
Возможности Мастера MQL5, которые вам нужно знать (Часть 28): Сети GAN в контексте темпа обучения
Введение
Мы возвращаемся к разновидности нейронной сети, которую мы рассматривали в одной из предыдущих статей, но при этом фокусируемся на одном конкретном гиперпараметре. Это темп обучения (learning rate). Генеративно-состязательная сеть — это нейронная сеть, работающая парами, где одна сеть обучена распознавать правду, а другая - отличать проекции первой от реальных событий. Эта двойственность подразумевает, что первая сеть пытается обмануть вторую, однако обе сети находятся в "одной команде", и одновременное обучение обеих в конечном итоге делает сеть-генератор более полезной для трейдера. В этой статье мы подробно рассмотрим процесс обучения, уделив особое внимание темпу обучения.
Как всегда в этих статьях, цель состоит в том, чтобы продемонстрировать классы сигналов, трейлинга или управления капиталом, которые не установлены предварительно в библиотеке, но тем не менее могут быть совместимы в той или иной форме с существующими стратегиями трейдера. В частности, Мастер MQL5 позволяет легко выполнять сборку и тестирование с минимальными требованиями к кодированию для общих торговых функций советника. Таким образом мы можем тестировать пользовательский класс независимо как собранный советник или параллельно с другими классами Мастера, поскольку сборка с помощью Мастера легко позволяет это сделать. Подробнее об использовании Мастера можно узнать здесь и здесь.
Поэтому в этой статье мы рассмотрим, какое влияние темп обучения оказывает на производительность в простой генеративно-состязательной сети (GAN). "Производительность" сама по себе является весьма субъективным понятием, и, строго говоря, тестирование должно проводиться в течение гораздо более длительных периодов, чем мы рассматриваем в этих статьях. Для наших целей "производительностью" будет просто общая прибыль с учетом коэффициента восстановления. Мы рассмотрим несколько типов (или графиков) темпа обучения и постараемся провести исчерпывающее тестирование для всех из них, особенно если они явно отличаются от остальных.
Формат этой статьи будет несколько отличаться от того, к которому мы привыкли в предыдущих статьях. При представлении каждого формата темпа обучения будут прилагаться отчеты о тестировании стратегии. Это немного отличается от того, что было раньше, когда все отчеты обычно размещались в конце статьи, перед заключением. Этот исследовательский формат позволяет непредвзято оценивать влияние темпа обучения на производительность алгоритмов машинного обучения, в частности, GAN. Поскольку мы рассматриваем различные типы и форматы показателей темпа обучения, важно иметь единые метрики тестирования, и именно поэтому мы будем использовать единый символ, временные рамки и период тестирования для всех типов показателей темпа обучения.
Исходя из этого, нашим символом будет EURJPY, таймфреймом — день, а тестовым периодом — 2023 год. Мы проводим тестирование на GAN, и ее архитектура по умолчанию, безусловно, является важным параметром. Существует мнение, что более сложная конструкция с точки зрения количества и размера каждого слоя имеет первостепенное значение, однако здесь мы сосредоточимся на темпе обучения. Для этого наши сети GAN будут относительно простыми и будут содержать всего 3 слоя, включая один скрытый слой. Общий размер каждого из них будет 5-8-1 от входа к выходу. Их настройки указаны в прилагаемом коде и могут быть легко изменены читателем, если он захочет их изменить.
Для генерации длинных и коротких условий мы реализуем все различные форматы темпа обучения таким же образом, как мы это делали в вышеупомянутой статье, в которой рассматривалось использование GAN в качестве пользовательского класса сигналов в MQL5. Исходный код, как всегда, прилагается, однако для полноты картины он представлен ниже:
//+------------------------------------------------------------------+ //| "Voting" that price will grow. | //+------------------------------------------------------------------+ int CSignalCGAN::LongCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out > 50.0) { result = int(_gen_out); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out));return(0); return(result); } //+------------------------------------------------------------------+ //| "Voting" that price will fall. | //+------------------------------------------------------------------+ int CSignalCGAN::ShortCondition(void) { int result = 0; double _gen_out = 0.0; bool _dis_out = false; GetOutput(_gen_out, _dis_out); _gen_out *= 100.0; if(_dis_out && _gen_out < 50.0) { result = int(fabs(_gen_out)); } //printf(__FUNCSIG__ + " generator output is: %.5f, which is backed by discriminator as: %s", _gen_out, string(_dis_out));return(0); return(result); }
Фиксированный темп обучения
Начнем с того, что фиксированный темп обучения, вероятно, используют большинство новых пользователей алгоритмов машинного обучения, поскольку он наиболее прост. Стандартная мера, с помощью которой веса и смещения алгоритма корректируются на каждой итерации обучения. Она не меняется на протяжении различных эпох обучения.
Преимущества фиксированного темпа заключаются в его простоте. Это очень просто реализовать, поскольку у нас есть одно значение с плавающей точкой для использования во всех эпохах, и это также делает динамику обучения более предсказуемой, что помогает лучше понять весь процесс, а также отладить его. Кроме того, это способствует воспроизводимости. Во многих нейронных сетях, особенно тех, которые инициализируются случайными весами, результаты тестового прогона не всегда воспроизводимы. В нашем случае во всех различных форматах темпа обучения мы используем стандартный начальный вес 0,1 и начальное смещение 0,01. Зафиксировав такие значения, мы сможем лучше воспроизвести результаты наших тестовых запусков.
Кроме того, фиксированный темп обучения обеспечивает стабильность на ранних этапах процесса обучения, поскольку темп обучения не уменьшается и не падает на более поздних этапах, как это происходит в большинстве других форматов темпа обучения. Данные, которые встречаются позже в ходе тестовых запусков, рассматриваются в той же степени, что и самые старые данные. Это упрощает проведение сравнительного анализа и сравнения в случаях, когда вы настраиваете сеть на другой гиперпараметр. Это может быть, например, начальный вес, используемый нейронной сетью. При фиксированном темпе обучения такой поиск оптимизации может быстрее прийти к значимому результату.
Основная проблема при фиксированном темпе обучения — неоптимальная сходимость. Есть опасения, что при обучении градиентный спуск градиентный спуск может застрять на локальных минимумах и не сойтись оптимально. Это особенно важно до того, как будет установлен идеальный фиксированный темп обучения. Кроме того, существует аргумент о плохой адаптации, который следует из общего мнения о том, что по мере сближения эпох обучения потребность "учиться" не остается прежней. По общему мнению, она уменьшается.
С учетом этих плюсов и минусов мы получаем следующую картину при проведении тестового прогона для пары EURJPY в 2023 году на дневном таймфрейме:


Пошаговое затухание
Далее следует темп обучения с пошаговым затуханием, который на самом деле является фиксированным темпом обучения с двумя дополнительными параметрами, которые управляют тем, как начальный фиксированный темп обучения уменьшается с каждой последующей эпохой. В MQL5 это реализовано следующим образом:
if(m_learning_type == LEARNING_STEP_DECAY) { int _epoch_index = int(MathFloor((m_epochs - i) / m_decay_epoch_steps)); _learning_rate = m_learning_rate * pow(m_decay_rate, _epoch_index); }
Таким образом, определение темпа обучения в каждой эпохе представляет собой двухэтапный процесс. Сначала нам нужно получить индекс эпохи. Он измеряет, насколько далеко мы продвинулись по эпохам во время сеанса обучения. На его значение сильно влияет второй входной параметр m_decay_epoch_steps. Наш цикл for отсчитывает в обратном направлении, а не в прямом, как это обычно бывает, поэтому мы вычитаем текущее значение i из общего числа эпох, а затем выполняем его деление Math-Floor на этот второй входной параметр. Полученное округленное целое число служит индексом эпохи, который мы используем для количественной оценки того, насколько нам необходимо снизить начальный темп обучения в текущей эпохе. Если наш размер шага (второе входное значение) равен 5, мы всегда ждем и уменьшаем темп обучения только после каждых 5 эпох. Если размер шага равен 10, то уменьшение происходит через 10 эпох и так далее.
Общая стратегия шагового затухания заключается в постепенном снижении темпа обучения, чтобы не "превысить" минимум и эффективно прийти к оптимальному решению. Стратегия обеспечивает баланс между быстрым начальным обучением и дальнейшей тонкой настройкой. Это может помочь избежать локальных минимумов и седловых точек в ландшафте потерь (loss landscape) и часто приводит к лучшему обобщению за счет снижения темпа обучения (в отличие от фиксированного темпа), что может помочь избежать переобучения.
При прогонах на EURJPY на дневном таймфрейме за 2023 год получим следующее:


Экспоненциальное затухание
В отличие от предыдущего варианта, темп обучения с экспоненциальным затуханием характеризуется более плавным снижением темпа обучения. Мы видели, что темп обучения с пошаговым затуханием уменьшается только при увеличении индекса эпохи или после заранее определенного количества шагов эпохи. При экспоненциальном затухании снижение темпа обучения всегда происходит с каждой новой эпохой. Это представлено следующей формулой:
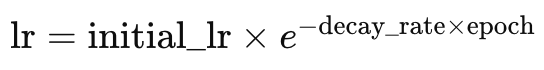
где
- lr - темп обучения
- initial_lr - начальный темп обучения
- e - постоянная Эйлера
- decay_rate - скорость затухания
- epoch - эпоха
На языке MQL5 это будет выглядеть так:
else if(m_learning_type == LEARNING_EXPONENTIAL_DECAY) { _learning_rate = m_learning_rate * exp(-1.0 * m_decay_rate * (m_epochs - i + 1)); }
Экспоненциальное затухание способно снизить темп обучения, умножая его на коэффициент затухания в каждой новой эпохе. Это обеспечивает более постепенное снижение темпа обучения по сравнению с пошаговым подходом, описанным выше. Преимущества постепенного подхода, как правило, больше соответствуют общим подходам к снижению темпа обучения. Они уже были рассмотрены выше в методе пошагового затухания. Экспоненциальное затухание может обеспечить то, чего не хватает при пошаговом - возможность избежать резких падений темпа обучения, которые могут дестабилизировать процесс обучения.
При прогонах на EURJPY на дневном таймфрейме за 2023 год получим следующее:


Несмотря на то, что экспоненциальное затухание позволяет более плавно и постепенно снижать темп обучения, путем его пересмотра в каждой эпохе, не все шаги снижения имеют одинаковый размер. В начале обучения снижение темпа значительно больше, и эти значения снижаются по мере продвижения обучения к последним эпохам.
Полиномиальное затухание
Как и экспоненциальное затухание, снижает темп обучения по мере его прогрессирования. Однако, в отличие от экспоненциального, полиномиальное затухание начинается с медленного снижения темпа обучения. Скорость снижения постепенно увеличивается по мере приближения тренировки к последним эпохам. Это можно представить в виде уравнения следующим образом:
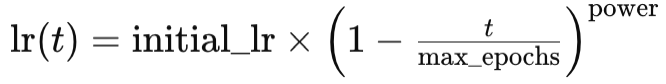
где
- lr(t) - темп обучения в эпоху t
- initial_lr - начальный темп обучения
- t - индекс эпохи
- max_epochs - максимальное количество эпох
- power - степень
Таким образом, реализация будет выглядеть следующим образом:
else if(m_learning_type == LEARNING_POLYNOMIAL_DECAY) { _learning_rate = m_learning_rate * pow(1.0 - ((m_epochs - i) / m_epochs), m_polynomial_power); }
Полиномиальное затухание вводит входной параметр power (степень) в наш класс сигналов. Все форматы темпа обучения объединяются в единый файл класса сигнала, где входные параметры позволяют выбрать определенный темп обучения. Этот файл кода прикреплен в конце статьи. Степень представляет собой постоянную экспоненту коэффициента, который мы используем для снижения темпа обучения в зависимости от эпохи, как показано в формуле выше.
Полиномиальное затухание, также как экспоненциальное и пошаговое, снижает темп обучения. Отличие полиномиального затухания заключается в быстром снижении темпа обучения к его окончанию. Это быстрое снижение, как правило, позволяет осуществлять "тонкую настройку" обучения, при которой темп обучения поддерживается на максимально высоком уровне как можно дольше и снижается только по мере исчерпания эпох. Такая "тонкая настройка" достигается путем определения оптимальной степени полинома в различных обучающих сценариях, и как только она определена, можно ожидать более оптимального процесса обучения.
Преимущества полиномиального затухания аналогичны тем, что мы упоминали выше в отношении других форматов темпа обучения, и в первую очередь сосредоточены на постепенном сокращении, что обеспечивает более плавный процесс в целом. Тонкая настройка темпа обучения, как уже упоминалось, помимо определения идеального темпа на протяжении эпох, также позволяет контролировать количество времени, которое занимает процесс обучения. Можно предположить, что большая степень полинома ускоряет процесс обучения, тогда как низкая степень должна его замедлять.
При прогонах на EURJPY на дневном таймфрейме за 2023 год получим следующее:


Обратное временное затухание
Обратное время (inverse time) также снижает темп обучения на основе каждой эпохи за счет так называемого временного затухания (time decay). В то время как выше мы рассматривали быстрое начальное снижение темпа обучения при экспоненциальном затухании и медленное снижение темпа обучения с полиномиальным затуханием, временное затухание допускает еще более медленное снижение темпа обучения, что делает его более подходящим, чем даже полиномиальное затухание, при обработке очень больших наборов обучающих данных.
Формула обратного времени:
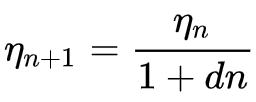
где
- ηn+1 - темп обучения в эпоху n + 1
- ηn - предыдущий темп обучения в эпоху n
- d - скорость затухания
- n - индекс эпохи.
Реализация в MQL5 выглядит так:
else if(m_learning_type == LEARNING_INVERSE_TIME_DECAY) { _learning_rate = m_prior_learning_rate / (1.0 + (m_decay_rate * (m_epochs - i))); m_prior_learning_rate = _learning_rate; }
Алгоритм идеально подходит для очень больших наборов обучающих данных, учитывая, как он действительно замедляет снижение темпа обучения. Он разделяет большинство уже упомянутых преимуществ с другими форматами темпа обучения. Алгоритм включен сюда в качестве образца для исследования, чтобы сравнить его с другими показателями темпа обучения при тестировании на том же символе, таймфрейме и периоде. Полный исходный код прилагается, чтобы пользователь мог вносить изменения для проведения более сложных тестов. Если мы проведем тестовый запуск, следуя настройкам, которые мы использовали до сих пор, мы получим следующие результаты:


Косинусный отжиг
Планировщик скорости косинусного отжига (cosine annealing) также постепенно снижает темп обучения до заранее установленного минимума, следуя косинусной функции. Цель снижения темпа обучения аналогична форматам, упомянутым выше, однако при косинусном отжиге существует целевой минимум, и процесс перезапускается всякий раз, когда достигается минимальный темп обучения, пока все эпохи не будут исчерпаны.
Необходимую формулу можно представить следующим образом:
![]()
где
- lr(t) - темп обучения в эпоху t
- initial_lr - начальный темп обучения
- t - индекс эпохи
- T - общее количество эпох
- min_lr - минимальный темп обучения
Реализация на MQL5 может быть следующей:
else if(m_learning_type == LEARNING_COSINE_ANNEALING) { _learning_rate = m_min_learning_rate + (0.5 * (m_learning_rate - m_min_learning_rate) * (1.0 + MathCos(((m_epochs - i) * M_PI) / m_epochs))); }
Косинусный отжиг подходит для больших наборов данных даже лучше, чем метод обратного временного затухания. Это объясняется тем, что, в то время как обратное временное затухание в основном откладывает большие падения темпа обучения до последних эпох обучения, косинусный отжиг позволяет "сбросить" обучение, восстанавливая его до начального значения после достижения заданного минимального темпа обучения. Это отчасти напоминает метод "теплых перезапусков" (warm restarts), где в заданном цикле обучения его скорость восстанавливается до исходного значения.
Теплые перезапуски подходят для очень больших сценариев обучения, где используются пакеты/циклы таким образом, что каждый пакет разбивается на эпохи, в отличие от подхода с одним пакетом, который мы рассматривали до сих пор во всех форматах темпа обучения. При использовании пакетов сброс или восстановление темпа обучения до исходного значения будет выполняться автоматически в конце данного пакета.
Результаты тестирования косинусного отжига в формате одного пакета дают нам следующие результаты:


Тонкая настройка также возможна с помощью косинусного отжига, поскольку у нас есть дополнительный входной параметр минимального темпа обучения. В зависимости от того, какое значение мы присваиваем этому показателю, мы не только можем контролировать качество/полноту обучения, но и определять, как долго будет длиться обучение на протяжении всех эпох. Таким образом, в зависимости от размера обучающих данных, с которыми приходится иметь дело, это может иметь огромное значение.
В связи с этим часто утверждается, что косинусный отжиг обеспечивает баланс между исследованием (exploration) и применением (exploitation). Исследование — это поиск идеального темпа обучения, в частности, путем корректировки и точной настройки минимального темпа обучения, в то время как применение - это сбор наилучших весов и смещений сети с использованием наиболее известных темпов обучения. Это обычно приводит к улучшенному обобщению модели с учетом двунаправленной оптимизации.
Циклический темп обучения
Циклический темп обучения, в отличие от форматов, которые мы рассматривали до сих пор, начинается с увеличения темпа обучения, а затем в конечном итоге снижается до минимума. Это происходит циклично. Training therefore always starts with the minimum learning rate on each cycle. Формула следующая:
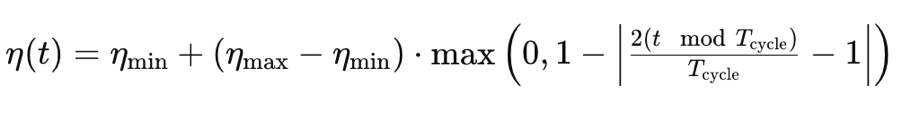
где
- η(t) - темп обучения в эпоху t
- ηmin - минимальный темп обучения
- ηmax - максимальный темп обучения
- Tcycle - л общее количество эпох в данном пакете или цикле (мы тестируем только отдельные циклы)
- (t modTcycle) - остаток от деления числа эпох в цикле на индекс эпохи. Умножаем это значение на 2.
Реализация в MQL5 выглядит так:
else if(m_learning_type == LEARNING_CYCLICAL) { double _x = fabs(((2.0 * fmod(m_epochs - i, m_epochs))/m_epochs) - 1.0); _learning_rate = m_min_learning_rate + ((m_learning_rate - m_min_learning_rate) * fmax(0.0, (1.0 - _x))); }
Тесты на том же символе, таймфрейме и периоде тестирования, которые мы использовали выше, дает нам следующие результаты:


Существует еще одна реализация циклического темпа обучения, называемая triangular-2, где темп обучения сначала увеличивается, а затем снижается до минимума. Отличие заключается в том, что максимальное значение темпа обучения продолжает уменьшаться с каждым циклом.
Мы рассмотрим этот формат темпа обучения, а также дополнительные форматы, в частности адаптивный темп обучения (которая в свою очередь включает в себя различные форматы), теплые перезапуски и скорости одиночного цикла в следующей статье.
Заключение
Мы увидели, как изменение исключительно темпа обучения в алгоритме машинного обучения, таком как генеративно-состязательные сети, может привести к множеству различных результатов. Очевидно, что темп обучения — очень чувствительный гиперпараметр. Основная идея, которая на первый взгляд может показаться невыразительной, заключается в достижении более конкретных и востребованных весов и смещений сети, и тем не менее очевидно, что путь, выбранный для достижения этих весов и смещений, при тестировании в течение фиксированного периода времени и ресурсов может значительно различаться в зависимости от используемого темпа обучения.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/15349
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
 MetaTrader 5 на macOS
MetaTrader 5 на macOS
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования