
Нейросети — это просто (Часть 76): Изучение разнообразных режимов взаимодействия (Multi-future Transformer)

Введение
Прогнозирование предстоящего ценового движения — один из ключевых компонентов построения успешной торговой стратегии. Поэтому нам необходимо изучить возможности создания точных и мультимодальных прогнозов будущего движения. В предыдущих статьях мы познакомились с некоторыми методами прогнозирования ценового движения. Среди них были и мультимодальные, предлагающие несколько вариантов развития событий.
Однако, все они редко концентрируются на будущих возможностях взаимодействия между анализируемыми агентами, что может привести к потере информации и неоптимальному прогнозированию. Кроме того, довольно сложно масштабировать ранее рассмотренные методы на случай нескольких агентов, поскольку независимые прогнозы могут привести к экспоненциальному числу комбинаций. Большая часть полученных комбинаций неосуществима из-за противоречивых прогнозов. Поэтому важно сосредоточиться на прогнозировании сцен в целом, оценивая одновременно будущее состояние нескольких агентов.
В статье «Multi-future Transformer: Learning diverse interaction modes for behaviour prediction in autonomous driving» для решения подобных задач предлагается метод Multi-future Transformer (MFT). Основная идея которого заключается в разложении мультимодального распределение будущего на несколько унимодальных распределений, что позволяет эффективно моделировать разнообразные модели взаимодействия между агентами на сцене.
В MFT прогнозы создаются нейронной сетью с фиксированными параметрами за один прямой проход без необходимости стохастической выборки скрытых переменных, предварительного определения привязок или запуска итеративного алгоритма постобработки. Это позволяет модели работать в детерминированном, воспроизводимом режиме.
1. Алгоритм Multi-future Transformer
Основная цель метода Multi-future Transformer состоит в последовательном прогнозировании будущего движения Y всех агентов на сцене. Для этого анализируется динамическое состояние агентов X и контекстная информация M. Таким образом, общее вероятностное распределение для захвата равно P(Y|X,M), которое является мультимодальным в результате четкой эволюции сцены.
Обычно очень сложно напрямую смоделировать совместное мультимодальное распределение. И авторы метода вводят предположение, что целевое распределение можно разложить на смесь нескольких унимодальных распределений, а затем эти унимодальные распределения моделируются отдельно, что формулируется как
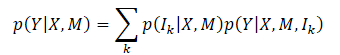
где Ik — k-я составляющая режима;
p(Ik|X,M) — распределение вероятностей различных режимов;
p(Y|X,M,Ik) — факторизованное унимодальное распределение.
Согласно этой формулировке, ключевым моментом MFT является то, что основное различие между каждым режимом целевого распределения заключается в различных моделях взаимодействия между агентами, а также между агентами и контекстом. Моделирование каждого унимодального распределения может быть реализовано путем изучения закономерностей взаимодействия мод-соответствий. Интуитивно понятно, что будущая неопределенность сцены может быть в основном разложена на две части: неопределенность намерения и неопределенность взаимодействия.
Ненаблюдаемые намерения можно хорошо уловить путем моделирования взаимодействия между агентом и контекстом, поскольку конечная точка будущей траектории, представляющая намерения агента, тесно связана с контекстом сцены. Чтобы учесть неопределенность взаимодействия, моделируются различные режимы взаимодействия между агентами. Таким образом, путем совместного захвата взаимодействия агента с агентом, а также взаимодействия агента с контекстом, будущая неопределенность сводится к минимуму и можно определить развитие сцены.
Для достижения описанной выше декомпозиции мультимодального совместного распределения была разработана общая архитектура предлагаемого подхода MFT, которая состоит из трех частей:
- Кодировщиков,
- Модуля параллельного взаимодействия,
- Заголовков прогнозирования.
В модель включены два типа кодировщиков:
- динамический кодировщик агента используется для извлечения функций из наблюдаемых динамических состояний,
- кодировщик сегментов контекста служит модулем представления карты для изучения поточечных функций для точек полосы.
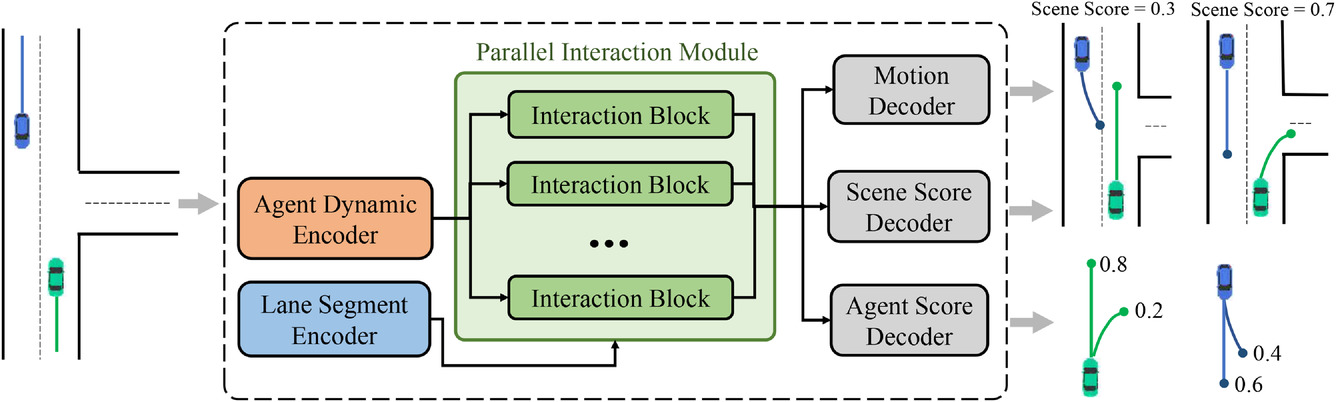
Ядром модели MFT является модуль параллельного взаимодействия, который состоит из нескольких блоков взаимодействия в параллельной структуре и изучает будущие особенности движения агентов для каждого режима. Три заголовка прогнозирования включают:
- Декодер движения,
- Декодер оценки агента,
- Декодер оценки сцены.
Они отвечают за декодирование будущих траекторий для каждого агента и оценивают показатели достоверности для каждой прогнозируемой траектории и каждого режима сцены. В этой архитектуре пути, по которым проходят прямые и обратные сигналы каждого режима, независимы друг от друга, и каждый путь содержит уникальный блок взаимодействия, который обеспечивает информационное взаимодействие между сигналами одного и того же режима. Следовательно, блоки взаимодействия могут одновременно фиксировать соответствующие шаблоны взаимодействия разных режимов. Однако кодеры и заголовки прогнозирования являются общими для каждого режима, тогда как блоки взаимодействия параметризуются как разные объекты. Так что каждое унимодальное распределение, которое теоретически имеет разные параметры, может быть смоделировано более эффективным с точки зрения параметров способом. Авторская визуализация метода представлена ниже.
Пройденные траектории агентов на историческом горизонте можно представить как X={x1,...,xatt}, где динамическое состояние на каждом временном шаге xt=(x,y,vx,vy,w) содержит позицию (x,y), скорость (vx,vy), и угол отклонения от курса w в этот момент.
Динамические состояния агента рассматриваются как набор точек в многомерном пространстве, где каждая точка представлена координатами (x,y), а другие измерения являются дополнительными локальными особенностями. Для этих точек сохраняются свойства взаимодействия и заданная локальная структура, поскольку наблюдаемые состояния агента взаимодействуют друг с другом и вместе образуют прошлую траекторию агента. Кроме того, еще одним немаловажным свойством этих точек траектории является временной порядок, который является неявной характеристикой по сравнению со статическими точками полосы движения. Естественно, что одни и те же точки траектории с обратным временным порядком приводят к совершенно другой траектории прошлого. Вышеупомянутые свойства требуют, чтобы модель представляла точки траектории не только путем объединения точечных функций, но также путем введения информации о временном порядке. С этой целью для кодирования информации об упорядочении используется абсолютное позиционное кодирование. Модель вычисляет динамические характеристики для каждого агента следующим образом:
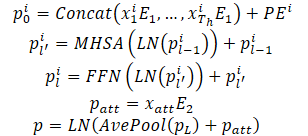
Hесколько слоев кодера объединены в стопку, чтобы улучшить способность модели представлять динамическую информацию. Усреднение выполняется по всем точкам траектории агента для обобщения исторической динамической информации, относящейся к конкретному агенту.
Точечные характеристики, соответствующие текущему моменту, также были извлечены для получения динамической информации. Это обеспечивает производительность, аналогичную среднему пулу. При работе с частично наблюдаемыми историческими состояниями структура, основанная на Self-Attention, может просто маскировать ненаблюдаемые положения без дополнительных усилий, тем самым эффективно избегая путаницы функций, вызванной недопустимым заполнением.
Отличительной характеристикой задачи прогнозирования поведения является мультимодальность, вызванная будущей неопределенностью сцены. Общий подход заключается в использовании нескольких голов результатов для независимого декодирования будущих траекторий каждого агента на основе общего вектора признаков. Однако этот метод имеет два основных недостатка:
- информация о движении различных возможных будущих траекторий содержится в одном векторе признаков с фиксированной размерностью, что приводит к ограничению информации и в значительной степени ограничивает выразительные возможности модели;
- прямые и обратные сигналы разных мод смешиваются в процессе взаимодействия признаков и распространения градиента, что приводит к проблеме путаницы мод, которая ухудшает возможность делать мультимодальные прогнозы.
Вместо этого в MFT моделирование взаимодействия разделяется на разные режимы для достижения мультимодального результата путем изучения уникального шаблона взаимодействия, соответствующего каждому режиму. С этой целью был спроектирован модуль параллельного взаимодействия. Этот модуль содержит несколько блоков параллельного взаимодействия, каждый из которых представляет определенный режим будущего развития событий. В этой структуре внутрирежимные прямые и обратные сигналы пересекают блок взаимодействия соответствующего режима. В то же время другие режимы не создают помех, что позволяет избежать проблемы путаницы режимов.
Кроме того, каждый блок взаимодействия параметризуется как отдельный объект, что позволяет модели иметь достаточную выразительную силу, позволяющую справиться с большой разницей между различными режимами. В каждом блоке взаимодействия используется механизм Self-Attention для моделирования взаимодействия между агентами и механизм Cross-Attention для фиксации взаимодействия между агентами и сценой. Эти два типа функций взаимодействия добавляются к динамической функции посредством остаточного соединения для получения окончательной функции предстоящего движения для каждого агента и режима. Вышеописанный процесс можно описать следующим образом:

Окончательную структуру модуля параллельного взаимодействия можно рассматривать как распараллеливание декодера Transformer с последовательной структурой. Однако мультимодальное прогнозирование и повышенная выразительная сила достигаются при аналогичных вычислительных затратах по сравнению со стандартным аналогом. Проведенные авторами метода эксперименты подтверждают, что в сочетании с использование ошибки "победитель получает все" на уровне сцены предложенный метод может обеспечить согласованное прогнозирование поведения нескольких агентов. Также было проведено исследование продемонстрировать незаменимость двух типов моделируемых взаимодействий и обоснованность конструкции модульной структуры.
Авторская визуализация структуры модулей представлена ниже.

Помимо прогнозирования будущей траектории каждого агента, MFT осуществляет оценку правдоподобия для каждого возможного развития сцены, а также для каждой прогнозируемой траектории агента. Для задач планирования движения, идеальными входными данными могут быть прогнозирование мультимодальной сцены с соответствующим показателем достоверности для каждого режима сцены. Алгоритм планирования может напрямую вычислить возможную будущую траекторию движения, учитывая все соседние агенты одновременно. Для этой цели авторы метода разработали головы прогнозирования различных вариантов сцены и их вероятностей.
Для оценки вероятности на уровне сцены, выполняется усреднение векторов признаков всех агентов на сцене. Что позволяет получить представление на уровне сцены.
Кроме того, чтобы обратить особое внимание на агента, оценка правдоподобия должна выполняться с точки зрения самого агента. Следовательно, создан третья голова модели для декодирования оценок достоверности прогнозируемых траекторий каждого агента. Процесс декодирования Multi-future Transformer формулируется следующим образом:
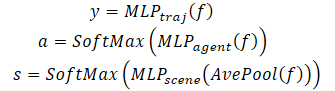
Стоит добавить, что для декодирования мультимодальной сцены используется декодер с одинаковыми параметрами для всех вариантов возможного развития событий.
2. Реализация средствами MQL5
После рассмотрения теоретических аспектов метода Multi-future Transformer мы переходим к практической части нашей статьи. И рассмотрим вариант реализации предложенного метода средствами MQL5.
Из представленного выше описания алгоритма Multi-future Transformer можно сказать, что основную сложность реализации для нас представляет модуль параллельного взаимодействия. В нашей библиотеки уже есть реализованные слои много-голового Self-Attention (CNeuronMLMHAttentionOCL) и Cross-Attention (CNeuronMH2AttentionOCL). Однако, даже при использовании нескольких голов внимания, потоки информации в них смешиваются при прямом и обратном проходах. Что не удовлетворяет условиям метода Multi-future Transformer.
Поэтому свою реализацию метода мы начнем с создания класса нового нейронного слоя.
2.1. Модуль параллельного взаимодействия
Алгоритм модуля параллельного взаимодействия мы реализуем в классе CNeuronMFTOCL, который мы создадим наследником класса CNeuronMLMHAttentionOCL.
Здесь стоит отметить, что выбор родительского класса не случаен. Дело в том, что в классе CNeuronMLMHAttentionOCL уже реализован функционал многослойного Self-Attention. В реализации нового класса мы воспользуемся существующими наработками. Только вместо последовательного вычисления слоев блока внимания, мы будем осуществлять прогнозирования различных вариантов развития событий. Кроме того, мы добавим функционал Cross-Attention, предусмотренный алгоритмом Multi-future Transformer.
Структура нового класса представлена ниже. Как можно заметить, помимо переопределения основных методов мы добавляем ещё одну коллекцию буферов данных для транспонирования данных, которая нам потребуется для реализации механизма Cross-Attention.
class CNeuronMFTOCL : public CNeuronMLMHAttentionOCL { protected: //--- CCollection cTranspose; //--- virtual bool feedForward(CNeuronBaseOCL *NeuronOCL); virtual bool Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols); virtual bool MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out); //--- virtual bool updateInputWeights(CNeuronBaseOCL *NeuronOCL); virtual bool MHCAInsideGradients(CBufferFloat *q, CBufferFloat *qg, CBufferFloat *kv, CBufferFloat *kvg, CBufferFloat *score, CBufferFloat *aog); public: CNeuronMFTOCL(void) {}; ~CNeuronMFTOCL(void) {}; virtual bool Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch); virtual bool calcInputGradients(CNeuronBaseOCL *prevLayer); //--- virtual int Type(void) const { return defNeuronMFTOCL; } //--- methods for working with files virtual bool Save(int const file_handle); virtual bool Load(int const file_handle); virtual CLayerDescription* GetLayerInfo(void); virtual bool WeightsUpdate(CNeuronBaseOCL *source, float tau); virtual void SetOpenCL(COpenCLMy *obj); };
Объявление новой коллекции буферов данных статичной позволяет нам оставить «пустыми» конструктор и деструктоор класса. А непосредственное создание всех внутренних объектов класса осуществляется в методе инициализации Init.
bool CNeuronMFTOCL::Init(uint numOutputs, uint myIndex, COpenCLMy *open_cl, uint window, uint window_key, uint heads, uint units_count, uint features, ENUM_OPTIMIZATION optimization_type, uint batch) { if(!CNeuronBaseOCL::Init(numOutputs, myIndex, open_cl, window * units_count * features, optimization_type, batch)) return false;
В параметрах метод получает всю необходимую информацию для воссоздания требуемой архитектуры. А в теле метода мы сразу вызываем аналогичный метод базового класса нейронных слоев CNeuronBaseOCL.
Обратите внимание, что мы вызываем метод инициализации не прямого родительского класса CNeuronMLMHAttentionOCL, а «через голову» обращаемся к базовому классу нейронных слоев CNeuronBaseOCL. Это связано с некоторыми различиями в реализации CNeuronMFTOCL и CNeuronMLMHAttentionOCL.
Если в родительском классе CNeuronMLMHAttentionOCL мы последовательно обрабатывали исходные данные в нескольких слоях блока внимания и на выходе получали результат с размерностью аналогичной исходным данным. То в новом слое CNeuronMFTOCL мы будем последовательно генерировать различные варианты возможного развития событий. Соответсвенно, результат работы слоя будет кратно (по количеству вариантов прогноза) превышать размер исходных данных. Следовательно нам нужно увеличить буфер результатов.
Кроме того, для исключения излишнего копирования данных, в родительском классе мы осуществляли подмену буферов результатов и градиентов самого слоя и последнего внутреннего слоя. В реализации же нового класса такой подход неприемлем, так как нам предстоит конкатенировать результаты нескольких параллельных блоков в единый буфер.
Но вернемся к нашему методу инициализации. После успешного выполнения метода инициализации базового класса нейронных слоев мы сохраним ключевые параметры архитектуры во внутренние переменные класса.
iWindow = fmax(window, 1); iWindowKey = fmax(window_key, 1); iUnits = fmax(units_count, 1); iHeads = fmax(heads, 1); iLayers = fmax(features, 1);
Здесь стоит обратить внимание, что все параметры мы сохраняем в переменные родительского класса. И здесь есть небольшое отклонение между названием переменной и её функционалом: в переменной iLayers будет храниться количество планируемых вариантов. С целью более эффективного использования ресурсов я решил не создавать дополнительной переменной и «закрыть глаза» на несоответствие наименования и функционала переменной.
Далее мы осуществим расчёт основных параметров наших блоков.
//--- MHSA uint num = 3 * iWindowKey * iHeads * iUnits; //Size of QKV tensor uint qkv_weights = 3 * (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of QKV tensor uint scores = iUnits * iUnits * iHeads; //Size of Score tensor uint mh_out = iWindowKey * iHeads * iUnits; //Size of multi-heads self-attention uint out = iWindow * iUnits; //Size of output tensor uint w0 = (iWindowKey + 1) * iHeads * iWindow; //Size W0 tensor
//--- MHCA uint num_q = iWindowKey * iHeads * iUnits; //Size of Q tensor uint num_kv = 2 * iWindowKey * iHeads * iUnits; //Size of KV tensor uint q_weights = (iWindow + 1) * iWindowKey * iHeads; //Size of weights' matrix of Q tensor uint kv_weights = 2 * (iUnits + 1) * iWindowKey * iHeads; //Size of weights' matrix of KV tensor uint scores_ca = iUnits * iWindow * iHeads; //Size of Score tensor
//--- FF uint ff_1 = 4 * (iWindow + 1) * iWindow; //Size of weights' matrix 1-st feed forward layer uint ff_2 = (4 * iWindow + 1) * iWindow; //Size of weights' matrix 2-nd feed forward layer
После завершения подготовительной работы мы организуем цикл, в котором будем последовательно создавать буферы данных для каждого варианта развития событий в нашем блоке параллельного взаимодействия.
for(uint i = 0; i < iLayers; i++) { CBufferFloat *temp = NULL; for(int d = 0; d < 2; d++) { //--- MHSA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
Здесь мы создадим вложенный цикл для создания буферов прямого и обратного прохода. В теле вложенного цикла сначала мы создадим буфер конкатенированных эмбедингов Query, Key и Value блока MHSA. И сразу добавим буфер матрицы коэффициентов Score.
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
Добавим буфер результатов много-голового внимания.
//--- Initialize multi-heads attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
И на выходе блока MHSA создадим буфер объединения результатов различных голов внимания.
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
Здесь следует обратить внимание, что для удовлетворения требований алгоритма MFT объединяются результаты голов внимания только в пределах одного варианта взаимодействия.
Далее мы создадим аналогичные буферы для блока Cross-Attention (MHCA). Только в данном случае мы отделим буфер эмбедингов Query от Key и Value, так как будут использоваться различные исходные данные.
//--- MHCA //--- Initilize QKV tensor temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_q, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!cTranspose.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(num_kv, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Tensors.Add(temp)) return false;
//--- Initialize scores temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(scores_ca, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!S_Tensors.Add(temp)) return false;
//--- Initialize multi-heads cross attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(mh_out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!AO_Tensors.Add(temp)) return false;
//--- Initialize attention out temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
После создания буферов для блоков внимания мы создадим буфера блока FeedForward.
//--- Initialize Feed Forward 1 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(4 * out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false;
//--- Initialize Feed Forward 2 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(out, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Tensors.Add(temp)) return false; }
Выше мы создали буферы результатов и градиентов ошибки отдельных блоков. Далее нам предстоит создать матрицы обучаемых весовых коэффициентов для этих блоков. Создавать мы их будем в той же последовательности. Сначала сгенерируем веса для эмбедингов Query, Key и Value блока MHSA.
//--- MHSA //--- Initilize QKV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(qkv_weights)) return false; float k = (float)(1 / sqrt(iWindow + 1)); for(uint w = 0; w < qkv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
И слоя объединения голов внимания.
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
Повторим операции для блока MHCA.
//--- MHCA //--- Initilize Q weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(q_weights)) return false; for(uint w = 0; w < q_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize KV weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(kv_weights)) return false; float kv = (float)(1 / sqrt(iUnits + 1)); for(uint w = 0; w < kv_weights; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* kv)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
//--- Initilize Weights0 temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(w0)) return false; for(uint w = 0; w < w0; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
И создадим матрицы блока FeedForward.
//--- Initilize FF Weights temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_1)) return false; for(uint w = 0; w < ff_1; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.Reserve(ff_2)) return false; k = (float)(1 / sqrt(4 * iWindow + 1)); for(uint w = 0; w < ff_2; w++) { if(!temp.Add((GenerateWeight() - 0.5f)* k)) return false; } if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
После чего мы организуем ещё один вложенный цикл, в котором создадим буферы моментов обновления матриц весовых коэффициентов. Обратите внимание, что количество буферов моментов зависит от выбранного алгоритма оптимизации.
for(int d = 0; d < (optimization == SGD ? 1 : 2); d++) { //--- MHSA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(qkv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- MHCA temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(q_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(kv_weights, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!QKV_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(w0, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
//--- FF Weights momentus temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_1, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false;
temp = new CBufferFloat(); if(CheckPointer(temp) == POINTER_INVALID) return false; if(!temp.BufferInit(ff_2, 0)) return false; if(!temp.BufferCreate(OpenCL)) return false; if(!FF_Weights.Add(temp)) return false; } } //--- return true; }
После успешной инициализации всех необходимых буферов данных мы завершаем работу метода с результатом true.
Как можно заметить, выше мы создали довольно большое количество буферов и в них легко запутаться. Поэтому мы создадим таблицу навигации по буферам данных.
| id | QKV_Tensors | S_Tensors, AO_Tensors | FF_Tensors | QKV_Weights | FF_Weights |
|---|---|---|---|---|---|
| 0 | Query, Key, Value MHSA | MHSA | MHSA Out | Query, Key, Value MHSA | MHSA W0 |
| 1 | Query MHCA | MHCA | MHCA Out | Query MHCA | MHCA W0 |
| 2 | Key, Value MHCA | Gradient MHSA | FF1 | Key, Value MHCA | FF1 |
| 3 | Gradient Query, Key, Value MHSA | Gradient MHCA | FF2 | Momentum1 Query, Key, Value MHSA | FF2 |
| 4 | Gradient Query MHCA | Gradient MHSA Out | Momentum1 Query MHCA | Momentum1 MHSA W0 | |
| 5 | Gradient Key, Value MHCA | Gradient MHCA Out | Momentum1 Key, Value MHCA | Momentum1 MHCA W0 | |
| 6 | Gradient FF1 | Momentum2 Query, Key, Value MHSA | Momentum1 FF1 | ||
| 7 | Gradient FF2 | Momentum2 Query MHCA | Momentum1 FF2 | ||
| 8 | Momentum2 Key, Value MHCA | Momentum2 MHSA W0 | |||
| 9 | Momentum2 MHCA W0 | ||||
| 10 | Momentum2 FF1 | ||||
| 11 | Momentum2 FF2 |
После инициализации класса CNeuronMFTOCL мы переходим к построению алгоритма прямого прохода. Надо сказать, что при реализации алгоритма MFT мы не создавали новые кернелы на стороне программы OpenCL. Однако, для вызова ранее созданных нам пришлось создать некоторые методы на стороне основной программы. В частности, для нашего класса CNeuronMFTOCL мы создали метод транспонирования матрицы. Алгоритм метода полностью дублирует метод прямого прохода слоя транспонирования. Но есть отличия в деталях. В параметрах новый метод получает указатели на 2 буфера данных (исходные данные и результаты), а так же размеры исходной матрицы.
bool CNeuronMFTOCL::Transpose(CBufferFloat *in, CBufferFloat *out, int rows, int cols) { if(!in || !out) return false; //--- uint global_work_offset[2] = {0, 0}; uint global_work_size[2] = {rows, cols}; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_in, in.GetIndex())) return false; if(!OpenCL.SetArgumentBuffer(def_k_Transpose, def_k_tr_matrix_out, out.GetIndex())) return false; if(!OpenCL.Execute(def_k_Transpose, 2, global_work_offset, global_work_size)) { string error; CLGetInfoString(OpenCL.GetContext(), CL_ERROR_DESCRIPTION, error); printf("%s %d Error of execution kernel Transpose: %d -> %s", __FUNCTION__, __LINE__, GetLastError(), error); return false; } //--- return true; }
Соответственно, в теле метода мы проверяем полученные указатели на буферы данных и в размерности пространства задач указываем значения из параметров. Сам же алгоритм вызова кернела остался без изменений.
Аналогичная ситуация с методом прямого прохода MHCA. В параметрах метода мы получаем указатели на буфера данных. Для сравнения метод CNeuronMH2AttentionOCL::attentionOut не имел параметров, а в своем функционале использовал внутренние объекты.
bool CNeuronMFTOCL::MHCA(CBufferFloat *q, CBufferFloat *kv, CBufferFloat *score, CBufferFloat *out) { if(!q || !kv || !score || !out) return false;
В теле метода мы создаем размерности пространства задач.
uint global_work_offset[3] = {0}; uint global_work_size[3] = {iUnits, iWindow, iHeads}; uint local_work_size[3] = {1, iWindow, 1};
Передаем параметры кернелу.
ResetLastError(); if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_q, q.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_kv, kv.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_score, score.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgumentBuffer(def_k_MH2AttentionOut, def_k_mh2ao_out, out.GetIndex())) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; } if(!OpenCL.SetArgument(def_k_MH2AttentionOut, def_k_mh2ao_dimension, (int)iWindowKey)) { printf("Error of set parameter kernel %s: %d; line %d", __FUNCTION__, GetLastError(), __LINE__); return false; }
И осуществляем его постановку в очередь.
if(!OpenCL.Execute(def_k_MH2AttentionOut, 3, global_work_offset, global_work_size, local_work_size)) { printf("Error of execution kernel %s: %d", __FUNCTION__, GetLastError()); return false; } //--- return true; }
Непосредственно алгоритм прямого прохода MFT реализован в методе CNeuronMFTOCL::feedForward. Как и аналогичные методы других нейронных слоев, в параметрах метод получает указатель на предществующий нейронный слой. И в теле метода мы сразу проверяем актуальность полученного указателя.
bool CNeuronMFTOCL::feedForward(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false;
Далее мы организуем цикл последовательного вычисления различных вариантов взаимодействия агентов.
for(uint i = 0; (i < iLayers && !IsStopped()); i++) { //--- MHSA //--- Calculate Queries, Keys, Values CBufferFloat *inputs = NeuronOCL.getOutput(); CBufferFloat *qkv = QKV_Tensors.At(i * 6); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), inputs, qkv, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Здесь мы сначала получаем сущности Query, Key и Value блока MHSA. После чего определим матрицу коэффициентов внимания.
//--- Score calculation CBufferFloat *temp = S_Tensors.At(i * 4); if(IsStopped() || !AttentionScore(qkv, temp, false)) return false;
И сгенерируем результат много-голового само-внимания.
//--- Multi-heads attention calculation CBufferFloat *out = AO_Tensors.At(i * 4); if(IsStopped() || !AttentionOut(qkv, temp, out)) return false;
Результат много-голового внимания уменьшим до размера исходных данных. Напомню, что объединение голов внимания осуществляется в рамках одного варианта взаимодействия агентов.
//--- Attention out calculation temp = FF_Tensors.At(i * 8); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Полученные тензор мы суммируем с исходными данными. Результаты операции нормализуем.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
Далее идет блок крос-внимания. Здесь мы сначала определяем сущность Query.
//--- MHCA inputs = temp; CBufferFloat *q = QKV_Tensors.At(i * 6 + 1); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 1), inputs, q, iWindow, iWindowKey * iHeads, None)) return false;
Затем мы транспонируем исходные данные и вычисляем сущности Key и Value.
CBufferFloat *tr = cTranspose.At(i * 2); if(IsStopped() || !Transpose(inputs, tr, iUnits, iWindow)) return false;
CBufferFloat *kv = QKV_Tensors.At(i * 6 + 2); if(IsStopped() || !ConvolutionForward(QKV_Weights.At(i * (optimization == SGD ? 6 : 9) + 2), tr, kv, iUnits, 2 * iWindowKey * iHeads, None)) return false;
И определим результаты много-голового кросс-внимания.
//--- Multi-heads cross attention calculation temp = S_Tensors.At(i * 4 + 1); out = AO_Tensors.At(i * 4 + 1); if(IsStopped() || !MHCA(q, kv, temp, out)) return false;
Полученные результаты сжимаем до размера исходных данных.
//--- Cross Attention out calculation temp = FF_Tensors.At(i * 8 + 1); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out, temp, iWindowKey * iHeads, iWindow, None)) return false;
Суммируем с результатами блока MHSA и нормализуем данные.
//--- Sum and normilize attention if(IsStopped() || !SumAndNormilize(temp, inputs, temp, iWindow)) return false;
После чего организуем передачу данных через блок FeedForward.
//--- Feed Forward inputs = temp; temp = FF_Tensors.At(i * 8 + 2); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), inputs, temp, iWindow, 4 * iWindow, LReLU)) return false; out = FF_Tensors.At(i * 8 + 3); if(IsStopped() || !ConvolutionForward(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), temp, out, 4 * iWindow, iWindow, activation)) return false;
Результаты работы блока FeedForward мы суммируем с результатами MHCA. Полученные данные нормализуются и записываются в буфер результатов со смещением, соответствующим анализируемому варианту взаимодействия.
//--- Sum and normilize out if(IsStopped() || !SumAndNormilize(out, inputs, Output, iWindow, true, 0, 0, i * inputs.Total())) return false; } //--- return true; }
Далее мы переходим к следующей итерации цикла анализа следующего варианта взаимодействия агентов на сцене.
После успешного анализа всех вариантов взаимодействия агентов мы завершаем работу метода с результатом true.
Если при прямом проходе осуществляется выполнения основного функционала анализа вариантов взаимодействия агентов на сцене и прогнозирования возможных вариантов развития событий, то обучение модели не возможно без реализации методов обратного прохода. Именно во время обратного прохода осуществляется оптимизация параметров модели для получения оптимальных результатов. Следовательно, после реализации методов прямого прохода мы переходим к построению алгоритма обратного прохода.
Как и в случае прямого прохода, для реализации обратного прохода нам потребуется создание дополнительного метода MHCAInsideGradients, алгоритм которго практически полностью дублирует алгоритм CNeuronMH2AttentionOCL::AttentionInsideGradients. Только MHCAInsideGradients работает не с внутренними объектами класса, а с буферами, полученными в параметрах метода. Выше уже приведены примеры подобных доработок. И мы не будем сейчас останавливаться на подробном рассмотрении метода. А с его кодом Вы можете ознакомиться во вложении.
Непосредственно же алгоритм обратного прохода реализован в методе calcInputGradients, который в параметрах получает указатель на объект предыдущего нейронного слоя.
bool CNeuronMFTOCL::calcInputGradients(CNeuronBaseOCL *prevLayer) { if(CheckPointer(prevLayer) == POINTER_INVALID) return false;
В теле метода мы сразу проверяем действительность полученного указателя. После чего мы сохраним в локальные переменные указатели на буферы, с которыми будут работать все блоки параллельного взаимодействия.
CBufferFloat *out_grad = Gradient; CBufferFloat *inp = prevLayer.getOutput(); CBufferFloat *grad = prevLayer.getGradient();
После проведения подготовительной работы мы организовываем цикл распределения градиентов ошибки через отдельные блоки параллельного взаимодействия.
for(int i = 0; (i < (int)iLayers && !IsStopped()); i++) { //--- Passing gradient through feed forward layers if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 3), Gradient, FF_Tensors.At(i * 8 + 2), FF_Tensors.At(i * 8 + 6), 4 * iWindow, iWindow, None, i * inp.Total())) return false;
Здесь мы сначала проводим градиент ошибки через блок FeedForward.
CBufferFloat *temp = FF_Tensors.At(i * 8 + 5); if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(i * 8 + 6), FF_Tensors.At(i * 8 + 1), temp, iWindow, 4 * iWindow, LReLU)) return false;
Напомню, что при прямом проходе результаты работы блока FeedForward мы складывали с выходом блока MHCA. Аналогично мы проводим градиент ошибки в обратном направлении. Только на это раз без нормализации.
//--- Sum gradient if(IsStopped() || !SumAndNormilize(Gradient, temp, temp, iWindow, false, i * inp.Total(), 0, 0)) return false; out_grad = temp;
Далее нам предстоит провести градиент ошибки через модуль кросс-внимания. Здесь сначала мы распределяем градиент ошибки по головам внимания.
//--- MHCA //--- Split gradient to multi-heads if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12) + 1), out_grad, AO_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3), iWindowKey * iHeads, iWindow, None)) return false;
Затем распределим градиент ошибки до соответствующих сущностей.
if(IsStopped() || !MHCAInsideGradients(QKV_Tensors.At(i * 6 + 1), QKV_Tensors.At(i * 6 + 4), QKV_Tensors.At(i * 6 + 2), QKV_Tensors.At(i * 6 + 5), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 3))) return false;
И теперь нам необходимо транспонировать градиент ошибки от Key и Value блока MHCA.
CBufferFloat *tr = cTranspose.At(i * 2 + 1); if(IsStopped() || !Transpose(QKV_Tensors.At(i * 6 + 5), tr, iWindow, iUnits)) return false;
Полученные результаты мы сначала суммируем между собой.
//--- Sum temp = FF_Tensors.At(i * 8 + 4); if(IsStopped() || !SumAndNormilize(QKV_Tensors.At(i * 6 + 4), tr, temp, iWindow, false)) return false;
А затем с градиентом ошибки на выходе блока MHCA.
if(IsStopped() || !SumAndNormilize(out_grad, temp, temp, iWindow, false)) return false;
После чего нам предстоит провести градиент ошибки через блок MHSA. Как и в случае кросс-внимания, мы сначала распределяем градиент ошибки по головам внимания.
//--- MHSA //--- Split gradient to multi-heads out_grad = temp; if(IsStopped() || !ConvolutionInputGradients(FF_Weights.At(i * (optimization == SGD ? 8 : 12)), out_grad, AO_Tensors.At(i * 4), AO_Tensors.At(i * 4 + 2), iWindowKey * iHeads, iWindow, None)) return false;
Спускаем градиент ошибки до соответствующих сущностей.
//--- Passing gradient to query, key and value if(IsStopped() || !AttentionInsideGradients(QKV_Tensors.At(i * 6), QKV_Tensors.At(i * 6 + 3), S_Tensors.At(i * 4), S_Tensors.At(i * 4 + 1), AO_Tensors.At(i * 4 + 1))) return false;
И доводим до уровня исходных данных.
if(IsStopped() || !ConvolutionInputGradients(QKV_Weights.At(i * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(i * 6 + 3), inp, tr, iWindow, 3 * iWindowKey * iHeads, None)) return false;
Теперь нам необходимо сложить градиент ошибки на входе и выходе блока MHSA, а результат записать в буфер градиентов предыдущего слоя. Но здесь есть один нюанс. В буфер градиентов предыдущего слоя нам необходимо записать сумму градиентов ошибки от всех блоков параллельного взаимодействия. Поэтому мы сначала проверяем идентификатор блока параллельного взаимодействия. Для первого блока мы просто записываем в буфер градиентов ошибки предыдущего слоя сумму градиентов от 2 потоков. А для остальных блоков параллельного взаимодействия мы прибавляем полученные градиенты ошибки к данным в буфере предыдущего слоя.
//--- Sum gradients if(i > 0) { if(IsStopped() || !SumAndNormilize(grad, tr, grad, iWindow, false)) return false; if(IsStopped() || !SumAndNormilize(out_grad, grad, grad, iWindow, false)) return false; } else if(IsStopped() || !SumAndNormilize(out_grad, tr, grad, iWindow, false)) return false; } //--- return true; }
И далее мы переходи к следующей итерации цикла для проведения градиента ошибки через следующий блок параллельного взаимодействия.
После успешного выполнения всех итераций цикла мы завершаем работу метода с результатом true.
Выше мы организовали процесс прямого прохода и обратного распределения градиента ошибки в классе CNeuronMFTOCL. И для полной реализации основного функционала класса нам остается добавить метод обновления обучаемых параметров updateInputWeights. Алгоритм данного метода довольно прост. Мы лишь в цикле вызываем метод родительского класса ConvolutuionUpdateWeights, в котором осуществляется обновления параметров отдельного буфера. А необходимые для работы буфера данных передаются в параметрах метода.
bool CNeuronMFTOCL::updateInputWeights(CNeuronBaseOCL *NeuronOCL) { if(CheckPointer(NeuronOCL) == POINTER_INVALID) return false; CBufferFloat *inputs = NeuronOCL.getOutput(); for(uint l = 0; l < iLayers; l++) { if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9)), QKV_Tensors.At(l * 6 + 3), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 3) : QKV_Weights.At(l * 9 + 3)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 6)), iWindow, 3 * iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 1), QKV_Tensors.At(l * 6 + 4), inputs, (optimization == SGD ? QKV_Weights.At(l * 6 + 4) : QKV_Weights.At(l * 9 + 4)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 7)), iWindow, iWindowKey * iHeads)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(QKV_Weights.At(l * (optimization == SGD ? 6 : 9) + 2), QKV_Tensors.At(l * 6 + 5), cTranspose.At(l * 2), (optimization == SGD ? QKV_Weights.At(l * 6 + 5) : QKV_Weights.At(l * 9 + 5)), (optimization == SGD ? NULL : QKV_Weights.At(l * 9 + 8)), iUnits, 2 * iWindowKey * iHeads)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12)), FF_Tensors.At(l * 8 + 4), AO_Tensors.At(l * 4), (optimization == SGD ? FF_Weights.At(l * 8 + 4) : FF_Weights.At(l * 12 + 4)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 8)), iWindowKey * iHeads, iWindow)) return false; if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 1), FF_Tensors.At(l * 8 + 5), AO_Tensors.At(l * 4 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 5) : FF_Weights.At(l * 12 + 5)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 9)), iWindowKey * iHeads, iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 2), FF_Tensors.At(l * 8 + 6), FF_Tensors.At(l * 8 + 1), (optimization == SGD ? FF_Weights.At(l * 8 + 6) : FF_Weights.At(l * 12 + 6)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 10)), iWindow, 4 * iWindow)) return false; //--- if(IsStopped() || !ConvolutuionUpdateWeights(FF_Weights.At(l * (optimization == SGD ? 8 : 12) + 3), FF_Tensors.At(l * 8 + 7), FF_Tensors.At(l * 8 + 2), (optimization == SGD ? FF_Weights.At(l * 8 + 7) : FF_Weights.At(l * 12 + 7)), (optimization == SGD ? NULL : FF_Weights.At(l * 12 + 11)), 4 * iWindow, iWindow)) return false; } //--- return true; }
На этом мы завершаем рассмотрение методов реализации основного функционала алгоритма Multi-future Transformer в классе CNeuronMFTOCL. С реализацией вспомогательных методов Вы можете самостоятельно ознакомиться во вложении. Там же Вы найдете полный код всех программ, используемых при подготовке данной статьи. А мы переходим к реализации советников построения и обучения моделей.
2.2 Архитектура моделей
Выше мы построили класс реализации блока параллельного взаимодействия, архитектура которого была предложена авторами метода Multi-future Transformer. Однако, это всего лишь один слой нашей модели. И сейчас нам предстоит описать полную архитектуру создаваемых моделей. На вход которых мы будем подавать «сырые» исходные данные. А в результате работы моделей мы бы хотели получить вектор оптимальных действий Агента, совершение которых способно принести прибыль при работе на финансовых рынках.
Должен сказать, что при построении своей модели я немного отошел от архитектуры, предложенной авторами метода. И тому есть несколько причин.
Во-первых, метод Multi-future Transformer был предложен для прогнозирования взаимодействия автономных транспортных средств с окружающей средой. Мы же планируем использовать свою модель для финансовых рынков. В обоих задачах есть своя специфика, которая накладывает отпечаток на построение моделей.
Во-вторых, в предыдущей статье мы уделили немало внимания оптимизации производительности моделей. И я бы хотел воспользоваться полученным опытом. Поэтому в качестве «донора» я воспользовался архитектурой моделей из предыдущей статьи. При этом мы внесли изменения в модели планирования траекторий.
Как Вы знаете, архитектура моделей прогнозирования будущих траекторий описана в методе CreateTrajNetDescriptions файла «...\Experts\MFT\Trajectory.mqh». В параметрах метод получаает указатели на динамические массивы для создания 3 моделей:
- Энкодер состояния;
- Декодер конечных точек;
- Вероятностей сцены.
В предыдущих статьях мы решили не прогнозировать полную траекторию движения цены, а сконцентрировались на прогнозировании основных экстремумов ценового движения:
- Close
- High
- Low.
Поэтому в своей работе мы рассматриваем состояние динамики ценового движения как варианты сцены. И не анализируем вероятности конечных траекторий отдельных агентов.
bool CreateTrajNetDescriptions(CArrayObj *encoder, CArrayObj *endpoints, CArrayObj *probability) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!endpoints) { endpoints = new CArrayObj(); if(!endpoints) return false; } if(!probability) { probability = new CArrayObj(); if(!probability) return false; }
В теле метода мы проверяем актуальность полученных в параметрах указателей на объекты и, при необходимости, создаем новые.
Первым мы описали архитектуру Энкодера, на вход которого мы подаем сырые исходные данные описания текущего состояния окружающей среды.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; int prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Как обычно, полученные данные проходят первичную обработку в слое пакетной нормализации.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
После чего мы создаем эмбединг текущего состояния и сохраняем его в во внутреннем стеке модели.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronEmbeddingOCL; { int temp[] = {prev_count}; ArrayCopy(descr.windows, temp); } prev_count = descr.count = GPTBars; int prev_wout = descr.window_out = EmbeddingSize; if(!encoder.Add(descr)) { delete descr; return false; }
Каждый элемент эмбединга для нас ассоциируется с отдельным агентом на сцене окружающей среды. В соответствии с методом MFT мы осуществим позиционное кодирование исходных данных.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronPEOCL; descr.count = prev_count; descr.window = prev_wout; if(!encoder.Add(descr)) { delete descr; return false; }
Далее в архитектуре авторов метода MFT следует стек блоков MHSA. Здесь мое первое отступление от предложенной архитектуры. Я решил воспользоваться наработками прошлой статьи и оставил 2 слоя Crystal-GCN, разделенных слоем пакетной нормализации.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = prev_count * prev_wout; descr.batch = MathMax(1000, GPTBars); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCGConvOCL; descr.count = prev_count * prev_wout; descr.window = descr.count; if(!encoder.Add(descr)) { delete descr; return false; }
За которым расположился один слой MHSA.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMLMHAttentionOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = 1; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее авторы метода предлагают усреднить показатели динамики каждого агента. При этом в блоке параллельного взаимодействия осуществляется кросс-анализ данных с контекстными данными карты. В нашем же случае нет карты возможного предстоящего движения цены. Вместо этого мы будем использовать контекстный анализ пройденных траекторий анализируемых признаков.
И следующем в нашей архитектуре идет созданный выше блок параллельных вычислений. В данном блоке мы используем блоки Self-Attention и Cross-Attention с 4 головами внимания. Авторы метода в своей работе использовали только 1 голову внимания в блоках параллельного взаимодействия. Количество вариантов взаимодействия агентов определяется константой NForecast.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronMFTOCL; descr.count = prev_count; descr.window = prev_wout; descr.step = 4; descr.window_out = 16; descr.layers = NForecast; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Далее следует отметить один архитектурный момент. В своей реализации мы построили класс CNeuronMFTOCL таким образом, что результат его работы можно представить в виде 3-мерного тензора {количество элементов последовательности, вариант взаимодействия, количество агентов}. Подобный формат данных не совсем удобен нам для последующей обработки, так как далее нам необходимо работать с каждым отдельным вариантом взаимодействия. А расположение варианта взаимодействия внутри измерений тензора усложняет эту работу. Поэтому далее мы транспонируем данные, чтобы вынести вариант взаимодействия агентов в первое измерение тензора.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; descr.window = prev_wout * NForecast; if(!encoder.Add(descr)) { delete descr; return false; }
Таким образом, на выходе Энкодера мы получили тензор {вариант взаимодействия агентов, количество агентов, длина вектора описания динамики агента}.
После Энкодера мы создаем модель Декодирования конечных точек. На вход модели мы будем подавать тензор результатов Энкодера.
//--- Endpoints endpoints.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = (prev_count * prev_wout) * NForecast; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Напомню, что методом MTF предусматривается использование декодера с одними параметрами для всех вариантов взаимодействия агентов. Подобный подход мы можем реализовать с использование сверточного слоя с размером окна и шага равным тензору одного варианта взаимодействия агентов. Данный этап мы разделим на 2 этапа. Сначала мы свернем динамику каждого отдельного агента.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast * prev_wout; descr.window = prev_count; descr.step = descr.window; descr.window_out = LatentCount; descr.activation = SIGMOID; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
А затем получим варианты сцены для каждого анализируемого варианта взаимодействия.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NForecast; descr.window = LatentCount * prev_wout; descr.step = descr.window; descr.window_out = 3; descr.activation = None; descr.optimization = ADAM; if(!endpoints.Add(descr)) { delete descr; return false; }
Модель оценки вероятностей отдельных прогнозируемых сцен осталась практически без изменений. Как и в случае Декодера, на вход модели подаются результаты работы Энкодера.
//--- Probability probability.Clear(); //--- Input layer if(!probability.Add(endpoints.At(0))) return false;
Которые объединяются с прогнозными вариантами сцены.
//--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatenate; descr.count = LatentCount; descr.window = prev_count * prev_wout * NForecast; descr.step = 3 * NForecast; descr.optimization = ADAM; descr.activation = SIGMOID; if(!probability.Add(descr)) { delete descr; return false; }
Данные анализируются 2 полносвязными слоями.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = LReLU; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = NForecast; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; }
И нормализуются функцией SoftMax.
//--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronSoftMaxOCL; descr.count = NForecast; descr.step = 1; descr.activation = None; descr.optimization = ADAM; if(!probability.Add(descr)) { delete descr; return false; } //--- return true; }
Архитектура моделей Актера были перенесены практически без изменений. Были сделаны лишь точечные правки в части обработки результатов Энкодера текущего состояния.
Так же следует сказать, что изменения, внесенные архитектуру модели, практически не оказали влияние на алгоритмы взаимодействия с окружающей средой и обучения моделей. Поэтому все советник были перенесены из предыдущей статьи с минимальными правками. И, позвольте, не останавливаться на описании их алгоритмов в рамках данной статьи. А с полным кодом всех программ, используемых в статье, Вы можете ознакомиться во вложении.
3.Тестирование
Выше мы реализовали алгоритм Multi-future Transformer средствами MQL5 и описали архитектуру моделей, которые позволяют нам использовать предложенные подходы для обучения моделей прогнозирования нескольких вариантов предстоящего ценового движения с оценкой вероятности их осуществления. И теперь пришло время проверить результаты нашей работы на реальных данных в тестере стратегий MetaTrader 5.
Как всегда, модель обучается и тестируется на исторических данных инструмента EURUSD тайм-фрейм H1. Обучение моделей осуществлялось на исторических данных за 7 месяцев 2023 года. А тестирование обученной модели произведено на данных Августа 2023 года.
Сразу хочу отметить, что для обучения модели использовалась обучающая выборка и советник обучения из предыдущей статьи. Таким образом, можно отметить, что изменение полученных результатов главным образом обусловлено изменением архитектуры модели. Конечно, мы не можем исключать и фактор случайности, который выражается в начальной инициализации модели случайными параметрами. И таким же случайным семплированием данных из буфера воспроизведения опыта в процессе обучения. Но влияние данного фактора минимизируется с ростом эпох обучения.
Напомню, в предыдущей статье модель показала довольно стабильный результат, но очень малое количество сделок. В новой модели мы видим увеличение количества сделок при сохранении положительного результата.
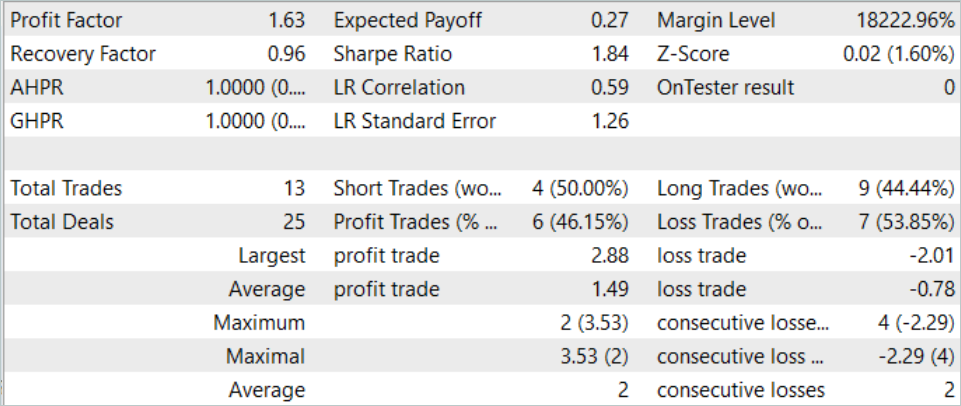
За Август 2023 года модель совершила 13 сделок, 6 из которых было закрыто с прибылью. В результате работы модели за тестовый период достигнут профит-фактор 1.63
Заключение
В данной статье мы познакомились с ещё одним методов прогнозирования предстоящего ценового движения Multi-future Transformer. Одной из ключевых особенностей данного метода является построение мультимодальных прогнозов движения агентов с акцентом на их взаимодействие между собой и со сценой окружающей среды. Что позволяет делать более точные прогнозы предстоящего движения.
В практической части мы реализовали предложенные подходы средствами MQL5. Обучили и протестировали модель на реальных данных в тестере стратегий MetaTrader 5. Полученные результаты подтверждают эффективность предложенных подходов. Можно отметить разнообразность полученных прогнозов, которая достигается благодаря изолированности прогнозов отдельных модальностей при сохранении анализа взаимодействия агентов.
Ссылки
Программы, используемые в статье
| # | Имя | Тип | Описание |
|---|---|---|---|
| 1 | Research.mq5 | Советник | Советник сбора примеров |
| 2 | ResearchRealORL.mq5 | Советник | Советник сбора примеров методом Real-ORL |
| 3 | Study.mq5 | Советник | Советник обучения Моделей |
| 4 | Test.mq5 | Советник | Советник для тестирования модели |
| 5 | Trajectory.mqh | Библиотека класса | Структура описания состояния системы |
| 6 | NeuroNet.mqh | Библиотека класса | Библиотека классов для создания нейронной сети |
| 7 | NeuroNet.cl | Библиотека | Библиотека кода программы OpenCL |
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.

- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования