
MetaTrader 5機械学習の設計図(第2回):機械学習のための金融データのラベリング

目次
はじめに
想像してみてください。あなたはエリート狙撃兵になるための訓練を受けています。射撃練習にどちらを使うべきでしょうか。完璧な円が描かれた紙の標的か、人間のシルエットを模した実戦的な標的か。答えは明らかで、実際の戦闘状況を反映した標的で練習すべきです。
機械学習を金融市場に適用する際も同じです。学術研究では「固定時間ラベリング(fixed-time horizon labeling)」がよく用いられますが、これは先ほどの紙の円形ターゲットに相当します。この手法は「X日後に価格が上昇しているか下落しているか」という単純な問いを立てます。しかし実際のトレーダーが気にするのは、最終的な価格だけではありません。ストップロスがいつヒットするか、どのタイミングで利益確定すべきか、そしてその過程で価格がどのように動くかが重要です。
本連載へようこそ。第1回では、多くの取引アルゴリズムを密かに破綻させる「タイムスタンプの罠」を解決しました。今回取り組むのは、実際の取引に即したラベルを作る方法という、同じくらい重要なテーマです。
考えてみてください。もしあなたが心臓発作を予測するモデルを作るなら、「365日後に生存しているかどうか」だけを見るでしょうか。当然そうではありません。警告サイン、早期介入、医療判断に関わる一連の状況を把握するはずです。金融市場でもこれと同じです。
本記事は、Pythonの基本操作と機械学習の基礎概念を理解している読者を対象とします。すぐに実践できるコード例と現場レベルの応用について、深く掘り下げて解説していきます。
第1回の振り返り:データリーケージとタイムスタンプ修正
第1回では、MetaTrader 5のデフォルトデータ構造が内包する「タイムスタンプの罠」および「データリーケージ」といった、金融機械学習モデルを陰で破綻させる重大な問題について解説しました。また、生のティックデータからクリーンでバイアスのないバーを構築する重要性を強調し、信頼できるデータ基盤の作り方を示しました。これらは、堅牢な金融機械学習モデルを構築する上で欠かすことができません。まだ第1回を読んでいない場合は、先に確認することを強くお勧めします。
第1回で確立したデータ基盤により、以下が保証されます。
- データの整合性: タイムスタンプが実際に利用可能だった情報を正しく反映すること
- 統計的健全性:アクティビティ駆動型のバーが、機械学習モデルに適した統計的特性を提供すること
- 実運用との整合性:バー生成が市場の実際の情報フローと一致していること
これらの根本的なデータ品質の問題を解決したことで、次の重要なステップ、つまり市場のダイナミクスをより忠実に捉えるラベリング手法に進むための、クリーンでバイアスのないデータセットを準備できました。
ラベリング手法の概要
金融分野の機械学習モデルが失敗する理由の多くは、驚くほど平凡なものです。原因はアルゴリズムの質でも、計算資源の不足でもなく、劣悪なラベルにあります。取引モデルの構築を始めた頃、特徴量の最適化やニューラルネットワークのアーキテクチャ検証に何か月も費やしましたが、最終的に気づいたのは、自分のラベリング方式が根本から間違っていたという事実でした。実際には暴風の中で揺れ動く的を狙う必要があるのに、私はモデルに「中心点だけを狙う」訓練をさせていたのです。
金融市場は容赦なくノイズに満ちています。各ティックには、実際の情報とランダムなカオスが混在しています。私たちの役割は、シグナルを抽出しながらも、多くの値動きが市場参加者の気まぐれやマイクロ秒レベルのアルゴ反応によって生じるものだと理解することです。良いラベリングとは単に何が起きたかを教えるだけでなく、実際の取引判断で何が重要かを明確にするものです。
最もシンプルで、多くの人が最初におこなうのが固定時間ラベリングです。たとえば5日という期間を設定し、その期間の終わりに価格が上がっているか下がっているかを判断します。Apple株が月曜日に150ドルで引け、金曜日までに155ドルに達したなら、月曜日は「買い」シグナルとしてラベル付けされます。クリーンで直感的ですが、実際の取引の仕組みとは根本的にズレています。株を買うとき、「何があっても5日後に結果を見る」と考えるでしょうか。火曜日に20%急落したら金曜日まで待たないでしょうし、水曜日に15%急騰したら即座に利益確定したくなるはずです。
ここで登場するのが、金融MLの実務家の考え方を一変させたトリプルバリア法(triple-barrier method)です。この手法は恣意的な時間スパンを排除し、プロのトレーダーがおこなうように、各エントリー候補に3つのバリアを設定します。エントリー価格から5%上の利確ライン、3%下のストップロス、そして「無期限で塩漬けしないための」時間制限です。この3つのうち、どれが最初に到達するかによってラベルが決まります。モデルが学ぶのは抽象的な価格変動ではなく、「特定のセットアップがストップに掛かる前に利確に到達するか」という実用的な問いになります。
この手法が優れているのは、実際のトレーダーの心理を自然に反映している点です。トレーダーは、最終的に上がるかどうかではなく、ストップロスに掛からずに上がってくれるかを気にします。つまり、目的地と同じくらい、価格が辿った道筋が重要であり、トリプルバリア法はこのパス依存性をそのまま取り込みます。さらに、ボラティリティに応じてバリア幅を動的に調整することも可能です。市場が荒れているときにはストップ幅を広げ、落ち着いているときにはタイトにする、といった調整を自然におこなえます。
そして、市場のトレンド期間が大きく変動するケースでは、トレンドスキャン法が有効です。このアルゴリズムは固定期間を押し付けるのではなく、複数の将来期間を検証し、最も統計的に有意なトレンドを選びます。5日のトレンドは弱いが、10日は強く、15日は中程度といったケースでは、最も強いシグナルが採用され、そのシグナルに基づいてラベル付けがおこなわれます。つまり、市場状況に応じてアルゴリズム自身が最適な予測期間を選択し、それに応じてラベルを決定する仕組みです。
次にメタラベリングがあります。これはまったく別の問題に取り組む手法です。市場方向の予測ではなく、「他の予測を信頼すべきタイミングはいつか?」を判断します。すでに売買シグナルを生成する戦略があるとします。メタラベリングでは、第二のモデルを構築し、各シグナルが本当に利益を生む可能性が高いかどうかを評価します。メイン戦略が「買い」と判断しても、メタモデルは最近の成績、ボラティリティ、重要ニュースからの経過時間など追加要素を踏まえて信頼度を出力します。信頼度が高ければ積極的にポジションを取る、低ければ小さくする、あるいは見送る、といった運用ができます。
ここには重要な洞察があります。どれだけ正しく予測できるかよりも、自分が正しいときにそれをどれほど活かせるかの方が利益につながることが多いということです。これは、優れた予測者であることと、実際に利益を出せるトレーダーであることとの決定的な違いでもあります。多くの戦略は方向予測そのものが悪いのではなく、高信頼シグナルと低信頼シグナルを同じサイズで賭けてしまうことが原因で失敗します。
各ラベリング手法はモデルに異なることを学習させます。固定期間ラベリングは純粋な価格方向にフォーカスします。トリプルバリア法はリスク管理とパス依存性を取り込みます。トレンドスキャン法は市場状況に適応します。メタラベリングは確信度とポジションサイズを最適化します。どの手法を選ぶかは、モデルが何を学び、実運用でどのように振る舞うかを根本的に決定づけます。
金融データを扱う際の重要な考慮事項
- 先読みバイアスを避ける: ラベルは、意思決定時点までに利用可能な情報だけに基づいて付与しなければなりません。たとえば「今日」のデータポイントにラベル付けする場合、特徴量に使えるのは「今日まで」の情報のみであり、ラベルを決める際には「今日から見た未来」の情報を利用します。
- クラスのバランスをとる:「買い」「売り」「保持」のようなラベル付けをおこなうと、保持(あるいは小動き)が非常に多くなることがあります。クラスが極端に不均衡だと、MLモデルが少数クラスを学習しにくくなります。オーバーサンプリング、アンダーサンプリング、適切な評価指標の利用など、これを扱うための手法が存在します。
- ボラティリティが鍵:金融市場ではボラティリティが常に変動します。平穏な市場では2%の値動きは大きな意味を持ちますが、荒れた市場では大した変化ではないかもしれません。トリプルバリア法のように、ボラティリティに応じて閾値を調整するラベリングを検討すべきです。
- 定常性:金融時系列は非定常であり、平均や分散といった統計的性質が時間とともに変化します。ラベリング自体がデータを定常化するわけではありませんが、たとえば価格ではなくリターンを対象にラベル付けするなど、より定常性の高い指標を使うこと、そしてその後の特徴量設計が非常に重要です。
- 反復と改良:最初のラベリング手法が最適であるとは限りません。異なる手法、期間、閾値を試し、目的や分析対象の資産に最も適した方法を探る姿勢が必要です。
実装:トリプルバリア法
動的バリアの設定
前のセクションで述べたように、実務ではエントリーした賭けに内在するリスクに応じて、利確およびストップロスの水準を設定する必要があります。そうしないと、現在のボラティリティを踏まえたときに、利確幅が大きすぎる(𝜏 ≫ 𝜎ti,0)場合もあれば、小さすぎる(𝜏 ≪ 𝜎ti,0)場合もあるためです。
以下のコードでは、日次ボラティリティを、日中の推定ポイントにおいて算出しています。この際、一定日数のスパンを用いた指数加重移動標準偏差(EWMA)によってボラティリティを計算します。このボラティリティを、利確バリアおよびストップロスバリアを設定する際に利用します。
