Машинное обучение и Data Science (Часть 39): Тестируем связку новостей с ИИ

Содержание
- Введение
- Сбор новостей
- Подготовка новостных данных для обучения моделей
- Обучение модели на новостных данных
- Торговый робот: Новости + Искусственный интеллект
- Заключение
Введение
Наверняка вы слышали, что финансовые и валютные рынки движимы и подвержены влиянию новостей, особенно Non-Farm Payrolls (NFP). Это так, ведь новости описывают текущие события в реальном мире.
Торговля на новостях обычно включает экономические отчеты, корпоративные заявления, геополитические события и сообщения от центральных банков. Часто, когда выходят такие новости (за несколько мгновений до или после), они создают волатильность и торговые возможности по связанным активам и инструментам.
Поскольку новости описывают происходящее в мире в конкретном регионе или стране и их ожидаемые последствия, они являются одними из лучших предикторов финансовых рынков. Например, если брать пару EURUSD, то информация о росте CPI в новости Core CPI по евро может привести к бычьему движению EUR, поскольку это часто повышает ожидания ужесточения монетарной политики (повышения процентных ставок), а также может привести к медвежьему движению USD.
Есть определенный тип новостей, например корпоративные объявления и экономические отчеты, которые могут оказывать влияние на рынки в любом направлении. А есть события, такие как стихийные бедствия, которые, как правило, оказывают преимущественно негативное влияние на валютные и фондовые рынки.
Чтобы стать успешными трейдерами, недостаточно полагаться исключительно на технические аспекты рынка. Нужно также учитывать новости, поскольку они являются одним из ключевых факторов, влияющих на финансовые рынки.

Учитывая сказанное, мы знаем, что новости являются одним из, если не самым значимым, факторов, определяющих поведение рынков. В этой статье мы будем новости из платформы MetaTrader 5 в качестве входных данных для AI-моделей и посмотрим, действительно ли такое сочетание способно обеспечить преимущество в алгоритмической торговле.
Сбор новостей
Это первый этап, который нам предстоит пройти в рамках нашего проекта.
Сбор новостей может быть достаточно сложной задачей. Здесь необходимо тщательно учитывать несколько моментов, включая временные рамки сбора данных, используемый инструмент (символ) и обработку пустых переменных (NaN).
Ниже представлена структура данных, содержащая переменные, которые мы будем использовать для хранения собираемых новостных данных.
struct news_data_struct { datetime time[]; //News release time string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value }
Данная структура отражает часть атрибутов новостей, предоставляемых MqlCalendarEvent и MqlCalendarValue.
Ниже показано, как осуществляется сбор новостей путем перебора исторических данных.
//--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } }
Хотя данный код позволяет получить необходимые новости, нам также требуется собрать значения Open, High, Low и Close (OHLC) на момент публикации новости. Эти значения будут полезны при анализе и при формировании целевой переменной для обучения с учителем.
Также нам нужен функционал для сохранения этой информации в CSV-файл для последующего внешнего использования.
Ниже приведена полная функция для сбора новостей.
void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
Процесс сохранения информации в CSV-файл выполняется вне цикла, чтобы мы могли собирать данные как для баров, на которых новости публиковались, так и для тех, на которых новостей не было. Это важно, поскольку нам нужны бары без новостей для оценки влияния новостей до и после их публикации.
В качестве периода я выбрал с 01.01.2023 по 31.12.2023, то есть полный год новостных и торговых данных.
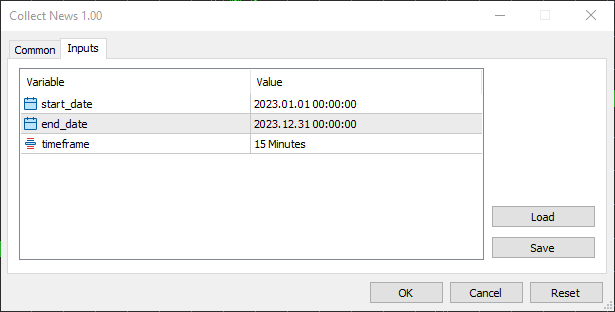
Я выбрал таймфрейм 15 минут, поскольку именно его, по моим наблюдениям, большинство трейдеров используют при разработке новостных фильтров и в целом новостных стратегий. Это оптимальный баланс между захватом значимых ценовых реакций после публикации новостей и фильтрацией рыночного шума, который характерен для таймфреймов ниже 15 минут.
