
Redes neurais em trading: Previsão probabilística de séries temporais (Conclusão)

Introdução
As séries temporais financeiras continuam sendo um dos tipos de dados mais difíceis de serem analisados. Seu comportamento não pode ser chamado de estável, pois não apresentam regularidades bem definidas, mas uma combinação de tendências, ciclos, ruído e mudanças estruturais inesperadas. Por esse motivo, os modelos tradicionais de regressão linear ou de médias móveis, apesar de simples e rápidos, na maioria dos casos são insuficientes. Por outro lado, as soluções modernas baseadas em redes neurais, com seu enorme poder de representação, frequentemente sofrem com overfitting, instabilidade e falta de interpretabilidade.
Nessas condições, tornam-se especialmente interessantes as abordagens híbridas, que combinam construções matemáticas já consagradas com a flexibilidade das redes neurais. É justamente sobre esse equilíbrio que se baseia o framework K²VAE, um sistema criado para análise e previsão de séries temporais, levando em conta suas particularidades reais. A principal vantagem desse framework é a capacidade de captar a dinâmica oculta do sistema, aprendendo com sequências de estados de mercado e ajustando suas inferências à medida que novos dados chegam.
O framework se baseia em três ideias fundamentais, cada uma complementando a outra e compensando seus pontos fracos. A primeira é a representação de Koopman, cuja essência consiste em transferir o comportamento de um sistema não linear para um subespaço linear. Essa transformação, ainda que aproximada, fornece uma ferramenta poderosa para descrição e previsão, permitindo trabalhar com séries temporais não no nível de estatísticas superficiais, mas por meio da reconstrução da dinâmica profunda.
A segunda ideia é o uso do filtro de Kalman, mas não em sua forma canônica, e sim em uma versão estabilizada, adequada para aplicação em arquiteturas neurais estocásticas. Aqui, o filtro de Kalman cumpre a função de corretor adaptativo: ele refina as estimativas obtidas do módulo KoopmanNet com base em novas observações e, ao mesmo tempo, fornece informações sobre o grau de confiança em cada previsão. Isso é especialmente valioso quando se trata não apenas de prever preços, mas também de estimar a probabilidade de determinados cenários.
A terceira ideia é a integração de um autoencoder variacional. Ele permite construir previsões não pontuais, mas probabilísticas: em vez de um único cenário possível, obtemos toda uma distribuição, na qual se refletem tanto a tendência principal quanto os possíveis desvios.
Assim, o K²VAE deixa de ser apenas mais um modelo no arsenal de análise e passa a ser um sistema capaz de descrever quantitativamente a incerteza, considerar cenários alternativos e se adaptar a novas condições de mercado.

Em trabalhos anteriores, já examinamos detalhadamente os principais componentes desse framework. Foi descrito como a KoopmanNet funciona, como a representação latente é formada, de que maneira o filtro de Kalman é integrado à arquitetura e como ocorre o treinamento conjunto de todos os elementos. Foi dada atenção especial à estabilidade dos cálculos e à mecânica da propagação de informação dentro do modelo.
Arquitetura do modelo
Após a construção gradual dos componentes individuais que compõem a base arquitetural do framework K²VAE, passamos à próxima etapa lógica: a integração de todos os elementos em um único sistema funcional.
Cabe destacar que, assim como nos trabalhos anteriores, nosso objetivo não é construir um modelo preditivo em sua forma clássica e isolada. Aqui, a previsão é apenas um subproduto, secundário em relação a uma tarefa mais fundamental: criar uma representação latente expressiva e estável do estado atual do ambiente. Essa representação não apenas generaliza as informações recebidas, mas também serve como entrada-chave para a tomada de decisão de trading por parte do Agente em treinamento.
Assim, consideramos o framework K²VAE não como um modelo de previsão autônomo, mas como um Encoder avançado do estado do ambiente, incorporado à arquitetura previamente implementada com base na abordagem Actor-Director-Critic. Aqui, o componente VAE se torna um mecanismo de geração de uma descrição probabilística de cenários futuros, a KoopmanNet responde pela dinâmica linear no espaço latente, e o filtro de Kalman realiza a correção e o refinamento com base nas observações recebidas. Tudo isso trabalha para um único objetivo: fornecer ao Agente uma representação do ambiente externo que contenha o máximo de informações úteis para a tomada de decisões de trading ponderadas e estatisticamente fundamentadas.
A incorporação dos componentes do K²VAE à arquitetura Actor-Director-Critic permite conferir ao sistema a profundidade e a robustez necessárias. Graças a isso, o estado latente produzido pelo Encoder carrega informações não apenas sobre a situação atual, mas também sobre as possíveis trajetórias de sua evolução. Isso melhora qualitativamente o comportamento do Agente: ele não apenas reage aos sinais atuais, mas atua levando em conta possíveis cenários de desenvolvimento, o que é especialmente importante em condições de alta volatilidade e imprevisibilidade do mercado.
É aqui que entra em cena o método CreateDescriptions. É ele o responsável pela montagem de todas as descrições arquiteturais, do Encoder e dos módulos de previsão aos componentes de tomada de decisão. Esse método cria a base para o treinamento futuro, definindo quais camadas e em que ordem serão utilizadas dentro de cada componente do nosso sistema.
bool CreateDescriptions(CArrayObj *&encoder, CArrayObj *&forecast1, CArrayObj *&forecast2, CArrayObj *&forecast3, CArrayObj *&actor, CArrayObj *&director, CArrayObj *&critic ) { //--- CLayerDescription *descr; //--- if(!encoder) { encoder = new CArrayObj(); if(!encoder) return false; } if(!forecast1) { forecast1 = new CArrayObj(); if(!forecast1) return false; } if(!forecast2) { forecast2 = new CArrayObj(); if(!forecast2) return false; } if(!forecast3) { forecast3 = new CArrayObj(); if(!forecast3) return false; } if(!actor) { actor = new CArrayObj(); if(!actor) return false; } if(!director) { director = new CArrayObj(); if(!director) return false; } if(!critic) { critic = new CArrayObj(); if(!critic) return false; }
Nos parâmetros do método, recebemos ponteiros para uma série de arrays dinâmicos, um para cada modelo. Esses são os contêineres nos quais será registrada a descrição arquitetural dos blocos de rede neural. Antes de passar ao seu preenchimento, realizamos uma verificação obrigatória da validade dos ponteiros recebidos. Na ausência do objeto necessário, não tentamos trabalhar com memória pendente, mas criamos cuidadosamente uma nova instância do array. Esse passo pode parecer uma rotina técnica, mas, na prática, é justamente ele que estabelece a estabilidade de todo o trabalho posterior.
Depois disso, começa a parte principal: o preenchimento de cada array com as respectivas camadas e conexões, formando a configuração completa da rede neural. Comecemos pelo elemento central do sistema, o Encoder do estado do ambiente. É justamente nesse componente que integramos as principais ideias incorporadas ao framework K²VAE. Lembremos que a tarefa do Encoder não é apenas reunir informações sobre a situação do mercado, mas criar uma representação latente expressiva e informativa, capaz de servir como base confiável para a tomada de decisões de trading pelo Agente.
Os dados brutos de entrada, recebidos diretamente do terminal, são encaminhados para uma camada totalmente conectada. Aqui, ela cumpre o papel de interface entre o mundo externo e a lógica interna do modelo.
//--- Encoder encoder.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; uint prev_count = descr.count = (HistoryBars * BarDescr); descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormWithNoise; descr.count = prev_count; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, os dados são enviados para a etapa de processamento inicial, a camada de normalização em lote. É nesse ponto que características de entrada heterogêneas, que diferem em escala, faixa de valores ou significado físico, são colocadas em uma forma comparável. Esse passo é importante não apenas do ponto de vista da estabilidade numérica, mas também sob a ótica do treinamento de todo o modelo: dados normalizados permitem que a rede neural converja mais rapidamente e capte com mais precisão as dependências entre as características.
A normalização em lote, nesse contexto, atua como um filtro que suaviza o ruído estatístico e equaliza as distribuições dos componentes individuais do sinal de entrada. Isso cria um ambiente estável e previsível para as transformações posteriores, minimizando distorções no estágio inicial do processamento.
Após a normalização, os dados estão prontos para a próxima etapa importante: a separação espacial, ou patching. Os autores do framework K²VAE original propõem dividir os dados de entrada preparados em patches não sobrepostos, cada um dos quais representa um fragmento do fluxo geral de informações. Ao mesmo tempo, os valores de diferentes canais são misturados dentro de um mesmo patch, o que permite ao modelo aprender naturalmente a identificar dependências cruzadas entre as características.
No entanto, em nossa implementação, fomos além e decidimos não nos limitar ao esquema padrão de patching, mas introduzimos uma estrutura mais complexa, inspirada em várias arquiteturas modernas, anteriormente analisadas em nossos artigos. Primeiro, enriquecemos adicionalmente o array de características de entrada, adicionando derivadas que refletem as variações passo a passo dos valores de cada canal. Isso permite considerar a dinâmica de curto prazo dos sinais e aumentar a sensibilidade do modelo às mudanças na estrutura do mercado, preservando ao mesmo tempo a robustez ao ruído.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConcatDiff; prev_count = descr.count = HistoryBars; descr.layers = BarDescr; descr.step = 1; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, marcas temporais são adicionadas aos dados, um elemento importante que permite ao modelo considerar não apenas os valores das características, mas também sua posição no tempo. Essas marcas fornecem à rede neural o contexto do momento real em que o evento ocorre, seja minuto, hora, dia da semana ou outra escala. Graças a isso, o modelo passa a ter a capacidade de identificar padrões recorrentes e oscilações sazonais característicos das séries temporais financeiras. A introdução dessa informação temporal é especialmente importante ao trabalhar com cotações históricas, nas quais a ciclicidade desempenha um papel fundamental na formação de estratégias de trading.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defMamba4CastEmbeding; prev_count = descr.count = HistoryBars; descr.window = 2 * BarDescr; uint prev_out = descr.window_out = NSkills; { uint temp[] = {PeriodSeconds(PERIOD_H1), PeriodSeconds(PERIOD_D1)}; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeOCL; descr.count = prev_count; prev_count = descr.window = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_out = descr.count;
Aqui vale destacar especialmente um ponto importante: diferentes canais de informação de entrada podem apresentar ritmos internos distintos, isto é, exibir ciclos com períodos diferentes. Nessas condições, a simples união mecânica dos valores de todos os canais em um único fluxo pode neutralizar dependências sazonais ocultas e distorcer a dinâmica dos sinais.
Para evitar a perda dessas características, implementamos um mecanismo de convolução adaptativa. Sua tarefa é analisar o comportamento de cada sequência temporal e formar os patches levando em conta as particularidades individuais de cada canal. Dessa forma, cada canal recebe a mesma quantidade de representações no espaço latente e, ao mesmo tempo, preserva-se a sensibilidade à sua ciclicidade específica.
//--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronAdaptConv; descr.count = Segments; descr.window = 2 * prev_out / Segments; descr.variables = prev_count; prev_out = descr.window_out = EmbeddingSize; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; } prev_count = descr.count; uint prev_var = descr.variables;
Aos patches formados, adicionamos a codificação RoPE (Rotary Positional Encoding), que confere ao modelo a noção da posição relativa de cada elemento na sequência temporal. Diferentemente das codificações posicionais clássicas, o RoPE incorpora a informação de posição por meio da rotação do vetor de características no espaço latente. Isso permite preservar a estrutura temporal dos dados durante o processamento posterior pelas camadas do transformer, além de transmitir com eficiência a informação sobre as distâncias entre os eventos. Essa abordagem é especialmente importante em tarefas de análise de séries temporais, nas quais a ordem e o intervalo entre os eventos desempenham um papel crítico.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronRoPE; descr.count = prev_count; descr.window = prev_out; descr.variables = prev_var; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Em seguida, transpomos para o formato de sequência temporal de patches mistos o tensor tridimensional obtido, que representa os patches de canais independentes. Essa transformação permite passar de uma estrutura do tipo [Canais × Patches × Características] para uma forma mais adequada ao processamento sequencial do modelo, [Patches × Canais × Características], em que cada patch passa a representar um recorte temporal contendo, simultaneamente, dados de todos os canais. Assim, preparamos os dados para o processamento posterior no encoder K²VAE, direcionando a atenção do modelo para as inter-relações entre as características dentro de um fluxo temporal comum.
//--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTransposeRCDOCL; descr.count = prev_var; descr.window = prev_count; descr.step = prev_out; descr.batch = BatchSize; descr.optimization = ADAM; descr.activation = None; if(!encoder.Add(descr)) { delete descr; return false; }
Essa forma de representação dos dados está totalmente alinhada às ideias centrais propostas pelos autores do framework K²VAE, em particular a busca pela integração de informações heterogêneas em um espaço latente unificado. No entanto, ao contrário da implementação básica, preservamos propriedades importantes da estrutura das séries temporais, em especial a ciclicidade de canais individuais, um aspecto crítico para dados financeiros. Além disso, por meio do patching expandido, dos desvios passo a passo e das marcas temporais, enriquecemos a representação de entrada, ampliando a capacidade do modelo de reconhecer padrões estáveis e dependências sazonais, sem perder as nuances das fontes de dados individuais.
Os patches formados, contendo informações enriquecidas e estruturadas sobre o estado atual do ambiente, são encaminhados ao encoder K²VAE. Nessa etapa, ocorre a codificação probabilística: cada sequência de entrada é transformada em uma distribuição de embeddings na saída do bloco. Cada embedding individual dessa distribuição representa uma descrição compacta, porém expressiva, de um dos possíveis cenários de evolução da série temporal analisada. Assim, o modelo forma não apenas uma estimativa pontual do estado futuro, mas um conjunto de hipóteses probabilísticas que reflete a diversidade de trajetórias potenciais. Isso é especialmente importante em condições de alta incerteza, características dos mercados financeiros.
//--- layer 8 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronK2VAEEncoder; { uint temp[] = {prev_count, // units in NScenarios, // Scenarios NExperts, // MoE TopK // Top K }; if(ArrayCopy(descr.units, temp) < int(temp.Size())) return false; } descr.step = NHeads; { uint temp[] = {prev_out * prev_var, // window prev_out * prev_var / descr.step, // dimension Key 2 * prev_out*prev_var / NExperts // dimension MoE }; if(ArrayCopy(descr.windows, temp) < int(temp.Size())) return false; } descr.layers = 3; descr.variables = 1; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }
Aqui, cabe observar que será justamente a distribuição no espaço latente, obtida na saída do encoder K²VAE, que será transmitida ao Agente para a posterior tomada de decisão de trading. No entanto, para garantir a expressividade e o valor prático desse estado latente, isto é, sua capacidade de conter informações sobre os cenários mais prováveis do comportamento futuro da série temporal, precisamos estruturar um fluxo completo de previsão dentro do modelo.
Como já foi observado anteriormente, o objetivo do nosso framework não é criar uma previsão exata em seu sentido clássico. Ainda assim, precisamos estruturar o fluxo de treinamento de modo que o gradiente de erro possa se propagar do resultado final de volta a cada elemento da distribuição probabilística de embeddings. Para isso, adicionamos a camada especializada TimeMoEAttention.
Essa camada desempenha uma função importante: ela agrega os embeddings probabilísticos, formando a partir deles uma representação unificada e, com isso, cria a aparência funcional necessária de um modelo de previsão tradicional. Essa solução nos permite conciliar a natureza probabilística do espaço latente com as exigências de treinabilidade e otimização, garantindo o treinamento completo da distribuição com base no resultado final.
//--- layer 9 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronTimeMoEAttention; descr.window_out = EmbeddingSize; { uint temp[] = {prev_out, prev_out, 8, TopK}; //Window Main, Window Cross, Experts dimension, TopK if(ArrayCopy(descr.windows, temp) < ArraySize(temp)) return false; } { uint temp[] = {prev_var, prev_var * NScenarios, NExperts}; //Units Main, Units Cross, Experts if(ArrayCopy(descr.units, temp) < ArraySize(temp)) return false; } descr.layers = 3; descr.step = NHeads; // Attention heads descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!encoder.Add(descr)) { delete descr; return false; }//--- CLayerDescription *latent = descr;
Em seguida, passamos à definição da arquitetura de três modelos clássicos de previsão, cada um responsável por prever em seu próprio horizonte de planejamento: curto, médio e longo prazo. Esses modelos desempenham um papel importante: eles desdobram a representação latente obtida no encoder de volta ao espaço dos dados observáveis. Dessa forma, cada estado passa a ter uma interpretação em termos de grandezas reais, refletindo possíveis cenários do comportamento futuro da série temporal.
Cabe destacar que as arquiteturas desses modelos de previsão foram examinadas detalhadamente em nossos trabalhos anteriores. Elas demonstraram sua eficácia na prática e, justamente por isso, foram incorporadas diretamente, sem alterações. No contexto deste artigo, não vamos nos aprofundar nos detalhes técnicos de sua construção.
O próximo passo lógico é a construção da arquitetura do trading Actor, elemento central do sistema de tomada de decisões. Sua tarefa é escolher a melhor ação de trading com base nas informações disponíveis. Diferentemente dos modelos preditivos clássicos, o Actor não tenta prever diretamente o comportamento futuro do mercado, mas utiliza a descrição probabilística dos cenários possíveis, fornecida pelo encoder, para avaliar a eficácia potencial de cada uma das ações possíveis.
O modelo do Actor recebe na entrada duas fontes de informação. A primeira é o estado atual da conta, incluindo posições ativas, capital e outras informações auxiliares. A segunda é a distribuição de representações latentes obtida a partir do encoder K²VAE, em que cada representação descreve uma das possíveis variantes de evolução da situação de mercado no futuro. Essa distribuição não apenas carrega informações sobre as trajetórias mais prováveis, mas também transmite o nível de incerteza do modelo em relação a esses cenários.
Para a primeira, como antes, utilizamos uma camada totalmente conectada, que desempenha o papel de interface externa do modelo. É justamente por meio dela que o Actor recebe, na entrada, as informações sobre o estado da conta.
//--- Actor latent = encoder.At(LatentLayer); actor.Clear(); //--- Input layer if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = AccountDescr; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 1 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBatchNormOCL; descr.count = AccountDescr; descr.batch = BatchSize; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Os dados recebidos na entrada são colocados em uma forma comparável com o auxílio da camada de normalização em lote. Isso permite eliminar diferenças de escala entre as características e garantir o funcionamento estável das camadas subsequentes do modelo, independentemente das magnitudes originais e da natureza dos dados.
Depois que os dados sobre o estado da conta são colocados em uma forma comparável, eles são enviados ao módulo de atenção cruzada, que analisa essas informações no contexto da distribuição probabilística dos estados futuros do ambiente.
Aqui é importante destacar uma diferença fundamental em relação aos modelos clássicos: o Actor não apenas reage à situação atual, mas avalia os riscos da tomada de decisão levando em conta a largura e a forma da distribuição dos cenários futuros. Quanto maior a confiança do encoder na previsão, o que se expressa em uma distribuição mais estreita e concentrada, menor é a dispersão de cenários recebida pelo Actor. Nesse caso, ele pode agir de maneira mais decisiva, por exemplo, aumentando o volume da posição ou utilizando parâmetros de operação mais agressivos. Dessa forma, a estratégia se ajusta de maneira adaptativa ao grau variável de incerteza do mercado.
//--- layer 2 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronCrossDMHAttention; { uint temp[] = {AccountDescr, // Inputs window latent.windows[0] // Cross window }; if(ArrayCopy(descr.windows, temp) < (int)temp.Size()) return false; } { uint temp[] = {1, // Inputs units latent.units[1] // Cross units }; if(ArrayCopy(descr.units, temp) < (int)temp.Size()) return false; } descr.step = NHeads; // Heads descr.window_out = 8; descr.batch = 1e4; descr.layers = 2; descr.activation = None; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Em seguida, a informação processada é enviada a uma rede neural totalmente conectada de três camadas, MLP, que conclui a cadeia de processamento e forma a decisão final de trading. É justamente nessa etapa que ocorre a integração de todas as características: o estado atual da conta, a representação probabilística do futuro e o contexto identificado com o auxílio do mecanismo de atenção. O modelo analisa o conjunto desses fatores e determina a direção da operação e seus parâmetros. Essa estrutura, apesar da aparente simplicidade, desempenha um papel decisivo para garantir a flexibilidade e a adaptabilidade de todo o sistema de trading.
//--- layer 3 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.batch = BatchSize; descr.activation = TANH; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 4 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = LatentCount; descr.activation = TANH; descr.batch = BatchSize; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 5 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronBaseOCL; descr.count = 2 * NActions; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
Na saída do Actor, é utilizada uma cabeça estocástica de geração da decisão de trading, implementada por meio da camada CNeuronVAEOCL.
//--- layer 6 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronVAEOCL; descr.count = NActions; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; } //--- layer 7 if(!(descr = new CLayerDescription())) return false; descr.type = defNeuronConvOCL; descr.count = NActions / 3; descr.window = 3; descr.step = 3; descr.window_out = 3; descr.activation = SIGMOID; descr.optimization = ADAM; if(!actor.Add(descr)) { delete descr; return false; }
À primeira vista, essa solução pode parecer excessivamente arriscada: a combinação da distribuição probabilística dos cenários futuros com a própria natureza probabilística da cabeça do Actor realmente aumenta a parcela de aleatoriedade no processo de tomada de decisão. E, no contexto das condições reais de mercado, isso gera preocupações justificáveis.
No entanto, a essência da abordagem está no fato de que a natureza estocástica do Actor se manifesta plenamente apenas nos estágios iniciais do treinamento do modelo. Nesse período, o Actor explora ativamente possíveis variantes de comportamento, aprendendo com um amplo espectro de reações do ambiente. À medida que acumula experiência e reavalia os resultados obtidos, a distribuição das saídas se torna cada vez mais concentrada em torno das melhores estratégias, e a dispersão diminui. Como resultado, o comportamento do Actor se estabiliza, adquirindo a direção e o foco necessários para uma tomada de decisão confiante em condições reais de mercado.
Os modelos de avaliação do Director e do Critic, em grande medida, repetem a arquitetura do Actor, preservando a estrutura geral e os princípios de processamento dos dados. A principal diferença está na fonte do fluxo principal de dados de entrada: em vez do estado da conta, eles recebem como entrada o tensor de ações gerado pelo Actor. Isso lhes permite avaliar cada ação de forma mais objetiva e detalhada.
Ao mesmo tempo, a cabeça estocástica de tomada de decisão, característica do Actor, está ausente aqui. Em vez de uma distribuição probabilística de ações, o Director e o Critic formam avaliações concretas e sinais de qualidade para cada ação. Esse feedback detalhado ajuda o Actor a refinar suas estratégias e aumentar a eficácia das decisões de trading.
O código-fonte completo que descreve a solução arquitetural de todos os modelos é apresentado no anexo.
Treinamento
Após a conclusão da etapa de construção da arquitetura de todos os componentes do modelo, passamos ao próximo passo, o treinamento. Como nos trabalhos anteriores, o treinamento é organizado em duas etapas. Na primeira etapa, realizamos o treinamento offline com dados históricos disponíveis diretamente no terminal. A particularidade da abordagem está no fato de que o treinamento é realizado sem a necessidade de um conjunto de treinamento previamente preparado. Em vez disso, incorporamos à própria rotina de treinamento um mecanismo de avaliação de ações. Com isso, amplia-se significativamente a cobertura dos dados históricos disponíveis para a etapa inicial de treinamento e elimina-se a limitação associada à rotulagem manual ou à formação de datasets especializados.
Aqui vale prestar atenção especial a um ponto importante, identificado ao longo dos experimentos anteriores. Ao usar o modelo de avaliação das ações do Actor em um horizonte limitado de estados previstos, observa-se um comportamento negativo persistente. O modelo tende a formar níveis excessivamente ambiciosos de stop loss e take profit, que não chegam a se concretizar dentro da janela de avaliação definida. Isso leva à manutenção prolongada de posições no prejuízo, quando posições perdedoras são mantidas por tempo demais, sem fundamento suficiente para uma reversão ou saída do mercado. Esse comportamento se torna dominante, e o modelo efetivamente perde a capacidade de reagir a mudanças de curto prazo no mercado, reduzindo a estratégia a um acompanhamento passivo da tendência global.
Para combater esse efeito, foram introduzidas duas mudanças principais na rotina de treinamento. Primeiro, reduzimos significativamente o fator de desconto (Discount Factor), deslocando a ênfase para a obtenção de lucro mais rápido. Essa decisão permite que o modelo se concentre nos resultados mais imediatos de suas ações, atribuindo maior peso às consequências de curto prazo. Afinal, dentro dessa abordagem, os prejuízos atuais passam a exercer influência mais significativa sobre a recompensa final do que um lucro potencial em um futuro distante, mesmo que este último pareça mais expressivo. Dessa forma, o modelo passa a evitar estratégias baseadas na espera passiva por uma reversão do mercado e reduz a propensão à manutenção indesejada de posições no prejuízo, aumentando sua adaptabilidade à dinâmica real do mercado.
A segunda solução, já de natureza construtiva, foi implementada no método CheckAction. Aqui, abandonamos a avaliação das ações dentro de um horizonte limitado de previsão e passamos a uma abordagem em que a avaliação é realizada em todo o intervalo histórico disponível. Esse passo permite aumentar significativamente a precisão do feedback, pois, na grande maioria dos casos, sabemos exatamente qual dos níveis de trading, stop loss ou take profit, será alcançado dentro desse histórico expandido. Isso, por sua vez, fornece uma avaliação mais objetiva de cada ação e permite que o sistema de treinamento diferencie com mais clareza decisões eficazes e ineficazes.
double CheckAction(CBufferFloat *action, double equity, uint start_position) { if(!action || start_position >= Rates.Size()) return 0;
Nos parâmetros do método, recebemos:
- action, o tensor da ação de trading: volumes, níveis de SL/TP;
- equity, o estado atual da equity, usado para avaliar o drawdown máximo;
- start_position, o índice do estado de abertura da posição no array de dados de mercado Rates.
O método começa com a verificação da validade do ponteiro para o objeto action e do índice da posição inicial, que não deve ultrapassar os limites do array de cotações.
Em seguida, ocorre a extração dos parâmetros da operação.
double buy_lot = MathMax(double(action[0] - action[3]), 0); double sell_lot = MathMax(double(action[3] - action[0]), 0);
Dessa forma, o sistema suporta o fornecimento separado do volume por direção. Por exemplo, se action[0] > action[3], assume-se a abertura de uma posição buy; caso contrário, uma posição sell.
Em seguida, calcula-se a margem requerida com base no preço atual, calcula-se o custo de um ponto de movimento, point_cost, e, em caso de volume insuficiente, menor que o mínimo permitido, o método retorna o prejuízo esperado, o lucro não obtido, com base na amplitude da vela.
double marg = 0; if(!OrderCalcMargin(ORDER_TYPE_BUY, Symb.Name(), 1, Symb.Ask(), marg)) return 0; double point_cost = Symb.TickValue() / Symb.TickSize(); if(MathMax(buy_lot, sell_lot) < Symb.LotsMin()) { double loss = -MathMax(Rates[start_position].high - Rates[start_position].open, Rates[start_position].open - Rates[start_position].low) * point_cost * equity / (2 * marg); return loss; } if((marg * MathMax(buy_lot, sell_lot)) >= equity) { double loss = -MathMax(Rates[start_position].high - Rates[start_position].open, Rates[start_position].open - Rates[start_position].low) * point_cost * MathMax(buy_lot, sell_lot); return loss; } point_cost *= MathAbs(buy_lot - sell_lot);
Situação análoga ocorre em caso de volume excessivo, não coberto pelos recursos disponíveis, marg * lot > equity. Isso incentiva o modelo a realizar operações dentro dos limites dos recursos disponíveis, evitando a inação.
Em seguida, passamos à verificação da eficácia das ações propostas. Primeiro, verificamos as posições compradas.
//--- double tp = 0, sl = 0, profit = 0, reward = 0; int stops = MathMax(Symb.StopsLevel(), 10); int spread = Symb.Spread(); if(buy_lot > 0) { tp = action[1] * MaxTP; sl = action[2] * MaxSL; if(int(tp) < stops || int(sl) < (stops + spread)) { double loss = -MathMax(Rates[start_position].high - Rates[start_position].open, Rates[start_position].open - Rates[start_position].low) * point_cost * buy_lot; return loss; } tp = (tp + spread) * Symb.Point() + Rates[start_position].open; sl = Rates[start_position].open - (sl + spread) * Symb.Point(); reward = profit = -spread * Symb.Point() * point_cost;
Os níveis de TakeProfit e StopLoss são extraídos dos elementos do tensor action. Depois disso, eles são escalados e verificados quanto à conformidade com o nível de stops da corretora.
Se as condições forem válidas, TP e SL são convertidos em valores absolutos de preço. Caso contrário, calculamos o valor do lucro não obtido.
Na sequência, é realizada a simulação do movimento do preço no intervalo de dados históricos. Para isso, organizamos um loop de iteração sobre os dados históricos em ordem cronológica.
Aqui, cabe observar que o array Rates é uma série temporal. Por isso, para preservar a sequência histórica, a iteração dos dados é realizada em ordem inversa.
for(uint i = start_position; i >=0; i--) { if(sl >= Rates[i].low) { double p = (Rates[i].open - sl) * point_cost; profit -= p; reward -= p * MathPow(DiscFactor, float(i - start_position)); break; }
No corpo do loop, é implementada uma abordagem estritamente orientada ao risco: a prioridade na verificação é dada ao nível de stop loss. Essa decisão é ditada pelo bom senso, pois as perdas no mercado, em regra, ocorrem de forma repentina e muito mais rapidamente do que o lucro se acumula. Caso o nível de stop seja atingido, determina-se o valor da perda em termos monetários, levando em conta o fator de desconto.
A aplicação do fator de desconto permite equilibrar de forma flexível resultados rápidos e resultados postergados, treinando o modelo para escolher ações que conduzam a uma rentabilidade estável. Quanto maior o fator, mais o modelo se orienta para ganhos de longo prazo, e vice-versa. No entanto, essa flexibilidade tem seu lado negativo: o uso do desconto dificulta a avaliação correta de um drawdown profundo. Perdas que ocorrem após um número significativo de etapas sofrem forte desvalorização e podem ser percebidas pelo modelo como pouco relevantes. Como resultado, o modelo tende a manter posições no prejuízo na esperança de uma reversão, o que, em condições reais de mercado, pode levar a um drawdown fatal até o nível de StopOut. Para evitar esse tipo de comportamento, além da avaliação descontada, aplica-se o controle do drawdown absoluto.
De forma análoga, verifica-se o atingimento do nível de take profit.
if(tp <= Rates[i].high) { double p = (tp - Rates[i].open) * point_cost; profit += p; reward += p * MathPow(DiscFactor, float(i - start_position)); break; }
Se nenhum dos níveis de trading for atingido, o lucro ou prejuízo atual é fixado pelo preço de abertura da vela seguinte.
double p = (Rates[i - 1].open - Rates[i].open) * point_cost; profit += p; reward += p * MathPow(DiscFactor, float(i - start_position));
Aqui é especialmente importante destacar o uso justamente do preço de abertura da próxima barra, e não do preço de fechamento da barra atual. Embora, na maioria dos casos, esses valores coincidam ou apresentem diferença pouco significativa, somos obrigados a considerar as particularidades da dinâmica do mercado. Nosso modelo toma a decisão de trading na abertura de uma nova barra e, por isso, é justamente esse preço que deve ser considerado ao fixar os resultados de posições não encerradas.
Essa abordagem permite preservar o realismo da simulação e não ignorar a probabilidade de surgimento de gaps de preço, característicos de trechos de alta volatilidade do mercado ou de momentos de divulgação de notícias relevantes. O uso do preço de abertura da próxima barra também enfatiza a sequência dos eventos de trading, destacando a lógica de causa e efeito entre a decisão tomada e sua execução em condições reais de mercado.
Em seguida, comparamos as perdas acumuladas sem considerar o fator de desconto com o nível de equity no momento da abertura da posição. Essa abordagem permite controlar a suficiência de recursos para a execução da operação de trading. Se as perdas excederem o capital disponível, ou seja, se ocorrer a perda total do depósito, aumentamos a penalização na função de recompensa e encerramos imediatamente o processo de simulação. Isso imita a situação real do mercado, em que a insuficiência de recursos leva à interrupção da atividade de trading, e garante uma avaliação mais precisa e segura da estratégia de trading durante o treinamento do modelo.
if(-profit >= equity) { reward-=1000; break; } } }
De forma análoga, realizamos a avaliação da posição vendida.
if(sell_lot > 0) { tp = action[4] * MaxTP; sl = action[5] * MaxSL; if(int(tp) < stops || int(sl) < (stops + spread)) { double loss = -MathMax(Rates[start_position].high - Rates[start_position].open, Rates[start_position].open - Rates[start_position].low) * point_cost * sell_lot; return loss; } tp = Rates[start_position].open - (tp + spread) * Symb.Point(); sl = Rates[start_position].open + (sl - spread) * Symb.Point(); for(uint i = start_position; i >=0; i--) { if(sl <= Rates[i].high) { double p = (sl - Rates[i].open) * point_cost; profit -= p; reward -= p * MathPow(DiscFactor, float(i - start_position)); break; } if(tp >= Rates[i].low) { double p = (Rates[i].open - tp) * point_cost; profit += p; reward += p * MathPow(DiscFactor, float(i - start_position)); break; } double p = (Rates[i - 1].open - Rates[i].open) * point_cost; profit -= p; reward -= p * MathPow(DiscFactor, float(i - start_position)); if(-profit >= equity) { reward-=1000; break; } } } //--- return reward; }
Depois disso, concluímos o funcionamento do método, retornando ao programa chamador a recompensa acumulada com o fator de desconto aplicado.
O código completo do EA de treinamento offline do modelo "…\Experts\K2VAE\Study.mq5" é apresentado no anexo. No mesmo local, também estão disponíveis todos os programas utilizados na preparação do artigo.
Teste
Como já mencionamos, o treinamento do modelo é realizado em duas etapas sequenciais. Primeiro, realizamos o treinamento offline com 15 anos de histórico do par EURUSD no timeframe H1. Esse conjunto de dados abrange todos os tipos de situações de mercado: de longos períodos laterais a tendências bruscas, de fases tranquilas a picos de volatilidade. Graças a isso, o modelo conseguiu aprender a diversidade do comportamento do mercado. O Encoder aprendeu a destacar os principais padrões e a transformar o estado do mercado em uma representação compacta, porém informativa, que se tornou a base para a tomada de decisões pelo Agente. Já o Actor, utilizando o feedback do Critic e do Director, formou uma estratégia robusta, capaz de operar com eficiência em diferentes condições.
Em seguida, veio a segunda etapa: o treinamento online com dados de 2024, organizado no testador de estratégias do MetaTrader 5. Aqui, o modelo operou em um regime próximo ao tempo real, analisando o mercado vela a vela. Ele enfrentou ruídos, flutuações aleatórias e distorções características do mercado real. Essa abordagem permitiu não apenas continuar o treinamento do modelo, mas também adaptar seu comportamento à dinâmica real, aprimorar a estratégia e aumentar a robustez em condições de incerteza.
Após a conclusão do treinamento, realizamos o teste com novos dados, as cotações de janeiro a março de 2025, mantendo todos os parâmetros usados durante o treinamento. Os resultados do teste são apresentados abaixo.
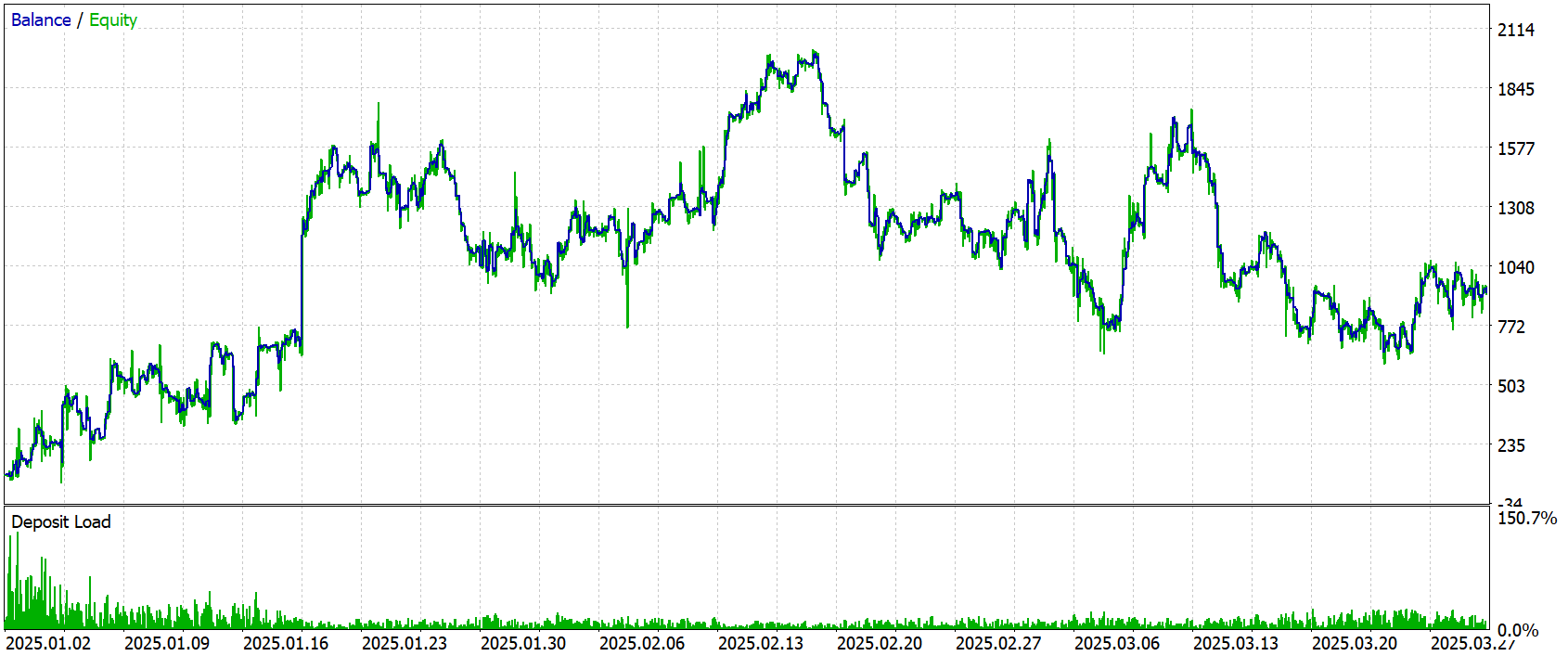
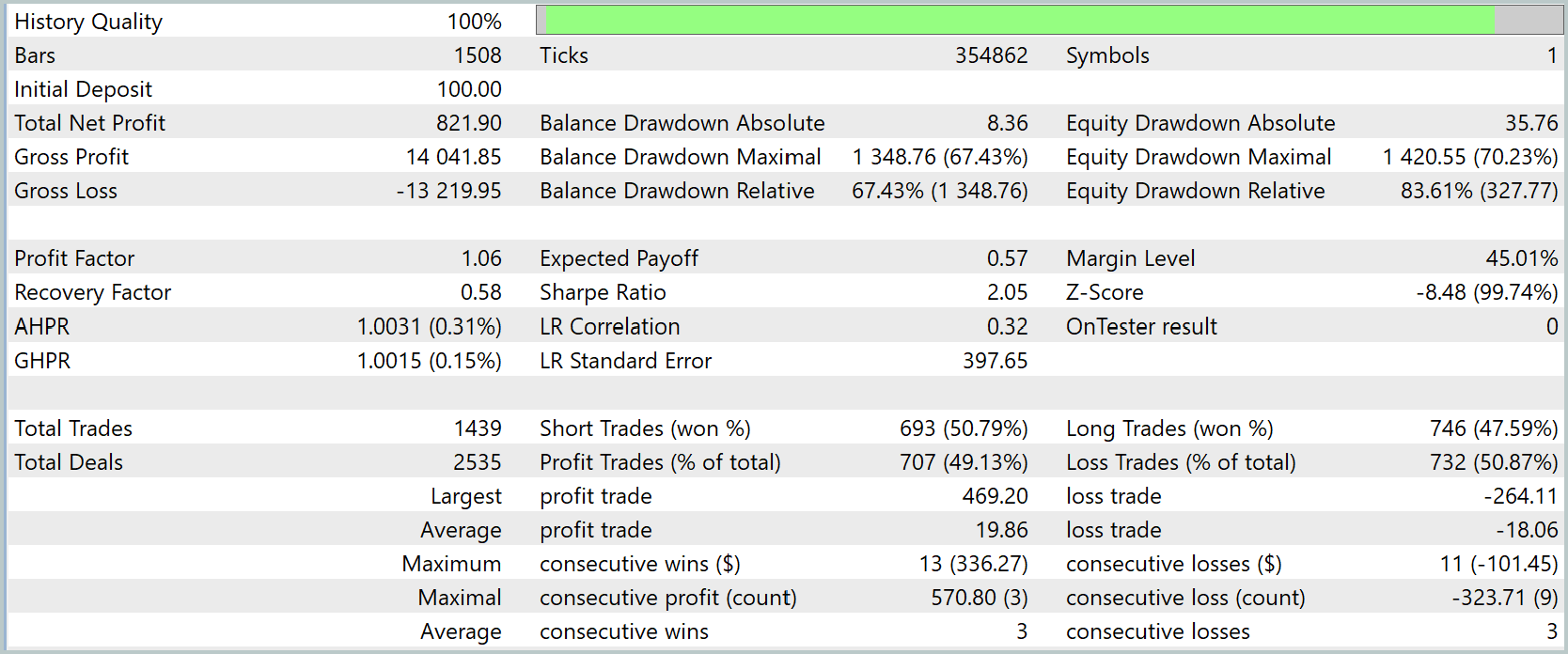
Os resultados do teste mostram que o modelo apresentou lucro positivo no período histórico selecionado. O lucro líquido total foi de $821.90 com um depósito inicial de $100.0, o que indica crescimento do capital. Ao mesmo tempo, cabe observar que o Profit Factor ficou em 1.06, o que indica uma ligeira superioridade dos lucros sobre as perdas.
Pelos indicadores de trading, vê-se que a quantidade de operações lucrativas é aproximadamente igual à de operações perdedoras, cerca de 49% e 51%, respectivamente, o que indica um equilíbrio entre posições vencedoras e perdedoras.
No gráfico, vê-se que a curva de saldo apresenta crescimento no geral, apesar dos drawdowns visíveis e dos períodos de queda. Chama especialmente a atenção a clara tendência de crescimento do saldo em janeiro e na primeira metade de fevereiro. Ao mesmo tempo, o mês de março se mostra claramente deficitário. Isso pode indicar a necessidade de continuar o treinamento do modelo em um intervalo histórico mais longo.
Considerações finais
Para concluir, observamos que o framework K²VAE, como parte do nosso agente de trading, comprovou seu funcionamento e obteve confirmação em uma amostra histórica real. O modelo combina compreensão profunda da dinâmica oculta do mercado, ajuste adaptativo de risco e geração de cenários probabilísticos, o que permitiu alcançar crescimento do capital. Ao mesmo tempo, a redução da eficiência em um intervalo mais longo de teste indica a necessidade de buscar formas de aumentar a capacidade de generalização do modelo.
Links
- K²VAE: Um Autoencoder Variacional Aprimorado por Koopman-Kalman para Previsão Probabilística de Séries Temporais
- Outros artigos da série
Programas utilizados no artigo
| # | Nome | Tipo | Descrição |
|---|---|---|---|
| 1 | Study.mq5 | Expert Advisor | EA de treinamento offline de modelos |
| 2 | StudyOnline.mq5 | Expert Advisor | EA de treinamento online de modelos |
| 3 | Test.mq5 | Expert Advisor | EA para teste do modelo |
| 4 | Trajectory.mqh | Biblioteca de classe | Estrutura de descrição do estado do sistema e da arquitetura dos modelos |
| 5 | NeuroNet.mqh | Biblioteca de classe | Biblioteca de classes para criação de redes neurais |
| 6 | NeuroNet.cl | Biblioteca | Biblioteca de código de programas OpenCL |
Traduzido do russo pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/ru/articles/18807
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso
Estou tendo alguns problemas com o VAE.mqh e descobri que o seguinte funciona muito bem para contornar o problema.