def get_daily_vol(close, lookback=100): """ Advances in Financial Machine Learning, Snippet 3.1, page 44. Daily Volatility Estimates Computes the daily volatility at intraday estimation points. In practice we want to set profit taking and stop-loss limits that are a function of the risks involved in a bet. Otherwise, sometimes we will be aiming too high (tao ≫ sigma_t_i,0), and sometimes too low (tao ≪ sigma_t_i,0), considering the prevailing volatility. Snippet 3.1 computes the daily volatility at intraday estimation points, applying a span of lookback days to an exponentially weighted moving standard deviation. See the pandas documentation for details on the pandas.Series.ewm function. Note: This function is used to compute dynamic thresholds for profit taking and stop loss limits. :param close: (pd.Series) Closing prices :param lookback: (int) Lookback period to compute volatility :return: (pd.Series) Daily volatility value """ # Find previous valid trading day for each date prev_idx = close.index.searchsorted(close.index - pd.Timedelta(days=1)) prev_idx = prev_idx[prev_idx > 0] # Drop indices before the start # Align current and previous closes curr_idx = close.index[close.shape[0] - prev_idx.shape[0] :] prev_close = close.iloc[prev_idx - 1].values # Previous day's close ret = close.loc[curr_idx] / prev_close - 1 vol = ret.ewm(span=lookback).std() return vol
垂直バリアの設定
垂直バリアを設定するために、以下の関数を使用します。アクティビティ駆動型バーを用いる場合、一定の時間期間における変動幅が極端に大きくなり得るため、固定期間で垂直バリアを設定するよりも、バーの残存数にもとづいてバリアを設定する方が理にかなっています。
# Snippet 3.4 page 49, Adding a Vertical Barrier def add_vertical_barrier(t_events, close, num_bars=0, **time_delta_kwargs): """ Advances in Financial Machine Learning, Enhanced Implementation. Adding a Vertical Barrier For each event in t_events, finds the timestamp of the next price bar at or immediately after: - A fixed number of bars (for activity-based sampling), OR - A time delta (for time-based sampling) This function creates a series of vertical barrier timestamps aligned with the original events index. Out-of-bound barriers are marked with NaT for downstream handling. :param t_events: (pd.Series) Series of event timestamps (e.g., from symmetric CUSUM filter) :param close: (pd.Series) Close price series with DateTimeIndex :param num_bars: (int) Number of bars for vertical barrier (activity-based mode). Takes precedence over time delta parameters when > 0. :param time_delta_kwargs: Time components for time-based barrier (mutually exclusive with num_bars): :param days: (int) Number of days :param hours: (int) Number of hours :param minutes: (int) Number of minutes :param seconds: (int) Number of seconds :return: (pd.Series) Vertical barrier timestamps with same index as t_events. Out-of-bound events return pd.NaT. Example: # Activity-bar mode (tick/volume/dollar bars) vertical_barriers = add_vertical_barrier(t_events, close, num_bars=10) # Time-based mode vertical_barriers = add_vertical_barrier(t_events, close, days=1, hours=3) """ # Validate inputs if num_bars and time_delta_kwargs: raise ValueError("Use either num_bars OR time deltas, not both") # BAR-BASED VERTICAL BARRIERS if num_bars > 0: indices = close.index.get_indexer(t_events, method="nearest") t1 = [] for i in indices: if i == -1: # Event not found t1.append(pd.NaT) else: end_loc = i + num_bars t1.append(close.index[end_loc] if end_loc < len(close) else pd.NaT) return pd.Series(t1, index=t_events) # TIME-BASED VERTICAL BARRIERS td = pd.Timedelta(**time_delta_kwargs) if time_delta_kwargs else pd.Timedelta(0) barrier_times = t_events + td # Find next index positions t1_indices = np.searchsorted(close.index, barrier_times, side="left") t1 = [] for idx in t1_indices: if idx < len(close): t1.append(close.index[idx]) else: t1.append(pd.NaT) # Mark out-of-bound for downstream return pd.Series(t1, index=t_events)
トリプルバリアラベリングの適用
トリプルバリア法は本質的にパス依存の手法であり、ラベルを決めるために最終価格だけを見ればよいというものではありません。代わりに、ポジションを取ってから手仕舞いするまでの価格の軌跡を追跡する必要があります。手仕舞いは、利確、ストップロス、または時間切れのいずれかによって発生します。
トリプルバリア法を適用する際、私たちが本質的に問いかけているのは、「時刻ti,0を起点として先に進んだとき、最初に何が起こるのか」ということです。このプロセスは、最初のバリアに触れた瞬間を表すti,1に到達するまで続きます。それは利確ラインかもしれませんし、ストップロスかもしれませんし、あるいは最大保有期間(ti,0 + hに設定された垂直バリア)かもしれません。ラベリングに使用するリターンは、エントリー時刻ti,0からこの最初の接触時刻ti,1までのリターンとして計算されます。
apply_pt_sl_on_t1()関数は、このロジックを実装するものであり、適切に動作するにはいくつかの入力が必要です。まず、実際の価格の軌跡を追跡するために終値系列が必要です。eventsデータフレームには各エントリー候補に関する重要情報が含まれています。t1列は、各エントリーがいつ期限切れになるか(垂直バリア)を示し、trgt列は、横方向バリアの幅(profit-taking / stop-lossバリアの基準幅)を定義します。
pt_slパラメータは特に重要です。これは2要素のリストで、バリア幅を決める倍率を制御します。最初の要素(pt_sl[0])は利確バリアの幅を何倍にするか、2番目の要素(pt_sl[1])はストップロスバリアの幅を何倍にするか をそれぞれ指定します。いずれかが0の場合、そのバリアは無効化されます。これにより、たとえばストップロスはタイトに、利確は大きく伸ばすといった非対称なリスクリワード構造を構築できます。
この関数は、設定されたバリアを体系的に処理し、価格をバーごとに追跡しながら、どれかのバリアがブレイクされるまで進みます。これにより、正確なラベリングに必要なバリア接触時点とリターン情報が取得されます。
# Snippet 3.2, page 45, Triple Barrier Labeling Method def apply_pt_sl_on_t1(close, events, pt_sl, molecule): """ Advances in Financial Machine Learning, Snippet 3.2, page 45. Triple Barrier Labeling Method This function applies the triple-barrier labeling method. It works on a set of datetime index values (molecule). This allows the program to parallelize the processing. Mainly it returns a DataFrame of timestamps regarding the time when the first barriers were reached. :param close: (pd.Series) Close prices :param events: (pd.Series) Indices that signify "events" (see cusum_filter function for more details) :param pt_sl: (np.array) Element 0, indicates the profit taking level; Element 1 is stop loss level :param molecule: (an array) A set of datetime index values for processing :return: (pd.DataFrame) Timestamps of when first barrier was touched """ # Apply stop loss/profit taking, if it takes place before t1 (end of event) events = events.loc[molecule].copy() out = events[["t1"]].copy(deep=True) profit_taking_multiple = pt_sl[0] stop_loss_multiple = pt_sl[1] # Profit taking active if profit_taking_multiple > 0: profit_taking = np.log(1 + profit_taking_multiple * events["trgt"]) else: profit_taking = pd.Series(index=events.index) # NaNs # Stop loss active if stop_loss_multiple > 0: stop_loss = np.log(1 - stop_loss_multiple * events["trgt"]) else: stop_loss = pd.Series(index=events.index) # NaNs # Use dictionary to collect barrier hit times barrier_dict = {"sl": {}, "pt": {}} # Get events for loc, vertical_barrier in events["t1"].fillna(close.index[-1]).items(): closing_prices = close[loc:vertical_barrier] # Path prices for a given trade cum_returns = np.log(closing_prices / close[loc]) * events.at[loc, "side"] # Path returns barrier_dict["sl"][loc] = cum_returns[ cum_returns < stop_loss[loc] ].index.min() # Earliest stop loss date barrier_dict["pt"][loc] = cum_returns[ cum_returns > profit_taking[loc] ].index.min() # Earliest profit taking date # Convert dictionary to DataFrame and join to `out` barrier_df = pd.DataFrame(barrier_dict) out = out.join(barrier_df) # Join on index (loc) return out
トリプルバリア法では、どのバリアを有効化するかによって8通りの設定が可能です。各セットアップは[profit_target, stop_loss, time_limit]で表し、1が有効、0が無効を意味します。
- 実務でよく使われる3パターン
- [1,1,1] - 完全セットアップ:3つのバリアすべてを有効化。利確を狙いつつ、下方リスクと保有期間を管理します。多くのプロトレーダーの運用スタイルに最も近い構成です。
- [0,1,1] - 利益は伸ばす:利確バリアは無効ですが、X期間後、またはストップロスにヒットした時点で手仕舞いします。トレンドフォロー戦略のように、勝ちポジションを最大化したい場合に適しています。
- [1,1,0] - 時間制限なし:利確バリアとストップロスは有効ですが、時間制限はなし。価格バリアのいずれかに触れるまでポジションを保有します。
- 技術的には可能だが実務的にはあまり現実的でない3パターン
- [0,0,1] - 固定期間:時間ベースでの手仕舞いのみ。基本的には固定時間ラベリングと同じですが、アクティビティ駆動型バーでは利用可能です。
- [1,0,1] - 損失無視:利益が出るか、時間切れになるまで保有。途中の損失は無視します。リスク管理上危険な構成です。
- [1,0,0] - 永遠に保有:ストップロスも時間制限もなし。損失ポジションをいつか利益になるまで保有する、ポートフォリオ破壊のリスクが高い構成です。
- 実質的に使えない2パターン
- [0,1,0] - 失敗前提:ストップロスに到達するまで保有。損失だけを前提にポジションを取る意味はありません。
- [0,0,0] - 手仕舞いなし:すべてのバリアが無効。ポジションは閉じられず、ラベルも生成されません。
以下に、トリプルバリア法の2つの具体的な設定例を示します。
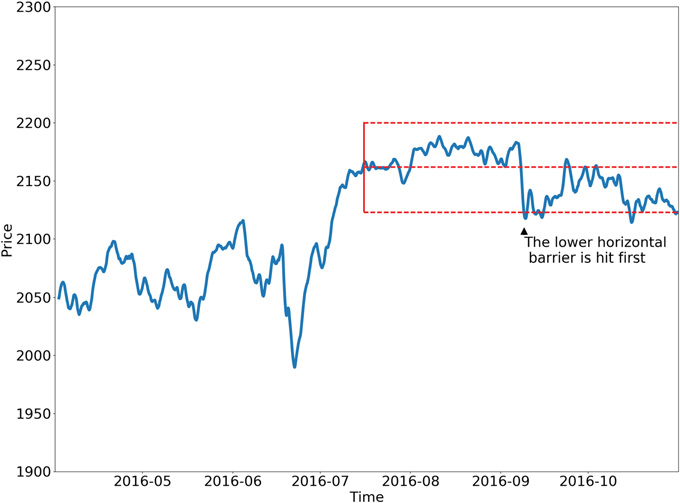
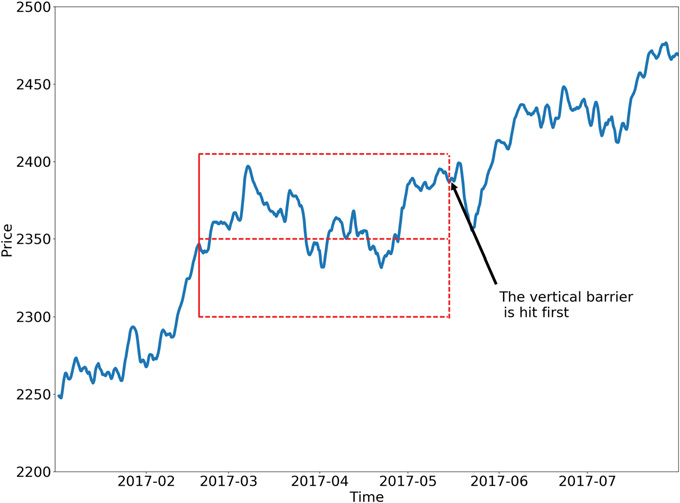
サイドとサイズの学習
このセクションの関数は、トリプルバリア法を用いて、get_events()でside_prediction=Noneの場合にはポジションの方向{1, 0, -1}を学習し、サイドが既知の場合にはメタラベリング済みデータからサイズを学習します。ポジションのサイドを学習するということは、横方向のバリアが存在しないか、あるいは利確とストップロスのバリアが対称であることを意味します。これは、この時点では利確バリアとストップロスバリアを区別できないためです。サイドが判明すれば、バリア幅を最適化して、どの組み合わせが最もパフォーマンスの高いモデルになるかを探ることができます。最初に接触したバリアの日時は、get_events()を実行することで取得します。
# Snippet 3.3 -> 3.6 page 50, Getting the Time of the First Touch, with Meta Labels def get_events(close, t_events, pt_sl, target, min_ret, num_threads, vertical_barrier_times=False, side_prediction=None, verbose=True): """ Advances in Financial Machine Learning, Snippet 3.6 page 50. Getting the Time of the First Touch, with Meta Labels This function is orchestrator to meta-label the data, in conjunction with the Triple Barrier Method. :param close: (pd.Series) Close prices :param t_events: (pd.Series) of t_events. These are timestamps that will seed every triple barrier. These are the timestamps selected by the sampling procedures discussed in Chapter 2, Section 2.5. E.g.: CUSUM Filter :param pt_sl: (list) Element 0, indicates the profit taking level; Element 1 is stop loss level. A non-negative float that sets the width of the two barriers. A 0 value means that the respective horizontal barrier (profit taking and/or stop loss) will be disabled. :param target: (pd.Series) of values that are used (in conjunction with pt_sl) to determine the width of the barrier. In this program this is daily volatility series. :param min_ret: (float) The minimum target return required for running a triple barrier search. :param num_threads: (int) The number of threads concurrently used by the function. :param vertical_barrier_times: (pd.Series) A pandas series with the timestamps of the vertical barriers. We pass a False when we want to disable vertical barriers. :param side_prediction: (pd.Series) Side of the bet (long/short) as decided by the primary model :param verbose: (bool) Flag to report progress on asynch jobs :return: (pd.DataFrame) Events -events.index is event's starttime -events['t1'] is event's endtime -events['trgt'] is event's target -events['side'] (optional) implies the algo's position side -events['pt'] is profit taking multiple -events['sl'] is stop loss multiple """ # 1) Get target target = target.reindex(t_events) target = target[target > min_ret] # min_ret # 2) Get vertical barrier (max holding period) if vertical_barrier_times is False: vertical_barrier_times = pd.Series(pd.NaT, index=t_events, dtype=t_events.dtype) # 3) Form events object, apply stop loss on vertical barrier if side_prediction is None: side_ = pd.Series(1.0, index=target.index) pt_sl_ = [pt_sl[0], pt_sl[0]] else: side_ = side_prediction.reindex(target.index) # Subset side_prediction on target index. pt_sl_ = pt_sl[:2] # Create a new df with [v_barrier, target, side] and drop rows that are NA in target events = pd.concat({'t1': vertical_barrier_times, 'trgt': target, 'side': side_}, axis=1) events = events.dropna(subset=['trgt']) # Apply Triple Barrier first_touch_dates = mp_pandas_obj(func=apply_pt_sl_on_t1, pd_obj=('molecule', events.index), num_threads=num_threads, close=close, events=events, pt_sl=pt_sl_, verbose=verbose) for ind in events.index: events.at[ind, 't1'] = first_touch_dates.loc[ind, :].dropna().min() if side_prediction is None: events = events.drop('side', axis=1) # Add profit taking and stop loss multiples for vertical barrier calculations events['pt'] = pt_sl[0] events['sl'] = pt_sl[1] return events
get_bins()を使用すると、次の情報を持つeventsデータフレームが返されます。
- events.indexはイベントの開始時刻
- events ['t1']はイベントの終了時刻
- events ['trgt']はイベントのターゲット
- events ['side'](オプション)は戦略のポジションサイド
- ケース1:sideが存在しない場合、ラベルは{-1, 1}で、価格の動きに基づいて決定されます。
- ケース2:sideが存在する場合、ラベルは{0, 1}で、損益(PnL)に基づいたメタラベリングとなります。
# Snippet 3.4 -> 3.7, page 51, Labeling for Side & Size with Meta Labels def get_bins(triple_barrier_events, close, vertical_barrier_zero=False, pt_sl=[1, 1]): """ Advances in Financial Machine Learning, Snippet 3.7, page 51. Labeling for Side & Size with Meta Labels Compute event's outcome (including side information, if provided). events is a DataFrame where: Now the possible values for labels in out['bin'] are {0,1}, as opposed to whether to take the bet or pass, a purely binary prediction. When the predicted label the previous feasible values {−1,0,1}. The ML algorithm will be trained to decide is 1, we can use the probability of this secondary prediction to derive the size of the bet, where the side (sign) of the position has been set by the primary model. :param triple_barrier_events: (pd.DataFrame) Events DataFrame with the following structure: - **index**: pd.DatetimeIndex of event start times - **t1**: (pd.Series) Event end times - **trgt**: (pd.Series) Target returns - **side**: (pd.Series, optional) Algo's position side Labeling behavior depends on the presence of 'side': - Case 1: If 'side' not in events → `bin ∈ {-1, 1}` (label by price action) - Case 2: If 'side' is present → `bin ∈ {0, 1}` (label by PnL — meta-labeling) :param close: (pd.Series) Close prices :param vertical_barrier_zero: (bool) If True, set bin to 0 for events that touch vertical barrier, else bin is the sign of the return. :param pt_sl: (list) Take-profit and stop-loss multiples :return: (pd.DataFrame) Meta-labeled events :returns index: Event start times :returns t1: Event end times :returns trgt: Target returns :returns side: Optional. Algo's position side :returns ret: Returns of the event :returns bin: Labels for the event, where 1 is a positive return, -1 is a negative return, and 0 is a vertical barrier hit """ # 1. Align prices with their respective events events = triple_barrier_events.dropna(subset=["t1"]) all_dates = events.index.union(other=events["t1"].array).drop_duplicates() prices = close.reindex(all_dates, method="bfill") # 2. Create out DataFrame out_df = events[["t1"]].copy() out_df["ret"] = np.log(prices.loc[events["t1"].array].array / prices.loc[events.index]) out_df["trgt"] = events["trgt"] # Meta labeling: Events that were correct will have pos returns if "side" in events: out_df["ret"] *= events["side"] # meta-labeling if vertical_barrier_zero: # Label 0 when vertical barrier reached out_df["bin"] = barrier_touched( out_df["ret"].values, out_df["trgt"].values, np.array(pt_sl, dtype=float), ) else: # Label is the sign of the return out_df["bin"] = np.where(out_df["ret"] > 0, 1, -1).astype("int8") # Meta labeling: label incorrect events with a 0 if "side" in events: out_df.loc[out_df["ret"] <= 0, "bin"] = 0 # Add the side to the output. This is useful for when a meta label model must be fit if "side" in triple_barrier_events.columns: out_df["side"] = triple_barrier_events["side"].astype("int8") out_df["ret"] = np.exp(out_df["ret"]) - 1 # Convert log returns to simple returns return out_df
注:上記で使用しているmp_pandas_obj()は、pandasオブジェクトを扱う際に並列処理を容易にするヘルパー関数です(pandasは通常、単一CPU上でのみ動作します)。添付ファイルmultiprocess.pyには、この関数やその他のマルチプロセッシング用ヘルパー関数が含まれています。
垂直バリアに触れたときにラベルを0に設定するには、get_bins()内でbarrier_touched()を呼び出します。
# Snippet 3.9, page 55, Question 3.3 def barrier_touched(ret, target, pt_sl): """ Advances in Financial Machine Learning, Snippet 3.9, page 55, Question 3.3. Adjust the getBins function (Snippet 3.7) to return a 0 whenever the vertical barrier is the one touched first. Top horizontal barrier: 1 Bottom horizontal barrier: -1 Vertical barrier: 0 :param ret: (np.array) Log-returns :param target: (np.array) Volatility target :param pt_sl: (ArrayLike) Take-profit and stop-loss multiples :return: (np.array) Labels """ N = ret.shape[0] # Number of events store = np.empty(N, dtype=np.int8) # Store labels in an array profit_taking_multiple = pt_sl[0] stop_loss_multiple = pt_sl[1] # Iterate through the DataFrame and check if the vertical barrier was reached for i in range(N): pt_level_reached = ret[i] > np.log(1 + profit_taking_multiple * target[i]) sl_level_reached = ret[i] < np.log(1 - stop_loss_multiple * target[i]) if ret[i] > 0.0 and pt_level_reached: # Top barrier reached store[i] = 1 elif ret[i] < 0.0 and sl_level_reached: # Bottom barrier reached store[i] = -1 else: # Vertical barrier reached store[i] = 0 return store
ゼロラベルとリターン符号ラベルの使い分け
バーに触れなかったイベントをゼロとしてラベル付けするのは、モデルに明確にリスク管理された結果だけに注目させたい場合に有効です。一方、ホライゾン時点のリターンの符号でラベル付けすると、リスク閾値を超えていなくても、方向性のドリフトすべてを捉えることができます。
ゼロラベルを使用するのは、次のような場合です。
- 三クラス分類器(上昇、下降、ニュートラル)を構築しており、「ニュートラル」をリスク内で決定的な値動きがない状態と定義したい場合
- 学習からあいまいなシグナル(バリアに触れない小さなドリフト)を除外したい場合
- 事前に定めた利確・損切りの閾値に達したかどうかだけでイベントの成功を測定したい場合
次の場合はリターンの符号でラベル付けします。
- すべてのサンプルに二値方向(上昇/下降)を持たせる必要がある二クラス問題や、中立ラベルが過剰になるのを避けたい場合
- 厳密なリスク管理ではなく、モメンタムや期間リターンをモデル化したい場合
- 価格の動きがわずかであっても情報としてモデルに反映させたい場合
この選択に加え、クラスバランスやラベルノイズへの影響も考慮する必要があります。ゼロラベルが多すぎる場合は、中立サンプルをアンダーサンプリングしたり、横方向バリアを広げたりすると良いでしょう。一方、リターン符号ラベルがノイズ過多の場合は、+1/-1を割り当てる前に最小リターン閾値を設定することで改善できます。
イベントベースサンプリング
トレーダーとして、私たちは単にランダムに売買のタイミングを決めるわけではありません。代わりに、市場で特定の出来事が起きるのを待ってから取引をおこないます。こうした「トリガーイベント」には、以下のようなものがあります。
- 重要な経済指標の発表(雇用統計やインフレレポートなど)
- 市場価格が急に非常に不安定になる場合
- 関連する投資商品の価格差が通常の水準から大きく逸脱した場合
これらのイベントが発生した時点で、市場で何か重要な動きが起きている可能性があるシグナルとして扱います。その後、機械学習アルゴリズムにその状況下で正確な予測関数が存在するかを判断させることができます。
重要な考え方は、これらのイベントが発生した際に、価格の動きを正確に予測できる方法があるかどうかを学習することです。もし特定の種類のイベントが正確な予測に結びつかないことが分かれば、重要なイベントの定義を見直すか、モデルへの入力特徴量を変更して再度試す必要があります。
CUSUMフィルタ
イベントベースサンプリングにおいて強力な手法の一つがCUSUMフィルタです。これはもともと品質管理で用いられる手法で、測定値の平均値の変化を検出するために使われます。金融分野では、価格のような市場変数が大きく変動したタイミングでデータポイントをサンプリングするように、このフィルタを応用できます。CUSUMフィルタは、期待値からの偏差を累積し、その累積値が一定の閾値を超えたときにサンプリングイベントを発生させる仕組みです。
対称型CUSUMフィルタは次のように定義されます。
-
S⁺ = max(0, S⁺ + ΔP)
-
S⁻ = min(0, S⁻ + ΔP)
ここでΔPは価格変動です。イベントは、S⁺が正の閾値hを超えるか、S⁻が負の閾値−hを下回ったときに発生します。イベントが発生した場合、対応する累積値はリセットされます。この方法により、価格が閾値付近で上下する際に複数のイベントが誤って発生することを防げます。これは、ボリンジャーバンドなどの一般的な市場シグナルに見られる欠点です。CUSUMフィルタを使用することで、市場活動が顕著な瞬間にサンプリングされた特徴行列Xを作成でき、機械学習モデルにとってより関連性の高いデータを提供できます。
# Snippet 2.4, page 39, The Symmetric CUSUM Filter. def cusum_filter(raw_time_series, threshold, time_stamps=True): """ Advances in Financial Machine Learning, Snippet 2.4, page 39. The Symmetric Dynamic/Fixed CUSUM Filter. The CUSUM filter is a quality-control method, designed to detect a shift in the mean value of a measured quantity away from a target value. The filter is set up to identify a sequence of upside or downside divergences from any reset level zero. We sample a bar t if and only if S_t >= threshold, at which point S_t is reset to 0. One practical aspect that makes CUSUM filters appealing is that multiple events are not triggered by raw_time_series hovering around a threshold level, which is a flaw suffered by popular market signals such as Bollinger Bands. It will require a full run of length threshold for raw_time_series to trigger an event. Once we have obtained this subset of event-driven bars, we will let the ML algorithm determine whether the occurrence of such events constitutes actionable intelligence. Below is an implementation of the Symmetric CUSUM filter. Note: As per the book this filter is applied to closing prices but we extended it to also work on other time series such as volatility. :param raw_time_series: (pd.Series) Close prices (or other time series, e.g. volatility). :param threshold: (float or pd.Series) When the abs(change) is larger than the threshold, the function captures it as an event, can be dynamic if threshold is pd.Series :param time_stamps: (bool) Default is to return a DateTimeIndex, change to false to have it return a list. :return: (datetime index vector) Vector of datetimes when the events occurred. This is used later to sample. """ t_events = [] s_pos = 0 s_neg = 0 # log returns raw_time_series = pd.DataFrame(raw_time_series) # Convert to DataFrame raw_time_series.columns = ['price'] raw_time_series['log_ret'] = raw_time_series.price.apply(np.log).diff() if isinstance(threshold, (float, int)): raw_time_series['threshold'] = threshold elif isinstance(threshold, pd.Series): raw_time_series.loc[threshold.index, 'threshold'] = threshold else: raise ValueError('threshold is neither float nor pd.Series!') raw_time_series = raw_time_series.iloc[1:] # Drop first na values # Get event time stamps for the entire series for tup in raw_time_series.itertuples(): thresh = tup.threshold pos = float(s_pos + tup.log_ret) neg = float(s_neg + tup.log_ret) s_pos = max(0.0, pos) s_neg = min(0.0, neg) if s_neg < -thresh: s_neg = 0 t_events.append(tup.Index) elif s_pos > thresh: s_pos = 0 t_events.append(tup.Index) # Return DatetimeIndex or list if time_stamps: event_timestamps = pd.DatetimeIndex(t_events) return event_timestamps return t_events
未フィルタのエントリーシグナルとCUSUMフィルタ済みのシグナルで、ミーンリバージョン(平均回帰)型のボリンジャーバンド戦略のパフォーマンスががどのように変わるかを分析してみます。 学習および検証には、EURUSDの5分足データを2018-01-01から2021-12-31まで使用し、アウトオブサンプルテストには2022-01-01から2024-12-31までのデータを使用します。
このデモでは、意図的に感度の高いボリンジャーバンド設定(期間20、標準偏差1.5)を使用し、メタモデルが評価するための大量のエントリーシグナルを生成します。この設定は単独の戦略としてはノイズが多すぎますが、ラベリングとフィルタリングのパイプラインをストレステストするには理想的です。
すべての戦略で一貫性と相互運用性を確保するため、Pythonのオブジェクト指向設計を用いて、共通インターフェースまたは基盤クラスを通じて戦略を構築することを推奨します。これにより、各戦略が同じコア機能(シグナル生成、イベントフィルタリングなど)を公開でき、比較や拡張、より広範なワークフローへの統合が容易になります。また、一般的に使用されるシグナル生成にはTA-LibやPandas TAを使用することが有効です。これらのライブラリは業界標準の計算式を実装しており、高度に最適化されたCバックエンド上で動作するため、同等のPython実装よりも2~4倍高速です。また、出力が標準化されており、エッジケースが一貫して処理されるため、ラベリングやフィルタリング、可視化などの下流処理も容易になります。これらのライブラリはインストールがやや難しい場合があるため、こちらの記事の手順に従うことを推奨します。
import pandas as pd from typing import Tuple, Union import logging from abc import ABC, abstractmethod from typing import Dict, Tuple, Union import numpy as np import pandas as pd import talib from loguru import logger class BaseStrategy(ABC): """Abstract base class for trading strategies""" @abstractmethod def generate_signals(self, data: pd.DataFrame) -> pd.Series: """Generate trading signals (1 for long, -1 for short, 0 for no position)""" pass @abstractmethod def get_strategy_name(self) -> str: """Return strategy name""" pass @abstractmethod def get_objective(self) -> str: """Return strategy objective""" pass class BollingerMeanReversionStrategy(BaseStrategy): """Bollinger Bands mean reversion strategy""" def __init__(self, window: int = 20, num_std: float = 2.0, objective: str = "mean_reversion"): self.window = window self.num_std = num_std self.objective = objective def generate_signals(self, data: pd.DataFrame) -> pd.Series: """Generate mean-reversion signals using Bollinger Bands""" close = data["close"] # Calculate Bollinger Bands upper_band, _, lower_band = talib.BBANDS( close, timeperiod=self.window, nbdevup=self.num_std, nbdevdn=self.num_std ) # Generate signals signals = pd.Series(0, index=data.index, dtype="int8", name="side") signals[(close >= upper_band)] = -1 # Sell signal (mean reversion) signals[(close <= lower_band)] = 1 # Buy signal (mean reversion) return signals def get_strategy_name(self) -> str: return f"Bollinger_w{self.window}_std{self.num_std}" def get_objective(self) -> str: return self.objective def get_entries( strategy: 'BaseStrategy', data: pd.DataFrame, filter_events: bool = False, filter_threshold: Union[float, pd.Series] = None, on_crossover: bool = True, ) -> Tuple[pd.Series, pd.DatetimeIndex]: """Get timestamps and position information for entry events. This function processes signals from a given `BaseStrategy` to identify trade entry points. It can apply a CUSUM filter to isolate significant events or, by default, detect entries at signal crossover points. Args: strategy (BaseStrategy): The trading strategy object that generates the primary signals. data (pd.DataFrame): A pandas DataFrame containing the input data, expected to have a 'close' column if `filter_events` is True. filter_events (bool, optional): If True, a CUSUM filter is applied to the signals to identify significant events. Defaults to False. filter_threshold (Union[float, pd.Series], optional): The threshold for the CUSUM filter. Must be a float or a pandas Series. Defaults to None. on_crossover (bool, optional): If True, only events where the signal changes from the previous period are considered entry points. Defaults to True. Raises: ValueError: If `filter_events` is True and `filter_threshold` is not a `float` or `pd.Series`. Returns: Tuple[pd.Series, pd.DatetimeIndex]: A tuple containing: side (pd.Series): A Series with the same index as the input data, where each value represents the trading position (-1 for short, 1 for long, 0 for no position). t_events (pd.DatetimeIndex): A DatetimeIndex of the timestamps for each detected entry event. """ primary_signals = strategy.generate_signals(data) signal_mask = primary_signals != 0 # Vectorized CUSUM filter application if filter_events: try: close = data.close except AttributeError as e: logger.error(f"Dataframe must have a 'close' column: {e}") raise e if not isinstance(filter_threshold, (pd.Series, float)): raise ValueError("filter_threshold must be a Series or a float") elif isinstance(filter_threshold, pd.Series): filter_threshold = filter_threshold.copy().dropna() close = close.reindex(filter_threshold.index) # Assuming cusum_filter is a function that takes a Series and a threshold filtered_events = cusum_filter(close, filter_threshold) signal_mask &= primary_signals.index.isin(filtered_events) else: # Vectorized signal change detection if on_crossover: signal_mask &= primary_signals != primary_signals.shift() t_events = primary_signals.index[signal_mask] side = pd.Series(index=data.index, name="side") side.loc[t_events] = primary_signals.loc[t_events] side = side.ffill().fillna(0).astype("int8") if filter_events: s = " generated by CUSUM filter" elif on_crossover: s = " generated by crossover" else: s = "" logger.info(f"Generated {len(t_events):,} trade events{s}.") return side, t_events
メタラベリングのための特徴量エンジニアリング
金融時系列の微妙なダイナミクスを捉えるために、統計的厳密さとドメイン固有の知見を融合させた豊富な特徴量セットを構築しました。これには、ボラティリティ調整済みのモメンタム指標、自己相関構造、高次のリターンモーメント(歪度や尖度)に加え、ボリンジャーバンド由来の指標や正規化移動平均差分が含まれます。また、RSI、MACD、ADX、ATRといったテクニカルシグナルは、TA-Libとpandas-taを用いて抽出しており、一貫性と再現性が確保されています。短期および長期の特徴量を組み込むことで、モデルは市場行動の微妙な変化を検知し、変化する取引状況に対応できるようになっています。具体例として、遅行リターン、Yang-Zhangボラティリティ推定、トレンドフォロー指標などを特徴量に含めています。コードは添付ファイルfeatures.pyに記載されています。
CUSUMフィルタの有効性を示すため、EURUSDの5分足データに対して、未フィルタとフィルタ済みシグナルを用いてランダムフォレストを学習させました。 横方向バリアは、100日間の指数加重日次ボラティリティをターゲットとして設定し、利確バリアを1、ストップロスバリアを2に設定しました。垂直バリアは50バーに設定しています。
target = get_daily_vol(close, lookback=100)
cusum_filter_threshold = target.mean()
データフィルタリングの効果
モデルの比較に入る前に、各分類レポートで報告される主要な指標について簡単に確認します。- 適合率:陽性と予測したサンプルのうち、実際に正しかった割合。高い値であれば誤警報が少ないことを示します。
- 再現率:実際の陽性サンプルのうち、正しく予測できた割合。高い値であれば見逃しが少ないことを示します。
- F1スコア:メタラベリングのようにクラス不均衡がある場合、単純な精度では評価が不十分になることがあります。たとえば、ラベル0(負例)がラベル1(正例)よりも圧倒的に多い場合、すべてのサンプルを負例と予測するだけで適合率は高くなりますが、再現率は0で適合率は定義できません。F1スコアは、適合率と再現率の調和平均を用いることで、この欠点を補正します。
- サポート:検証セットにおける各クラスのサンプル数。
- 制度: 全体に対する正解率。
これらの指標の詳細なチュートリアルについては、「How to Interpret the Classification Report in sklearn」を参照してください。
スコアを比較する前に、まず、CUSUMフィルタを適用するとサンプル数が76.1%減少することに注目してください。
| フィルタなし | フィルタあり | 削減率 |
|---|---|---|
| 32828 | 7825 | 76.1 |
表0: シグナル数(フィルタ前後比較)
CUSUMフィルタは「ノイズ」、すなわちクラス0のダイナミクスに本質的に関連するサンプルを除去することを目的としています。理想的には、クラス1のF1が改善され(イベント捕捉の向上)、クラス0のF1が維持されることです。実際、フィルタ済みのプライマリモデルは理想的な結果となりましたが、フィルタ済みのメタモデルではクラス0のF1が5.8%減少しました。この場合は、モデルのハイパーパラメータを調整するか、特徴量セットを変更することで改善可能です。
| 指標 | フィルタなし | フィルタあり | Δ |
|---|---|---|---|
| 再現率(1) | 1.00 | 1.00 | 0% |
| 適合率(1) | 0.33 | 0.38 | +15.2% |
| F1 (1) | 0.49 | 0.55 | +11.0% |
| 指標 | フィルタなし | フィルタあり | Δ |
|---|---|---|---|
| F1 (0) | 0.69 | 0.65 | -5.8% |
| F1 (1) | 0.57 | 0.60 | +5.3% |
| 精度 | 0.64 | 0.63 | -1.6% |
表4: メタモデル(フィルタ前後比較)
データ削減とモデルパフォーマンスのトレードオフは、次の式で評価できます。
- パフォーマンス維持 = フィルタありでのパフォーマンス / フィルタなしでのパフォーマンス * 100
- ネットベネフィット = パフォーマンス維持 - データ削減
ネットベネフィットがプラスであれば、フィルタは効率的であり、使用する必要があります。
| モデル | データ削減 | パフォーマンス維持 | ネットベネフィット |
|---|---|---|---|
| プライマリ | 76.1% | 112.2% | +36.1% |
| メタ | 76.1% | 98.5% | +22.4% |
表5: トレードオフ分析
フィルタリングされていないシグナルとフィルタリングされたシグナルを比較すると、次のことがわかります。
- CUSUMフィルタはイベントの76.1%をノイズとして除去することに成功した
- フィルタリングにより、プライマリモデルおよびメタモデルの適合率が向上した
- メタモデルの全体パフォーマンスは76%のデータ削減にもかかわらずわずかに低下した クラス1ではF1が+5.3%向上し、クラス0では-5.6%の低下が見られたが、ネットベネフィットはプラスとなり、CUSUMフィルタの使用が有効であることが確認できた
メタラベルレポート:ボリンジャーバンド戦略
以下の分類レポートおよびROCカーブは、メタラベリングは現実的かつリスク認識されたラベリングスキームと組み合わせることで効果を発揮するという重要な洞察を示しています。

図1:固定時間プライマリモデル分類レポート

図2:固定時間メタモデル分類レポート

図3: トリプルバリアプライマリモデル分類レポート

図4:トリプルバリアメタモデル分類レポート
受信者操作特性曲線

図5:固定時間 vs トリプルバリアメタモデルのROC
結果の解釈:モデルパフォーマンスの読み解き
これらの結果の明確な差は、ラベリングが成功を定義するという本連載の核心を裏付けています。固定時間モデルの分類レポートは、モデルが本質的に学習できていないことを示しています。シグナルをランダム以上に識別できないことは、ROC曲線が対角線上に沿って張り付いていることで視覚的にも確認できます。これは、実用に耐えない分類器の典型的な特徴です。一方で、トリプルバリア法のレポートでは、予測パターンを正しく捉えたモデルであることが示されています。ROC曲線が左上隅に大きく弓状に偏っていることは、真陽性率と偽陽性率の間で有意なトレードオフが存在することを示しており、ROC AUC値が0.5を大きく上回ることは、モデルに実際的な予測力があることを意味します。
さらに重要なのは、適合率の指標が取引の現実に直結する点です。クラス1の適合率が高いということは、予測した利益性の高い取引(メタラベル)が正しい確率が高くなることを意味し、戦略の潜在的利益を高めるとともに、信頼度に基づくポジションサイズ設定の統計的根拠を提供します。
経済的意義: アウトオブサンプルパフォーマンス
トリプルバリアモデルはROC AUCにおいて統計的に有意な改善を示しましたが、その真価はシミュレーションによる資産曲線で明らかになります。図7に示す通り、新しいラベリング手法を活用した戦略は、-0.03%のリターン、最大ドローダウン36.9%を記録し、ベンチマークである固定時間戦略(リターン-0.71%、最大ドローダウン76%)を大幅に上回りました。

図6: 固定時間パフォーマンス - 資本曲線

図7:トリプルバリア戦略のパフォーマンス - 資本曲線
以下は、各ラベリング方法のパフォーマンス指標の包括的な表です。
| 指標 | 固定時間 | トリプルバリア |
|---|---|---|
| total_return | -0.709771 | -0.028839 |
| annualized_return | -0.338102 | -0.009714 |
| volatility | 0.483111 | 0.37613 |
| downside_volatility | 0.336945 | 0.231413 |
| sharpe_ratio | -4.778646 | -0.021566 |
| sortino_ratio | -6.851611 | -0.035053 |
| var_95 | -0.002864 | -0.00215 |
| cvar_95 | -0.004164 | -0.002992 |
| skewness | -0.014451 | 0.034745 |
| kurtosis | 3.857222 | 2.507046 |
| max_drawdown | 0.761708 | 0.368585 |
| avg_drawdown | 0.08375 | 0.039945 |
| drawdown_duration | 84 days 01:18:50 | 32 days 03:17:12 |
| ulcer_index | 0.217503 | 0.098507 |
| calmar_ratio | -0.443874 | -0.026354 |
| bet_frequency | 3901 | 3969 |
| bets_per_year | 1300.040115 | 1322.701671 |
| num_trades | 37691 | 27426 |
| trades_per_year | 12560.83363 | 9139.93853 |
| win_rate | 0.497546 | 0.504339 |
| avg_win | 0.001266 | 0.001081 |
| avg_loss | -0.001322 | -0.001105 |
| best_trade | 0.014599 | 0.01451 |
| worst_trade | -0.013828 | -0.010548 |
| profit_factor | 0.952754 | 0.999799 |
| expectancy | -0.000034 | -0.000002 |
| kelly_criterion | -0.027194 | -0.002226 |
| consecutive_wins | 77 | 92 |
| consecutive_losses | 66 | 90 |
| avg_trade_duration | 0 days 00:39:18 | 0 days 06:22:15 |
表6:アウトオブサンプルパフォーマンス指標
結論
連載第2回では、ラベリングの選択が金融モデルの挙動や信頼性をどのように形作るかを探りました。固定時間法を超え、トリプルバリア法のようなパス依存型手法を採用することで、リスク認識や現実的なトレードのダイナミクスを学習プロセスに直接組み込む方法を示しました。
さらに、メタラベリングは、低信頼度のシグナルをフィルタリングし適合率を向上させる戦略的オーバーレイとして機能することが明らかになりました。特に、堅牢なラベリングスキームと組み合わせることで効果が高く、分類レポートやROC曲線は、積極的なフィルタリング下でもシグナルの品質が向上することを示しています。
しかし、私たちの旅はまだ終わっていません。
次回の記事では、トレンドスキャン法を実装します。この手法により、モデルは統計的に有意な価格変動に基づいて予測期間を動的に選択できるようになり、変動の大きい市場において新たな適応性を獲得できます。
また、複数のシグナルが時間的に重なる金融データの同時性の課題にも取り組みます。各観測値の独自性や関連性を反映したサンプルの重みを導入することで、モデルが冗長なノイズではなく、真に独立したシグナルから学習できるようにします。
さらに、メタラベリングによって生成される確率を活用して、より賢明にポジションサイズを決定する方法も検討します。単純な二値実行ではなく、確率的な信頼度に応じてポジションサイズを調整することで、モデルの確信度と資本配分を整合させます。
これらの改良を組み合わせることで、金融市場向けの実運用に耐える機械学習パイプラインにより近づきます。技術的に堅牢であるだけでなく、現実の取引行動にも戦略的に適合したパイプラインの構築を目指します。
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/18864
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索
分からないことがあります:
生のティックデータではなく、構築されたバー(時間、ティックなど)でモデルをトレーニングする場合、ライブ取引中にバーを構築する必要がありますか?
私には理解できないことがある:
生のティックデータではなく、構築されたバー(時間、ティックなど)でモデルをトレーニングする場合、ライブ取引中にバーを構築する必要がありますか?