
Показатель склонности (Propensity score) в причинно-следственном выводе
Введение
Продолжаем свое погружение в мир причинно-следственного вывода и его современный инструментарий. Конечно же, задача стоит несколько шире, - применение методов causal inference в трейдинге. Мы уже начали с изучения основ и даже написали свои первые мета-лернеры, которые, к слову, оказались достаточно робастными. Вернее, робастными оказались модели, которые были получены с их помощью. Стоит оговориться, что первыми они были только для читателя, потому что для писателя они является очередными экспериментами. Поэтому обратной дороги нет и придется идти конца, пока вся тема причинно-следственного вывода в трейдинге не будет исчерпана. Ведь подходы в причинно-следственном выводе могут быть разными, и хотелось бы как можно шире осветить эту интересную тему. Или не осветить, поскольку один из потенциальных исходов нам неизвестен, - это же основной парадокс причинно-следственного вывода (шутка).
В этой статье подробнее осветим тему матчинга, который был тезисно затронут в предыдущей статье, а вернее одну из его разновидностей - Propensity score matching.
Это важно потому, что мы имеем определенный набор размеченных данных, которые неоднородны. Например, на форексе каждый отдельный обучающий пример может принадлежать к области высокой или низкой волатильности, более того, некоторые примеры могут чаще встречаться в выборке, а некоторые реже. Пытаясь определить средний причинно-следственный эффект (АТЕ) в такой выборке, мы неизбежно столкнемся со смещенными оценками, если будем предполагать, что все примеры в выборке имеют одинаковую склонность к получению тритмента. А при попытке получить условный средний причинно-следственный эффект (CATE) нас может ждать неприятность, которая называется "проклятие размерности".
Матчинг — это семейство методов оценки причинных эффектов путем сопоставления аналогичных наблюдений (или единиц) в группах тритмента и контроля. Цель сопоставления — провести сравнения между аналогичными единицами, чтобы добиться как можно более точной оценки истинного причинного эффекта.
Некоторые авторы материалов по причинно-следственному выводу предполагают, что сопоставление должно рассматриваться как этап предварительной обработки данных, поверх которого может использоваться любой оценщик (например, мета-лернер). Если у нас достаточно данных, чтобы потенциально отбросить некоторые наблюдения, использование сопоставления в качестве этапа предварительной обработки обычно полезно.
Представьте, что у вас есть набор данных для анализа. Эти данные содержат 1000 наблюдений. Каковы шансы, что вы найдете хотя бы одно точное совпадение для каждой строки, если в вашем наборе данных 18 переменных? Ответ, очевидно, зависит от ряда факторов. Сколько переменных являются двоичными? Сколько непрерывны? Сколько из них категориальных? Какое количество уровней у категориальных переменных? Являются переменные независимыми или коррелируют друг с другом?
Aleksander Molak в книге "Causal inference and discovery in Python" дает хороший наглядный пример.
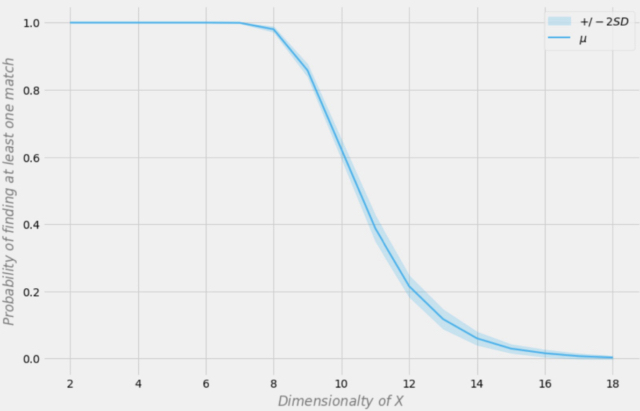
Вероятность обнаружения точного совпадения в зависимости от размерности набора данных
Предположим, что в нашей выборке 1000 наблюдений. На рисунке выше ось X представляет размерность набора данных (количество переменных в наборе данных), а ось Y представляет вероятность найти хотя бы одно точное совпадение в каждой строке.
Синяя линия — это средняя вероятность, а заштрихованные области представляют +/- два стандартных отклонения. Набор данных был создан с использованием независимых распределений Бернулли с p = 0,5. Поэтому каждая переменная является двоичной и независимой.
Я решил проверить это утверждение из книги и написал скрипт на Python, который вычисляет такую вероятность.
import numpy as np import matplotlib.pyplot as plt def calculate_exact_match_probability(dimensions): num_samples = 1000 num_trials = 1000 match_count = 0 for _ in range(num_trials): dataset = np.random.randint(2, size=(num_samples, dimensions)) row_sums = np.sum(dataset, axis=1) if any(row_sums == dimensions): match_count += 1 return match_count / num_trials def plot_probability_curve(max_dimensions): dimensions_range = list(range(1, max_dimensions + 1)) probabilities = [calculate_exact_match_probability(dim) for dim in dimensions_range] mean_probability = np.mean(probabilities) std_dev = np.std(probabilities) plt.plot(dimensions_range, probabilities, label='Exact Match Probability') plt.axhline(mean_probability, color='blue', linestyle='--', label='Mean Probability') plt.xlabel('Number of Variables') plt.ylabel('Probability') plt.title('Exact Match Probability in Binary Dataset') plt.legend() plt.show()
Действительно, для 1000 наблюдений вероятности совпали. В качестве эксперимента, можете посчитать их для размерностей своих датасетов самостоятельно. Для нашей дальнейшей работы достаточно осознания этого факта, что если в данных слишком много признаков (ковариат) по сравнению с количеством обучающих примеров, то возможность обобщения таких данных через классификатор будет ограничена. Здесь почти всегда работает принцип: чем больше данных, тем точнее статистические оценки.
*На практике это не всегда так, поскольку необходимо соблюдение условия i.i.d. (independent and identically-distributed).
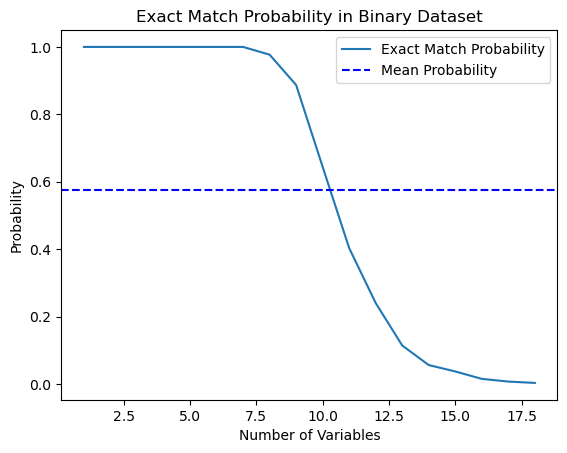
Как видите, вероятность найти точное совпадение в 18-мерном двоичном случайном наборе данных по сути равна нулю. В реальном мире мы редко работаем с чисто двоичными наборами данных и для непрерывных данных многомерное сопоставление становится еще более трудным. Это представляет собой серьезную проблему для матчинга, даже в приближенном случае. Как мы можем решить эту проблему?
Уменьшение размерности данных с использованием показателя склонности
Мы можем решить проблему проклятия размерности с помощью показателя склонности (Propensity score). Оценки склонности представляют собой оценки вероятности того, что данная единица будет отнесена к экспериментальной группе, исходя из ее характеристик. Согласно теореме о степени склонности (Розенбаум и Рубин, 1983), если у нас есть несмешанность данных по признакам Х, мы также будем иметь несмешанность с учетом показателя склонности, предполагая положительность (positivity). Положительность означает то, что леченные и нелеченные распределения должны пересекаться. Это предположение о позитивности причинного вывода. Это также имеет интуитивный смысл. Если тестовая группа и контрольная не пересекаются, это означает, что они очень разные, и мы не сможем экстраполировать эффект одной группы на другую. Такая экстраполяция не является невозможной (ее делает регрессия), но она очень опасна. Это похоже на тестирование нового препарата в эксперименте, где лечение получают только мужчины, а затем предполагают, что женщины будут реагировать на него одинаково хорошо. Формально, показатель склонности записывается следующим образом:
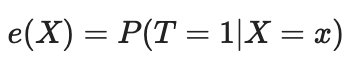
В идеальном мире у нас была бы истинная оценка склонности. Однако на практике механизм назначения тритмента неизвестен, и нам необходимо заменить истинную предрасположенность ее оценкой или ожиданием. Одним из распространенных способов сделать это является использование логистической регрессии, но можно использовать и другие методы машинного обучения, такие как градиентный бустинг (хотя это требует некоторых дополнительных шагов, чтобы избежать переобучения).
Мы можем использовать это уравнение для решения проблемы многомерности. Оценки склонности являются одномерными, и поэтому теперь мы можем сопоставлять только два значения, а не многомерные векторы.
Таким образом, если мы имеем условную независимость потенциальных исходов от тритмента,
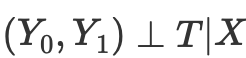
то можем посчитать средний причинно-следственный эффект для непрерывного и дискретного случаев при матчинге без propensity score:
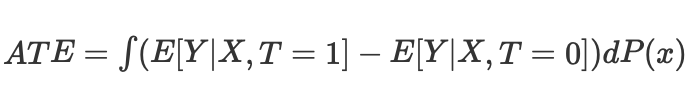
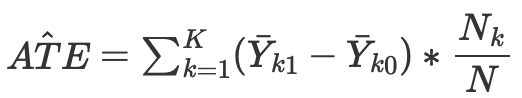
Где Nk - количество наблюдений в каждой ячейке. Под ячейкой подразумевается подгруппа наблюдений, сопоставленных по какой-нибудь метрике близости.
Однако, оценка склонности возникает в результате осознания того, что нам не нужно напрямую контролировать искажающие факторы X, чтобы достичь условной независимости
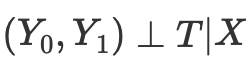
Вместо этого достаточно контролировать балансирующий показатель
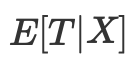
Оценка склонности позволяет не зависеть от X в целом, чтобы добиться независимости потенциальных исходов от тритмента. Достаточно обусловить эту единственную переменную, которая является показателем склонности:
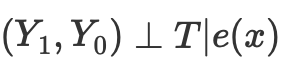
В литературе по causal inference описывается ряд проблем такого подхода:
- Во-первых, показатели склонности уменьшают размерность наших данных и – по определению – вынуждают нас выбросить некоторую информацию.
- Во-вторых, два наблюдения, которые сильно различаются в исходном пространстве признаков, могут иметь тот же показатель склонности. Это может привести к совпадению очень разных наблюдений и, следовательно, к искажению результатов.
- В-третьих, PSM (Propensity score modeling) приводит к парадоксу. В бинарном случае оптимальный показатель склонности будет равен 0,5. Что происходит в идеальном сценарии, когда все наблюдения имеют оптимальную оценку склонности 0,5? Положение каждого наблюдения в пространстве оценок склонности становится идентичным любому другому наблюдению. Это иногда называется парадоксом PSM.
Матчинг при помощи показателя склонности и связанные с ним методы
Существует ряд методов сопоставления (мачинга) юнитов на основе Propensity score. Основным методом принято считать метод ближайших соседей, который сопоставляет каждую единицу i в экспериментальной группе с единицей j в контрольной группе с ближайшим абсолютным расстоянием между их показателями склонности, выраженным как
d(i, j) = minj{|e(Xi) – e(Xj)|}.
В качестве альтернативы, матчинг по порогу сопоставляет каждую единицу i в группе лечения с единицей j в контрольной группе в пределах заранее заданного порога b; то есть
d(i, j) = minj{|e(Xi) – e(Xj)| <b}.
Рекомендуется, чтобы заранее заданный порог b был меньше или равен 0,25 стандартного отклонения показателей склонности. Другие исследователи утверждают, что b = 0,20 стандартного отклонения показателей склонности является оптимальным.
Другим вариантом сопоставления по порогу является сопоставление по радиусу, которое представляет собой сопоставление «один ко многим» и сопоставляет каждую единицу i в группе лечения с несколькими единицами в контрольной группе в пределах заранее заданного диапазона b; то есть
d(i, j) = {|e(Xi) – e(Xj)| <b}.
Другие методы сопоставления оценок склонности включают метрику Махаланобиса. При сопоставлении с помощью метрики Махаланобиса каждая единица i в экспериментальной группе сопоставляется с единицей j в контрольной группе, при этом ближайшее расстояние Махаланобиса рассчитывается на основе близости переменных.
Методы сопоставления показателей склонности, обсуждавшиеся до сих пор, могут быть реализованы с использованием либо жадного алгоритма сопоставления, либо алгоритма оптимального сопоставления.
- При жадном сопоставлении после того, как сопоставление выполнено, совпавшие единицы не могут быть изменены. Каждая пара подобранных юнитов является наилучшей парой, доступной на данный момент.
- При оптимальном сопоставлении предыдущие сопоставленные единицы можно изменить перед выполнением текущего матчинга, чтобы достичь общего минимального или оптимального расстояния.
- Оба алгоритма матчинга обычно производят одинаковые совпадающие данные, когда размер контрольной группы велик; однако оптимальное сопоставление приводит к меньшим общим расстояниям внутри сопоставляемых единиц. Таким образом, если цель состоит в том, чтобы просто найти хорошо согласованные группы, жадного сопоставления может быть достаточно; если вместо этого цель состоит в том, чтобы найти хорошо подобранные пары, то оптимальное соответствие может быть предпочтительнее.
Существуют методы, связанные с сопоставлением показателей склонности, которые не сопоставляют строго отдельные единицы выборки. Например, субклассификация (или стратификация) классифицирует все единицы всей выборки на несколько слоев на основе соответствующего количества перцентилей оценок склонности и сопоставляет единицы по страте. Было замечено, что пять страт устраняют до 90% ошибок отбора.
Особым типом субклассификации является полное сопоставление, при котором подклассы создаются оптимальным способом. Полностью совпадающая выборка состоит из совпадающих подмножеств, в которых каждый совпадающий набор содержит одну эксперементальную единицу и одну или несколько контрольных единиц или одну контрольную единицу и одну или несколько эксперементальных единиц. Полный матчинг является оптимальным с точки зрения минимизации средневзвешенного значения предполагаемой меры расстояния между каждым субъектом, получающим лечение, и каждым контрольным субъектом в каждом подклассе.
Другой метод, связанный с сопоставлением показателей склонности, — это сопоставление по ядру (или локальное линейное сопоставление), которое сочетает в себе сопоставление и анализ результатов в одной процедуре с сопоставлением «один ко всем».
Несмотря на многообразие предлагаемых методов сопоставления (матчинга), эффективность их применения больше зависит от правильной постановки задачи, нежели от конкретного метода.
Допущение о сильном игнорировании
«Сильное игнорирование» — это решающее допущение при построении показателя склонности (Propensity score), целью которого является оценка причинных эффектов в наблюдениях, где назначение лечения является случайным. По сути, это означает, что назначение лечения не зависит от потенциальных результатов, учитывая наблюдаемые исходные ковариаты (признаки).
Разберемся подробнее:
- Распределение тритмента: это то, получает ли юнит лечение или нет (например, прием нового лекарства или участие в программе).
- Потенциальные исходы: это те исходы, которые юнит испытал бы как в условиях лечения, так и в условиях контроля, но мы можем наблюдать только один для каждого юнита.
- Базовые ковариаты: это характеристики юнитов, измеренные до распределения лечения, которые могут влиять как на вероятность получения лечения, так и на исход.
Предположение "strongly ignorable" утверждает, что:
- Нет неизмеренных конфаундеров: нет ненаблюдаемых переменных, которые влияют как на распределение лечения, так и на исход. Это важно, потому что ненаблюдаемые конфаундеры могут вносить смещение в оцененный эффект лечения.
- Положительность: у каждого юнита есть ненулевая вероятность получить как лечение так и контроль, учитывая его наблюдаемые ковариаты. Это гарантирует, что в сравниваемых группах есть достаточно юнитов для значимого сравнения.
Если эти условия соблюдены, то обуславливание propensity score (оцененная вероятность получения лечения, учитывая ковариаты) позволяет получить несмещенные оценки среднего эффекта лечения (ATE). ATE представляет собой среднюю разницу в исходах между группами лечения и контроля, как если бы лечение было распределено случайным образом.
Взвешивание по обратной вероятности
Взвешивание по обратной вероятности (Inverse probability weighting) — это один из подходов к устранению помех или мешающих факторов (англ. confounding) путем попытки перевзвешивания наблюдений в наборе данных на основе обратной вероятности назначения лечения. Идея состоит в том, чтобы придать больший вес наблюдениям, которые оценены как менее вероятные быть леченными при назначении тритмента, что сделает их более репрезентативными для общей популяции.
- Сначала оценивается показатель склонности, который представляет собой вероятность получения лечения с учетом наблюдаемых ковариат.
- Для каждого наблюдения рассчитывается обратная оценка склонности.
- Затем каждое наблюдение умножается на соответствующий ему вес. Это означает, что наблюдения с более низкой вероятностью получения наблюдаемого лечения имеют больший вес.
- Затем взвешенный набор данных используется для анализа. Веса применяются как к экспериментальной, так и к контрольной группам с поправкой на потенциальное влияние наблюдаемых ковариат.
Взвешивание по обратной вероятности может помочь сбалансировать распределение ковариат между обработанными (тритмент) и контрольными группами, уменьшая систематическую ошибку при оценке причинных эффектов. Однако он основан на предположении, что все соответствующие мешающие переменные измерены и включены в модель, используемую для оценки показателя склонности. Кроме того, как и любой статистический метод, успех IPW зависит от качества модели, используемой для оценки показателя склонности.
Формула обратной оценки склонности выглядит следующим образом:
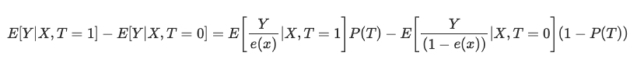
Не вдаваясь в детали, можно сравнить два члена уравнения. Левый для тритмент группы, правый для контрольной группы. Из формулы видно, что простое сравнение средних эквивалентно сравнению средних, взвешенных по обратной оценке. Это создает популяцию того же размера, что и исходная, но в которой в левой части все получают лечение. По тем же соображениям правая рассматривает нелеченых и придает большое значение тем, которые выглядят как леченные.
Оценка результатов после матчинга
В причинно-следственном выводе оценка строится как ATE или CATE, то есть разница взвешенных средних (с учетом показателя склонности) целевых значений леченных и нелеченных.
Когда мы получили показатель склонности в виде e(x), мы можем использовать эти значения, например, для обучения другого классификатора, вместо исходных значений признаков Х. А также мы можем сопоставить семплы из выборки по их Propensity score, чтобы разделить на страты. Еще одним вариантом является добавление e(x) в качестве отдельного признака при обучении финального оценщика, что поможет избавиться от смещенных оценок из-за путаницы в данных (англ. confounding), когда разные примеры в выборке имеют разные оценки по версии Propensity score.
Нам интересно найти такие подгруппы, которые поддаются тритменту (обучению моделей) хорошо или плохо. И затем обучать финальный классификатор только на тех данных, которые хорошо поддаются обучению (ошибка классификации минимальна). А данные, которые которые плохо классифицируются, вынести во вторую подгруппу и обучить второй классификатор отличать эти две подгруппы, то есть отделить зерна от плевел, или выделить подгруппы, наиболее хорошо поддающиеся тритменту. Поэтому мы не станем сейчас перенимать всю методологию Propensity score, а будем матчить семплы по полученным вероятностям обученного классификатора, тогда как общая оценка ATE (average treatment effect) нас мало интересует.
Иными словами, мы будем строить свою оценку по результатам работы алгоритма на новых данных, которые не участвовали в обучении. Дополнительно, нас все так же будет интересовать средняя скорость набора моделей, обучающихся на рандомизированных данных. Чем выше средняя оценка независимых моделей, тем больше доверия к каждой конкретной.
Переходим к экспериментам
Начиная данную статью я осознавал, что для многих трейдеров, особенно для незнакомых с машинным обучением, данный углубленный материал может показаться весьма контринтуитивным. Вспоминая мое первое знакомство с причинно-следственным выводом, это первоначальное непонимание настолько сильно задело мое самолюбие, что не углубиться в подробности я просто не мог. Тем более даже не мог представить, что возьму на себя смелость адаптировать методики causal inference к классификации временных рядов.
- файл propensity without matching.py
Давайте начнем со способа, благодаря которому мы можем инкорпорировать оценки propensity score напрямую в наш оценщик, или мета-лернер. Для этого следует обучить две модели. Сперва саму PSM (propensity score model), которая позволит получить вероятности отнесения обучающих примеров к тритмент или тестовой группам. Полученные вероятности, вместе с признаками (ковариатами) мы подадим на вход второй модели, которая будет предсказывать исходы (покупку или продажу).
Интуиция такого подхода заключается в том, что мета-лернер теперь сможет различать подгруппы семплов на основании их склонности к тритменту. Таким образом, мы получим взвешенные прогнозы исходов, которые должны оказаться более точными. После этого мы разделим датасет на хорошо предсказуемые и плохо предсказуемые случаи, как это было в предыдущих статьях. В этом случае нам не понадобится явный матчинг сэмплов, потому что мета-лернер будет автоматически учитывать показатель склонности в своих оценках. Мне такой подход кажется довольно удобным, потому что машинное обучение делает за нас всю работу.
Сначала создадим подвыборки train и val для обучения мета-модели. Поскольку мета-лернер будет обучаться на train подвыборке, создадим пару целевых y_T1, y_T0, и заполним их единицами и нулями. Это будет соответствовать тому, получали ли юниты тритмент (обучение модели) или нет. Затем снова перемешаем подвыбору, целевыми переменными в которой являются тритменты.
X_train, X_val, y_train, y_val = train_test_split( X, y, train_size = 0.5, test_size = 0.5, shuffle = True) # randomly assign treated and control y_T1 = pd.DataFrame(y_train) y_T1['T'] = 1 y_T1 = y_T1.drop(['labels'], axis=1) y_T0 = pd.DataFrame(y_val) y_T0['T'] = 0 y_T0 = y_T0.drop(['labels'], axis=1) y_TT = pd.concat([y_T1, y_T0]) y_TT = y_TT.sort_index() X_trainT, X_valT, y_trainT, y_valT = train_test_split( X, y_TT, train_size = 0.5, test_size = 0.5, shuffle = True)
Следующим шагом необходимо обучить PSM модель предсказывать принадлежность сэмплов к тритмент или контрольной подвыборкам.
# fit propensity model PSM = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', use_best_model=True, early_stopping_rounds=15, verbose = False).fit(X_trainT, y_trainT, eval_set = (X_valT, y_valT), plot = False)
Затем нужно получить предсказания принадлежности к тритмент и контрольной группам и добавить их к признакам мета-лернера, после чего обучить его.
# predict probabilities train_proba = PSM.predict_proba(X_train)[:, 1] val_proba = PSM.predict_proba(X_val)[:, 1] # fit meta-learner meta_m = CatBoostClassifier(iterations = iterations, depth = depth, custom_loss = ['Accuracy'], eval_metric = 'Accuracy', verbose = False, use_best_model = True, early_stopping_rounds=15).fit(X_train.assign(T=train_proba), y_train, eval_set = (X_val.assign(T=val_proba), y_val), plot = False)
На финальном этапе получим предсказания мета-лернера, сравним предсказанные метки с фактическими и заполним книгу плохих примеров.
# create daatset with predicted values predicted_PSM = PSM.predict_proba(X)[:,1] X_psm = X.assign(T=predicted_PSM) coreset = X.assign(T=predicted_PSM) coreset['labels'] = y coreset['labels_pred'] = meta_m.predict_proba(X_psm)[:,1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) # add bad samples of this iteration (bad labels indices) coreset_b = coreset[coreset['labels']==0] coreset_s = coreset[coreset['labels']==1] diff_negatives_b = coreset_b['labels'] != coreset_b['labels_pred'] diff_negatives_s = coreset_s['labels'] != coreset_s['labels_pred'] BAD_BUY = BAD_BUY.append(diff_negatives_b[diff_negatives_b == True].index) BAD_SELL = BAD_SELL.append(diff_negatives_s[diff_negatives_s == True].index)
Теперь давайте попробуем обучить 25 моделей и посмотрим на лучший и средний результаты.
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res)) options.sort(key=lambda x: x[0]) test_model(options[-1][1:], plt=True) test_all_models(options)
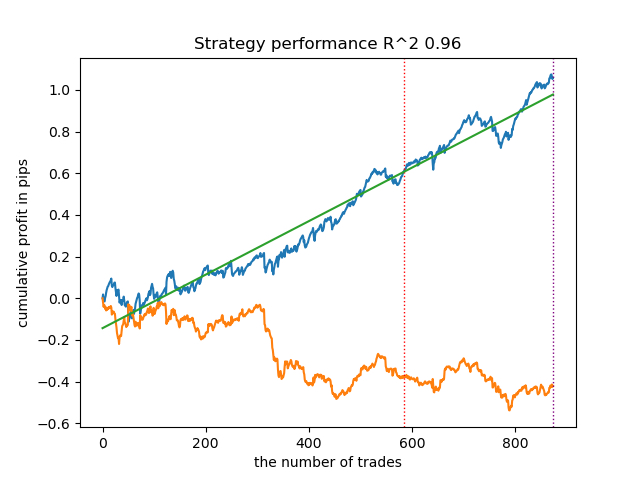
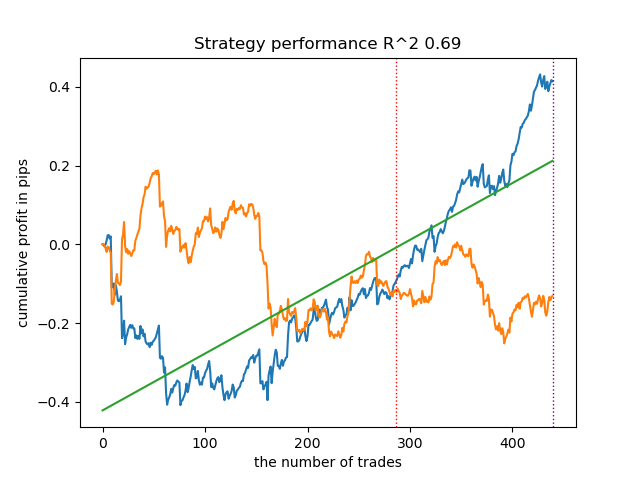
Я провел серию таких обучений и cделал вывод, что такой подход практически ничем не отличается по качеству моделей от моего подхода, который был описан в предыдущей статье. Оба варианта способны генерировать неплохие модели, которые проходят OOS. Это не должно нас удивлять, потому что мы использовали e(x) как дополнительный признак, а остальной алгоритм остался без изменения.
- файл propensity matching naive.py
В ходе размышлений о методах реализации, никогда нельзя знать заранее какой метод сработает лучше, а какой хуже. В качестве эксперимента я решил сделать матчинг не по склонности к назначению тритмента, а по склонности предсказания целевых меток. Это должно показаться читателю более интуитивно понятным. Основным отличием здесь является то, что обучается всего одна, теперь уже условно названная, PSM модель. Дальше предсказываются вероятности и создается список бинов по количеству страт, на которые мы хотим разделить полученные вероятности. Для каждой страты считается количество правильно/неправильно угаданных исходов, после чего для страт, где количество неправильно угаданных (умноженное на коэффициент) примеров превышает количество правильно угаданных, срабатывает условие добавления плохих примеров в книгу плохих примеров.
bins = np.linspace(lower_bound, upper_bound, num=bins_number) coreset['bin'] = pd.cut(coreset['propensity'], bins) for val in range(len(coreset['bin'].unique())): values = coreset.loc[coreset['bin'] == coreset['bin'].unique()[val]] diff_negatives = values['labels'] != values['labels_pred'] if len(diff_negatives[diff_negatives == False]) < (len(diff_negatives[diff_negatives == True]) * coefficient): B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index)
Такой подход имеет дополнительные параметры:
- bins_number - количество бинов
- lower_bound - нижняя граница вероятности, от которой считаются страты
- upper_bound - верхняя граница вероятности, до которой считаются страты
Поскольку мы используем мета-лернер с небольшой глубиной, то вероятности обычно группируются вокруг 0.5 и редко достигают предельных границ. Поэтому можно отбрасывать крайние значения как неинформативные, с помощью задания верхней и нижней границ.
Обучим 25 моделей и посмотрим на результаты. Хочу отметить, что все модели обучаются на одном и том же датасете, поэтому их сравнение получается достаточно корректным.
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.3, upper_bound=0.7, coefficient=1.0))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res)) options.sort(key=lambda x: x[0]) test_model(options[-1][1:], plt=True)
К удивлению, такая спонтанная реализация показала себя достаточно хорошо на новых данных. Ниже представлены графики торговли лучшей модели и всех 25 моделей сразу.
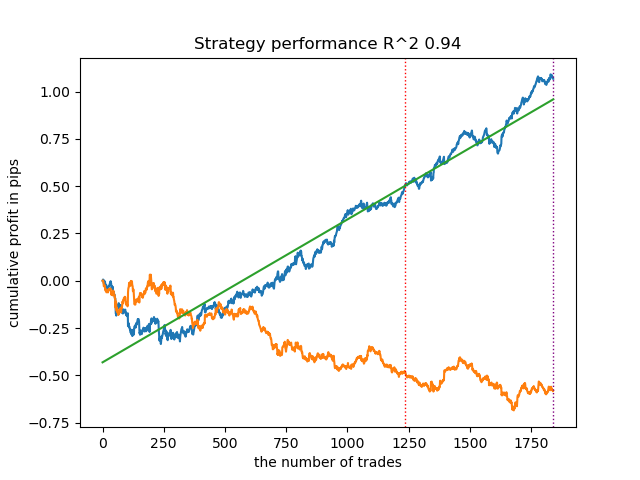
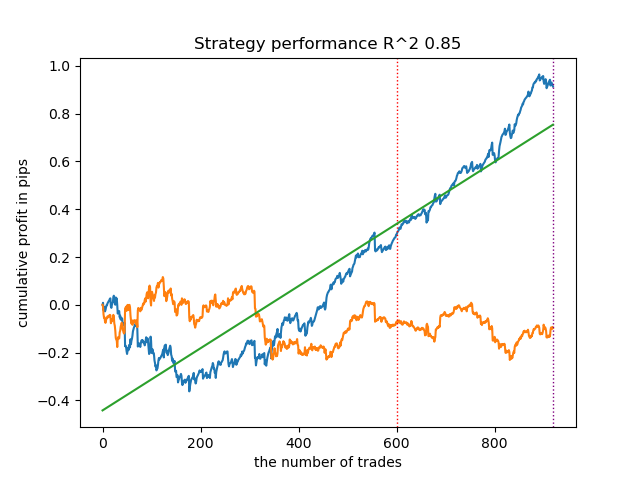
- файл propensity matching original.py
Переходим к реализации наиболее приближенного к теории примера, в котором будет выполняться допущение о сильном игнорировании (strongly ignorable). Напомню, что strongly ignorable — это когда назначение тритмента никак не зависит от потенциальных исходов, то есть оно полностью случайно и нет никаких неучтенных переменных, влияющих на предвзятость. Для этого случайно назначим тритмент и обучим PSM модель. Затем обучим мета-оценщик предсказывать исходы сделок (метки классов). После этого стратифицируем выборку по оценке propensity score и добавим семплы в книгу плохих примеров только из тех бинов, количество неудачных предсказаний в которых превышает количество удачных, с учетом коэффициента.
Также я добавил возможность применения IPW (inverse probability weighting), которое было описано в теоретической части.
После обучения двух классификаторов выполняется следующий код.
# create daatset with predicted values coreset = X.copy() coreset['labels'] = y coreset['propensity'] = PSM.predict_proba(X)[:, 1] if Use_IPW: coreset['propensity'] = coreset['propensity'].apply(lambda x: 1 / x if x > 0.5 else 1 / (1 - x)) coreset['propensity'] = coreset['propensity'].round(3) coreset['labels_pred'] = meta_m.predict_proba(X)[:, 1] coreset['labels_pred'] = coreset['labels_pred'].apply(lambda x: 0 if x < 0.5 else 1) bins = np.linspace(lower_bound, upper_bound, num=bins_number) coreset['bin'] = pd.cut(coreset['propensity'], bins) for val in range(len(coreset['bin'].unique())): values = coreset.loc[coreset['bin'] == coreset['bin'].unique()[val]] diff_negatives = values['labels'] != values['labels_pred'] if len(diff_negatives[diff_negatives == False]) < (len(diff_negatives[diff_negatives == True]) * coefficient): B_S_B = B_S_B.append(diff_negatives[diff_negatives == True].index)
Обучим 25 моделей без использования IPW и посмотрим на лучший график баланса и на усредненный по всем моделям, c такими настройками:
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.3, upper_bound=0.7, coefficient=1.5, Use_IPW=False))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res))
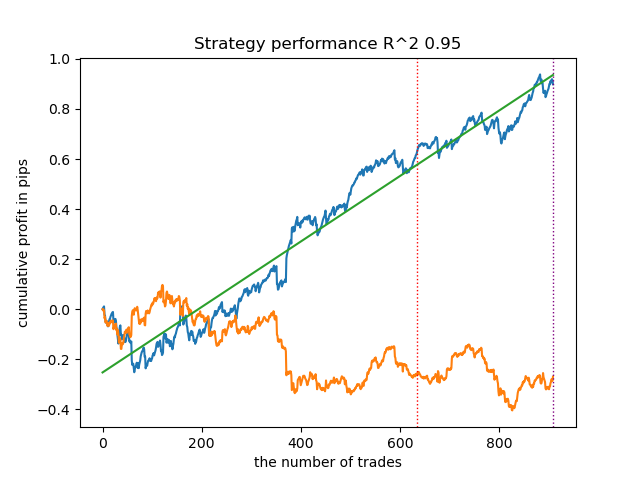
В целом, результаты сопоставимы с результатами предыдущих реализаций. Теперь давайте сделаем то же самое со включенным IPW.
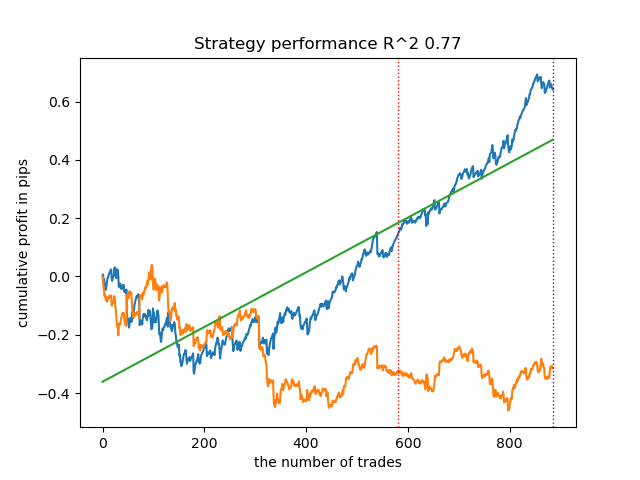
options = [] best_res = 0.0 for i in range(25): print('Learn ' + str(i) + ' model') options.append(learn_final_models(meta_learners(models_number=5, iterations=25, depth=2, bad_samples_fraction=0.5, bins_number=25, lower_bound=0.1, upper_bound=10.0, coefficient=1.5, Use_IPW=True))) if options[-1][0] > best_res: best_res = options[-1][0] print("BEST: " + str(best_res))

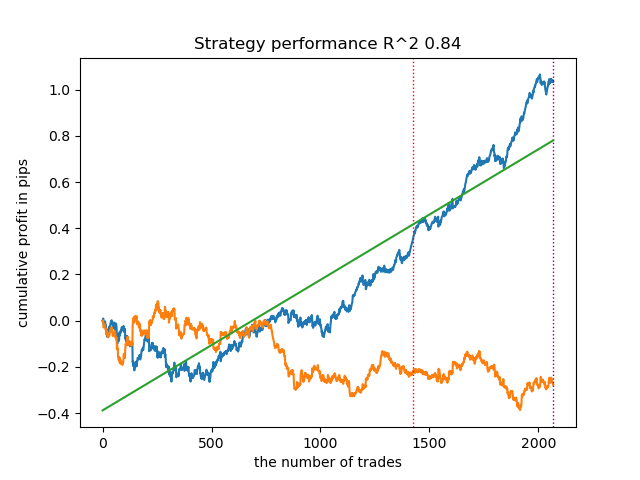
Результаты оказались одними из самых лучших. Конечно, для более детального сравнения необходимо проводить множественное тестирование на разных символах, но это слишком увеличило бы объем и без того большой статьи. Таблица полученных результатов представлена ниже.
| Алгоритм | Лучший результат | Средний результат (25 моделей) |
|---|---|---|
| propensity without matching.py | 0.96 | 0.69 |
| propensity matching naive.py | 0.94 | 0.85 |
| propensity matching original.py | 0.95 | 0.77 |
| propensity matching original.py IPW | 0.97 | 0.84 |
Заключение
Мы рассмотрели возможность использования показателя склонности для задачи классификации финансовых временных рядов. Такой подход имеет хорошее теоретическое обоснование в науке о причинно-следственном выводе, но также имеет свои недостатки. В целом, он позволил получить модели, которые сохраняют свои характеристики на новых данных.
Предупреждение: все права на данные материалы принадлежат MetaQuotes Ltd. Полная или частичная перепечатка запрещена.
Данная статья написана пользователем сайта и отражает его личную точку зрения. Компания MetaQuotes Ltd не несет ответственности за достоверность представленной информации, а также за возможные последствия использования описанных решений, стратегий или рекомендаций.
- Бесплатные приложения для трейдинга
- 8 000+ сигналов для копирования
- Экономические новости для анализа финансовых рынков
Вы принимаете политику сайта и условия использования
https://www.mql5.com/ru/code/48482
Архив моделей из статьи (кроме самой первой в списке), для быстрого ознакомления без установки Python.
Здравствуйте . Использовал ваш метод : propensity_matching_naive.py в параметрах выставил обучение 25 моделей. После обучения появилась в директории питон папка :
catboost_info.
Что пытался сделать я? Загрузил котировки AUDCAD h1, далее используя файл :
propensity_matching_naive.py из вашей публикации : https://www.mql5.com/ru/articles/14360
Не могу понять ,что делать дальше, что бы сохранить дальше в формате ONNX, или данный метод работает только как оценка качества тестирования ?? :
Пользуюсь pythom первый раз в жизни, установил без проблем, библиотеки так же не сложно. Прочитал ваши публикации , серьезный подход ,но возможно не самый легкий метод расчета, могу ошибаться, все относительно.
Прикрепил скрины ,что получилось у меня в обучении.
Здравствуйте . Использовал ваш метод : propensity_matching_naive.py в параметрах выставил обучение 25 моделей. После обучения появилась в директории питон папка :
catboost_info.
Что пытался сделать я? Загрузил котировки AUDCAD h1, далее используя файл :
propensity_matching_naive.py из вашей публикации : https://www.mql5.com/ru/articles/14360
Не могу понять ,что делать дальше, что бы сохранить дальше в формате ONNX, или данный метод работает только как оценка качества тестирования ?? :
Пользуюсь pythom первый раз в жизни, установил без проблем, библиотеки так же не сложно. Прочитал ваши публикации , серьезный подход ,но возможно не самый легкий метод расчета, могу ошибаться, все относительно.
Прикрепил скрины ,что получилось у меня в обучении.
Добрый. в предыдущих статьях описаны 2 способа экспорта.
1. более ранний, экспорт модели в нативный MQL код
2. экспорт в onnx формат в более поздних статьях
Не помню, есть ли в питон файлах к этой статье функция экспорта модели. "export_model_to_ONNX()", Если нет, можно взять из предыдущих.