
Redes neurais em trading: modelo multivariado de ponta a ponta para previsão de séries temporais (GinAR)

Introdução
A previsão de séries temporais multivariadas (MTSF) tornou-se parte indispensável da análise em diversos setores, desde o transporte e a ecologia até, naturalmente, os mercados financeiros. Em nossa área, isso significa a possibilidade de prever o comportamento de diversos instrumentos financeiros inter-relacionados, como ações, índices e moedas, com base em sua dinâmica histórica. Esses modelos permitem tomar decisões de investimento mais fundamentadas, gerenciar riscos e identificar relações ocultas entre os ativos.
Formalmente, uma série temporal multivariada (MTS) pode ser representada como um grafo espaço-temporal, no qual cada variável, seja a cotação de uma moeda, o volume de negociação ou a taxa de retorno, é observada ao longo do tempo e se relaciona com outras variáveis por meio de dependências ocultas. Essas dependências se dividem em dois tipos principais: temporais, isto é, relações de causa e efeito entre eventos, e espaciais, isto é, a influência mútua entre ativos ou setores do mercado.
Para prever MTS com eficiência, é essencial saber identificar e utilizar essas dependências espaço-temporais. Isso é especialmente crítico em condições de alta volatilidade e choques de mercado, quando os modelos tradicionais simplesmente não conseguem se adaptar a tempo. É aí que entram as redes neurais em grafos. Esses modelos combinam as vantagens das redes convolucionais em grafos e dos modelos recorrentes, permitindo construir previsões mais precisas com base em dependências complexas entre as variáveis.
Mas, na prática, nem tudo é tão simples. Os dados financeiros frequentemente são incompletos. Parte das métricas fica indisponível, ou então apenas uma parte do intervalo temporal é observada. As lacunas podem ser causadas por qualquer fator: falhas no fornecimento de dados, mudanças na política de cálculo de indicadores ou erros técnicos das corretoras. E, se faltam dados de ativos-chave, a precisão da previsão cai drasticamente. Em geral, os modelos em grafos perdem, nesses casos, a capacidade de avaliar adequadamente as dependências, o que leva a um acúmulo em cascata de erros e à redução da qualidade das previsões.
Algumas tentativas de contornar esse problema baseiam-se na simples exclusão das variáveis indisponíveis. Mas isso é pouco sensato, pois a ausência de dados de um ativo importante pode comprometer toda a estrutura lógica do modelo e levar a conclusões equivocadas. Abordagens mais sofisticadas utilizam métodos de reconstrução de dados ausentes, ou (imputação), combinando o contexto temporal e relações espaciais fixas, como correlações ou estruturas de rede entre ativos. No entanto, esses métodos frequentemente falham quando a porcentagem de dados ausentes é alta ou quando não há relações confiáveis entre as variáveis observadas e as ausentes. E, mais uma vez, os erros se acumulam, e a previsão se torna pouco confiável.
O que fazer, então? A solução está na construção de modelos capazes de usar informações sobre as variáveis disponíveis para reconstruir os dados ausentes diretamente durante o processo de previsão, sem separar o treinamento em etapas de "Reconstrução -> Previsão". É exatamente assim que funciona o novo framework Graph Interpolation Attention Recursive Network (GinAR), apresentado no trabalho "GinAR: An End-To-End Multivariate Time Series Forecasting Model Suitable for Variable Missing". Trata-se de uma nova arquitetura end-to-end voltada para o trabalho com variáveis ausentes em séries temporais multivariadas.
Na base do GinAR está uma rede recorrente simples (SRU), na qual estão incorporados dois componentes-chave:
- Interpolation Attention (IA), um mecanismo que reconstrói variáveis ausentes por meio da aplicação de algoritmos de atenção aos dados disponíveis. Isso permite evitar erros causados por tentativas de inferir padrões a partir de zeros e outliers.
- Adaptive Graph Convolution (AGCN), uma convolução em grafo adaptativa em grafo que recompõe a estrutura de inter-relações entre as variáveis após a reconstrução, permitindo considerar tanto correlações diretas quanto indiretas entre os ativos.
Dessa forma, o GinAR prevê e ajusta simultaneamente o modelo de dependências, impedindo a propagação dos erros. E, o que é especialmente importante, ele funciona até mesmo em condições extremas. Nos testes com dados reais realizados pelos autores do framework, o modelo manteve alta precisão mesmo quando até 90% das variáveis estavam indisponíveis. Imagine a situação em que você tem dados de apenas alguns ativos da carteira, enquanto os demais não fornecem dados: o GinAR ainda assim gera previsões para todo o sistema.
Em resumo, os principais avanços do GinAR:
- É o primeiro modelo voltado para MTSF com variáveis ausentes que funciona sem uma etapa preliminar de reconstrução.
- A nova arquitetura (IA + AGCN) substitui as camadas totalmente conectadas da SRU, minimizando distorções nas dependências.
