Нейросети — это просто (Часть 77): Кросс-ковариационный Трансформер (XCiT)

Введение
Трансформеры демонстрируют большой потенциал при решении задач анализа различных последовательностей. Операция Self-Attention, которая лежит в основе трансформеров, обеспечивает глобальные взаимодействия между всеми токенами в последовательности. Что позволяет оценивать взаимозависимости в пределах всей анализируемой последовательности. Однако это сопровождается квадратичной сложностью по времени вычислений и использованию памяти, что затрудняет применение алгоритма к длинным последовательностям.
Для решения этой проблемы авторы статьи "XCiT: Cross-Covariance Image Transformers" предложили "транспонированную" версию Self-Attention, которая действует через каналы признаков, а не через токены, где взаимодействия основаны на матрице кросс-ковариации между ключами и запросами. Результатом является кросс-ковариационное внимание (XCA) с линейной сложностью по количеству токенов, что позволяет эффективно обрабатывать большие последовательности данных. Кросс-ковариационный трансформер изображений (XCiT), основанный на XCA, сочетает точность обычных трансформеров с масштабируемостью сверточных архитектур. В авторской статье экспериментально подтверждается эффективность и общность XCiT. Представленные эксперименты демонстрируют отличные результатах на нескольких визуальных бенчмарках, включая классификацию изображений, обнаружение объектов и сегментацию экземпляров.
1. Алгоритм XCiT
Авторы метода предлагают функцию Self-Attention на основе кросс-ковариации, которая действует вдоль измерения признаков, а не вдоль измерения токенов, как в классическом Self-Attention токенов. Используя определения Query, Key и Value, функция внимания на основе кросс-ковариации определяется следующим образом:
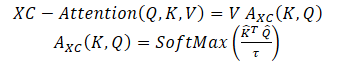
где каждое вложение выходного токена является выпуклой комбинацией dv признаков его соответствующего вложения токена в V. Веса внимания A вычисляются на основе матрицы кросс-ковариации.
В дополнение к построению новой функции внимания на основе матрицы кросс-ковариации, авторы метода предлагают ограничивать величину значений матриц Query и Key путем их L2-нормализации, так чтобы каждый столбец длиной N нормализованных матриц Q и K имел единичную норму. И каждый элемент кросс-ковариационной матрицы коэффициентов внимания размером d * d находился в диапазоне [−1, 1]. Авторы метода утверждают, что контроль нормы значительно повышает стабильность обучения, особенно при обучении с переменным числом токенов. Однако, ограничение нормы снижает репрезентативную мощность операции, удаляя степень свободы. Поэтому авторы вводят обучаемый параметр температуры τ, который масштабирует скалярные произведения перед выполнением нормализации SoftMax, что позволяет получить более четкое или более равномерное распределение весов внимания.
Кроме того, авторы метода ограничивают количество признаков, взаимодействующих между собой. Они предлагают разделить их на h групп, или "головы", аналогично много-головному Self-Attention токенов. При этом авторы метода применяют кросс-ковариационное внимание отдельно для каждой головы.
Для каждой головы обучаются отдельные матрицы весов проекции исходных данных X на Query, Key и Value. Соответствующие матрицы весов собираются в тензоры Wq размерностью {h * d * dq}, Wk — {h * d * dk} и Wv — {h * d * dv} \). Устанавливается dk = dq = dv = d/h.
Ограничение внимания в пределах голов имеет два преимущества:
- Сложность агрегирования значений с весами внимания уменьшается на коэффициент h;
- более важно, авторы метода эмпирически демонстрируют, что версия с блочно-диагональной матрицей проще оптимизируется и обычно приводит к улучшенным результатам.
Классический Self-Attention токенов с h головами имеет временную сложность O(N^2 * d) и память O(hN^2 + Nd). Из-за квадратичной сложности проблематично масштабировать Self-Attention токенов для последовательностей с большим количеством токенов. Предложенное кросс-ковариационное внимание преодолевает этот недостаток, поскольку его вычислительная сложность O(Nd^2 / h) масштабируется линейнон с количеством токенов, также как и сложность памяти O(d^2 / h + Nd).
Следовательно, предложенная авторами модель XCA масштабируется гораздо лучше в случаях, когда количество токенов N большое, а размерность признаков d относительно мала, особенно при разбиении признаков на h голов.
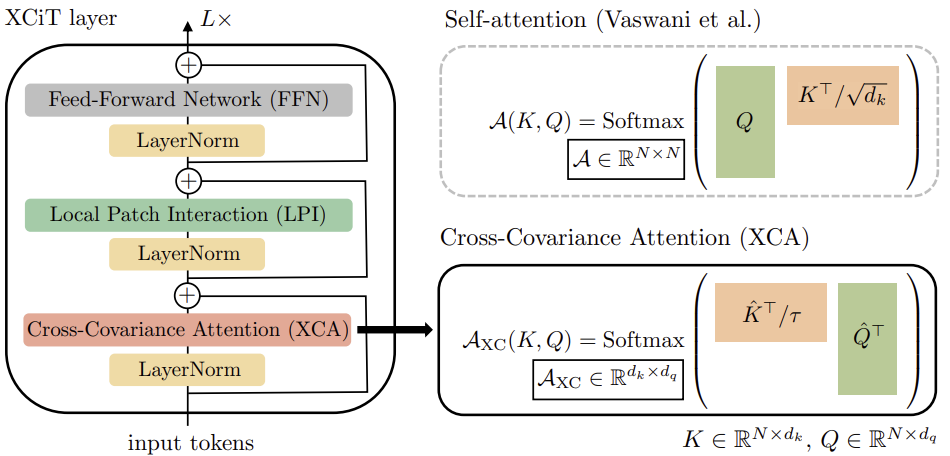
Для построения Кросс-Ковариационных Трансформера изображений (XCiT) авторы метода предлагают столбцовую архитектуру, которая поддерживает одинаковое пространственное разрешение на всех слоях. Они объединяют блок Кросс-Ковариационного Внимания (XCA) с 2 последующими дополнительными модулями, каждому из которых предшествует нормализация в рамках слоя.
В блоке XCA коммуникация между патчами осуществляется только косвенно через общую статистику. Чтобы обеспечить явную коммуникацию между патчами, авторы метода добавляют простой блок локального взаимодействия патчей (LPI) после каждого блока XCA. LPI состоит из двух сверточных слоев и слоем пакетной нормализации между ними. В качестве функции активации первого слоя предлагается GELU. Из-за его глубинной структуры блок LPI имеет незначительные накладные расходы по параметрам, а также очень ограниченные накладные расходы по пропускной способности и использованию памяти.
Как и обычно в моделях трансформеров, далее добавляется сеть прямого распространения (FFN) с точечными сверточными слоями, которая имеет один скрытый слой с 4d скрытыми блоками. В то время как взаимодействие между признаками ограничено в группах в блоке XCA, и в блоке LPI не происходит взаимодействие между признаками, FFN позволяет взаимодействовать со всеми признаками.
В отличие от карты внимания, включенной в Self-Attention токенов, в XCiT блоки ковариации имеют фиксированный размер, независимо от разрешения входноq последовательности. SoftMax всегда работает с одинаковым числом элементов, что может объяснить, почему XCiT модели лучше себя ведут при работе с изображениями различного разрешения. XCiT включает аддитивное синусоидальное позиционное кодирование с входными токенами.
Авторская визуализация алгоритма представлена ниже.
2. Реализация средствами MQL5
После ознакомления с теоретическими аспектами Кросс-Ковариоционного Трансформера (XCiT) мы переходим к практической реализации предложенных подходов средствами MQL5.
2.1 Класс Кросс-Ковариационного Трансформера
И для реализации алгоритма блока XCiT мы создадим новый класс нейронного слоя CNeuronXCiTOCL. В качестве родительского класса мы будем использовать класс классического много-голового много-слойного внимания CNeuronMLMHAttentionOCL. Новый класс мы так же будем создавать со встроенной много-слойной архитектурой.
class CNeuronXCiTOCL : public CNeuronMLMHAttentionOCL { protected: //--- uint iLPIWindow; uint iLPIStep; uint iBatchCount; //--- CCollection cLPI; CCollection cLPI_Weights; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out); virtual bool BatchNorm(CBufferFloat *inputs, CBufferFloat *options, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog); virtual bool BatchNormInsideGradient(CBufferFloat *inputs, CBufferFloat *inputs_g, CBufferFloat *options, CBufferFloat *out, CBufferFloat *out_g, ENUM_ACTIVATION activation); virtual bool BatchNormUpdateWeights(CBufferFloat *options, CBufferFloat *out_g); public: CNeuronXCiTOCL(void) {}; ~CNeuronXCiTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronXCiTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Сразу скажу, что в новом классе мы будем максимально использовать инструменты родительского класса. Однако нам все равно потребуются значительные доработки. Прежде всего мы добавим коллекции буферов для LPI блока:
- cLPI — буферы результатов и градиентов;
- cLPI_Weights — матрицы весов и моментов.
Кроме того, для блока LPI потребуются дополнительные константы
- iLPIWindow — окно свертки первого слоя блока;
- iLPIStep — шаг окна свертки первого слоя блока;
- iBatchCount — количество совершенных операций в слое пакетной нормализации блока.
Мы указываем параметры свертки только в первом слое. Так как во втором слое нам необходимо выйти на размер слоя исходных данных. Ведь авторы метода предлагают сложение и нормализацию данных с результатами работы предыдущего блока XCA.
В данном классе все добавленные объекты объявлены статичными, поэтому конструктор и деструктор слоя мы оставляем пустыми. Сам же процесс начальной инициализации слоя осуществляется в методе Init. В параметрах метод получает все параметры, необходимы для инициализации внутренних объектов.
bool CNeuronXCiTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint lpi_window, uint heads, uint units_count, uint layers, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count, optimization_type, batch)) return false;
В теле метода мы не организовываем блок контроля полученных параметров. Вместо этого мы вызываем метод инициализации базового класса всех нейронных слоев, в котором уже реализованы минимально необходимые контроли и осуществляется инициализации унаследованных объектов.
Здесь следует обратить внимание, что мы вызываем метод базового класса, а не родительского класса. Это связано с тем, что размеры создаваемых нами буферов внутренних слоев и их количество будет отличаться. Поэтому, чтобы не выполнять оду работу 2 раза, мы все буферы будем инициализировать в теле нашего нового метода инициализации.
Вначале мы сохраним основные параметры в локальные переменные.
iWindow = fmax(window, 1); iUnits = fmax(units_count, 1); iHeads = fmax(fmin(heads, iWindow), 1); iWindowKey = fmax((window + iHeads - 1) / iHeads, 1); iLayers = fmax(layers, 1); iLPIWindow = fmax(lpi_window, 1); iLPIStep = 1;
Обратите внимание, что размерности внутренних сущностей мы пересчитываем исходя из размера вектора описания одного элемента последовательности и количества голов внимания. Как это предлагается авторами метода XCiT.
Далее мы определим основные размерности буферов в каждом блоке.
//--- XCA uint num = 3 * iWindowKey * iHeads * iUnits; // Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; // Size of weights' matrix of // QKV tensor uint scores = iWindowKey * iWindowKey * iHeads; // Size of Score tensor uint out = iWindow * iUnits; // Size of output tensor
//--- LPI uint lpi1_num = iWindow * iHeads * iUnits; // Size of LPI1 tensor uint lpi1_weights = (iLPIWindow + 1) * iHeads; // Size of weights' matrix of // LPI1 tensor uint lpi2_weights = (iHeads + 1) * 2; // Size of weights' matrix of // LPI2 tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; // Size of weights' matrix 1-st // feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; // Size of weights' matrix 2-nd // feed forward layer
После чего мы организуем цикл по числу внутренних слоев.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL;
В теле цикла мы сначала создадим буферы промежуточных результатов и градиентов к ним. Для этого мы создадим вложенный цикл. На первой итерации цикла мы создадим буферы промежуточных результатов. А на второй — соответствующих градиентов ошибки.
for(int d = 0; d < 2; d++) { //--- XCiT //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Query, Key и Value мы объединим в один конкатенированный буфер. Это позволит нам генерировать значения всех сущностей за 1 проход для всех голов внимания в параллельных потоках.
Затем создадим уменьшенный буфер коэффициентов кросс-ковариационного внимания.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Завершает блок внимания буфер его результатов.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
Предложенный авторами метода подход с расчетом размера сущностей позволяет нам отказаться от слоя понижения размерности блока внимания.
Далее мы создаем буферы блока LPI. Здесь мы создаем буфер результатов первого слоя свертки.
//--- LPI //--- Initilize LPI tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI1 return false;
За ним идет буфер результатов пакетной нормализации.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI Normalize return false;
И завершает блок буфер результатов второго сверточного слоя.
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI.Add(temp)) // LPI2 return false;
В завершении создадим буфера результатов блока FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Обратите внимание на нюанс с буфером результатов второго слоя блока. Данный буфер мы создаем только для промежуточных данных. Для последнего внутреннего слоя мы не создаем новые буфера, а лишь сохраняем указатель на ранее созданный буфер результатов нашего слоя.
//--- Initialize Feed Forward 2 if(i == iLayers - 1) { if(!FF_Tensors.Add(d == 0 ? Output : Gradient)) return false; continue; } temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
В том же порядке мы создадим буферы матриц весов.
//--- XCiT //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize LPI1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi1_weights)) return false; for(uint w = 0; w < lpi1_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Normalization int count = (int)lpi1_num * (optimization_type == SGD ? 7 : 9); temp = new CBufferFloat(); if(!temp.BufferInit(count, 0.0f)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initilize LPI2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(lpi2_weights)) return false; for(uint w = 0; w < lpi2_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
После инициализации матриц обучаемых весовых коэффициентов мы создадим буферы для записи моментов в процессе обучения моделей. Но здесь следует обратить внимание на буфер параметров слоя пакетной нормализации. В нем уже учтены параметры и их моменты. Поэтому для указанного слоя мы не будем создавать буферы моментов.
Кроме того, количество необходимых буферов моментов зависит от метода оптимизации. Для учета этой особенности мы будем создавать буферы в цикле, число итераций которого зависит от метода оптимизации.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- XCiT temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- LPI temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi1_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(lpi2_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cLPI_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } iBatchCount = 1; //--- return true; }
После успешного создания всех необходимых буферов мы завершаем работу метода и возвращаем логический результат выполнения операций вызывающей программе.
Выполнив инициализацию класса, мы переходим к описанию алгоритма прямого прохода метода XCiT. Как уже было сказано выше, реализация предложенного метода потребует значительных изменений. И для реализации прямого прохода нам необходимо создать кернел на стороне OpenCL программы для реализации алгоритма XCA.
Здесь сразу надо сказать, что сами сущности мы получаем в унаследованном от родительского класса методе ConvolutionForward. И наш кернел работает уже со сформированными сущностями Query, Key и Value, которые мы передаем в кернел единым буфером. Кроме них в параметрах кернела мы передадим указатели еще на 2 буфера данных: коэффициентов внимание и результатов блока внимания.
__kernel void XCiTFeedForward(__global float *qkv, __global float *score, __global float *out) { const size_t d = get_local_id(0); const size_t dimension = get_local_size(0); const size_t u = get_local_id(1); const size_t units = get_local_size(1); const size_t h = get_global_id(2); const size_t heads = get_global_size(2);
Сам кернел мы будем запускать в 3 мерном пространстве задач:
- размерность одного элемента сущностей;
- длина последовательности;
- количества голов внимания.
По первым двум измерениям мы объединим в локальные рабочие группы.
Сразу объявим 2 локальных 2 мерных массива для записи промежуточных данных и обмена информацией в рамках рабочей группы.
const uint ls_u = min((uint)units, (uint)LOCAL_ARRAY_SIZE); const uint ls_d = min((uint)dimension, (uint)LOCAL_ARRAY_SIZE); __local float q[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE]; __local float k[LOCAL_ARRAY_SIZE][LOCAL_ARRAY_SIZE];
Перед началом работы по анализу кросс-ковариационного внимания нам предстоит провести нормализацию сущностей Query и Key, как было предложено авторами метода.
Для этого мы сначала в рамках группы посчитаем размеры векторов по каждому параметру.
//--- Normalize Query and Key for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { float q_val = 0; float k_val = 0; //--- if(d < ls_d && (cur_d + d) < dimension && u < ls_u) { for(int count = u; count < units; count += ls_u) { int shift = count * dimension * heads * 3 + dimension * h + cur_d + d; q_val += pow(qkv[shift], 2.0f); k_val += pow(qkv[shift + dimension * heads], 2.0f); } q[u][d] = q_val; k[u][d] = k_val; } barrier(CLK_LOCAL_MEM_FENCE);
uint count = ls_u; do { count = (count + 1) / 2; if(d < ls_d) { if(u < ls_u && u < count && (u + count) < units) { float q_val = q[u][d] + q[u + count][d]; float k_val = k[u][d] + k[u + count][d]; q[u + count][d] = 0; k[u + count][d] = 0; q[u][d] = q_val; k[u][d] = k_val; } } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
После чего разделим каждый каждый элемент в последовательности на корень квадратный из размера вектора по соответствующему измерению.
int shift = u * dimension * heads * 3 + dimension * h + cur_d; qkv[shift] = qkv[shift] / sqrt(q[0][d]); qkv[shift + dimension * heads] = qkv[shift + dimension * heads] / sqrt(k[0][d]); barrier(CLK_LOCAL_MEM_FENCE); }
Теперь, когда наши сущности нормализованы, мы можем переходить к определению коэффициентов зависимости. Для этого нам предстоит умножить матрицы Query и Key. При этом мы сразу берем экспоненту от полученного значения и суммируем их.
//--- Score int step = dimension * heads * 3; for(int cur_r = 0; cur_r < dimension; cur_r += ls_u) { for(int cur_d = 0; cur_d < dimension; cur_d += ls_d) { if(u < ls_d && d < ls_d) q[u][d] = 0; barrier(CLK_LOCAL_MEM_FENCE); //--- if((cur_r + u) < ls_d && (cur_d + d) < ls_d) { int shift_q = dimension * h + cur_d + d; int shift_k = dimension * (heads + h) + cur_r + u; float scr = 0; for(int i = 0; i < units; i++) scr += qkv[shift_q + i * step] * qkv[shift_k + i * step]; scr = exp(scr); score[(cur_r + u)*dimension * heads + dimension * h + cur_d + d] = scr; q[u][d] += scr; } } barrier(CLK_LOCAL_MEM_FENCE);
int count = ls_d; do { count = (count + 1) / 2; if(u < ls_d) { if(d < ls_d && d < count && (d + count) < dimension) q[u][d] += q[u][d + count]; if(d + count < ls_d) q[u][d + count] = 0; } barrier(CLK_LOCAL_MEM_FENCE); } while(count > 1);
После чего нормализуем коэффициенты зависимости.
if((cur_r + u) < ls_d) score[(cur_r + u)*dimension * heads + dimension * h + d] /= q[u][0]; barrier(CLK_LOCAL_MEM_FENCE); }
В завершении операций кернела мы умножим тензор Value на коэффициенты зависимости. Результат данной операции сохраним в буфер результатов блока внимания XCA.
int shift_out = dimension * (u * heads + h) + d; int shift_s = dimension * (heads * d + h); int shift_v = dimension * (heads * (u * 3 + 2) + h); float sum = 0; for(int i = 0; i < dimension; i++) sum += qkv[shift_v + i] * score[shift_s + i]; out[shift_out] = sum; }
После создания кернела на стороне OpenCL программы мы переходим к работе в нашем классе на стороне основной программы. Здесь мы создаем сначала метод CNeuronXCiTOCL::XCiT, в котором реализуем алгоритм вызова созданного кернела.
bool CNeuronXCiTOCL::XCiT(CBufferFloat *qkv, CBufferFloat *score, CBufferFloat *out) { if(!OpenCL || !qkv || !score || !out) return false;
В параметрах метода мы будем передавит указатели на 3 используемых буфера данных. И в теле метода мы сразу проверяем актуальность полученных указателей.
После чего определим пространство задач и смещения в нем.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads}; uint local_work_size[3] = {iWindowKey, iUnits, 1};
Как было сказано выше, мы объединяем потоки в рабочие группы по первым 2 измерениям.
Далее мы передаем в кернел указатели на буферы данных.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_score, score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTFeedForward, def_k_XCiTff_out, out.GetIndex())) return false;
И ставим кернел в очередь выполнения.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTFeedForward, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); Print(error); return false; } //--- return true; }
В дополнение к выше описанному методу мы создадим метод прямого прохода слоя пакетной нормализации CNeuronXCiTOCL::BatchNorm, алгоритм которого полностью перенесен с метода CNeuronBatchNormOCL::feedForward. Но мы не будем сейчас останавливаться на рассмотрении его алгоритма. Давайте перейдем непосредственно к анализу метода CNeuronXCiTOCL::feedForward, который представляет собой общую схему алгоритма прямого распространения в блокеа XCiT.
bool CNeuronXCiTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
В параметрах метод получает указатель на объект предыдущего слоя, который предоставляет нам исходные данные. И в теле метода мы сразу проверяем актуальность полученного указателя.
После успешного прохождения точки контроля мы создаем цикл перебора внутренних слоев. Именно в теле данного цикла мы и построим весь алгоритм метода.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- Calculate Queries, Keys, Values CBufferFloat *inputs = (i == 0 ? NeuronOCL.getOutput() : FF_Tensors.At(4 * i - 2)); CBufferFloat *qkv = QKV_Tensors.At(i * 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Здесь мы сначала формируем наши сущности Query, Key и Value. А затем вызовем наш метод крос-ковариационного внимания.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 2); CBufferFloat *out = AO_Tensors.At(i * 2); if(IsStopped() || !XCiT(qkv, temp, out)) return false;
Результаты внимания складываем с исходными данными и нормализуем полученные значения.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Далее идет блок LPI. Сначала организуем работу первого слоя блока.
//--- LPI inputs = out; temp = cLPI.At(i * 6); if(IsStopped() || !ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), inputs, temp, iLPIWindow, iHeads, LReLU, iLPIStep)) return false;
Результаты работы первого слоя нормализуем.
out = cLPI.At(i * 6 + 1); if(IsStopped() || !BatchNorm(temp, cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), out)) return false;
И передадим во второй слой блока.
temp = out; out = cLPI.At(i * 6 + 2); if(IsStopped() ||!ConvolutionForward(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, out, 2 * iHeads, 2, None, iHeads)) return false;
Повторно суммируем и нормализуем результаты.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false;
Организуем работу блока FeedForward.
//--- Feed Forward inputs = out; temp = FF_Tensors.At(i * 4); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 4 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 4 : 6) + 1), temp, out, 4 * iWindow, iWindow, activation)) return false;
И на выходе слоя суммируем и нормализуем результаты работы блоков.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, out, iWindow, true)) return false; } iBatchCount++; //--- return true; }
На этом мы завершаем работу по реализации прямого прохода нашего нового слоя Кросс-Ковариационного трансформера CNeuronXCiTOCL. И переходим к построению алгоритма обратного прохода. Здесь нам так же предстоит вернуться к OpenCL программе и создать ещё один кернел. Алгоритм обратного прохода XCA блока мы построим в кернеле XCiTInsideGradients. В параметрах кернелу мы будем передавать указатели на 4 буфера данных:
- qkv — конкатенированный вектор сущностей Query, Key и Value;
- qkv_g — конкатенированный вектор градиентов ошибки сущностей Query, Key и Value;
- scores — матрица коэффициентов зависимости;
- gradient — тензор градиентов ошибки на выходе блока внимания XCA.
__kernel void XCiTInsideGradients(__global float *qkv, __global float *qkv_g, __global float *scores, __global float *gradient) { //--- init const int q = get_global_id(0); const int d = get_global_id(1); const int h = get_global_id(2); const int units = get_global_size(0); const int dimension = get_global_size(1); const int heads = get_global_size(2);
Кернел мы планируем запускать в 3 мерном пространстве задач. И в теле кернела мы сразу идентифицируем поток и пространство задач. После чего определим смещение в буферах данных до анализируемых элементов.
const int shift_q = dimension * (heads * 3 * q + h); const int shift_k = dimension * (heads * (3 * q + 1) + h); const int shift_v = dimension * (heads * (3 * q + 2) + h); const int shift_g = dimension * (heads * q + h); int shift_score = dimension * h; int step_score = dimension * heads;
В соответствии с алгоритмом обратного прохода мы первым определяем градиент ошибки на тензоре Value.
//--- Calculating Value's gradients float sum = 0; for(int i = 0; i < dimension; i ++) sum += gradient[shift_g + i] * scores[shift_score + d + i * step_score]; qkv_g[shift_v + d] = sum;
Затем определим градиент ошибки для Query. Здесь нам предстоит сначала определить градиент ошибки на соответствующем векторе матрицы коэффициентов. Затем скорректировать полученные градиенты ошибки на производную функции SoftMax. И лишь только в таком случае мы можем получить необходимы градиент ошибки.
//--- Calculating Query's gradients float grad = 0; float val = qkv[shift_v + d]; for(int k = 0; k < dimension; k++) { float sc_g = 0; float sc = scores[shift_score + k]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_score + v] * val * gradient[shift_g + v * dimension] * ((float)(k == v) - sc); grad += sc_g * qkv[shift_k + k]; } qkv_g[shift_q] = grad;
Для тензора Key градиент ошибки определяем аналогично, но в перпендикулярном направлении векторов.
//--- Calculating Key's gradients grad = 0; float out_g = gradient[shift_g]; for(int scr = 0; scr < dimension; scr++) { float sc_g = 0; int shift_sc = scr * dimension * heads; float sc = scores[shift_sc + d]; for(int v = 0; v < dimension; v++) sc_g += scores[shift_sc + v] * out_g * qkv[shift_v + v] * ((float)(d == v) - sc); grad += sc_g * qkv[shift_q + scr]; } qkv_g[shift_k + d] = grad; }
После построения кернела, мы возвращаемся к работе с нашим классом на стороне основной программы. Здесь мы создаем метод CNeuronXCiTOCL::XCiTInsideGradients. В параметрах метод получает указатели на необходимые буферы данных.
bool CNeuronXCiTOCL::XCiTInsideGradients(CBufferFloat *qkv, CBufferFloat *qkvg, CBufferFloat *score, CBufferFloat *aog) { if(!OpenCL || !qkv || !qkvg || !score || !aog) return false;
В теле метода мы сразу проверяем актуальность полученных указателей.
После чего определяем 3 мерное пространство задач. Только на этот раз мы не определяем рабочие группы.
uint global_work_offset[3] = {0, 0, 0}; uint global_work_size[3] = {iWindowKey, iUnits, iHeads};
Указатели на буферы данных передадим в параметры кернелу.
if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv, qkv.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_qkv_g, qkvg.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_scores,score.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_XCiTInsideGradients, def_k_XCiTig_gradient,aog.GetIndex())) return false;
После выполнения подготовительной работы нам остается лишь поставить кернел в очередь выполнения.
ResetLastError(); if(!OpenCL.Execute(def_k_XCiTInsideGradients, 3, global_work_offset, global_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Полный алгоритм обратного блока XCiT собран в диспетчерском методе CNeuronXCiTOCL::calcInputGradients. В параметрах метод получает указатель на объект предшествующего слоя.
bool CNeuronXCiTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
В теле метода мы сразу проверяем действительность полученного указателя. И после успешного прохождения точки контроля мы организуем цикл обратного перебора внутренних слоев с передачей градиента ошибки.
CBufferFloat *out_grad = Gradient; //--- for(int i = int(iLayers - 1); (i >= 0 && !IsStopped()); i--) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i*(optimization==SGD ? 4:6)+1), out_grad, FF_Tensors.At(i * 4), FF_Tensors.At(i * 4 + 2), 4 * iWindow, iWindow, None)) return false;
В теле цикла мы сначала проведем градиент ошибки через блок FeedForward.
CBufferFloat *temp = cLPI.At(i * 6 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 4 : 6)), FF_Tensors.At(i * 4 + 1), cLPI.At(i * 6 + 2), temp, iWindow, 4 * iWindow, LReLU)) return false;
Напомню, что при прямом проходе мы складывали результаты работы блоков с исходными данными. Аналогично, мы проводим градиент ошибки по 2 потокам.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
Далее мы передаем градиент ошибки через блок LPI.
out_grad = temp; //--- Passing gradient through LPI if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 2), temp, cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), 2 * iHeads, 2, None, 0, iHeads)) return false; if(IsStopped() || !BatchNormInsideGradient(cLPI.At(i * 6), cLPI.At(i * 6 + 3), cLPI_Weights.At(i * (optimization == SGD ? 5 : 7) + 1), cLPI.At(i * 6 + 1), cLPI.At(i * 6 + 4), LReLU)) return false; if(IsStopped() || !ConvolutionInputGradients(cLPI_Weights.At(i * (optimization == SGD ? 5 : 7)), cLPI.At(i * 6 + 3), AO_Tensors.At(i * 2), AO_Tensors.At(i * 2 + 1), iLPIWindow, iHeads, None, 0, iLPIStep)) return false;
Снова складываем градиенты ошибки.
temp = AO_Tensors.At(i * 2 + 1); //--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
После чего проводим градиент ошибки через блок внимания XCA.
out_grad = temp; //--- Passing gradient to query, key and value if(IsStopped() || !XCiTInsideGradients(QKV_Tensors.At(i * 2), QKV_Tensors.At(i * 2 + 1), S_Tensors.At(i * 2), temp)) return false;
И передадим его в буфер градиентов исходных данных.
CBufferFloat *inp = NULL; if(i == 0) { inp = prevLayer.getOutput(); temp = prevLayer.getGradient(); } else { temp = FF_Tensors.At(i * 4 - 1); inp = FF_Tensors.At(i * 4 - 3); } if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(i * 2 + 1), inp, temp, iWindow, 3 * iWindowKey * iHeads, None)) return false;
И не забываем добавить градиент ошибки по второму потоку.
//--- Sum and normilize gradients if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow)) return false; if(i > 0) out_grad = temp; } //--- return true; }
Выше мы реализовали алгоритм распространения градиента ошибки к внутренним слоям и передачи его на предшествующий нейронный слой. И в завершении операций обратного прохода нам предстоит обновить параметры модели.
Обновление параметров нашего нового слоя Кросс-Ковариационного Трансформера осуществляется в методе CNeuronXCiTOCL::updateInputWeights. Как и аналогичные методы других нейронных слоев, в параметрах метод получает указатель на нейронный слой предшествующего слоя.
bool CNeuronXCiTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput();
И в теле метода мы проверяем актуальность полученного указателя.
Как и распределение градиента ошибки, обновления параметров мы будем осуществлять в цикле перебора внутренних слоев.
for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 2 : 3)), QKV_Tensors.At(l * 2 + 1), inputs, (optimization==SGD ? QKV_Weights.At(l*2+1):QKV_Weights.At(l*3+1)), (optimization==SGD ? NULL : QKV_Weights.At(l*3+2)), iWindow, 3 * iWindowKey * iHeads)) return false;
Первыми мы обновляем параметры матриц формирования сущностей Query, Key и Value.
Далее обновляем параметры блока LPI. Данный блок содержит 2 сверточных слоя и слой пакетной нормализации.
if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7)), cLPI.At(l * 6 + 3), AO_Tensors.At(l * 2), (optimization==SGD ? cLPI_Weights.At(l*5+3):cLPI_Weights.At(l*7+3)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 5)), iLPIWindow, iHeads, iLPIStep)) return false; if(IsStopped() || !BatchNormUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 1), cLPI.At(l * 6 + 4))) return false; if(IsStopped() || !ConvolutuionUpdateWeights(cLPI_Weights.At(l * (optimization == SGD ? 5 : 7) + 2), cLPI.At(l * 6 + 5), cLPI.At(l * 6 + 1), (optimization==SGD ? cLPI_Weights.At(l*5+4):cLPI_Weights.At(l*7+4)), (optimization==SGD ? NULL : cLPI_Weights.At(l * 7 + 6)), 2 * iHeads, 2, iHeads)) return false;
И завершает работу метода блок обновления параметров блока FeedForward.
if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6)), FF_Tensors.At(l * 4 + 2), cLPI.At(l * 6 + 2), (optimization==SGD ? FF_Weights.At(l*4+2):FF_Weights.At(l*6+2)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 4)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 4 : 6) + 1), FF_Tensors.At(l * 4 + 3), FF_Tensors.At(l * 4), (optimization==SGD ? FF_Weights.At(l*4+3):FF_Weights.At(l*6+3)), (optimization==SGD ? NULL : FF_Weights.At(l * 6 + 5)), 4 * iWindow, iWindow)) return false; inputs = FF_Tensors.At(l * 4 + 1); } //--- return true; }
На этом мы завершаем работу по организации методов прямого и обратного прохода нашего класса Кросс-Ковариационного Трансформера CNeuronXCiTOCL. Для полноценной работы класса еще необходимо добавить несколько вспомогательных методов. Среди которых и методы работы с файлами (Save и Load). Алгоритм данных методов не сложен и не содержит каких-либо уникальных моментов, относящихся к рассматриваемому методу XCiT. Поэтому я не буду останавливаться на описании их алгоритмов в рамках данной статье. И предлагаю Вам самостоятельно ознакомиться с ними во вложении. Там Вы можете найти полный код представленного класса. А так же все программы, используемые при подготовке данной статьи.
2.2 Архитектура моделей
А мы переходим к построению советников обучения и тестирования моделей. И тут надо сказать, что в своей работе авторы метода не представили конкретной архитектуры моделей. По существу, предложенный Кросс-Ковариационный Трансформер может заменить рассматриваемый нами ранее классический Трансформер в любой модели. Следовательно, в рамках эксперимента мы можем взять модель из предыдущей статьи и заменить слой CNeuronMLMHAttentionOCL на CNeuronXCiTOCL.
Конечно, здесь надо быть честными. В предыдущей работе мы использовали различные блоки внимания. И акцент был сделан на использование CNeuronMFTOCL, который в силу архитектурных особенностей не может быть заменен на CNeuronXCiTOCL.
Тем не менее, замена даже одного слоя позволяет нам в той или иной степени оценить внесенные изменения.
И так, финальная архитектура тестируемой модели имеет следующий вид.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
"Сырые" исходные данные описания 1 бара поступают на слой исходных данных энкодера состояния окружающей среды.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Полученные данные обрабатываются в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Из нормализованных данных формируется эмбединг состояния окружающей среды и добавляется во внутренний стек.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Здесь же мы добавляем позиционное кодирование данных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
За которым идет графовый блок с пакетной нормализацией между слоями.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
А далее мы добавим наш новый слой Кросс-Ковариоционного Трансформера. Количество элементов последовательности и окна исходных данных мы оставили без изменений. Указанные параметры определяются тензором исходных данных.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronXCiTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 3; descr.layers = 1; descr.batch = MathMax(1000, GPTBars); descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
В данном случае мы используем 4 головы внимания.
Напомню, что авторы метода предлагают для определения размера вектора сущностей использовать целочисленное деление размера вектора описания одного элемента последовательности на количества голов внимания. В таком варианте у нас высвобождается параметр descr.window_out. Мы воспользуемся этим фактом и укажем в данный параметр размер окна первого слоя LPI. А также укажем размер пакета для нормализации данных в блоке LPI.
За энкодером идет блок MFT.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
И транспонируем тензор для приведения в соответствующий вид.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Результаты энкодера состояния окружающей среды и MFT используются для декодирования наиболее вероятных конечных точек.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
И оценки их вероятности.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false; //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
В модели Актера не использовались слои внимания. И, следовательно, модель была полностью перенесена без изменений. А с полной архитектурой всех моделей Вы можете самостоятельно ознакомиться во вложении.
Сразу надо сказать, замена одного слоя в архитектуре энкодера состояния окружающей среды не оказывает влияние на организацию процесса обучения и тестирования моделей. Поэтому все советники обучения и взаимодействия с окружающей средой были перенесены без изменений. На мой взгляд это повышает интерес результатам тестирования. Ведь при сохранении прочих равных условий мы можем наиболее честно оценить влияние замены слоя в архитектуре модели.
С полным кодом всех программ, используемых при подготовке статьи, Вы можете самостоятельно ознакомиться во вложении. А мы переходим к тестированию построенного слоя Кросс-Ковариационного Трансформера CNeuronXCiTOCL.
3. Тестирование
Выше была проделана большая работа по построению нового класса Кросс-Ковариационного Трансформера CNeuronXCiTOCL, предложенного в статье " XCiT: Cross-Covariance Image Transformers". Как уже было сказано выше, мы полностью перенесли советник из предыдущей статьи. Следовательно, и для обучения моделей мы можем восполльзоваться ранее собранной выборкой обучающих данных. Для этого мы переименуем файл "MFT.bd" в "XCiT.bd".
Если у Вас нет ранее собранной обучающей выборки, то перед обучением модели необходимо собрать её. Я рекомендую сначала собрать данные с реальных сигналов по методу, описанному в статье "Использование прошлого опыта для решения новых задач". А затем дополнить обучающую выборку случайными проходами советник "...\Experts\XCiT\Research.mq5" в тестере стратегий.
Обучение моделей осуществляется в советнике "...\Experts\XCiT\Study.mq5" после сбора обучающих данных.
Как и ранее, модель обучается на исторических данных инструмента EURUSD тайм-фрейм H1. Параметры всех анализируемых индикаторов используются по умолчанию.
Обучение модели осуществлялось на исторических данных за первые 7 месяцев 2023 года. И тут можно сразу отметить первые результаты проверки эффективности предложенных подходов. В процессе обучения было зафиксировано сокращение затрат времени почти на 2% с сохранением итераций обучения.
Оценка эффективности обученной модели производилась на исторических данных за август 2023 года. Период тестирования не входит в обучающую выборку. Но при этом следует непосредственно за периодом обучения. По результатам тестирования обученной модели был зафиксирован результат, близкий к предыдущему.
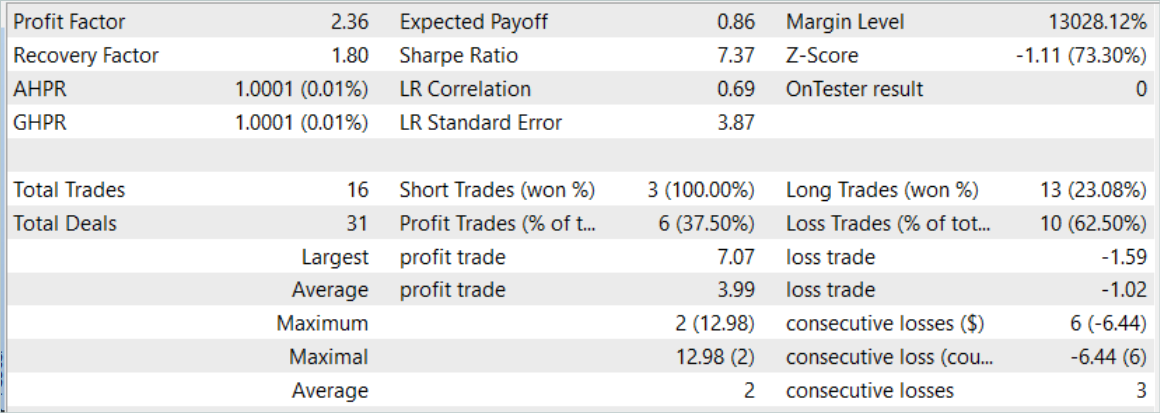
Тем не менее, за небольшим увеличением количества сделок кроется и увеличение коэффициента профит фактора.
Заключение
В данной статье мы познакомились с новой архитектурой Кросс-Ковариационного Трансформера (XCiT), которая объединяет преимущества Трансформеров и Сверточных архитектур. Она обеспечивает высокую точность и масштабируемость при обработке последовательностей различной длины. Небольшая эффективность достигается при анализе больших последовательностей с малы м размером токенов.
XCiT использует архитектуру Кросс-Ковариационного внимания для эффективного моделирования глобальных взаимодействий между признаками элементов последовательности, что позволяет ей успешно справляться с длинными последовательностями токенов.
Авторы метода экспериментально подтверждают высокую эффективность XCiT на нескольких визуальных задачах, включая классификацию изображений, обнаружение объектов и семантическую сегментацию.
В практической части нашей статьи мы реализовали предложенные методы средствами MQL5. Провели обучение и тестирование модели на реальных исторических данных. В процессе обучение было отмечено незначительное сокращение времени обучения при сохранении количества обучаемых итераций. При этом мы заменили всего лишь один слой в модели.
А небольшое повышение эффективности обученной модели может свидетельствовать о лучшей обобщающей способности предложенной архитектуры.
Напоминаю, что торговля на финансовых рынках относится к инвестициям с высоким риском. Все программы, представленные в статье, носят только ознакомительный характер и не оптимизированы для реальной торговли.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования