце статьи.
pip install -r requirements.txt
Импорт.
import pandas as pd import numpy as np import MetaTrader5 as mt5 import matplotlib.pyplot as plt import seaborn as sns from prophet import Prophet plt.style.use('fivethirtyeight') sns.set_style("darkgrid")
Let us get the data from MetaTrader 5.
if not mt5.initialize(r"c:\Program Files\MetaTrader 5 IC Markets (SC)\terminal64.exe"): print("Failed to initialize MetaTrader5. Error = ",mt5.last_error()) mt5.shutdown() symbol = "EURUSD" timeframe = mt5.TIMEFRAME_H1 rates = mt5.copy_rates_from_pos(symbol, timeframe, 1, 10000) if rates is None: print(f"Failed to copy rates for symbol={symbol}. MT5 Error = {mt5.last_error()}")
Модель Prophet сильно зависит от признака datetime (временной метки). Этот признак обязателен для работы модели.
После получения данных (котировок) из MetaTrader 5 преобразуем их в объект Pandas DataFrame. Затем столбец времени, содержащий время в секундах, преобразуем в формат datetime.
rates_df = pd.DataFrame(rates) # we convert rates object to a dataframe rates_df["time"] = pd.to_datetime(rates_df["time"], unit="s") # we convert the time from seconds to datatime rates_df
Результаты.
| time | open | high | low | close | tick_volume | spread | real_volume | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-10 23:00:00 | 1.06849 | 1.06873 | 1.06826 | 1.06846 | 762 | 0 | 0 |
| 1 | 2023-11-13 00:00:00 | 1.06828 | 1.06853 | 1.06779 | 1.06841 | 1059 | 10 | 0 |
| 2 | 2023-11-13 01:00:00 | 1.06854 | 1.06907 | 1.06854 | 1.06906 | 571 | 0 | 0 |
| 3 | 2023-11-13 02:00:00 | 1.06904 | 1.06904 | 1.06822 | 1.06839 | 1053 | 0 | 0 |
| 4 | 2023-11-13 03:00:00 | 1.06840 | 1.06886 | 1.06811 | 1.06867 | 1204 | 0 | 0 |
Модель Prophet является одномерной и требует только два признака в DataFrame: признак datetime с именем ds (date stamp) и целевую переменную с именем y.
Для начала создадим простой датасет из данных, полученных из MetaTrader 5. Он будет содержать два признака: время time и волатильность volatility. Именно эти данные мы будем использовать далее в модели Prophet.
prophet_df = pd.DataFrame({
"time": rates_df["time"],
"volatility": rates_df["high"] - rates_df["low"]
}).set_index("time")
prophet_df Волатильность (рассчитанная как разница между максимальной и минимальной ценой) выступает в качестве целевой переменной.
В отличие от других моделей прогнозирования временных рядов, таких как ARIMA и VAR (рассмотренных ранее), которые требуют стационарности целевой переменной, у модели Prophet нет такого ограничения. Она может работать и с нестационарными данными. Однако все модели машинного обучения, как правило, лучше работают со стационарными переменными, поскольку их легче обучать (у них постоянные среднее значение, дисперсия и стандартное отклонение).
В данном случае была выбрана стационарная целевая переменная, чтобы упростить задачу.
Теперь построим график DataFrame и проанализируем признаки.
# Color pallete for plotting color_pal = ["#F8766D", "#D39200", "#93AA00", "#00BA38", "#00C19F", "#00B9E3", "#619CFF", "#DB72FB"] prophet_df.plot(figsize=(7,5), color=color_pal, title="Volatility (high-low) against time", ylabel="volatility", xlabel="time")
Результаты.
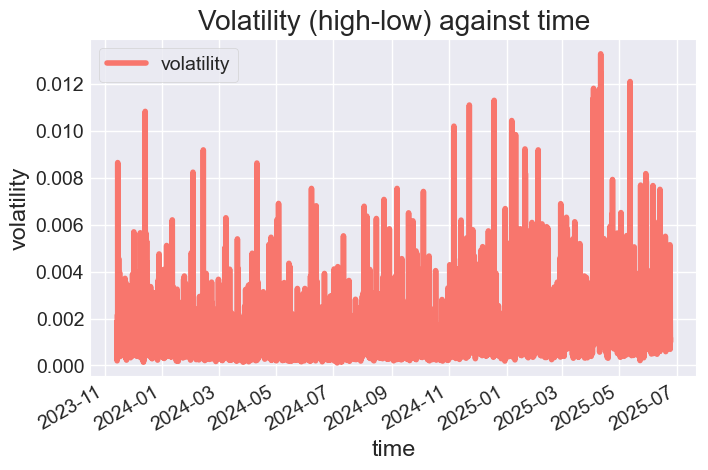
Рисунок 03
При желании мы можем сформировать признаки X и y для оценки влияния временных характеристик на волатильность рынка.
def create_features(df, label=None): """ Creates time series features from datetime index. """ df = df.copy() df['date'] = df.index df['hour'] = df['date'].dt.hour df['dayofweek'] = df['date'].dt.dayofweek df['quarter'] = df['date'].dt.quarter df['month'] = df['date'].dt.month df['year'] = df['date'].dt.year df['dayofyear'] = df['date'].dt.dayofyear df['dayofmonth'] = df['date'].dt.day df['weekofyear'] = df['date'].dt.isocalendar().week X = df[['hour','dayofweek','quarter','month','year', 'dayofyear','dayofmonth','weekofyear']] if label: y = df[label] return X, y return X X, y = create_features(prophet_df, label='volatility') features_and_target = pd.concat([X, y], axis=1)
Результаты.
| hour | dayofweek | quarter | month | year | dayofyear | dayofmonth | weekofyear | volatility | |
|---|---|---|---|---|---|---|---|---|---|
| time | |||||||||
| 2023-11-13 16:00:00 | 16 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00122 |
| 2023-11-13 17:00:00 | 17 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00179 |
| 2023-11-13 18:00:00 | 18 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00186 |
| 2023-11-13 19:00:00 | 19 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00125 |
| 2023-11-13 20:00:00 | 20 | 0 | 4 | 11 | 2023 | 317 | 13 | 46 | 0.00150 |
Можем построить графики этих признаков относительно волатильности для ручного анализа.
sns.pairplot(features_and_target.dropna(), hue='hour', x_vars=['hour','dayofweek', 'year','weekofyear'], y_vars='volatility', height=5, plot_kws={'alpha':0.45, 'linewidth':0.5} ) plt.suptitle(f"{symbol} close prices by Hour, Day of Week, Year, and Week") plt.show()
Результаты.

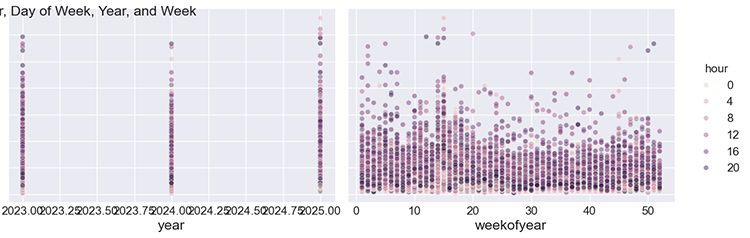
Рисунок 04
Видно, что час, день недели, год и неделя года оказывают влияние на волатильность в каждый час графика. Это дает нам уверенность в том, что данные подходят для использования в модели Prophet.
Обучение модели Prophet
Начнем с разделения данных на обучающую и тестовую выборки.
split_date = '01-Jan-2025' # threshold date between training and testing samples, all values after this date are for testing prophet_df_train = prophet_df.loc[prophet_df.index <= split_date].copy().reset_index().rename(columns={"time": "ds", "volatility": "y"}) prophet_df_test = prophet_df.loc[prophet_df.index > split_date].copy().reset_index().rename(columns={"time": "ds", "volatility": "y"})
Обучаем модель Prophet на обучающих данных.
model = Prophet() model.fit(prophet_df_train)
После обучения модели обычно нужно проверить ее эффективность на данных вне обучающей выборки, то есть на информации, которую модель ранее не видела. В отличие от других моделей, Prophet возвращает прогнозы несколько иначе.
test_fcst = model.predict(df=prophet_df_test)
Вместо вектора предсказаний модель возвращает полный датафрейм, которые содержит различные признаки, отражающие прогнозы и состояние модели.
test_fcst.head()
Результаты.
ds trend yhat_lower yhat_upper trend_lower trend_upper additive_terms additive_terms_lower additive_terms_upper daily daily_lower daily_upper weekly weekly_lower weekly_upper multiplicative_terms multiplicative_terms_lower multiplicative_terms_upper yhat 0 2025-01-02 00:00:00 0.001674 0.000168 0.001993 0.001674 0.001674 -0.000571 -0.000571 -0.000571 -0.000510 -0.000510 -0.000510 -0.000061 -0.000061 -0.000061 0.0 0.0 0.0 0.001102 1 2025-01-02 01:00:00 0.001674 0.000161 0.001977 0.001674 0.001674 -0.000614 -0.000614 -0.000614 -0.000556 -0.000556 -0.000556 -0.000057 -0.000057 -0.000057 0.0 0.0 0.0 0.001060 2 2025-01-02 02:00:00 0.001674 0.000337 0.002123 0.001674 0.001674 -0.000483 -0.000483 -0.000483 -0.000430 -0.000430 -0.000430 -0.000054 -0.000054 -0.000054 0.0 0.0 0.0 0.001191
В следующей таблице приведено значение некоторых столбцов (признаков), возвращаемых методом predict.
| Столбец | Значение |
|---|---|
| ds | Дата и время (timestamp) прогнозируемой точки |
| yhat | Итоговое прогнозируемое значение (предсказание модели) |
| yhat_lower, yhat_upper | Нижняя и верхняя границы доверительного интервала (80% или 95%) для yhat |
| trend | Значение компонента тренда в момент времени ds (например, медленный рост или спад) |
| trend_lower, trend_upper | Доверительный интервал компонента тренда |
| additive_terms | Сумма всех сезонных и праздничных компонентов в момент ds (например, дневные + недельные + праздники) |
| additive_terms_lower, additive_terms_upper | Границы для аддитивных компонентов |
| daily | Дневная сезонность (например, внутридневные почасовые паттерны) |
| daily_lower, daily_upper | Доверительный интервал дневной компоненты |
| weekly | Недельная сезонность (например, различия между выходными и буднями) |
| weekly_lower, weekly_upper | Доверительный интервал недельной компоненты |
Наиболее важными для нас являются столбцы: yhat, yhat_lower, yhat_upper, trend, сезонные компоненты (daily, weekly, yearly), праздники (если есть) и границы ошибок для компонентов (*_lower and *_upper) columns.
Построим график фактических значений и прогнозов для тестовой выборки, а также добавим фактические значения обучающей выборки.
f, ax = plt.subplots(figsize=(7,5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') # plot actual values from the testing sample in red fig = model.plot(test_fcst, ax=ax) # plot the forecasts
Результат.
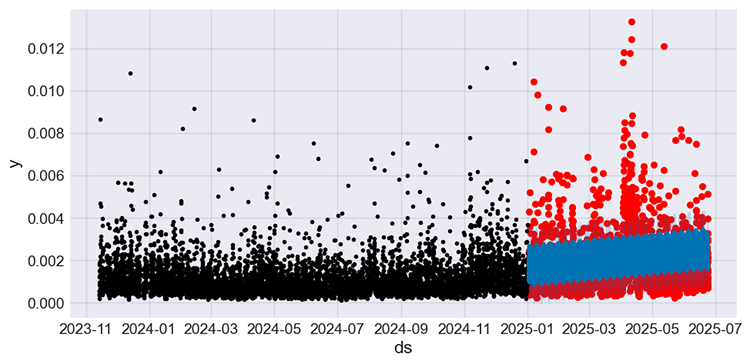
Рисунок 05
Значения, показанные черным цветом, соответствуют обучающей выборке, красным — фактические значения тестовой выборки, а синим — прогнозы модели для тестовой выборки.
По данному графику сложно оценить эффективность модели. Давайте построим отдельные графики для фактических значений и прогнозов на тестовой выборке.
Оценим модель на данных за январь 2025 года — первый месяц тестовой выборки.
f, ax = plt.subplots(figsize=(7, 5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') fig = model.plot(test_fcst, ax=ax) ax.set_xbound( lower=pd.to_datetime("2025-01-01"), # starting data on the x axis upper=pd.to_datetime("2025-02-01")) # ending data on the x axis ax.set_ylim(0, 0.005) plot = plt.suptitle("January 2025, Actual vs Forecasts")
Результаты.
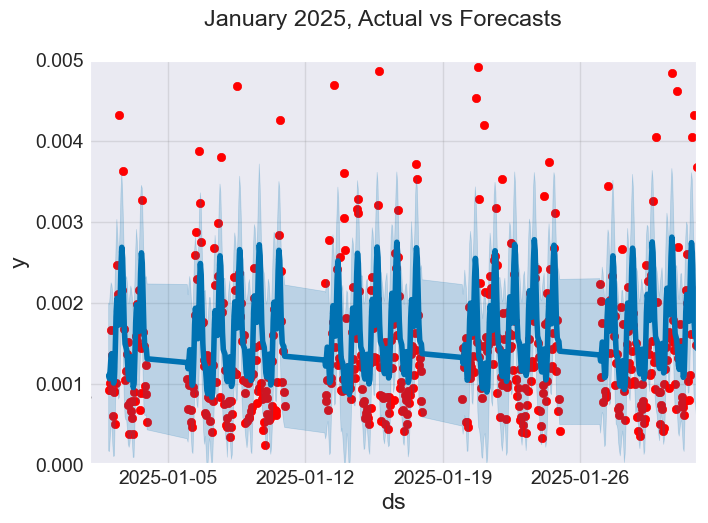
Рисунок 06
Судя по графику выше, модель Prophet в некоторых случаях делает верные прогнозы, однако плохо справляется с выбросами в данных.
При желании можно провести более детальный анализ, сравнив фактические значения с прогнозами модели за первую неделю января (с 1 по 8 января).
f, ax = plt.subplots(figsize=(9, 5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') fig = model.plot(test_fcst, ax=ax) ax.set_xbound( lower=pd.to_datetime("2025-01-01"), upper=pd.to_datetime("2025-01-08")) ax.set_ylim(0, 0.005) plot = plt.suptitle("January 01-08, 2025. Actual vs Forecasts")
Результаты.
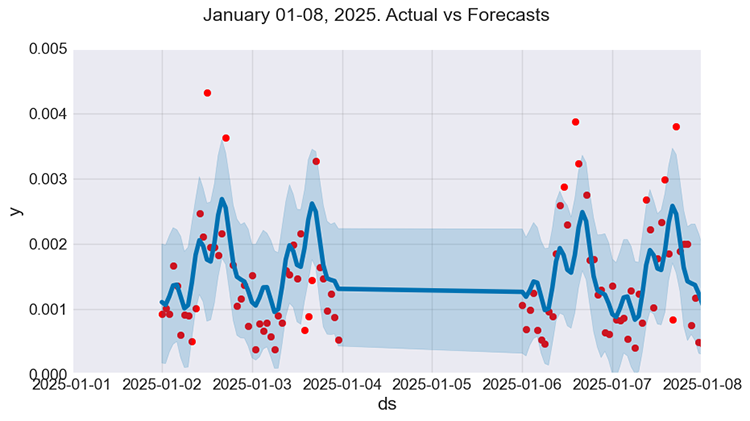
Рисунок 07
Результат выглядит значительно лучше. Тем не менее, хотя модель улавливает определенные закономерности, ее прогнозы не слишком близки к фактическим значениям. А ведь от регрессионных моделей нам нужно именно это.
Тем не менее, модель демонстрирует неплохую обобщающую способность.
Давайте оценим её с использованием метрик качества.
import sklearn.metrics as metric def forecast_accuracy(forecast, actual): # Convert to numpy arrays if they aren't already forecast = np.asarray(forecast) actual = np.asarray(actual) metrics = { 'mape': metric.mean_absolute_percentage_error(actual, forecast), 'me': np.mean(forecast - actual), # Mean Error 'mae': metric.mean_absolute_error(actual, forecast), 'mpe': np.mean((forecast - actual) / actual), # Mean Percentage Error 'rmse': metric.root_mean_squared_error(actual, forecast), 'minmax': 1 - np.mean(np.minimum(forecast, actual) / np.maximum(forecast, actual)), "r2_score": metric.r2_score(forecast, actual) } return metrics results = forecast_accuracy(test_pred, prophet_df_test["y"]) for metric_name, value in results.items(): print(f"{metric_name:<10}: {value:.6f}")
Результаты.
mape : 0.603277 me : 0.000130 mae : 0.000829 mpe : 0.430299 rmse : 0.001221 minmax : 0.339292 r2_score : -4.547775
В данном случае нас интересует метрика MAPE (Mean Absolute Percentage Error). Значение около 0.6 означает, что в среднем прогнозы модели отклоняются от фактических значений на 60%. Проще говоря, модель делает крайне неточные прогнозы и подвержена значительным ошибкам.
Добавление праздников в модель Prophet
Модель Prophet изначально разработана с учетом того, что в любых данных могут присутствовать события, вызывающие аномальные изменения во временных рядах — такие события называются праздниками.
В реальном мире праздники могут оказывать нерегулярное влияние на бизнес-данные, например:
- Государственные праздники (например, Новый год, Рождество)
- Бизнес-события (например, Черная пятница, запуск продукта)
- Финансовые события (например, заявления центральных банков, конец квартала)
- Локальные события (например, выборы, погодные катаклизмы)
Эти дни не следуют регулярной сезонной структуре, однако повторяются — ежегодно, ежеквартально, ежедневно и т.д.
В финансовых (торговых) данных экономические новости можно рассматривать как праздники, поскольку они вызывают аналогичные эффекты. Это может помочь модели решить текущую проблему — неспособность корректно учитывать экстремальные значения.
Как видно из Рисунка 01 с формулой модели Prophet, добавление компонента праздников делает модель более полной, поскольку праздники являются одной из ключевых составляющих формулы.
Для этого необходимо собрать новости — будем делать это на MQL5.
Название файла: OHLC + News.mq5
input datetime start_date = D'01.01.2023'; input datetime end_date = D'24.6.2025'; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; MqlRates rates[]; struct news_data_struct { datetime time[]; //News release time double open[]; //Candle opening price double high[]; //Candle high price double low[]; //Candle low price double close[]; //Candle close price string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value void Resize(uint size) { ArrayResize(time, size); ArrayResize(open, size); ArrayResize(high, size); ArrayResize(low, size); ArrayResize(close, size); ArrayResize(name, size); ArrayResize(sector, size); ArrayResize(importance, size); ArrayResize(actual, size); ArrayResize(forecast, size); ArrayResize(previous, size); } } news_data; //+------------------------------------------------------------------+ //| Script program start function | //+------------------------------------------------------------------+ void OnStart() { //--- if (!ChartSetSymbolPeriod(0, Symbol(), timeframe)) return; SaveNews(StringFormat("%s.%s.OHLC + News.csv",Symbol(),EnumToString(timeframe))); } //+------------------------------------------------------------------+ //| | //| The function which collects news alongsided OHLC values and | //| saves the data to a CSV file | //| | //+------------------------------------------------------------------+ void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price information from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI|FILE_COMMON,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
После сбора новостей внутри функции SaveNews данные сохраняются в CSV-файл в общей gfgrt.
В Python-скрипте эти данные загружаются из той же директории.
from Trade.TerminalInfo import CTerminalInfo import os terminal = CTerminalInfo() data_path = os.path.join(terminal.common_data_path(), "Files") timeframe = "PERIOD_H1" df = pd.read_csv(os.path.join(data_path, f"{symbol}.{timeframe}.OHLC + News.csv")) df
Результаты.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06983 | 1.06927 | 1.06983 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 02:00:00 | 1.06984 | 1.07059 | 1.06914 | 1.07041 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 03:00:00 | 1.07059 | 1.07069 | 1.06858 | 1.06910 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 04:00:00 | 1.06909 | 1.06909 | 1.06828 | 1.06880 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 05:00:00 | 1.06881 | 1.07029 | 1.06880 | 1.06897 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
Поскольку в MQL5-скрипте новости собираются для каждой строки данных, в столбце новостей появляются значения null, указывающие на отсутствие новостей в данный момент — такие строки необходимо отфильтровать.
news_df = df[df['Name'] != "(null)"].copy()
Аналогично тому, как мы структурировали основной датасет (два столбца: ds и y), датасет праздников также должен содержать два столбца: ds и holiday. В колонке праздников содержатся названия новостей.
holidays = news_df[['Time', 'Name']].rename(columns={ 'Time': 'ds', 'Name': 'holiday' }) holidays['ds'] = pd.to_datetime(holidays['ds']) # Ensure datetime format holidays
Результаты.
| ds | holiday | |
|---|---|---|
| 0 | 2023-01-02 01:00:00 | New Year's Day |
| 1 | 2023-01-02 02:00:00 | New Year's Day |
| 2 | 2023-01-02 03:00:00 | New Year's Day |
| 3 | 2023-01-02 04:00:00 | New Year's Day |
| 4 | 2023-01-02 05:00:00 | New Year's Day |
Дополнительно DataFrame праздников может содержать два необязательных столбца: lower_window и upper_window. Эти столбцы указывают модели, как именно событие влияет на данные до и после своего наступления.
В реальности влияние всех событий редко ограничивается только моментом их публикации — оно часто распространяется на периоды до и после.
holidays['lower_window'] = 0 holidays['upper_window'] = 1 # Extend effect to 1 hour after
Колонка lower_window определяет влияние события до его наступления, а колонка upper_window определяет влияние на события на временной ряд после того, как оно произошло.
- Для колонки lower_window значения могут быть равны нулю или меньше (≤ 0), при этом по умолчанию это 0, что означает, что праздник никак не влияет на предыдущие значения во временном ряду. Значение -1 означает, что событие повлияло на один предыдущий бар и т.д.
- Для колонки upper_window значения могут быть равны нулю или больше него (≥ 0), а значение по умолчанию также равно 0 — это означает, что событие не влияет на будущие значения во временном ряду. Значение 1 означает влияние на один следующий бар и т.д.
Теперь добавим эти признаки в модель.
holidays['lower_window'] = -1 # The anticipation of the news affect the volatility 1 bar before it's release holidays['upper_window'] = 1 # The news affects the volatility 1 bar after its release holidays
Теперь наш датафрейм с данными о праздниках выглядит так:
| ds | holiday | lower_window | upper_window | |
|---|---|---|---|---|
| 0 | 2023-01-02 01:00:00 | New Year's Day | -1 | 1 |
| 1 | 2023-01-02 02:00:00 | New Year's Day | -1 | 1 |
| 2 | 2023-01-02 03:00:00 | New Year's Day | -1 | 1 |
| 3 | 2023-01-02 04:00:00 | New Year's Day | -1 | 1 |
| 4 | 2023-01-02 05:00:00 | New Year's Day | -1 | 1 |
| ... | ... | ... | ... | ... |
| 15369 | 2025-06-20 18:00:00 | Eurogroup Meeting | -1 | 1 |
| 15370 | 2025-06-20 19:00:00 | Eurogroup Meeting | -1 | 1 |
| 15371 | 2025-06-20 20:00:00 | Eurogroup Meeting | -1 | 1 |
| 15372 | 2025-06-20 21:00:00 | Eurogroup Meeting | -1 | 1 |
| 15373 | 2025-06-20 22:00:00 | Eurogroup Meeting | -1 | 1 |
Передадим модели Prophet датафрейм праздников и подготовленные ранее обучающие данные.
model_w_holidays = Prophet(holidays=holidays) model_w_holidays.fit(prophet_df_train)
Проверим теперь прогнозы модели с учетом новостей, построив график предсказанных и фактических значений, как и ранее.
# Predict on training set with model test_fcst = model_w_holidays.predict(df=prophet_df_test) test_pred = test_fcst.yhat # We get the predictions # Plot the forecast with the actuals f, ax = plt.subplots(figsize=(10,5)) ax.scatter(prophet_df_test["ds"], prophet_df_test['y'], color='r') fig = model_w_holidays.plot(test_fcst, ax=ax)
Результаты.
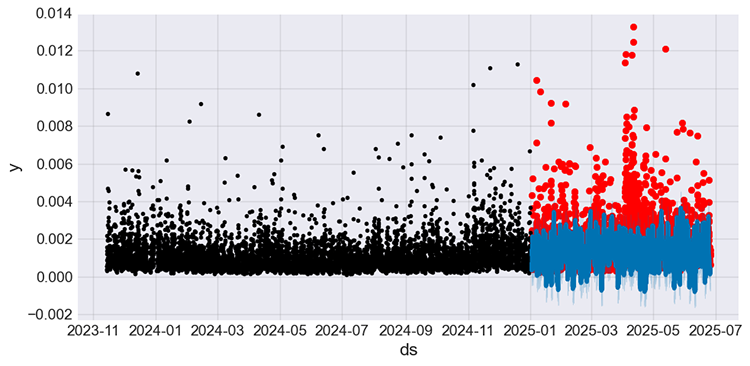
Рисунок 08
В отличие от модели без новостей (Рисунок 05), где прогнозы выглядят более статичными, новая модель с учетом новостей лучше захватывает колебания, которые ранее не учитывались.
Снова оценим модель с использованием тех же метрик.
results = forecast_accuracy(test_pred, prophet_df_test["y"]) for metric_name, value in results.items(): print(f"{metric_name:<10}: {value:.6f}")
Результаты.
mape : 0.549152 me : -0.000633 mae : 0.000970 mpe : -0.175082 rmse : 0.001487 minmax : 0.461444 r2_score : -2.793478
Показатель MAPE показывает улучшение в предсказаниях модели примерно на 10%. Предыдущая модель допускала примерно 60% ошибок, а эта — около 55%. Это улучшение также подтверждает показатель r2_score.
Тем не менее, модель с ошибкой 55% все еще нельзя считать качественной — хорошая модель должна иметь ошибку менее 50% (< 50%). Следовательно, у нас остается возможность дополнительно улучшить модель за счет более грамотной обработки праздников и новостей.
В данном примере значения lower_window и upper_window заданы как -1 и 1 соответственно, что означает влияние новости на волатильность за один бар до и после ее публикации. Хотя это привело к улучшению, нельзя утверждать, что такой подход является оптимальным.
Мы понимаем, что различные новости имеют разную силу воздействия и различную длительность эффекта, поэтому использование одинаковых значений для всех событий является концептуально неверным. Кроме того, в модели учитывались все новости, включая малозначимые, которые трейдеры обычно игнорируют, поскольку они происходят слишком часто, и их влияние трудно выявить на графике.
Для решения этих двух проблем необходимо задавать значения lower_window и upper_window динамически, в зависимости от типа новости и ее исторически наблюдаемого влияния.
Пример псевдокода.
def get_windows(name): if "CPI" in name: return (-1, 4) # CPI news affects one previous bar volatility, and it affects the volatility of four bars ahead (4 hours impact forward) elif "NFP" in name: return (-1, 2) # NFP news affects one previous bar volatility, and it affects the volatility of two bars ahead (2 hours impact afterward) elif "FOMC" in name or "Rate" in name: return (-2, 6) # NFP news affects two previous bar volatility, and it affects the volatility of six bars ahead (6 hours impact afterward) else: return (0, 1) # Default holidays[['lower_window', 'upper_window']] = holidays['holiday'].apply( lambda name: pd.Series(get_windows(name)) )
Учитывая, что существует десятки тысяч различных типов новостей, и необходимо точно определить параметры их воздействия, такой подход является крайне сложным в реализации, однако именно он является наиболее корректным. Поэтому эту часть предстоит проработать самостоятельно.
На текущем этапе разумным решением является фильтрация новостей с целью оставить только события высокой и средней значимости.
news_df = df[ (df['Name'] != "(null)") & # Filter rows without news at all ((df['Importance'] == "CALENDAR_IMPORTANCE_HIGH") | (df['Importance'] == "CALENDAR_IMPORTANCE_MODERATE")) # Filter other news except high importance news ].copy() news_df
Результаты.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 7 | 2023.01.02 08:00:00 | 1.06921 | 1.06973 | 1.06724 | 1.06858 | S&P Global Manufacturing PMI | CALENDAR_SECTOR_BUSINESS | CALENDAR_IMPORTANCE_MODERATE | 47.10 | 47.400 | 47.400 |
| 8 | 2023.01.02 09:00:00 | 1.06878 | 1.06909 | 1.06627 | 1.06784 | S&P Global Manufacturing PMI | CALENDAR_SECTOR_BUSINESS | CALENDAR_IMPORTANCE_MODERATE | 47.80 | 47.800 | 47.800 |
| 31 | 2023.01.03 08:00:00 | 1.06636 | 1.06677 | 1.06514 | 1.06524 | Unemployment | CALENDAR_SECTOR_JOBS | CALENDAR_IMPORTANCE_MODERATE | 2.52 | 2.522 | 2.538 |
| 37 | 2023.01.03 14:00:00 | 1.05283 | 1.05490 | 1.05241 | 1.05355 | S&P Global Manufacturing PMI | CALENDAR_SECTOR_BUSINESS | CALENDAR_IMPORTANCE_HIGH | 46.20 | 46.200 | 46.200 |
| 38 | 2023.01.03 15:00:00 | 1.05353 | 1.05698 | 1.05304 | 1.05602 | Construction Spending m/m | CALENDAR_SECTOR_HOUSING | CALENDAR_IMPORTANCE_MODERATE | 0.20 | 0.200 | -0.300 |
После этого, извлекая столбцы времени и названия события в датайрейме holidays, добавляем значения lower_window и upper_window.
holidays = news_df[['Time', 'Name']].rename(columns={ 'Time': 'ds', 'Name': 'holiday' }) holidays['ds'] = pd.to_datetime(holidays['ds']) # Ensure datetime format holidays['lower_window'] = 0 holidays['upper_window'] = 1 holidays
После повторного обучения модели ниже представлен график, где черным цветом обозначены значения обучающей выборки, красным — фактические значения тестовой выборки, синим — прогнозы модели для тестовой выборки.
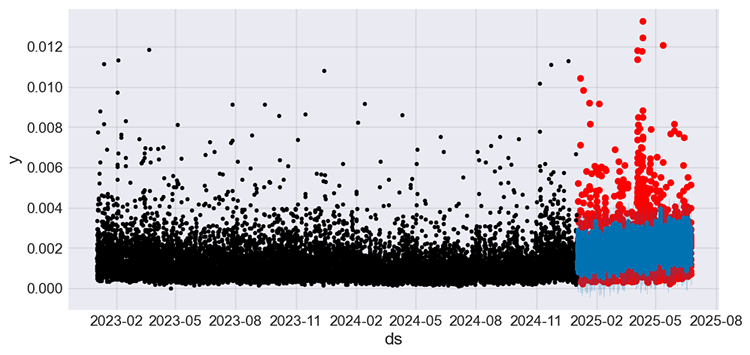
Рисунок 09
Модель снова улучшилась — согласно метрике MAPE, ошибка снизилась примерно до 50%. Теперь данную регрессионную модель можно использовать для прогнозирования.
mape : 0.506827 me : -0.000053 mae : 0.000783 mpe : 0.271597 rmse : 0.001234 minmax : 0.320422 r2_score : -3.318859
Можно заметить, что новости импортировались отдельно из CSV-файла, а обучающие данные поступали напрямую из MetaTrader 5.
Модель Prophet автоматически выравнивает (синхронизирует) даты из датафрейма holidays с датами основного обучающего набора данных, при условии, что временные метки из holidays попадают в диапазон обучающего или прогнозируемого периода.
Несмотря на возможность автоматической синхронизации, необходимо явно убедиться, что оба набора данных имеют одинаковые начальные даты, чтобы добиться максимальной эффективности.
В данном случае потребовалось вернуться к процессу получения ценовых данных из MetaTrader 5 в main.ipynb и изменить его так, чтобы начальные и конечные даты совпадали с используемыми в скрипте OHLC + News.mq5.
# set time zone to UTC timezone = pytz.timezone("Etc/UTC") # create 'datetime' objects in UTC-time to avoid the implementation of a local time zone offset utc_from = datetime(2023, 1, 1, tzinfo=timezone) utc_to = datetime(2025, 6, 24, hour = 0, tzinfo=timezone) rates = mt5.copy_rates_range(symbol, timeframe, utc_from, utc_to)
Создание торгового робота MetaTrader 5 на основе модели Prophet
Для создания торгового робота на базе модели Prophet необходимо обеспечить возможность получения прогнозов в реальном времени для целевой переменной (в данном случае — волатильности).
Для этого требуется построить пайплайн, позволяющий получать актуальные рыночные данные по символам, а также последние новости. В обучающем скрипте main.ipynb данные извлекались из MetaTrader 5 с помощью пакета MetaTrader 5-Python, однако он не предоставляет возможности получения новостей, поэтому необходимо использовать MQL5.
Идея заключается в организации обмена данными между Python-скриптом и советником на MQL5.
- Советник Data for Prophet.mq5, работающий на графике MetaTrader 5, периодически сохраняет данные (новости и значения OHLC) в CSV-файл в общей директории.
- Python-скрипт Prophet-trading-bot.py затем считывает этот файл и периодически обучает модель Prophet.
- После обучения модель используется для генерации прогнозов, которые затем применяются для принятия торговых решений внутри того же Python-скрипта
Файл: Data for Prophet.mq5
input uint collect_news_interval_seconds = 60; input uint training_bars = 1000; input ENUM_TIMEFRAMES timeframe = PERIOD_H1; //... other lines of code //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- create timer EventSetTimer(collect_news_interval_seconds); if (!ChartSetSymbolPeriod(0, Symbol(), timeframe)) return INIT_FAILED; //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- destroy timer EventKillTimer(); } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- } //+------------------------------------------------------------------+ //| Timer function | //+------------------------------------------------------------------+ void OnTimer() { //--- MqlDateTime time_struct; TimeToStruct(TimeGMT(), time_struct); SaveNews(StringFormat("%s.%s.OHLC.date=%s.hour=%d + News.csv",Symbol(),EnumToString(timeframe), TimeToString(TimeGMT(), TIME_DATE), time_struct.hour)); }
Чтобы гарантировать работу с корректным файлом, в имени CSV-файла используются текущая дата и час (в формате UTC).
Данный советник собирает новости и другие значения и по умолчанию сохраняет их в CSV-файл каждую минуту в соответствии с функцией OnTimer.
В Python-скрипте мы аналогичным образом загружаем CSV-файл из общей директории и импортируем данные.
Файл: Prophet-trading-bot.py
def prophet_vol_predict() -> float: # Getting the data with news now_utc = datetime.utcnow() current_date = now_utc.strftime("%Y.%m.%d") current_hour = now_utc.hour filename = f"{symbol}.{timeframe}.OHLC.date={current_date}.hour={current_hour} + News.csv" # the same file naming as in MQL5 script common_path = os.path.join(terminal.common_data_path(), "Files") csv_path = os.path.join(common_path, filename) # Keep trying to read a CSV file until it is found, as there could be a temporary difference in values for the file due to the change in time while True: if os.path.exists(csv_path): try: rates_df = pd.read_csv(csv_path) rates_df["Time"] = pd.to_datetime(rates_df["Time"], unit="s", errors="ignore") # Convert time from seconds to datetime print("File loaded successfully.") break # Exit the loop once file is read except Exception as e: print(f"Error reading the file: {e}") time.sleep(30) else: print("File not found. Retrying in 30 seconds...") time.sleep(30)
Далее подготавливаем столбец волатильности, а также извлекаем названия новостей для формирования обучающего набора данных и праздников соответственно.
# Getting continous variables for the prophet model prophet_df = pd.DataFrame({ "time": rates_df["Time"], "volatility": rates_df["High"] - rates_df["Low"] }).set_index("time") prophet_df = prophet_df.reset_index().rename(columns={"time": "ds", "volatility": "y"}).copy() print("Prophet df\n",prophet_df.head()) # Getting the news data for the model as well news_df = rates_df[ (rates_df['Name'] != "(null)") & # Filter rows without news at all ((rates_df['Importance'] == "CALENDAR_IMPORTANCE_HIGH") | (rates_df['Importance'] == "CALENDAR_IMPORTANCE_MODERATE")) # Filter other news except high importance news ].copy() holidays = news_df[['Time', 'Name']].rename(columns={ 'Time': 'ds', 'Name': 'holiday' }) holidays['ds'] = pd.to_datetime(holidays['ds']) # Ensure datetime format holidays['lower_window'] = 0 holidays['upper_window'] = 1 print("Holidays df\n", holidays)
В конце функции prophet_vol_pred модель обучается на полученных данных и возвращает одно прогнозируемое значение — ожидаемую волатильность следующего бара на рынке.
# re-training the prophet model prophet_model = Prophet(holidays=holidays) prophet_model.fit(prophet_df) # Making future predictions future = prophet_model.make_future_dataframe(periods=1) # prepare the dataframe for a single value prediction forecast = prophet_model.predict(future) # Predict the next one value return forecast.yhat[0] # return a single predicted value
Как и в случае с другими моделями машинного обучения для прогнозирования временных рядов, модель необходимо регулярно обновлять, чтобы учитывать актуальную информацию, важную для будущих прогнозов. Именно поэтому перед каждым новым прогнозом выполняется переобучение модели.
Запустим функцию и проанализируем результат.
print("predicted volatility: ",prophet_vol_predict())
Результаты.
File loaded successfully. Prophet df ds y 0 2025.04.29 01:00:00 0.00100 1 2025.04.29 02:00:00 0.00210 2 2025.04.29 03:00:00 0.00170 3 2025.04.29 04:00:00 0.00215 4 2025.04.29 05:00:00 0.00278 Holidays df ds holiday lower_window upper_window 8 2025-04-29 09:00:00 GfK Consumer Climate 0 1 14 2025-04-29 15:00:00 Retail Inventories excl. Autos m/m 0 1 31 2025-04-30 08:00:00 Consumer Spending m/m 0 1 33 2025-04-30 10:00:00 Unemployment 0 1 35 2025-04-30 12:00:00 GDP y/y 0 1 .. ... ... ... ... 978 2025-06-24 19:00:00 FOMC Member Williams Speech 0 1 979 2025-06-24 20:00:00 2-Year Note Auction 0 1 982 2025-06-24 23:00:00 Fed Vice Chair for Supervision Barr Speech 0 1 984 2025-06-25 01:00:00 Jobseekers Total 0 1 994 2025-06-25 11:00:00 Bbk Executive Board Member Mauderer Speech 0 1 [186 rows x 4 columns] 16:01:50 - cmdstanpy - INFO - Chain [1] start processing 16:01:50 - cmdstanpy - INFO - Chain [1] done processing predicted volatility: 0.0013592111956094713
Мы теперь можем получать прогнозируемое значение, так что используем его в торговой стратегии.
symbol = "EURUSD" timeframe = "PERIOD_H1" terminal = CTerminalInfo() m_position = CPositionInfo() def main(): m_symbol = CSymbolInfo(symbol=symbol) magic_number = 25062025 slippage = 100 m_trade = CTrade(magic_number=magic_number, filling_type_symbol=symbol, deviation_points=slippage) m_symbol.refresh_rates() # Get recent information from the market # we want to open random buy and sell trades if they don't exist and use the predicted volatility to set our stoploss and takeprofit targets predicted_volatility = prophet_vol_predict() print("predicted volatility: ",prophet_vol_predict()) if pos_exists(mt5.POSITION_TYPE_BUY, magic_number, symbol) is False: m_trade.buy(volume=m_symbol.lots_min(), symbol=symbol, price=m_symbol.ask(), sl=m_symbol.ask()-predicted_volatility, tp=m_symbol.ask()+predicted_volatility) if pos_exists(mt5.POSITION_TYPE_SELL, magic_number, symbol) is False: m_trade.sell(volume=m_symbol.lots_min(), symbol=symbol, price=m_symbol.bid(), sl=m_symbol.bid()+predicted_volatility, tp=m_symbol.bid()-predicted_volatility)
Данная функция получает прогнозируемую волатильность из модели Prophet и использует её для установки уровней stop loss и take profit в сделках. Перед открытием новой сделки проверяем, что нет другой открытой позиции того же типа.
Вызов функции.
main()
Результат.
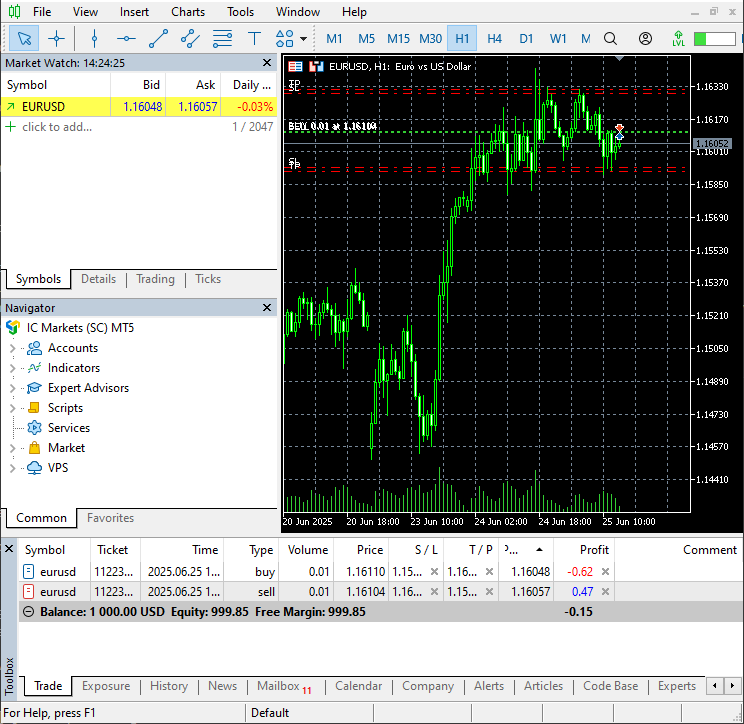
Рисунок 10
В MetaTrader 5 были открыты две противоположные сделки с уровнями стоп-лосс и тейк-профит, рассчитанными на основе прогнозируемой волатильности.
Процесс обучения можно автоматизировать и регулярно отслеживать торговые операции и сигналы.
schedule.every(1).minute.do(main) # train and run trading operations after every one minute while True: schedule.run_pending() time.sleep(1)
Заключение
Несмотря на то, что во многих статьях, публикациях и руководствах утверждается, что модель Prophet хорошо подходит для прогнозирования временных рядов, в рамках данной серии материалов она показала себя как одна из наименее эффективных моделей.
Она может быть полезна для решения простых задач прогнозирования, например, предсказания спроса в бизнесе, зависящего от погодных условий, праздников или сезонных факторов. Однако финансовые рынки значительно сложнее. Как видно из графиков (Рисунки 05–09), демонстрирующих фактические и прогнозируемые значения на тестовой выборке, модель Prophet не способна точно предсказывать большинство значений.
Вероятно, существуют способы улучшить модель, но на данный момент я рекомендую использовать ее только для относительно простых задач.
Основные ограничения модели:
- Простая структура модели, не поддерживающая сложные взаимодействия
- Низкая эффективность при работе с волатильностью — как мы увидели, модель плохо справляется с данными Forex
- Отсутствие многомерного моделирования — используются только два признака: время и целевая переменная
- Отсутствие встроенных механизмов кросс-валидации и настройки гиперпараметров — управление трендом, сезонностью и точками изменения выполняется вручную.
Всем удачи!
Источники и ссылки
- https://facebook.github.io/prophet/
- https://otexts.com/fpp3/prophet.html
- https://www.geeksforgeeks.org/time-series-analysis-using-facebook-prophet/
- https://www.kaggle.com/code/omegajoctan/time-series-forecasting-with-prophet/edit
Таблица вложений
| Имя файла | Описание и назначение |
|---|---|
| Python code\main.ipynb | Блокнот Jupyter для анализа данных и изучения модели Prophet. |
| Python code\Prophet-trading-bot.py | Торговый робот на основе Python для MetaTrader 5. |
| Python code\requirementx.txt | Текстовый файл, содержащий зависимости Python и номера их версий. |
| Python code\error_description.py | Содержит описание всех кодов ошибок, генерируемых MetaTrader 5. |
| Python code\Trade\* | Содержит торговые классы (CTrade, CPositionInfo и т. д.) для Python, аналогичные тем, что есть в MQL5. |
| Experts\Data for Prophet.mq5 | Советник, который периодически собирает и сохраняет данные для обучения модели Prophet в CSV-файл. |
| Scripts\OHLC + News.mq5 | Скрипт для сбора и сохранения данных для обучения модели Prophet в CSV-файле. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/18549
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования