Dominando Logs (Parte 6): Armazenando logs em um banco de dados

Introdução
Imagine um movimentado mercado de negociações digitais e sofisticação financeira onde cada movimento é rastreado, registrado e meticulosamente analisado em busca do sucesso. E se você pudesse não apenas acessar um uma cronologia de todas as decisões e erros cometidos pelos seus Expert Advisors (EAs), mas também utilizar uma poderosa ferramenta para otimizar e aprimorar esses robôs em tempo real? Bem-vindo à Parte 1 de Dominando Registros de Log (Parte 1): Conceitos Fundamentais e Primeiros Passos em MQL5, onde começamos a criar uma sofisticada biblioteca de logs sob medida para o desenvolvimento em MQL5.
Aqui, superamos as limitações da interface de logs padrão do MetaTrader 5 para criar uma solução de registro robusta, ajustável e dinâmica que aprimora o ecossistema do MQL5. Nossa jornada começou incorporando requisitos essenciais: uma estrutura Singleton confiável para manter a consistência do código, armazenamento avançado de logs em banco de dados para trilhas de auditoria abrangentes para trilhas de auditoria abrangentes para trilhas de auditoria abrangentes, flexibilidade na saída, classificação dos níveis de log e formatos personalizáveis para atender às diversas necessidades dos projetos.
Junte-se a nós enquanto nos aprofundamos em como você pode transformar dados brutos em informações acionáveis para compreender, controlar e elevar o desempenho dos seus EAs como nunca antes.
Neste artigo, exploraremos desde os conceitos fundamentais até a implementação prática de um manipuladores (handler) de logs que grava e consulta dados diretamente em um banco de dados.
O que são bancos de dados
Os logs são o pulso de um sistema, capturando tudo o que acontece nos bastidores. Mas armazená-los de forma eficiente é outra história. Até agora, salvamos os logs em arquivos de texto, uma solução simples e funcional para muitos casos. O problema surge quando o volume de dados cresce: procurar informações entre milhares de linhas torna-se um pesadelo de desempenho e gerenciamento.
É aí que entram os bancos de dados. Eles oferecem uma forma estruturada e otimizada de armazenar, consultar e organizar informações. Em vez de percorrer arquivos manualmente, podemos executar consultas rápidas e encontrar exatamente o que precisamos. Mas, afinal, o que é um banco de dados e por que ele é tão essencial?
A estrutura de um banco de dados
Um banco de dados funciona como um sistema inteligente de armazenamento, onde os dados são organizados de forma lógica para facilitar pesquisas e manipulações. Pense nele como um arquivo bem catalogado, onde cada informação possui seu lugar definido. No contexto dos logs, em vez de salvar registros em arquivos dispersos, podemos armazená-los de forma estruturada, filtrando rapidamente por data, tipo de erro ou qualquer outro critério relevante.
Para entender melhor, vamos dividir um sistema de catalogação bem organizado em seus três componentes fundamentais: tabelas, colunas e linhas.
-
Tabelas: a base do banco de dados. Uma tabela funciona como uma planilha, onde agrupamos dados relacionados. No caso dos logs, poderíamos ter uma tabela chamada "logs", dedicada exclusivamente ao armazenamento desses registros.
Cada tabela é projetada para um tipo específico de dado, garantindo organização e eficiência no acesso às informações.
Colunas: os campos de dados. Dentro de uma tabela, temos as colunas, que representam as diferentes categorias de informações armazenadas. Cada coluna equivale a um campo de dados e define um tipo específico de informação. Por exemplo, em uma tabela de logs, podemos ter colunas como:
- id → Identificador único do log
- timestamp → Data e hora do registro
- level → Nível do log (DEBUG, INFO, ERROR...)
- message → Mensagem do log
- source → Origem do log (qual sistema ou módulo gerou o registro)
Cada coluna possui uma função bem definida. O timestamp, por exemplo, armazena datas e horários, enquanto message contém texto. Essa estrutura evita redundâncias e melhora o desempenho das consultas.
-
Linhas: os registros armazenados. Se as colunas definem quais informações serão armazenadas, as linhas representam os registros individuais dentro da tabela. Cada linha contém um conjunto completo de valores preenchendo as respectivas colunas. Veja um exemplo prático de uma tabela de logs:
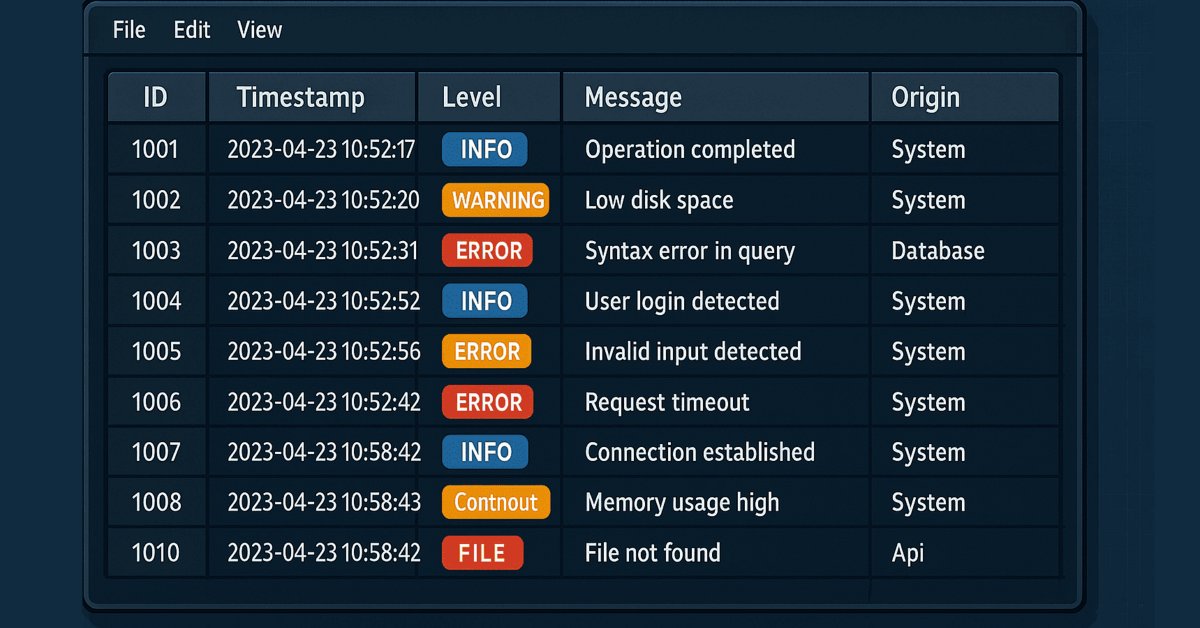
ID Timestamp Nível Mensagem Origem 1 2025-02-12 10:15 DEBUG Valor do indicador RSI calculado: 72.56 Indicadores 2 2025-02-12 10:16 INFO Ordem de compra enviada com sucesso Gerenciamento de Ordens 3 2025-02-12 10:17 ALERT Stop Loss ajustado para o nível de breakeven Gerenciamento de Risco 4 2025-02-12 10:18 ERROR Falha ao enviar ordem de venda Gerenciamento de Ordens 5 2025-02-12 10:19 FATAL Falha ao inicializar o EA: Configurações inválidas Inicialização Cada linha é um registro único, descrevendo um evento específico.
Agora que entendemos a estrutura do banco de dados, podemos explorar como aplicá-la na prática dentro do MQL5 para armazenar e consultar logs de forma eficiente. Vamos ver isso na prática.
Bancos de dados em MQL5
O MQL5 permite armazenar e recuperar dados de forma estruturada, mas seu suporte a bancos de dados possui algumas particularidades que precisam ser compreendidas antes de avançarmos para a implementação.
Ao contrário das linguagens voltadas para aplicações web ou corporativas, o MQL5 não oferece suporte nativo a bancos de dados relacionais robustos, como MySQL ou PostgreSQL. Mas isso não significa que estamos limitados a arquivos de texto! Podemos contornar essa limitação de duas maneiras:
Utilizando o SQLite, um banco de dados leve baseado em arquivos que possui suporte nativo no MQL5 (veja as funções de banco de dados no MQL5), ou estabelecendo conexões externas por meio de APIs, permitindo a integração com bancos de dados mais robustos. Para o nosso propósito de armazenar e consultar logs de forma eficiente, o SQLite é a escolha ideal. Ele é simples, rápido e não requer um servidor dedicado, tornando-se perfeito para o que precisamos. Antes de avançarmos para a implementação, vamos entender melhor as características de um banco de dados baseado em um arquivo .sqlite.
- Vantagens
- Não requer servidor: O SQLite é um banco de dados "embutido", o que significa que não requer instalação nem configuração de um servidor.
- Pronto para uso: Basta criar o arquivo .sqlite e começar a armazenar os dados.
- Leitura rápida: Como é armazenado em um único arquivo, o SQLite pode ser extremamente rápido para leitura de pequenos e médios volumes de dados.
- Baixa latência: Para consultas simples, ele pode ser mais rápido do que bancos de dados relacionais tradicionais.
- Alta compatibilidade: Compatível com diversas linguagens de programação.
- Desvantagens
- Risco de corrupção do arquivo: Se o arquivo for danificado, a recuperação dos dados pode ser complicada.
- Backup manual: O backup precisa ser feito copiando o arquivo .sqlite, já que o SQLite não possui suporte nativo para replicação automática.
- Não escala bem: Para grandes volumes de dados e acessos concorrentes, o SQLite não é a melhor opção. Mas, como nosso objetivo é armazenar logs localmente, isso não será um problema.
Agora que conhecemos as possibilidades e limitações dos bancos de dados no MQL5, podemos nos aprofundar nas operações básicas que precisaremos implementar para armazenar e recuperar logs de forma eficiente.
As operações básicas de banco de dados de que precisamos
Antes de implementarmos nosso manipulador (handler), precisamos entender as operações fundamentais que utilizaremos no banco de dados. Essas operações incluem criar tabelas, inserir novos registros, recuperar dados e, quando necessário, excluir ou atualizar logs.
Em um contexto de registro de logs, normalmente precisamos armazenar informações como data e hora, nível do log, mensagem e, possivelmente, o nome do arquivo ou componente que gerou a entrada. Para isso, devemos estruturar nossa tabela de forma que facilite consultas rápidas e eficientes.
Primeiro, vamos criar um Expert Advisor (EA) simples para testes chamado DatabaseTest.mq5 dentro da pasta Experts/Logify. Com o arquivo criado, teremos algo semelhante a isto:
//+------------------------------------------------------------------+ //| DatabaseTest.mq5 | //| joaopedrodev | //| https://www.mql5.com/en/users/joaopedrodev | //+------------------------------------------------------------------+ #property copyright "joaopedrodev" #property link "https://www.mql5.com/en/users/joaopedrodev" #property version "1.00" //+------------------------------------------------------------------+ //| Import CLogify | //+------------------------------------------------------------------+ #include <Logify/Logify.mqh> //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- //--- return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+
Criando e conectando ao banco de dados
O primeiro passo é criar e conectar-se ao banco de dados. Para isso, utilizamos a função DatabaseOpen(), que recebe dois parâmetros:
- filename : Nome do arquivo do banco de dados, relativo à pasta "MQL5\\Files".
- flags : Combinação de flags da enumeração ENUM_DATABASE_OPEN_FLAGS. Essas flags determinam como o banco de dados será acessado. As flags disponíveis são:
- DATABASE_OPEN_READONLY - Acesso somente para leitura.
- DATABASE_OPEN_READWRITE - Permite leitura e escrita.
- DATABASE_OPEN_CREATE - Cria o banco de dados no disco caso ele não exista.
- DATABASE_OPEN_MEMORY - Cria um banco de dados temporário na memória.
- DATABASE_OPEN_COMMON - O arquivo será armazenado na pasta comum a todos os terminais.
Para o nosso exemplo, utilizaremos DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE. Dessa forma, garantimos que o banco de dados será criado automaticamente caso ainda não exista, evitando verificações manuais.
A função DatabaseOpen() retorna um identificador do banco de dados (database handle), que armazenamos em uma variável para utilizá-lo em operações futuras. Além disso, é essencial fechar a conexão ao final do uso, o que fazemos com a função DatabaseClose().
Nosso código agora se parece com isto:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Opening a database connection int dbHandle = DatabaseOpen(path,DATABASE_OPEN_READWRITE|DATABASE_OPEN_CREATE); if(dbHandle == INVALID_HANDLE) { Print("[ERROR] ["+TimeToString(TimeCurrent())+"] Database error (Code: "+IntegerToString(GetLastError())+")"); return(INIT_FAILED); } Print("Open database file"); //--- Closing database after use DatabaseClose(handle_db); Print("Closed database file"); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+
Agora que conseguimos abrir e fechar o banco de dados, é hora de estruturar os dados armazenados. Vamos começar criando nossa primeira tabela: logs.
Criando uma tabela
Mas, antes de começarmos a criar tabelas sem nenhum critério, precisamos verificar se ela já existe. Para isso, utilizamos a função DatabaseTableExists(). Se a tabela ainda não estiver presente no banco de dados, então a criaremos com um simples comando SQL. Falando em SQL (Structured Query Language), esta é a linguagem utilizada para interagir com bancos de dados, permitindo inserir, consultar, modificar ou excluir dados. Pense no SQL como uma espécie de "cardápio de restaurante" para bancos de dados: você faz um pedido (consulta SQL) e recebe exatamente o que solicitou, desde que o pedido tenha sido formulado corretamente, é claro!
Agora, veremos isso na prática e estruturaremos nossa tabela de logs, garantindo que ela seja criada corretamente sempre que necessário.
Para o nosso propósito, precisamos conhecer apenas alguns comandos SQL, sendo o primeiro deles utilizado para criar uma tabela:
CREATE TABLE {table_name} ({column_name} {type_data}, …); - {table_name}: Nome da tabela a ser criada.
- {column_name} {type_data}: Definição das colunas, onde {type_data} indica o tipo de dado (texto, número, data etc.).
Agora, utilizaremos a função DatabaseExecute() para executar o comando de criação da tabela. A estrutura da tabela será baseada na estrutura MqlLogifyModel, contendo os seguintes campos:
- id: Identificador único da linha.
- formated: Mensagem formatada.
- levelname: Nome do nível de log.
- msg: Mensagem original.
- args: Argumentos da mensagem.
- timestamp: Data e hora em formato numérico.
- date_time: Data e hora formatadas.
- level: Nível de severidade do log.
- origin: Origem do log.
- filename: Nome do arquivo de origem.
- function: Função onde o log foi gerado.
- line: Linha de código onde o log foi gerado.
Nosso código agora se parece com isto:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Open the database connection int dbHandle = DatabaseOpen("db\\logs.sqlite", DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE); if(dbHandle == INVALID_HANDLE) { Print("[ERROR] [" + TimeToString(TimeCurrent()) + "] Unable to open database (Error Code: " + IntegerToString(GetLastError()) + ")"); return(INIT_FAILED); } Print("[INFO] Database connection opened successfully"); //--- Create the 'logs' table if it does not exist if(!DatabaseTableExists(dbHandle, "logs")) { DatabaseExecute(dbHandle, "CREATE TABLE logs (" "id INTEGER PRIMARY KEY AUTOINCREMENT," // Auto-incrementing unique ID "formated TEXT," // Formatted log message "levelname TEXT," // Log level (INFO, ERROR, etc.) "msg TEXT," // Main log message "args TEXT," // Additional details "timestamp BIGINT," // Log event timestamp (Unix time) "date_time DATETIME,"// Human-readable date and time "level BIGINT," // Log level as an integer "origin TEXT," // Module or component name "filename TEXT," // Source file name "function TEXT," // Function where the log was recorded "line BIGINT);"); // Source code line number Print("[INFO] 'logs' table created successfully"); } //--- Close the database connection DatabaseClose(dbHandle); Print("[INFO] Database connection closed successfully"); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+
Isso conclui a etapa de criação do banco de dados e da tabela "logs". Após a criação da tabela, o arquivo do banco de dados deverá aparecer na pasta Files no explorador de arquivos:
Ao clicar no arquivo, o MetaEditor oferece suporte a esse tipo de arquivo, e ele deverá ser aberto em uma tela semelhante a esta:
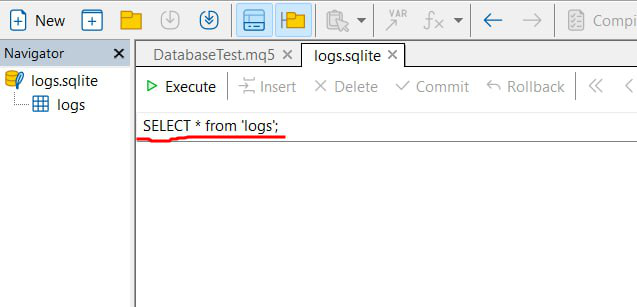
Aqui temos uma interface onde podemos visualizar os dados do banco de dados e executar diferentes comandos SQL, conforme destacado em vermelho. Utilizaremos bastante esse recurso para visualizar os dados diretamente no editor.
Como inserir dados no banco de dados
Em SQL, o comando utilizado para inserir dados em uma tabela é:
INSERT INTO {table_name} ({column}, ...) VALUES ({value}, ...) No contexto do MQL5, essa instrução pode ser simplificada com a ajuda de funções específicas que tornam o processo mais intuitivo e menos sujeito a erros. As principais funções que você utilizará são:
- DatabasePrepare() - Essa função cria um identificador para a consulta SQL, preparando-a para a execução posterior. Ela representa o primeiro passo para que a consulta seja interpretada pelo banco de dados.
- DatabaseBind() - Utilizando essa função, você associa valores reais aos parâmetros da consulta. No comando SQL, os valores são representados por placeholders (por exemplo, ?1, ?2 etc.), que serão substituídos pelos dados fornecidos no momento da execução.
- DatabaseRead() - Responsável por executar a consulta preparada. No caso de comandos que não retornam registros (como INSERT), essa função garante a execução da instrução e a transição para o próximo registro, quando necessário.
- DatabaseFinalize() - Após o uso, é importante liberar os recursos associados à consulta. Essa função finaliza a consulta preparada anteriormente, evitando vazamentos de memória.
Ao criar a consulta para inserção de dados, podemos utilizar placeholders para indicar onde os valores serão vinculados posteriormente. Considere o exemplo a seguir, que insere um novo registro na tabela logs, seguindo as colunas que criamos anteriormente:
INSERT INTO logs (formated, levelname, msg, args, timestamp, date_time, level, origin, filename, function, line) VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9, ?10, ?11);
Observe que todos os campos da tabela foram listados, exceto o campo id, que é gerado automaticamente pelo banco de dados. Além disso, os valores a serem inseridos são indicados por ?1, ?2 etc. Cada placeholder corresponde a um índice que será posteriormente utilizado para associar o valor real por meio da função DatabaseBind().
//--- Prepare SQL statement for inserting a log entry string sql = "INSERT INTO logs (formated, levelname, msg, args, timestamp, date_time, level, origin, filename, function, line) " "VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9, ?10, ?11);"; int sqlRequest = DatabasePrepare(dbHandle, sql); if(sqlRequest == INVALID_HANDLE) { Print("[ERROR] Failed to prepare SQL statement for log insertion"); } //--- Bind values to the SQL statement DatabaseBind(sqlRequest, 0, "06:24:00 [INFO] Buy order sent successfully"); // Formatted log message DatabaseBind(sqlRequest, 1, "INFO"); // Log level name DatabaseBind(sqlRequest, 2, "Buy order sent successfully"); // Main log message DatabaseBind(sqlRequest, 3, "Symbol: EURUSD, Volume: 0.1"); // Additional details DatabaseBind(sqlRequest, 4, 1739471040); // Unix timestamp DatabaseBind(sqlRequest, 5, "2025.02.13 18:24:00"); // Readable date and time DatabaseBind(sqlRequest, 6, 1); // Log level as integer DatabaseBind(sqlRequest, 7, "Order Management"); // Module or component name DatabaseBind(sqlRequest, 8, "File.mq5"); // Source file name DatabaseBind(sqlRequest, 9, "OnInit"); // Function name DatabaseBind(sqlRequest, 10, 100); // Line numberApós vincular todos os valores, a função DatabaseRead() é utilizada para executar a consulta preparada. Se a execução for bem-sucedida, uma mensagem de confirmação será exibida; caso contrário, um erro será informado:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Open the database connection int dbHandle = DatabaseOpen("db\\logs.sqlite", DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE); if(dbHandle == INVALID_HANDLE) { Print("[ERROR] [" + TimeToString(TimeCurrent()) + "] Unable to open database (Error Code: " + IntegerToString(GetLastError()) + ")"); return(INIT_FAILED); } Print("[INFO] Database connection opened successfully"); //--- Create the 'logs' table if it does not exist if(!DatabaseTableExists(dbHandle, "logs")) { DatabaseExecute(dbHandle, "CREATE TABLE logs (" "id INTEGER PRIMARY KEY AUTOINCREMENT," // Auto-incrementing unique ID "formated TEXT," // Formatted log message "levelname TEXT," // Log level (INFO, ERROR, etc.) "msg TEXT," // Main log message "args TEXT," // Additional details "timestamp BIGINT," // Log event timestamp (Unix time) "date_time DATETIME,"// Human-readable date and time "level BIGINT," // Log level as an integer "origin TEXT," // Module or component name "filename TEXT," // Source file name "function TEXT," // Function where the log was recorded "line BIGINT);"); // Source code line number Print("[INFO] 'logs' table created successfully"); } //--- Prepare SQL statement for inserting a log entry string sql = "INSERT INTO logs (formated, levelname, msg, args, timestamp, date_time, level, origin, filename, function, line) " "VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9, ?10, ?11);"; int sqlRequest = DatabasePrepare(dbHandle, sql); if(sqlRequest == INVALID_HANDLE) { Print("[ERROR] Failed to prepare SQL statement for log insertion"); } //--- Bind values to the SQL statement DatabaseBind(sqlRequest, 0, "06:24:00 [INFO] Buy order sent successfully"); // Formatted log message DatabaseBind(sqlRequest, 1, "INFO"); // Log level name DatabaseBind(sqlRequest, 2, "Buy order sent successfully"); // Main log message DatabaseBind(sqlRequest, 3, "Symbol: EURUSD, Volume: 0.1"); // Additional details DatabaseBind(sqlRequest, 4, 1739471040); // Unix timestamp DatabaseBind(sqlRequest, 5, "2025.02.13 18:24:00"); // Readable date and time DatabaseBind(sqlRequest, 6, 1); // Log level as integer DatabaseBind(sqlRequest, 7, "Order Management"); // Module or component name DatabaseBind(sqlRequest, 8, "File.mq5"); // Source file name DatabaseBind(sqlRequest, 9, "OnInit"); // Function name DatabaseBind(sqlRequest, 10, 100); // Line number //--- Execute the SQL statement if(!DatabaseRead(sqlRequest)) { Print("[ERROR] SQL insertion request failed"); } else { Print("[INFO] Log entry inserted successfully"); } //--- Close the database connection DatabaseClose(dbHandle); Print("[INFO] Database connection closed successfully"); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+Ao executar este Expert Advisor, as seguintes mensagens serão exibidas no console:
[INFO] Database file opened successfully [INFO] Table 'logs' created successfully [INFO] Log entry inserted successfully [INFO] Database file closed successfully
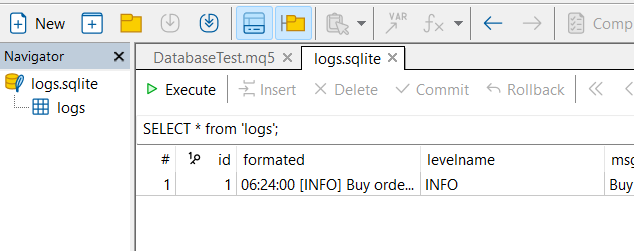
Além disso, ao abrir o banco de dados no editor, você poderá visualizar a tabela logs com todos os dados inseridos, conforme mostrado na imagem abaixo:
Como ler dados do banco de dados
A leitura de dados de um banco de dados envolve um processo muito semelhante ao de inserção de registros, mas com o objetivo de recuperar informações já armazenadas. No MQL5, o fluxo básico para leitura de dados consiste em:
- Preparar a consulta SQL: Utilizando a função DatabasePrepare(), você cria um identificador para a consulta que será executada.
- Executar a consulta: Com o identificador preparado, a função DatabaseRead() executa a consulta e posiciona o cursor no primeiro registro do resultado.
- Extrair os dados: A partir do registro atual, você utiliza funções específicas para obter os valores de cada coluna, de acordo com o tipo de dado esperado. Essas funções incluem:
- DatabaseColumnText() - Obtém o valor do campo do registro atual como uma string.
- DatabaseColumnInteger() - Obtém um valor int do registro atual.
- DatabaseColumnLong() - Obtém um valor long do registro atual.
- DatabaseColumnDouble() - Obtém um valor double do registro atual.
- DatabaseColumnBlob() - Obtém o valor do campo do registro atual como um array.
Com essas etapas, você tem um fluxo simples e eficiente para recuperar informações e utilizá-las conforme a necessidade da sua aplicação.
Por exemplo, suponha que você queira recuperar todos os registros da tabela logs. A consulta SQL para essa operação é bastante simples:
SELECT * FROM logs
Essa consulta seleciona todas as colunas de todos os registros da tabela. No MQL5, utilizamos a função DatabasePrepare() para criar o identificador da consulta, assim como fizemos ao inserir dados.
Ao final, o código fica assim:
//+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Open the database connection int dbHandle = DatabaseOpen("db\\logs.sqlite", DATABASE_OPEN_READWRITE | DATABASE_OPEN_CREATE); if(dbHandle == INVALID_HANDLE) { Print("[ERROR] [" + TimeToString(TimeCurrent()) + "] Unable to open database (Error Code: " + IntegerToString(GetLastError()) + ")"); return INIT_FAILED; } Print("[INFO] Database connection opened successfully."); //--- Create the 'logs' table if it doesn't exist if(!DatabaseTableExists(dbHandle, "logs")) { string createTableSQL = "CREATE TABLE logs (" "id INTEGER PRIMARY KEY AUTOINCREMENT," // Auto-incrementing unique ID "formated TEXT," // Formatted log message "levelname TEXT," // Log level name (INFO, ERROR, etc.) "msg TEXT," // Main log message "args TEXT," // Additional arguments/details "timestamp BIGINT," // Timestamp of the log event "date_time DATETIME," // Human-readable date and time "level BIGINT," // Log level as an integer "origin TEXT," // Module or component name "filename TEXT," // Source file name "function TEXT," // Function where the log was recorded "line BIGINT);"; // Line number in the source code DatabaseExecute(dbHandle, createTableSQL); Print("[INFO] 'logs' table created successfully."); } //--- Prepare SQL statement to retrieve log entries string sqlQuery = "SELECT * FROM logs"; int sqlRequest = DatabasePrepare(dbHandle, sqlQuery); if(sqlRequest == INVALID_HANDLE) { Print("[ERROR] Failed to prepare SQL statement."); } //--- Execute the SQL statement if(!DatabaseRead(sqlRequest)) { Print("[ERROR] SQL query execution failed."); } else { Print("[INFO] SQL query executed successfully."); //--- Bind SQL query results to the log data model MqlLogifyModel logData; DatabaseColumnText(sqlRequest, 1, logData.formated); DatabaseColumnText(sqlRequest, 2, logData.levelname); DatabaseColumnText(sqlRequest, 3, logData.msg); DatabaseColumnText(sqlRequest, 4, logData.args); DatabaseColumnLong(sqlRequest, 5, logData.timestamp); string dateTimeStr; DatabaseColumnText(sqlRequest, 6, dateTimeStr); logData.date_time = StringToTime(dateTimeStr); DatabaseColumnInteger(sqlRequest, 7, logData.level); DatabaseColumnText(sqlRequest, 8, logData.origin); DatabaseColumnText(sqlRequest, 9, logData.filename); DatabaseColumnText(sqlRequest, 10, logData.function); DatabaseColumnLong(sqlRequest, 11, logData.line); Print("[INFO] Data retrieved: Formatted = ", logData.formated, " | Level = ", logData.level, " | Origin = ", logData.origin); } //--- Close the database connection DatabaseClose(dbHandle); Print("[INFO] Database connection closed successfully."); return INIT_SUCCEEDED; } //+------------------------------------------------------------------+
Certo, com isso, ao executar o código, temos este resultado.
[INFO] Database file opened successfully [INFO] SQL request successfully [INFO] Data read! | Formated: 06:24:00 [INFO] Buy order sent successfully | Level: 1 | Origin: Order Management [INFO] Database file closed successfully
Com essas operações básicas em mente, estamos prontos para configurar nosso manipulador (handler) de banco de dados. Vamos preparar o ambiente necessário para integrar o banco de dados à nossa biblioteca de logs.
Configurando o manipulador (handler) de banco de dados
Para utilizar um banco de dados para armazenar logs, precisamos configurar corretamente nosso manipulador (handler). Isso envolve definir os atributos da estrutura de configuração, de forma semelhante ao que fizemos com o manipulador (handler) de arquivos. Vamos criar uma estrutura de configuração chamada "MqlLogifyHandleDatabaseConfig" e copiar essa estrutura realizando algumas alterações:
struct MqlLogifyHandleDatabaseConfig { string directory; // Directory for log files string base_filename; // Base file name ENUM_LOG_FILE_EXTENSION file_extension; // File extension type ENUM_LOG_ROTATION_MODE rotation_mode; // Rotation mode int messages_per_flush; // Messages before flushing uint codepage; // Encoding (e.g., UTF-8, ANSI) ulong max_file_size_mb; // Max file size in MB for rotation int max_file_count; // Max number of files before deletion //--- Default constructor MqlLogifyHandleDatabaseConfig(void) { directory = "logs"; // Default directory base_filename = "expert"; // Default base name file_extension = LOG_FILE_EXTENSION_LOG;// Default to .log extension rotation_mode = LOG_ROTATION_MODE_SIZE;// Default size-based rotation messages_per_flush = 100; // Default flush threshold codepage = CP_UTF8; // Default UTF-8 encoding max_file_size_mb = 5; // Default max file size in MB max_file_count = 10; // Default max file count } };
Destaquei os atributos atributos como rotação, tipo de arquivo, número máximo de arquivos, modo de codificação, entre outros, que serão removidos, pois não fazem sentido no contexto de um banco de dados. Com os atributos definidos, ajustaremos o método ValidityConfig(). Ao final, o código fica assim:
//+------------------------------------------------------------------+ //| Struct: MqlLogifyHandleDatabaseConfig | //+------------------------------------------------------------------+ struct MqlLogifyHandleDatabaseConfig { string directory; // Directory for log files string base_filename; // Base file name int messages_per_flush; // Messages before flushing //--- Default constructor MqlLogifyHandleDatabaseConfig(void) { directory = "logs"; // Default directory base_filename = "expert"; // Default base name messages_per_flush = 100; // Default flush threshold } //--- Destructor ~MqlLogifyHandleDatabaseConfig(void) { } //--- Validate configuration bool ValidateConfig(string &error_message) { //--- Saves the return value bool is_valid = true; //--- Check if the directory is not empty if(directory == "") { directory = "logs"; error_message = "The directory cannot be empty."; is_valid = false; } //--- Check if the base filename is not empty if(base_filename == "") { base_filename = "expert"; error_message = "The base filename cannot be empty."; is_valid = false; } //--- Check if the number of messages per flush is positive if(messages_per_flush <= 0) { messages_per_flush = 100; error_message = "The number of messages per flush must be greater than zero."; is_valid = false; } //--- No errors found return(is_valid); } };
Com a configuração pronta, finalmente podemos começar a implementar o manipulador (handler).
Implementando o manipulador (handler) de banco de dados
Agora que estruturamos nossa configuração, vamos para a parte prática: implementar o manipulador (handler) de banco de dados. Vou detalhar cada parte da implementação, explicando as escolhas feitas e garantindo que o manipulador (handler) seja flexível para futuras melhorias.
Começamos definindo a classe CLogifyHandlerDatabase, que estende CLogifyHandler. Essa classe precisa armazenar a configuração do manipulador (handler), um utilitário de controle de tempo (CIntervalWatcher) e um cache de mensagens de log. Esse cache serve para evitar gravações excessivas no banco de dados, armazenando temporariamente as mensagens antes de gravá-las.
class CLogifyHandlerDatabase : public CLogifyHandler { private: //--- Config MqlLogifyHandleDatabaseConfig m_config; //--- Update utilities CIntervalWatcher m_interval_watcher; //--- Cache data MqlLogifyModel m_cache[]; int m_index_cache; public: CLogifyHandlerDatabase(void); ~CLogifyHandlerDatabase(void); //--- Configuration management void SetConfig(MqlLogifyHandleDatabaseConfig &config); MqlLogifyHandleDatabaseConfig GetConfig(void); virtual void Emit(MqlLogifyModel &data); // Processes a log message and sends it to the specified destination virtual void Flush(void); // Clears or completes any pending operations virtual void Close(void); // Closes the handler and releases any resources };
O construtor inicializa os atributos, garantindo que o nome do manipulador (handler) seja "database", define um intervalo para o m_interval_watcher e limpa o cache. No destrutor, chamamos Close(), garantindo que todos os logs pendentes sejam gravados antes da finalização do objeto.
Outro método importante é SetConfig(), que permite configurar o manipulador (handler), armazenando a configuração e validando-a para garantir que não existam erros. O método GetConfig() simplesmente retorna a configuração atual.
CLogifyHandlerDatabase::CLogifyHandlerDatabase(void) { m_name = "database"; m_interval_watcher.SetInterval(PERIOD_D1); ArrayFree(m_cache); m_index_cache = 0; } CLogifyHandlerDatabase::~CLogifyHandlerDatabase(void) { this.Close(); } void CLogifyHandlerDatabase::SetConfig(MqlLogifyHandleDatabaseConfig &config) { m_config = config; string err_msg = ""; if(!m_config.ValidateConfig(err_msg)) { Print("[ERROR] ["+TimeToString(TimeCurrent())+"] Log system error: "+err_msg); } } MqlLogifyHandleDatabaseConfig CLogifyHandlerDatabase::GetConfig(void) { return(m_config); }
Agora vamos ao coração do manipulador (handler) de banco de dados: salvar diretamente os registros de log. Para isso, implementaremos os três métodos básicos de todo manipulador (handler):
- Emit(MqlLogifyModel &data): Processa uma mensagem de log e a envia para o cache.
- Flush(): Finaliza ou descarrega quaisquer operações, gravando as informações no destino apropriado (arquivo, console, banco de dados etc.).
- Close(): Fecha o manipulador (handler) e libera todos os recursos associados.
Começando pelo método Emit(), que é responsável por adicionar os dados ao cache e, caso ele atinja o limite definido, chama Flush().
//+------------------------------------------------------------------+ //| Processes a log message and sends it to the specified destination| //+------------------------------------------------------------------+ void CLogifyHandlerDatabase::Emit(MqlLogifyModel &data) { //--- Checks if the configured level allows if(data.level >= this.GetLevel()) { //--- Resize cache if necessary int size = ArraySize(m_cache); if(size != m_config.messages_per_flush) { ArrayResize(m_cache, m_config.messages_per_flush); size = m_config.messages_per_flush; } //--- Add log to cache m_cache[m_index_cache++] = data; //--- Flush if cache limit is reached or update condition is met if(m_index_cache >= m_config.messages_per_flush || m_interval_watcher.Inspect()) { //--- Save cache Flush(); //--- Reset cache m_index_cache = 0; for(int i=0;i<size;i++) { m_cache[i].Reset(); } } } } //+------------------------------------------------------------------+
Continuando com o método Flush(), que lê os dados do cache e os adiciona ao banco de dados, seguindo a mesma estrutura que ensinei no início do artigo, na seção "Como inserir dados no banco de dados", utilizando a função DatabasePrepare().
//+------------------------------------------------------------------+ //| Clears or completes any pending operations | //+------------------------------------------------------------------+ void CLogifyHandlerDatabase::Flush(void) { //--- Get the full path of the file string path = m_config.directory+"\\"+m_config.base_filename+".sqlite"; //--- Open database ResetLastError(); int handle_db = DatabaseOpen(path,DATABASE_OPEN_CREATE|DATABASE_OPEN_READWRITE); if(handle_db == INVALID_HANDLE) { Print("[ERROR] ["+TimeToString(TimeCurrent())+"] Log system error: Unable to open log file '"+path+"'. Certifique-se de que o diretório existe e permite gravação. (Code: "+IntegerToString(GetLastError())+")"); return; } if(!DatabaseTableExists(handle_db,"logs")) { DatabaseExecute(handle_db, "CREATE TABLE logs (" "id INTEGER PRIMARY KEY AUTOINCREMENT," "formated TEXT," "levelname TEXT," "msg TEXT," "args TEXT," "timestamp BIGINT," "date_time DATETIME," "level BIGINT," "origin TEXT," "filename TEXT," "function TEXT," "line BIGINT);"); } //--- string sql="INSERT INTO logs (formated, levelname, msg, args, timestamp, date_time, level, origin, filename, function, line) VALUES (?1, ?2, ?3, ?4, ?5, ?6, ?7, ?8, ?9, ?10, ?11);"; // parâmetro de consulta int request = DatabasePrepare(handle_db,sql); if(request == INVALID_HANDLE) { Print("Erro"); } //--- Loop through all cached messages int size = ArraySize(m_cache); for(int i=0;i<size;i++) { if(m_cache[i].timestamp > 0) { DatabaseBind(request,0,m_cache[i].formated); DatabaseBind(request,1,m_cache[i].levelname); DatabaseBind(request,2,m_cache[i].msg); DatabaseBind(request,3,m_cache[i].args); DatabaseBind(request,4,m_cache[i].timestamp); DatabaseBind(request,5,TimeToString(m_cache[i].date_time,TIME_DATE|TIME_MINUTES|TIME_SECONDS)); DatabaseBind(request,6,(int)m_cache[i].level); DatabaseBind(request,7,m_cache[i].origin); DatabaseBind(request,8,m_cache[i].filename); DatabaseBind(request,9,m_cache[i].function); DatabaseBind(request,10,m_cache[i].line); DatabaseRead(request); DatabaseReset(request); } } //--- DatabaseFinalize(request); //--- Close database DatabaseClose(handle_db); } //+------------------------------------------------------------------+
Por fim, o método Close() garante que todos os logs pendentes sejam gravados antes do encerramento.
void CLogifyHandlerDatabase::Close(void) { Flush(); }
Com isso, implementamos um manipulador (handler) robusto, garantindo que os logs sejam armazenados de forma eficiente e sem perda de dados. O próximo passo, agora que nosso manipulador (handler) de banco de dados está pronto para gravar registros de log, é criar métodos eficientes para consultar esses registros. A ideia é ter um método base genérico, chamado Query(), que receba um comando SQL em formato de string e retorne os dados em um array do tipo MqlLogifyModel. A partir dele, podemos construir métodos específicos para facilitar consultas recorrentes. Nosso método Query() será responsável por abrir o banco de dados, executar a consulta e armazenar os resultados na estrutura de log. Veja a implementação abaixo:
class CLogifyHandlerDatabase : public CLogifyHandler { public: //--- Query methods bool Query(string query, MqlLogifyModel &data[]); }; //+------------------------------------------------------------------+ //| Get data by sql command | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::Query(string query, MqlLogifyModel &data[]) { //--- Get the full path of the file string path = m_config.directory+"\\"+m_config.base_filename+".sqlite"; //--- Open database ResetLastError(); int handle_db = DatabaseOpen(path,DATABASE_OPEN_READWRITE); if(handle_db == INVALID_HANDLE) { Print("[ERROR] ["+TimeToString(TimeCurrent())+"] Log system error: Unable to open log file '"+path+"'. Certifique-se de que o diretório existe e permite gravação. (Code: "+IntegerToString(GetLastError())+")"); return(false); } //--- Prepare the SQL query int request = DatabasePrepare(handle_db,query); if(request == INVALID_HANDLE) { Print("Erro query"); return(false); } //--- Clears array before inserting new data ArrayFree(data); //--- Reads query results line by line for(int i=0;DatabaseRead(request);i++) { int size = ArraySize(data); ArrayResize(data,size+1,size); //--- Maps database data to the MqlLogifyModel model DatabaseColumnText(request,1,data[size].formated); DatabaseColumnText(request,2,data[size].levelname); DatabaseColumnText(request,3,data[size].msg); DatabaseColumnText(request,4,data[size].args); DatabaseColumnLong(request,5,data[size].timestamp); string value; DatabaseColumnText(request,6,value); data[size].date_time = StringToTime(value); DatabaseColumnInteger(request,7,data[size].level); DatabaseColumnText(request,8,data[size].origin); DatabaseColumnText(request,9,data[size].filename); DatabaseColumnText(request,10,data[size].function); DatabaseColumnLong(request,11,data[size].line); } //--- Ends the query and closes the database DatabaseFinalize(handle_db); DatabaseClose(handle_db); return(true); } //+------------------------------------------------------------------+
Esse método nos oferece total flexibilidade para executar qualquer consulta SQL dentro do banco de dados de logs. No entanto, para facilitar seu uso, criaremos métodos auxiliares que encapsulam as consultas mais comuns.
Para evitar que os desenvolvedores precisem escrever SQL toda vez que quiserem consultar logs, criei métodos que já incluem os comandos SQL mais utilizados. Eles funcionam como atalhos para pesquisar logs filtrando por nível de severidade, data, origem, mensagem, argumentos, nome do arquivo e nome da função. Abaixo estão os comandos SQL correspondentes a cada um desses filtros:
SELECT * FROM 'logs' WHERE level=1;
SELECT * FROM 'logs' WHERE timestamp BETWEEN '{start_time}' AND '{stop_time}';
SELECT * FROM 'logs' WHERE origin LIKE '%{origin}%';
SELECT * FROM 'logs' WHERE msg LIKE '%{msg}%';
SELECT * FROM 'logs' WHERE args LIKE '%{args}%';
SELECT * FROM 'logs' WHERE filename LIKE '%{filename}%';
SELECT * FROM 'logs' WHERE function LIKE '%{function}%'; Agora, implementamos os métodos específicos que utilizam esses comandos:
class CLogifyHandlerDatabase : public CLogifyHandler { public: //--- Query methods bool Query(string query, MqlLogifyModel &data[]); bool QueryByLevel(ENUM_LOG_LEVEL level, MqlLogifyModel &data[]); bool QueryByDate(datetime start_time, datetime stop_time, MqlLogifyModel &data[]); bool QueryByOrigin(string origin, MqlLogifyModel &data[]); bool QueryByMsg(string msg, MqlLogifyModel &data[]); bool QueryByArgs(string args, MqlLogifyModel &data[]); bool QueryByFile(string file, MqlLogifyModel &data[]); bool QueryByFunction(string function, MqlLogifyModel &data[]); }; //+------------------------------------------------------------------+ //| Get logs filtering by level | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByLevel(ENUM_LOG_LEVEL level, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE level="+IntegerToString(level)+";",data)); } //+------------------------------------------------------------------+ //| Get logs filtering by start end stop time | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByDate(datetime start_time, datetime stop_time, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE timestamp BETWEEN '"+IntegerToString((ulong)start_time)+"' AND '"+IntegerToString((ulong)stop_time)+"';",data)); } //+------------------------------------------------------------------+ //| Get logs filtering by origin | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByOrigin(string origin, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE origin LIKE '%"+origin+"%';",data)); } //+------------------------------------------------------------------+ //| Get logs filtering by message | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByMsg(string msg, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE msg LIKE '%"+msg+"%';",data)); } //+------------------------------------------------------------------+ //| Get logs filtering by args | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByArgs(string args, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE args LIKE '%"+args+"%';",data)); } //+------------------------------------------------------------------+ //| Get logs filtering by file name | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByFile(string file, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE filename LIKE '%"+file+"%';",data)); } //+------------------------------------------------------------------+ //| Get logs filtering by function name | //+------------------------------------------------------------------+ bool CLogifyHandlerDatabase::QueryByFunction(string function, MqlLogifyModel &data[]) { return(this.Query("SELECT * FROM 'logs' WHERE function LIKE '%"+function+"%';",data)); } //+------------------------------------------------------------------+
Agora temos um conjunto de métodos eficientes e flexíveis para acessar os logs diretamente do banco de dados. O método Query() permite executar qualquer comando SQL, inclusive possibilitando passar um comando SQL mais complexo, com mais filtros, dependendo das suas necessidades específicas, enquanto os métodos auxiliares encapsulam as consultas mais comuns, tornando seu uso mais intuitivo e reduzindo a ocorrência de erros.
Agora que nosso manipulador (handler) está implementado, é hora de testar se tudo está funcionando corretamente. Vamos visualizar os resultados e garantir que os logs estejam sendo armazenados e recuperados conforme o esperado.
Visualizando o resultado
Após implementar o manipulador (handler), o próximo passo é verificar se ele está funcionando conforme o esperado. Precisamos testar a inserção dos logs, validar se os registros estão sendo armazenados corretamente no banco de dados e garantir que as consultas sejam rápidas e precisas.
Nos testes, utilizarei o mesmo arquivo LogifyTest.mq5, apenas adicionando algumas mensagens de log no início. Também adicionaremos algumas operações sem uma estratégia complexa, apenas abrindo uma posição caso não exista nenhuma posição aberta e definindo take profit e stop loss na posição para realizar a saída.
//+------------------------------------------------------------------+ //| Import CLogify | //+------------------------------------------------------------------+ #include <Logify/Logify.mqh> #include <Trade/Trade.mqh> CLogify logify; CTrade trade; //+------------------------------------------------------------------+ //| Expert initialization function | //+------------------------------------------------------------------+ int OnInit() { //--- Configs MqlLogifyHandleDatabaseConfig m_config; m_config.directory = "db"; m_config.base_filename = "logs"; m_config.messages_per_flush = 5; //--- Handler Database CLogifyHandlerDatabase *handler_database = new CLogifyHandlerDatabase(); handler_database.SetConfig(m_config); handler_database.SetLevel(LOG_LEVEL_DEBUG); handler_database.SetFormatter(new CLogifyFormatter("hh:mm:ss","{date_time} [{levelname}] {msg}")); //--- Add handler in base class logify.AddHandler(handler_database); //--- Using logs logify.Info("Expert starting successfully", "Boot", "",__FILE__,__FUNCTION__,__LINE__); return(INIT_SUCCEEDED); } //+------------------------------------------------------------------+ //| Expert deinitialization function | //+------------------------------------------------------------------+ void OnDeinit(const int reason) { //--- } //+------------------------------------------------------------------+ //| Expert tick function | //+------------------------------------------------------------------+ void OnTick() { //--- No positions if(PositionsTotal() == 0) { double price_entry = SymbolInfoDouble(_Symbol,SYMBOL_ASK); double volume = 1; if(trade.Buy(volume,_Symbol,price_entry,price_entry - 100 * _Point, price_entry + 100 * _Point,"Buy at market")) { logify.Debug("Transaction data | Price: "+DoubleToString(price_entry,_Digits)+" | Symbol: "+_Symbol+" | Volume: "+DoubleToString(volume,2), "CTrade", "",__FILE__,__FUNCTION__,__LINE__); logify.Info("Purchase order sent successfully", "CTrade", "",__FILE__,__FUNCTION__,__LINE__); } else { logify.Debug("Error code: "+IntegerToString(trade.ResultRetcode(),_Digits)+" | Description: "+trade.ResultRetcodeDescription(), "CTrade", "",__FILE__,__FUNCTION__,__LINE__); logify.Error("Failed to send purchase order", "CTrade", "",__FILE__,__FUNCTION__,__LINE__); } } } //+------------------------------------------------------------------+
Ao testar o Strategy Tester durante 1 dia no EURUSD, foi suficiente para gerar 909 registros de log. Conforme configurado, eles foram salvos no arquivo .sqlite. Para acessá-los, basta abrir a pasta do terminal ou pressionar “Ctrl/Cmd + Shift + D”, e o explorador de arquivos será exibido. Siga o caminho “MQL5/Files/db/logs.sqlite”. Com o arquivo em mãos, podemos abri-lo diretamente no MetaEditor, como fizemos anteriormente:
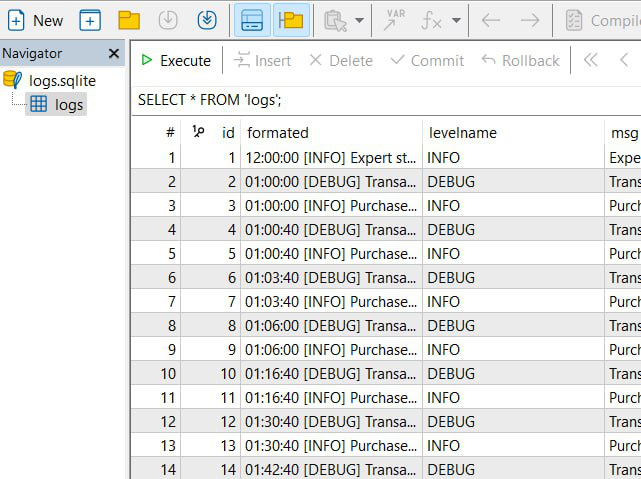
Com isso, concluímos mais uma etapa da nossa biblioteca de logs. Agora, nossos logs podem ser armazenados e recuperados de forma eficiente em um banco de dados, proporcionando maior escalabilidade e organização.
Conclusão
Ao longo deste artigo, exploramos a integração de bancos de dados à nossa biblioteca de logs, desde os conceitos fundamentais até a implementação prática de um manipulador (handler)dedicado. Primeiramente, discutimos a importância dos bancos de dados como uma alternativa mais escalável e estruturada para o armazenamento de logs, destacando suas vantagens em relação aos arquivos de texto convencionais. Em seguida, examinamos as particularidades do uso de bancos de dados no contexto do MQL5, abordando suas limitações e as soluções disponíveis para superá-las.
Por fim, analisamos os resultados da nossa implementação, garantindo que os logs fossem armazenados corretamente e pudessem ser acessados de forma rápida e eficiente. Além disso, discutimos maneiras de visualizar esses logs, seja por meio de consultas diretas ao banco de dados ou por ferramentas específicas para monitoramento de logs. Esse processo de validação foi essencial para garantir que a solução implementada fosse funcional e eficaz em cenários reais.
Com isso, concluímos mais uma etapa no desenvolvimento da nossa biblioteca de logs. A adoção de bancos de dados para armazenar logs trouxe benefícios significativos, tornando o gerenciamento dos registros mais organizado, acessível e escalável. Essa abordagem nos permite lidar com grandes volumes de dados de forma mais eficiente, além de facilitar a análise e o monitoramento das informações registradas pelo sistema.
Traduzido do Inglês pela MetaQuotes Ltd.
Artigo original: https://www.mql5.com/en/articles/17709
Aviso: Todos os direitos sobre esses materiais pertencem à MetaQuotes Ltd. É proibida a reimpressão total ou parcial.
Esse artigo foi escrito por um usuário do site e reflete seu ponto de vista pessoal. A MetaQuotes Ltd. não se responsabiliza pela precisão das informações apresentadas nem pelas possíveis consequências decorrentes do uso das soluções, estratégias ou recomendações descritas.

 Está chegando o novo MetaTrader 5 e MQL5
Está chegando o novo MetaTrader 5 e MQL5
- Aplicativos de negociação gratuitos
- 8 000+ sinais para cópia
- Notícias econômicas para análise dos mercados financeiros
Você concorda com a política do site e com os termos de uso