
Возможности Мастера MQL5, которые вам нужно знать (Часть 07): Дендрограммы
Введение
В этой статье, которая является частью серии об использовании Мастера MQL5, рассматриваются дендрограммы. Мы уже рассмотрели несколько идей, связанных с Мастером MQL5, которые могут быть полезны трейдерам, например: Линейный дискриминантный анализ, цепи Маркова, преобразование Фурье и некоторые другие. В этой статье рассмотрены способы использования обширного кода ALGLIB, переведенного MetaQuotes, вместе с использованием встроенного Мастера MQL5 для эффективного тестирования и разработки новых идей.
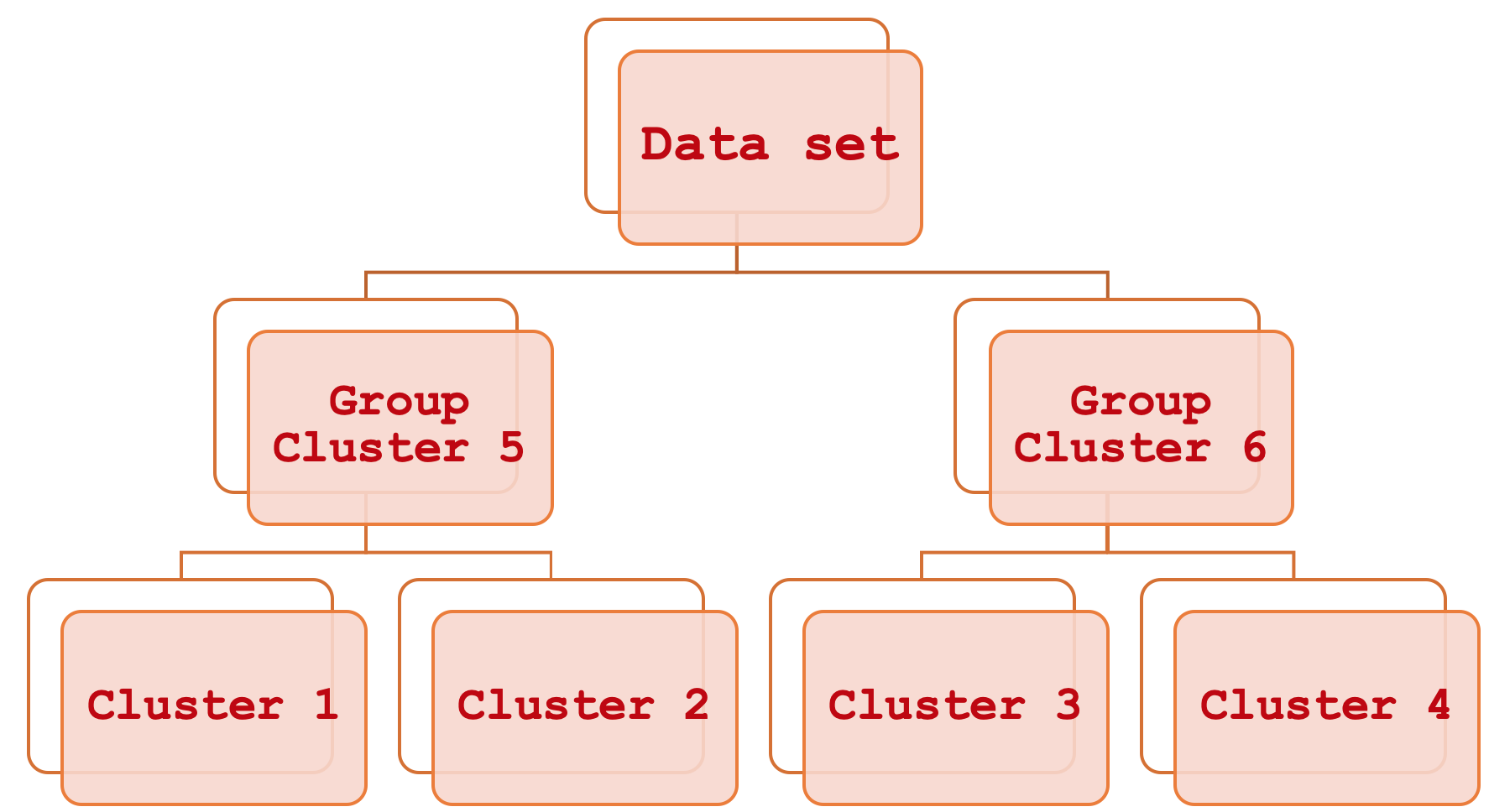
Агломеративная иерархическая классификация звучит очень сложно, но на самом деле всё достаточно просто. Говоря коротко, это способ связать различные части набора данных, сначала рассматривая основные отдельные кластеры, а затем систематически группируя их шаг за шагом, пока весь набор данных не станет рассматриваться как единая отсортированная единица. Результатом этого процесса является иерархическая диаграмма, которую чаще называют дендрограммой.
В статье основное внимание будет уделено тому, как эти составляющие кластеры можно использовать для оценки и, таким образом, прогнозирования диапазона ценовых баров, но в отличие от прошлых частей, когда мы делали это для помощи в настройке трейлинг-стопа, здесь мы будем использовать полученные знания для управления капиталом и определения размера позиции. Статья рассчитана на тех, кто только знакомится с платформой MetaTrader и языком программирования MQL5, поэтому опытным пользователям некоторые темы могут показаться неинтересными.
Важность точных прогнозов ценового диапазона во многом субъективна. Их значение во многом зависит от стратегии трейдера и общего подхода к торговле. Когда точность прогнозов не будет иметь большого значения? Например, если в ваших торговых настройках вы сначала используете минимальное кредитное плечо или вообще его не используете, у вас есть определенный стоп-лосс, и вы склонны удерживать позиции в течение длительных периодов, которые могут длиться, скажем, месяцами, и у вас есть фиксированный размер маржинальной позиции (или даже фиксированный лот). В этом случае волатильность ценового бара можно отложить на второй план, пока вы сосредоточитесь на проверке сигналов входа и выхода. Если же вы внутридневной трейдер, используете большое кредитное плечо или не оставляете открытых торговых позиции на выходные, или у вас среднее/короткое время удержания позиций на рынке, тогда диапазон ценовых баров – это, безусловно, то, на что вам следует обратить внимание. Мы рассмотрим использование диапазона в управлении капиталом, создав собственный экземпляр класса ExpertMoney, но его применение может выйти за рамки управления капиталом и даже включать в себя риск, если учесть, что способность понимать и разумно прогнозировать диапазон ценового бара может помочь решить, когда увеличивать открытые позиции и, наоборот, когда их уменьшать.
Волатильность
Диапазоны ценовых баров (именно так мы определяем волатильность в этой статье) в контексте торговли — это разница между максимумом и минимумом цены торгуемого символа в течение установленного периода времени. Если мы возьмем, скажем, дневной период времени, и в течение дня цена торгуемого символа поднимется до уровня H, но не выше H, и упадет до уровня L и снова не ниже L, тогда наш диапазон для целей этой статьи вычисляется так:
H – L;
Волатильность важна из-за явления, часто называемого кластеризацией волатильности (volatility clustering). Это явление, когда периоды высокой волатильности обычно сменяются большей волатильностью, и, наоборот, периоды низкой волатильности также сопровождаются более низкой волатильностью. Значимость этого субъективна, как указано выше, однако для большинства трейдеров (включая, по моему мнению, всех новичков) знание того, как торговать с использованием кредитного плеча, может быть плюсом в долгосрочной перспективе, поскольку высокая волатильность может привести к стоп-ауту не потому, что сигнал на вход был неправильным, а потому, что была слишком большая волатильность. Даже если у вас есть приличный стоп-лосс, бывают случаи, когда его цена может быть недоступна. Тут можно вспомнить историю с швейцарским франком в январе 2015 года. В этом случае ваша позиция будет закрыта брокером по следующей лучшей доступной цене, которая часто хуже вашего стоп-лосса. Только лимитные ордера гарантируют цену, стоп-ордера и стоп-лосс такой гарантии не дают.
Таким образом, диапазоны ценовых баров не только дают общее представление о рыночной среде, но и могут помочь определить уровни цен входа и даже выхода. Опять же, в зависимости от вашей стратегии, если, например, вы держите длинную позицию по какому-то символу, то степень прогнозируемого диапазона ценового бара (то, что вы прогнозируете) может легко определить или, по крайней мере, указать, где разместить уровень входа и даже тейк-профит.
Здесь я рискую показаться скучным, но, возможно, было бы полезно выделить основные типы ценовых свечей, а также показать их соответствующие диапазоны. Наиболее известные свечные паттерны - медвежье удержание, бычье удержание, молот, надгробие, длинноногоий дожи и стрекоза. Конечно, паттернов на самом деле больше, но упомянутые охватывают большинство ситуаций, с которыми вы столкнетесь на ценовом графике. Во всех этих случаях, как будет показано ниже, диапазон ценового бара представляет собой просто максимальную цену за вычетом минимальной цены.
Агломеративная иерархическая классификация
Агломеративная иерархическая классификация (Agglomerative Hierarchical Classification, AHC) — это метод классификации данных в заданное количество кластеров, а затем связывание этих кластеров систематическим иерархическим образом посредством так называемой дендрограммы. Преимущества метода в основном связаны с тем фактом, что классифицируемые данные часто являются многомерными, и поэтому необходимость учитывать множество переменных в одной точке данных — это то, с чем может быть непросто справиться при проведении сравнений. Например, компания, желающая оценить своих клиентов на основе полученной от них информации, может использовать этот метод, поскольку информация обязательно будет охватывать различные аспекты жизни клиентов, такие как прошлые покупки, возраст, пол, адрес и т. д. AHC, количественно оценивая все эти переменные для каждого клиента, создает кластеры из очевидных центроидов каждой точки данных. Более того, эти кластеры группируются в иерархию для систематических отношений, поэтому, если классификация требует, скажем, 5 кластеров, то AHC предоставит в отсортированном формате эти 5 кластеров, что означает, что вы можете сделать вывод, какие кластеры более похожи, а какие более различны. Это сравнение кластеров, хотя и вторичное, может пригодиться, если вам нужно сравнить более одной точки данных, и оказывается, что они находятся в отдельных кластерах. Ранжирование кластеров будет определять, насколько далеко друг от друга различаются две точки, используя величину разделения между их соответствующими кластерами.
Классификация AHC является обучением без учителя. Это означает, что ее можно использовать при прогнозировании по различным классификаторам. В нашем случае мы прогнозируем диапазоны ценовых баров. Другой пользователь с такими же обученными кластерами может использовать их для прогнозирования изменений цен закрытия или другого аспекта, имеющего отношение к его торговле. Это обеспечивает большую гибкость, чем при обучении с учителем на конкретном классификаторе, потому что в этом случае модель будет использоваться только для прогнозирования того аспекта, по которому она была классифицирована. Это означает, что прогнозирование для другой цели потребует переобучения модели с новым набором данных.
Инструменты и библиотеки
Платформа MQL5 с помощью своей IDE позволяет разрабатывать собственные советники с нуля. Гипотетически мы могли бы пойти по этому пути. Однако этот вариант потребует принятия множества решений относительно торговой системы, которые могут варьироваться у разных трейдеров при реализации одной и той же концепции. Кроме того, код такой реализации может быть слишком перенастроен и подвержен ошибкам и его очень сложно модифицировать для различных ситуаций. Поэтому наиболее оптимальный путь - это интеграция нашей идеи в состав других "стандартных" классов советников, предоставляемых Мастером MQL5. Нам не только придется меньше заниматься отладкой (даже во встроенных классах MQL5 иногда встречаются ошибки, но их немного), но, сохранив его как экземпляр одного из стандартных классов, класс можно использовать и комбинировать с широким спектром других классов в Мастере MQL5 для создания различных советников, что обеспечивает полноту эксперимента.
Код библиотеки MQL5 содержит классы AlgLib, которые упоминались в предыдущих статьях этой серии и будут снова использованы в этой статье. В частности, в файле DATAANALYSIS.MQH мы будем использовать класс CClustering и пару других связанных классов при создании классификации AHC для наших данных ценовых рядов. Поскольку нас в первую очередь интересует диапазон ценовых баров, из этого следует, что наши обучающие данные будут состоять из таких диапазонов из предыдущих периодов. При использовании классов обучения данных из включаемого файла анализа данных обычно эти данные помещаются в матрицу XY, где X обозначает независимые переменные, а Y представляет классификаторы или "метки", которым обучается модель. Оба обычно представлены в одной матрице.
Подготовка данных для обучения
Однако в этой статье, поскольку мы проводим обучение без учителя, наши входные данные состоят только из независимых переменных X. Это будут исторические диапазоны ценовых баров. В то же время мы хотели бы делать прогнозы, рассматривая другой поток связанных данных, а именно конечный диапазон ценовых баров. Это эквивалент Y. Чтобы объединить эти два набора данных, сохраняя при этом гибкость обучения без учителя, мы можем использовать следующую структуру данных:
//+------------------------------------------------------------------+ //| | //+------------------------------------------------------------------+ class CMoneyAHC : public CExpertMoney { protected: double m_decrease_factor; int m_clusters; // clusters int m_training_points; // training points int m_point_featues; // point featues ... public: CMoneyAHC(void); ~CMoneyAHC(void); virtual bool ValidationSettings(void); //--- virtual double CheckOpenLong(double price,double sl); virtual double CheckOpenShort(double price,double sl); //--- void DecreaseFactor(double decrease_factor) { m_decrease_factor=decrease_factor; } void Clusters(int value) { m_clusters=value; } void TrainingPoints(int value) { m_training_points=value; } void PointFeatures(int value) { m_point_featues=value; } protected: double Optimize(double lots); double GetOutput(); CClusterizerState m_state; CAHCReport m_report; struct Sdata { CMatrixDouble x; CRowDouble y; Sdata(){}; ~Sdata(){}; }; Sdata m_data; CClustering m_clustering; CRowInt m_clustering_index; CRowInt m_clustering_z; };
Таким образом, исторические диапазоны ценовых баров будут собираться как новая партия на каждом новом баре. Советники, созданные мастером MQL5, склонны принимать торговые решения на каждом новом баре, и для наших целей тестирования этого достаточно. Действительно, существуют альтернативные подходы, такие как получение большой партии, охватывающей многие месяцы или даже годы, а затем на основе тестирования изучение того, насколько хорошо кластеры модели могут отделять возможные ценовые бары с низкой волатильностью от баров с высокой волатильностью. Также имейте в виду, что мы используем только 3 кластера, из которых один крайний кластер предназначен для очень волатильных баров, один для очень низкой волатильности и один для средней волатильности. Опять же, можно исследовать, например, 5 кластеров, но принцип для наших целей будет тот же. Расположим кластеры в порядке от наибольшей возможной волатильности до наименьшей и определим, в каком кластере находится наша текущая точка данных.
Заполнение данными
Код для получения последних диапазонов баров на каждом новом баре и заполнение пользовательской структуры выглядят следующим образом:
m_data.x.Resize(m_training_points,m_point_featues); m_data.y.Resize(m_training_points-1); m_high.Refresh(-1); m_low.Refresh(-1); for(int i=0;i<m_training_points;i++) { for(int ii=0;ii<m_point_featues;ii++) { m_data.x.Set(i,ii,m_high.GetData(StartIndex()+ii+i)-m_low.GetData(StartIndex()+ii+i)); } }
Количество обучающих точек определяет, насколько велик наш набор обучающих данных. Это настраиваемый входной параметр точки данных. Однако этот параметр определяет количество "измерений", которые есть у каждой точки данных. Итак, в нашем случае по умолчанию у нас есть 4 измерения, но это просто означает, что мы используем последние 4 диапазона ценовых баров для определения любой заданной точки данных. Это похоже на вектор.
Создание кластеров
Итак, как только у нас появятся данные в нашей пользовательской структуре, следующим шагом будет их моделирование с помощью генератора моделей AHC Alglib. В листинге кода эта модель называется "состоянием", поэтому наша модель называется m_state. Это двухэтапный процесс. Сначала нам нужно сгенерировать точки модели на основе предоставленных данных обучения, а затем запустить генератор AHC. Установку точек можно рассматривать как инициализацию модели и обеспечение четкого определения всех ключевых параметров. В нашем коде вызов происходит следующим образом:
m_clustering.ClusterizerSetPoints(m_state, m_data.x, m_training_points, m_point_featues, 20);
Вторым важным шагом является запуск модели для определения кластеров каждой из предоставленных точек данных в наборе обучающих данных. Это делается путем вызова функции ClusterizerRunAHC, как указано ниже:
m_clustering.ClusterizerRunAHC(m_state, m_report);
С точки зрения Alglib, это основа создания кластеров, которые нам нужны. Эта функция выполняет краткую предварительную обработку, а затем вызывает защищенную (приватную) функцию ClusterizerRunAHCInternal, которая выполняет всю тяжелую работу. Всё необходимое можно найти в файле include\math\AlgLib\dataanalysis.mqh, начиная со строки 22463. Особого внимания заслуживает генерация дендрограммы в выходном массиве cidx. Этот массив умело объединяет большое количество информации о кластерах в один массив. Незадолго до этого необходимо будет создать матрицу расстояний для всех точек обучающих данных, используя их центроиды. Сопоставление значений матрицы расстояний с индексами кластера фиксируется этим массивом, причем первые значения до общего количества обучающих точек представляют собой кластер каждой точки, а последующие индексы представляют собой слияние этих кластеров для формирования дендрограммы.
Не менее примечательным является тип расстояния, используемый при создании матрицы расстояний. Доступны девять вариантов: от расстояния Чебышева, евклидова расстояния и до ранговой корреляции Спирмена. Каждой из этих альтернатив присваивается индекс, который мы устанавливаем, когда вызываем упомянутую выше функцию заданных значений. Выбор типа расстояния должен быть очень чувствителен к природе и типу создаваемых кластеров, поэтому на это следует обратить внимание. Использование евклидова расстояния (индекс которого равен 2) обеспечивает большую гибкость реализации при настройке алгоритма AHC, поскольку в отличие от других типов расстояний здесь можно использовать метод Уорда.
Получение кластеров
Извлечение кластеров так же просто, как и их создание. Мы просто вызываем одну функцию ClusterizerGetKClusters, и она извлекает два массива из выходного отчета функции генерации кластера, которую мы вызывали ранее (запускаем AHC). Массивы представляют собой массив индексов кластеров и массивы z-кластеров, и они определяют не только то, как определяются кластеры, но и то, как из них можно сформировать дендрограмму. Вызов этой функции выполняется просто, как указано ниже:
m_clustering.ClusterizerGetKClusters(m_report, m_clusters, m_clustering_index, m_clustering_z);
Структура полученных кластеров очень проста, поскольку в нашем случае мы классифицировали наш набор обучающих данных только на 3 кластера. Это означает, что у нас есть не более трех уровней слияния внутри дендрограммы. Если бы мы использовали больше кластеров, наша дендрограмма, безусловно, была бы более сложной и потенциально имела бы уровни слияния n-1, где n — количество кластеров, используемых моделью.
Разметка точек данных
Затем следует разметка точек обучающих данных для помощи в прогнозировании. Нас не интересует простая классификация наборов данных, но мы хотим использовать их, и поэтому нашими "метками" будет конечный диапазон цен после каждой точки обучающих данных. Мы извлекаем новый набор данных для каждого нового бара, который будет включать текущую точку данных, для которой ее конечная волатильность неизвестна. Вот почему при разметке мы пропускаем точку данных с индексом 0, как показано в нашем коде ниже:
for(int i=0;i<m_training_points;i++) { if(i>0)//assign classifier only for data points for which eventual bar range is known { m_data.y.Set(i-1,m_high.GetData(StartIndex()+i-1)-m_low.GetData(StartIndex()+i-1)); } }
Конечно, можно использовать и другие варианты разметки. Например, вместо того, чтобы сосредотачиваться на диапазоне цен только следующего бара, мы могли бы рассмотреть диапазон, скажем, следующих 5 или 10 баров, используя общий диапазон этих баров в качестве значения y. Этот подход может привести к более "точным" и менее ошибочным значениям, и фактически тот же прогноз можно использовать, если наши метки предназначены для направления цены (изменения цены закрытия), в результате чего мы попытаемся спрогнозировать не один, а гораздо больше баров. В любом случае, поскольку мы пропустили первый индекс, поскольку у нас не было его конечного значения, мы пропустили бы n баров (где n — это ближайшие бары, которые мы хотим проецировать). Этот долгосрочный подход приведет к значительной задержке из-за увеличения n. С другой стороны большие задержки позволят безопасно сравнивать с прогнозным значением, поскольку задержка составляет всего один бар от целевого значения y.
Прогнозирование волатильности
Закончив "разметку" обученного набора данных, мы можем приступить к определению того, к какому кластеру принадлежит наша текущая точка данных среди кластеров, определенных в модели. Это делается путем простого перебора выходных массивов отчета о моделировании и сравнения индекса кластера текущей точки данных с индексами других точек обучающих данных. Если они совпадают, то они принадлежат одному кластеру. Ниже приведен относительно простой код:
if(m_report.m_terminationtype==1) { int _clusters_by_index[]; if(m_clustering_index.ToArray(_clusters_by_index)) { int _output_count=0; for(int i=1;i<m_training_points;i++) { //get mean target bar range of matching cluster if(_clusters_by_index[0]==_clusters_by_index[i]) { _output+=(m_data.y[i-1]); _output_count++; } } // if(_output_count>0){ _output/=_output_count; } } }
Как только совпадение найдено, мы одновременно приступаем к вычислению среднего значения Y всех точек обучающих данных в этом кластере. Получение среднего значения можно считать довольно грубым методом, но его можно использовать. Другие возможные методы включают поиск медианы или модуль. Независимо от того, какой вариант выбран, применяется тот же принцип получения значения Y нашей текущей точки только из других точек данных в ее кластере.
Использование дендрограмм
Приведенный исходный код демонстрирует, как созданные индивидиуальные кластеры можно использовать для классификации и составления прогнозов. Какова же тогда роль дендрограммы? Почему важно количественно определять, насколько каждый кластер отличается от других? Чтобы ответить на этот вопрос, мы могли бы рассмотреть возможность сравнения двух точек данных обучения, а не классификации только одной, как мы это сделали. В плане волатильности в этом сценарии мы могли бы получить данные из истории в ключевой точке перегиба (это может быть ключевой фрактал в колебаниях цен, если вы прогнозируете направление цен, но в этой статье мы рассматриваем волатильность). Поскольку у нас будут кластеры обеих точек, расстояние между ними скажет нам, насколько близка наша текущая точка данных к прошлой точке перегиба.
Примеры
Несколько тестов было проведено с помощью советника, собранного Мастером с настроенным экземпляром класса управления капиталом. Класс сигналов был основан на осцилляторе Awesome. Советник запускался на EURUSD H4 с 2022.10.01 по 2023.10.01. Отчет представлен ниже:

В качестве контроля мы также провели тесты с теми же условиями, что и выше, за исключением того, что в качестве управления капиталом использовалась опция фиксированной маржи, предоставленная библиотекой, и это дало нам следующий отчет:

Последствия нашего краткого тестирования на основе этих двух отчетов заключаются в том, что существует потенциал корректировки нашего объема в соответствии с преобладающей волатильностью символа. Ниже показаны настройки, используемые для нашего советника и элемента управления.

И

Как видно, в основном использовались аналогичные настройки за исключением нашего советника, где нам пришлось их изменить для управления капиталом.
Заключение
Мы изучили, как агломеративная иерархическая классификация и дендрограмма могут помочь идентифицировать и оценить различные наборы данных и как эту классификацию можно использовать при составлении прогнозов. Как всегда, общие идеи и исходный код предназначены для тестирования идей, особенно в условиях, когда они сочетаются с различными подходами. Именно поэтому использован формат кода для классов Мастера MQL5.
Примечания к приложениям
Прикрепленный код предназначен для сборки с помощью Мастера MQL5 как часть сборки, включающей файл класса сигнала и файл трейлинг-класса. В этой статье сигнальным файлом был осциллятор Awesome (SignalAO.mqh). Здесь можно найти более подробную информацию об использовании Мастера.
Перевод с английского произведен MetaQuotes Ltd.
Оригинальная статья: https://www.mql5.com/en/articles/13630
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
Очень хорошо, что Вы освещаете функционал библиотеки AlgLib - это может быть полезно!
В статье очень не хватает кода для визуализации дендрограмм.