- De acordo com os resultados experimentais apresentados no trabalho original, o GinAR superou outros 11 modelos em cinco conjuntos de dados diferentes, mostrando resultados consistentes mesmo em níveis criticamente altos de dados ausentes.
Para os mercados financeiros, isso significa apenas uma coisa: mesmo com ausência parcial de dados, ainda é possível fazer previsões de forma sistemática e precisa. Isso significa que estratégias adaptativas, testes de estresse e gestão de riscos podem ser implementados com confiabilidade, sem depender de dados iniciais perfeitos. Afinal, na prática, o mercado nunca é ideal, e foi justamente para operar nessas condições que o GinAR foi criado.
Algoritmo GinAR
A arquitetura do framework GinAR segue o esquema clássico Encoder -> Decoder. Como Encoder, utiliza-se uma pilha de camadas GinAR, enquanto o Decoder é implementado com base em um perceptron multicamadas (MLP). O elemento-chave do sistema é a célula GinAR, um módulo construído com base no princípio da modelagem recursiva. Quando dados incompletos são fornecidos na entrada, isto é, séries temporais com variáveis ausentes, o modelo é capaz de prever simultaneamente os valores futuros de todas as variáveis, inclusive aquelas para as quais não existe um histórico completo.
Ao projetar a lógica interna do GinAR, os autores do framework propuseram substituir todas as camadas totalmente conectadas (fully connected) da estrutura recorrente clássica da SRU por dois componentes especializados, IA (Interpolation Attention) e AGCN (Adaptive Graph Convolution Network).
O primeiro componente reconstrói as variáveis ausentes usando informações das vizinhas disponíveis. No contexto dos mercados financeiros, isso é especialmente importante: se faltarem dados de ativos-chave, mesmo que parcialmente, o modelo pode perder precisão de forma acentuada. O mecanismo IA permite evitar esse problema ao reconstruir representações significativas das séries temporais ausentes com base nas disponíveis e minimizar a influência do ruído.
O segundo componente, o AGCN, abandona os grafos fixos de dependências, por exemplo, conexões previamente definidas entre ativos, índices e setores, e aprende uma estrutura de grafo adaptativa diretamente durante o treinamento. Isso possibilita capturar de forma flexível as relações espaciais entre as variáveis, mesmo quando elas são mutáveis ou não evidentes.
O Encoder do GinAR é implementado por meio de um esquema recorrente, no qual, a cada passo temporal, são fornecidos na entrada os atributos do momento atual e o estado interno do passo anterior. A célula GinAR os processa, atualiza o estado e forma a representação oculta do passo temporal atual. Essa abordagem permite, ao mesmo tempo, reconstruir dados ausentes, reconstituir o grafo de dependências e extrair padrões dinâmicos, tudo em um único módulo. Graças às conexões residuais (skip connections), o modelo pode ser profundo sem perder a estabilidade do treinamento. Isso é especialmente importante em tarefas de previsão de sinais complexos de mercado, nas quais tanto as oscilações de curto prazo quanto as tendências de longo prazo são relevantes.
A etapa seguinte é a previsão. Para isso, é necessário agregar corretamente as representações ocultas obtidas. Por um lado, cada estado oculto final da célula GinAR contém informações completas sobre a estrutura temporal dos dados de origem, mérito do caráter recorrente do modelo. Por outro lado, graças à arquitetura multicamada e à presença de skip connections, cada representação oculta reflete diferentes níveis de abstração, dos micromovimentos às correlações globais. Por isso, os atributos de todas as camadas são combinados em um único tensor e fornecidos na entrada do Decoder. No papel de decoder, atua um perceptron multicamadas treinado segundo a estratégia Direct Multi-Step Forecasting (DMSF), ou previsão direta de múltiplos períodos. Essa abordagem permite prever de imediato todo o horizonte-alvo, (por exemplo, o movimento das cotações nos próximos 5 a 10 barras), sem recorrer à previsão iterativa passo a passo, que tende ao acúmulo de erros.
Como resultado, o GinAR forma uma arquitetura robusta, capaz de lidar com eficiência com tarefas de previsão em condições de dados ausentes, inter-relações dinâmicas e alta correlação entre séries temporais. O modelo reúne reconstrução de dados, aprendizado do grafo e previsão, tudo em uma única solução end-to-end, capaz de se adaptar às condições reais de incerteza do mercado.
O mecanismo Interpolation Attention (IA) é projetado para reconstruir as representações de variáveis com histórico completamente ausente. Para cada variável ausente, é necessário determinar o conjunto de variáveis disponíveis com base nas quais a reconstrução será realizada, bem como os respectivos pesos de influência dessas variáveis. Esse processo consiste em duas etapas-chave: primeiro, são formadas as correspondências entre as variáveis ausentes e as disponíveis, e depois é aplicado o mecanismo de atenção para agregar as informações e realizar a reconstrução.
Na primeira etapa, é construída uma matriz de correspondência entre as variáveis. São inicializadas uma matriz diagonal IN ∈ Rᴺ*ᴺ, bem como dois embeddings matriciais das variáveis: EIA1 ∈ Rᴺ*ᵈ e EIA2 ∈ Rᵈ*ᴺ. Esses embeddings são treinados em conjunto com o modelo. A matriz de correlação entre as variáveis é calculada pela fórmula:
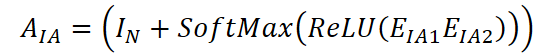
O elemento (i, j) da matriz AIA ∈ Rᴺ*ᴺ reflete o grau de relação entre as variáveis i e j. Se o valor for positivo, isso indica que a variável disponível j pode ser usada para reconstruir a variável ausente i. Assim, para cada variável ausente i, pode-se definir o conjunto de variáveis disponíveis relacionadas N(i) ⊆ {1,…,N}.
Depois de definidas as correspondências, a reconstrução das representações das variáveis ausentes é realizada com o auxílio de mecanismos de atenção. Para isso, são calculados os coeficientes de atenção aij, que refletem a importância da variável disponível j na reconstrução da variável i:
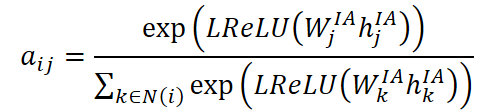
onde aij é a representação oculta atual da variável j, e Wᴵᴬ é uma matriz de pesos treinável. A ativação é aplicada por meio da função LReLU, o que permite evitar a anulação dos gradientes em ativações fracas.
Os coeficientes obtidos são usados para agregar informações das variáveis disponíveis. A representação da variável ausente i é reconstruída pela fórmula:
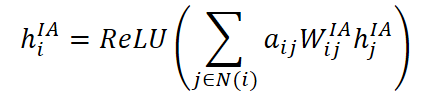
onde aij é uma matriz de pesos treinável individual para cada par de variáveis i e j, e a agregação final é normalizada com ReLU para aumentar a robustez a outliers.
Esse processo é repetido para todas as variáveis ausentes até que sejam reconstruídas as representações de todos os M componentes ausentes. Depois disso, obtém-se um novo tensor XᴵᴬM ∈ Rᴺ*ᴴ*ᶜ′, no qual todas as variáveis, inclusive as anteriormente ausentes, passam a ter representações ocultas completas. Vale notar que, na prática, para aumentar a eficiência da reconstrução, as etapas 2 e 3 são implementadas por meio de multiplicação de matrizes e computação paralela.
Assim, o mecanismo Interpolation Attention permite reconstruir de forma flexível os dados em séries temporais multivariadas com variáveis ausentes, sem a necessidade de fixar rigidamente de antemão a estrutura de relações entre as variáveis. Isso é especialmente importante para tarefas na área de previsão financeira, em que as estruturas de correlação entre os ativos podem ser mutáveis, e os dados históricos podem ser incompletos ou ruidosos.
Em tarefas de previsão multivariada de séries temporais, costuma-se usar uma estrutura de grafo predefinida para refletir as dependências espaciais entre as variáveis. Para isso, define-se a matriz de adjacência A, que permite ao modelo capturar as inter-relações básicas. No entanto, em condições de volume significativo de dados ausentes, especialmente quando falta informação completa sobre uma série de variáveis, essa estrutura de grafo predefinida pode ser insuficiente. Para superar essa limitação, os autores do framework introduzem uma convolução em grafo adaptativa, que combina a estrutura predefinida e um grafo formado com base nos dados.
Como base da estrutura de grafo predefinida, utiliza-se informação sobre distâncias, por exemplo, em redes de transporte, ou o coeficiente de correlação de Pearson entre as variáveis, caso os dados não contenham informações sobre a topologia. A matriz de adjacência para a convolução em grafo, nesse caso, é calculada da seguinte forma:
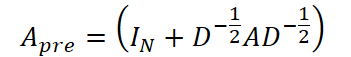
onde IN ∈ Rᴺ*ᴺ é a matriz diagonal identidade, D é a matriz de graus dos vértices do grafo, e A é a matriz de adjacência original. Essa normalização permite estabilizar a escala dos pesos durante o treinamento.
No entanto, quando parte das variáveis está ausente, ou quando suas relações são desconhecidas, torna-se necessário identificar dinamicamente as dependências espaciais. Para isso, é construído um grafo adaptativo, treinado com base nos dados. Esse processo começa com a inicialização da matriz diagonal identidade IN ∈ Rᴺ*ᴺ e com a inicialização aleatória dos embeddings das variáveis EA ∈ Rᴺ*ᵈ. Esses embeddings são atualizados ao longo do treinamento do modelo.
Após a reconstrução das variáveis com o auxílio do mecanismo IA, obtém-se o tensor de representações ocultas XᴵᴬM ∈ Rᴺ*ᴴ*ᶜ′. Em seguida, é calculada a representação atualizada das variáveis En ∈ Rᴺ*ᵈ, que combina tanto os embeddings quanto as representações temporais:
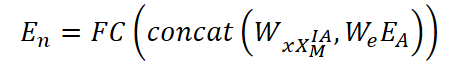
onde Wx e We são matrizes de pesos treináveis para os atributos temporais e para os embeddings, respectivamente, e concat(⋅) é a operação de concatenação ao longo do último eixo. Essa representação é usada para construir a matriz de adjacência adaptativa:
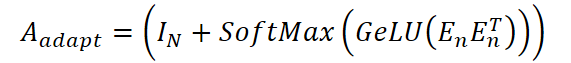
A etapa final é a agregação das informações de ambos os grafos por meio de uma convolução em grafo adaptativa, que combina dois canais: um usa a estrutura predefinida, e o outro, a estrutura adaptativa. A representação final das variáveis é calculada pela fórmula:
![]()
Essa construção garante a combinação de informações espaciais estáticas e dinâmicas, o que é especialmente importante na previsão de séries temporais multivariadas com variáveis parcialmente ausentes.
Graças à combinação de dois grafos, o modelo obtém uma estrutura robusta e adaptativa, que permite identificar com mais precisão as dependências entre as variáveis e, como consequência, melhorar a precisão da previsão de curto e médio prazo.
A ideia central da arquitetura GinAR consiste em integrar o mecanismo de atenção interpolativa (IA) e a convolução em grafo adaptativa (AGCN) em um modelo recorrente simples. Essa combinação permite não apenas reconstruir variáveis ausentes, mas também considerar de forma eficaz as dependências espaço-temporais.
Vamos examinar em detalhes a estrutura da célula GinAR e o processo passo a passo de previsão dos dados.
No nível de um único passo temporal, a célula GinAR representa o bloco computacional básico. Ela utiliza IA para reconstruir os valores iniciais ausentes e AGCN para processar as relações espaciais entre as variáveis. Na entrada, recebe-se o tensor xT, que primeiro é transformado com o auxílio do mecanismo de atenção interpolativa:
![]()
Em seguida, são calculadas as portas de esquecimento fT e de reset rT por meio da agregação de informações do grafo predefinido Apre e do grafo adaptativo Aadapt:
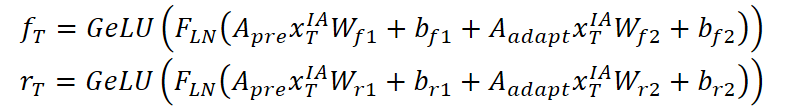
O novo estado cT é formado como uma combinação da entrada transformada atual e do estado anterior cT-1, ponderados pela porta de esquecimento:
![]()
Por fim, o estado oculto hT é calculado por meio da combinação não linear do estado atualizado da célula e da entrada:
![]()
Assim, cada célula GinAR executa um ciclo completo de atualização dos estados internos, incluindo a reconstrução dos dados e a agregação da informação espacial.
No nível global, o Encoder GinAR consiste em várias camadas GinAR. Cada camada inclui H células conectadas sequencialmente. Os dados de entrada originais X∈ Rᴺ*ᴴ*ᶜ são previamente normalizados e mascarados, formando o tensor XM ∈ Rᴺ*ᴴ*ᶜ, no qual os valores de M variáveis são zerados.
Em seguida, XM é fornecido à entrada da primeira camada GinAR, na qual cada célula é responsável pelo processamento de um passo temporal. O processo começa com a inicialização do estado c₀, após a qual x₁ e c₀ são enviados para a primeira célula, formando h¹₁ e c₁. Esses valores seguem então para a célula seguinte junto com x₂, e assim por diante. Como resultado, obtém-se a sequência de estados ocultos da primeira camada h¹ = [h¹₁, h¹₂, …, h¹H].
Esse tensor torna-se a entrada da próxima camada. O processo se repete até que todas as n camadas tenham sido percorridas. Em seguida, de cada camada é extraído o último estado oculto hHⁱ, e eles são combinados no vetor final halln.
A representação final halln é enviada ao decoder baseado em um perceptron multicamadas (MLP), que gera os valores de previsão:
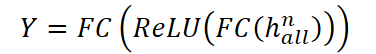
Assim, o GinAR realiza o processamento end-to-end completo de séries temporais com valores ausentes, combinando reconstrução de dados e modelagem de dependências espaço-temporais em um framework único recorrente-convolucional.
A visualização do framework GinAR apresentada pelos autores é mostrada abaixo.

Implementação com MQL5
Após analisar os aspectos teóricos do framework GinAR, passamos à parte prática, na qual demonstraremos uma das opções de implementação das abordagens descritas, propostas pelos autores do framework, com os recursos do MQL5.
No entanto, antes de começar a construir o algoritmo principal, é necessário realizar um pequeno trabalho preparatório. Como se pode ver pela descrição do GinAR apresentada acima, no algoritmo original a normalização dos dados é aplicada repetidamente com o uso da função SoftMax. Por isso, decidimos implementá-la como uma função separada no lado do programa OpenCL, garantindo assim flexibilidade e alto desempenho no trabalho com dados multidimensionais.
Trabalho preparatório
Para uma melhor organização, dividimos a implementação do algoritmo em blocos funcionais separados. Vamos começar pelo primeiro: a busca do valor máximo entre os fluxos do grupo de trabalho. Essa tarefa é executada pela função LocalMax.
A função LocalMax recebe dois parâmetros: o valor calculado na thread atual e o número da dimensão no espaço de tarefas (loc), segundo o qual as threads são agrupadas em grupos de trabalho.
#define BarrierLoc barrier(CLK_LOCAL_MEM_FENCE) float LocalMax(const float value, const int loc) { const size_t id = get_local_id(loc); const size_t total = get_local_size(loc); //--- __local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total, (uint)LOCAL_ARRAY_SIZE);
Na primeira etapa, são determinados o identificador da thread no grupo local e o tamanho total do grupo de trabalho. Em seguida, é criado o array Temp, alocado na memória local do dispositivo, que será usado para trocar valores intermediários entre as threads de um mesmo grupo de trabalho.
Depois disso, começa a iteração por todos os subgrupos formados dentro do grupo de trabalho, com o objetivo de encontrar os máximos locais. Os valores são gravados nos elementos do array Temp.
//--- Look Max for(int d = 0; d < total; d += ls) { if(id >= d && id < (d + ls) && (d == 0 || Temp[id - d] < value)) Temp[id - d] = IsNaNOrInf(value, MIN_VALUE); BarrierLoc; }
Em seguida, é iniciado o processo iterativo de redução () do array Temp até um único valor, o maior entre todos os elementos.
int count = ls; do { count = (count + 1) / 2; if(id < count && (id + count) < ls && Temp[id] < Temp[id + count]) Temp[id] = Temp[id + count]; BarrierLoc; } while(count > 1); //--- return IsNaNOrInf(Temp[0], MIN_VALUE); }
O resultado das operações é retornado ao programa chamador.
De forma análoga à função anterior, LocalMax, criamos mais um bloco básico de construção, a função de soma dos elementos dentro do grupo de trabalho local. Essa tarefa é executada pela função LocalSum, construída segundo o mesmo princípio de LocalMax, mas com a operação de soma em vez da busca do valor máximo.
float LocalSum(const float value, const int loc) { const size_t id = get_local_id(loc); const size_t total = get_local_size(loc); //--- __local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total, (uint)LOCAL_ARRAY_SIZE);
Na etapa inicial, como antes, são determinados o identificador da thread e o tamanho do grupo de trabalho. Também é criado o array local Temp, no qual serão armazenadas as somas intermediárias.
Em seguida, ocorre a iteração por todas as threads do grupo local, com o acúmulo dos valores intermediários. Observe o uso da condição d == 0, que permite inicializar corretamente o array Temp na primeira iteração.
//--- Sum float result = IsNaNOrInf(value, 0); for(int d = 0; d < total; d += ls) { if(id >= d && id < (d + ls)) Temp[id - d] = (d == 0 ? result : Temp[id - d] + result); BarrierLoc; }
Depois disso, é realizada a redução que já nos é familiar, com a divisão sucessiva por dois do número de elementos. Aqui, em vez de comparação, ocorre a simples soma dos elementos do array Temp.
int count = ls; do { count = (count + 1) / 2; if(id < count && (id + count) < ls) Temp[id] += Temp[id + count]; BarrierLoc; } while(count > 1); result = IsNaNOrInf(Temp[0], 0); //--- return result; }
O valor final, isto é, a soma de todos os elementos do grupo de trabalho, é retornado ao programa chamador.
Na etapa final do trabalho preparatório, combinaremos as funções auxiliares já implementadas, LocalMax e LocalSum em um único algoritmo, a função LocalSoftMax, que executa a normalização numericamente estável dos valores dentro do grupo de trabalho.
float LocalSoftMax(const float value, const int loc) { //--- Look Max const float max = LocalMax(value, loc); BarrierLoc;
Dentro da função LocalSoftMax, primeiro é chamada a função LocalMax, que encontra o valor máximo entre todas as threads do grupo de trabalho. Isso é necessário para estabilizar os cálculos: a subtração do valor máximo de cada valor permite evitar estouros e aumentar a estabilidade numérica das operações exponenciais.
Depois disso, já levando em conta o deslocamento, calcula-se a exponencial de cada valor. O resultado dessa operação é armazenado temporariamente na variável result, após o que chamamos a função LocalSum para calcular a soma total das exponenciais dentro do grupo.
//--- SoftMax float result = IsNaNOrInf(exp(value - max), 0); const float sum = LocalSum(result, loc); result = IsNaNOrInf(result / (sum == 0 ? 1 : sum), 0); //--- return result; }
Em seguida, é feita a normalização: o valor result é dividido pela soma de todas as exponenciais. Ao mesmo tempo, também é prevista uma proteção contra divisão por zero: se a soma for igual a zero, o valor um é usado no denominador. Como etapa final, retornamos o valor normalizado.
Essa estrutura permite usar o SoftMax como um bloco de construção flexível para os próximos kernels OpenCL. Isso torna o código mais limpo, simplifica a depuração e melhora a legibilidade de toda a arquitetura, especialmente no contexto de modelos em grafos e mecanismos de atenção aplicados na implementação do GinAR com MQL5.
No entanto, para treinar o modelo, apenas a propagação para frente pelo SoftMax ainda não é suficiente. Para atualizar corretamente os pesos durante a retropropagação do erro, é necessário implementar a função correspondente de distribuição do gradiente. Essa função permite que o modelo leve em conta como a alteração do valor de entrada afetará o erro final.
Esse recurso será implementado na função LocalSoftMaxGrad, que determinará o gradiente da função SoftMax em relação ao valor de entrada. Os parâmetros de entrada são: o valor value, correspondente à saída do SoftMax; o gradiente grad, transmitido de uma camada posterior da rede; e o valor de índice da dimensão do espaço de tarefas loc, a partir do qual os grupos de trabalho são formados.
float LocalSoftMaxGrad(const float value, const float grad, const int loc) { const size_t id = get_local_id(loc); const size_t total = get_local_size(loc); //--- __local float Temp[LOCAL_ARRAY_SIZE]; const uint ls = min((uint)total, (uint)LOCAL_ARRAY_SIZE);
No início da função, determinamos o número da thread atual e o número total de threads no grupo local. Criamos um array local Temp para armazenar valores intermediários, de forma análoga ao que foi feito em LocalMax e LocalSum. A variável val representa um valor de entrada protegido contra erros.
float result = 0; float val = IsNaNOrInf(value, 0); for(uint d = 0; d < total; d += ls) { if(id >= d && id < (d + ls)) Temp[id - d] = IsNaNOrInf(val * grad, 0); BarrierLoc; for(uint l = 0; l < min(ls, (uint)(total - d)); l++) result += Temp[l] * ((float)((d + l) == id) - val); BarrierLoc; } //--- return result; }
Em seguida, iniciamos a iteração pelas subgrupos dentro de todo o grupo de trabalho. Em cada bloco, preenchemos o buffer temporário com os valores do produto val * grad e, usando a expressão clássica da derivada do SoftMax, acumulamos o resultado na variável result. A própria expressão usa a verificação lógica (d + l) == id, que garante o processamento correto dos elementos diagonais e não diagonais do jacobiano.
O resultado da função é o valor final do gradiente correspondente a esse elemento de entrada. Esse resultado é retornado ao kernel chamador, garantindo a implementação correta da propagação reversa na arquitetura do modelo.
Assim, essa função conclui a implementação do ciclo completo de processamento do SoftMax dentro do módulo OpenCL, desde o cálculo direto até a retropropagação correta do gradiente.
Interpolation Attention
Após concluir o trabalho preparatório relacionado à implementação de operações básicas, como o SoftMax e a distribuição de seu gradiente, passamos à construção do mecanismo Interpolation Attention, que desempenha um papel fundamental na arquitetura do GinAR. Na primeira etapa, nosso objetivo é implementar a propagação para frente desse algoritmo com recursos do OpenCL, garantindo processamento paralelo eficiente no lado do acelerador gráfico.
Como dados de entrada, o kernel InterpositionAttention recebe vários arrays:
- a matriz de atributos de entrada matrix_in,
- os parâmetros treináveis W e A,
- as representações latentes GL,
- as matrizes de adjacência Adj,
- as representações intermediárias H,
- os valores de atenção Atten,
- a matriz resultante matrix_out.
Além disso, é transmitida a dimensionalidade do espaço de atributos dimension.
__kernel void InterpositionAttention(__global const float* matrix_in, __global const float* W, __global const float* A, __global const float* GL, __global float* Adj, __global float* H, __global float* Atten, __global float* matrix_out, const int dimension ) { const size_t i = get_global_id(0); const size_t j = get_local_id(1); const size_t total = get_global_size(0); const size_t total_loc = get_local_size(1);
No início da execução, determinamos os índices globais e locais das threads i e j, que serão usados para percorrer os elementos nos arrays de entrada e de saída. Em seguida, calculamos os deslocamentos correspondentes para garantir o acesso correto aos subarrays dentro do buffer global.
const int shift_i = i * dimension; const int shift_j = j * dimension; const int shift_adj = i * total_loc + j;
O primeiro passo é o cálculo dos pesos de adjacência entre dois nós i e j por meio da multiplicação par a par de suas representações latentes do array GL.
float adj = 0; for(int d = 0; d < dimension; d++) adj += IsNaNOrInf(GL[shift_i + d] * GL[shift_j + d], 0); adj = max(IsNaNOrInf(adj, 0), 0); adj = LocalSoftMax(adj, 1); Adj[shift_adj] = adj; adj += (float)(i == j);
O resultado é acumulado na variável adj, normalizado com a função LocalSoftMax e armazenado na matriz de adjacência Adj. Em seguida, adiciona-se uma unidade ao valor de adj se i coincidir com j, garantindo assim a preservação do elemento diagonal.
Depois passamos à formação da representação intermediária H. Para isso, os atributos de entrada do nó atual são multiplicados gradualmente pela matriz de pesos treinável W. Cada valor é armazenado no array H, e, para sincronização entre as threads, utiliza-se a barreira BarrierLoc.
for(int id_h = 0; id_h < dimension; id_h += total_loc) { if(j >= (dimension - id_h)) break; float h = 0; for(int w = 0; w < dimension; w++) h += IsNaNOrInf(matrix_in[shift_i + w] * W[(id_h + j) * dimension + w], 0); H[shift_i + id_h + j] = h; BarrierLoc; }
Depois que H é formado, calcula-se o valor de atenção e, que determina a importância da interação entre os nós i e j. O valor é inicializado como uma pequena grandeza positiva para evitar divisão por zero. Em caso de correlação positiva entre os elementos, ocorre a acumulação de produtos escalares ponderados entre as linhas correspondentes de H e o vetor treinável A. O resultado é novamente normalizado pela função LocalSoftMax e armazenado no array Atten.
float e = 1e-12f; if(adj > 0) { e = 0; for(int a = 0; a < dimension; a++) e += IsNaNOrInf(H[shift_i + a] * A[a], 0) + IsNaNOrInf(H[shift_j + a] * A[dimension + a], 0); } e = LocalSoftMax(e, 1); Atten[shift_adj] = e;
A etapa final é a reconstrução do valor da variável analisada com base nas informações obtidas de outras variáveis observadas. O valor da variável ausente, ou reconstruída, i é agregado por soma ponderada das representações das variáveis j, sendo que as próprias representações são multiplicadas pelos respectivos valores dos coeficientes de atenção. Essa agregação permite transferir informações úteis dos vizinhos para a variável-alvo.
for(int d = 0; d < dimension; d += total_loc) { if(j >= (dimension - d)) break; float out = 0; int shift_h = d + j; int shift_att = i * total_loc; int shift_out = i * dimension + shift_h; for(int n = 0; n < total_loc; n++) out += IsNaNOrInf(H[shift_h + n * dimension] * Atten[shift_att + n], 0); matrix_out[shift_out] = Activation(out, ActFunc_LReLU); } }
Para aumentar a robustez a outliers e suavizar a influência de valores anômalos, o resultado obtido é normalizado com a função de ativação LReLU. Isso contribui para um treinamento mais estável do modelo, especialmente em condições de amostras instáveis ou ruidosas.
Essa etapa conclui a propagação para frente do Interpolation Attention e forma a representação final da variável i, levando em conta tanto as conexões internas entre as variáveis quanto os parâmetros de correlação aprendidos.
Assim, o kernel OpenCL descrito implementa a propagação para frente do Interpolation Attention, utilizando de forma eficiente o paralelismo para processar elementos da estrutura em grafo. Ele garante a construção de um modelo adaptativo de interação entre os elementos da série temporal com base em atributos latentes, o que permite considerar o contexto e adaptar-se de forma flexível à estrutura dos dados.
A próxima etapa do nosso trabalho é a implementação do algoritmo de propagação reversa do Interpolation Attention, que também estruturaremos na forma de um kernel OpenCL. Nessa função, são calculados os gradientes para todos os parâmetros e dados de entrada que participam da propagação para frente.
A ideia central do código é, para cada elemento, calcular as derivadas parciais do erro em relação às variáveis intermediárias: os atributos ocultos H, os coeficientes de atenção Atten, as matrizes de entrada, os pesos e a matriz de atributos GL.
__kernel void InterpositionAttentionGrad(__global const float* matrix_in, __global float* matrix_in_gr, __global const float* W, __global float* W_gr, __global const float* A, __global float* A_gr, __global const float* GL, __global float* GL_gr, __global float* Adj, __global float* H, __global float* H_gr, __global float* Atten, __global float* matrix_out_gr, const int dimension ) { const size_t i = get_global_id(0); const size_t j = get_local_id(1); const size_t total = get_global_size(0); const size_t total_loc = get_local_size(1);
Dentro do kernel, para cada thread, identificada pelos índices i e j, é realizado o cálculo sequencial:
- Os gradientes em relação aos atributos ocultos Hgrad são calculados com base nos gradientes da saída e nos pesos de atenção, levando em conta a função de ativação LeakyReLU.
const int shift_i = i * dimension; const int shift_j = j * dimension; const int shift_adj = i * total_loc + j; //--- H Gradient for(int d = 0; d < dimension; d += total_loc) { if(j >= (dimension - d)) break; float h_grad = 0; int shift_h = shift_i + d + j; int shift_att = i; int shift_out = d + j; for(int n = 0; n < total_loc; n++) { float gr = matrix_out_gr[shift_out + n * dimension]; h_grad += IsNaNOrInf( Deactivation(gr, gr, ActFunc_LReLU) * Atten[shift_att + n * total_loc], 0); } H_gr[shift_h] = h_grad; BarrierLoc; }
- Em seguida, é calculado o gradiente em relação aos coeficientes de atenção Attgrad, que passa pela função reversa do SoftMax para a correta propagação dos erros na distribuição de atenção.
//--- Attention Gradient float att_grad = 0; for(int d = 0; d < dimension; d++) { float gr = matrix_out_gr[shift_i + d]; gr = Deactivation(gr, gr, ActFunc_LReLU); att_grad += IsNaNOrInf(gr * H[shift_j + d], 0) } att_grad = LocalSoftMaxGrad(Atten[shift_adj], att_grad, 1);
- Esse gradiente é então usado para atualizar os gradientes em relação aos atributos ocultos H, levando em conta os pesos da matriz A, bem como para acumular os gradientes da própria matriz A.
for(int d = 0; d < dimension; d++) { float h_grad = att_grad * A[d]; h_grad = LocalSum(h_grad, 1); if(j == 0) H_gr[shift_i + d] += h_grad; h_grad = att_grad * A[dimension + d]; h_grad = LocalSum(h_grad, 1); if(j == 0) H_gr[shift_j + d] += h_grad; float a_grad = att_grad * H[shift_i + d]; a_grad = LocalSum(a_grad, 1); A_gr[d] += a_grad; a_grad = att_grad * H[shift_j + d]; a_grad = LocalSum(a_grad, 1); A_gr[dimension + d] += a_grad; }
- Os gradientes em relação aos atributos de entrada são obtidos usando os gradientes dos atributos ocultos e as matrizes de pesos W, o que permite atualizar corretamente os dados de entrada durante o treinamento.
//--- Inputs' Gradient for(int d = 0; d < dimension; d += total_loc) { if(j >= (dimension - id_h)) break; float grad = 0; for(int w = 0; w < dimension; w++) grad += IsNaNOrInf(H_gr[shift_i + w] * W[(id_h + j) + dimension * w], 0); matrix_in_gr[shift_i + d + j] = grad; BarrierLoc; }
- Por fim, os gradientes em relação à matriz adaptativa GL são calculados por meio do SoftMax reverso pela adjacência e acumulados para ambas as variáveis i e j.
//--- Adj Gradient float grad = LocalSoftMaxGrad(Adj[shift_adj], att_grad, 1); for(int d = 0; d < dimension; d++) { GL_gr[shift_i + d] += IsNaNOrInf(grad * GL[shift_j + d], 0); GL_gr[shift_j + d] += IsNaNOrInf(grad * GL[shift_i + d], 0); } }
A estrutura geral da função é construída com o uso de sincronização local das threads (BarrierLoc), o que garante a correção da troca de dados entre elas e evita condições de corrida.
Essa abordagem garante uma atualização precisa e estável de todos os parâmetros do modelo durante o treinamento, permitindo ajustar os pesos com eficiência e aumentar a qualidade da reconstrução de valores ausentes em séries temporais multivariadas.
Nesta etapa, concluímos a implementação dos componentes-chave no lado do programa OpenCL. O próximo passo lógico será organizar todo o processo no programa principal: integração, controle dos cálculos e treinamento do modelo com recursos do MQL5. No entanto, o volume do material já aumentou consideravelmente e, para preservar a clareza e a qualidade da exposição, proponho fazer uma pausa.
Continuaremos esse importante trabalho no próximo artigo, em que analisaremos em detalhes a implementação prática do algoritmo em MQL5, as particularidades da interação com o OpenCL e a otimização de desempenho. Assim, poderemos nos concentrar em cada etapa sem pressa, preservando a profundidade e a completude da abordagem do tema.
Considerações finais
Para concluir, pode-se destacar que o framework GinAR apresentado demonstra uma abordagem poderosa para a previsão de séries temporais multivariadas com valores ausentes. A integração da atenção interpolativa e da convolução em grafo adaptativa em uma arquitetura recorrente permite reconstruir com eficiência os dados ausentes e considerar dependências espaço-temporais complexas.
A implementação prática dos componentes-chave em OpenCL, apresentada no artigo, abre amplas possibilidades para posterior otimização e adoção em sistemas de trading reais.
O trabalho futuro será dedicado à integração desses desenvolvimentos ao programa principal em MQL5, o que permitirá revelar todo o potencial dos métodos propostos. Convido os leitores a continuar explorando o tema no próximo artigo.
Links
- GinAR: An End-To-End Multivariate Time Series Forecasting Model Suitable for Variable Missing
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline dos modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online dos modelos |
| 3 | Test.mq5 | Expert Advisor | EA para testar o modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programas OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18854
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso