データサイエンスとML(第39回):ニュース × 人工知能、それに賭ける価値はあるか

内容
はじめに
金融市場や為替市場はニュースによって動かされ、影響を受けることをご存知でしょう。特に非農業部門雇用者数(NFP)の発表はその典型例です。ニュースは現実世界で進行中の出来事を表すため、金融市場に対して非常に重要な情報源となります。
ニュース取引には、経済指標、企業発表、地政学的イベント、中央銀行の発表などが含まれます。これらのニュースが発生する前後数瞬の間に、関連資産や銘柄でボラティリティが生じ、取引機会が生まれることがあります。
ニュースは地域や国で起きている出来事と、その予測される結果を示します。そのため、金融市場を予測する上で非常に有力な指標となります。たとえばEURUSDにおいて、ユーロ圏のコアCPIが上昇した場合、より引き締まった金融政策(利上げ)が期待され、ユーロは強気、米ドルは弱気となる可能性があります。
企業発表や経済指標のように市場にどちらの方向にも影響を与えるニュースもあれば、自然災害のように主にマイナスの影響を与え、市場や株式を混乱させるニュースも存在します。
トレーダーが成功するには、テクニカル分析だけでなくニュースにも注目することが欠かせません。ニュースは金融市場を動かす最大の要因のひとつだからです。

以上のように、ニュースは市場の動向を決定する最も重要な要素のひとつであることが分かります。本記事では、MetaTrader 5が提供するニュース情報をAIモデルに活用し、この強力な組み合わせがアルゴリズム取引において有効かどうかを検証します。
ニュースの収集
まず最初のプロセスはニュース収集です。
ニュース収集は複雑で注意を要します。特にデータ収集の時間足、対象となる銘柄、空の値やNaN値の扱いに注意する必要があります。
以下は、これから収集するニュース情報を格納するために使用する変数を含むデータ構造体です。
struct news_data_struct { datetime time[]; //News release time string name[]; //Name of the news ENUM_CALENDAR_EVENT_SECTOR sector[]; //The sector a news is related to ENUM_CALENDAR_EVENT_IMPORTANCE importance[]; //Event importance double actual[]; //actual value double forecast[]; //forecast value double previous[]; //previous value }
この構造体は、MqlCalendarEventおよびMqlCalendarValueが提供するニュース属性の一部を表しています。
以下は、過去の複数のバーを順に処理してニュースを収集するメソッドです。
//--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } }
このコードで必要なニュースを取得できますが、ニュース発表時点のOpen、High、Low、Close(OHLC)値も収集する必要があります。これらの値は分析や、教師あり機械学習の目的変数を作成する際に役立ちます。
また、この情報を外部で利用できるようにCSVファイルに保存する機能も必要です。
以下は、ニュースを収集するための完全な関数です。
void SaveNews(string csv_name) { //--- get OHLC values first ResetLastError(); if (CopyRates(Symbol(), timeframe, start_date, end_date, rates)<=0) { printf("%s failed to get price infromation from %s to %s. Error = %d",__FUNCTION__,string(start_date),string(end_date),GetLastError()); return; } uint size = rates.Size(); news_data.Resize(size-1); //--- FileDelete(csv_name); //Delete an existing csv file of a given name int csv_handle = FileOpen(csv_name,FILE_WRITE|FILE_SHARE_WRITE|FILE_CSV|FILE_ANSI,",",CP_UTF8); //csv handle if(csv_handle == INVALID_HANDLE) { printf("Invalid %s handle Error %d ",csv_name,GetLastError()); return; //stop the process } FileSeek(csv_handle,0,SEEK_SET); //go to file begining FileWrite(csv_handle,"Time,Open,High,Low,Close,Name,Sector,Importance,Actual,Forecast,Previous"); //write csv header MqlCalendarValue values[]; //https://www.mql5.com/en/docs/constants/structures/mqlcalendar#mqlcalendarvalue for (uint i=0; i<size-1; i++) { news_data.time[i] = rates[i].time; news_data.open[i] = rates[i].open; news_data.high[i] = rates[i].high; news_data.low[i] = rates[i].low; news_data.close[i] = rates[i].close; int all_news = CalendarValueHistory(values, rates[i].time, rates[i+1].time, NULL, NULL); //we obtain all the news with their values https://www.mql5.com/en/docs/calendar/calendarvaluehistory for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { news_data.name[i] = event.name; news_data.sector[i] = event.sector; news_data.importance[i] = event.importance; news_data.actual[i] = !MathIsValidNumber(values[n].GetActualValue()) ? 0 : values[n].GetActualValue(); news_data.forecast[i] = !MathIsValidNumber(values[n].GetForecastValue()) ? 0 : values[n].GetForecastValue(); news_data.previous[i] = !MathIsValidNumber(values[n].GetPreviousValue()) ? 0 : values[n].GetPreviousValue(); } } FileWrite(csv_handle,StringFormat("%s,%f,%f,%f,%f,%s,%s,%s,%f,%f,%f", (string)news_data.time[i], news_data.open[i], news_data.high[i], news_data.low[i], news_data.close[i], news_data.name[i], EnumToString(news_data.sector[i]), EnumToString(news_data.importance[i]), news_data.actual[i], news_data.forecast[i], news_data.previous[i] )); } //--- FileClose(csv_handle); }
情報をCSVファイルに保存する処理はループの外でおこなわれます。これは、ニュースが発生した場合だけでなく、発生していない場合のバーも収集するためです。ニュースの前後で市場に与える影響を評価するには、この情報が重要となります。
収集期間は2023年1月1日から2023年12月31日まで、1年分のニュースおよびその他の取引情報を対象としました。
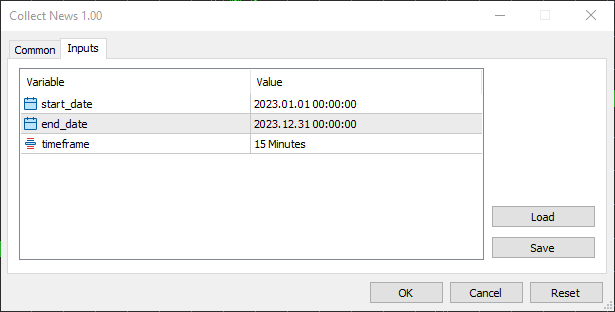
時間足は15分足を選びました。というのも、ニュースフィルターの作成やニュースベースの戦略運用において、ほとんどのトレーダーがその時間足を使っているのを見かけるからです。これは、多くのトレーダーがニュースフィルターの作成やニュースベースの戦略を構築する際に使用している時間足であり、ニュース後の意味のある価格反応を捉えることと、15分以下の時間足で発生する市場ノイズを除外することの最適なバランスを取ることができるためです。
AIモデル学習用ニュースデータの準備
Pythonスクリプト(Jupyter Notebook)内では、まずニュースデータを含むCSVファイルをインポートすることから始めます。
df = pd.read_csv("/kaggle/input/nfp-forexdata/EURUSD.PERIOD_M15.News.csv") df.head(5)
以下が出力です。
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | 元日 | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | 元日 | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | 元日 | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | 元日 | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | 元日 | CALENDAR_SECTOR_HOLIDAYS | CALENDAR_IMPORTANCE_NONE | 0.0 | 0.0 | 0.0 |
ニュースデータには、Actual、Previous、Forecastの各値に常にNaN値が含まれることがあります。そのため、Collect News MQL5スクリプト内でファイルにNaN値が挿入されないようチェックをおこなっていても、CSVファイルにNaN値が紛れ込んでいないかを明示的に確認する必要があります。
df.info()
以下が出力です。
<class 'pandas.core.frame.DataFrame'> RangeIndex: 24848 entries, 0 to 24847 Data columns (total 11 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Time 24848 non-null object 1 Open 24848 non-null float64 2 High 24848 non-null float64 3 Low 24848 non-null float64 4 Close 24848 non-null float64 5 Name 24848 non-null object 6 Sector 24848 non-null object 7 Importance 24848 non-null object 8 Actual 24848 non-null float64 9 Forecast 24848 non-null float64 10 Previous 24848 non-null float64 dtypes: float64(7), object(4) memory usage: 2.1+ MB
目的変数の作成
教師あり機械学習では、モデルが予測変数と推定したい結果との関係を学習できるように、目的変数が必要です。
ニュースが発表されると、市場はトレーダーの行動や反応に応じて急速に上下に動く傾向があります。しかし、ここでの課題は、「市場の変動が実際に直近のニュースによるものとみなせる期間はどれくらいか」を判断することです。
ニュース発表後の取引を避けるトレーダーは、一般的にニュース発表後15~30分間は取引を控え、この時間を過ぎるとニュースの影響が薄れると考えています。
ニュース発表後の市場は大きなボラティリティや予期せぬ急騰や急落が発生し、多くのノイズが生じます。そこで、目的変数は15バー先(おおよそ4時間後)を基準に作成することにします。
lookahead = 15 clean_df = df.copy() clean_df["Future Close"] = df["Close"].shift(-lookahead) clean_df.dropna(inplace=True) # drop nan caused by shifting operation clean_df["Signal"] = (clean_df["Future Close"] > clean_df["Close"]).astype(int) # if the future close > current close = bullish movement otherwise bearish movement clean_df
データからニュースのない行を削除する
目的変数を作成した後、ニュースが発表されなかった行をすべて削除します。モデルにはニュースが含まれる行のみを学習させたいからです。
具体的には、ニュース名を保持するName列の値がnullとなっている行をすべてフィルタリングして削除します。
clean_df = clean_df[clean_df['Name'] != '(null)'] clean_df
データフレーム内の文字列のエンコード
多くの機械学習モデルでは文字列がサポートされていないため、文字列の値を整数にエンコードする必要があります。
文字列はName、Sector、Importanceの列に含まれています。
from sklearn.preprocessing import LabelEncoder
categorical_cols = ['Name', 'Sector', 'Importance'] label_encoders = {} encoded_df = clean_df.copy() for col in categorical_cols: le = LabelEncoder() encoded_df[col] = le.fit_transform(clean_df[col]) # Save classes to binary file (.bin) with open(f"{col}_classes.bin", 'wb') as f: np.save(f, le.classes_, allow_pickle=True) label_encoders[col] = le encoded_df.head(5)
あるいは、LabelEncoderをパイプラインに組み込むことで、より簡単に扱うこともできます。
各列のエンコード時に、ラベルエンコーダオブジェクトによって検出されたクラスを保存しておくことが非常に重要です。これは、最終的にMQL5言語で作成するプログラム内でニュースをエンコードする際に、同じ情報が必要になるためです。
これは主に、エンコードパターンを一貫させることと、学習していない予期せぬニュースが発生した場合にエラーを発生させるためです。現実世界では予期せぬニュースが起こることは避けられません。
以下が出力です。
| Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | Future Close | Signal | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.01.02 01:00:00 | 1.06967 | 1.06976 | 1.06933 | 1.06935 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06880 | 0 |
| 1 | 2023.01.02 01:15:00 | 1.06934 | 1.06947 | 1.06927 | 1.06938 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06888 | 0 |
| 2 | 2023.01.02 01:30:00 | 1.06939 | 1.06943 | 1.06939 | 1.06942 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06891 | 0 |
| 3 | 2023.01.02 01:45:00 | 1.06943 | 1.06983 | 1.06942 | 1.06983 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06892 | 0 |
| 4 | 2023.01.02 02:00:00 | 1.06984 | 1.06989 | 1.06984 | 1.06989 | 162 | 4 | 3 | 0.0 | 0.0 | 0.0 | 1.06897 | 0 |
次に、データをX(特徴量)とY(目的変数)のセットに分割し、さらにこれらのセットを学習用サンプルとテスト用サンプルに分割します。
X = encoded_df.drop(columns=[ "Time", "Open", "High", "Low", "Close", "Future Close", "Signal" ]) y = encoded_df["Signal"] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state = 42, shuffle=True)
ニュースに関する情報を含む列以外のすべての列を削除したことに注意してください。
ニュースデータを用いたAIモデルの学習
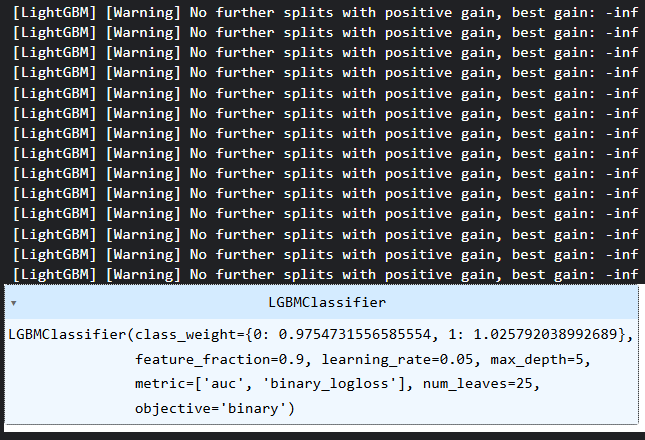
今回はLight Gradient Boosting Machine (LightGBM)モデルを学習させることにしました。理由は、シンプルで高速かつ高精度であることに加え、現在扱っているカテゴリデータにも適した決定木ベースのモデルだからです。
params = {
'boosting_type': 'gbdt', # Gradient Boosting Decision Tree
'objective': 'binary', # For binary classification (use 'regression' for regression tasks)
'metric': ['auc','binary_logloss'], # Evaluation metric
'num_leaves': 25, # Number of leaves in one tree
'n_estimators' : 100, # number of trees
'max_depth': 5,
'learning_rate': 0.05, # Learning rate
'feature_fraction': 0.9 # Fraction of features to be used for each boosting round
}
class_weights = compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
weight_dict = dict(zip(np.unique(y_train), class_weights))
model = lgb.LGBMClassifier(**params, class_weight=weight_dict)
# Fit the model to the training data
model.fit(X_train, y_train) クラスの重みは、モデルの判断におけるバイアスを軽減するための手段として導入されました。
以下が出力です。
以下は、テストサンプルに対するモデルの予測結果に基づく分類レポートです。
[LightGBM] [Warning] feature_fraction is set=0.9, colsample_bytree=1.0 will be ignored. Current value: feature_fraction=0.9 Classification Report precision recall f1-score support 0 0.59 0.52 0.55 1116 1 0.55 0.61 0.58 1049 accuracy 0.56 2165 macro avg 0.57 0.57 0.56 2165 weighted avg 0.57 0.56 0.56 2165
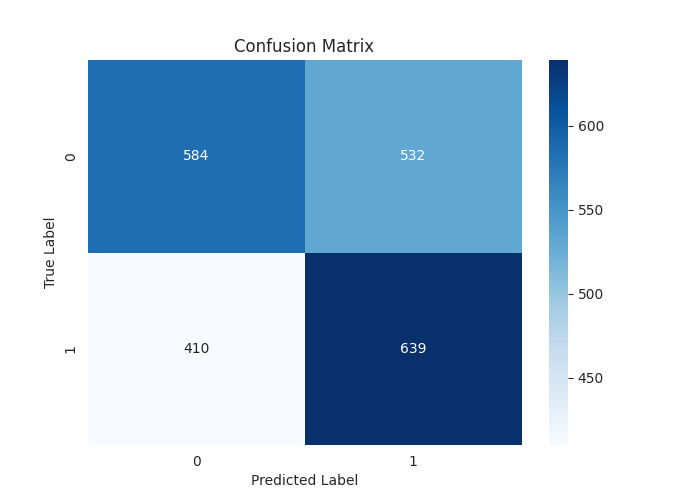
テストデータにおいて1.0中0.56という優れた全体精度を達成しました。これは、テクニカルデータを用いた機械学習モデルの学習では容易に達成できない数値です。
現時点では、私たちが構築したモデルはブラックボックスであり、ニュースがモデルの最終的な判断にどのように影響しているのかは分かりません。では、モデルの特徴量からどのような物語が見えてくるのかを確認してみましょう。
SHAPを使用します。
import shap
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train) 以下が出力です。
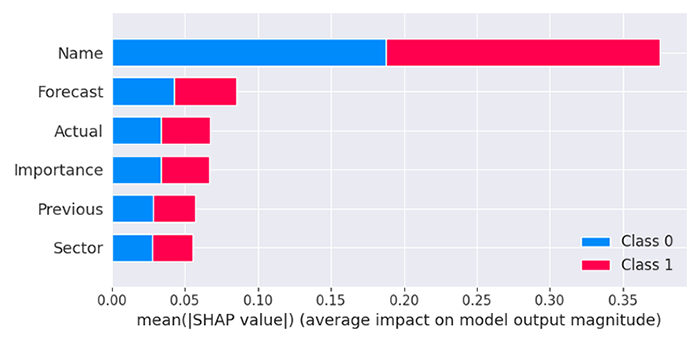
モデルの分析によると、すべての列の中で最も影響力が大きいのはName列でした。これは、特定の名称を持つニュースが、他の予測変数と比較して市場反応に大きな影響を与えていることを意味します。
次に重要度が高いのは予測値(Forecast)であり、その後に実際値(Actual)、重要度(Importance)、前回値(Previous)、そしてニュースの分野(Sector)が続きます。
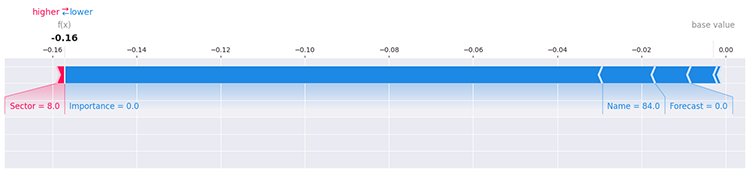
ただし、これだけでは十分に明確な結論は得られません。各特徴量に含まれるユニークな値がモデルにどのような影響を与えているかを調べる方法は数多く存在します。たとえば、SHAPを用いて最初の行のデータを評価することで、その影響を確認できます。
i=0 shap.force_plot(explainer.expected_value[1], shap_values[1][i], X_train.iloc[i], matplotlib=True)
以下が出力です。
モデルのさらなる探索方法や詳細については、SHAPLEYのドキュメントを参照してください。
最後に、このモデルを外部で利用できるようにONNX形式で保存する必要があります。
# Registering ONNX converter update_registered_converter( lgb.LGBMClassifier, "GBMClassifier", calculate_linear_classifier_output_shapes, convert_lightgbm, options={"nocl": [False], "zipmap": [True, False, "columns"]}, ) # Final conversion model_onnx = convert_sklearn( model, "lightgbm_model", [("input", FloatTensorType([None, X_train.shape[1]]))], target_opset={"": 14, "ai.onnx.ml": 2}, ) # And save. with open("lightgbm.EURUSD.news.M15.onnx", "wb") as f: f.write(model_onnx.SerializeToString())
ニュースとAIを活用した自動売買ロボット(EA)
この自動売買ロボットが動作するには、いくつかの依存関係とファイルが必要です。
#define NEWS_CSV "EURUSD.PERIOD_M15.News.csv" //For simulating news on the strategy tester, making testing possible //--- Encoded classes for the columns stored in a binary file #define SECTOR_CLASSES "Sector_classes.bin" #define NAME_CLASSES "Name_classes.bin" #define IMPORTANCE_CLASSES "Importance_classes.bin" #define LIGHTGBM_MODEL "lightgbm.EURUSD.news.M15.onnx" //AI model //--- Tester files #property tester_file NEWS_CSV #property tester_file SECTOR_CLASSES #property tester_file NAME_CLASSES #property tester_file IMPORTANCE_CLASSES #property tester_file LIGHTGBM_MODEL
これらのファイルはストラテジーテスターで使用できるように有効化する必要があります。なぜなら、それこそが最も必要とされる場面だからです。
//--- Dependencies #include <Trade\Trade.mqh> #include <Trade\PositionInfo.mqh> #include <pandas.mqh> //https://www.mql5.com/en/articles/17030 #include <Lightgbm.mqh> //For importing LightGBM model CLightGBMClassifier lgbm; CTrade m_trade; CPositionInfo m_position;
Collect News.mq5(ニュースデータの収集に使用したスクリプト)内で使用したのと同じニュース構造体が必要です。
MqlRates rates[]; struct news_data_struct { datetime time; double open; double high; double low; double close; int name; int sector; int importance; double actual; double forecast; double previous; } news_data;
Pythonで文字列特徴量の変換に使用したものと同様のLabelEncoderがMQL5にも用意されているため、そのクラスを読み込み、各列(Name、Sector、Importance)に対応する3つの変数に割り当てることができます。
CLabelEncoder le_name, le_sector, le_importance;
Init関数はほぼ完璧でなければなりません。すべてのファイルをインポートし、読み込み、それぞれの配列やオブジェクトに割り当てた場合にのみ、ロボットが初期化されるようにする必要があります。
CDataFrame news_df; //Pandas like Dataframe object from pandas.mqh //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Initializing LightGBM model if (!lgbm.Init(LIGHTGBM_MODEL, ONNX_DEFAULT)) { printf("%s failed to initialize ONNX model, error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Assign the classes read from Binary files to the label encoders class objects if (!read_bin(le_name.m_classes, NAME_CLASSES)) { printf("%s Failed to read name classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_sector.m_classes, SECTOR_CLASSES)) { printf("%s Failed to read sector classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } if (!read_bin(le_importance.m_classes, IMPORTANCE_CLASSES)) { printf("%s Failed to read importance classes for the news, Error = %d",__FUNCTION__,GetLastError()); return INIT_FAILED; } //--- Setting the symbol and timeframe if (!MQLInfoInteger(MQL_TESTER) && !MQLInfoInteger(MQL_DEBUG)) if (!ChartSetSymbolPeriod(0, symbol_, timeframe)) { printf("%s failed to set symbol %s and timeframe %s",__FUNCTION__,symbol_,EnumToString(timeframe)); return INIT_FAILED; } //--- Loading news from a csv file for testing the EA in the strategy tester if (MQLInfoInteger(MQL_TESTER)) { if (!news_df.from_csv(NEWS_CSV,",", false, "Time", "Name,Sector,Importance" )) { printf("%s failed to read news from a file %s, Error = %d",__FUNCTION__,NEWS_CSV,GetLastError()); return INIT_FAILED; } } //--- Configuring the CTrade class m_trade.SetExpertMagicNumber(magic_number); m_trade.SetDeviationInPoints(slippage); m_trade.SetMarginMode(); m_trade.SetTypeFillingBySymbol(Symbol()); return(INIT_SUCCEEDED); }
CDataFrameが提供するfrom_csv関数は、指定すると日時値や文字列列を自動的にエンコードします。
bool CDataFrame::from_csv(string file_name,string delimiter=",",bool is_common=false, string datetime_columns="",string encode_columns="", bool verbosity=false)
これにより、ニュースデータを格納したnews_dfオブジェクトを扱う際に、CSVファイルから抽出した列を手動でエンコードする必要がなくなり、作業が簡素化されます。
Time列はdatetime型ではなく、秒数を表すdouble型に変換されます。
受信したデータは以下のようになります。
news_df.head();
以下が出力です。
QE 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | Index | Time | Open | High | Low | Close | Name | Sector | Importance | Actual | Forecast | Previous | MI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 0 | 1672621200.00000000 | 1.06967000 | 1.06976000 | 1.06933000 | 1.06935000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 1 | 1672622100.00000000 | 1.06934000 | 1.06947000 | 1.06927000 | 1.06938000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | RI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 2 | 1672623000.00000000 | 1.06939000 | 1.06943000 | 1.06939000 | 1.06942000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 3 | 1672623900.00000000 | 1.06943000 | 1.06983000 | 1.06942000 | 1.06983000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 | JI 0 18:21:45.159 Core 1 2023.01.01 00:00:00 | 4 | 1672624800.00000000 | 1.06984000 | 1.06989000 | 1.06984000 | 1.06989000 | 161.00000000 | 4.00000000 | 3.00000000 | 0.00000000 | 0.00000000 | 0.00000000 |
getNews関数内では、最も多くの計算がおこなわれます。
vector getNews() { //--- vector v = vector::Zeros(6); ResetLastError(); if (CopyRates(Symbol(), timeframe, 0, 1, rates)<=0) { printf("%s failed to get price infromation. Error = %d",__FUNCTION__,GetLastError()); return vector::Zeros(0); } news_data.time = rates[0].time; news_data.open = rates[0].open; news_data.high = rates[0].high; news_data.low = rates[0].low; news_data.close = rates[0].close; //--- if (MQLInfoInteger(MQL_TESTER)) //If we are on the strategy tester, read the news from a dataframe object { if ((ulong)n_idx>=news_df["Time"].Size()) TesterStop(); //End the strategy tester as there are no enough news to read datetime news_time = (datetime)news_df["Time"][n_idx]; //Convert time from seconds back into datetime datetime current_time = TimeCurrent(); if (news_time >= (current_time - PeriodSeconds(timeframe)) && (news_time <= (current_time + PeriodSeconds(timeframe)))) //We ensure if the incremented news time is very close to the current time { n_idx++; //Move on to the next news if weve passed the previous one } else return vector::Zeros(0); if (n_idx>=(int)news_df["Name"].Size() || n_idx >= (int)news_df.m_values.Rows()) TesterStop(); //End the strategy tester as there are no enough news to read news_data.name = (int)news_df["Name"][n_idx]; news_data.sector = (int)news_df["Sector"][n_idx]; news_data.importance = (int)news_df["Importance"][n_idx]; news_data.actual = !MathIsValidNumber(news_df["Actual"][n_idx]) ? 0 : news_df["Actual"][n_idx]; news_data.forecast = !MathIsValidNumber(news_df["Forecast"][n_idx]) ? 0 : news_df["Forecast"][n_idx]; news_data.previous = !MathIsValidNumber(news_df["Previous"][n_idx]) ? 0 : news_df["Previous"][n_idx]; if (news_data.name==0.0) //(null) return vector::Zeros(0); } else { int all_news = CalendarValueHistory(calendar_values, rates[0].time, rates[0].time+PeriodSeconds(timeframe), NULL, NULL); //we obtain all the news with their calendar_values https://www.mql5.com/en/docs/calendar/calendarvaluehistory if (all_news<=0) return vector::Zeros(0); for (int n=0; n<all_news; n++) { MqlCalendarEvent event; CalendarEventById(calendar_values[n].event_id, event); //Here among all the news we select one after the other by its id https://www.mql5.com/en/docs/calendar/calendareventbyid MqlCalendarCountry country; //The couhtry where the currency pair originates CalendarCountryById(event.country_id, country); //https://www.mql5.com/en/docs/calendar/calendarcountrybyid if (StringFind(Symbol(), country.currency)>-1) //We want to ensure that we filter news that has nothing to do with the base and the quote currency for the current symbol pair { //--- Important | Encode news names into integers using the same encoder applied on the training data news_data.name = le_name.transform((string)event.name); news_data.sector = le_sector.transform((string)event.sector); news_data.importance = le_importance.transform((string)event.importance); news_data.actual = !MathIsValidNumber(calendar_values[n].GetActualValue()) ? 0 : calendar_values[n].GetActualValue(); news_data.forecast = !MathIsValidNumber(calendar_values[n].GetForecastValue()) ? 0 : calendar_values[n].GetForecastValue(); news_data.previous = !MathIsValidNumber(calendar_values[n].GetPreviousValue()) ? 0 : calendar_values[n].GetPreviousValue(); } } if (news_data.name==0.0) //(null) return vector::Zeros(0); } v[0] = news_data.name; v[1] = news_data.sector; v[2] = news_data.importance; v[3] = news_data.actual; v[4] = news_data.forecast; v[5] = news_data.previous; return v; }
この関数は、EAがストラテジーテスター内で実行されていることを検出すると、市場から直接ニュースを取得するのではなく、データフレームオブジェクトに保存されたニュースを読み込みます。これはテスター環境では市場から直接取得することが不可能であるためです。
また、ニュースから受け取った文字列は、OnInit関数内で学習データに基づいて構築されたクラスを持つエンコーダによって整数に変換されている点に注目してください。
さらに、getNews関数内にはいくつかのチェックがあり、エラーが発生した場合や現時点でニュースが取得できなかった場合には空のベクトルを返すようになっています。そのため、OnTick関数内では受け取ったベクトルが空でないかどうかを確認し、空でなければシンプルな取引戦略を実行します。
void OnTick() { //--- vector x = getNews(); if (x.Size()==0) //No present news at the moment return; long signal = lgbm.predict(x).cls; //--- MqlTick ticks; if (!SymbolInfoTick(Symbol(), ticks)) { printf("Failed to obtain ticks information, Error = %d",GetLastError()); return; } double volume_ = SymbolInfoDouble(Symbol(), SYMBOL_VOLUME_MIN); //--- if (signal == 1) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_BUY) && !PosExists(POSITION_TYPE_SELL)) m_trade.Buy(volume_, Symbol(), ticks.ask,0,0); } if (signal == 0) //Check if there are is atleast a special pattern before opening a trade { if (!PosExists(POSITION_TYPE_SELL) && !PosExists(POSITION_TYPE_BUY)) m_trade.Sell(volume_, Symbol(), ticks.bid,0,0); } CloseTradeAfterTime((Timeframe2Minutes(Period())*lookahead)*60); //Close the trade after a certain lookahead and according the the trained timeframe }
モデルが受け取ったニュースに基づいて市場が強気(signal = 1)と予測した場合は買いポジションを、弱気(signal = 0)と予測した場合は売りポジションをオープンします。
取引は、現在の時間足においてlookahead値に等しいバー数が経過した後に決済されます。lookahead値は、Pythonスクリプトで目的変数を作成する際に使用したものと同じでなければなりません。これにより、学習済みモデルの予測ホライズンに従ったポジション保有が保証されます。
最後に、この自動売買ロボットをストラテジーテスター内で、学習に使用したものと同じ期間でテストしてみましょう。
- 銘柄:EURUSD
- 時間足:PERIOD_M15
- モデリング:始値のみ
以下は、ストラテジーテスターの結果です。
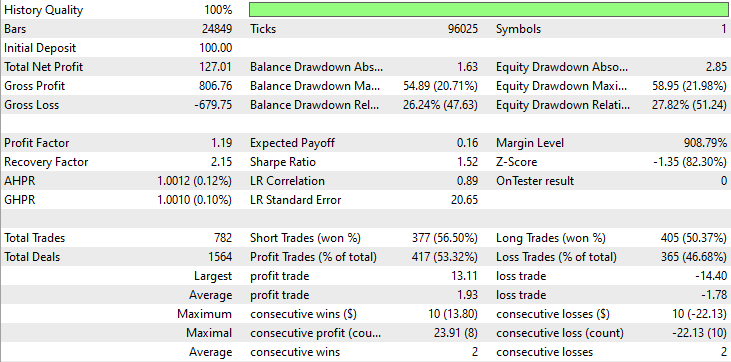
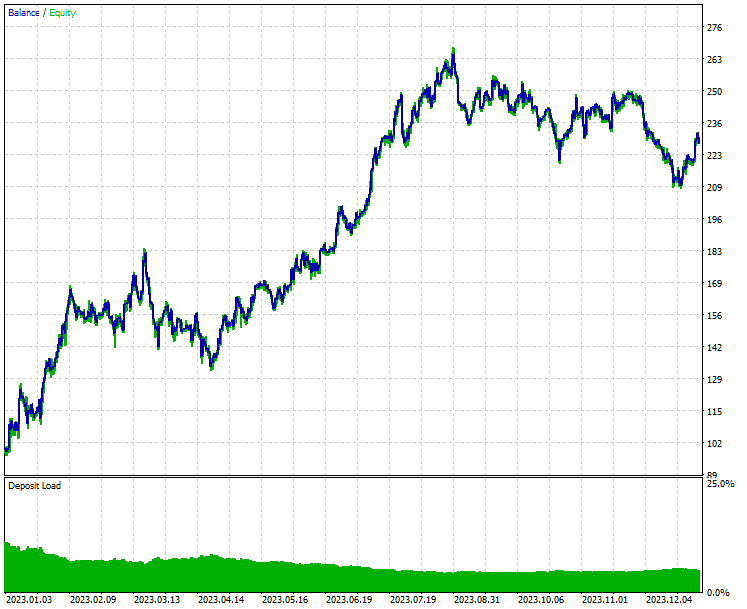
結論
ストラテジーテスターの結果から分かるように、ニュースと高性能な機械学習モデル(LightGBM)の組み合わせは、学習に使用した年において非常に優れた予測および取引結果を生み出しました。
ニュースは外国為替や株式市場における最も強力な予測要素のひとつですが、ニュース発表中や直後の取引は、市場で発生する予期せぬボラティリティのため非常にリスクが高くなります。この期間に自分の資金をニュース自動売買ロボットに委ねる際は、十分に注意してください。
本プロジェクトには改善の余地があることは間違いありません。設定を調整してアイデアをさらに発展させることも可能です。ぜひ、ディスカッション欄で皆さんの意見をお聞かせください。
ご一読、誠にありがとうございました。
今後の更新にもご注目ください。こちらのGitHubリポジトリで、MQL5言語向けの機械学習アルゴリズムの開発にぜひ貢献してください。
添付ファイルの表
| ファイル名とパス | 説明と使用法 |
|---|---|
Files\AI+NFP.mq5 | AIモデルとニュースを用いた取引およびテスト用のメインEA |
Files\Collect News.mq5 | MetaTrader 5からニュースを収集し、CSVファイルにエクスポートするスクリプト |
Include\Lightgbm.mqh | ONNX形式のLightGBMモデルを読み込み、展開するためのライブラリ |
Include\pandas.mqh | データ格納および操作用のPandas風データフレームを提供するライブラリ |
Files\* | 本記事で使用するONNX、CSV、バイナリファイルがこのフォルダ内に格納されています |
Python\nfp-ai.ipynb | Pythonコード(モデル学習、データクレンジングなど)が記載されたJupyter Notebook |
MetaQuotes Ltdにより英語から翻訳されました。
元の記事: https://www.mql5.com/en/articles/17986
警告: これらの資料についてのすべての権利はMetaQuotes Ltd.が保有しています。これらの資料の全部または一部の複製や再プリントは禁じられています。
この記事はサイトのユーザーによって執筆されたものであり、著者の個人的な見解を反映しています。MetaQuotes Ltdは、提示された情報の正確性や、記載されているソリューション、戦略、または推奨事項の使用によって生じたいかなる結果についても責任を負いません。

- 無料取引アプリ
- 8千を超えるシグナルをコピー
- 金融ニュースで金融マーケットを探索