Подготовка новостных данных для обучения моделей
Внутри Python-скрипта (Jupyter Notebook) мы начинаем с импорта CSV-файла, содержащего новостные данные.
df = pd.read_csv("/kaggle/input/nfp-forexdata/EURUSD.PERIOD_M15.News.csv") df.head(5)
Результаты.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
Для новостных данных в полях Факт, Предыдущее и Прогноз используются значения NaN. Поэтому необходимо явно проверять, не попали ли в CSV-файл какие-либо значения NaN, дополнительно к проверкам на отсутствие NaN внутри скрипта 'Collect News MQL5'.
df.info()
Результаты.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 24848 entries, 0 to 24847 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Time 24848 non-null object 1 Open 24848 non-null float64 2 High 24848 non-null float64 3 Low 24848 non-null float64 4 Close 24848 non-null float64 5 Name 24848 non-null object 6 Sector 24848 non-null object 7 Importance 24848 non-null object 8 Actual 24848 non-null float64 9 Forecast 24848 non-null float64 10 Previous 24848 non-null float64 dtypes: float64(7), object(4) memory usage: 2.1+ MB
Формирование целевой переменной
В задачах обучения с учителем необходима целевая переменная, которую модель будет использовать для установления взаимосвязей между предикторами и этой целевой переменной.
Мы знаем, что после публикации новости рынки обычно быстро реагируют, двигаясь в том или ином направлении в зависимости от действий и реакций трейдеров. Однако основная сложность заключается в определении того, как долго происходящее на рынке можно считать следствием недавно опубликованной новости.
Есть те, кто не торгует непосредственно сразу после выхода новостей, они могут ждать 15–30 минут после публикации, полагая, что по истечении этого времени влияние новости ослабевает.
Поскольку после выхода новостей рынок испытывает повышенную волатильность и даже иногда шпильки, со значительным количеством шума, мы создадим целевую переменную на 15 баров вперед (примерно на 4 часа вперед по времени).
lookahead = 15 clean_df = df.copy() clean_df["Future Close"] = df["Close"].shift(-lookahead) clean_df.dropna(inplace=True) # drop nan caused by shifting operation clean_df["Signal"] = (clean_df["Future Close"] > clean_df["Close"]).astype(int) # if the future close > current close = bullish movement otherwise bearish movement clean_df
Удаление строк без новостей из данных
После формирования целевой переменной мы можем удалить все строки, в которых новости не публиковались. Нам нужно обучать модель только на строках, содержащих новости.
Фильтруем все строки со значением (null) в столбце Name (столбец, содержащий названия новостей).
clean_df = clean_df[clean_df['Name'] != '(null)'] clean_df
Строковые значения в датафрейме
Поскольку строковые значения не поддерживаются во многих моделях машинного обучения, нужно преобразовать строковые значения в integer.
Строковые значения присутствуют в столбцах: Name (название), Sector (сектор) и Importance (важность).
from sklearn.preprocessing import LabelEncoder
categorical_cols = ['Name', 'Sector', 'Importance'] label_encoders = {} encoded_df = clean_df.copy() for col in categorical_cols: le = LabelEncoder() encoded_df[col] = le.fit_transform(clean_df[col]) # Save classes to binary file (.bin) with open(f"{col}_classes.bin", 'wb') as f: np.save(f, le.classes_, allow_pickle=True) label_encoders[col] = le encoded_df.head(5)
В качестве альтернативы можно обернуть LabelEncoder в Pipeline для удобства.
Важно сохранить классы, которые объект label encoder нашел для каждого запрограммированного столбца, поскольку нам потребуется та же информация при кодировании новостей в финальных программах, написанных на языке MQL5.
Это позволит соблюсти согласованность схем, а также для своевременно выявлять ошибки в случае, если энкодер сталкивается с новостями, на которых он не обучался, поскольку появление неожиданных новостей в мире неизбежно.
Результаты.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | Future Close | Signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06880 | 0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06888 | 0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06891 | 0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06892 | 0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06897 | 0 |
Теперь разделим данные на выборки X и Y, а затем разделим эти два набора на обучающую и тестовую выборки.
X = encoded_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "Future Close", "Signal" ]) y = encoded_df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 42, shuffle=True)
Обратите внимание, что мы удалили все столбцы, кроме тех, которые содержали информацию о новостях.
Обучение модели на новостных данных
Для обучения я выбрал модель LightGBM (Light Gradient Boosting Machine), поскольку она простая, быстрая и точная. Не говоря уже о том, что это модель, основанная на деревьях решений, которая отлично работает с категориальными данными, подобными тем, которые у нас сейчас есть.
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # For binary classification (use 'regression' for regression tasks)
'metric': ['auc','binary_logloss'], # Evaluation metric
'num_leaves': 25, # Number of leaves in one tree
'n_estimators' : 100, # number of trees
'max_depth': 5,
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9 # Fraction of features to be used for each boosting round
}
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
weight_dict = dict(zip(np.unique(y_train), class_weights))
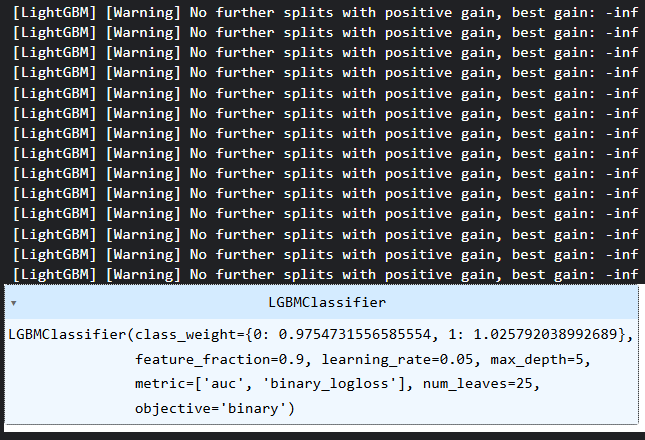
model = lgb.LGBMClassifier(**params, class_weight=weight_dict)
# Fit the model to the training data
model.fit(X_train, y_train) Здесь введены весовые коэффициенты классов для предотвращения предвзятости в решениях моделей.
Результаты.
Ниже представлен отчет о классификации прогнозов, сделанных моделью на тестовой выборке.
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 Classification Report precision recall f1-score support 0 0.59 0.52 0.55 1116 1 0.55 0.61 0.58 1049 accuracy 0.56 2165 macro avg 0.57 0.57 0.56 2165 weighted avg 0.57 0.56 0.56 2165
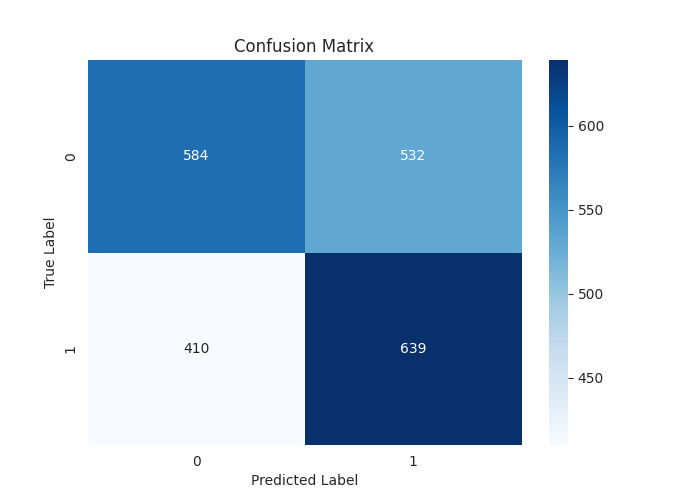
Общая точность 0.56 из 1.0 на тестовых данных является впечатляющим результатом. Достичь подобного уровня при обучении моделей машинного обучения исключительно на "технических данных" непросто.
На данный момент построенная модель представляет собой черный ящик — мы не знаем, каким образом новости влияют на итоговые решения модели. Посмотрим, какую историю модель рассказывает нам через важность признаков.
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train) Результаты.
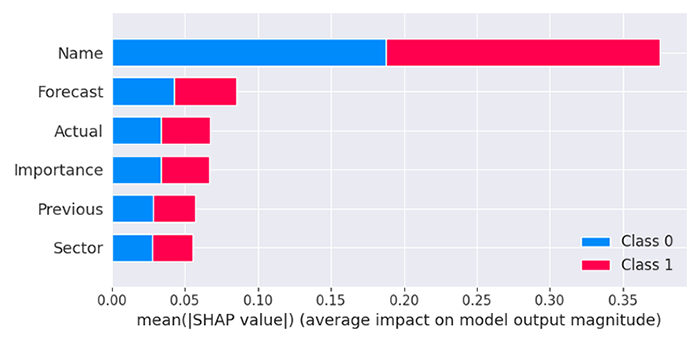
Модель определяет, что столбец Name оказывает наибольшее влияние среди всех признаков, что означает: некоторые новости с конкретными названиями оказывают значительно более сильное влияние на рыночную реакцию по сравнению с другими предикторами.
Прогнозируемые значения (Forecast) являются вторым по значимости фактором для модели, за ними следуют Actual, Importance, Previous и Sector новости.
Тем не менее это по-прежнему не дает полной ясности. Существует множество способов определить влияние каждого уникального значения внутри признака на модель, например, с использованием метода SHAP — в частности, можно оценить вклад первой строки данных.
i=0 shap.force_plot(explainer.expected_value[1], shap_values[1][i], X_train.iloc[i], matplotlib=True)
Результаты.
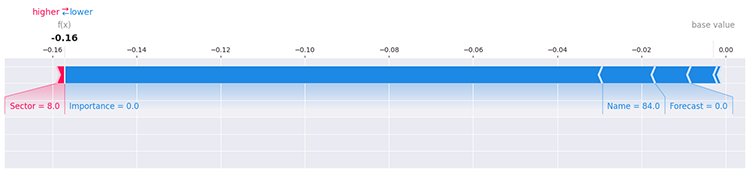
Больше информации можете найти в документации SHAPLEY.
Наконец, нам необходимо сохранить модель в формате ONNX для внешнего использования.
# Registering ONNX converter update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final conversion model_onnx = convert_sklearn( model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 14, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.EURUSD.news.M15.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Торговый робот: Новости + Искусственный интеллект
Чтобы этот торговый робот работал, нужно добавить несколько зависимостей и файлов.
#define NEWS_CSV "EURUSD.PERIOD_M15.News.csv" //For simulating news on the strategy tester, making testing possible //--- Encoded classes for the columns stored in a binary file #define SECTOR_CLASSES "Sector_classes.bin" #define NAME_CLASSES "Name_classes.bin" #define IMPORTANCE_CLASSES "Importance_classes.bin" #define LIGHTGBM_MODEL "lightgbm.EURUSD.news.M15.onnx" //AI model //--- Tester files #property tester_file NEWS_CSV #property tester_file SECTOR_CLASSES #property tester_file NAME_CLASSES #property tester_file IMPORTANCE_CLASSES #property tester_file LIGHTGBM_MODEL
Мы должны разрешить использование этих файлов в тестере стратегий, поскольку именно там они наиболее необходимы.
//--- Dependencies #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Lightgbm.mqh> //For importing LightGBM model CLightGBMClassifier lgbm; CTrade m_trade; CPositionInfo m_position;
Нужна та же структура новостей, что и использовалась в Collect News.mq5 (скрипт, применявшийся для сбора новостных данных).
MqlRates rates[]; struct news_data_struct { datetime time; double open; double high; double low; double close; int name; int sector; int importance; double actual; double forecast; double previous; } news_data;
Поскольку в MQL5 имеется аналог LabelEncoder, схожий с тем, который мы использовали в Python для преобразования строковых признаков, мы можем загрузить его классы и назначить их трем переменным — по одной для каждого столбца (Name, Sector и Importance).
CLabelEncoder le_name, le_sector, le_importance;
Функция Init должна быть практически безупречной: роботу надо разрешить инициализироваться только в том случае, если все файлы успешно импортированы, загружены и присвоены соответствующим массивам и объектам.
CDataFrame news_df; //Pandas like Dataframe object from pandas.mqh //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Initializing LightGBM model if (!lgbm.Init(LIGHTGBM_MODEL, ONNX_DEFAULT)) { printf("%s failed to initialize ONNX model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Assign the classes read from Binary files to the label encoders class objects if (!read_bin(le_name.m_classes, NAME_CLASSES)) { printf("%s Failed to read name classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_sector.m_classes, SECTOR_CLASSES)) { printf("%s Failed to read sector classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_importance.m_classes, IMPORTANCE_CLASSES)) { printf("%s Failed to read importance classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe)); return INIT_FAILED; } //--- Loading news from a csv file for testing the EA in the strategy tester if (MQLInfoInteger(MQL_TESTER)) { if (!news_df.from_csv(NEWS_CSV,",", false, "Time", "Name,Sector,Importance" )) { printf("%s failed to read news from a file %s, Error = %d",__FUNCTION__,NEWS_CSV,GetLastError()); return INIT_FAILED; } } //--- Configuring the CTrade class m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); return(INIT_SUCCEEDED); }
Функция from_csv, предоставляемая CDataFrame, автоматически кодирует значения datetime и строковые столбцы при соответствующей настройке.
bool CDataFrame::from_csv(string file_name,string delimiter=",",bool is_common=false, string datetime_columns="",string encode_columns="", bool verbosity=false)
Это упрощает работу с полученными данными, хранящимися в объекте news_df, поскольку нам не нудно будет вручную кодировать столбцы, извлеченные из CSV-файла.
Столбец Time будет преобразован в секунды (тип данных double) вместо datetime (тип данных datetime).
Полученные данные показаны ниже.
news_df.head();
Результаты.
QE 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | Index | Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | MI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 0 | 1672621200.00000000 | 1.06967000 | 1.06976000 | 1.06933000 | 1.06935000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 1 | 1672622100.00000000 | 1.06934000 | 1.06947000 | 1.06927000 | 1.06938000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | RI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 2 | 1672623000.00000000 | 1.06939000 | 1.06943000 | 1.06939000 | 1.06942000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 3 | 1672623900.00000000 | 1.06943000 | 1.06983000 | 1.06942000 | 1.06983000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 4 | 1672624800.00000000 | 1.06984000 | 1.06989000 | 1.06984000 | 1.06989000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 |
Именно внутри функции getNews выполняется основной объем вычислений.
vector getNews() { //--- vector v = vector::Zeros(6); ResetLastError(); if (CopyRates(Symbol(), timeframe, 0, 1, rates)<=0) { printf("%s failed to get price infromation. Error = %d",__FUNCTION__,GetLastError()); return vector::Zeros(0); } news_data.time = rates[0].time; news_data.open = rates[0].open; news_data.high = rates[0].high; news_data.low = rates[0].low; news_data.close = rates[0].close; //--- if (MQLInfoInteger(MQL_TESTER)) //If we are on the strategy tester, read the news from a dataframe object { if ((ulong)n_idx>=news_df["Time"].Size()) TesterStop(); //End the strategy tester as there are no enough news to read datetime news_time = (datetime)news_df["Time"][n_idx]; //Convert time from seconds back into datetime datetime current_time = TimeCurrent(); if (news_time >= (current_time - PeriodSeconds(timeframe)) && (news_time <= (current_time + PeriodSeconds(timeframe)))) //We ensure if the incremented news time is very close to the current time { n_idx++; //Move on to the next news if weve passed the previous one } else return vector::Zeros(0); if (n_idx>=(int)news_df["Name"].Size() || n_idx >= (int)news_df.m_values.Rows()) TesterStop(); //End the strategy tester as there are no enough news to read news_data.name = (int)news_df["Name"][n_idx]; news_data.sector = (int)news_df["Sector"][n_idx]; news_data.importance = (int)news_df["Importance"][n_idx]; news_data.actual = !MathIsValidNumber(news_df["Actual"][n_idx]) ? 0 : news_df["Actual"][n_idx]; news_data.forecast = !MathIsValidNumber(news_df["Forecast"][n_idx]) ? 0 : news_df["Forecast"][n_idx]; news_data.previous = !MathIsValidNumber(news_df["Previous"][n_idx]) ? 0 : news_df["Previous"][n_idx]; if (news_data.name==0.0) //(null) return vector::Zeros(0); } else { int all_news = CalendarValueHistory(calendar_values, rates[0].time, rates[0].time+PeriodSeconds(timeframe), NULL, NULL); //we obtain all the news with their calendar_values https://www.mql5.com/en/docs/calendar/calendarvaluehistory if (all_news<=0) return vector::Zeros(0); for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(calendar_values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { //--- Important | Encode news names into integers using the same encoder applied on the training data news_data.name = le_name.transform((string)event.name); news_data.sector = le_sector.transform((string)event.sector); news_data.importance = le_importance.transform((string)event.importance); news_data.actual = !MathIsValidNumber(calendar_values[n].GetActualValue()) ? 0 : calendar_values[n].GetActualValue(); news_data.forecast = !MathIsValidNumber(calendar_values[n].GetForecastValue()) ? 0 : calendar_values[n].GetForecastValue(); news_data.previous = !MathIsValidNumber(calendar_values[n].GetPreviousValue()) ? 0 : calendar_values[n].GetPreviousValue(); } } if (news_data.name==0.0) //(null) return vector::Zeros(0); } v[0] = news_data.name; v[1] = news_data.sector; v[2] = news_data.importance; v[3] = news_data.actual; v[4] = news_data.forecast; v[5] = news_data.previous; return v; }
Когда данная функция видит, что советник запущен в тестере стратегий, она считывает новости, хранимые в объекте DataFrame, а не пыьается получить их непосредственно с рынка (это невозможно в среде тестера).
Обратите внимание, что строки, полученные из новостей, были преобразованы в целые числа с использованием энкодеров, заполненных классами, применявшимися при обучении данных внутри функции OnInit.
Поскольку внутри функции getNews предусмотрено несколько проверок, гарантирующих возврат пустого вектора при возникновении ошибки или при отсутствии новостей в текущий момент, в функции OnTick мы проверяем, что полученный вектор не пуст. Если он не пуст, переходим к выполнению простой торговой стратегии.
void OnTick() { //--- vector x = getNews(); if (x.Size()==0) //No present news at the moment return; long signal = lgbm.predict(x).cls; //--- MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); //--- if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe }
Если модель прогнозирует, что на основании полученных новостей рынок будет расти (signal = 1), мы открываем позицию на покупку; если модель прогнозирует снижение рынка (signal = 0), открываем позицию на продажу.
Сделка будет закрыта после прохождения количества баров, равного значению lookahead на текущем таймфрейме. Значение lookahead должно совпадать с тем, которое использовалось при формировании целевой переменной в Python-скрипте. Это значит, что позиции будут удерживаться в соответствии с горизонтом прогнозирования обученной модели.
Наконец, протестируем советник в тестере стратегий MetaTrader 5 на том же периоде, на котором он обучался.
- Инструмент: EURUSD
- Таймфрейм: PERIOD_M15
- Режим моделирования: только цены открытия
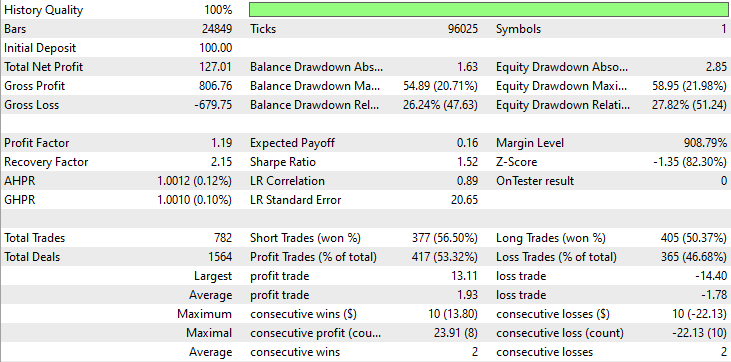
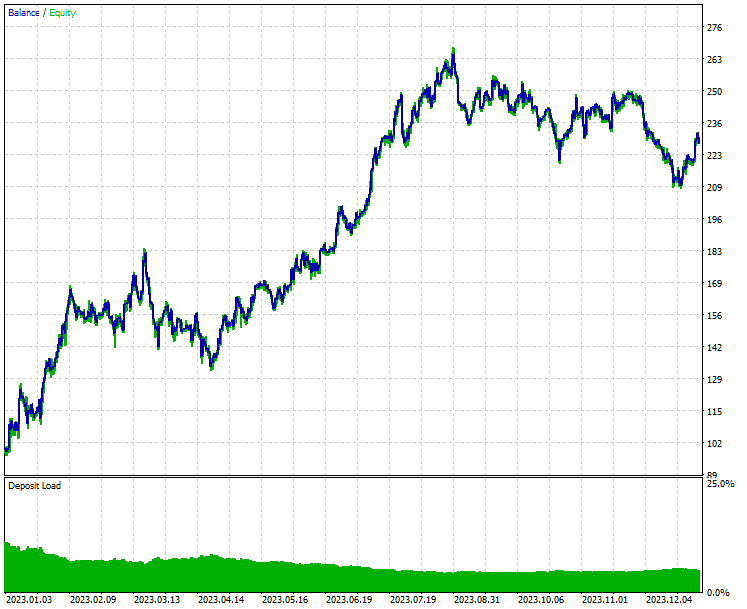
Результат из тестера стратегий.
Заключение
Как видно из результатов тестера, сочетание новостей и производительной модели машинного обучения (в данном случае LightGBM) продемонстрировало впечатляющие прогнозные и торговые результаты на том году, на котором проводилось обучение.
Хотя новости являются одним из самых сильных предикторов валютных и фондовых рынков, торговля во время выхода новостей или сразу после них сопряжена с очень высоким риском из-за непредсказуемой волатильности, возникающей в этот период. Об этом нужно помнить каждый раз, когда вы собираетесь доверить свои с трудом заработанные средства роботу, торгующему на новостях.
Можно с уверенностью сказать, что у данного проекта есть потенциал для улучшения. Поэтому поэкспериментируйте с параметрами и развивайте идею. Делитесь своими мыслями в разделе обсуждения.
Всем удачи!
Оставайтесь с нами и вносите свой вклад в разработку алгоритмов машинного обучения для языка MQL5 в этом GitHub-репозитории.
Таблица вложений
| Имя файла и путь | Описание и назначение |
|---|---|
Files\AI+NFP.mq5 | Основной советник по внедрению моделей ИИ и новостей для торговли и тестирования. |
Files\Collect News.mq5 | Скрипт для сбора новостей из MetaTrader 5 и экспорта их в CSV-файл. |
Include\Lightgbm.mqh | Библиотека для загрузки и развертывания модели LightGBM в формате ONNX. |
Include\pandas.mqh | Библиотека, содержащая DataFrame, аналогичный Pandas, для хранения и обработки данных. |
Files\* | Файлы ONNX, CSV и бинарные файлы, использованные в этой статье, находятся в этой папке. |
Python\nfp-ai.ipynb | Jupyter Notebook — это хранилище всего кода Python, используемого для обучения, очистки данных и т.д. |
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/17986
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования