Datenwissenschaft und ML (Teil 39): News + Künstliche Intelligenz, würden Sie darauf wetten?

Inhalt
- Einführung
- Sammeln der Nachrichten
- Aufbereitung von Nachrichtendaten für das Training von AI-Modellen
- Training eines KI-Modells mit Nachrichtendaten
- Nachrichten + AI Handelsroboter
- Schlussfolgerung
Einführung
Sie haben es wahrscheinlich schon gehört: Die Finanz- und Devisenmärkte werden von den Nachrichten beeinflusst, die auch als Non-Farm Payrolls (NFP) bekannt sind. Dies ist eine wahre Aussage, denn Nachrichten beschreiben laufende Ereignisse in der realen Welt.
Zu den Handelsnachrichten gehören in der Regel Wirtschaftsberichte, Unternehmensmitteilungen, geopolitische Ereignisse und Mitteilungen der Zentralbanken. Wenn diese Ereignisse eintreten (wenige Augenblicke vorher oder nachher), entstehen oft Volatilität und Handelsmöglichkeiten für verwandte Vermögenswerte und Symbole.
Da Nachrichten beschreiben, was in der Welt in einer bestimmten Region oder einem bestimmten Land passiert und welche Ergebnisse zu erwarten sind, sind sie einer der besten Prädiktoren für die Finanzmärkte. Beim EURUSD beispielsweise könnte ein steigender Verbraucherpreisindex, wie er in den Nachrichten über den Kernverbraucherpreisindex für die EUR-Währung angegeben wird, zu einem zinsbullischen EUR führen, da er häufig die Erwartungen einer strafferen Geldpolitik (Zinserhöhungen) erhöht, und könnte auch zu einem rückläufigen USD führen.
Im Gegensatz zu Nachrichten wie Unternehmensmeldungen und Wirtschaftsberichten, die sich in beide Richtungen auf die Märkte auswirken können. Einige Nachrichten, wie z.B. Naturkatastrophen, wirken sich meist negativ aus und stören die Devisenmärkte und Aktien.
Um als Händler erfolgreich zu sein, sollten wir uns nicht zu sehr auf den technischen Aspekt des Marktes verlassen, sondern auch die Nachrichten im Auge behalten, da sie einer der größten Treiber der Finanzmärkte sind.

In diesem Artikel werden wir die von MetaTrader 5 angebotenen Nachrichteninformationen für KI-Modelle nutzen und sehen, ob diese leistungsstarke Kombination im algorithmischen Handel wirklich etwas bringt.
Sammeln der Nachrichten
Dies ist der erste Prozess, den wir in unserem Projekt durchführen müssen.
Das Sammeln von Nachrichten kann schwierig und knifflig sein. Es gibt eine Reihe von Dingen, die wir sorgfältig bedenken müssen, einschließlich des Zeitrahmens für die Datenerhebung, des Instruments (Symbol) und des Umgangs mit leeren/Nicht-eine-Zahl-Variablen (NaN).
Nachfolgend finden Sie die Datenstruktur mit den Variablen, die wir für die Speicherung der zu sammelnden Nachrichteninformationen verwenden werden.
struct news_data_struct { datetime time[]; //News release time string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value }
Diese Struktur stellt einige der von MqlCalendarEvent und MqlCalendarValue bereitgestellten Nachrichtenattribute dar.
Im Folgenden wird gezeigt, wie wir die Nachrichten sammeln, indem wir verschiedene Balken in der Geschichte durchlaufen, um die Nachrichten zu erhalten.
//--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } }
Mit diesem Code erhalten wir zwar die gewünschten Nachrichten, aber wir müssen auch die Werte für Open, High, Low und Close (OHLC) zum Zeitpunkt der Nachrichtenveröffentlichung erfassen. Diese Werte werden bei der Analyse und bei der Erstellung der Zielvariablen für das überwachte maschinelle Lernen hilfreich sein.
Außerdem benötigen wir die Möglichkeit, diese Informationen zur externen Verwendung in einer CSV-Datei zu speichern.
Nachstehend finden Sie die vollständige Funktion zum Sammeln der Nachrichten.
void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
Die Speicherung der Informationen in einer CSV-Datei erfolgt außerhalb der Schleife, sodass wir die Nachrichten sammeln, wenn sie eingetreten sind und wenn nicht. Dies ist wichtig, weil wir diese Balken ohne Nachrichten benötigen, um die Auswirkungen der Nachrichten vor und nach ihrem Eintreten zu bewerten.
Ich wählte als Startdatum den 01.01.2023 und als Enddatum den 31.12.2023, also ein Jahr voller Nachrichten und anderer Handelsinformationen.
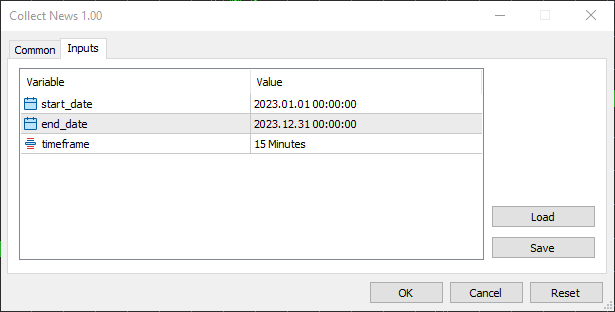
Ich habe den 15-Minuten-Zeitrahmen gewählt, weil ich sehe, dass die meisten Händler diesen Zeitrahmen für die Erstellung von Nachrichtenfiltern und die Arbeit mit nachrichtenbasierten Strategien im Allgemeinen verwenden. Es ist ein optimales Gleichgewicht zwischen dem Erfassen aussagekräftiger Kursreaktionen nach der Nachricht und dem Herausfiltern von Marktgeräuschen, die in Zeitrahmen unterhalb der 15 Minuten zu finden sind.
Aufbereitung von Nachrichtendaten für das Training von KI-Modellen
In einem Python-Skript (Jupyter Notebook) importieren wir zunächst die CSV-Datei mit den Nachrichtendaten.
df = pd.read_csv("/kaggle/input/nfp-forexdata/EURUSD.PERIOD_M15.News.csv") df.head(5)
Ausgabe:
| Time | Open | High | Low | Close | Name | Sector | Bedeutung | Aktuell | Prognose | Vorherig | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
Da Nachrichtendaten immer mit NaN-Werten in aktuelle, vorheriger und prognostizierter Wert verbunden sind. Wir müssen explizit prüfen, ob sich ein NaN-Wert in die CSV-Datei eingeschlichen hat, obwohl wir die Prüfungen haben, die sicherstellen, dass keine NaN-Werte in die Datei im Collect News MQL5-Skript eingefügt werden.
df.info()
Ausgabe:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 24848 entries, 0 to 24847 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Time 24848 non-null object 1 Open 24848 non-null float64 2 High 24848 non-null float64 3 Low 24848 non-null float64 4 Close 24848 non-null float64 5 Name 24848 non-null object 6 Sector 24848 non-null object 7 Importance 24848 non-null object 8 Actual 24848 non-null float64 9 Forecast 24848 non-null float64 10 Previous 24848 non-null float64 dtypes: float64(7), object(4) memory usage: 2.1+ MB
Herstellung der Zielvariablen
Beim überwachten maschinellen Lernen benötigen wir eine Zielvariable, die das Modell verwenden kann, um die Beziehungen zwischen den Prädiktoren und dieser Zielvariable abzubilden.
Wir wissen, dass die Märkte nach der Veröffentlichung von Nachrichten dazu neigen, schnell in die eine oder andere Richtung zu reagieren, je nachdem, wie die Händler agieren und wie sie auf die Nachrichten reagieren. Die Herausforderung besteht jedoch darin, festzustellen, wie lange wir davon ausgehen können, dass das, was auf dem Markt passiert, tatsächlich auf die kürzlich veröffentlichten Nachrichten zurückzuführen ist.
Diejenigen, die den Handel nach der Veröffentlichung von Nachrichten verhindern, halten sich oft 15 bis 30 Minuten nach der Veröffentlichung von Nachrichten zurück, weil sie glauben, dass nach dieser Anzahl von Minuten die durch die Nachricht verursachte Wirkung abgeklungen ist.
Da die Märkte nach der Veröffentlichung von Nachrichten eine enorme Volatilität und unerwartete Ausschläge aufweisen, die zu einer Menge Lärm führen, erstellen wir die Zielvariable für 15 Balken im Voraus (etwa 4 Stunden im Voraus).
lookahead = 15 clean_df = df.copy() clean_df["Future Close"] = df["Close"].shift(-lookahead) clean_df.dropna(inplace=True) # drop nan caused by shifting operation clean_df["Signal"] = (clean_df["Future Close"] > clean_df["Close"]).astype(int) # if the future close > current close = bullish movement otherwise bearish movement clean_df
Entfernen von Zeilen ohne Neuigkeiten in den Daten
Nachdem wir die Zielvariable erstellt haben, können wir alle Zeilen löschen, in denen keine Nachrichten veröffentlicht wurden, da wir unser Modell nur mit Zeilen füttern wollen, die Nachrichten enthalten.
Wir filtern alle Zeilen mit dem Wert (null) in der Spalte Name (eine Spalte, die die Namen der Nachrichten enthält).
clean_df = clean_df[clean_df['Name'] != '(null)'] clean_df
Kodierung von Zeichenketten im Datenrahmen
Da Strings in vielen Modellen für maschinelles Lernen nicht unterstützt werden, müssen wir String-Werte in Ganzzahlen kodieren.
Zeichenketten können in Spalten gefunden werden: Name, Sektor und Bedeutung.
from sklearn.preprocessing import LabelEncoder
categorical_cols = ['Name', 'Sector', 'Importance'] label_encoders = {} encoded_df = clean_df.copy() for col in categorical_cols: le = LabelEncoder() encoded_df[col] = le.fit_transform(clean_df[col]) # Save classes to binary file (.bin) with open(f"{col}_classes.bin", 'wb') as f: np.save(f, le.classes_, allow_pickle=True) label_encoders[col] = le encoded_df.head(5)
Alternativ können Sie die LabelEncoder in eine Pipeline einfügen, um die Handhabung zu erleichtern.
Es ist sehr wichtig, die vom Objekt des Label-Encoders erkannten Klassen für jede kodierte Spalte zu speichern, da wir dieselben Informationen bei der Kodierung von Nachrichten in unseren endgültigen, mit der Sprache MQL5 erstellten Programmen benötigen.
Das liegt vor allem daran, dass wir mit unseren Kodierungsmustern konsistent sein wollen, und auch daran, dass wir wachsam bleiben und Fehler auslösen, wenn der Kodierer auf Nachrichten stößt, auf die er nicht trainiert wurde, da unerwartete Nachrichten in der Welt immer vorkommen können.
Ausgabe:
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | Future Close | Signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06880 | 0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06888 | 0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06891 | 0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06892 | 0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06897 | 0 |
Teilen wir nun die Daten in X- und Y-Sätze auf und unterteilen diese beiden Sätze anschließend in Trainings- und Testproben.
X = encoded_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "Future Close", "Signal" ]) y = encoded_df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 42, shuffle=True)
Beachten Sie, dass wir alle Spalten außer denen, die Informationen über die Nachrichten enthalten, weggelassen haben.
Trainieren eines AI-Modells anhand von Nachrichtendaten
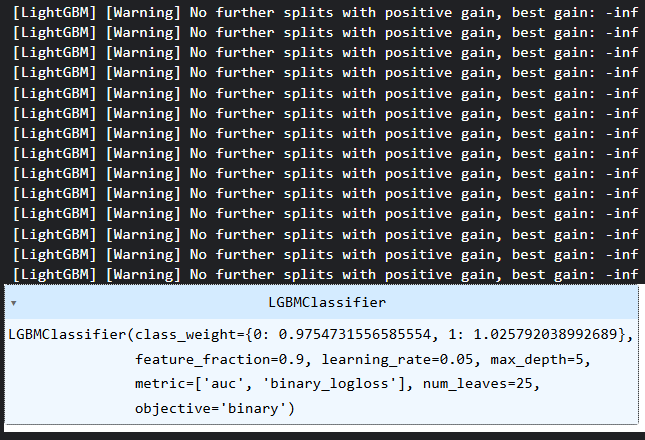
Ich habe mich für ein Light Gradient Boosting Machine (LightGBM) Modell entschieden, weil es einfach, schnell und genau ist. Ganz zu schweigen davon, dass es sich um ein baumbasiertes Entscheidungsmodell handelt, das gut mit kategorialen Daten wie den uns vorliegenden funktioniert.
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # For binary classification (use 'regression' for regression tasks)
'metric': ['auc','binary_logloss'], # Evaluation metric
'num_leaves': 25, # Number of leaves in one tree
'n_estimators' : 100, # number of trees
'max_depth': 5,
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9 # Fraction of features to be used for each boosting round
}
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
weight_dict = dict(zip(np.unique(y_train), class_weights))
model = lgb.LGBMClassifier(**params, class_weight=weight_dict)
# Fit the model to the training data
model.fit(X_train, y_train) Klassengewichte wurden als Maßnahme eingeführt, um Verzerrungen in den Entscheidungen der Modelle auszugleichen.
Ausgabe:
Nachfolgend finden Sie den Klassifizierungsbericht mit den Vorhersagen des Modells für die Testprobe.
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 Classification Report precision recall f1-score support 0 0.59 0.52 0.55 1116 1 0.55 0.61 0.58 1049 accuracy 0.56 2165 macro avg 0.57 0.57 0.56 2165 weighted avg 0.57 0.56 0.56 2165
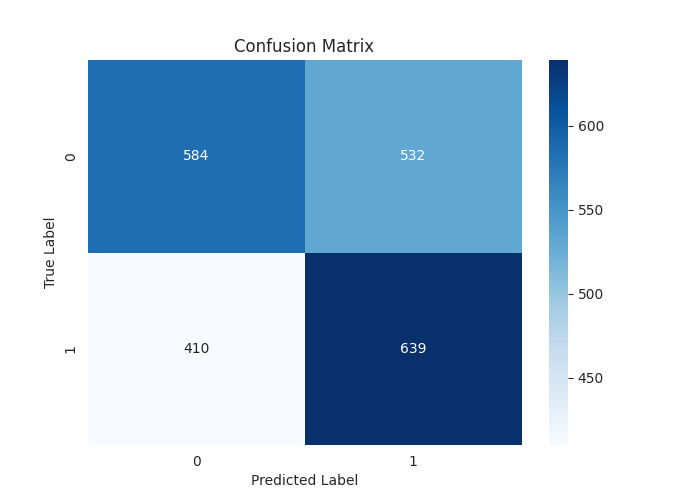
Eine beeindruckende Gesamtgenauigkeit von 0,56 von 1,0 bei den Testdaten. Das ist etwas, was man nicht so einfach erreichen kann, wenn man Modelle für maschinelles Lernen mit „technischen Daten“ trainiert.
Im Moment ist das Modell, das wir gerade erstellt haben, eine Blackbox, wir wissen nicht, wie sich die Nachrichten auf die endgültigen Entscheidungen des Modells auswirken. Mal sehen, was uns das Modell über seine Eigenschaften erzählt.
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train) Ausgabe:
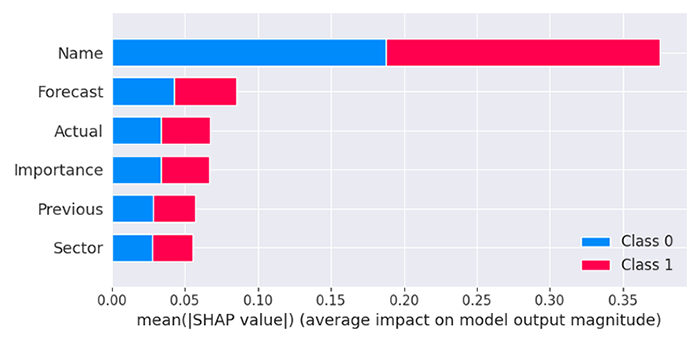
Das Modell zeigt, dass die Spalte „Name“ von allen Spalten den größten Einfluss hat, was bedeutet, dass Nachrichten mit bestimmten Namen die Marktreaktion im Vergleich zu anderen Vorhersagefaktoren stark beeinflussen.
Die prognostizierten Werte sind die zweitwichtigsten Werte für unser Modell, gefolgt von den Werten für die Aktualität, die Wichtigkeit, die Vorgeschichte und den Sektor der Nachrichten.
Damit ist immer noch nicht viel geklärt, denn es gibt viele Möglichkeiten, die Auswirkungen jedes einzelnen Wertes innerhalb eines Merkmals auf das Modell mit SHAP zu bestimmen, z. B. die Bewertung der ersten Zeile in den Daten.
i=0 shap.force_plot(explainer.expected_value[1], shap_values[1][i], X_train.iloc[i], matplotlib=True)
Ausgabe:
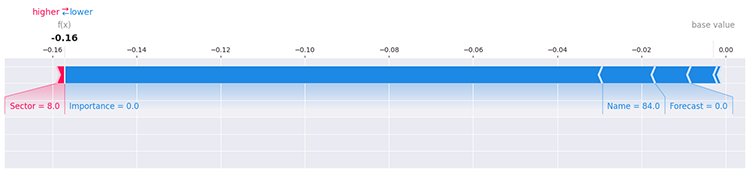
Weitere Informationen und Einzelheiten zur Erkundung des Modells finden Sie in der Dokumentation von SHAPLEY.
Schließlich müssen wir dieses Modell zur externen Verwendung im ONNX-Format speichern.
# Registering ONNX converter update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final conversion model_onnx = convert_sklearn( model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 14, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.EURUSD.news.M15.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
Nachrichten + AI-Handelsroboter (EA)
Damit dieser Handelsroboter funktioniert, benötigen wir eine Reihe von Abhängigkeiten und Dateien.
#define NEWS_CSV "EURUSD.PERIOD_M15.News.csv" //For simulating news on the strategy tester, making testing possible //--- Encoded classes for the columns stored in a binary file #define SECTOR_CLASSES "Sector_classes.bin" #define NAME_CLASSES "Name_classes.bin" #define IMPORTANCE_CLASSES "Importance_classes.bin" #define LIGHTGBM_MODEL "lightgbm.EURUSD.news.M15.onnx" //AI model //--- Tester files #property tester_file NEWS_CSV #property tester_file SECTOR_CLASSES #property tester_file NAME_CLASSES #property tester_file IMPORTANCE_CLASSES #property tester_file LIGHTGBM_MODEL
Wir müssen die Verwendung dieser Dateien im Strategietester aktivieren, weil wir sie dann am meisten brauchen.
//--- Dependencies #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Lightgbm.mqh> //For importing LightGBM model CLightGBMClassifier lgbm; CTrade m_trade; CPositionInfo m_position;
Wir benötigen dieselbe Nachrichtenstruktur wie in Collect News.mq5 (ein Skript, das wir zum Sammeln von Nachrichtendaten verwendet haben).
MqlRates rates[]; struct news_data_struct { datetime time; double open; double high; double low; double close; int name; int sector; int importance; double actual; double forecast; double previous; } news_data;
Da wir die LabelEncoder in MQL5 haben wie die, die wir zur Transformation von String-Features in Python verwendet haben, können wir ihre Klasse laden und sie drei Variablen für jede Spalte zuweisen (Name, Sektor und Wichtigkeit).
CLabelEncoder le_name, le_sector, le_importance;
Die Funktion Init muss nahezu perfekt sein. Der Roboter sollte erst dann initialisieren dürfen, wenn alle Dateien erfolgreich importiert, geladen und den jeweiligen Arrays und Objekten zugewiesen wurden.
CDataFrame news_df; //Pandas like Dataframe object from pandas.mqh //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Initializing LightGBM model if (!lgbm.Init(LIGHTGBM_MODEL, ONNX_DEFAULT)) { printf("%s failed to initialize ONNX model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Assign the classes read from Binary files to the label encoders class objects if (!read_bin(le_name.m_classes, NAME_CLASSES)) { printf("%s Failed to read name classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_sector.m_classes, SECTOR_CLASSES)) { printf("%s Failed to read sector classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_importance.m_classes, IMPORTANCE_CLASSES)) { printf("%s Failed to read importance classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe)); return INIT_FAILED; } //--- Loading news from a csv file for testing the EA in the strategy tester if (MQLInfoInteger(MQL_TESTER)) { if (!news_df.from_csv(NEWS_CSV,",", false, "Time", "Name,Sector,Importance" )) { printf("%s failed to read news from a file %s, Error = %d",__FUNCTION__,NEWS_CSV,GetLastError()); return INIT_FAILED; } } //--- Configuring the CTrade class m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); return(INIT_SUCCEEDED); }
Die von CDataFrame bereitgestellte Funktion from_csv kodiert automatisch Datumswerte und Textspalten, wenn sie dazu aufgefordert werden.
bool CDataFrame::from_csv(string file_name,string delimiter=",",bool is_common=false, string datetime_columns="",string encode_columns="", bool verbosity=false)
Dies vereinfacht die Arbeit mit den in einem news_df-Objekt gespeicherten Daten, da wir die aus der CSV-Datei extrahierten Spalten nicht unbedingt manuell kodieren müssen.
Die Spalte Time wird in Sekunden (Double-Datentyp) statt in datetime (Datentyp datetime) konvertiert.
Sie können die empfangenen Daten wie folgt anzeigen.
news_df.head();
Ausgabe:
QE 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | Index | Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | MI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 0 | 1672621200.00000000 | 1.06967000 | 1.06976000 | 1.06933000 | 1.06935000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 1 | 1672622100.00000000 | 1.06934000 | 1.06947000 | 1.06927000 | 1.06938000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | RI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 2 | 1672623000.00000000 | 1.06939000 | 1.06943000 | 1.06939000 | 1.06942000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 3 | 1672623900.00000000 | 1.06943000 | 1.06983000 | 1.06942000 | 1.06983000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 4 | 1672624800.00000000 | 1.06984000 | 1.06989000 | 1.06984000 | 1.06989000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 |
Innerhalb der Funktion getNews finden die meisten Berechnungen statt.
vector getNews() { //--- vector v = vector::Zeros(6); ResetLastError(); if (CopyRates(Symbol(), timeframe, 0, 1, rates)<=0) { printf("%s failed to get price infromation. Error = %d",__FUNCTION__,GetLastError()); return vector::Zeros(0); } news_data.time = rates[0].time; news_data.open = rates[0].open; news_data.high = rates[0].high; news_data.low = rates[0].low; news_data.close = rates[0].close; //--- if (MQLInfoInteger(MQL_TESTER)) //If we are on the strategy tester, read the news from a dataframe object { if ((ulong)n_idx>=news_df["Time"].Size()) TesterStop(); //End the strategy tester as there are no enough news to read datetime news_time = (datetime)news_df["Time"][n_idx]; //Convert time from seconds back into datetime datetime current_time = TimeCurrent(); if (news_time >= (current_time - PeriodSeconds(timeframe)) && (news_time <= (current_time + PeriodSeconds(timeframe)))) //We ensure if the incremented news time is very close to the current time { n_idx++; //Move on to the next news if weve passed the previous one } else return vector::Zeros(0); if (n_idx>=(int)news_df["Name"].Size() || n_idx >= (int)news_df.m_values.Rows()) TesterStop(); //End the strategy tester as there are no enough news to read news_data.name = (int)news_df["Name"][n_idx]; news_data.sector = (int)news_df["Sector"][n_idx]; news_data.importance = (int)news_df["Importance"][n_idx]; news_data.actual = !MathIsValidNumber(news_df["Actual"][n_idx]) ? 0 : news_df["Actual"][n_idx]; news_data.forecast = !MathIsValidNumber(news_df["Forecast"][n_idx]) ? 0 : news_df["Forecast"][n_idx]; news_data.previous = !MathIsValidNumber(news_df["Previous"][n_idx]) ? 0 : news_df["Previous"][n_idx]; if (news_data.name==0.0) //(null) return vector::Zeros(0); } else { int all_news = CalendarValueHistory(calendar_values, rates[0].time, rates[0].time+PeriodSeconds(timeframe), NULL, NULL); //we obtain all the news with their calendar_values https://www.mql5.com/en/docs/calendar/calendarvaluehistory if (all_news<=0) return vector::Zeros(0); for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(calendar_values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { //--- Important | Encode news names into integers using the same encoder applied on the training data news_data.name = le_name.transform((string)event.name); news_data.sector = le_sector.transform((string)event.sector); news_data.importance = le_importance.transform((string)event.importance); news_data.actual = !MathIsValidNumber(calendar_values[n].GetActualValue()) ? 0 : calendar_values[n].GetActualValue(); news_data.forecast = !MathIsValidNumber(calendar_values[n].GetForecastValue()) ? 0 : calendar_values[n].GetForecastValue(); news_data.previous = !MathIsValidNumber(calendar_values[n].GetPreviousValue()) ? 0 : calendar_values[n].GetPreviousValue(); } } if (news_data.name==0.0) //(null) return vector::Zeros(0); } v[0] = news_data.name; v[1] = news_data.sector; v[2] = news_data.importance; v[3] = news_data.actual; v[4] = news_data.forecast; v[5] = news_data.previous; return v; }
Wenn diese Funktion erkennt, dass sich der EA im Strategietester befindet, liest sie die im Dataframe-Objekt gespeicherten Nachrichten, anstatt sie direkt vom Markt zu beziehen, was in der Testerumgebung nicht möglich ist.
Beachten Sie, dass die von den Nachrichten empfangenen Zeichenketten mithilfe von Kodierern, die mit den für die Trainingsdaten verwendeten Klassen gefüllt wurden, in der OnInit-Funktion in Ganzzahlen umgewandelt wurden.
Da wir innerhalb der Funktion getNews einige Überprüfungen durchführen, um sicherzustellen, dass die Funktion einen leeren Vektor zurückgibt, wenn ein Fehler auftritt oder wenn derzeit keine Nachrichten empfangen wurden. In der Funktion OnTick wird geprüft, ob der empfangene Vektor nicht leer ist. Ist dies nicht der Fall, fahren wir mit einer einfachen Handelsstrategie fort.
void OnTick() { //--- vector x = getNews(); if (x.Size()==0) //No present news at the moment return; long signal = lgbm.predict(x).cls; //--- MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); //--- if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe }
Wenn das Modell vorhersagt, dass der Markt nach den eingegangenen Nachrichten nach oben tendieren wird (Signal = 1), eröffnen wir ein Kaufgeschäft, und wenn das Modell vorhersagt, dass der Markt nach unten gehen wird (Signal = 0), eröffnen wir ein Verkaufsgeschäft.
Ein Handel wird geschlossen, nachdem die Anzahl der Bars, die dem Lookahead-Wert entsprechen, im aktuellen Zeitrahmen vergangen ist. Der Lookahead-Wert muss derselbe sein, der bei der Erstellung einer Zielvariablen in einem Python-Skript verwendet wird. Dadurch wird sichergestellt, dass wir die Positionen entsprechend dem Vorhersagehorizont des trainierten Modells halten.
Abschließend wollen wir diesen Handelsroboter mit dem gleichen Zeitraum testen, für den er im Strategietester trainiert wurde.
- Symbol: EURUSD
- Zeitrahmen: PERIOD_M15
- Modellierung: Nur Öffnungspreise (Open Prices Only)
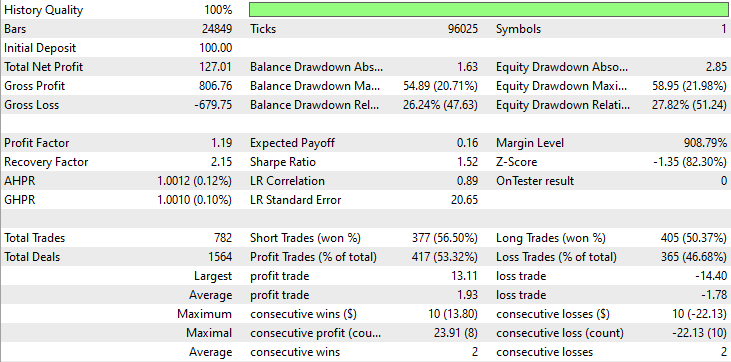
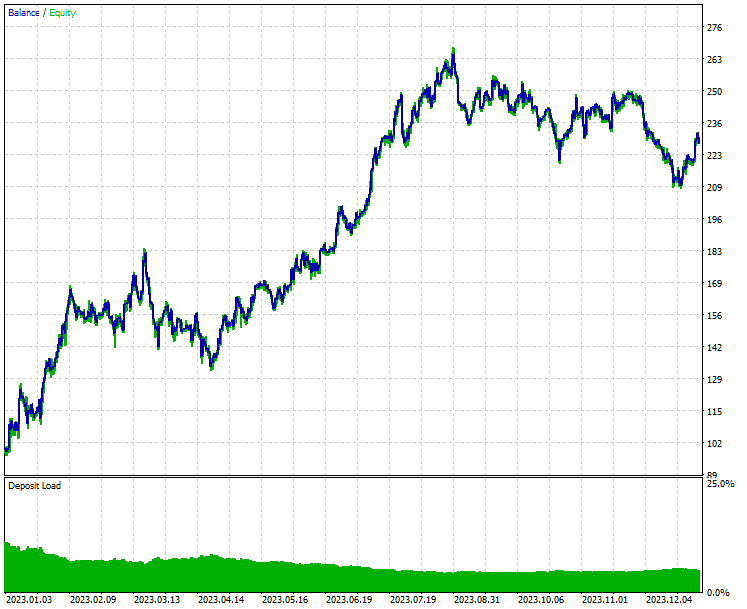
Ergebnis des Strategietesters.
Schlussfolgerung
Wie Sie aus den Ergebnissen des Strategietesters ersehen können, hat die Kombination aus Nachrichten und einem leistungsfähigen maschinellen Lernmodell (LightGBM) beeindruckende Vorhersage- und Handelsergebnisse für das Jahr erbracht, für das es trainiert wurde.
Während Nachrichten einer der stärksten Prädiktoren für die Devisen- und Aktienmärkte sind, ist der Handel während oder kurz nach der Veröffentlichung von Nachrichten aufgrund der unerwarteten Volatilität, die in diesem Zeitraum auf dem Markt auftritt, sehr riskant. Sie müssen sich dessen immer bewusst sein, wenn Sie Ihr hart verdientes Geld einem Nachrichten-Handelsroboter überlassen wollen.
Man kann sagen, dass dieses Projekt noch verbesserungsfähig ist, also fühlen Sie sich frei, ein paar Einstellungen zu verändern und diese Idee zu verbessern. Bitte teilen Sie uns Ihre Meinung im Diskussionsbereich mit.
Mit freundlichen Grüßen.
Bleiben Sie dran und tragen Sie zur Entwicklung von Algorithmen für maschinelles Lernen für die Sprache MQL5 in diesem GitHub Repository bei.
Tabelle der Anhänge
| Dateiname & Pfad | Beschreibung und Verwendung |
|---|---|
Files\AI+NFP.mq5 | Der wichtigste Expert Advisor für den Einsatz von KI-Modellen und Nachrichten zu Handels- und Testzwecken. |
Files\Collect News.mq5 | Ein Skript zum Sammeln von Nachrichten aus MetaTrader 5 und deren Export in eine CSV-Datei. |
Include\Lightgbm.mqh | Eine Bibliothek zum Laden und Bereitstellen des LightGBM-Modells im ONNX-Format. |
Include\pandas.mqh | Eine Bibliothek, die Pandas-ähnliche Datenrahmen für die Speicherung und Manipulation von Daten enthält. |
Files\* | Die in diesem Artikel verwendeten ONNX-, CSV- und Binärdateien befinden sich in diesem Ordner. |
Python\nfp-ai.ipynb | Das Jupyter-Notebook von Python, in dem der gesamte Python-Code für Training, Datenbereinigung usw. zu finden ist. |
Übersetzt aus dem Englischen von MetaQuotes Ltd.
Originalartikel: https://www.mql5.com/en/articles/17986
Warnung: Alle Rechte sind von MetaQuotes Ltd. vorbehalten. Kopieren oder Vervielfältigen untersagt.
Dieser Artikel wurde von einem Nutzer der Website verfasst und gibt dessen persönliche Meinung wieder. MetaQuotes Ltd übernimmt keine Verantwortung für die Richtigkeit der dargestellten Informationen oder für Folgen, die sich aus der Anwendung der beschriebenen Lösungen, Strategien oder Empfehlungen ergeben.

- Freie Handelsapplikationen
- Über 8.000 Signale zum Kopieren
- Wirtschaftsnachrichten für die Lage an den Finanzmärkte
Sie stimmen der Website-Richtlinie und den Nutzungsbedingungen zu.