Data Science and ML (Part 39): News + Artificial Intelligence, Would You Bet on it?

Contents
- Introduction
- Collecting the news
- Preparing news data for AI Models Training
- Training an AI model on news data
- News + AI Trading robot
- Conclusion
Introduction
You've probably heard it: financial and forex markets are driven and impacted by the news also known as Non-Farm Payrolls (NFP). This is a true statement, as news describes ongoing events in the real world.
Trading news usually includes economic reports, corporate announcements, geopolitical events, and central bank communications. Often, when these news events occur (a few moments before or after) create volatility and trading opportunities across related assets and symbols.
Since news describes what's happening in the world in a specific region or country and their expected outcomes, they are one of the best predictors of financial markets. For example, on EURUSD, a rising CPI indicated on the Core CPI news for the EUR currency could result in a bullish EUR as it often increases expectations of tighter monetary policy (rate hikes) and could also lead to a bearish USD.
Unlike news such as corporate announcements and economic reports which can have an impact in either direction in the markets. Some news such as, natural disasters tends to negatively impact and disrupt forex markets and stocks mostly.
To become successful traders, we shouldn't rely too much on a technical aspect of the market, we should also be mindful of the news as they are one of the biggest drivers of financial markets.

That being said, we know that news serves as one of, if not the most prominent determiner of the markets, in this article we are going to use news information offered by MetaTrader 5 to AI models and see if this powerful combination is the real deal in algorithmic trading.
Collecting the News
This is the first process we have to perform in our project.
Collecting the news can be challenging and tricky, there are a couple of things that we must consider carefully including, the timeframe for data collection, the instrument (symbol), and handling the presence of empty/Not a Number (NaN) variables.
Below is the data structure containing variables that we'll use for storing news information we are about to collect.
struct news_data_struct { datetime time[]; //News release time string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value }
This structure represents some of the news attributes provided by MqlCalendarEvent and MqlCalendarValue.
Below is how we collect the news by iterating across various bars in history to obtain the news.
//--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } }
While this code gets us the news we want, we also need to collect Open, High, Low, and Close (OHLC) values at the time of the news release. These values will be helpful in analysis and when it comes to making the target variable for supervised machine learning.
We also need the functionality for saving this information to a CSV file for external usage.
Below is the complete function for collecting the news.
void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
The process of saving the information to a CSV file is done outside the loop so that we collect the news when they have occurred and when they haven't. This is important because we need those bars without news for assessing the impact of the news before and after they have occurred.
I chose the starting date to 01.01.2023 and the end date to 31.12.2023, a year worth of news and other trading information.
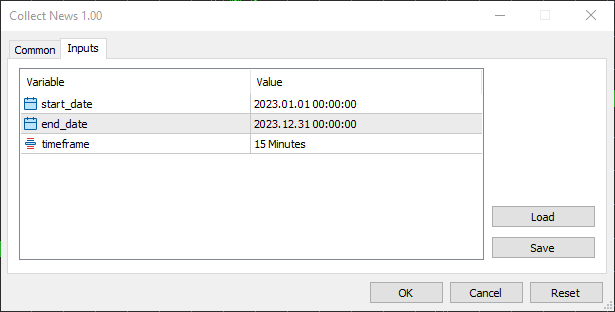
I chose the 15 minutes timeframe because that's what I see most traders use in crafting news filters and working with news-based strategies in general. It is an optimal balance between capturing meaningful price reactions after the news and filtering out market noises which can be found in timeframes lower than the 15 minutes.
Preparing News Data for AI Models Training
Inside a Python script (Jupyter Notebook), we start by importing the CSV file containing news data.
df = pd.read_csv("/kaggle/input/nfp-forexdata/EURUSD.PERIOD_M15.News.csv") df.head(5)
Outputs.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | New Year's Day | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
Since news data is always associated with NaN values in Actual, Previous, and Forecast values. We have to explicitly check if any NaN value slipped into the CSV file, despite having the checks to ensure no NaN values are inserted in the file inside Collect News MQL5 script.
df.info()
Outputs.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 24848 entries, 0 to 24847 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Time 24848 non-null object 1 Open 24848 non-null float64 2 High 24848 non-null float64 3 Low 24848 non-null float64 4 Close 24848 non-null float64 5 Name 24848 non-null object 6 Sector 24848 non-null object 7 Importance 24848 non-null object 8 Actual 24848 non-null float64 9 Forecast 24848 non-null float64 10 Previous 24848 non-null float64 dtypes: float64(7), object(4) memory usage: 2.1+ MB
Making the target variable
In supervised machine learning, we need a target variable that the model can use to map the relationships between the predictors and this target variable.
We know that once the news is released, the markets tend to react rapidly heading into either direction based on traders' actions and reactions to the news but, the challenge here is determining how long could we consider what's happening in the market is actually due to the recently released news?
Those who prevent trading after news releases often abstain from trading activities for 15 - 30 minutes after news release believing that after this number of minutes the impact caused by the news has weared off.
Since after news releases the markets experiences huge volatility and unexpected spikes leading to a plenty of noise, let's create the target variable for 15 bars ahead (approximately 4 hours ahead in time).
lookahead = 15 clean_df = df.copy() clean_df["Future Close"] = df["Close"].shift(-lookahead) clean_df.dropna(inplace=True) # drop nan caused by shifting operation clean_df["Signal"] = (clean_df["Future Close"] > clean_df["Close"]).astype(int) # if the future close > current close = bullish movement otherwise bearish movement clean_df
Removing rows without news in the data
After making the target variable, we can go ahead and drop all rows where there were no news released, we want fo feed our model with all rows containing news only.
We filter all rows with the value (null) in the Name column (a column for holding news names).
clean_df = clean_df[clean_df['Name'] != '(null)'] clean_df
Encoding strings in the dataframe
Since strings aren't supported in many machine learning models, we have to encode string values into integers.
Strings can be found in columns: Name, Sector, and Importance.
from sklearn.preprocessing import LabelEncoder
categorical_cols = ['Name', 'Sector', 'Importance'] label_encoders = {} encoded_df = clean_df.copy() for col in categorical_cols: le = LabelEncoder() encoded_df[col] = le.fit_transform(clean_df[col]) # Save classes to binary file (.bin) with open(f"{col}_classes.bin", 'wb') as f: np.save(f, le.classes_, allow_pickle=True) label_encoders[col] = le encoded_df.head(5)
Alternatively, you can wrap the LabelEncoder inside a Pipeline for ease of use.
It is very crucial to save the classes detected by the label encoder object for each column encoded because we need the same information when encoding news inside our final programs made with the MQL5 language.
This is mainly because we want to be consistent with our encoding patterns also to stay alert and throw errors when the encoder encounters news it wasn't trained on as unexpected news are bound to happend in the world.
Outputs.
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | Future Close | Signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06880 | 0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06888 | 0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06891 | 0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06892 | 0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06897 | 0 |
Now let's split the data into X and Y sets, followed by splitting these two sets into training and testing samples.
X = encoded_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "Future Close", "Signal" ]) y = encoded_df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 42, shuffle=True)
Notice that we dropped all columns except the ones containing information about the news.
Training an AI Model on News Data
I chose to train a Light Gradient Boosting Machine (LightGBM) model because it's simple, fast, and accurate. Not to mention it is a decision tree-based model which works fine with categorical data like the one we currently have.
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # For binary classification (use 'regression' for regression tasks)
'metric': ['auc','binary_logloss'], # Evaluation metric
'num_leaves': 25, # Number of leaves in one tree
'n_estimators' : 100, # number of trees
'max_depth': 5,
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9 # Fraction of features to be used for each boosting round
}
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
weight_dict = dict(zip(np.unique(y_train), class_weights))
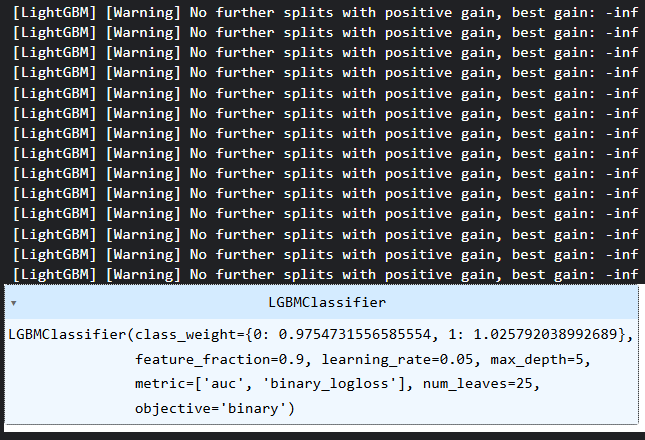
model = lgb.LGBMClassifier(**params, class_weight=weight_dict)
# Fit the model to the training data
model.fit(X_train, y_train) Class weights were introduced as a measure to counter bias in models' decisions.
Outputs.
Below is the classification report of the predictions made by the model on the testing sample.
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 Classification Report precision recall f1-score support 0 0.59 0.52 0.55 1116 1 0.55 0.61 0.58 1049 accuracy 0.56 2165 macro avg 0.57 0.57 0.56 2165 weighted avg 0.57 0.56 0.56 2165
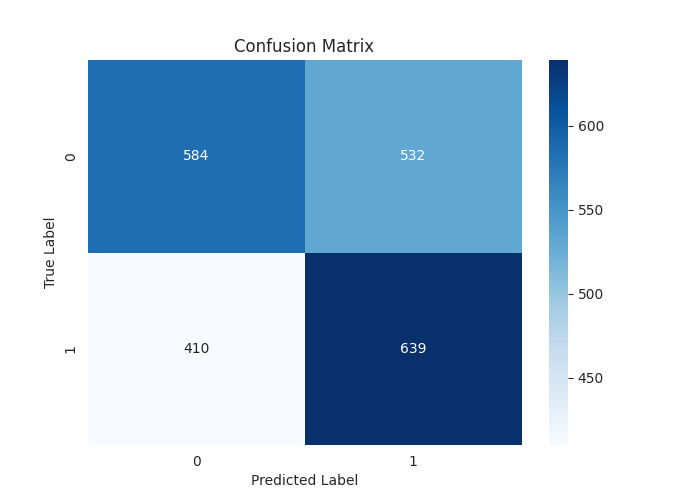
An impressive overall accuracy of 0.56 out of 1.0 on the testing data. This is something you cannot achieve easily when training machine learning models using the "Technical data".
Right now, the model we just built is a black box, we don't know how the news impacts the final decisions made by the model. Let's see what story does the model tell us on its features.
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train) Outputs.
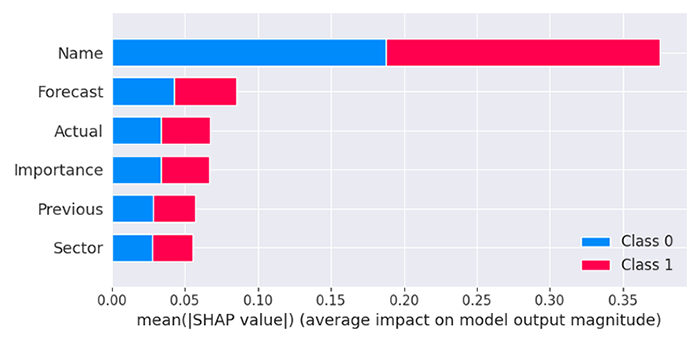
The model finds that the column Name is the most impactful of all columns, meaning that some news with specific names impacts the market reaction in a big way compared to other predictiors.
The forecasted values are the second most important values to our model, followed by Actual, Importance, Previous, and Sector of the news.
This still doesn't clarify much, there are a plenty of ways to determine the impact each unique value within a feature impacts the model using SHAP, for example assessing the first row in a data.
i=0 shap.force_plot(explainer.expected_value[1], shap_values[1][i], X_train.iloc[i], matplotlib=True)
Outputs.
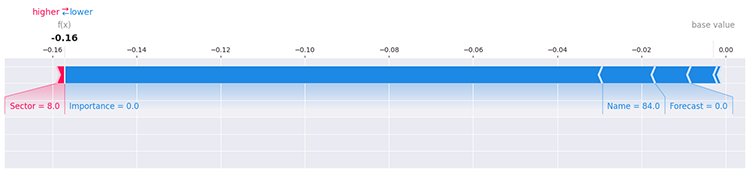
For more information and details on exploring the model, kindly refer to SHAPLEY documentation.
Finally, we have to save this model in ONNX format for external usage.
# Registering ONNX converter update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final conversion model_onnx = convert_sklearn( model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 14, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.EURUSD.news.M15.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
News + AI Trading Robot (EA)
For this trading robot to work, we need a couple of dependencies and files.
#define NEWS_CSV "EURUSD.PERIOD_M15.News.csv" //For simulating news on the strategy tester, making testing possible //--- Encoded classes for the columns stored in a binary file #define SECTOR_CLASSES "Sector_classes.bin" #define NAME_CLASSES "Name_classes.bin" #define IMPORTANCE_CLASSES "Importance_classes.bin" #define LIGHTGBM_MODEL "lightgbm.EURUSD.news.M15.onnx" //AI model //--- Tester files #property tester_file NEWS_CSV #property tester_file SECTOR_CLASSES #property tester_file NAME_CLASSES #property tester_file IMPORTANCE_CLASSES #property tester_file LIGHTGBM_MODEL
We have to enable the use of these files in the strategy tester because that's when we need them the most.
//--- Dependencies #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Lightgbm.mqh> //For importing LightGBM model CLightGBMClassifier lgbm; CTrade m_trade; CPositionInfo m_position;
We need the same news structure as the one we used inside Collect News.mq5 (a script we used for collecting news data).
MqlRates rates[]; struct news_data_struct { datetime time; double open; double high; double low; double close; int name; int sector; int importance; double actual; double forecast; double previous; } news_data;
Since we have a similar LabelEncoder in MQL5 to the one we used to transform string features in Python, we can load its class and assign it to three variables for each column (Name, Sector, and Importance).
CLabelEncoder le_name, le_sector, le_importance;
The Init function has to be near perfect, the robot should be allowed to initalize only when all the files have been successfully imported, loaded, and assigned into their respective arrays and objects.
CDataFrame news_df; //Pandas like Dataframe object from pandas.mqh //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Initializing LightGBM model if (!lgbm.Init(LIGHTGBM_MODEL, ONNX_DEFAULT)) { printf("%s failed to initialize ONNX model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Assign the classes read from Binary files to the label encoders class objects if (!read_bin(le_name.m_classes, NAME_CLASSES)) { printf("%s Failed to read name classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_sector.m_classes, SECTOR_CLASSES)) { printf("%s Failed to read sector classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_importance.m_classes, IMPORTANCE_CLASSES)) { printf("%s Failed to read importance classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe)); return INIT_FAILED; } //--- Loading news from a csv file for testing the EA in the strategy tester if (MQLInfoInteger(MQL_TESTER)) { if (!news_df.from_csv(NEWS_CSV,",", false, "Time", "Name,Sector,Importance" )) { printf("%s failed to read news from a file %s, Error = %d",__FUNCTION__,NEWS_CSV,GetLastError()); return INIT_FAILED; } } //--- Configuring the CTrade class m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); return(INIT_SUCCEEDED); }
The function named from_csv provided by CDataFrame automatically encodes datetime values and string(s) columns when instructed.
bool CDataFrame::from_csv(string file_name,string delimiter=",",bool is_common=false, string datetime_columns="",string encode_columns="", bool verbosity=false)
This simplifies working with the resulting data stored in a news_df object, as we won't necessarily need to encode the columns extracted from the CSV file manually.
The Time column will be converted into seconds (double datatype) instead of datetime (datetime datatype).
You can view the received data as follows.
news_df.head();
Outputs.
QE 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | Index | Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | MI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 0 | 1672621200.00000000 | 1.06967000 | 1.06976000 | 1.06933000 | 1.06935000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 1 | 1672622100.00000000 | 1.06934000 | 1.06947000 | 1.06927000 | 1.06938000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | RI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 2 | 1672623000.00000000 | 1.06939000 | 1.06943000 | 1.06939000 | 1.06942000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 3 | 1672623900.00000000 | 1.06943000 | 1.06983000 | 1.06942000 | 1.06983000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 4 | 1672624800.00000000 | 1.06984000 | 1.06989000 | 1.06984000 | 1.06989000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 |
Inside the getNews function is where the most computations occur.
vector getNews() { //--- vector v = vector::Zeros(6); ResetLastError(); if (CopyRates(Symbol(), timeframe, 0, 1, rates)<=0) { printf("%s failed to get price infromation. Error = %d",__FUNCTION__,GetLastError()); return vector::Zeros(0); } news_data.time = rates[0].time; news_data.open = rates[0].open; news_data.high = rates[0].high; news_data.low = rates[0].low; news_data.close = rates[0].close; //--- if (MQLInfoInteger(MQL_TESTER)) //If we are on the strategy tester, read the news from a dataframe object { if ((ulong)n_idx>=news_df["Time"].Size()) TesterStop(); //End the strategy tester as there are no enough news to read datetime news_time = (datetime)news_df["Time"][n_idx]; //Convert time from seconds back into datetime datetime current_time = TimeCurrent(); if (news_time >= (current_time - PeriodSeconds(timeframe)) && (news_time <= (current_time + PeriodSeconds(timeframe)))) //We ensure if the incremented news time is very close to the current time { n_idx++; //Move on to the next news if weve passed the previous one } else return vector::Zeros(0); if (n_idx>=(int)news_df["Name"].Size() || n_idx >= (int)news_df.m_values.Rows()) TesterStop(); //End the strategy tester as there are no enough news to read news_data.name = (int)news_df["Name"][n_idx]; news_data.sector = (int)news_df["Sector"][n_idx]; news_data.importance = (int)news_df["Importance"][n_idx]; news_data.actual = !MathIsValidNumber(news_df["Actual"][n_idx]) ? 0 : news_df["Actual"][n_idx]; news_data.forecast = !MathIsValidNumber(news_df["Forecast"][n_idx]) ? 0 : news_df["Forecast"][n_idx]; news_data.previous = !MathIsValidNumber(news_df["Previous"][n_idx]) ? 0 : news_df["Previous"][n_idx]; if (news_data.name==0.0) //(null) return vector::Zeros(0); } else { int all_news = CalendarValueHistory(calendar_values, rates[0].time, rates[0].time+PeriodSeconds(timeframe), NULL, NULL); //we obtain all the news with their calendar_values https://www.mql5.com/en/docs/calendar/calendarvaluehistory if (all_news<=0) return vector::Zeros(0); for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(calendar_values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { //--- Important | Encode news names into integers using the same encoder applied on the training data news_data.name = le_name.transform((string)event.name); news_data.sector = le_sector.transform((string)event.sector); news_data.importance = le_importance.transform((string)event.importance); news_data.actual = !MathIsValidNumber(calendar_values[n].GetActualValue()) ? 0 : calendar_values[n].GetActualValue(); news_data.forecast = !MathIsValidNumber(calendar_values[n].GetForecastValue()) ? 0 : calendar_values[n].GetForecastValue(); news_data.previous = !MathIsValidNumber(calendar_values[n].GetPreviousValue()) ? 0 : calendar_values[n].GetPreviousValue(); } } if (news_data.name==0.0) //(null) return vector::Zeros(0); } v[0] = news_data.name; v[1] = news_data.sector; v[2] = news_data.importance; v[3] = news_data.actual; v[4] = news_data.forecast; v[5] = news_data.previous; return v; }
When this function detects that the EA is in the strategy tester, it reads the news stored in the Dataframe object instead of getting them directly from the market, something which is not possible in the tester environment.
Notice how the strings received from the news were converted into integers using encoders populated with classes used on the training data inside the OnInit function.
Since we have a couple of checks inside getNews function to ensure the function returns an empty vector when an error occurs or when no news have been received presently. Inside the OnTick function, we check if the vector received is not empty. If it's not, we proceed with a simple trading strategy.
void OnTick() { //--- vector x = getNews(); if (x.Size()==0) //No present news at the moment return; long signal = lgbm.predict(x).cls; //--- MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); //--- if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe }
If the model predicts that, according to the news received, the market will be bullish (signal = 1), we open a buy trade, and if the model predicts that the market will go down (signal = 0), we open a sell trade.
A trade will be closed after the number of bars which are equal to the lookahead value have passed in the current timeframe. The lookahead value has to be the same as the one used when crafting a target variable in a Python script. This ensures that we hold positions according to the predictive horizon of the trained model.
Finally, let us test this trading robot on the same period it was trained on inside the strategy tester.
- Symbol: EURUSD
- Timeframe: PERIOD_M15
- Modelling: Open Prices Only
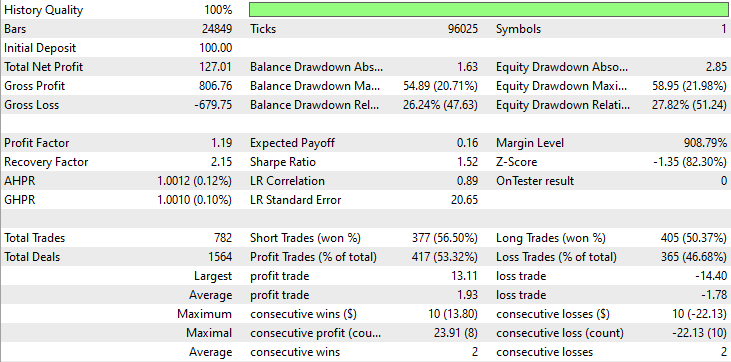
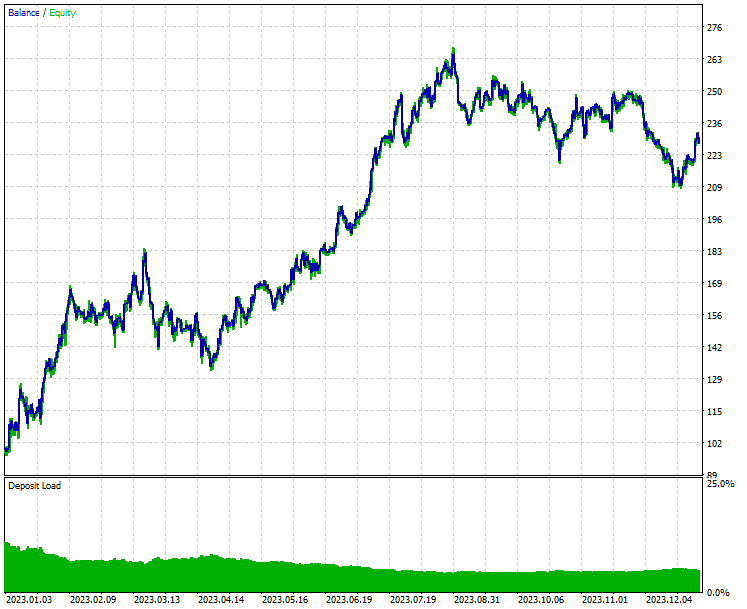
Strategy Tester outcome.
Conclusion
As you can see from the outcome from the strategy tester, the combination of news and a capable machine learning model (LightGBM) produced impressive predictive and trading outcomes on the year it was trained on.
While news are one among the strongest predictors of forex and stocks markets, trading during news releases or shortly afterward is very risky due to unexpected volatility that happens in the market during that period, you need to be mindful of this anytime you want to hand over your hard-earned money to a news-trading robot.
It's fair to say that there is room for improvement for this project, so feel free to tweak a couple of settings and improve this idea. Please let us know your thoughts on the discussion section.
Best regards.
Stay tuned and contribute to machine learning algorithms development for MQL5 language in this GitHub repository.
Attachments Table
| Filename & Path | Description & Usage |
|---|---|
Files\AI+NFP.mq5 | The main expert advisor for deploying AI models and news for trading & testing purposes. |
Files\Collect News.mq5 | A script for collecting news from MetaTrader 5 and exporting them to a CSV file. |
Include\Lightgbm.mqh | A library for loading and deploying the LightGBM model in ONNX format. |
Include\pandas.mqh | A library containing Pandas-Like Dataframe for data storage and manipulation. |
Files\* | ONNX, CSV, and binary files used in this article can be located under this folder. |
Python\nfp-ai.ipynb | Python's Jupyter notebook where all the python code for training, data cleaning, etc. can be found. |
Warning: All rights to these materials are reserved by MetaQuotes Ltd. Copying or reprinting of these materials in whole or in part is prohibited.
This article was written by a user of the site and reflects their personal views. MetaQuotes Ltd is not responsible for the accuracy of the information presented, nor for any consequences resulting from the use of the solutions, strategies or recommendations described.

- Free trading apps
- Over 8,000 signals for copying
- Economic news for exploring financial markets
You agree to website policy and terms of use